理想的实验
1.关于“问题”的问题
一项研究计划可以围绕四个基本问题(frequently asked questions,FAQ)展开:
- 研究对象间的(因果)关系(relationship of interest)
这里更关注的是“因果关系”,谁是因,谁是果?
→班级规模对学生分数的影响
→教育水平对工资水平的因果效用,个体接受更多的教育所带来的工资增长量
→殖民地制度对经济增长的影响
- 理想条件下的实验(ideal experiment)
理想条件下的实验通常是假设出来的
这个问题让我们思考如果能进行理想的实验,我们会怎样做。
这通常涉及到一种假设情况,我们可以完全控制并随机分配影响因果关系的所有潜在变量。这是一种理论上的设想,可以帮助我们设计实际的研究方法。
- 识别策略(identification strategy)
研究人员如何运用观察数据(不是随机实验产生的数据)来逼近真实实验
- 推断模型(mode of interest)
需要描述被研究的总体、所使用的样本以及构建标准误时所作的假设
这四个问题提供了一个从提出研究问题到设计实验,然后进行数据分析并得出结论的基本框架。在经济学和其他社会科学的研究中,这是一种非常有用的方法。
2.理想的实验
最可信和最有影响力的研究设计应该使用随机分配(random assignment)的方法
2.1 选择性偏误
研究问题:医院能让人变得更健康吗?
调查方法:全国健康采访调研
| 组别 | 样本大小 | 平均健康水平 | 标准误 |
|---|---|---|---|
| 去过医院 | 7774 | 3.21 | 0.014 |
| 没有去过医院 | 90049 | 3.93 | 0.003 |
从表格知道,两者之间的平均差距是0.72,没有去过医院的人健康状况更好,两者之差大且显著, t t t统计量为58.9。这个结果意味着去医院会使人健康状况变差。
❓事实真是如此吗? 去医院的人可能本身健康水平就比较差。人们去医院通常是因为他们生病或者有健康问题,而健康的人则不需要去医院。因此,当我们比较这两组人的健康状况时,我们实际上是在比较生病的人和健康的人,而不是比较去医院的效果。这个问题被称为选择性偏误,因为人们是否去医院是根据他们的健康状况来选择的,而这个选择可能与他们的健康状况相关。这使得我们很难确定去医院是否会改善人们的健康状况,因为我们不能确定健康状况的改变是由于去医院,还是由于他们本来就生病。
🔆解决这个问题的一种方法是使用随机化实验设计。
- 个体 i i i是否接受医院治疗 D i = { 0 , 1 } D_i=\{0,1\} Di={0,1},个体 i i i的健康水平记为 Y i Y_i Yi。对于任何个体而言,他们的健康状况都有两种潜在结果:
Y i = { Y 1 i if D i > 0 Y 0 i if D i = 0 = Y 0 i + ( Y 1 i − Y 0 i ) D i Y_i = \begin{cases} Y_{1i} & \text{if } D_i > 0 \\ Y_{0i} & \text{if } D_i = 0 \end{cases} = Y_{0i}+(Y_{1i}-Y_{0i})D_i Yi={Y1iY0iif Di>0if Di=0=Y0i+(Y1i−Y0i)Di
也就是说,一个人没有去医院,他的健康状态是 Y 0 i Y_{0i} Y0i;一个人去医院接受了治疗,他的健康状态是 Y 1 i Y_{1i} Y1i。我们想知道的个体因果效应就是 Y 1 i − Y 0 i Y_{1i}-Y_{0i} Y1i−Y0i,这个值可以解释为个体 i i i在医院接受治疗对其健康状况产生的影响。【Rubin因果模型】
2.平均因果效应(average casual effect)
E [ Y i ∣ D i = 1 ] − E [ Y i ∣ D i = 0 ] = E [ Y 1 i ∣ D i = 1 ] − E [ Y 0 i ∣ D i = 0 ] = E [ Y 1 i ∣ D i = 1 ] − E [ Y 0 i ∣ D i = 1 ] + E [ Y 0 i ∣ D i = 1 ] − E [ Y 0 i ∣ D i = 0 ] E[Y_i| D_i =1]-E[Y_i| D_i =0] \\ =E[Y_{1i}|D_i=1]-E[Y_{0i}|D_i=0] \\ =E[Y_{1i}|D_i=1]-E[Y_{0i}|D_i=1]+E[Y_{0i}|D_i=1]-E[Y_{0i}|D_i=0] E[Yi∣Di=1]−E[Yi∣Di=0]=E[Y1i∣Di=1]−E[Y0i∣Di=0]=E[Y1i∣Di=1]−E[Y0i∣Di=1]+E[Y0i∣Di=1]−E[Y0i∣Di=0]
其中, E [ Y 1 i ∣ D i = 1 ] E[Y_{1i}|D_i=1] E[Y1i∣Di=1]是接受住院治疗的人的平均健康水平, E [ Y 0 i ∣ D i = 1 ] E[Y_{0i}|D_i=1] E[Y0i∣Di=1]是如果接受住院治疗的人本来没有得到治疗,他们的健康水平。
E [ Y 1 i ∣ D i = 1 ] − E [ Y 0 i ∣ D i = 1 ] E[Y_{1i}|D_i=1]-E[Y_{0i}|D_i=1] E[Y1i∣Di=1]−E[Y0i∣Di=1]是处理的平均因果效应
E [ Y 0 i ∣ D i = 1 ] − E [ Y 0 i ∣ D i = 0 ] E[Y_{0i}|D_i=1]-E[Y_{0i}|D_i=0] E[Y0i∣Di=1]−E[Y0i∣Di=0]是选择性偏误。是去医院的接受治疗与不去医院接受治疗的人如果没有被治疗时的健康状况的平均差异。
2.2 用随机分配解决选择性偏误
补充:
随机分配处理是消除选择性偏误的一种方法,因为它可以确保处理组和控制组在其他所有相关特性上的分布是相同的。这意味着,任何观察到的结果差异都可以归因于处理,而不是混淆变量。更具体地说,当处理( D i D_i Di)是随机分配的,我们可以期望处理组和控制组在未观察到的特性上的平均值是相同的。
补充:
随机分配满足非混杂性:给定协变量 X i X_i Xi,对个体的干预分配独立于潜在结果,即
( Y 0 i , Y 1 i ) ⊥ D i ∣ X i (Y_{0i}, Y_{1i}) \perp D_i | X_i (Y0i,Y1i)⊥Di∣Xi
其中, ⊥ \perp ⊥ 表示独立性, Y 0 i Y_{0i} Y0i 和 Y 1 i Y_{1i} Y1i 是潜在结果, D i D_i Di 是处理指示符(例如,是否去医院), X i X_i Xi 是协变量向量(例如,个体的其他特性)。
对 D i D_i Di进行随机分配可以消除选择性偏误,因为随机分配使得 D i D_i Di独立于潜在结果。在数学上,这意味着
E [ Y 0 i ∣ D i = 1 ] = E [ Y 0 i ∣ D i = 0 ] E[Y_{0i}|D_i=1] = E[Y_{0i}|D_i=0] E[Y0i∣Di=1]=E[Y0i∣Di=0]
如果这个等式成立,那么选择性偏误就为0,因为选择性偏误被定义为
E [ Y 0 i ∣ D i = 1 ] − E [ Y 0 i ∣ D i = 0 ] E[Y_{0i}|D_i=1] - E[Y_{0i}|D_i=0] E[Y0i∣Di=1]−E[Y0i∣Di=0]
因此,当处理是随机分配的,可以得出
E [ Y i ∣ D i = 1 ] − E [ Y i ∣ D i = 0 ] = E [ Y 1 i ∣ D i = 1 ] − E [ Y 0 i ∣ D i = 1 ] = E [ Y 1 i − Y 0 i ∣ D i = 1 ] = E [ Y 1 i − Y 0 i ] E[Y_i|D_i=1]-E[Y_i|D_i=0]=E[Y_{1i}|D_i=1]-E[Y_{0i}|D_i=1] =E[Y_{1i}-Y_{0i}|D_i=1]=E[Y_{1i}-Y_{0i}] E[Yi∣Di=1]−E[Yi∣Di=0]=E[Y1i∣Di=1]−E[Y0i∣Di=1]=E[Y1i−Y0i∣Di=1]=E[Y1i−Y0i]
也就是说,处理的平均因果效应等于接受治疗和不接受治疗的个体的期望健康状况之差。这就允许我们直接估计平均因果效应,而无需担心选择性偏误的问题。
2.3 对实验的回归分析
Y i = β 0 + β 1 D i + ϵ i Y_i = \beta_0 + \beta_1 D_i + \epsilon_i Yi=β0+β1Di+ϵi
其中, β 0 = E ( Y 0 i ) \beta_0=E(Y_{0i}) β0=E(Y0i), β 1 = ( Y 1 i − Y 0 i ) \beta_1=(Y_{1i}-Y_{0i}) β1=(Y1i−Y0i), ϵ i \epsilon_i ϵi是 Y 0 i Y_{0i} Y0i的随机部分,即 ϵ i = Y 0 i − E ( Y 0 i ) \epsilon_i=Y_{0i}-E(Y_{0i}) ϵi=Y0i−E(Y0i)
对上面这个等式求数学期望:
E [ Y i ∣ D i = 1 ] = β 0 + β 1 + E [ ϵ i ∣ D i = 1 ] E[Y_i|D_i=1]=\beta_0 + \beta_1+E[\epsilon_i|D_i=1] E[Yi∣Di=1]=β0+β1+E[ϵi∣Di=1]
E [ Y i ∣ D i = 0 ] = β 0 + E [ ϵ i ∣ D i = 0 ] E[Y_i|D_i=0]=\beta_0 +E[\epsilon_i|D_i=0] E[Yi∣Di=0]=β0+E[ϵi∣Di=0]
两式相减, E [ Y i ∣ D i = 1 ] − E [ Y i ∣ D i = 0 ] = β 1 + E [ ϵ i ∣ D i = 1 ] − E [ ϵ i ∣ D i = 0 ] E[Y_i|D_i=1]-E[Y_i|D_i=0]=\beta_1+E[\epsilon_i|D_i=1]-E[\epsilon_i|D_i=0] E[Yi∣Di=1]−E[Yi∣Di=0]=β1+E[ϵi∣Di=1]−E[ϵi∣Di=0]
β 1 \beta_1 β1是处理效应, E [ ϵ i ∣ D i = 1 ] − E [ ϵ i ∣ D i = 0 ] E[\epsilon_i|D_i=1]-E[\epsilon_i|D_i=0] E[ϵi∣Di=1]−E[ϵi∣Di=0]是选择性偏误
因此,选择性偏误意味着回归残差项 ϵ i \epsilon_i ϵi和回归元 D i D_i Di之间存在着相关性。
在随机化实验中,由于处理的分配是随机的,我们可以直接使用这个简单的回归模型来估计平均因果效应,而无需控制其他协变量。然而,在观察性研究中,我们通常需要将模型扩展为多元回归模型,以控制可能的混淆变量。例如:
Y i = β 0 + β 1 D i + β 2 X i + ϵ i Y_i = \beta_0 + \beta_1 D_i + \beta_2 X_i + \epsilon_i Yi=β0+β1Di+β2Xi+ϵi
其中, X i X_i Xi 是一个或多个协变量。在这个模型中, β 1 \beta_1 β1 仍然是处理的平均因果效应,但现在这个效应是在控制了 X i X_i Xi 的影响之后得到的。
相关文章:

理想的实验
1.关于“问题”的问题 一项研究计划可以围绕四个基本问题(frequently asked questions,FAQ)展开: 研究对象间的(因果)关系(relationship of interest) 这里更关注的是“因果关系”,…...

nginx配置开机启动(Windows环境)
文章目录 1、下载nginx,并解压2、配置nginx.conf,并启动Nginx3、开机自启动 1、下载nginx,并解压 2、配置nginx.conf,并启动Nginx 两种方法: 方法一:直接双击nginx.exe,双击后一个黑色弹窗一闪…...
)
MySQL 基础面试题02(事务索引)
1.什么是 MySQL 事务? MySQL 事务是指一组操作,是一个不可分割的工作单位,可以确保一组数据库操作要么全部执行,要么全部不执行。换句话说,事务是 MySQL 中保证数据一致性和完整性的机制。 在 MySQL 中,事…...
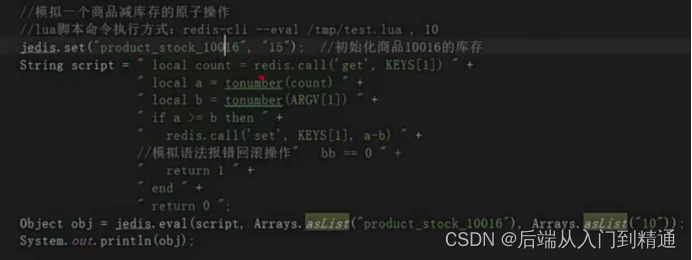
主从架构lua脚本-Redis(四)
上篇文章介绍了rdb、aof持久化。 持久化RDB/AOF-Redis(三)https://blog.csdn.net/ke1ying/article/details/131148269 redis数据备份策略 写job每小时copy一份到其他目录。目录里可以保留最近一个月数据。把目录日志保存到其他服务器,防止机…...

maven与idea版本适配问题
maven与idea版本适配问题 1.版本对应关系——3.6.3 注意:针对一些老项目 还是尽量采用 3.6.3版本,针对idea各个版本的兼容性就很兼容 0.IDEA 2022 兼容maven 3.8.1及之前的所用版本 1.IDEA 2021 兼容maven 3.8.1及之前的所用版本 2.IDEA 2020 兼容Mave…...

ChatGPT扫盲知识库
本文并不是教你如何使用ChatGPT,而是帮助小白理清一些与ChatGPT相关的概念,并解释一些常见的问题。 概念 OpenAI: 一家人工智能公司,ChatGPT属于该公司的产品之一。前身是一个非盈利组织,不过目前已经转变为一家商业公司。 GPT: O…...

chatgpt赋能python:Python轨迹可视化:用数据讲故事
Python轨迹可视化:用数据讲故事 介绍 随着物联网、智能城市等领域的发展,越来越多的数据被收集下来并存储在数据库中。这些数据对于决策者来说是非常重要的,但是如何将这些数据进行展示和分析呢?这时候Python轨迹可视化就可以派…...

K-means
K-means 主要缺点:对于高维度数据,用kmeans方法可能会受到数据形态的影响,其假设高维数据呈球形分布。...
)
归并排序(基础+提升)
目录 归并排序的理论知识 归并排序的实现 merge函数 递归实现 递归改非递归 归并排序的性能分析 题目强化 题目一:小和问题 题目二:求数组中的大两倍数对数量 题目三:LeetCode_327. 区间和的个数 归并排序的理论知识 归并排序&…...

MATLAB应用
目录 网站 智能图像色彩缩减和量化 网站 https://yarpiz.com/ 智能图像色彩缩减和量化 使用智能聚类方法:(a)k均值算法,(b)模糊c均值聚类(FCM)和(c)自组织神…...

LeetCode --- 1784. Check if Binary String Has at Most One Segment of Ones 解题报告
Given a binary string s without leading zeros, return true if s contains at most one contiguous segment of ones. Otherwise, return false. Example 1: Input: s = "1001" Output: false Explanation: The ones do not form a contiguous s…...

js:javascript中的事件体系:常见事件、事件监听、事件移除、事件冒泡、事件捕获、事件委托、阻止事件
参考资料 事件介绍Element事件 目录 常见的事件鼠标事件键盘事件Focus events 添加事件监听方式一:addEventListener()(推荐)方式二:事件处理器属性方式三:内联事件处理器(不推荐) 移除监听器方…...

【数据结构】特殊矩阵的压缩存储
🎇【数据结构】特殊矩阵的压缩存储🎇 🌈 自在飞花轻似梦,无边丝雨细如愁 🌈 🌟 正式开始学习数据结构啦~此专栏作为学习过程中的记录🌟 文章目录 🎇【数据结构】特殊矩阵的压缩存储Ἰ…...

在layui中使用vue,使用vue进行页面数据部分数据更新
layui是一款非常优秀的框架,使用也非常的广泛,许多后台管理系统都使用layui,简单便捷,但是在涉及页面部分数据变化,就比较难以处理,比如一个页面一个提交页,提交之后部分数据实时进行更新&#…...

Vue中如何进行数据导入与Excel导入
Vue中如何进行数据导入与Excel导入 Vue是一款非常流行的JavaScript框架,它提供了一套用于构建用户界面的工具和库。在Vue中,我们可以使用多种方式来导入数据,包括从服务器获取数据、从本地存储获取数据、从文件中读取数据等等。其中…...

git 的基本操作
1. git建立本地仓库 在想要建立的目录下输入命令 git init 我们可以看一下 .git目录下有什么 2. 配置git本地仓库 配置用户的 name 和 email 命令:git config [...] 配置完后,我们像查看一下 刚才的配置 2.1 查看配置命令 git config -l 2.2 删除…...
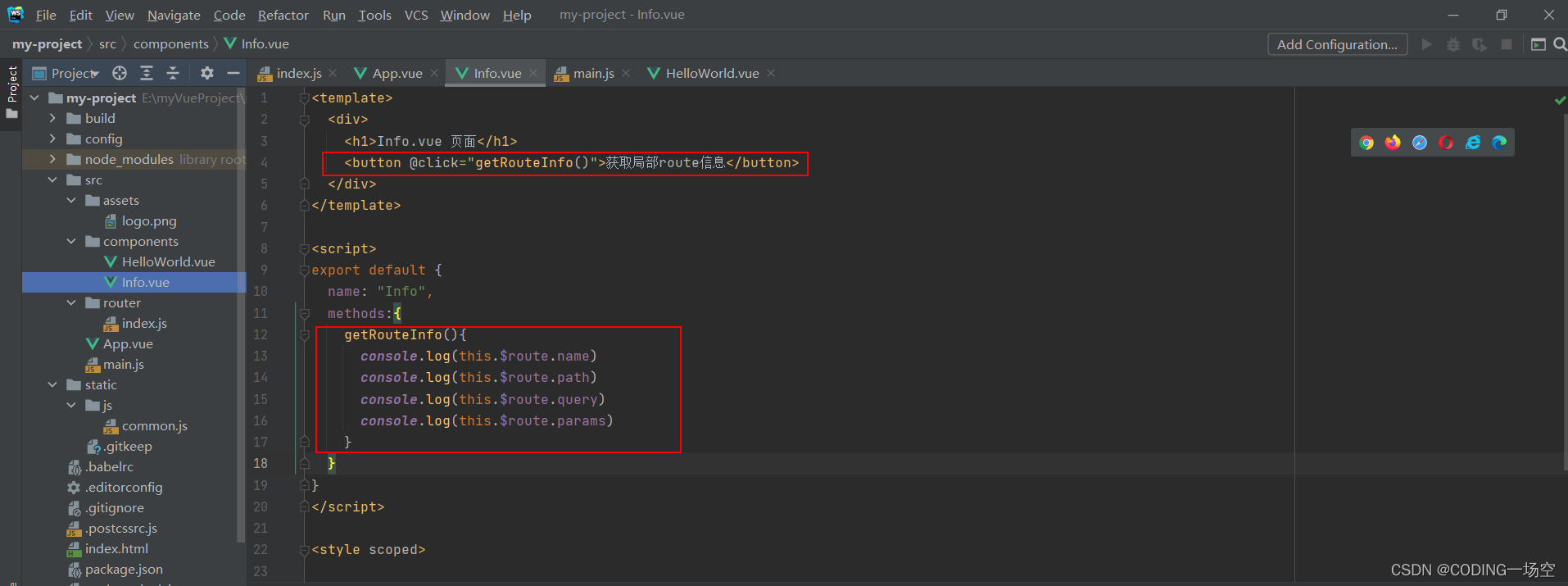
搭建Vue项目以及项目的常见知识
前言:使用脚手架搭建vue项目,使用脚手架可以开发者能够开箱即用快速地进行应用开发而开发。 搭建 #创建一个基于 webpack 模板的新项目 vue init webpack my-project #选择所需要的选项如图: cd my-project npm run dev访问localhost:808…...

TypeScript ~ TS Webpack构建工具 ⑦
作者 : SYFStrive 博客首页 : HomePage 📜: TypeScript ~ TS 📌:个人社区(欢迎大佬们加入) 👉:社区链接🔗 📌:觉得文章不错可以点点关注 &…...

Rust 自建HTTP Server支持图片响应
本博客是在杨旭老师的 rust web 全栈教程项目基础上进行修改,支持了图片资源返回,杨旭老师的rust web链接如下: https://www.bilibili.com/video/BV1RP4y1G7KFp1&vd_source8595fbbf160cc11a0cc07cadacf22951 本人默认读者已经学习了相关…...

[游戏开发][Unity]UnityWebRequest使用大全
首先记录个小问题 使用new UnityWebRequest的方式,最终的downloadHandler是个null 使用UnityWebRequest.Get的方式,最终的downloadHandler会是DownloadHandlerBuffer 从网站或本地下载内容,包括文本或二进制数据 IEnumerator downloadfile(st…...

效率飙升,跳过proteus安装配置,用快马ai秒建仿真项目
最近在做一个温度监测系统的项目,需要验证电路设计的可行性。按照传统方式,我得先下载安装Proteus软件,配置各种库文件,光是环境准备就得折腾半天。不过这次尝试了用InsCode(快马)平台的AI功能,整个过程变得异常高效。…...

KOReader终极指南:如何打造你的完美电子墨水屏阅读体验
KOReader终极指南:如何打造你的完美电子墨水屏阅读体验 【免费下载链接】koreader An ebook reader application supporting PDF, DjVu, EPUB, FB2 and many more formats, running on Cervantes, Kindle, Kobo, PocketBook and Android devices 项目地址: https:…...
)
Windows11状态栏图标失效?手把手教你修复注册表关联(附一键脚本)
Windows 11状态栏图标失效的终极修复指南:从原理到实战 Windows 11以其现代化的界面设计吸引了不少用户,但系统自定义过程中难免会遇到各种"小脾气"。最近不少用户反馈,在尝试去除桌面图标小箭头后,状态栏的应用程序图标…...
数据库事务超时:超时设置与回滚机制终极指南)
cool-admin(midway版)数据库事务超时:超时设置与回滚机制终极指南
cool-admin(midway版)数据库事务超时:超时设置与回滚机制终极指南 【免费下载链接】cool-admin-midway 🔥 cool-admin(midway版)一个很酷的后台权限管理框架,模块化、插件化、CRUD极速开发,永久开源免费,基于midway.js…...

2026年4月OpenClaw怎么集成?京东云小白6分钟部署及百炼APIKey配置步骤
2026年4月OpenClaw怎么集成?京东云小白6分钟部署及百炼APIKey配置步骤。OpenClaw(原Clawdbot)作为2026年主流的AI自动化助理平台,可通过阿里云轻量服务器实现724小时稳定运行,并快速接入钉钉,让AI在企业群聊…...

TouchGal:3个关键功能让你成为真正的Galgame收藏家
TouchGal:3个关键功能让你成为真正的Galgame收藏家 【免费下载链接】kun-touchgal-next TouchGAL是立足于分享快乐的一站式Galgame文化社区, 为Gal爱好者提供一片净土! 项目地址: https://gitcode.com/gh_mirrors/ku/kun-touchgal-next 你是否曾为寻找心仪的…...

TEA算法逆向实战:从特征识别到脚本魔改的CTF通关指南
1. TEA算法特征快速识别指南 第一次在CTF比赛中遇到TEA算法时,我盯着反编译代码看了半小时都没反应过来。直到后来总结出几个关键特征,现在遇到这类题目基本能在30秒内锁定目标。最明显的标志就是那个魔性的delta常量0x9E3779B9(或者它的补码…...
)
手把手教你配置Figma MCP:打造属于你自己的AI驱动设计组件库(以阅读题为例)
智能设计革命:用Figma MCP构建AI驱动的交互式学习组件库 当设计系统遇上生成式AI,一场关于效率与智能化的变革正在悄然发生。在Figma中构建可动态响应数据的智能组件库,已成为中高级UI/UX设计师突破传统设计边界的必备技能。本文将深入解析如…...

c++阿克曼函数详解
不爱吃饭的蓝胖子要开始整活了!!!大家好,我是蓝胖子!好久不见,倍感思念!今天带来的是--C阿克曼函数~~希望你能看到最后,有惊喜哈!正片开始 ——————————————…...

终极指南:免费开源fSpy相机匹配工具,3分钟实现2D图像到3D场景的完美转换
终极指南:免费开源fSpy相机匹配工具,3分钟实现2D图像到3D场景的完美转换 【免费下载链接】fSpy A cross platform app for quick and easy still image camera matching 项目地址: https://gitcode.com/gh_mirrors/fs/fSpy 还在为将2D照片转换为精…...