python爬虫从入门到精通
目录
一、正确认识Python爬虫
二、了解爬虫的本质
1. 熟悉Python编程
2. 了解HTML
3. 了解网络爬虫的基本原理
4. 学习使用Python爬虫库
三、了解非结构化数据的存储
1. 本地文件
2. 数据库
四、掌握各种技巧,应对特殊网站的反爬措施
1. User-Agent
2. Cookies
3. IP代理
五、学习爬虫框架,搭建工程化的爬虫
1. 创建Scrapy项目
2. 创建Spider
3. 编写Spider
4. 运行Spider
六、学习数据库基础,应对大规模数据存储
1. 数据库类型
2. 数据库设计
3. 数据库操作
七、分布式爬虫,实现大规模并发采集
1. 安装Redis
2. 安装Scrapy-Redis
3. 修改Scrapy配置
4. 编写Spider
5. 运行Spider
总结
一、正确认识Python爬虫
Python爬虫是指使用Python编程语言编写的一种程序,用于自动化地从互联网上获取数据。Python爬虫可以自动化地访问网站、获取网页内容、解析网页数据、存储数据等操作,从而实现对互联网上的数据进行快速、高效的获取和处理。
Python爬虫在各个领域都有广泛的应用,比如搜索引擎、数据分析、金融、医疗、教育等领域。Python爬虫的优点是可以快速地获取大量数据,同时可以自动化地处理数据,提高工作效率。
二、了解爬虫的本质
1. 熟悉Python编程
Python是一种高级编程语言,具有简单、易学、易读、易写的特点。Python编程语言可以用于各种领域的开发,包括Web开发、数据分析、人工智能等。Python编程语言的优点是语法简单、代码可读性高、拥有丰富的库和工具,可以快速地开发出高效的程序。
2. 了解HTML
HTML是一种标记语言,用于创建Web页面。HTML是Web开发的基础,掌握HTML语言可以帮助我们更好地理解Web页面的结构和内容。在Python爬虫中,我们需要使用HTML解析库来解析网页内容,从而获取我们需要的数据。
3. 了解网络爬虫的基本原理
网络爬虫是一种自动化程序,用于从互联网上获取数据。网络爬虫的基本原理是通过HTTP协议向Web服务器发送请求,获取Web页面的内容,然后解析Web页面的内容,从中提取我们需要的数据。网络爬虫可以自动化地访问网站、获取网页内容、解析网页数据、存储数据等操作,从而实现对互联网上的数据进行快速、高效的获取和处理。
4. 学习使用Python爬虫库
Python爬虫库是用于编写Python爬虫程序的工具包。Python爬虫库包括了各种功能强大的库,比如Requests、BeautifulSoup、Scrapy等。这些库可以帮助我们快速地编写Python爬虫程序,从而实现对互联网上的数据进行快速、高效的获取和处理。
三、了解非结构化数据的存储
爬虫获取的数据通常是非结构化的,需要进行处理和存储。常见的存储方式有本地文件、数据库等。
1. 本地文件
将数据存储到本地文件中是最简单的方式之一。可以使用Python内置的open()方法打开文件,使用write()方法将数据写入文件中。例如:
with open('data.txt', 'w') as f:
f.write(data)
2. 数据库
将数据存储到数据库中可以更好地管理和查询数据。Python中常用的数据库有MySQL、MongoDB等。使用Python的数据库驱动程序,可以方便地连接数据库并进行数据的增删改查操作。例如,使用MySQL数据库:
import mysql.connector
mydb = mysql.connector.connect(
host="localhost",
user="yourusername",
password="yourpassword",
database="mydatabase"
)
mycursor = mydb.cursor()
sql = "INSERT INTO customers (name, address) VALUES (%s, %s)"
val = ("John", "Highway 21")
mycursor.execute(sql, val)
mydb.commit()
print(mycursor.rowcount, "record inserted.")
四、掌握各种技巧,应对特殊网站的反爬措施
为了防止爬虫对网站造成过大的负担,很多网站都会采取反爬措施。爬虫需要应对这些反爬措施,才能正常获取数据。
1. User-Agent
有些网站会根据User-Agent来判断请求是否来自浏览器。因此,可以在请求头中添加User-Agent,模拟浏览器的请求。例如:
import requests
url = 'http://www.example.com'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'}
response = requests.get(url, headers=headers)
2. Cookies
有些网站会根据Cookies来判断请求是否来自同一个用户。因此,可以在请求头中添加Cookies,模拟同一个用户的请求。例如:
import requests
url = 'http://www.example.com'
cookies = {'name': 'value'}
response = requests.get(url, cookies=cookies)
3. IP代理
有些网站会根据IP地址来判断请求是否来自同一个用户。因此,可以使用IP代理,模拟不同的IP地址的请求。例如:
import requests
url = 'http://www.example.com'
proxies = {'http': 'http://10.10.1.10:3128', 'https': 'https://10.10.1.10:1080'}
response = requests.get(url, proxies=proxies)
五、学习爬虫框架,搭建工程化的爬虫
使用爬虫框架可以更好地管理和维护爬虫代码,提高开发效率。Python中常用的爬虫框架有Scrapy、PySpider等。
以Scrapy为例,介绍如何搭建工程化的爬虫。
1. 创建Scrapy项目
使用命令行工具创建Scrapy项目。例如:
scrapy startproject myproject
2. 创建Spider
使用命令行工具创建Spider。例如:
scrapy genspider myspider example.com
3. 编写Spider
在Spider中编写爬虫代码。例如:
import scrapy
class MySpider(scrapy.Spider):
name = 'myspider'
start_urls = ['http://www.example.com']
def parse(self, response):
# 解析网页内容
pass
4. 运行Spider
使用命令行工具运行Spider。例如:
scrapy crawl myspider
六、学习数据库基础,应对大规模数据存储
爬虫获取的数据通常是非常庞大的,需要进行大规模的数据存储。因此,学习数据库基础非常重要。
1. 数据库类型
常用的数据库类型有关系型数据库和非关系型数据库。关系型数据库如MySQL、Oracle等,非关系型数据库如MongoDB、Redis等。
2. 数据库设计
数据库设计是数据库应用的重要环节。需要根据数据的特点,设计出合理的数据库结构,以便于数据的存储和查询。
3. 数据库操作
Python中常用的数据库操作库有MySQLdb、pymongo等。使用这些库,可以方便地连接数据库并进行数据的增删改查操作。
七、分布式爬虫,实现大规模并发采集
分布式爬虫可以实现大规模并发采集,提高爬虫效率。常用的分布式爬虫框架有Scrapy-Redis、Distributed Spider等。
以Scrapy-Redis为例,介绍如何实现分布式爬虫。
1. 安装Redis
使用命令行工具安装Redis。例如:
sudo apt-get install redis-server
2. 安装Scrapy-Redis
使用命令行工具安装Scrapy-Redis。例如:
pip install scrapy-redis
3. 修改Scrapy配置
在Scrapy配置文件中添加Redis相关配置。例如:
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
REDIS_URL = 'redis://localhost:6379'
4. 编写Spider
在Spider中编写爬虫代码。例如:
import scrapy
from scrapy_redis.spiders import RedisSpider
class MySpider(RedisSpider):
name = 'myspider'
redis_key = 'myspider:start_urls'
def parse(self, response):
# 解析网页内容
pass
5. 运行Spider
使用命令行工具运行Spider。例如:
scrapy runspider myspider.py
总结
本文从入门到精通的角度,介绍了Python爬虫的基本原理及过程,以及如何应对特殊网站的反爬措施,搭建工程化的爬虫框架,实现大规模并发采集等内容。希望本文能够帮助读者更好地理解Python爬虫技术,并在实践中取得更好的效果。
相关文章:

python爬虫从入门到精通
目录 一、正确认识Python爬虫 二、了解爬虫的本质 1. 熟悉Python编程 2. 了解HTML 3. 了解网络爬虫的基本原理 4. 学习使用Python爬虫库 三、了解非结构化数据的存储 1. 本地文件 2. 数据库 四、掌握各种技巧,应对特殊网站的反爬措施 1. User-Agent 2. C…...
从0到1精通自动化,接口自动化测试——数据驱动DDT实战
目录:导读 前言一、Python编程入门到精通二、接口自动化项目实战三、Web自动化项目实战四、App自动化项目实战五、一线大厂简历六、测试开发DevOps体系七、常用自动化测试工具八、JMeter性能测试九、总结(尾部小惊喜) 前言 DDT简介 名称&am…...

【微服务】springboot整合swagger多种模式使用详解
目录 一、前言 1.1 编写API文档 1.2 使用一些在线调试工具 1.3 postman 1.4 swagger 二、swagger简介</...

AI 绘画(1):生成一个图片的标准流程
文章目录 文章回顾感谢人员生成一个图片的标准流程前期准备,以文生图为例去C站下载你需要的绘画模型导入参数导入生成结果?可能是BUG事后处理 图生图如何高度贴合原图火柴人转角色 涂鸦局部重绘 Ai绘画公约 文章回顾 AI 绘画(0)&…...
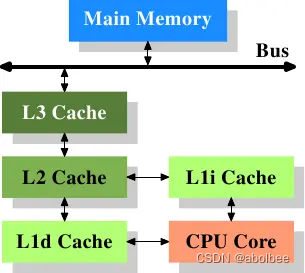
CPU、内存、缓存的关系
术语解释 (1)CPU(Central Processing Unit) 中央处理器 (2)内存 内存用于暂时存放CPU中的运算数据,以及与硬盘等外部存储器交换的数据。它是外存与CPU进行沟通的桥梁,内存的运行决定…...
AI黑客松近期比赛清单;36氪AI淘宝店盈利复盘;GitHub Copilot官方最佳实践;AI在HR领域的应用探索 | ShowMeAI日报
👀日报&周刊合集 | 🎡生产力工具与行业应用大全 | 🧡 点赞关注评论拜托啦! ⋙ 点击查看 AI Hackathon (黑客马拉松) 汇总清单 🤖 〖飞桨〗2023大模型应用创新挑战赛 百度飞桨联合上海市青年五十人创新创业研究院等…...
想要让视频素材格式快速调整转换的方法分享
有时候有些视频播放软件不支持播放某些格式的视频文件?那要怎么解决呢?换一个播放软件?不妨试试批量转换视频格式,简单的几步操作就能快速解决烦恼,跟着小编一起来看看具体的操作环节吧。 首先先进入“固乔科技”的官网…...

面向对象分析与设计 UML2.0 学习笔记
一、认识UML UML-Unified Modeling Language 统一建模语言,又称标准建模语言。是用来对软件密集系统进行可视化建模的一种语言。UML的定义包括UML语义和UML表示法两个元素。 UML是在开发阶段,说明、可视化、构建和书写一个面向对象软件密集系统的制品的…...
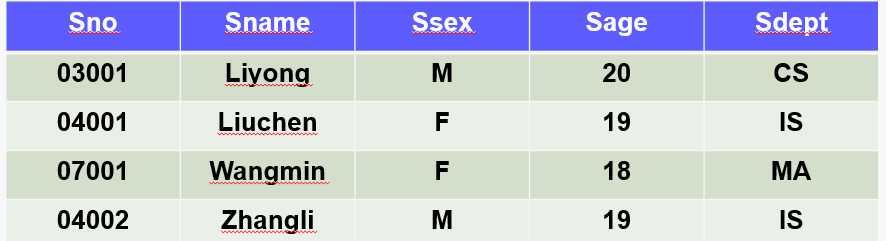
[数据库系统] 五、数据增删改
第一关:数据插入 用insert给数据库添加数据 相关知识 有关系student(sno,sname,ssex,sage,sdept),属性对应含义:学号,姓名,性别,所在系。现有的部分元组如下所示 insert 向数据库表插入数据的基本格式有…...

docker私有注册表创建和使用
说明 本文给出了一个具体的使用docker registry和nginx配置docker私有注册表的方案。 创建和配置 docker compose 使用docker compose的方式运行registry容器,配置如下: # cat docker-compose.yml services:registry:image: registry:2ports:- &quo…...

用OpenCV进行OCR字符分割
1. 引言 本文重点介绍如何利用传统的图像处理的方法来进行OCR字符切分,进而可以用分割后的单个字符做相应的后续任务,虽然现在计算机视觉依然是卷积神经网络的天下,但是对于一些相对简单的落地场景传统方案还是很有效的。 闲话少说ÿ…...

MyCat Docker 搭建与测试
mycat 是mysql分库分表的中间件,由java编写,本次进行mysql、mycat 的docker搭建,理解mycat的原理与特性。 一、mysql docker 搭建 这里启动两个实例: docker run -itd --name mysql1 -p 3307:3306 -e MYSQL_ROOT_PASSWORD123 m…...
车载通讯USB开发,增强车内娱乐体验
车载通讯开发中使用的 USB 协议常见于车内娱乐系统、车载设备和汽车诊断工具等应用。USB(Universal Serial Bus,通用串行总线)是一种常见的数字通信接口标准,用于连接计算机、外部设备及其他电子设备之间的数据传输和通信。 USB …...

js的一些小技巧
大厂面试题分享 面试题库 前后端面试题库 (面试必备) 推荐:★★★★★ 地址:前端面试题库 web前端面试题库 VS java后端面试题库大全 作用域 全局作用域局部作用域(函数里)也称函数作用域块级作用域 {…...

Springboot Mybatis 自定义顺序排序查询,指定某个字段
前言 与本文无关 "我进去了" ....... 正文 今天要讲些什么? 其实很简单,就是查询数据的时候,想根据自己指定的字段的自定义顺序,做排序查询数据。 本篇文章会讲到的几个点 : 1. 单纯sql 怎么实现 排序2. …...

期刊会议审稿意见
AAAI 修改意见 违背了研究方向的假设;虽然实验结果不错,但是没有明确地指向任何成功的方向,作者也没有充分地处理失败的案例——The results, though good are not clearly pointing to any direction of success, and the authors have no…...

Java类加载机制:从字节码到对象的奇妙之旅
目录 什么是类加载机制? 类加载顺序 类加载顺序图 双亲委派模型 双亲委派模型示意图 如何打破双亲委派模型? 要想学好java,首先得知道它是什么,怎么运行的,怎么加载的,运行的是个什么东西,…...

代码随想录第一天|二分法、双指针
代码随想录第一天 Leetcode 704 二分查找Leetcode 35 搜索插入位置Leetcode 34 在排序数组中查找元素的第一个和最后一个位置Leetcode 69 x 的平方根Leetcode 367 有效的完全平方数Leetcode 27 移除元素Leetcode 26 删除有序数组中的重复项Leetcode 283 移动零Leetcode 844 比较…...

Flink中KeyedStateStore实现--怎么做到一个Key对应一个State
背景 在Flink中有两种基本的状态:Keyed State和Operator State,Operator State很好理解,一个特定的Operator算子共享同一个state,这是实现层面很好做到的。 但是 Keyed State 是怎么实现的?一般来说,正常的…...

flex: 0 0 100%;
flex: 0 0 100%; flex: 0 0 100%; 是一个用于设置flex项的flex-grow、flex-shrink和flex-basis属性的缩写flex-grow:指定了flex项在剩余空间中的放大比例,默认为0,表示不放大。在这个例子中,设置为0表示不允许flex项在水平方向上…...

新手程序员必备:收藏这份Prompt指南,轻松驾驭大模型创造业务价值!
本文系统介绍了大模型Prompt的概念、撰写框架及核心原则,深入剖析了构建高质量Prompt的实操方法。从RTF、思考链到RISEN等五大框架,再到提升Prompt效果的策略,如明确指令、结构化输出、赋予模型思考时间等,帮助读者高效驾驭大模型…...

Jmeter接口测试项目实战
🍅 点击文末小卡片,免费获取软件测试全套资料,资料在手,涨薪更快 1、什么是jmeter?JMeter是100%完全由Java语言编写的,免费的开源软件,是非常优秀的性能测试和接口测试工具,支持主流…...

PyTorch 2.8镜像真实效果:量子计算电路→量子态演化视频模拟
PyTorch 2.8镜像真实效果:量子计算电路→量子态演化视频模拟 1. 量子计算模拟效果展示 量子计算作为前沿计算领域,其可视化一直是教学和研究的难点。我们使用PyTorch 2.8镜像实现了从量子电路到量子态演化的完整视频模拟流程,以下是关键效果…...

如何快速访问AO3镜像站:新手必看的5个实用技巧
如何快速访问AO3镜像站:新手必看的5个实用技巧 【免费下载链接】AO3-Mirror-Site 项目地址: https://gitcode.com/gh_mirrors/ao/AO3-Mirror-Site Archive of Our Own(AO3)是全球最大的同人创作平台,但部分地区访问受限。…...

深入RK3588 NPU架构:从NVDLA远亲到CNN加速器的设计取舍与性能真相
RK3588 NPU架构深度解构:CNN加速器的设计哲学与性能边界 当一块指甲盖大小的芯片宣称能提供6 TOPS的AI算力时,我们不禁要问:这数字背后隐藏着怎样的工程智慧与妥协?RK3588的NPU模块正引发这样的思考——它既非纯粹的学术创新&…...

基于Docker与CUDA的YOLOv5/v7高效部署实战指南
1. 环境准备:从零搭建CUDADocker开发环境 第一次在Docker里跑YOLOv5时,我盯着满屏的CUDA版本报错差点崩溃。后来才发现,环境配置就像搭积木,底层没摆正,上层再漂亮也会塌。下面分享我验证过的环境搭建方案,…...
)
用8086和蜂鸣器DIY音乐盒:手把手教你复刻童年旋律(附完整汇编代码)
用8086和蜂鸣器DIY音乐盒:手把手教你复刻童年旋律(附完整汇编代码) 记得小时候第一次听到电子贺卡发出《生日快乐》的单调旋律时,那种机械却又神奇的"音乐"让我盯着电路板研究了半天。现在想来,那些简单的方…...
来帮忙)
Linux内存不够用吧 Linux 交换内存(Swap)来帮忙
Linux内存不够用吧 Linux 交换内存(Swap)来帮忙 Linux 交换内存(Swap)完全指南:概念、配置与性能优化 我开发了一款内存管理工具,内存管理工具下载地址 1. 什么是交换内存(Swap)&a…...

网页资源提取工具:猫抓开源方案解决媒体获取难题
网页资源提取工具:猫抓开源方案解决媒体获取难题 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 在数字化学习与研究的过程中ÿ…...

Ubuntu下Minicom与Kermit串口工具对比:哪个更适合你的嵌入式开发?
Ubuntu下Minicom与Kermit串口工具深度评测:嵌入式开发者的终极选择指南 在嵌入式开发领域,串口通信如同开发者的"听诊器",是调试硬件、监控系统状态的核心工具。Ubuntu作为最受开发者欢迎的Linux发行版之一,其生态中Mi…...