【数据库原理与实践】知识点归纳(下)
第6章 规范化理论
一、关系模式设计中存在的问题
关系、关系模式、关系数据库、关系数据库的模式
关系模式看作三元组:R < U,F >,当且仅当U上的一个关系r满足F时,r称为关系模式R < U,F >的一个关系
第一范式(1NF):每个分量都是不可分开的数据项
数据依赖:一个关系内部属性与属性之间的一种约束关系,通过属性间值是否相等体现数据间的相互联系
数据依赖的类型:函数依赖FD、多值依赖MVD、其他
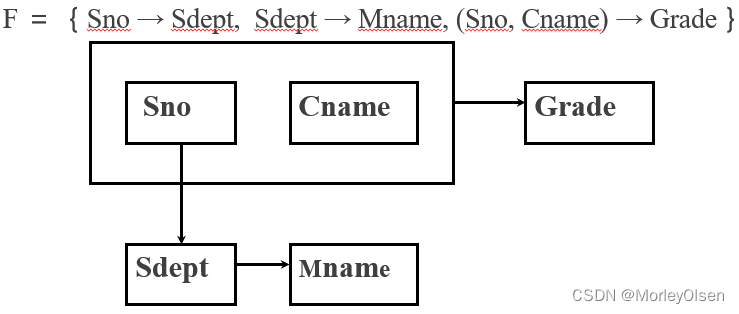
例:学校教务数据库
存在的问题:(1)数据冗余太大;(2)更新异常;(3)插入异常;(4)删除异常
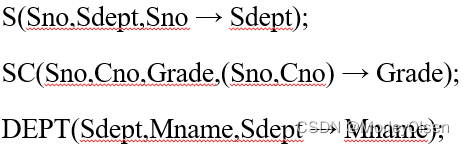
改进:把单一模式分成三个关系模式
二、函数依赖
1:函数依赖概念
(1)函数依赖(R的所有关系实例均满足约束条件)
- 设R(U)是一个属性集U上的关系模式,X和Y是U的子集。若对于R(U)的任意一个可能的关系r,r中不可能存在两个元组在X上的属性值相等,而在Y上的属性值不等,则称“X函数确定Y”或“Y函数依赖于X”,记作X→Y
- 若X→Y,并且Y→X, 则记为X←→Y
- 只能根据数据的语义确定一个函数依赖
- 若Y不函数依赖于X,则记为X不→Y
(2)平凡函数依赖与非平凡函数依赖
在关系模式R(U)中,对于U的子集X和Y,
若X→Y,但Y⊈![]() X,则X→Y是非平凡函数依赖
X,则X→Y是非平凡函数依赖
若X→Y,但Y⊆![]() X,则X→Y是平凡函数依赖
X,则X→Y是平凡函数依赖
若X→Y,则X为函数依赖的决定属性组,即决定因素
(3)完全函数依赖与部分函数依赖
在关系模式R(U)中,如果X→Y,并且对于X的任何一个真子集X′,都有

F:完全函数依赖;P:部分函数依赖
(4)传递函数依赖
在R(U)中,如果X→Y,(Y⊈![]() X),Y不→X, Y→Z, 则称Z对X传递函数依赖
X),Y不→X, Y→Z, 则称Z对X传递函数依赖
![]()
如果Y→X,即X←→Y,则Z直接依赖于X
2:码
设K为R<U,F>中的属性或属性组合,
若U完全函数依赖于K,则K称为R的候选码
若U部分函数依赖于K,则K称为R的超码
候选码是最小的超码,即候选码的任意一个真子集都不是候选码
若关系模式R有多个候选码,则选定其中一个作为主码
主属性:包含在任何一个候选码中的属性
非主属性:不包含在任何码中的属性
全码:整个属性组是码
外码(外部码):R中的属性X并非R的码,但X是另一个关系模式的码
主码与外码一起提供了表示关系间联系的手段
三、关系模式的分解
范式:符合某一种级别的关系模式的集合
范式的种类:1NF,2NF,3NF,BCNF,4NF,5NF
规范化:低一级范式的关系模式通过模式分解转换为若干个高一级范式的关系模式的集合的过程
(1)1NF,第一范式
定义:一个关系模式R的所有属性都是不可分的基本数据项
1NF是对关系模式的最起码要求,不满足1NF的数据库模式不是关系数据库
(2)2NF,第二范式
定义:关系模式R∈1NF,且每个非主属性都完全函数依赖于任何一个候选码
不属于2NF的关系模式产生的问题:插入异常、删除异常、修改复杂
——解决方法:投影分解
(3)3NF,第三范式
定义:关系模式R<U,F>中不存在码X、属性组Y、非主属性Z(Z⊈![]() Y),使得X→Y、Y→Z成立,Y不→X
Y),使得X→Y、Y→Z成立,Y不→X
3NF否定了传递依赖(非主属性对码具有)和部分依赖,判别时是没有属性对码传递依赖或部分依赖
·区分传递依赖和推导
性质:
- 如果R满足3NF,则R一定满足2NF
- 3NF只消除非主属性对候选码的传递依赖
(4)BCNF,BC范式
定义:关系模式R<U,F>∈1NF,X→Y且Y⊈![]() X时,X必含有码
X时,X必含有码
即:每一个决定属性集都包含候选码,判别时是没有其他决定因素
性质:
- 所有非主属性都完全函数依赖于每个候选码,所有主属性都完全函数依赖于每个不包含它的候选码,没有任何属性完全函数依赖于非码的任何一组属性(消除所有属性对候选码的传递依赖)
- BCNF实现了模式的彻底分解,达到了最高的规范化程度,消除了插入异常和删除异常
多值依赖:
设R(U)是一个属性集U上的一个关系模式, X、 Y和Z是U的子集,并且Z=U-X-Y,关系模式R(U)中多值依赖 X→→Y成立,当且仅当对R(U)的任一关系r,给定的一对(x,z)值,有一组Y的值,这组值仅仅决定于x值而与z值无关
特点:数据冗杂度大;增加操作复杂;删除操作复杂;修改操作复杂
等价的形式化定义:(z可对调)

平凡多值依赖:若X→→Y,而Z=φ,即Z为空,则称X→→Y为平凡的多值依赖;否则为非平凡多值依赖
多值依赖的性质:
- 对称性(完全二分图):若X→→Y,则X→→Z,其中Z=U-X-Y
- 传递性:即若X→→Y,Y→→Z, 则 X→→Z-Y
- 函数依赖是多值依赖的特殊情况:若X→Y,则 X→→Y
- 若X→→Y,X→→Z,则X→→YZ
- 若X→→Y,X→→Z,则X→→Y∩Z
- 若X→→Y,X→→Z,则X→→Y-Z,X→→Z -Y
多值依赖与函数依赖的区别:
多值依赖的有效性与属性集的范围有关。多值依赖的定义中不仅涉及属性组X和Y,而且涉及U中其余属性Z
若函数依赖X→Y在R (U)上成立,则对于任何Y'⊆![]() Y均有X→Y’ 成立。多值依赖X→→Y若在R(U)上成立,不能断言对于任何Y'⊆
Y均有X→Y’ 成立。多值依赖X→→Y若在R(U)上成立,不能断言对于任何Y'⊆![]() Y有X→→Y’成立
Y有X→→Y’成立
(5)4NF,第四范式
定义:关系模式R<U,F>∈1NF,对于R的每个非平凡多值依赖X→→Y(Y⊈![]() X),X都含有码
X),X都含有码
性质:
- 限制关系模式的属性之间不允许有非平凡且非函数依赖的多值依赖,允许的非平凡多值依赖是函数依赖
- 如果一个关系模式是4NF,则必为BCNF
候选码的确定:

小结:
- 第一范式:属性不可再分
- 第二范式:没有非主属性对候选码的部分函数依赖
- 第三范式:没有非主属性对候选码的部分函数依赖、传递依赖
- BC范式:没有非主以及主属性对候选码的部分函数依赖、传递依赖(判断函数依赖的箭头左边都是含有码的)
- 第四范式:依据多值依赖判断
四、关系模式的分解
1:数据依赖的公理系统
逻辑蕴含:
F逻辑蕴含X→Y:满足一组函数依赖集 F 的关系模式R <U,F>,其任何一个关系r,函数依赖X→Y 都成立
Armstrong公理系统:
用途:求给定关系模式的码;从一组函数依赖求得蕴含的函数依赖
推理规则:
- 自反律:若Y⊆
 X⊆
X⊆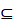 U,则X→Y为F所蕴含
U,则X→Y为F所蕴含 - 增广率:若X→Y为F所蕴含,且ZÍU,则XZ→YZ为F所蕴含
- 传递率:若X→Y及Y→Z为F所蕴含,则X→Z为F所蕴含
进一步推理规则:
- 合并规则:由X→Y,X→Z,有X→YZ
- 伪传递规则:由X→Y,WY→Z,有XW→Z
- 分解规则:由X→Y 及 Z⊆
 Y,有X→Z
Y,有X→Z
引理6.1:X→A1A2…Ak 成立的充分必要条件是X→Ai成立(i=l,2,…,k)
即X决定了每个Ai 等价于 X决定所有Ai的组合
Armstrong公理系统具有有效性和完备性
闭包:
F的闭包F+:在关系模式R<U,F>中,为F所逻辑蕴含的函数依赖的全体
属性集X关于函数依赖集F的闭包XF+:设F为属性集U上的一组函数依赖,X⊆![]() U,XF+ ={ A|X→A能由F根据Armstrong公理导出}
U,XF+ ={ A|X→A能由F根据Armstrong公理导出}
从X出发,所有能够根据函数依赖而推出的那些属性的集合
引理6.2:设F为属性集U上的一组函数依赖,X,Y⊆![]() U,X→Y能由F根据Armstrong公理导出的充分必要条件是Y⊆
U,X→Y能由F根据Armstrong公理导出的充分必要条件是Y⊆![]() XF+
XF+
求闭包的算法:

函数依赖集等价:
F覆盖G(F与G等价):G+=F+
引理6.3:F+ = G+ 的充分必要条件是F⊆![]() G+,和G⊆
G+,和G⊆![]() F+
F+
最小依赖集:
Fm最小依赖集不唯一,与对各函数依赖FDi及X→A中X各属性的处置顺序有关

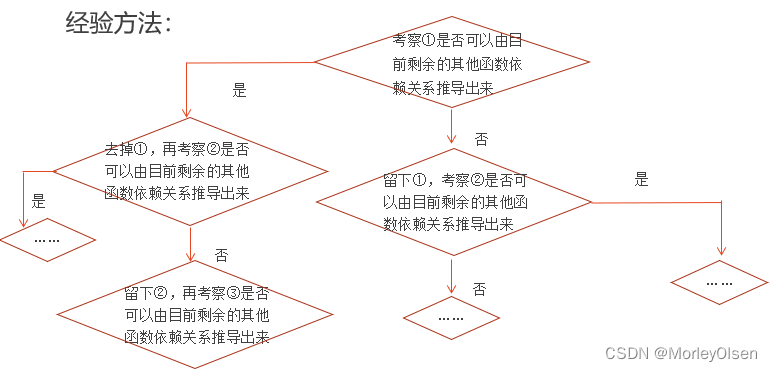
极小化过程:
- 函数依赖右边必须为单一属性
- 检查是否有些函数依赖可以由现有的其他的函数依赖推到而得,例如传递
检查函数依赖左边的是否由冗余属性。即去掉左边的某个属性,能否也推出A(有可能借助传递)
2:模式的分解
低一级的关系模式分解为若干个高一级的关系模式的方法不唯一
三种模式分解的等价定义:
(1)分解具有无损连接性
(2)分解要保持函数依赖
(3)分解既要保持函数依赖,又要具有无损连接性
F 在属性Ui上的投影:函数依赖集合{X→Y | X→Y∈F +∧XY⊆![]() Ui} 的一个覆盖 Fi
Ui} 的一个覆盖 Fi

无损连接性:R与R1、R2、…、Rn自然连接的结果相等
两个相互独立的标准:无损连接性——保证不丢失信息;保持函数依赖——减轻或解决各种异常情况
分解算法:
(1)判别一个分解的无损连接性
例题:
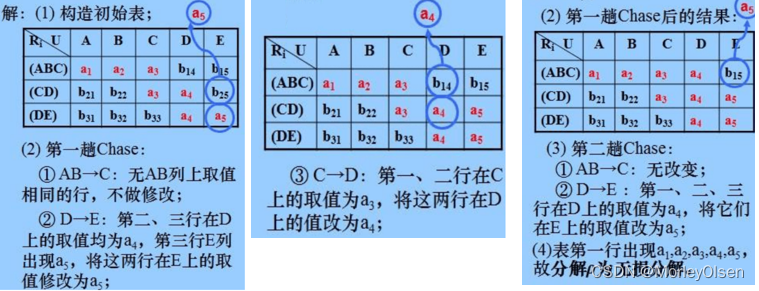
(2)转换为3NF的保持函数依赖的分解(合成法)
函数依赖左边相同的分一组,分组后若设计属性集有被包含的关系,则删除子集

(3)转换为3NF既有无损连接性又保持函数依赖的分解
若要求分解保持函数依赖,那么模式分离总可以达到3NF,但不一定能BCNF
由码、与码相关的所有函数依赖关系所构成的模式中,属性集已包含码本身
(4)转换为BCNF的无损连接分解(分解法)
(5)达到4NF的具有无损连接性的分解
无损连接分解的快捷判别方法:

前提:分解后的关系模式仅2个
关于数据依赖的公理系统:
8条公理:

4条推理规则:
- 合并规则:X→→Y,X→→Z,则X→→YZ
- 伪传递规则:X→→Y,WY→Z,则WX→→Z-WY
- 混合伪传递规则:X→→Y,XY→Z,则X→Z-Y
- 分解规则:X→→Y,X→Z,则X→→Y∩Z,X→→Y-Z,X→→Z-Y
五、小结
- 关系数据库中,对关系模式的基本要求是满足第一范式
- 规范化的实质:概念的单一化
关系模式规范化的基本步骤
- 不能说规范化程度越高的关系模式就越好。必须对现实世界的实际情况和用户应用需求作进一步分析,确定一个合适的、能够反映现实世界的模式
-
关系模式规范化的基本思想: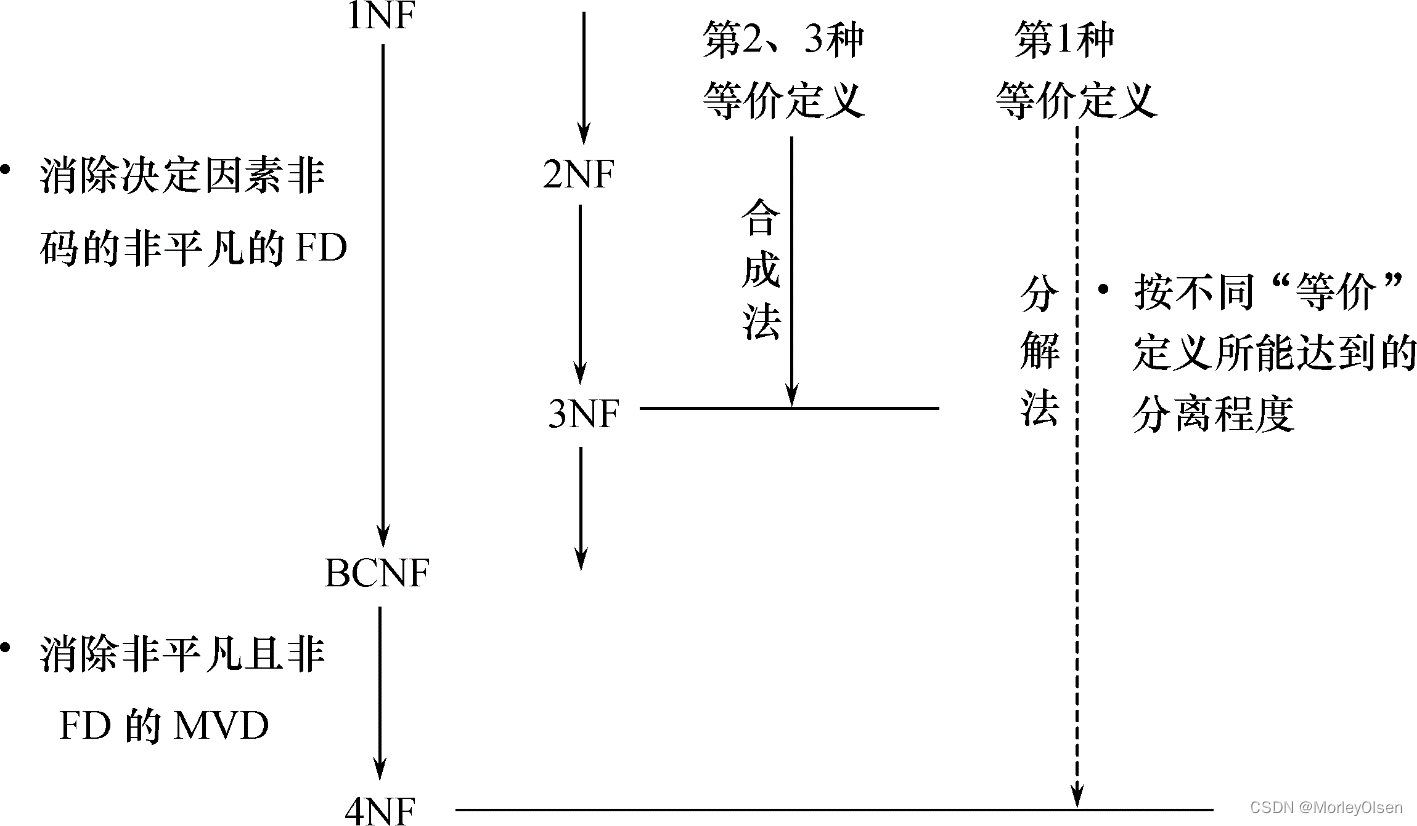
- 若要求分解具有无损连接性,那么模式分解一定能够达到4NF
- 若要求分解保持函数依赖,那么模式分解一定能够达到3NF,但不一定能够达到BCNF
- 若要求分解既具有无损连接性,又保持函数依赖,则模式分解一定能够达到3NF,但不一定能够达到BCNF
第7章 数据库设计
一、数据库系统设计概述
1:设计目标和特点
目标:
- 性能良好
- 满足不同用户使用要求
- 能被选定的DBMS所接受
- 完整反映现实世界中信息及信息之间的联系
- 有效进行数据存储,方便执行各种数据检索和处理操作
- 有利于数据维护和数据控制
特点:
- 三分技术,七分管理,十二分基础数据
- 管理:数据库建设项目管理,企业/应用部门的业务管理
- 基础数据:收集、入库,更新新的数据
- 结构(数据)设计和行为(处理)设计相结合:将数据库结构设计和数据处理设计密切结合
2:设计内容
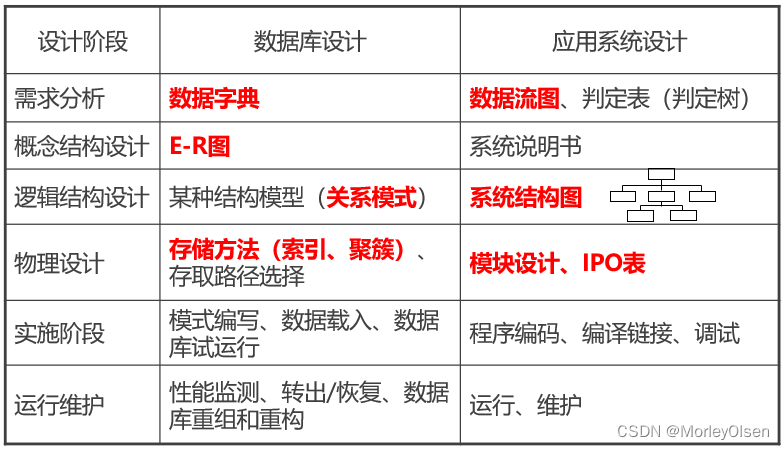
数据库系统设计:
- 结构特性设计:ER图、概念结构模型、逻辑结构模型
- 行为特性设计:数据流程图和数据字典、数据操作要求
- 物理模式设计:存储模式、存取方法
注意问题:
- 考虑计算机硬件、软件(DBMS和主语言系统的特点)、干件(用户技术和管理水平)
- 结构特性设计和行为特性设计结合(自上而下、逐步逼近)
3:设计方法
- 手工试凑法:过程迭代、逐步求精
- 新奥尔良方法:需求分析、概念设计、逻辑设计和物理设计
- 6阶段方法:需求分析、概念结构设计、逻辑结构设计、物理结构设计、数据库实施、数据库运行和维护
4:基本步骤
数据库设计与应用系统设计的对照:
二、系统需求分析
1:需求分析任务方法
- 系统需求的调查内容:数据库中的信息内容;数据处理内容;数据安全性和完整性要求
- 系统需求的调查步骤:了解现实世界的组织机构情况;了解相关部门的业务活动情况;确定新系统的边界
- 系统需求的调查方法:信息、处理、安全性、完整性要求
- 系统需求的分析方法:结构化分析方法(从上至下,逐层分解)
2:需求分析描述方式
(1)数据流图DFD
基本成分:外部实体、加工、数据存储、数据流
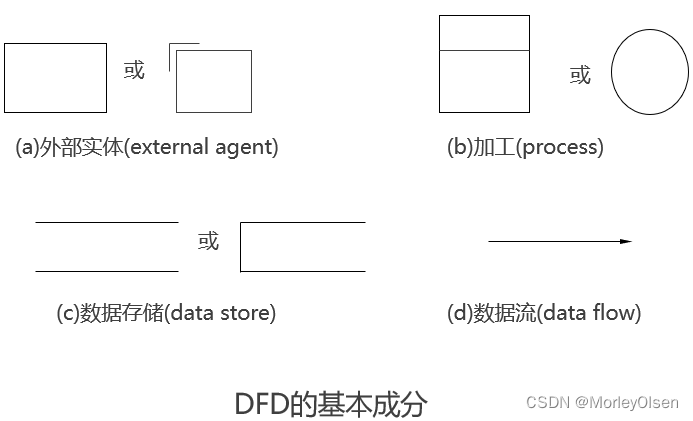
顶层数据流图:给出系统的外部用户
0层数据流图:给出系统针对的几类用户的几大主要功能
(2)数据字典及其表示
- 数据项:不可再分的数据单位,数据项 = {数据项名,数据项含义说明,别名,类型(定义数据完整性约束条件,是数据完整性检验依据),长度,取值范围,与其他数据项的逻辑关系}
- 数据结构:数据结构 = {数据结构名,含义说明,组成,{数据项或数据结构}}
- 数据流:数据结构在系统内传输的路径,数据流 = {数据流名,说明,流出过程,流入过程,组成:{数据结构},平均流量,高峰期流量}
- 数据存储:数据存储 = {数据结构名,说明,编号,输入的数据流,输出的数据流,组成:{数据结构}数据量,存取频度,存取方式}
- 处理过程:处理过程 = {处理过程名,说明,输入:{数据流},输出:{数据流},处理:{简要说明}}
3:需求分析举例分析
注意事项:须手机将来应用所涉及的数据,须有用户参与
三、概念结构设计
1:概念设计的特点和方法
用户需求—【抽象】—信息结构—【结果】—概念模型
(1)概念结构的特点:现实世界的真实模型、易理解、易更改、易于向数据模型转换
(2)概念结构的设计方法:自顶向下;自底向上;逐步扩张;混合策略
2:数据抽象和局部视图设计
(1)数据抽象方法:分类(定义某一类概念作为现实世界中一组对象的类型,如ER模型中的实体型);聚集(定义某一类型的组成部分,如ER模型中的实体属性);概括(定义类型之间的一种子集联系,如ER模型中的抽象机制的扩充)
(2)设计分ER图步骤:确定范围(2条原则)——确定实体、属性及其标识(数据对象的分类、确认实体与属性、对象的命名、确定实体的标识)——定义实体间的联系——给实体及联系加上描述属性
区分实体与属性的一般原则:实体一般需要描述信息而属性不需要;属性不能与其他实体具有联系
识别联系的类型:一对一;一对多;多对多
联系的识别与定义:存在性联系;功能性联系;事件联系
3:视图集成
任务:揭示矛盾、识别共性、消除冗余、解决冲突
实质:统一与归并
方法:多个分E-R图一次集成;逐步集成
集成的步骤:合并(关键是消除冲突)——修改和重构(分析方法 + 规范化理论)——验证并提交用户审核
冲突的类型:属性冲突;命名冲突;结构冲突
优化全局E-R模式的原则:两个有联系的实体型合并;冗余属性的消除;冗余联系的消除
4:概念数据模型实例研究
四、逻辑结构设计
1:逻辑设计的任务
把概念模型结构转换成某个具体的DBMS所支持的数据模型,ERD -> R(U,F)
2:模型转换规则
- 实体集的转换规则
- 实体集间联系的转换规则(1:1联系,1:n联系,m:n联系)
- 关系合并规则:合并具有相同码的关系模式
3:视图集成
4:用户子模式设计
- 更符合用户习惯的别名
- 不同级别用户定义不同的外模式
- 简化用户对系统的使用
5:逻辑数据模型实例研究
五、物理设计
1:物理设计的内容和方法
数据库的物理结构:数据库在物理设备上的存储结构和存取方法,依赖于具体的计算机系统
数据库的物理结构设计(物理设计):为一个给定数据库的逻辑结构选取一个最合适应用环境的存储结构和存取方法的过程
物理设计的内容:为关系模式选择存取方法;确定数据库存储结构;对物理结构进行评价(时间和效率)
2:关系模式存取方法的选择
选择数据存取方法的准备:清楚数据库查询事务的信息;清楚数据库更新事务的信息;清楚每个事务在各关系上运行的频率和性能要求
关系模式存取方法的选择:索引方法;聚簇方法;HASH方法
(1)索引方法的选择
索引类似一个两列组成的表
索引设计:确定组合索引、唯一索引等;一个关系可同时建立多个索引
创建索引的原则:经常在查询条件中出现;以聚集函数出现;在连接条件中出现
特定情况:主键属性列和外键属性列建立索引有助于唯一性和完整性检查,加快连接查询的速度
(2)聚簇方法的选择
聚簇码:建立聚簇的属性或属性组
一个数据库可以建立多个聚簇,但一个关系上只能加入一个聚簇
建立聚簇的原则:经常访问;值重复率高;很少增加或删除元组,属性列的值很少修改
3:确定数据库的存储结构
(1)确定数据的存放位置
磁盘分区设计的本质:确定数据库数据的存放位置,提高系统性能
磁盘分区设计的一般原则:减少访问冲突,提高I/O并行性;分散热点数据,均衡I/O负担;保证关键数据快速访问,缓解系统瓶颈
(2)确定系统配置
4:物理结构的评价
评价物理数据库的方法完全依赖于所选用的DBMS
定量估算各种方案的存储空间、存取时间和维护代价
六、实施和维护
1:数据库的建立和调整
数据库的实施:根据数据库的逻辑结构设计和物理结构设计的结果,在具体RDBMS支持的计算机系统上建立实际的数据库模式、装入数据、并进行测试和试运行的过程
数据库实施阶段的工作:数据的载入,应用程序的编码和调试;试运行并调试
- 数据库的建立:数据库模式的建立,数据加载
- 数据库的调整
- 应用程序编制与调试
2:数据库系统试运行
- 试运行阶段的主要工作:功能测试,性能测试
- 注意的问题:数据库的试运行操作应分步进行;数据库的实施和调试不可能一次完成
3:数据库系统运行和维护
- 数据库的转储和恢复
- 数据库的安全性和完整性控制
- 数据库性能的监督、分析和改造
- 数据库的重组织与重构造
七、小结
数据库的设计过程:需求分析——概念结构设计——逻辑结构设计——物理设计——实施——运行维护
第8章 数据库保护
一、数据库安全性
数据库安全性:防止非法用户的恶意破坏
1:数据库安全性定义
安全性控制的一般方法:
- 对有意的非法活动用加密存取数据的方法控制
- 对有意的非法操作用用户身份验证、限制操作权来控制
- 对无意的损坏可采用提高系统的可靠性和数据备份等方法来控制
2:可信计算机系统评测标准
国际:TCSEC桔皮书,TDI紫皮书,CC(ISO/IEC 15408-1999)
国内:GB17859(参考TCSEC),GB/T18336(等同于CC)
TDI/TCSEC的基本内容:安全策略(自主存取控制,客体重用,标记,强制存取控制)、责任(标识与鉴别,审计)、保证(操作保证,生命周期保证)、文档(安全特性用户指南,可信设施手册,测试文档,设计文档)
TDI/TCSEC的安全级别划分:4组DCBA,7等级,按系统可靠性或可信程度增高,偏序向下兼容
| 安全级别 | 定义 |
| A1 | 验证设计 |
| B3 | 安全域 |
| B2 | 结构化保护 |
| B1 | 标记安全保护 |
| C2 | 受控的存取保护 |
| C1 | 自主安全保护 |
| D | 最小保护 |
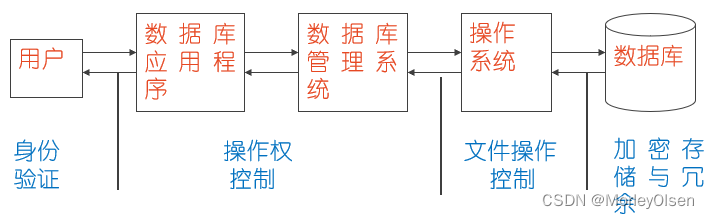
3:数据库安全控制模型
关键部分:身份鉴定;操作权;文件访问权限;加密形式
4:数据库安全控制方法
- 用户标识和鉴定:用户标识符(用户名+口令);口令有静态、动态、生物特征、智能卡;验证码(复杂化)
- 用户存取权限控制:授权表包含用户标识、数据对象、操作类型;用户类型有系统管理员、对象拥有者、普通用户;授权的粒度(范围大小)包括关系、记录、属性,粒度越细,授权子系统越灵活,安全性越完善;两类实现存取控制的方法(自主存取控制DAC——grant和revoke语句,强制存取控制MAC)
- 定义视图
- 数据加密:明文+密文;加密方法为替换方法、转换方法;加密方式为存储加密、传输加密
- 审计:监视措施,存放在审计日志中
- SQL注入:通过把SQL命令插入到Web表单递交或输入域名或页面请求的查询字符串,最终达到欺骗服务器执行恶意SQL命令
二、完整性控制
数据库完整性:防止合法用户的善意破坏
1:完整性的定义
保护数据库中数据的正确性、有效性、相容性
2:完整性的规则和条件
完整性的规则:触发条件;约束条件;违约响应
完整性规则的分类(按执行时间):立即执行约束(某一条语句执行完成后);延迟执行约束(整个事务执行结束后)
完整性规则的表示:五元组(D,O,A,C,P)
——DATA:约束作用的数据对象(关系、元组、列)
——OPERATION:触发完整性检查的数据库操作(立即、延迟)
——ASSERTION:数据对象必须满足的语义约束
——CONDITION:选择A作用的数据对象值的谓词
——PROCEDURE:违反完整性规则时触发执行的操作过程
服务器端实现数据完整性的方法:
- 定义表的时候声明数据完整性(DDL)
- 编写触发器实现数据完整性
主要优点:违约由系统处理,而不由用户处理
完整性约束条件是完整性控制机制的核心
关系模型的完整性内容:实体完整性(PRIMARY KEY)、参照完整性(FOREIGN KEY & REFENCE)、用户定义完整性(NOT NULL & UNIQUE & CHECK & ENUM)
——违反实体完整性 / 用户定义完整性:拒绝执行
——违反参照完整性:接受操作并执行附加操作,保证数据库的状态正确
完整性约束条件的作用对象:列级约束(数据类型、数据格式、取值范围)、元组约束(字段间的联系)、关系约束(元组间、关系间的联系)
完整性约束条件的分类:(约束条件使用对象)值的约束 & 结构的约束;(约束对象的状态)静态约束 & 动态约束
完整性约束的命名子句:CONSTRAIT <完整性约束条件名> <完整性约束条件>
3:完整性的实施
- 声明式数据完整性:将数据所需符合的条件融入到对象的定义中,特点是使用约束、默认值、规则
- 程序化数据完整性:条件及其实施通过所编写的程序代码完成,特点是使用存储过程、触发器
实时数据完整性的方法:约束,默认值,规则,存储过程,触发器
触发器类型:行级触发器(each row),语句级触发器(each statement)

4:规则
规则:数据库对存储在表中的列或用户自定义数据类型中的值的规定和限制
规则是单独存储的独立的数据库对象
规则和约束可同时使用,表的列可有1个规则和多个check约束
创建规则:CREATE RULE rule_name AS @ condition_expression
查看规则:sp_helptext[@objname = ] ‘name’
规则的绑定与松绑:(绑定)sp_bindrule[@rulename =]‘rule’,[@objname =]‘object_name’ [,‘futureonly’]
(解绑)sp_unbindrule [@objname =]‘object_name’ [,‘futureonly’]
删除规则:DROP RULE {rule_name} [,…n]
——在删除一个规则前必须先将与其绑定的对象解除绑定
5:默认
默认:向用户输入记录时没有指定具体数据的列中自动插入的数据
创建默认:CREATE DEFAULT default_name AS constant_expression
查看和修改默认:用sp_helptext
默认的绑定与松绑:(绑定)sp_bindefault [@defname =] 'default', [@objname =] 'object_name' [, 'futureonly']
(解绑)sp_unbindefault [@objname =] 'object_name' [,'futureonly']
删除默认: DROP DEFAULT {default_name} [,...n]
三、并发控制
1:并发和并发控制
数据资源共享——并行存取数据
并发控制:保持数据库中数据的一致性,在任何一个时刻数据库都将以相同的形式给用户提供数据
2:事务和事务特征
(1)事务
事务:并发控制的基本单位,用户定义的数据操作系列
一个事务内的所有语句被作为一个整体,要么全部执行,要么全部不执行
自动提交 autocommit=1,每条SQL语句会默认被封装成一个事务并自动提交
设置自动提交选项:set autoocmmit = 0或1
查询自动提交状态:select @@autocommit 或 show session variables like ‘autocommit’
显示处理事务的语句:
——START TRANSACTION:事务开始
——COMMIT:提交,事务正常结束,所有操作永久保存
——ROLLBACK:事务异常结束,事务中对数据库的所有已完成更新操作全部撤销,再回滚到事务开始时的状态
(2)事务的ACID特征
事务的4个特征(非平级关系):原子性(事务不做或全做);一致性(操作不做或全做);隔离性(并发控制保证事务间的隔离性);持久性(提交后数据持久)
(3)事务状态
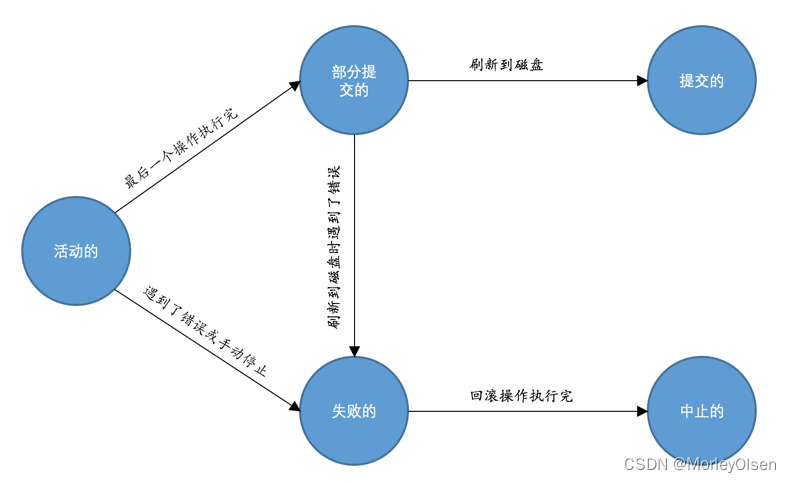
事务的5个状态:活动的;部分提交的;失败的;中止的;提交的
3:并发操作的异常
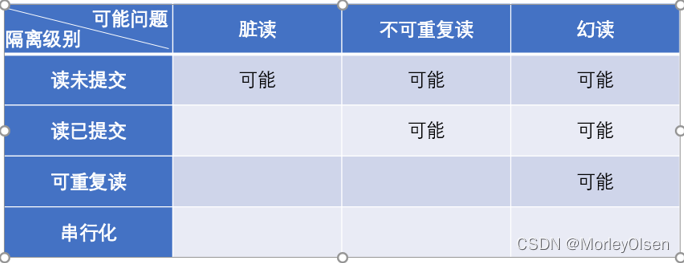
数据库并发操作导致的4种数据库不一致性:丢失修改;脏读;不可重读;幻影读
——丢失修改:不加锁,写写场景(提交)
——脏读:不加锁,读写场景(没提交)
——不可重读:不加锁,读写场景(提交)
——幻读:不加锁,读写场景(提交)
——主要原因:并发操作破坏了事务的隔离性
4:并发控制的措施
并发控制的主要技术:封锁控制LBCC;多版本控制MVCC
加锁:事务T在对某个数据操作之前,先向系统发出请求,对其加锁。加锁后事务T对其要操作的数据具有了一定的控制权,在事务T释放它的锁之前,其他事务不能操作这些数据
加锁的3个环节:申请锁——获得锁——释放锁
事务和锁的关系:锁是用于解决隔离性的一种机制
(1)锁的类型
基本的封锁类型:排它锁(写锁,X锁);共享锁(读锁,S锁)
——排他锁原理:禁止并发操作
事务T对数据对象A加了X锁,则允许T读取和修改A,但不允许其它事务再对A加任何类型的锁和进行任何操作(即申请不批准,进入等待)
——共享锁原理:允许其他用户对同一数据对象进行查询,但不能对该数据对象进行修改
事务T对数据对象A加了S锁,则事务T可以读A,但不能修改A,其它事务只能再对A加S锁(即申请便获得),而不能加X锁,直到T释放了A上的S锁
并发阻塞:多个事务都需要对某一资源进行锁定;被阻塞的请求会一直等待,直到原来的事务释放相关的锁
锁的相容矩阵:Y相容(锁的申请可以立即获得),N不相容(申请被拒绝,进入等待阶段)
(2)封锁协议
并发操作带来的数据不一致性,可以通过三级封锁协议解决
一级封锁协议:事务T在修改数据对象之前必须对其加X锁,直到事务结束(提交或回滚)时才释放锁;只防止丢失修改
二级封锁协议:在一级封锁协议的基础上,另外加上事务T在读取数据R之前必须先对其加S锁,读完后释放S锁;防止丢失修改、脏读
三级封锁协议:在一级封锁协议的基础上,另外加上事务T在读取数据R之前必须先对其加S锁,读完后并不释放S锁,而直到事务T结束才释放;防止丢失修改、脏读、重读
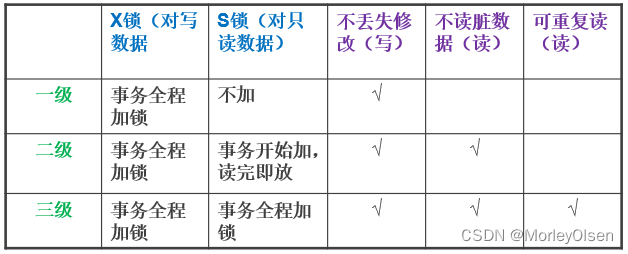
3个协议的主要区别:什么操作需要申请封锁,何时释放锁
(3)活锁和死锁
活锁特征:某个或几个事务永远等待,整体应用良好
避免活锁的方法:先来先服务
死锁特征:事务都在等待,整体应用阻塞
预防死锁的方法:一次封锁法;顺序封锁法
——一次封锁法:每个事务一次将所有要使用的数据全部依次加锁,并要求加锁成功,只要一个加锁不成功,表示本次加锁失败,则应该立即释放所有已加锁成功的数据对象,然后重新开始从头加锁;缺点是降低了系统的并发度
——顺序封锁法:预先对所有可加锁的数据对象规定一个加锁顺序,每个事务都需要按此顺序加锁,在释放时,按逆序进行;缺点是很难事先确定封锁对象和封锁顺序
一般允许发生死锁,在死锁发生后可以自动诊断并解除死锁——选择一个处理死锁代价最小的事务,将其撤销
(4)可串行化调度和两段锁协议
计算机系统对并发事务中并发操作的调度是随机的,不同的调度可能会产生不同的结果
可串行化调度:多个事务的并发执行是正确的,当且仅当其结果与按某一次序串行地执行它们时的结果相同
可串行性是并发事务正确性的准则,事务遵守两段锁协议是可串行化调度的充分不必要条件
两段锁协议(并发调度可串行性的封锁协议):所有事务必须分为两个阶段对数据项加锁和解锁;在对任何数据进行读、写操作之前,首先要申请并获得对该数据的封锁;在释放一个封锁之后,事务不再申请和获得任何其他封锁
——扩展阶段:获得封锁 ——收缩阶段:释放锁
(5)封锁粒度和多粒度封锁
封锁粒度:封锁对象的大小;封锁对象可是逻辑单元或物理单元
封锁粒度越小,并发度较高,系统开销就越大
多粒度封锁MGL:在一个系统中同时支持多种封锁粒度供不同的事务选择的封锁方法
多粒度树:根结点是整个数据库,表示最大的数据粒度;叶结点表示最小的数据粒度
多粒度封锁种一个数据对象的2种方式封锁(封锁效果一致):显式封锁;隐式封锁
——显式封锁:应事务的要求直接加到数据对象上的封锁
——隐式封锁:该数据对象没有独立加锁,是由于其上级结点加锁而使该数据对象加上锁
意向锁:如果对一个结点加意向锁,则说明该结点的下层结点正在被加行锁或表锁,可以让其他事物快速知悉此表状态
3种常用意向锁:意向共享锁IS,意向排它锁IX,共享意向排它锁SIX
——IS:后裔结点拟(意向)加S锁
——IX:后裔结点拟(意向)加X锁
——SIX:对当前数据对象(结点)加S锁,再加IX锁,即SIX = S + IX
锁的强度:对其他锁的排斥程度;一个事务在申请封锁时以强锁代替弱锁是安全的
锁的强度的偏序关系:X——SIX——S、IX——IS
申请封锁时应该按自上而下的次序进行;释放封锁时则应该按自下而上的次序进行
(6)事务隔离级别
隔离级别类型:读未提交RU(最低级别,只保证持久性);读提交RC(语句级别);可重复读RR(事务级别);串行化serializable(最高级别,完全串行化执行,性能低)
事务隔离级别与锁的关系:
——RU,读操作不需要加共享锁
——RC,读操作需要加共享锁,在语句执行完后释放共享锁
——RR,读操作需要加共享锁,在事务执行完后释放共享锁
——serializable,锁定整个范围的键,一直持有锁直到事务完成
事务隔离级别对于并发异常的控制:
MySQL的InnoDB引擎如何解决幻读问题:
- RR + MVCC,快照读,乐观锁思想
- RR + Next key-Lock,当前读,悲观锁思想
丢失更新的2个分类:回滚丢失;覆盖丢失
解决丢失更新的方法:加锁
加锁的机制:悲观锁;乐观锁
——悲观锁:假定问题高概率,一开始就锁住
添加共享锁:select * from account lock in share mode
添加排他锁:select * from account for update
——乐观锁:假定问题小概率,最后一步做更新时再锁住
在表中增加timestamp类型字段,在执行插入或更新时记录最新时间到该字段上;在修改数据时检查【时间戳】类型的字段是否改变判断当前的更新基于的查询是否已经过时
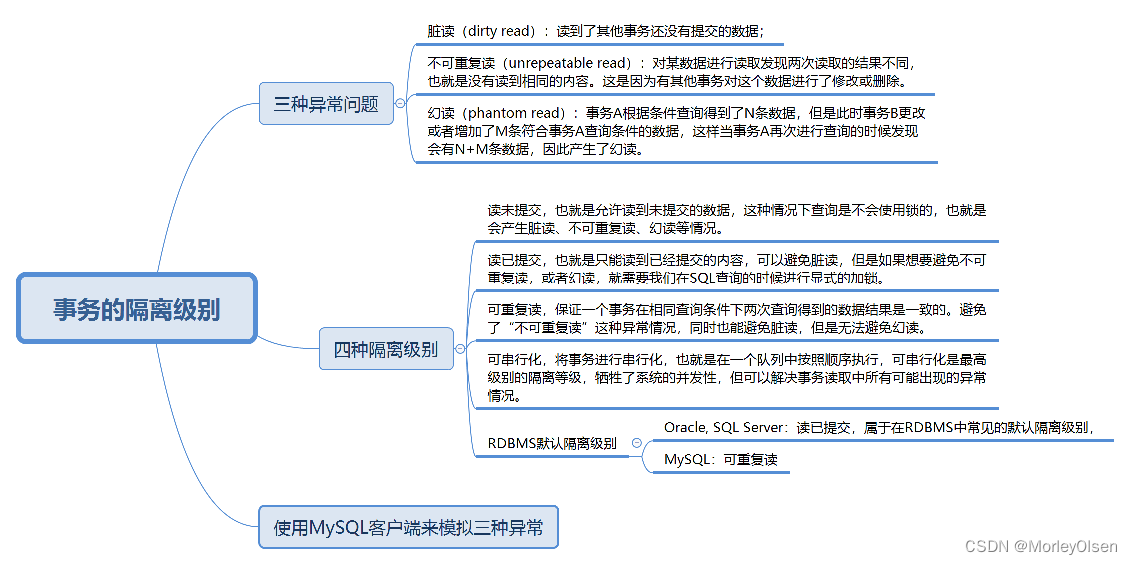
查询MySQL的隔离级别:
- SELECT @@global.transaction_isolation; --查询全局事务隔离级别
- SELECT @@session.transaction_isolation; --查询会话事务隔离级别
- SELECT @@transaction_isolation; --查询事务隔离级别,同会话级别
设置MySQL的隔离级别:
- SET [session|global] transaction isolation level read uncommitted
- SET [session|global.]transaction_isolation = 'read-uncommitted'
(7)MySQL并发控制
读写锁:读锁——共享锁;写锁——排它锁
锁粒度
表锁和行锁:表锁——开销小,MyISAM引擎;行锁——开销大,最大程度支持并发处理,InnoDB引擎
MyISAM引擎表锁控制:隐式(自动给表加读锁);显式(命令加锁);在自动加锁的情况下,一次获得SQL语句所需要的全部锁
InnoDB引擎行锁控制:锁索引(主键索引和非主键索引);临键锁算法实现,防止幻读,根据索引划分为左开右闭的区间
加锁规则:唯一索引列;普通索引列;普通列(上述三方面细分为等值查询和范围查询)
规则1:加锁的基本单位是Next Key-Lock,按临界锁加锁,左开右闭的区间
规则2:查找过程种访问到的数据都会加锁
优化1:唯一索引上的等值查询,命中时临界锁退化为记录锁;未命中时,退化为间隙锁
优化2:普通索引上的等值查询,命中时临界锁额外加间隙锁;为命中时,退化为间隙锁

优化3:范围查询会访问到不满足条件的第一个值为止
记录锁防止别的事务修改或删除,间隙锁防止别的事务新增,记录锁和间隙锁结合而成的临界锁共同解决RR级别在写数据时的幻读问题
并发控制中读操作的2个分类:当前读;快照读
——LBCC解决当前读的幻读,MVCC解决快照读(普通读)的幻读
——当前读:读取最新快照版本,基于临界锁
——快照读:读取记录的可见版本,可能是历史版本,不用加锁,基于MVCC和undo log。前提是隔离界别不是串行级别,否则会退化为当前读
InnoDB行锁的2个分类:
——隐式加锁(乐观锁):增删改语句自动加排它锁(X),查语句采用一致性非锁定读模式,实现不加锁的MVCC控制
——显式加锁(悲观锁):采取一致性锁定读模式,共享锁【LOCK IN SHARE MODE】,排它锁【FOR UPDATE】
MVCC:多版本并发控制,为事务分配单向增长的时间戳,为每个修改保存一个版本,解决读写冲突的无锁并发控制,实现一致性不加锁读,开销比行锁更低
在MySQL的InnoDB引擎,是通过给每行记录后面保存三个隐藏的列来实现的。一是单调递增的隐含ID,二是保存行的创建时间DB_TRX_ID,三是保存了行的过期时间(或删除时间)DB_ROLL_PT
每开启一个事务,系统版本号都会递增
多粒度锁:意向表锁 + 行锁
意向锁会阻塞表级的S锁和X锁,不会阻塞行锁和其他意向锁
MySQL事务日志:undo日志(逻辑日志);redo日志(物理日志)
——undo log的作用:保证数据的原子性和一致性,记录事务发生之前的一个版本,用于回滚;通过mvcc+undo log实现innodb事务可重复读和读取已提交隔离级别
——redo log的组成:重做日志缓冲(内存,易失);重做日志文件(硬盘,持久)
——binlog:二进制文件,记录追加式的SQL语句,用于主从同步、时间点的数据还原,server层面
——WAL技术:先写log,后刷磁盘。因为日志顺序写入,磁盘随机写入
——总结:Undo日志是对原始数据的备份,逻辑日志,记录反向语句;用来回滚数据的用于保障未提交事务的原子性。Redo日志是对原始数据的修改,物理日志,记录新值;用来恢复数据的用于保障已提交事务的持久性。
四、数据库恢复
1:数据库恢复概述
故障不可避免,影响分轻(运行事务非正常中断)、重(破坏数据库)
恢复技术是衡量系统优劣的重要指标
数据库管理系统对故障的对策:错误状态->一致状态;保证事务ACID;DBMS提供恢复子系统
2:故障分类
3个故障类别:事务故障;系统故障;介质故障
事务持久化策略:刷盘保存来保证持久化;uncommitted事务的持久化采用steal/no-steal策略;committed事务的持久化采用force/no-force策略;需要记录redo log和undo log
事务故障:某个事务在运行过程中因为某种原因为运行至正常终止点
事务故障的恢复:steal策略;预期故障执行回滚,非预期故障撤销事务;本质是撤销事务undo
系统故障:整个系统突然被破坏,所有正在运行的事务都非正常中止,内存中缓冲区信息均丢失,外存中数据不受影响
系统故障的恢复:steal策略;no-force策略
介质故障:硬件故障,外存数据丢失
介质故障的恢复:装入故障前的数据副本
3:数据库恢复
定义:系统必须具有检测故障并把数据库从错误状态中恢复到某一正确状态的功能
基本原理:利用存储在系统其他地方的冗余数据来修复
恢复系统的功能:生成冗余数据,利用冗余重建
数据库恢复的技术:数据转储;日志文件
4:数据库转储和日志文件
数据库转储:
- 指定备份策略时,考虑备份内容和备份频率
- 转储状态分为静态转储(无运行事务)和动态转储(与事务并发执行)
- 转储方式分为海量转储和增量转储
- 数据转储形式有4类:动态海量、动态增量、静态海量、静态增量
日志文件:
- 记录事务对数据库的更新操作的文件
- 格式:以记录为单位;以数据块为单位
- 登记内容:各个事务的开始标记、结束标记、所有更新操作
- 作用:进行事务故障恢复和系统故障恢复,协助介质故障恢复
- 登记日志文件的原则:登记次序严格按并发事务执行的时间次序;须先写日志文件,后写数据库
5:恢复策略
事务故障的恢复过程:反向扫描日志文件并执行相应操作的逆操作;由系统自动完成,对用户透明
系统故障的恢复过程:正向扫描日志文件,找出故障发生前已提交的事务,将其重做;同时找出故障发生时未完成的事务,并撤消这些事务
系统故障造成数据库不一致状态的原因:未完成事务对数据库的更新可能已写入数据库;已提交事务对数据库的更新可能还留在缓冲区中未写入数据库
介质故障的恢复过程:首先重装数据库,使数据库管理系统能正常运行,然后利用介质损坏前对数据库已做的备份或利用镜像设备恢复数据库
6:恢复方法
- 备份技术
- 事务日志
- 镜像技术:在不同的设备上同时存有两份数据库,把其中的一个设备称为主设备,把另一个称为镜像设备
- 小结
- 数据库的安全性是防止非法用户的恶意破坏,数据库的完整性是防止合法用户的善意破坏
- 安全性措施的防范对象是非法用户和非法操作,完整性措施的防范对象是合法用户的不合语义的数据
- 数据库的安全保护功能涉及:安全性控制、完整性控制、并发性控制、数据库恢复
- 数据库恢复的原理——冗余,技术——转储+日志
- 实现并发控制的方法:封锁技术。三封锁协议用于解决并发操作的一致性问题;两段锁协议用于解决并发调度的正确性问题
- 事务是数据库的逻辑工作单位
第9章 数据库集群技术
一、集群技术简介
集群:一种并行或分布式多处理系统;由一个或多个主节点和若干个从节点组成;配合分库、分表、分区技术;单一系统映像
分布式:任务分解,协同工作 集群:任务备份、均衡可靠 二者结合形成分布式集群
二、发展背景
提高性能;降低成本;提高可扩展性;增强可靠性
三、数据库集群技术特点
集群关键技术的4个层次:网络层;节点机及操作系统层;集群系统管理层;应用层
集群系统管理层是集群系统特有功能与技术的体现(自治性)
调度方法:进程迁移(动态负载平衡、容错性和高可用性、并行文件IO、充分利用特殊资源、内存导引机制)
四、数据库集成技术分类
集群的3大分类:高可用性集群HAC、负载均衡集群LBC、高性能计算集群HPC
——HAC:主从服务器(专用线缆、网络链接实现心跳)、活动第二服务器(全部复制、0共享、全部共享为实现形式)可实现高可用性
——LBC:web服务器;负载包括应用程序处理、网络流量
——HPC:并行计算基础;在公共消息传递层上进行通信以运行并行应用程序
Share-Disk架构:通过多个服务器节点共享一个存储来实现数据库集群;分单活(每个节点同时对外提供服务)和双活(仅一个节点对外提供服务)
Share-Nothing架构:分为①分布式架构,②各节点完全独立,节点间提供网络连接
五、数据库分库分表分区
选择RDMBS而不选NoSQL/NewSQL的原因:RDBMS生态完善,绝对稳定,事务特性好
处理海量数据的通用方式:分库分表
垂直/纵向切分:根据业务耦合性,将关联度低的不同表存储在不同的数据库
水平/横向切分:把单表按某个规则把数据分散到多个表;分片规则有【范围路由、Hash路由、配置路由】
如何数据迁移:停机迁移;平滑迁移
分库分表中间件的2大类型:Client模式、Proxy模式
分表:预先设计分表、Merge存储引擎分表
分库分表带来的问题:
- 跨节点关联查询join问题——全局表、字段冗余、数据组装可解决
- 跨节点分页、排序、函数问题
- 事务一致性问题
- 数据迁移、扩容问题
表分区的类型:RANGE分区,LIST分区,HASH分区,KEY分区
六、数据库集成技术应用
集群系统:Windows;Linux/Unix
数据库集成系统:主从复制+读写分离;数据库集群
复制相关的文件:mysql-bin.index;mysql-relay-bin.index;master.info;relay-log.info
复制过滤:在master上过滤二进制日志中的事件;在slave上过滤中继日志中的事件
主从复制的主要操作:
主服务器:
- 开启二进制日志
- 配置唯一的server-id
- 获得master二进制日志文件名及位置
- 创建一个用于slave和master通信的用户账号
从服务器:
- 配置唯一的server-id
- 使用master分配的用户账号读取master二进制日志
- 启用slave服务
MySQL cluster系统构成:管理节点;数据节点;SQL节点
第10章 非关系型数据库
一、NoSQL简介
Not Only SQL,不一定遵循传统数据库的基本要求(SQL标准、ACID属性、表结构)
优势:易扩展;数据模型灵活;高可用;高性能
不足:弱事务性;弱联表查询;非主流;不适合复杂分析查询环境;目前处于前生产环境阶段
二、发展背景
大数据的特征:海量volume,快速velocity,价值value,多样variety,真实veracity
三、CAP理论
分布式数据管理系统的CAP原理三要素:一致性;可用性;分区容忍性(最基本要求)
CAP定理:三要素最多同时实现2点,不能三者兼顾
四、NoSQL数据模型及分类
核心理论基础:BigTable和Dynamo
五、NoSQL应用现状
六、典型的NoSQL
- BigTable
- Dynamo
- Cassandra
- HBase
- Redis
- MongoDB
七、MongoDB
1:用户
移动应用、内容管理、信息面板&数据总线、物联网、电商产品信息、云化方案、大数据分析计算
2:基础
BSON格式
主要特点:
- 高性能、易部署、易使用,存储数据非常方便
- 面向集合存储,易存储对象类型的数据。
- 模式自由
- 支持动态查询
- 支持完全索引,包含内部对象
- 支持查询
- 支持复制和故障恢复
- 使用高效的二进制数据存储,包括大型对象(如视频等)
- 自动处理碎片,以支持云计算层次的扩展性
- 支持PHP,Java,C,C++,C#,Javascript,Python,Perl及Ruby语言的驱动程序
- 文件存储格式为BSON(一种JSON的扩展)
- 可通过网络访问
适用场景:网站数据、缓存、大尺寸低价值数据、高伸缩性场景、对象及JSON数据的存储
不适用场景:高度事务性系统
文档∈集合∈库∈实例
数据模型:数据库database,集合collection,文档document(多个键值对pair组合)
MongoDB的存储方式:内嵌Embedded 关系型数据库的存储方式:外键连接Linked
3:下载和安装配置
4:数据文件构成
存储引擎:MMAPV1、WiredTiger(写性能好、文档级并发、压缩、快照和检查点系统)
存储引擎查看:db.serverStatus()
5:操作
基本管理:启停服务、安全和认证、备份和恢复、监控
支持的数据类型:null、布尔、整数、浮点、字符串、对象ID、日期、时间戳、数组、内嵌文档、RegExp
对应关系:database——database;collection——table;document——row

数据库:

集合:

插入:


查询:




聚合框架主要管道命令和描述:
6:副本集
高可用分为2种:主从复制Master-Slave;副本集Replica Sets
区别:副本集没有固定的主节点
7:分片
分片:将数据拆分,将其分散在不同机器上的过程
8:C#操作
- MongoDB.Driver:驱动程序
- MongoDB.Bson:序列化、Json相关
- MongoDB.Driver.Core:驱动程序的核心和MongoDB.Driver的依赖
9:部署架构
- 单服务器模式
- 主从模式
- 副本集模式
- 分片模式
- 分片+复制模式
10:数据文件内部结构
B树、唯一索引、非唯一索引、联合索引
性能测试
SIGMOD、ICDE、VLDB 并称为国际数据库三大顶级会议
MySQL触发器
触发器的用途:在INSERT,UPDATE,DELETE命令之前或之后自动调用SQL命令或者SP
创建用法:
create trigger name
before|after insert|update|delete
on tablename
for each row
trigger_stmt
OLD.columnname返回一条现有记录在被修改或删除之前的内容(UPDATE,DELETE)
NEW.columnname返回一条新记录或被修改记录的新内容(INSERT,UPDATE)
一个数据表最多定义6个触发器
例子:
delimeter //
create trigger stu_tri
after insert on stu for each row
begin
update class set count = count +1 where id = NEW.cid;
End//
delimeter ;
数据库设计的反规范化
提高某些查询或应用的性能而破坏规范规则
反规范化技术:增加冗余列;增加派生列;重新组表;分割表(水平分割、垂直分割);
相关文章:
【数据库原理与实践】知识点归纳(下)
第6章 规范化理论 一、关系模式设计中存在的问题 关系、关系模式、关系数据库、关系数据库的模式 关系模式看作三元组:R < U,F >,当且仅当U上的一个关系r满足F时,r称为关系模式R < U,F >的一个关系 第一范式(1NF&…...

代码随想录day34
1005.K次取反后最大化的数组和 本题主要是想到排序的时候要按绝对值大小排序。 class Solution { static bool cmp(int a,int b){return abs(a)>abs(b); } public:int largestSumAfterKNegations(vector<int>& nums, int k) {sort(nums.begin(),nums.end(),cmp);…...

CSS知识点汇总(八)--Flexbox
1. flexbox(弹性盒布局模型)是什么,适用什么场景? 1. flexbox(弹性盒布局模型)是什么 Flexible Box 简称 flex,意为”弹性布局”,可以简便、完整、响应式地实现各种页面布局。采用…...

ASCII、Unicode、UTF-8、GBK
入门小菜鸟,希望像做笔记记录自己学的东西,也希望能帮助到同样入门的人,更希望大佬们帮忙纠错啦~侵权立删。 目录 一、定义 1、ASCII 2、Unicode 3、UTF-8 4、GB2312 5、GBK 6、\u和\x 二、相互转化 1、str 与 ASCII 2、str与utf-…...

【安全】使用docker安装Nessus
目录 一、准备docker环境服务器(略) 二、安装 2.1 搜索镜像 2.2 拉取镜像 2.3 启动镜像 三、离线更新插件 3.1 获取challenge 3.2 官方注册获取激活码 3.3 使用challenge码和激活码获取插件下载地址 3.4 下载的插件以及许可协议复制到容器内 四…...
【Hadoop综合实践】手机卖场大数据综合项目分析
🚀 本文章实现了基于MapReduce的手机浏览日志分析 🚀 文章简介:主要包含了数据生成部分,数据处理部分,数据存储部分与数据可视化部分 🚀 【本文仅供参考!!非唯一答案】其中需求实现的…...
服务器技术(三)--Nginx
Nginx介绍 Nginx是什么、适用场景 Nginx是一个高性能的HTTP和反向代理服务器,特点是占有内存少,并发能力强,事实上nginx的并发能力确实在同类型的网页服务器中表现较好。 Nginx专为性能优化而开发,性能是其最重要的考量…...
OpenCV——总结《车牌识别》之《常用的函数介绍》
1. cv2.getStructuringElement(cv2.MORPH_RECT, (10, 10))element cv2.getStructuringElement(shape, ksize[, anchor])用于创建形态学操作的结构元素(structuring element)。 参数解释: shape:结构元素的形状,可以…...

chatgpt赋能python:如何利用Python进行自动化办公
如何利用Python进行自动化办公 在现代办公环境中,自动化成为了一种趋势。利用计算机程序自动处理重复性劳动,可以提高生产效率和工作质量,同时也能够让工作更加轻松。Python作为一种常用的编程语言,在自动化办公中发挥了重要作用…...
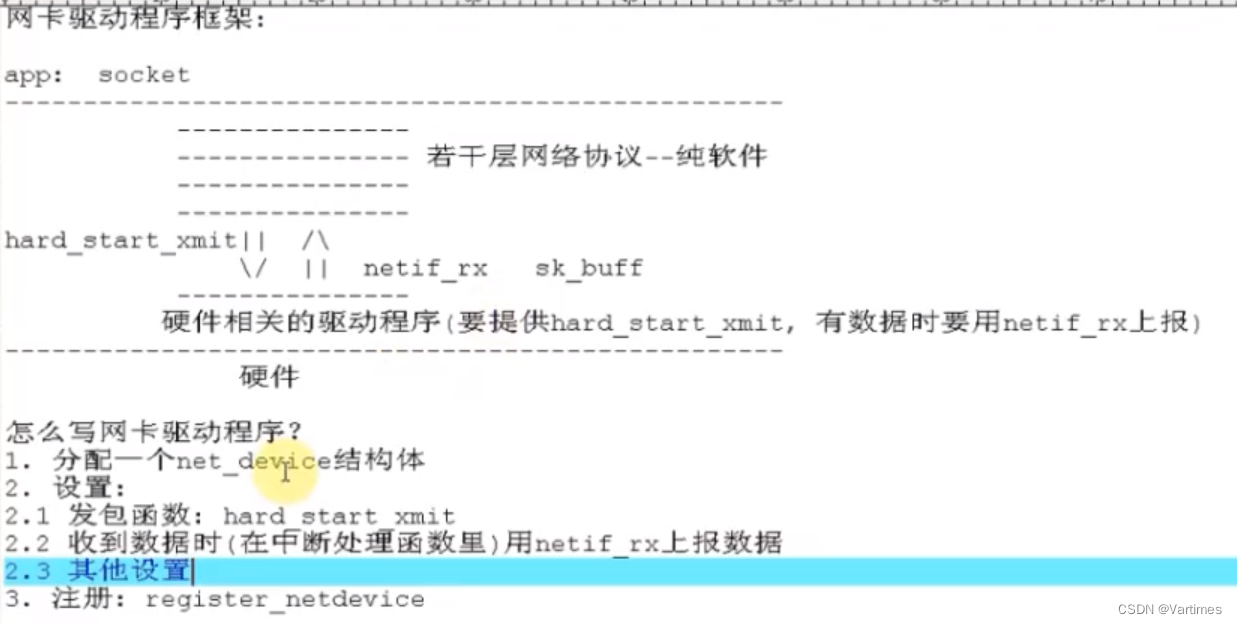
linux-2.6.22.6内核网卡驱动框架分析
网络协议分为很多层,而驱动这层对应于实际的物理网卡部分,这也是最底层的部分,以cs89x0.c这个驱动程序为例来分析下网卡驱动程序框架。 正常开发一个驱动程序时,一般都遵循以下几个步骤: 1.分配某个结构体 2.设置该结…...
机器学习7:特征工程
在传统的软件工程中,核心是代码,然而,在机器学习项目中,重点则是特征——也就是说,开发人员优化模型的方法之一是增加和改进其输入特征。很多时候,优化特征比优化模型带来的增益要大得多。 笔者曾经参与过一…...

coverage代码覆盖率测试介绍
coverage代码覆盖率测试介绍 背景知识补充 1、什么是覆盖率 测试过程中提到的覆盖率,指的是已测试的内容,占待测内容的百分比,在一定程度上反应测试的完整程度。 覆盖率有可以根据要衡量的对象细分很多种,比如接口覆盖率、分支…...
使用 Debian、Docker 和 Nginx 部署 Web 应用
前言 本文将介绍基于 Debian 的系统上使用 Docker 和 Nginx 进行 Web 应用部署的过程。着重介绍了 Debian、Docker 和 Nginx 的安装和配置。 第 1 步:更新和升级 Debian 系统 通过 SSH 连接到服务器。更新软件包列表:sudo apt update升级已安装的软件…...
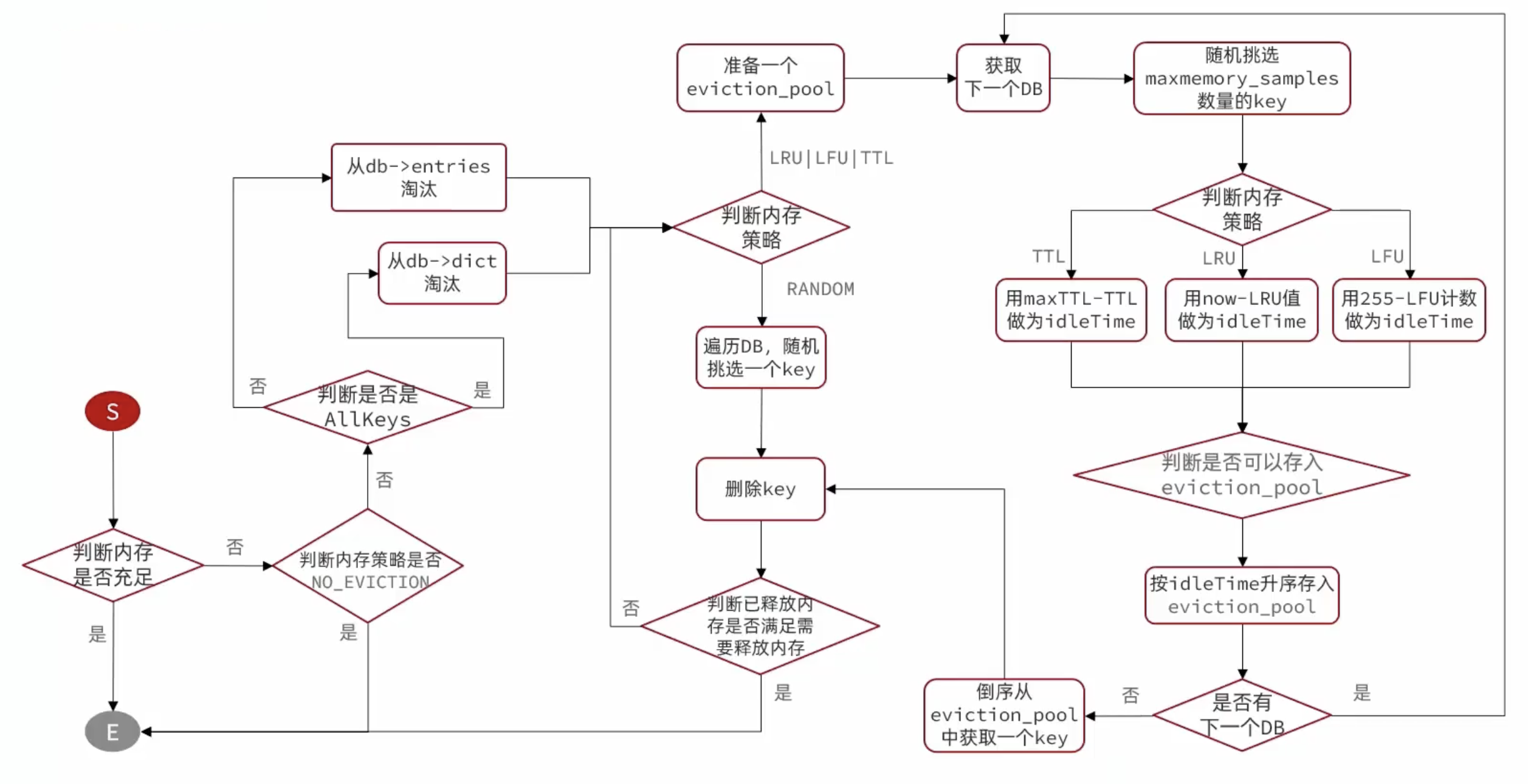
Redis原理 - 内存策略
原文首更地址,阅读效果更佳! Redis原理 - 内存策略 | CoderMast编程桅杆https://www.codermast.com/database/redis/redis-memery-strategy.html Redis 本身是一个典型的 key-value 内存存储数据库,因此所有的 key、value 都保存在之前学习…...
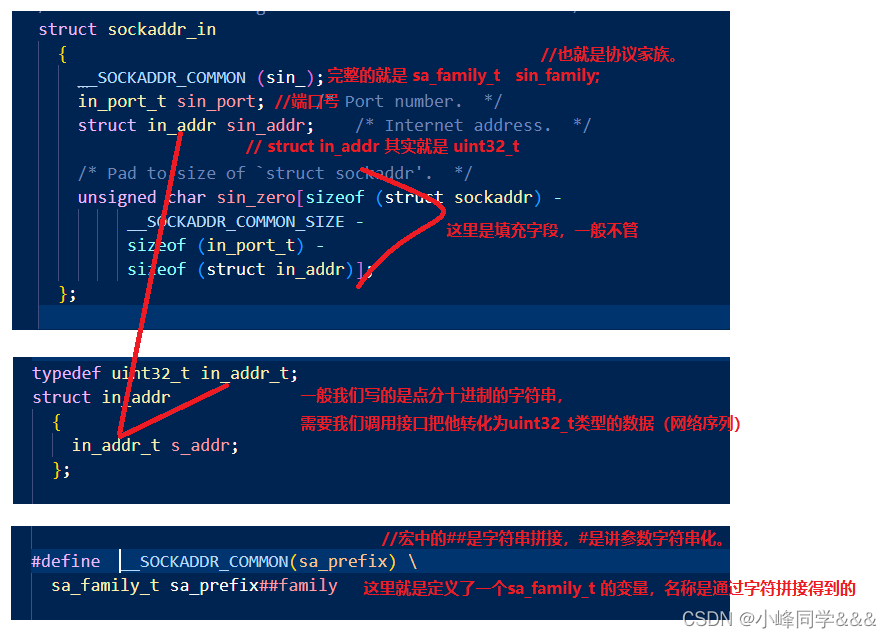
【计算机网络】IP 地址处理函数
目录 1.struct sockaddr_in的结构 2.一般我们写的结构 3.常见的“点分十进制” 到 ” uint32_t 的转化接口 3.1. inet_aton 和 inet_ntoa (ipv4) 3.2. inet_pton 和 inet_ntop (ipv4 和 ipv6) 3.3. inet_addr 和 inet_network 3…...
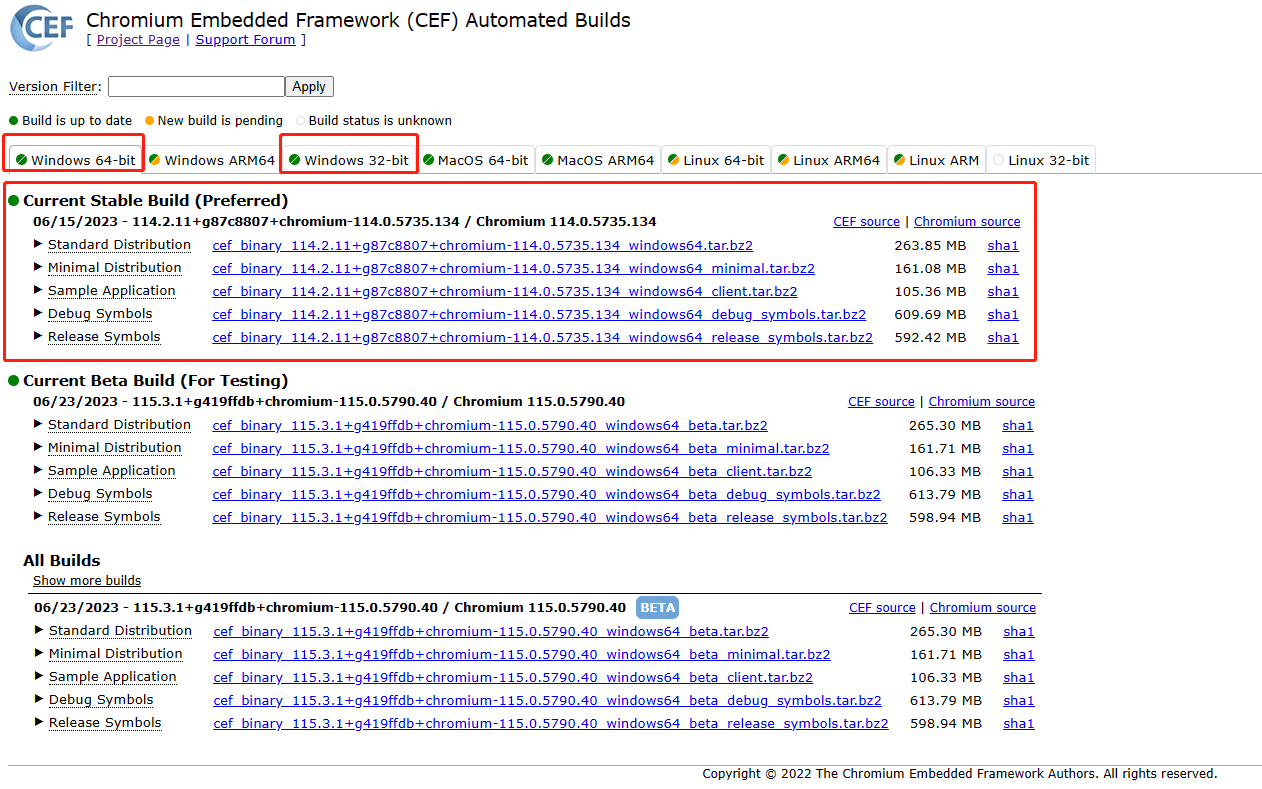
9i物联网浏览器(cef_114.2.110114.2.100支持H264视频)WinForm-CefSharp114(5735)视频版本体验
更新:2023.6.25 版本:Cef_114.2.110和114.2.100+chromium-114.0.5735.134的32位和64位 说明:支持图片,mp3,mp4(H264)多媒体 测试环境:windows server 2019 测试网址:www.html5test.com 1.包下载地址 1.1 https://www.nuget.org/packages/CefSharp.Common/ 1.2 https…...

如何在本地运行一个已关服但具有客户端的游戏
虽然游戏服务器关闭后,我们通常无法再进行在线游戏,但对于一些已经关服但仍保留客户端的游戏来说,我们仍然可以尝试在本地进行游玩。本文将介绍如何在本地运行一个已关服但具有客户端的游戏的方法。 一、获取游戏客户端 要在本地运行一个已关…...

C语言编程—预处理器
预处理器不是编译器的组成部分,但是它是编译过程中一个单独的步骤。简言之,C 预处理器只不过是一个文本替换工具而已,它们会指示编译器在实际编译之前完成所需的预处理。我们将把 C 预处理器(C Preprocessor)简写为 CP…...

使用 Maya Mari 设计 3D 波斯风格道具(p1)
今天瑞云渲染小编给大家带来了Simin Farrokh Ahmadi 分享的Persian Afternoon 项目过程,解释了 Maya 和 Mari 中的建模、纹理和照明过程。 介绍 我的名字是西敏-法罗赫-艾哈迈迪,人们都叫我辛巴 在我十几岁的时候,我就意识到我喜欢艺术和创造…...

Redis分布式问题
Redis实现分布式锁 Redis为单进程单线程模式,采用队列模式将并发访问变成串行访问,且多客户端对Redis的连接并不存在竞争关系Redis中可以使用SETNX命令实现分布式锁。当且仅当 key 不存在,将 key 的值设为 value。 若给定的 key 已经存在&…...

Kook Zimage 真实幻想 Turbo在软件测试中的应用:自动化UI设计验证
Kook Zimage 真实幻想 Turbo在软件测试中的应用:自动化UI设计验证 1. 引言:UI设计验证的痛点与机遇 在软件开发流程中,UI设计验证一直是个让人头疼的环节。测试人员需要对照设计稿,逐个像素检查界面元素的位置、颜色、字体和布局…...

WarcraftHelper:让经典魔兽争霸III在现代电脑上焕发新生的全能助手
WarcraftHelper:让经典魔兽争霸III在现代电脑上焕发新生的全能助手 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 还在为魔兽争霸III在宽…...

ICLR 2026 | 告别Top-K检索!RF-Mem在嵌入空间逐步重构证据链,实现长记忆渐进式唤醒
今天分享一篇来自大连理工大学、香港城市大学、华为和中国科学技术大学的最新工作 RF-Mem,发表于ICLR 2026。这篇工作关注个性化大模型中的一个关键问题:当用户历史越来越长时,模型到底该怎样从海量记忆里,准确找回“此时此刻最相…...
【科研必备】Elsevier Tracker:5分钟搞定学术投稿监控的终极解决方案
【科研必备】Elsevier Tracker:5分钟搞定学术投稿监控的终极解决方案 【免费下载链接】Elsevier-Tracker 项目地址: https://gitcode.com/gh_mirrors/el/Elsevier-Tracker 你是否也曾为了追踪Elsevier期刊的审稿状态而反复刷新页面?每天登录系统…...

Phi-3-mini-128k-instruct实战:利用VLOOKUP逻辑进行多源数据关联与报告生成
Phi-3-mini-128k-instruct实战:利用VLOOKUP逻辑进行多源数据关联与报告生成 1. 引言 如果你用过Excel,肯定对VLOOKUP这个函数不陌生。它的核心就一句话:根据一个表格里的某个值,去另一个表格里找到对应的信息,然后“…...

手把手教你将自定义视频问答JSON转成EasyR1可用的Parquet数据集
手把手教你将自定义视频问答JSON转成EasyR1可用的Parquet数据集 当你在构建视频问答模型时,可能已经收集了大量结构化的JSON格式数据,但如何将这些数据适配到EasyR1框架中却成了一个技术难题。本文将为你提供一个从零开始的完整解决方案,解决…...

FileConverter:重构文件格式转换流程,实现设计师与教育工作者的效率突破
FileConverter:重构文件格式转换流程,实现设计师与教育工作者的效率突破 【免费下载链接】FileConverter File Converter is a very simple tool which allows you to convert and compress files using the context menu in windows explorer. 项目地…...
)
Claude Code本地安装与配置国产智谱模型 (保姆级教程)
目录 一、安装 二、验证安装完整性 三、绕过区域限制协议 1. 创建专属启动脚本 2. 配置系统环境变量 3. 通过脚本启动 四、配置国产智普模型 今天给大家带来一期非常实用的 AI 工具部署教程。作为开发者,善用 AI 工具能极大提升我们的日常编码和解决问题的效…...

【生产环境禁用警告】:这6个Python内存反模式正悄悄拖垮你的K8s Pod——附自动检测脚本
第一章:Python智能体内存管理策略生产环境部署在高并发、长生命周期的Python智能体服务中,内存管理直接影响系统稳定性与响应延迟。默认的CPython引用计数循环垃圾回收(GC)机制在动态对象频繁创建销毁的场景下易引发内存抖动和不可…...

多品种小批量时代的排产革命:JVS-APS智能排产突破交付周期瓶颈
"紧急订单插入,全产线排程推倒重来"、"设备冲突、物料短缺让排产计划沦为纸上谈兵"、"明明产能充足,订单交付周期却比同行长30%"——这些困境正在困扰着越来越多的制造企业。在现代制造业中,多品种小批量生产模…...