JPA 批量插入较大数据 解决性能慢问题
JPA 批量插入较大数据 解决性能慢问题
使用jpa saveAll接口的话需要了解原理:
@Transactional@Overridepublic <S extends T> List<S> saveAll(Iterable<S> entities) {Assert.notNull(entities, "Entities must not be null!");List<S> result = new ArrayList<>();// 使用for循环遍历for (S entity : entities) {result.add(save(entity));}return result;}@Transactional@Overridepublic <S extends T> S save(S entity) {Assert.notNull(entity, "Entity must not be null.");// 每条数据都会查询之后 做下判断if (entityInformation.isNew(entity)) {em.persist(entity);return entity;} else {return em.merge(entity);}}public boolean isNew(T entity) {ID id = getId(entity);Class<ID> idType = getIdType();if (!idType.isPrimitive()) {// 如果id有值,则认为不是新数据,则更新操作,否则就是写入操作return id == null;}if (id instanceof Number) {return ((Number) id).longValue() == 0L;}throw new IllegalArgumentException(String.format("Unsupported primitive id type %s", idType));}
以上是jpa源码,所以导致写入数据很慢。因为for遍历一行一行数据写入,而且还要判断;
以下为亲测两种解决方案:
第一种: 自己编写写入逻辑,引入 EntityManager entityManager,代码如下
批量写入一批数据。一次事务提交一批。
@Value("${spring.jpa.properties.hibernate.jdbc.batch_size:1000}")private int batchSize;@PersistenceContextprivate EntityManager entityManager;public <T> void batchInsert(List<T> list) {if (!ObjectUtils.isEmpty(list)){for (int i = 1; i <= list.size(); i++) {// 写入操作entityManager.persist(list.get(i - 1));if (i % batchSize == 0) {entityManager.flush();entityManager.clear();}}if (list.size() % batchSize != 0) {//flush() 同步持久上下文环境,即将持久上下文环境的所有未保存实体的状态信息保存到数据库中。entityManager.flush();//clear() 清除持久上下文环境,断开所有关联的实体。如果这时还有未提交的更新则会被撤消。entityManager.clear();}}}public <T> void batchUpdate(List<T> list) {if (!ObjectUtils.isEmpty(list)){for (int i = 1; i < list.size(); i++) {entityManager.merge(list.get(i - 1));if (i % batchSize == 0) {entityManager.flush();entityManager.clear();}}if (list.size() % batchSize != 0) {entityManager.flush();entityManager.clear();}}}
第二种:不需要自己编写逻辑,使用jpa saveAll()方法
开启JPA批处理
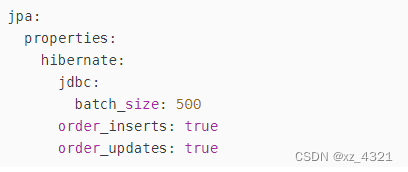
jpa 表映射@Table 下对主键使用序列,postgre支持创建序列,可以使用,其他数据源不一定。
@GeneratedValue(strategy = SEQUENCE, generator = "seqGen")@SequenceGenerator(name = "seqGen", sequenceName = "seq", initialValue = 1)
这样做的逻辑saveAll()不需要判断isNew,直接走em.persist(entity);
两种的性能差不多,记录下
相关文章:
JPA 批量插入较大数据 解决性能慢问题
JPA 批量插入较大数据 解决性能慢问题 使用jpa saveAll接口的话需要了解原理: TransactionalOverridepublic <S extends T> List<S> saveAll(Iterable<S> entities) {Assert.notNull(entities, "Entities must not be null!");List<…...

为啥离不了 linux
Linux与Windows都是十分常见的电脑操作系统,相信你对它们二者都有所了解!在你的使用过程中,是否有什么事让你觉得在Linux上顺理成章,换到Windows上就令你费解?亦或者关于这二者你有任何想要分享的,都可以在…...

基于分形的置乱算法和基于混沌系统的置乱算法哪种更安全?
在信息安全领域中,置乱算法是一种重要的加密手段,它可以将明文进行混淆和打乱,从而实现保密性和安全性。常见的置乱算法包括基于分形的置乱算法和基于混沌系统的置乱算法。下面将从理论和实践两方面,对这两种置乱算法进行比较和分…...

pve使用cloud-image创建ubuntu模板
首先连接pve主机的终端 下载ubuntu22.04的cloud-image镜像 wget -P /opt https://mirrors.cloud.tencent.com/ubuntu-cloud-images/jammy/current/jammy-server-cloudimg-amd64.img创建虚拟机,id设为9000,使用VirtIO SCSI控制器 qm create 9000 -core…...
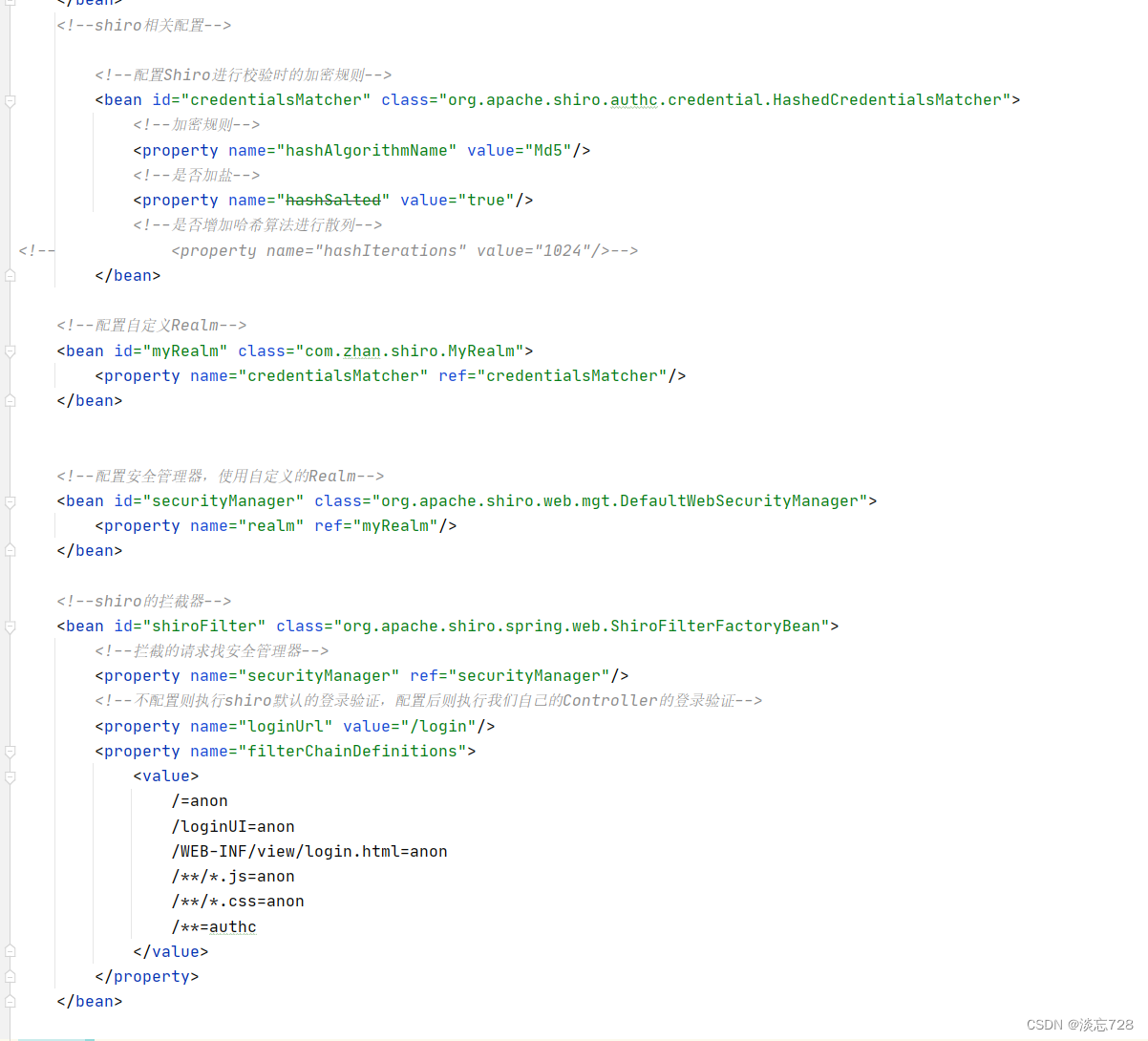
shiro入门
1、概述 Apache Shiro 是一个功能强大且易于使用的 Java 安全(权限)框架。借助 Shiro 您可以快速轻松地保护任何应用程序一一从最小的移动应用程序到最大的 Web 和企业应用程序。 作用:Shiro可以帮我们完成 :认证、授权、加密、会话管理、与 Web 集成、…...
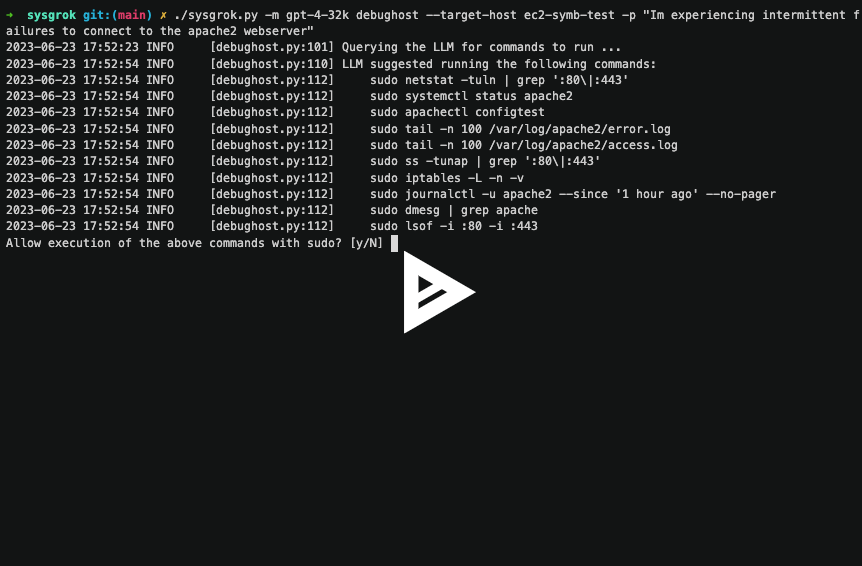
开源 sysgrok — 用于分析、理解和优化系统的人工智能助手
作者:Sean Heelan 在这篇文章中,我将介绍 sysgrok,这是一个研究原型,我们正在研究大型语言模型 (LLM)(例如 OpenAI 的 GPT 模型)如何应用于性能优化、根本原因分析和系统工程领域的问题。 你可以在 GitHub …...
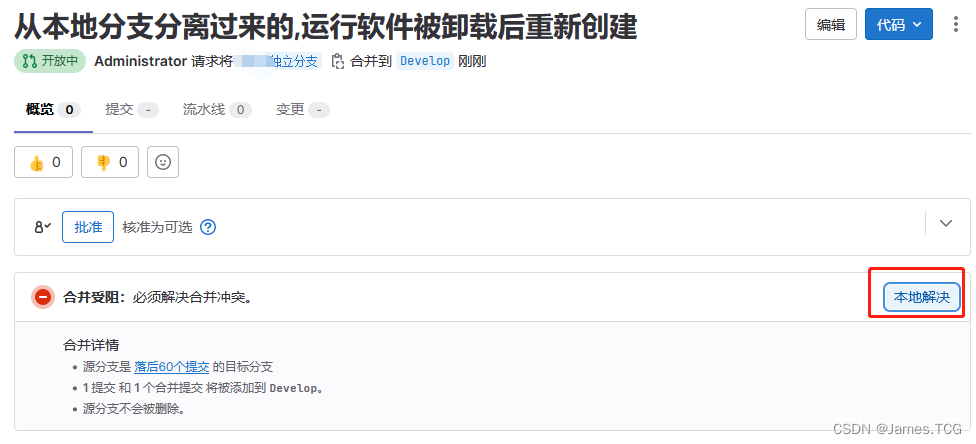
Gitlab保护分支与合并请求
目录 引言 1、成员角色指定 1、保护分支设置 2、合并请求 引言 熟悉了Git工作流之后,有几个重要的分支,如Master(改名为Main)、Develop、Release分支等,是禁止开发成员随意合并和提交的,在此分支上的提交和推送权限仅限项目负责…...

ad18学习笔记九:输出文件
一般来说提供给板卡厂的文件里要包括以下这些文件 1、装配图 2、bom文件 3、gerber文件 4、转孔文件 5、坐标文件 6、ipc网表 AD_PCB:Gerber等各类文件的输出 - 哔哩哔哩 原点|钻孔_硬件设计AD 生成 Gerber 文件 1、装配图 如何输出装配图? 【…...

PostgreSQL 内存配置 与 MemoryContext 的生命周期
PostgreSQL 内存配置与MemoryContext的生命周期 PG/GP 内存配置 数据库可用的内存 gp_vmem 整个 GP 数据库可用的内存 gp_vmem: >>> RAM 128 * GB >>> gp_vmem ((SWAP RAM) - (7.5*GB 0.05 * RAM)) / 1.7 >>> print(gp_vmem / G…...
)
vue3 组件间通信的方式(setup语法糖写法)
vue3 组件间通信的方式(setup语法糖写法) 1. Props方式 该方式用于父传子,父组件以数据绑定的形式声明要传递的数据,子组件通过defineProps()方法创建props对象,即可拿到父组件传来的数据。 // 父组件 <template><div><son…...

【Cache】Rsync远程同步
文章目录 一、rsync 概念二、rysnc 服务器部署1. 环境配置2. rysnc 同步源服务器2.1 安装 rsync2.2 建立 rsyncd.conf 配置文件2.3 创建数据文件(账号密码)2.4 启动服务2.5 数据配置 3. rysnc 客户端3.1 设置同步方法一方法二 3.2 免交互设置 4. rysnc 认…...

Gitlab升级报错一:rails_migration[gitlab-rails] (gitlab::database_migrations line 51)
Gitlab-ce从V14.0.12升级到V14.3.6或V14.10.5时报错:如下图: 解决办法: 先停掉gitlab: gitlab-ctl stop 单独启动数据库,如果不单独启动数据库,就会报以上错误 sudo gitlab-ctl start postgresql 解决办法&#x…...
chatGPT流式回复是怎么实现的
chatGPT流式回复是怎么实现的 先说结论: chatGPT的流式回复用的就是HTTP请求方案中的server-send-event流式接口,也就是服务端向客户端推流数据。 那eventStream流式接口怎么实现呢,下面就进入正题! 文章目录 chatGPT流式回复…...
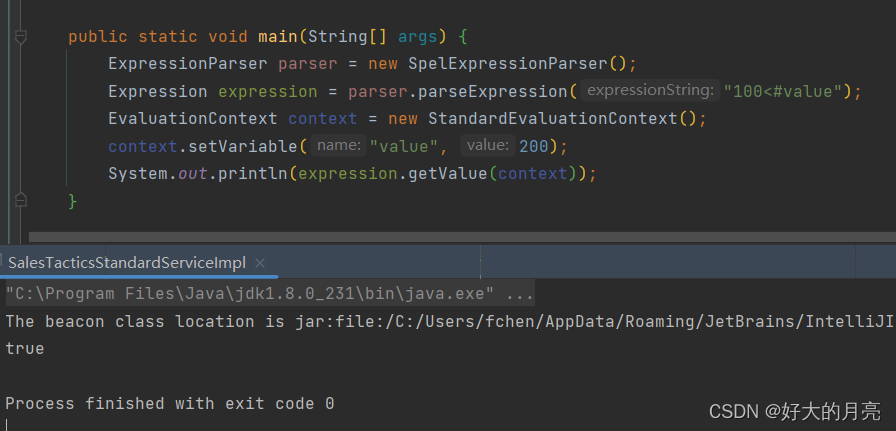
使用SpringEL获得字符串中的表达式运算结果
概述 有时候会遇上奇怪的需求,比如解析字符串中表达式的结果。 这个时候自己写解析肯定是比较麻烦的, 正好SprinngEL支持加()、减(-)、乘(*)、除(/)、求余(%)、幂(^)运算,可以免去造轮子的功夫…...

力扣 39. 组合总和
题目来源:https://leetcode.cn/problems/combination-sum/description/ C题解: 递归法。递归前对数组进行有序排序,可方便后续剪枝操作。 递归函数参数:定义两个全局变量,二维数组result存放结果集,数组pa…...
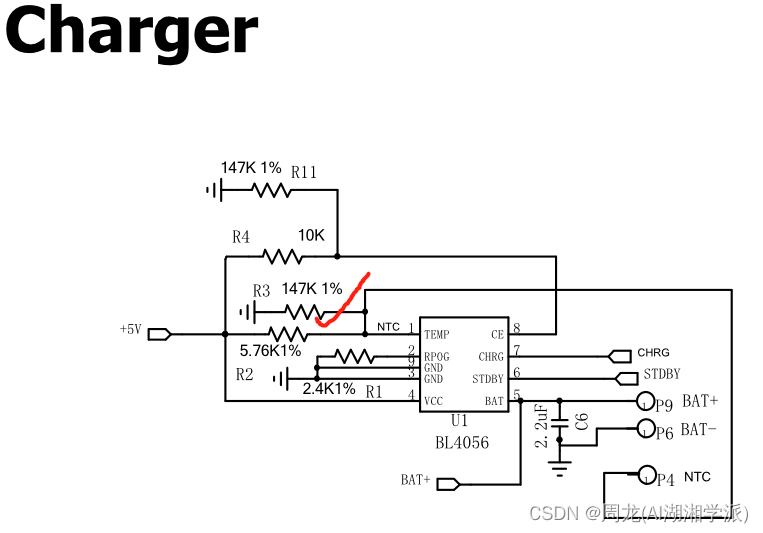
基于BES系列蓝牙耳机NTC充电电池保护电路设计
+hezkz17进数字音频系统研究开发交流答疑 一 在充电电路中NTC作用? 在充电电路中,NTC(Negative Temperature Coefficient)热敏电阻通常被用于温度检测和保护。它具有随温度变化而变化的电阻值。 以下是NTC在充电电路中的几种常见作用: 温度监测:NTC热敏电阻可以用来测量…...

13-C++算法笔记-递归
📚 Introduction 递归是一种常用的算法设计和问题求解方法。它基于问题可以分解为相同类型的子问题,并通过解决子问题来解决原始问题的思想。递归算法在实际编程中具有广泛的应用。 🎯 递归算法解决问题的特点 递归算法具有以下特点&#…...
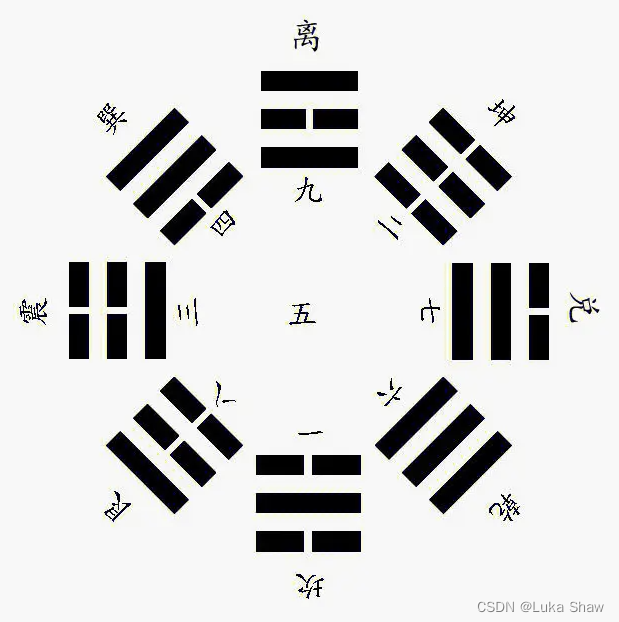
从古代八卦探究计算机的八进制
八进制,即八卦,是中国古代哲学体系中非常重要的一个概念,它被广泛应用于易经、道家、儒家等诸多领域。随着计算机科学的快速发展,人们开始思考:八进制是否可以应用到计算机上? 一、什么是八进制࿱…...

Linux shell mkfs.ext4命令参数使用
mkfs mkfs是个综合命令 mkfs 然后按两下tab 查看系统支持哪些文件系统的格式化功能 mkfs -t 文件系统格式名 以指定的文件系统格式来进行磁盘格式化 > 等于 mkfs.文件系统格式名 比如: mkfs -t xfs mkfs.xfs 常见的磁盘格式…...

【Docker】子系统与其相关名词的界定、Control Groups等详细讲解
前言 Docker 是一个开源的应用容器引擎,让开发者可以打包他们的应用以及依赖包到一个可移植的容器中,然后发布到任何流行的Linux或Windows操作系统的机器上,也可以实现虚拟化,容器是完全使用沙箱机制,相互之间不会有任何接口。 📕作者简介:热…...

解锁Claude无限潜能:技能生态系统的构建艺术
解锁Claude无限潜能:技能生态系统的构建艺术 【免费下载链接】awesome-claude-skills A curated list of awesome Claude Skills, resources, and tools for customizing Claude AI workflows 项目地址: https://gitcode.com/GitHub_Trending/aw/awesome-claude-s…...

StructBERT WebUI部署教程:CSDN GPU Pod环境下5000端口服务配置与防火墙适配
StructBERT WebUI部署教程:CSDN GPU Pod环境下5000端口服务配置与防火墙适配 1. 项目概述 StructBERT文本相似度服务是一个基于百度StructBERT大模型的高精度中文句子相似度计算工具。这个工具能够准确判断两个中文句子在语义上的相似程度,为各种文本处…...

从旅游Vlog到新闻视频:QVHIGHLIGHTS数据集在跨领域应用中的实战指南
QVHIGHLIGHTS数据集:跨领域视频内容智能解析的工程实践 当你在旅行Vlog中搜索"日落时分的海滩漫步",或在新闻视频中寻找"抗议活动现场冲突画面",传统视频平台只能返回整段视频——这就像给你一整本书而不是精确的页码。Q…...

springboot+vue基于web的宠物商城领养网站的设计与实现
目录同行可拿货,招校园代理 ,本人源头供货商功能模块分析技术实现要点特色功能扩展安全与性能项目技术支持源码获取详细视频演示 :文章底部获取博主联系方式!同行可合作同行可拿货,招校园代理 ,本人源头供货商 功能模块分析 用户模块 注册与登录&#…...

从夯到拉,大模型岗位全攻略:程序员转型指南与避坑指南
文章详细解析了大模型领域五个梯队岗位的工作内容、技能要求及发展前景,从底层预训练工程师到应用开发工程师,为不同背景的程序员提供转型建议。同时指出行业人才缺口巨大,传统程序员可凭借编程基础实现职业升级,并推荐系统学习路…...

RPA+AI市场进入精细化竞争阶段,企业选型逻辑正在改变
IDC最新数据显示,中国RPAAI解决方案市场规模已达31.5亿元,竞争格局呈现“头部集中、市场分散”特征:金智维以10.1%份额位居第一,艺赛旗(9.1%)、来也科技(8.4%)紧随其后,前…...
)
Python MCP服务端框架源码剖析(2024最新LTS版内核解密)
第一章:Python MCP服务端框架源码剖析(2024最新LTS版内核解密)Python MCP(Modular Control Protocol)服务端框架2024 LTS版标志着其架构从单体调度向轻量级异步模块总线的重大演进。该版本基于 Python 3.11 构建&#…...

KEPServerEX与SQLServer数据库的无缝集成指南
1. KEPServerEX与SQLServer集成的核心价值 在工业自动化和数据采集领域,KEPServerEX作为领先的通信平台,与SQLServer数据库的集成能够实现设备数据到关系型数据库的高效流转。这种组合特别适合需要长期存储设备运行数据、生成生产报表或进行数据分析的场…...

Qwen3-ASR-0.6B方言识别效果展示:粤语、四川话实测
Qwen3-ASR-0.6B方言识别效果展示:粤语、四川话实测 1. 引言 语音识别技术发展至今,已经能够很好地处理普通话和英语等主流语言,但方言识别一直是技术难点。不同地区的方言在发音、语调、词汇上都有很大差异,让机器准确识别并非易…...
)
Mojo加速Python科学计算:如何在72小时内将AI推理速度提升8.6倍(附完整可运行代码)
第一章:Mojo与Python混合编程概述Mojo 是一种为 AI 系统量身打造的现代系统编程语言,兼具 Python 的易用性与 C/C 的执行效率。它原生兼容 Python 生态,允许开发者在同一个项目中无缝调用 Python 模块、复用现有 NumPy/Torch 代码,…...