Hive on Spark的小文件设置参数
Hive on Spark的小文件设置参数
参数调优
了解完了Spark作业运行的基本原理之后,对资源相关的参数就容易理解了。所谓的Spark资源参数调优,其实主要就是对Spark运行过程中各个使用资源的地方,通过调节各种参数,来优化资源使用的效率,从而提升Spark作业的执行性能。以下参数就是Spark中主要的资源参数,每个参数都对应着作业运行原理中的某个部分。
num-executors/spark.executor.instances
参数说明:该参数用于设置Spark作业总共要用多少个Executor进程来执行。Driver在向YARN集群管理器申请资源时,YARN集群管理器会尽可能按照你的设置来在集群的各个工作节点上,启动相应数量的Executor进程。这个参数非常之重要,如果不设置的话,默认只会给你启动少量的Executor进程,此时你的Spark作业的运行速度是非常慢的。
参数调优建议:每个Spark作业的运行一般设置50~100个左右的Executor进程比较合适,设置太少或太多的Executor进程都不好。设置的太少,无法充分利用集群资源;设置的太多的话,大部分队列可能无法给予充分的资源。
executor-memory/spark.executor.memory
参数说明:该参数用于设置每个Executor进程的内存。Executor内存的大小,很多时候直接决定了Spark作业的性能,而且跟常见的JVM OOM异常,也有直接的关联。
参数调优建议:每个Executor进程的内存设置4G8G较为合适。但是这只是一个参考值,具体的设置还是得根据不同部门的资源队列来定。可以看看自己团队的资源队列的最大内存限制是多少,num-executors乘以executor-memory,是不能超过队列的最大内存量的。此外,如果你是跟团队里其他人共享这个资源队列,那么申请的内存量最好不要超过资源队列最大总内存的1/31/2,避免你自己的Spark作业占用了队列所有的资源,导致别的同学的作业无法运行。
executor-cores/spark.executor.cores
参数说明:该参数用于设置每个Executor进程的CPU core数量。这个参数决定了每个Executor进程并行执行task线程的能力。因为每个CPU core同一时间只能执行一个task线程,因此每个Executor进程的CPU core数量越多,越能够快速地执行完分配给自己的所有task线程。
参数调优建议:Executor的CPU core数量设置为2~4个较为合适。同样得根据不同部门的资源队列来定,可以看看自己的资源队列的最大CPU core限制是多少,再依据设置的Executor数量,来决定每个Executor进程可以分配到几个CPU core。同样建议,如果是跟他人共享这个队列,那么num-executors * executor-cores不要超过队列总CPU core的1/3~1/2左右比较合适,也是避免影响其他同学的作业运行。
driver-memory
参数调优建议:Driver的内存通常来说不设置,或者设置1G左右应该就够了。唯一需要注意的一点是,如果需要使用collect算子将RDD的数据全部拉取到Driver上进行处理,那么必须确保Driver的内存足够大,否则会出现OOM内存溢出的问题。
spark.default.parallelism
参数说明:该参数用于设置每个stage的默认task数量。这个参数极为重要,如果不设置可能会直接影响你的Spark作业性能。
参数调优建议:Spark作业的默认task数量为500~1000个较为合适。很多同学常犯的一个错误就是不去设置这个参数,那么此时就会导致Spark自己根据底层HDFS的block数量来设置task的数量,默认是一个HDFS block对应一个task。通常来说,Spark默认设置的数量是偏少的(比如就几十个task),如果task数量偏少的话,就会导致你前面设置好的Executor的参数都前功尽弃。试想一下,无论你的Executor进程有多少个,内存和CPU有多大,但是task只有1个或者10个,那么90%的Executor进程可能根本就没有task执行,也就是白白浪费了资源!因此Spark官网建议的设置原则是,设置该参数为num-executors * executor-cores的2~3倍较为合适,比如Executor的总CPU core数量为300个,那么设置1000个task是可以的,此时可以充分地利用Spark集群的资源。
spark.storage.memoryFraction
参数说明:该参数用于设置RDD持久化数据在Executor内存中能占的比例,默认是0.6。也就是说,默认Executor 60%的内存,可以用来保存持久化的RDD数据。根据你选择的不同的持久化策略,如果内存不够时,可能数据就不会持久化,或者数据会写入磁盘。
参数调优建议:如果Spark作业中,有较多的RDD持久化操作,该参数的值可以适当提高一些,保证持久化的数据能够容纳在内存中。避免内存不够缓存所有的数据,导致数据只能写入磁盘中,降低了性能。但是如果Spark作业中的shuffle类操作比较多,而持久化操作比较少,那么这个参数的值适当降低一些比较合适。此外,如果发现作业由于频繁的gc导致运行缓慢(通过spark web ui可以观察到作业的gc耗时),意味着task执行用户代码的内存不够用,那么同样建议调低这个参数的值。
spark.shuffle.memoryFraction
参数说明:该参数用于设置shuffle过程中一个task拉取到上个stage的task的输出后,进行聚合操作时能够使用的Executor内存的比例,默认是0.2。也就是说,Executor默认只有20%的内存用来进行该操作。shuffle操作在进行聚合时,如果发现使用的内存超出了这个20%的限制,那么多余的数据就会溢写到磁盘文件中去,此时就会极大地降低性能。
参数调优建议:如果Spark作业中的RDD持久化操作较少,shuffle操作较多时,建议降低持久化操作的内存占比,提高shuffle操作的内存占比比例,避免shuffle过程中数据过多时内存不够用,必须溢写到磁盘上,降低了性能。此外,如果发现作业由于频繁的gc导致运行缓慢,意味着task执行用户代码的内存不够用,那么同样建议调低这个参数的值。
–设置执行器个数
set spark.executor.instances=4;
–设置执行器计算核个数
set spark.executor.cores=4;
–设置执行器内存
set spark.executor.memory=8g;
–设置每个executor的jvm堆外内存
set spark.yarn.executor.memoryOverhead=4096;
hive.merge.sparkfiles 是否在hive on spark任务后开启小文件合并
hive.merge.smallfiles.avgsize 如果原先输出的文件平均大小小于这个值,则开启小文件合并。比如输出原本有100个文件,总大小1G,那平均每个文件大小只有10M,如果我们这个参数设置为16M,这时就会开启文件合并
hive.merge.size.per.task 开启小文件合并后,预期的一个合并文件的大小。比如原先的总大小有1G,我们预期一个文件256M的话,那么最终经过合并会生成4个文件。
我们都知道,mr控制map,reduce数量及合并小文件大小的相关参数,其实hive on spark同时适用
-- 控制map阶段的并行度:-- 每个Map最大输入大小,决定合并后的文件数set mapred.max.split.size=268435456; -- 一个节点上split的至少的大小 ,决定了多个data node上的文件是否需要合并set mapred.min.split.size.per.node=268435456; -- 一个交换机下split的至少的大小,决定了多个交换机上的文件是否需要合并set mapred.min.split.size.per.rack=268435456; -- 执行Map前进行小文件合并; 在map执行前合并小文件,减少map数set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat; -- 控制shuffle的并行度:-- 每个Reduce处理的数据量set hive.exec.reducers.bytes.per.reducer=268435456;-- 最大reduce数量set hive.exec.reducers.max=1099;-- 控制最终输出hdfs的单个文件大小,影响merge阶段的并行度(hive.merge.sparkFiles=true生效):-- 合并后每个文件的大小set hive.merge.size.per.task=268435456;-- 平均文件大小,是决定是否执行merge阶段操作的阈值,当输出文件的平均大小小于该值时,启动一个独立的任务进行文件mergeset hive.merge.smallfiles.avgsize=134217728;
相关文章:

Hive on Spark的小文件设置参数
Hive on Spark的小文件设置参数 参数调优 了解完了Spark作业运行的基本原理之后,对资源相关的参数就容易理解了。所谓的Spark资源参数调优,其实主要就是对Spark运行过程中各个使用资源的地方,通过调节各种参数,来优化资源使用的效…...
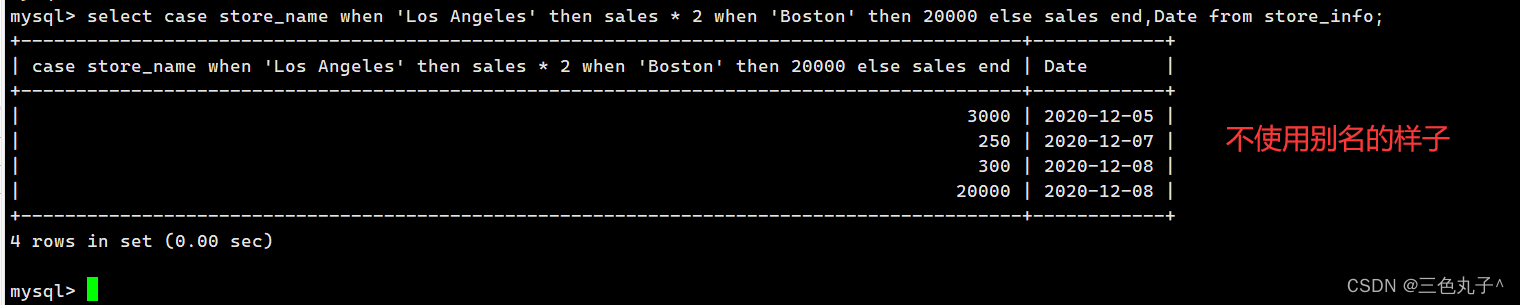
高级SQL语句
目录 MySQL 高级(进阶) SQL 语句函数数学函数:聚合函数字符串函数: 连接查询inner join(内连接):left join(左连接):right join(右连接): CREATE VIEW(视图)UNION(联集)C…...
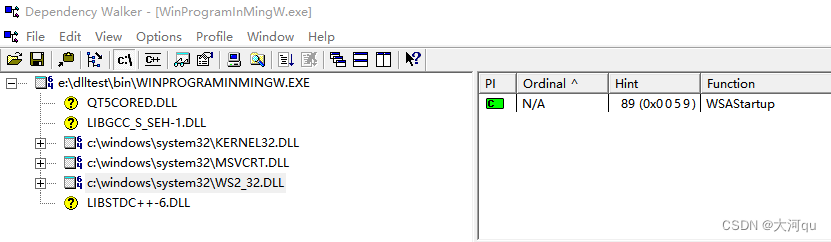
IDE /skipping incompatible xxx_d.dll when searching for -lxxx_d
文章目录 概述场景复现用以测试的代码编译器位数不匹配导致?保持编译器类型一致再验证编译器位数的影响MingW下调用OS的库咋不告警?以mingW下使用winSocket为例MingW下网络编程的头文件分析该环境下链接的ws2_32库文件在哪里?mingW为啥可以兼容window下的动态库 概…...
C语言学习准备-编辑器选择
今天继续给大家更新C语言经典案例 今天的案例会比昨天稍微有一些难度,但是同时还是非常经典的案例 本来是想给大家继续更新C语言经典案例,但是有朋友反应C语言编辑器的选择,刚好我自己也是想更换一下C语言的编辑器,跟大家分享一下…...
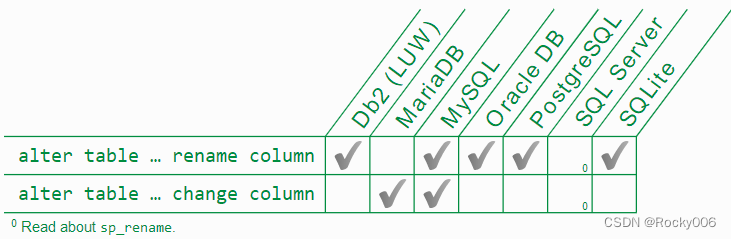
微信为什么使用 SQLite 保存聊天记录?
概要 SQLite 是一个被大家低估的数据库,但有些人认为它是一个不适合生产环境使用的玩具数据库。事实上,SQLite 是一个非常可靠的数据库,它可以处理 TB 级的数据,但它没有网络层。接下来,本文将与大家共同探讨 SQLite 在…...

VB串口通讯方式解释
目前,Visual Basic (简称VB) 已成为WINDOWS 系统开发的主要语言,以其高效、简单易学及功能强大的特点越来越为广大程序设计人员及用户所青睐。VB 支持面向对象的程序设计,具有结构化的事件驱动编程模式并可以使用无限扩增的控件。在VB 应用程序中可以方便地调用WINDOWS API函数…...
Mybatis-Plus不能更新对象字段为空值问题解决
问题描述: 在使用Mybatis-Plus调用updateById方法进行数据更新默认情况下是不能更新空值字段的,而在实际开发过程中,往往会遇到需要将字段值更新为空值的情况,该如何解决呢? 原因分析: Mybatis-Plus中字…...
d3dx9_43.dll丢失怎么解决
d3dx9_43.dll丢失的影响 当我们在运行某些需要DirectX 9支持的程序时,如果系统中缺少d3dx9_43.dll文件,就会出现错误提示,导致程序无法正常启动。这个错误提示通常会类似于“找不到d3dx9_43.dll”或“d3dx9_43.dll不存在”。 打开电脑浏览器…...

【花雕】全国青少年机器人技术一级考试备考实操搭建手册8
随着科技的不断进步,机器人技术已经成为了一个重要的领域。在这个领域中,机械结构是机器人设计中至关重要的一部分,它决定了机器人的形态、运动方式和工作效率。对于青少年机器人爱好者来说,了解机械结构的基础知识,掌…...
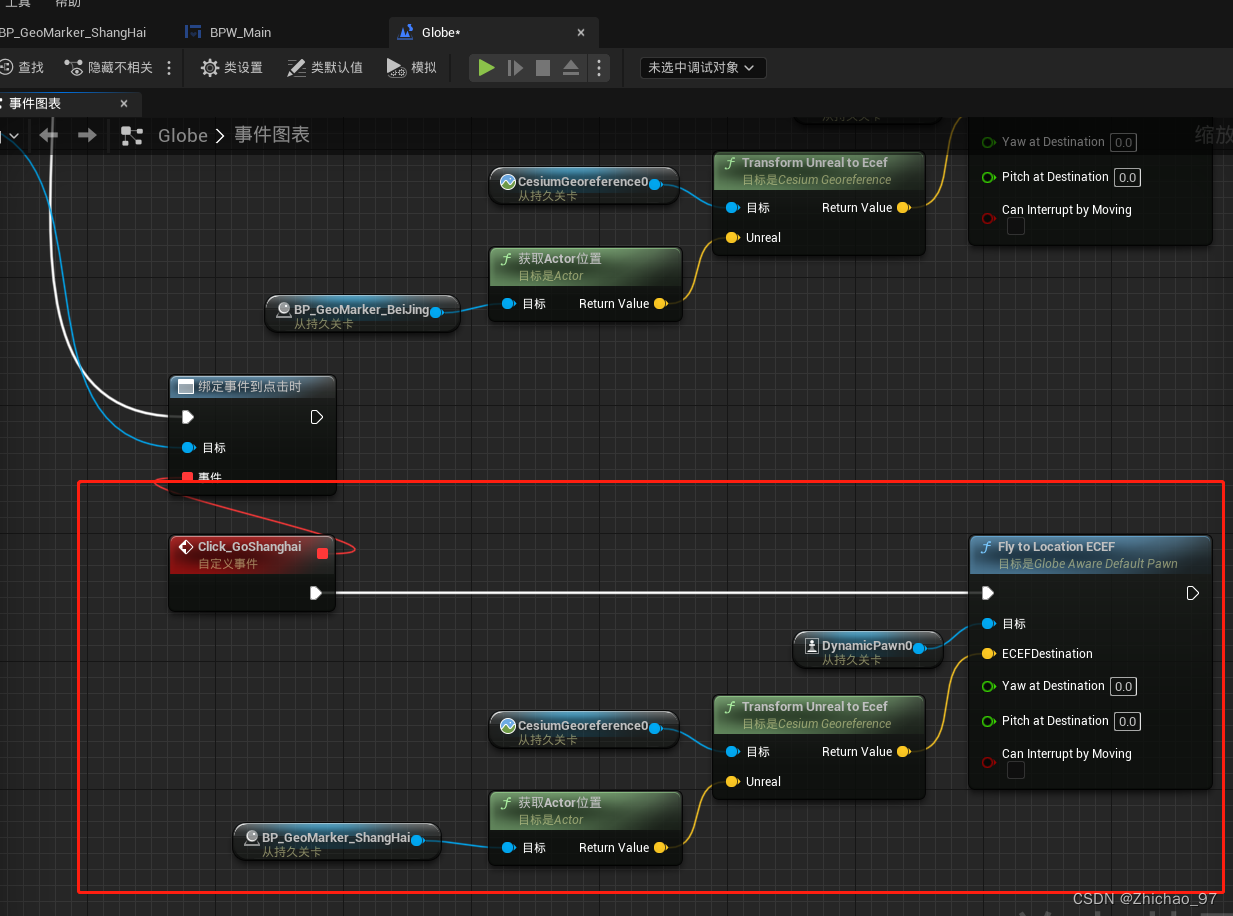
【UE5 Cesium】09-Cesium for Unreal 子关卡应用实例(下)
效果 通过按钮点击事件实现子关卡的切换 步骤 新建两个Actor蓝图作为GeoMarker,分别命名为“BP_GeoMarker_BeiJing”、“BP_GeoMarker_ShangHai” 分别打开这两个蓝图,添加文本渲染组件 在指定的地理位置上拖入蓝图“BP_GeoMarker_BeiJing” 控制“BP_…...
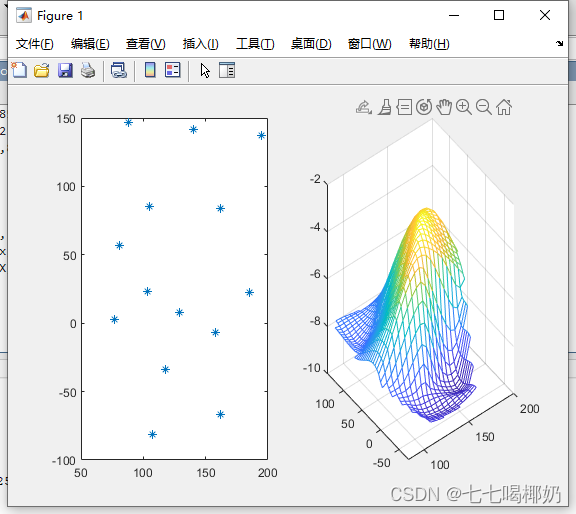
插值应用案例2
案例1 高点和高程 在一丘陵地带测量高程,x和y方向每隔100m测一个点,得到高程如下表所列,试插值一曲面,确定合适的模型,并由此测到最高点和相应的高程。 x0/z0\y0 100 200 300 400 500 100 636 697 624 478 …...

【新星计划Linux】——常用命令(1)
作者简介:一名云计算网络运维人员、每天分享网络与运维的技术与干货。 座右铭:低头赶路,敬事如仪 个人主页:网络豆的主页 目录 前言 一.常用命令 1.Linux的基本原则: 用户接口: 2.命令形…...

python应用-excel和数据库的读取及写入操作
近日完成一个交办任务,从excel表读取数据,根据ID在数据库表匹配相应的记录,并回填至excel表里。我使用的工具是python。下面记录下相应的模块。 一、从excel表读取数据 import pandas as pd import numpy as npdef read_excel():path &quo…...
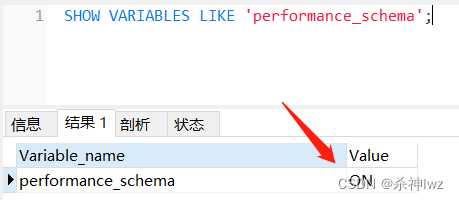
MySQL Optimization Learning(一)
目录 一、MySQL性能监控 1、show profile 2、performance schema 2.1、MYSQL performance schema详解 3、show processlist 一、MySQL性能监控 MySQL官网 拖到首页最下方找到 MySQL Reference Manual ->cmd命令行 C:\Users\Administrator>mysql -uroot -proot …...
Flink消费kafka出现空指针异常
文章目录 出现场景:表现:问题:解决: tombstone : Kafka中提供了一个墓碑消息(tombstone)的概念,如果一条消息的key不为null,但是其value为null,那么此消息就是墓碑消息. …...

【探索 Kubernetes|作业管理篇 系列 9】Pod 的服务对象
前言 大家好,我是秋意零。 在上一篇中,我们介绍了 Pod 的生命周期以及区分 Pod 字段的层次级别,相信你对此有了充分的认识。 今天,我们还会接着以 Pod 展开,说说它的 “服务对象”,一听就知道是对 Pod 提…...

多种拖拽= =自用留档
<template> <div class"main-drag"> <div v-if"stencil 0" class"mapped-fields"> <el-form ref"mapped" :model"mapped" class"demo-fieldsForm"> <el-form-item label"切换数…...

贝叶斯与认知——读《贝叶斯的博弈》有感
关于对贝叶斯与认知问题的相关思考 一、贝叶斯定理二、贝叶斯与认知的本质三、经验的偏见四、总结 自古以来,人们就在思考知识来自何处,“冯翼惟象,何以识之?”,对此的思考逐渐发展成哲学的认识论分支。德国哲学家康德…...
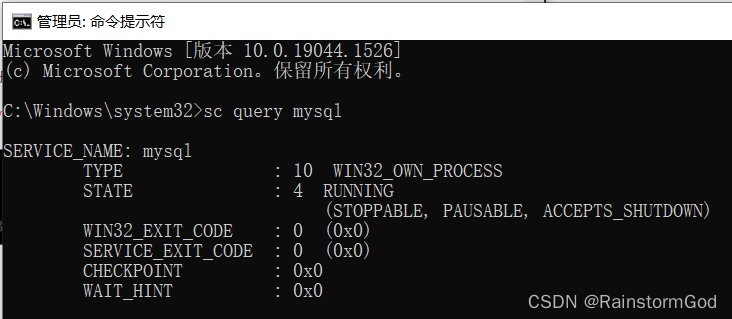
MySQL安装失败starting the sever
MySQL安装失败starting the sever 如果电脑是第一次安装MySQL,一般不会出现这样的报错。starting the sever失败,通常是因为上次安装该软件没有清除干净。 第一种解决方法:完全卸载mysql,重新安装 完全卸载该软件的办法&#…...

合并文件夹中所有文件,并输出重复的条形码值
文章目录 一、需求二、处理方式三、代码实现 一、需求 每天会生成一个记录文件(文件名按日期yyyyMMdd格式命名),记录文件中记录有条形码的内容,需要合并最近20次的数据,并提取出有重复的条形码。 也可以进行最近30天数…...

OpCore Simplify革新:4步实现OpenCore EFI配置的极简实践
OpCore Simplify革新:4步实现OpenCore EFI配置的极简实践 【免费下载链接】OpCore-Simplify A tool designed to simplify the creation of OpenCore EFI 项目地址: https://gitcode.com/GitHub_Trending/op/OpCore-Simplify 你是否曾在普通PC上安装macOS时&…...

10大好用的班组建设系统盘点!助力企业高效开展班组建设
在2026年数字化转型的深水区,班组建设系统已成为企业夯实基层管理、提升执行力的核心引擎。面对市场上琳琅满目的工具,如何筛选出真正好用的班组建设系统,切实助力企业高效开展班组建设,是管理者面临的首要难题。本文深度盘点10大…...

Hive与MySQL集成配置全流程解析
1. Hive与MySQL集成的核心价值 在企业级大数据环境中,Hive作为数据仓库工具经常需要处理PB级数据。但默认的Derby元数据库存在单会话限制和性能瓶颈,这正是MySQL大显身手的地方。我经历过多次生产环境迁移,将元数据从Derby切换到MySQL后&…...

5个技巧让文件识别效率翻倍:Magika智能检测工具深度解析
5个技巧让文件识别效率翻倍:Magika智能检测工具深度解析 【免费下载链接】magika 项目地址: https://gitcode.com/GitHub_Trending/ma/magika 还在为文件类型识别烦恼吗?传统工具常常误判,而手动检查又太耗时。让我们一起探索Magika—…...

Torch-Pruning高效剪枝实战:解决BERT模型部署中的计算资源瓶颈问题
Torch-Pruning高效剪枝实战:解决BERT模型部署中的计算资源瓶颈问题 【免费下载链接】Torch-Pruning [CVPR 2023] Towards Any Structural Pruning; LLMs / Diffusion / Transformers / YOLOv8 / CNNs 项目地址: https://gitcode.com/gh_mirrors/to/Torch-Pruning …...

3步告别卡顿:用鸣潮工具箱实现流畅游戏体验
3步告别卡顿:用鸣潮工具箱实现流畅游戏体验 【免费下载链接】WaveTools 🧰鸣潮工具箱 项目地址: https://gitcode.com/gh_mirrors/wa/WaveTools 你的游戏还在卡顿吗?试试这个免费解决方案 你是否曾经在《鸣潮》的激烈战斗中遭遇突然的…...

轴,V带轮,斜齿轮,丝杠零件图CAD图纸
轴作为机械系统中的核心传动部件,承担着传递扭矩与支撑旋转的重要功能。其设计需综合考虑材料强度、刚度及热处理工艺,以确保在复杂载荷下保持稳定运行。典型结构包含阶梯轴、空心轴等类型,通过优化轴肩定位与键槽布局,可有效提升…...

USB批量传输中ZLP的必要性:为何512字节整数倍数据包会丢失
1. USB批量传输中的ZLP到底是什么? 第一次遇到USB批量传输丢数据的问题时,我也是一头雾水。明明发送端显示数据已经成功发送,接收端却死活收不到完整数据。后来排查发现,问题出在数据包大小刚好是512字节的整数倍时。这就是我们今…...

Cursor试用限制终极解决方案:一篇文章彻底解决你的AI编程困境
Cursor试用限制终极解决方案:一篇文章彻底解决你的AI编程困境 【免费下载链接】go-cursor-help 解决Cursor在免费订阅期间出现以下提示的问题: Youve reached your trial request limit. / Too many free trial accounts used on this machine. Please upgrade to p…...

Qwen3字幕生成工具实战:快速处理会议录音,输出带时间戳字幕
Qwen3字幕生成工具实战:快速处理会议录音,输出带时间戳字幕 1. 会议录音转字幕的痛点与解决方案 处理会议录音是许多职场人士的日常任务。传统方法需要先听录音,再手动记录内容,最后还要逐句对齐时间轴,整个过程耗时…...