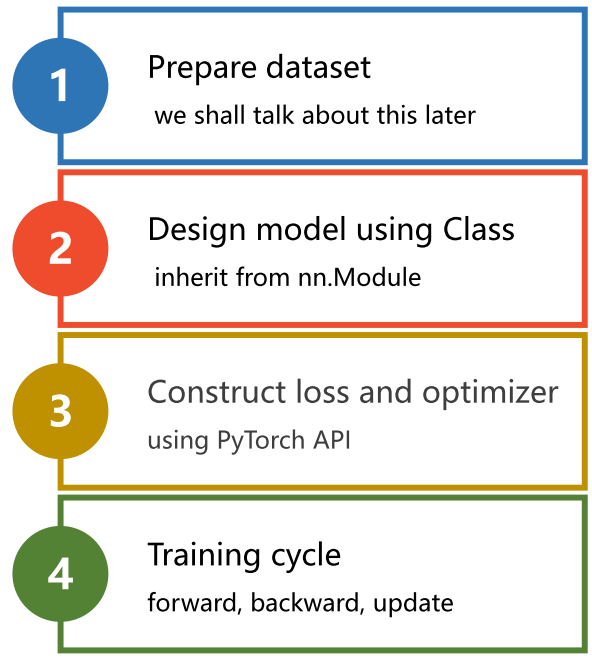
Lecture5 实现线性回归(Linear Regression with PyTorch)
目录
1 Pytorch实现线性回归
1.1 实现思路
1.2 完整代码
2 各部分代码逐行详解
2.1 准备数据集
2.2 设计模型
2.2.1 代码
2.2.2 代码逐行详解
2.2.3 疑难点解答
2.3 构建损失函数和优化器
2.4 训练周期
2.5 测试结果
3 线性回归中常用优化器
1 Pytorch实现线性回归
1.1 实现思路
1.2 完整代码
import torch
x_data = torch.Tensor([[1.0], [2.0], [3.0]])
y_data = torch.Tensor([[2.0], [4.0], [6.0]])
class LinearModel(torch.nn.Module):def __init__(self):super(LinearModel, self).__init__()self.linear = torch.nn.Linear(1, 1)def forward(self, x):y_pred = self.linear(x)return y_pred
model = LinearModel()
criterion = torch.nn.MSELoss(size_average=False)
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
for epoch in range(500):y_pred = model(x_data)loss = criterion(y_pred, y_data)print(epoch, loss.item())optimizer.zero_grad()loss.backward()optimizer.step()
print('w = ', model.linear.weight.item())
print('b = ', model.linear.bias.item())
x_test = torch.Tensor([[4.0]])
y_test = model(x_test)
print('y_pred = ', y_test.data)2 各部分代码逐行详解
2.1 准备数据集
在PyTorch中,一般需要采取mini-batch形式构建数据集,也就是把数据集定义成张量(Tensor)形式,以方便后续计算。
在下面这段代码中,x_data是个二维张量,它有3个样本,每个样本有1个特征值,即维度是 (3, 1);y_data同理。不清楚的同学可以使用 x.dim() 方法和 x.shape 属性来获取张量的维度和尺寸,自行调试。简言之,在minibatch中,行表示样本,列表示feature
import torch
x_data = torch.Tensor([[1.0], [2.0], [3.0]])
y_data = torch.Tensor([[2.0], [4.0], [6.0]])2.2 设计模型

主要目标:构建计算图
2.2.1 代码
class LinearModel(torch.nn.Module):def __init__(self):super(LinearModel, self).__init__()self.linear = torch.nn.Linear(1, 1)def forward(self, x):y_pred = self.linear(x)return y_pred
model = LinearModel()2.2.2 代码逐行详解
class LinearModel(torch.nn.Module):一般我们需要一个类,并继承自PyTorch的Module类,这是因为torch.nn.Module提供了很多有用的功能,使得我们可以更方便地定义、训练和使用神经网络模型。
接下来至少需要实现两个函数,即init和forward。
__init__方法
def __init__(self):super(LinearModel, self).__init__()self.linear = torch.nn.Linear(1, 1)该方法对模型的参数进行初始化。
在super(LinearModel, self).__init__() 中,第一个参数 LinearModel 指定了查找的起点,即在 LinearModel 类的父类中查找;第二个参数 self 指定了当前对象,即调用该方法的对象。该语句的作用是调用 LinearModel 的父类 torch.nn.Module 的 __init__ 方法,并对父类的属性进行初始化。这是初始化模型的一个必要语句。
接下来将一个torch.nn.Linear对象实例化并赋值给self.linear属性。torch.nn.Linear 的构造函数接收三个参数:in_features 、 out_features、bias,分别代表输入特征的数量、输出特征的数量和偏置量。

forward方法
def forward(self, x):y_pred = self.linear(x)return y_predforward()方法作用是进行前馈运算,相当于计算。
注意这里相当于是重写了torch.nn.Linear 类中的forward方法。在我们重写forward后,函数将会执行的过程如下:

y_pred = self.linear(x) 的作用是将输入 x 传入全连接层进行线性变换,得到输出 y_pred。
最后通过实例化LinearModel类来调用模型
model = LinearModel()2.2.3 疑难点解答
1、可能你会有疑问,代码中的backward过程体现在哪呢?
答:torch.nn.Module类构造出的对象会自动完成backward过程。Module 类及其子类在前向传递时会自动构建计算图,并在反向传播(backward)时自动进行梯度计算和参数更新。比如self.linear=torch.nn.Linear(1, 1),
这里的linear属性得到Linear类的实例后,相当于继承自Module,所以它也会自动进行backward,就无须我们再手动求导了。
2、y_pred = self.linear(x) 中,linear为什么后面可以直接跟括号呢?
这里涉及到了python语法中的可调用对象(Callable Object)知识点。在self.linear后面加括号,相当于直接在对象上加括号,相当于实现了一个可调用对象。
self.linear = torch.nn.Linear(1, 1)中,相当于我们创建了一个Module对象,因为nn.Linear类继承自nn.Module类。
接着我们执行了y_pred = self.linear(x)这段代码,相当于我们调用了Moudle 类的 __call__ 方法。
于是nn.Module类的__call__方法又会进一步去自动调用模块的forward方法。
举个例子:
class Adder:def __init__(self, n):self.n = ndef __call__(self, x):return self.n + xadd5 = Adder(5)
print(add5(3)) # 输出 8
在这个例子中,我们定义了一个 Adder 类,它接受一个参数 n,并且实现了 __call__ 方法。当我们创建 add5 对象时,实际上是创建了一个 Adder 对象,并且把参数 n 设置为 5。当我们调用 add5 对象时,实际上是调用了 Adder 对象的 __call__ 方法,
通过实现 __call__ 方法,我们可以让对象像函数一样被调用,这在一些场景下很有用,例如,我们可以用它来实现一个状态机、一个闭包或者一个装饰器等。
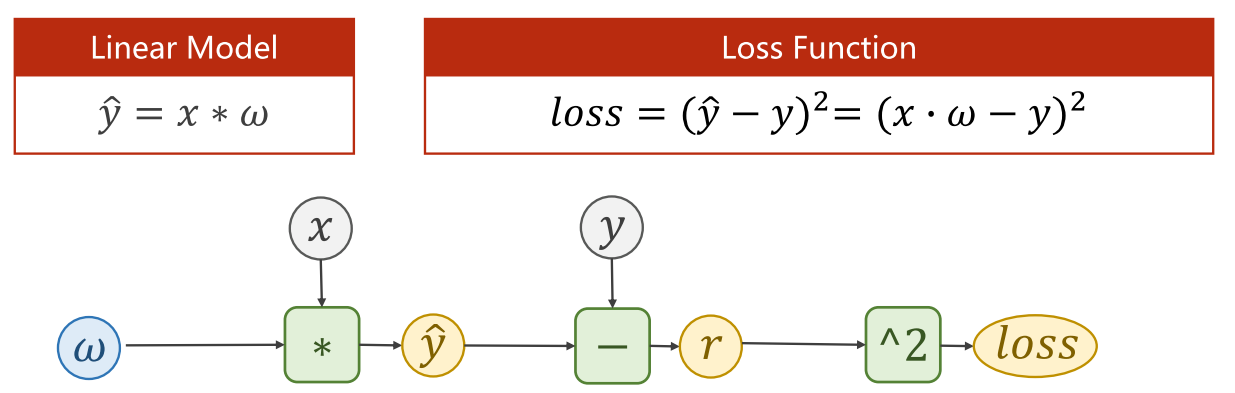
3、权重体现在哪?forward里面好像没涉及到权重值的传入?
这里 self.linear 实际上是一个 PyTorch 模块(Module),包含了权重矩阵和偏置向量,于是我们便可以用这个对象来完成下图所示计算


那么权重是怎么传入forward中的呢?
在torch.nn.Linear类的构造函数__init__中,它会自动创建一个nn.Parameter对象,用于存储权重,并将其注册为模型的可学习参数(Learnable Parameter)。
这个nn.Parameter对象的创建代码位于nn.Linear类的__init__函数中的这一行:
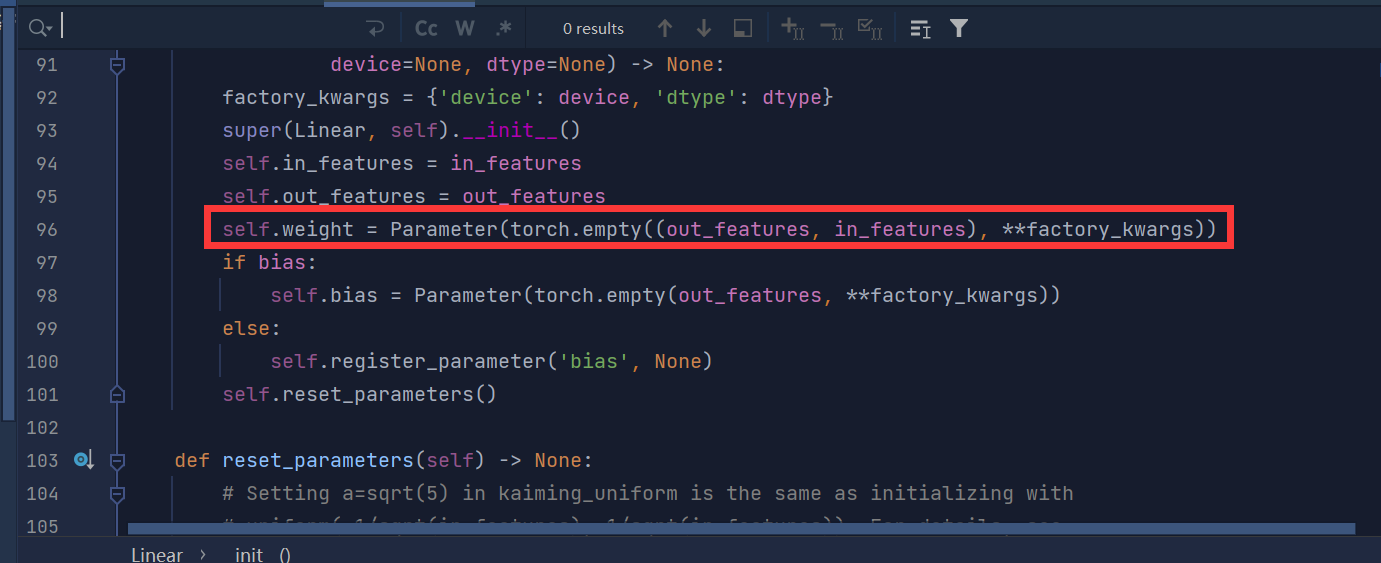
因此,self.linear中的weight属性实际上是从nn.Parameter对象中获取的。在forward方法中,self.linear会自动获取到它的weight属性,并用它来完成矩阵乘法的操作。
2.3 构建损失函数和优化器
criterion = torch.nn.MSELoss(size_average=False)
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
torch.nn.MSELoss 是一个均方误差损失函数,用于计算模型输出与真实值之间的差异,即MSE。其中,size_average 参数指定是否对损失求均值,默认为 True,即求平均值。在这个例子中,size_average=False 意味着我们希望得到所有样本的平方误差之和。

torch.optim.SGD 是随机梯度下降优化器,用于更新神经网络中的参数。其中,model.parameters() 对神经网络中的参数进行优化,它会检查所有成员,告诉优化器需要更新哪些参数。在反向传播时,优化器会通过这些参数计算梯度并对其进行更新。lr 参数表示学习率,即每次参数更新的步长。在这个例子中,我们使用随机梯度下降作为优化器,学习率为 0.01。最后我们得到了一个优化器对象optimizer。
2.4 训练周期
for epoch in range(500): # 训练500轮y_pred = model(x_data) # 前向计算loss = criterion(y_pred, y_data) # 计算损失print(epoch, loss.item()) # 打印损失值optimizer.zero_grad() # 梯度清零,不清零梯度的结果就变成这次的梯度+原来的梯度loss.backward() # 反向传播optimizer.step() # 更新权重2.5 测试结果
循环迭代进行训练500轮。
# Output weight and bias
print('w = ', model.linear.weight.item())
print('b = ', model.linear.bias.item())
# Test Model
x_test = torch.Tensor([[4.0]])
y_test = model(x_test)
print('y_pred = ', y_test.data)输出结果部分截图:
0 23.694297790527344
1 10.621758460998535
2 4.801174163818359
3 2.208972215652466
4 1.0539695024490356
5 0.5387794971466064
6 0.3084312379360199
7 0.20490160584449768
8 0.1578415036201477
9 0.13593381643295288
10 0.12523764371871948
11 0.1195460706949234
12 0.11609543859958649···
494 0.00010695526725612581
495 0.00010541956726228818
496 0.00010390445095254108
497 0.00010240855044685304
498 0.00010094392928294837
499 9.949218656402081e-05
w = 1.993359923362732
b = 0.015094676986336708
y_pred = tensor([[7.9885]])Process finished with exit code 0
总之,求yhat,求loss,然后backward,最后更新权重
3 线性回归中常用优化器
• torch.optim.Adagrad
• torch.optim.Adam
• torch.optim.Adamax
• torch.optim.ASGD
• torch.optim.LBFGS
• torch.optim.RMSprop
• torch.optim.Rprop
• torch.optim.SGD
阅读官方教程的更多示例:
Learning PyTorch with Examples — PyTorch Tutorials 1.13.1+cu117 documentation
相关文章:
Lecture5 实现线性回归(Linear Regression with PyTorch)
目录 1 Pytorch实现线性回归 1.1 实现思路 1.2 完整代码 2 各部分代码逐行详解 2.1 准备数据集 2.2 设计模型 2.2.1 代码 2.2.2 代码逐行详解 2.2.3 疑难点解答 2.3 构建损失函数和优化器 2.4 训练周期 2.5 测试结果 3 线性回归中常用优化器 1 Pytorch实现线性回归…...

Python与Matlab svd分解的差异
1.差异说明 Matlab和Python的NumPy库中的SVD函数(np.linalg.svd)都是用来对矩阵进行奇异值分解(SVD)的函数,但它们在默认参数和返回结果方面有一些差异。 在Matlab中,SVD函数的默认行为是计算矩阵的完整SVD,即对于一…...

2023年光模块行业发展趋势及未来前景
随着数字化时代的到来,互联网行业的快速发展,网络通信设备行业的发展也在逐渐加速。光模块作为网络设备的重要组成部分,也在不断创新和发展。那么,光模块行业的未来发展趋势又是怎样的呢?接下来就跟着易天光通信&#…...

Sysmac Studio使用Tortoise和Git实现版本控制
Sysmac Studio使用Tortoise和Git实现版本控制实验时间:2022/11/16 实验软件:Sysmac Studio(1.52,需要软件授权支持版本控制)、Git(2.38.1)、Tortoise(2.13.0)、gitee(代码仓库) 实验目的:Sysmac Studio实现版本控制、多人同时开…...

Intent 和 Bundle 传值的区别
文章目录1、使用上1.1 Intent 方式1.2 Bundle 方式2、为什么 Bundle 使用 ArrayMap 而不是 Hashmap 实现呢?1、使用上 1.1 Intent 方式 举例:将数据从页面 A 传递到 B,然后再传递到 CA 页面: Intent intentnew Intent(MainActi…...

TypeScript 初步
一、TypeScript是什么? Typed JavaScript at Any Scale: 添加了类型系统的JavaScript,使用于任何规模的项目。 两个重要特点: 类型系统 任何规模 中文官网:文档简介 TypeScript中文网 TypeScript——JavaScript的超集 TypeS…...
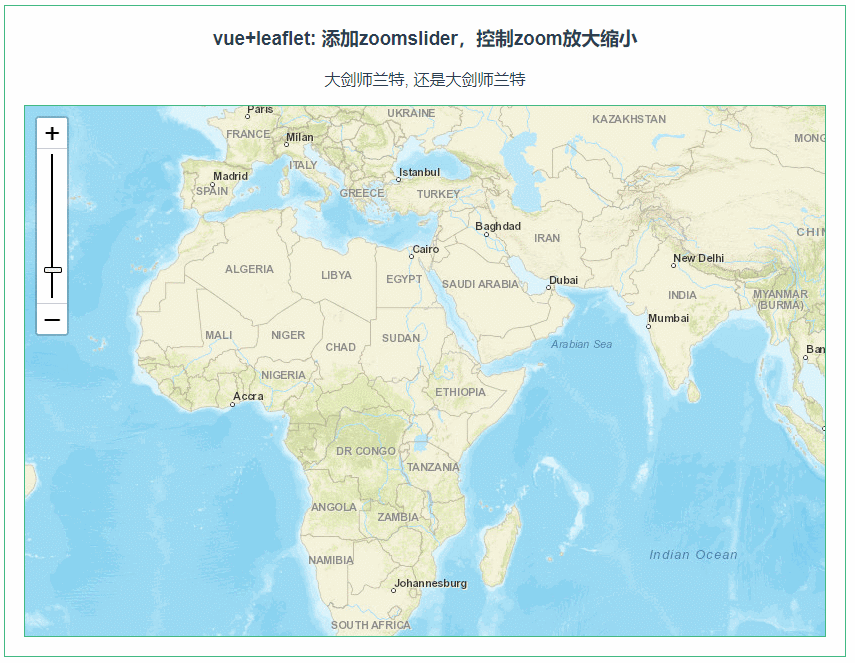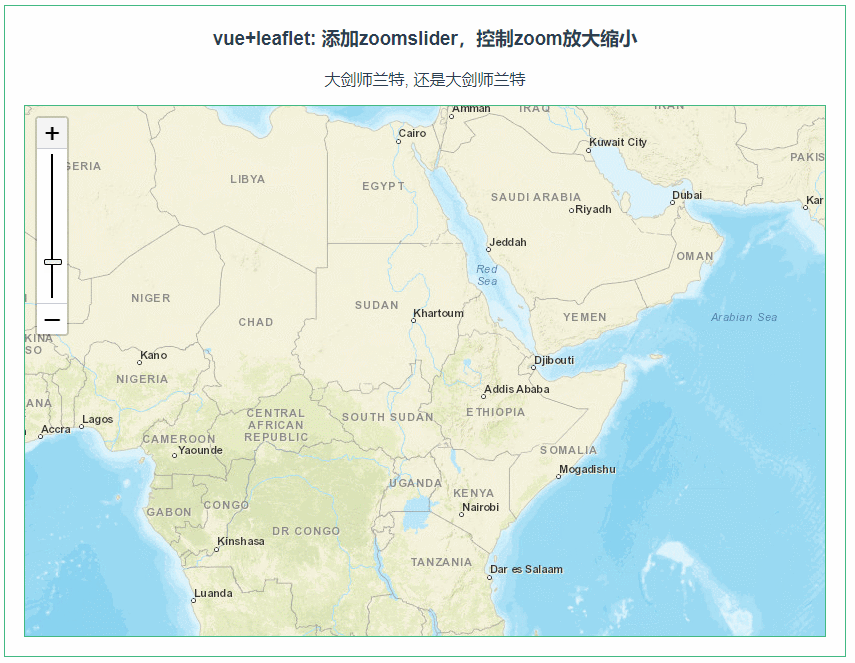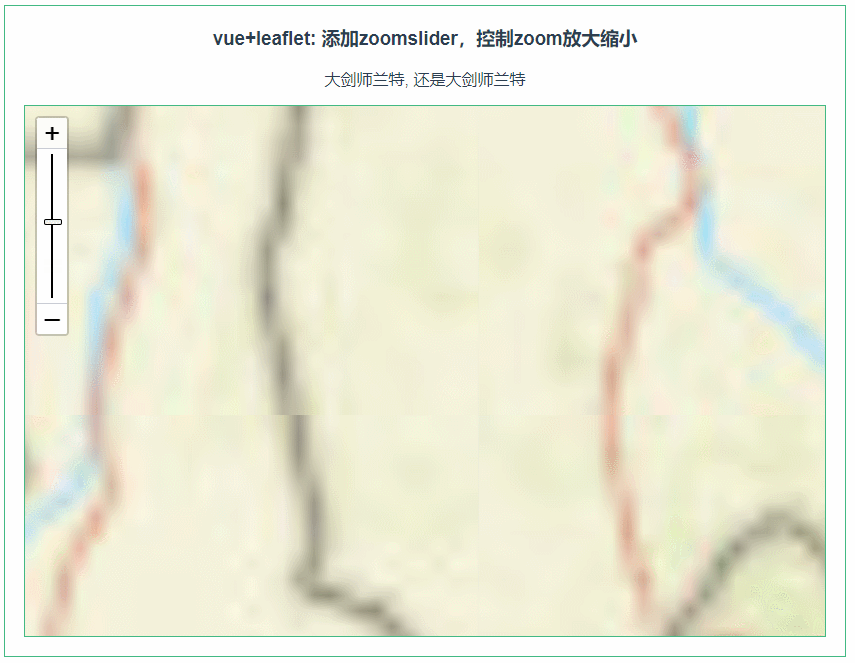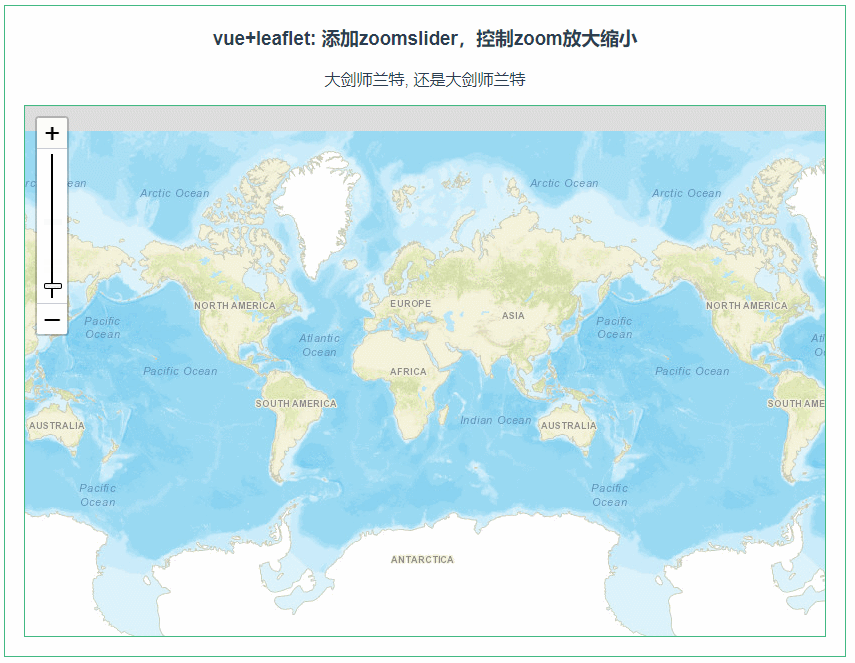
leaflet 添加zoomslider,控制zoom放大缩小(074)
第074个 点击查看专栏目录 本示例的目的是介绍演示如何在vue+leaflet中使用zoomslider,相比于普通的zoom控件,这个更加形象,更加具体些。 直接复制下面的 vue+leaflet源代码,操作2分钟即可运行实现效果 文章目录 示例效果配置方式示例源代码(共65行)相关API参考:专栏目…...

10分钟学会python对接【OpenAI API篇】
今天学习 OpenAI API,你将能够访问 OpenAI 的强大模型,例如用于自然语言的 GPT-3、用于将自然语言翻译为代码的 Codex 以及用于创建和编辑原始图像的 DALL-E。 首先获取生成 API 密钥 在我们开始使用 OpenAI API 之前,我们需要登录我们的 Op…...

2023美赛必须注意事项
文章目录首页部分要求竞赛期间题目查看题目下载论文要求比赛提示控制号提交解决方案更多注意事项首页部分要求 具体如下: 我提取一些关键词如下: 第一页:摘要页字体要求:12点的 Times New Roman 字体请勿在此页面或任何页面上…...
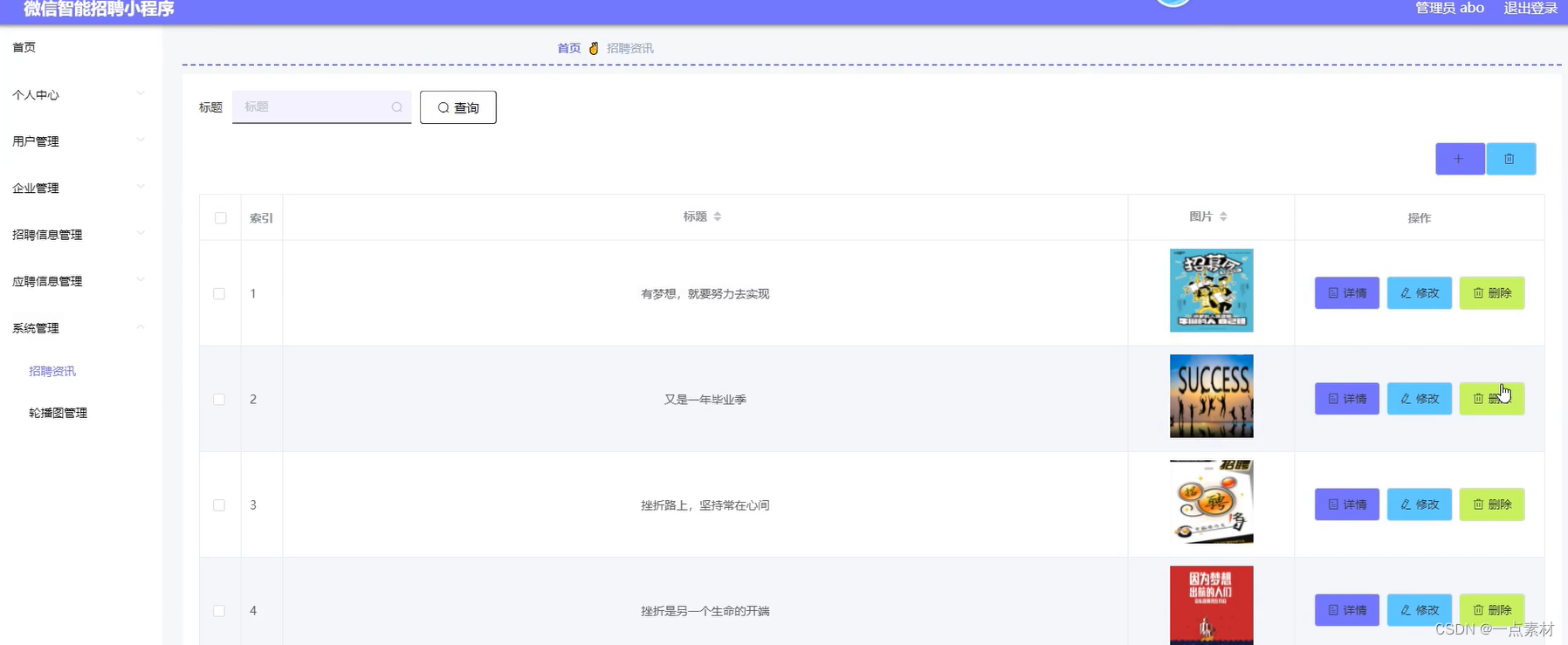
基于微信小程序的智能招聘小程序
文末联系获取源码 开发语言:Java 框架:ssm JDK版本:JDK1.8 服务器:tomcat7 数据库:mysql 5.7/8.0 数据库工具:Navicat11 开发软件:eclipse/myeclipse/idea Maven包:Maven3.3.9 浏览器…...

Java文件操作和I/O
Java 流(Stream)、文件(File)和IOJava.io 包几乎包含了所有操作输入、输出需要的类。所有这些流类代表了输入源和输出目标。Java.io 包中的流支持很多种格式,比如:基本类型、对象、本地化字符集等等。一个流可以理解为一个数据的序列。输入流表示从一个源…...
QT项目_RPC(进程间通讯)
QT项目_RPC(进程间通讯) 前言: 两个进程间通信、或是说两个应用程序之间通讯。实际情况是在QT开发的一个项目中,里面包含两个子程序,子程序有单独的界面和应用逻辑,这两个子程序跑起来之后需要一些数据的交互,例如&…...

移动硬盘文件丢失怎么恢复?
在我们的日常工作、学习和生活都离不开各种数据。每天都会接收或处理各种数据,尤其是做设计、自媒体、多媒体设计的人。移动硬盘成为我们常备的存储工具,但有使用就会伴随着意外情况的发生,这将导致移动硬盘上数据的丢失,比如误删…...
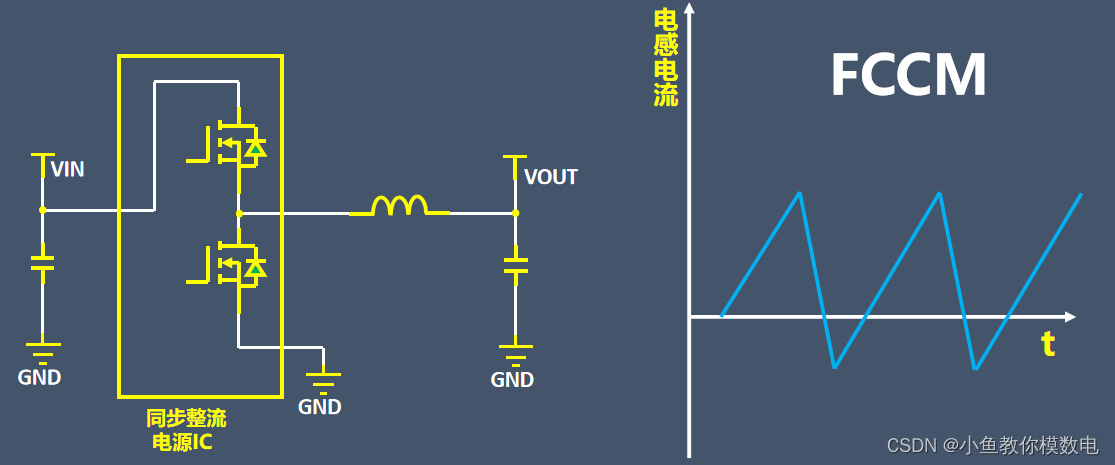
什么是同步整流和异步整流
在设计降压型DCDC电路的时候,经常会听到同步整流(synchronous)和异步整流(asynchronous)。那么什么是同步整流,什么是异步整流呢从这两种电路的拓扑来看,异步整流型外围有一个续流二极管&#x…...

关于PYTHON Enclosing 的一个小问题
问题分析 以下是一段每隔半小时重复执行测试用例的脚本,func是传入的测试函数,在执行func前后,会打印操作次数 def repeat(func, action):try:log.info(u******开始并发%s****** % action)thread_list []for i in range(repeat_count):def…...

LabVIEW错误-2147220623:最大内存块属性不存在
LabVIEW错误-2147220623:最大内存块属性不存在在使用NI Linux实时操作系统目标中,使用系统属性节点和分布式系统管理器(DSM),但遇到一些问题:它未正确报告系统上的可用物理内存量。在NI Linux实时系统上出现…...

图的总复习
一、图的定义Graph 图是由顶点vertex集合及顶点间关系集合组成的一种数据结构: 顶点的集合 和 边的集合 二、无向图 用(x,y)表示两个顶点x和y之间的一条边(edge) 边是无方向的 N{V,E},V{0…...

测试流程记录
1,需求评审 2,技术方案评审 3,编写测试用例 编写需求分析 编写测试用例 编写冒烟case 4,用例评审 5,提测 提测前给开发执行冒烟case 6,测试 测试完成前约产品验收时间 7,验收 跟进验收问题…...

Mysql主从架构与实例
mysql的主从架构 MySQL主从架构是一种常见的数据库高可用性解决方案,它通常由一个主数据库和多个从数据库组成。主数据库用于处理写入请求和读取请求,从数据库则用于处理只读请求。 在主从架构中,主数据库记录所有数据更改并将这些更改同步…...

webpack(高级)--Tapable
webpack 我们直到webpack中有两个非常重要的类Compiler和Compilation 他们通过注入插件的方式 来监听webpack的所有声明周期 插件的注入是通过创建Tapable库中的各种Hook的实例来得到 Tapable Tapable中的Hook分为同步与异步 同步 SyncHook SyncBailHook SyncWaterfallHook…...

别埋头苦选了!用对方法,俄罗斯的爆款就是你的货源!
标题建议(任选其一):🔥 扒光了同行底裤:跨境电商“无货源拿货”的顶级神操作,原来他们都在这么干!别再傻乎乎囤货了!一张图看懂“Ozon爆品 ➡️ 1688源头”的极速变现闭环。跨境圈不…...
)
云计算Linux——nginx httpd后端 配置 反向代理(十二)
一、反向代理核心原理与作用补充: 正向代理: VPN 反向代理: 访问网站(动态任务)1.什么是反向代理?反向代理是服务器端的代理。客户端访问反向代理服务器,由代理服务器将请求转发给后 端真实服务器…...

优化敏感焦虑型依恋
用几个学科的顶层思维,把你的问题重新教育一遍:你不是要“变得迟钝”,你是要完成一次升级:从“敏感地寻找危险”,升级为“敏锐地识别规律”。 从“害怕失去关系”,升级为“有能力经营关系”。 从“被情绪牵…...
3分钟让Windows任务栏焕然一新:TranslucentTB场景化配置全攻略
3分钟让Windows任务栏焕然一新:TranslucentTB场景化配置全攻略 【免费下载链接】TranslucentTB A lightweight utility that makes the Windows taskbar translucent/transparent. 项目地址: https://gitcode.com/gh_mirrors/tr/TranslucentTB 厌倦了Windows…...

ChatterUI本地模式深度解析:在移动设备上运行LLM的完整指南
ChatterUI本地模式深度解析:在移动设备上运行LLM的完整指南 【免费下载链接】ChatterUI Simple frontend for LLMs built in react-native. 项目地址: https://gitcode.com/gh_mirrors/ch/ChatterUI ChatterUI是一款基于React Native构建的轻量级LLM前端应用…...

Yeti社区插件生态解析:如何利用现有资源快速扩展平台功能
Yeti社区插件生态解析:如何利用现有资源快速扩展平台功能 【免费下载链接】yeti Your Everyday Threat Intelligence 项目地址: https://gitcode.com/gh_mirrors/ye/yeti Yeti作为一款强大的威胁情报平台(Your Everyday Threat Intelligence&…...

CANN/ops-nn自适应平均池化3D反向计算
aclnnAdaptiveAvgPool3dBackward 【免费下载链接】ops-nn 本项目是CANN提供的神经网络类计算算子库,实现网络在NPU上加速计算。 项目地址: https://gitcode.com/cann/ops-nn 产品支持情况 📄 查看源码 产品是否支持Ascend 950PR/Ascend 950DT√…...

Ascend NPU高效无损压缩技术解析与优化
1. 项目概述:Ascend NPU上的高效无损压缩技术在AI模型规模爆炸式增长的今天,模型权重的存储与传输已成为系统瓶颈。以Qwen3-32B模型为例,其65.6GB的权重文件在分布式训练中会产生显著的通信开销。传统CPU/GPU压缩方案如ZipNN(1.5GB/s)和NV-Bi…...

大跨度异型电动挡烟垂壁技术研发与工程应用研究
当前商业综合体、交通枢纽、会展场馆、大型厂房普遍采用大跨度、异形挑空设计,按消防规范需设置挡烟垂壁划分防烟分区,控制烟气蔓延。常规直线型、小跨度挡烟垂壁存在易变形、异型适配差、漏烟、运行不稳、验收难等问题,大跨度异型电动挡烟垂…...

如何用AI技术5分钟搞定视频硬字幕提取?这个开源工具让你轻松生成SRT字幕文件
如何用AI技术5分钟搞定视频硬字幕提取?这个开源工具让你轻松生成SRT字幕文件 【免费下载链接】video-subtitle-extractor 视频硬字幕提取,生成srt文件。无需申请第三方API,本地实现文本识别。基于深度学习的视频字幕提取框架,包含…...