【LLM】金融大模型场景和大模型Lora微调实战
文章目录
- 一、金融大模型背景
- 二、大模型的研究问题
- 三、大模型技术路线
- 四、LLaMA家族模型
- 五、Lora模型微调的原理
- 六、大模型Lora微调实战
- Reference
一、金融大模型背景
- 金融行业需要垂直领域LLM,因为存在金融安全和数据大多数存储在本地,在风控、精度、实时性有要求
- (1)500亿参数的BloombergGPT
- BloombergGPT金融大模型也是用transformer架构,用decoder路线, 构建目前规模最大的金融数据集FINPILE,对通用文本+金融知识的混合训练。
- 用了512块40GB的A100 GPU,训练中备份了4个模型,每个模型分了128块GPU。
- (2)度小满5月的【源轩大模型】
- 使用hybrid-tuning方式,首个千亿参数金融大模型
- 在通用能力评测中,轩辕有10.2%的任务表现超越ChatGPT 3.5, 61.22%的任务表现与之持平,涉及数学计算、场景写作、逻辑推理、文本摘要等13个主要维度。
- 金融大模型GPT落地场景:
- 新闻情感分类 ——> 金融机构判断对某事件看法,辅助量化策略、投资决策
- 财务类知识问答 ——> 辅助金融机构进行信用评估,筛选概念股,辅助分析师对专业领域的学习
- 财务报表分析和会计稽查 ——> 生成财务分析报告和招股书,辅助会计和审计
二、大模型的研究问题
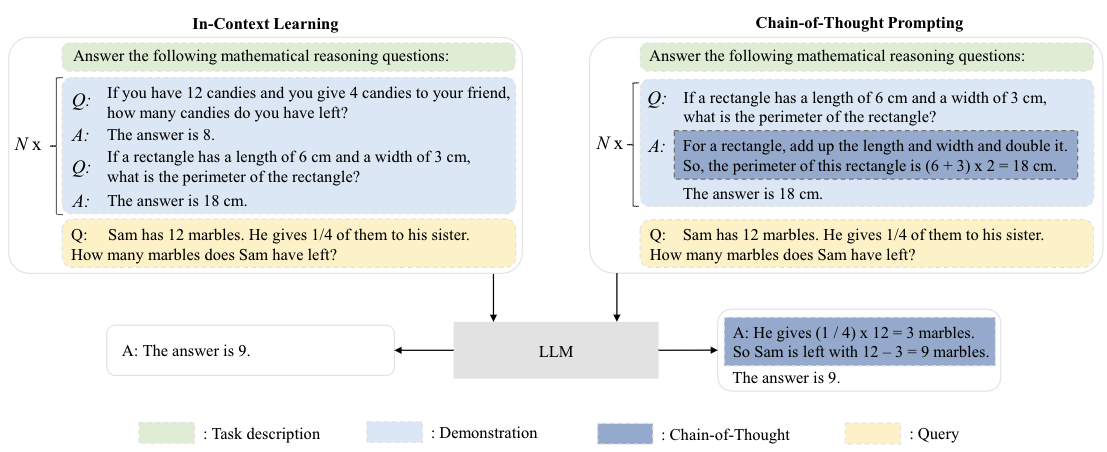
- LLM的理论基础:
- 如Few/Zero-Shot Learning、In-Context Learning、Chain-of-Thought能力;
- zero-shot是模型训练中没有接触过这个类别的样本,但仍能对没见过的类别进行分类;few-shot是每个类别中只有少量样本,希望模型学习一定类别的大量数据后,对于新类别的少量样本数据能快速学习。few-show是meta-learning的一种。
- 网络架构:transformer架构,括分词、归一化方法、归一化位置、位置编码、注意力与偏置等常见模块。是否有比transformer更好的架构,如有学者受到数学相关方向的启发,提出非欧空间Manifold网络框架。
- 大模型的高效计算:模型并行、tensor卸载、优化器卸载等,微软的deepspeed等工具
- 推理效率:模型剪枝、知识蒸馏、参数量化等
- 大模型的高效适配下游任务:
- prompt learning提示学习:如指令微调
- 参数高效微调:只调整大模型里的少量参数
- 大模型的可控生成:通过指令微调、提示工程、思维链、RLHF等控制模型生成
- 伦理问题:RLHF、RLAIF等对齐方法提高生成质量
- 模型评估:专业考题进行评测、更强的模型给小模型打分、人工评测等
三、大模型技术路线
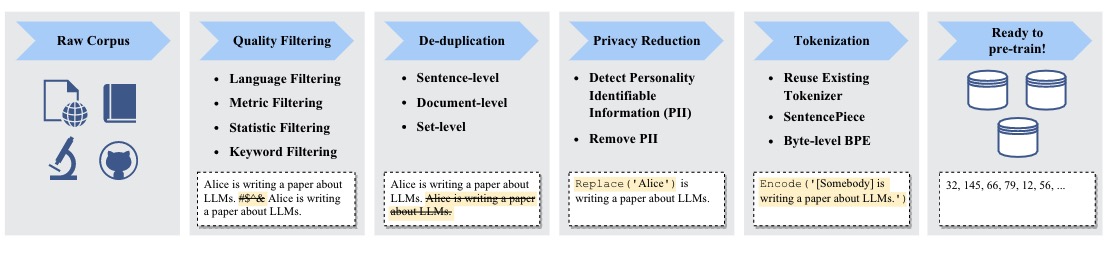
- Hugging Face 的 PEFT是一个库(LoRA 是其支持的技术之一,除此之外还有Prefix Tuning、P-Tuning、Prompt Tuning),可以让你使用各种基于 Transformer 结构的语言模型进行高效微调。
- AIpaca羊驼:让 OpenAI 的 text-davinci-003 模型以 self-instruct 方式生成 52K 指令遵循(instruction-following)样本,以此作为 Alpaca 的训练数据,最后训练的羊驼只有7B参数量。可以使用LoRA微调优化。
- LLM技术思路:
- 语言模型:llama、bloom、glm等
- 指令微调数据:alpaca_data、bella_data、guanaco_data等。目前指令微调数据上,很依赖alpaca以及chatgpt的self-instruct数据。数据处理参考上图
- 微调加速: lora(如Alpaca-Lora)等,还可以使用peft库、量化工具包bitsandbytes、deepspeed(先读
torch.distributed和ColossalAI再搞)、llama.cpp量化模型。在LoRA方法提出之前,也有很多方法尝试解决大模型微调困境的方法。其中有两个主要的方向:- 添加adapter层。adapter就是固定原有的参数,并添加一些额外参数用于微调;
- 由于某种形式的输入层激活。
- 训练优化方法:量化、3D并行、cpu卸载
四、LLaMA家族模型
五、Lora模型微调的原理
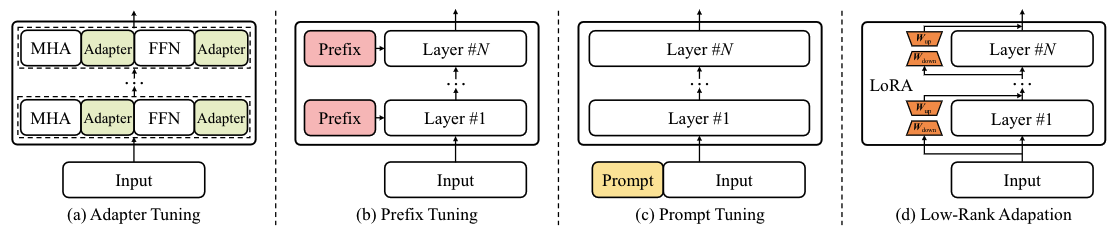
- prompt的本质是参数有效性学习(parameter-efficient learning, PEL),因为PLM全量参数更新训练耗时,而在参数有效性学习中,大模型只需指定或额外加入少量的可训练参数,冻结其他参数,提高训练效率和保证质量

- Lora低秩自适应,low-rank adaption,额外引入了可训练的低秩分解矩阵,同时固定预训练权重。通过反向传播学习分解的矩阵,将适应任务的新权重矩阵分解为低维(较小)矩阵,而不会丢失太多信息。
- 可以将新的lora权重矩阵与原始预训练权重合并,在推理中不会产生额外的开销;如上图所示,左边是预训练模型的权重,输入输出维度都是d,在训练时被冻结参数,右边对A使用随机的高斯初始化,B在训练初始为0。一个预训练的权重矩阵,使用低秩分解来表示,初始时△W=BA: h = W 0 x + Δ W x = W 0 x + B A x h=W_0 x+\Delta W x=W_0 x+B A x h=W0x+ΔWx=W0x+BAx
- LoRA原理:即在大型语言模型上对指定参数增加额外的低秩矩阵,并在模型训练过程中,仅训练而外增加的参数。当“秩值”远小于原始参数维度时,新增的低秩矩阵参数量很小,达到仅训练很小的参数,就能获取相应结果。
- 冻结预训练模型权重,并将可训练的秩分解矩阵注入到Transformer层的每个权重中,大大减少了下游任务的可训练参数数量。实际上是增加了右侧的“旁支”,也就是先用一个Linear层A,将数据从 d维降到r,再用第二个Linear层B,将数据从r变回d维。最后再将左右两部分的结果相加融合,得到输出的
hidden_state。
- 评价LLM生成文本的指标:困惑度、BLEU 和 ROUGE等
- Alpaca-Lora:基于LLaMA(7B)微调
项目链接:https://github.com/tloen/alpaca-lora
权重地址:https://huggingface.co/decapoda-research/llama-7b-hf- 项目诞生原因:Stanford Alpaca羊驼 是在 LLaMA 整个模型上微调,即对预训练模型中的所有参数都进行微调(full fine-tuning)。但该方法对于硬件成本要求仍然偏高且训练低效。LLaMA没有经过指令微调,生成效果较差
- 因此,Alpaca-Lora:利用 Lora 技术,在冻结原模型 LLaMA 参数的情况下,通过往模型中加入额外的网络层,并只训练这些新增的网络层参数。由于这些新增参数数量较少,这样不仅微调的成本显著下降(使用一块 RTX 4090 显卡,只用 5 个小时就训练了一个与 Alpaca 水平相当的模型,将这类模型对算力的需求降到了消费级),还能获得和全模型微调(full fine-tuning)类似的效果。
- 将LLaMA原始转钟转为transformers库对应的模型文件格式(也可以直接从huggingface上下载转好的模型,参考)
- 用LoRA(Low-rank Adaptation)微调模型、模型推理
- 将 LoRA 权重合并回基础模型以导出为 HuggingFace 格式和 PyTorch state_dicts。以帮助想要在 llama.cpp 或 alpaca.cpp 等项目中运行推理的用户
六、大模型Lora微调实战
- 下面以mt0-large模型进行lora为例:
- 选用金融领域情感分析任务
financial_sentiment_analysis,给定一个句子,要求识别出该句子是negative、positive还是neutral三个中的哪一个 - 下面借助
peft库(Parameter-Efficient Fine-Tuning)进行微调,支持如下tuning:- Adapter Tuning(固定原预训练模型的参数 只对新增的adapter进行微调)
- Prefix Tuning(在输入token前构造一段任务相关的virtual tokens作为prefix,训练时只更新Prefix不分的参数,而Transformer的其他不分参数固定,和构造prompt类似,只是prompt是人为构造的即无法在模型训练时更新参数,而Prefix可以学习<隐式>的prompt)
- Prompt Tuning(Prefix Tuning的简化版,只在输入层加入prompt tokens,并不需要加入MLP)
- P-tuning(将prompt转为可学习的embedding层,v2则加入了prompts tokens作为输入)
- LoRA(Low-Rank Adaption,为了解决adapter增加模型深度而增加模型推理时间、上面几种tuning中prompt较难训练,减少模型的可用序列长度)
- 该方法可以在推理时直接用训练好的AB两个矩阵和原预训练模型的参数相加,相加结果替换原预训练模型参数。
- 相当于用LoRA模拟full-tunetune过程
# !/usr/bin/python
# -*- coding: utf-8 -*-
"""
@Author : guomiansheng
@Software : Pycharm
@Contact : 864934027@qq.com
@File : main.py
"""
from transformers import AutoModelForSeq2SeqLM
from peft import get_peft_config, get_peft_model, get_peft_model_state_dict, LoraConfig, TaskType
import torch
from datasets import load_dataset
import os
os.environ["TOKENIZERS_PARALLELISM"] = "false"
from transformers import AutoTokenizer
from torch.utils.data import DataLoader
from transformers import default_data_collator, get_linear_schedule_with_warmup
from tqdm import tqdm
from datasets import load_datasetdef train_model():# device = "cuda"device = "mps"model_name_or_path = "bigscience/mt0-large"tokenizer_name_or_path = "bigscience/mt0-large"checkpoint_name = "financial_sentiment_analysis_lora_v1.pt"text_column = "sentence"label_column = "text_label"max_length = 128lr = 1e-3num_epochs = 3batch_size = 8# 搭建modelpeft_config = LoraConfig(task_type=TaskType.SEQ_2_SEQ_LM, inference_mode=False, r=8, lora_alpha=32,lora_dropout=0.1)model = AutoModelForSeq2SeqLM.from_pretrained(model_name_or_path)model = get_peft_model(model, peft_config)model.print_trainable_parameters()# 加载数据dataset = load_dataset("financial_phrasebank", "sentences_allagree")dataset = dataset["train"].train_test_split(test_size=0.1)dataset["validation"] = dataset["test"]del dataset["test"]classes = dataset["train"].features["label"].namesdataset = dataset.map(lambda x: {"text_label": [classes[label] for label in x["label"]]},batched=True,num_proc=1,)# 训练数据预处理tokenizer = AutoTokenizer.from_pretrained(model_name_or_path)def preprocess_function(examples):inputs = examples[text_column]targets = examples[label_column]model_inputs = tokenizer(inputs, max_length=max_length, padding="max_length", truncation=True,return_tensors="pt")labels = tokenizer(targets, max_length=3, padding="max_length", truncation=True, return_tensors="pt")labels = labels["input_ids"]labels[labels == tokenizer.pad_token_id] = -100model_inputs["labels"] = labelsreturn model_inputsprocessed_datasets = dataset.map(preprocess_function,batched=True,num_proc=1,remove_columns=dataset["train"].column_names,load_from_cache_file=False,desc="Running tokenizer on dataset",)train_dataset = processed_datasets["train"]eval_dataset = processed_datasets["validation"]train_dataloader = DataLoader(train_dataset, shuffle=True, collate_fn=default_data_collator, batch_size=batch_size, pin_memory=True)eval_dataloader = DataLoader(eval_dataset, collate_fn=default_data_collator, batch_size=batch_size, pin_memory=True)# 设定优化器和正则项optimizer = torch.optim.AdamW(model.parameters(), lr=lr)lr_scheduler = get_linear_schedule_with_warmup(optimizer=optimizer,num_warmup_steps=0,num_training_steps=(len(train_dataloader) * num_epochs),)# 训练和评估model = model.to(device)for epoch in range(num_epochs):model.train()total_loss = 0for step, batch in enumerate(tqdm(train_dataloader)):batch = {k: v.to(device) for k, v in batch.items()}outputs = model(**batch)loss = outputs.losstotal_loss += loss.detach().float()loss.backward()optimizer.step()lr_scheduler.step()optimizer.zero_grad()model.eval()eval_loss = 0eval_preds = []for step, batch in enumerate(tqdm(eval_dataloader)):batch = {k: v.to(device) for k, v in batch.items()}with torch.no_grad():outputs = model(**batch)loss = outputs.losseval_loss += loss.detach().float()eval_preds.extend(tokenizer.batch_decode(torch.argmax(outputs.logits, -1).detach().cpu().numpy(),skip_special_tokens=True))eval_epoch_loss = eval_loss / len(eval_dataloader)eval_ppl = torch.exp(eval_epoch_loss)train_epoch_loss = total_loss / len(train_dataloader)train_ppl = torch.exp(train_epoch_loss)print(f"{epoch=}: {train_ppl=} {train_epoch_loss=} {eval_ppl=} {eval_epoch_loss=}")# 保存模型peft_model_id = f"{model_name_or_path}_{peft_config.peft_type}_{peft_config.task_type}"model.save_pretrained(peft_model_id)def inference_model():# device = "cuda"device = "mps"model_name_or_path = "bigscience/mt0-large"tokenizer_name_or_path = "bigscience/mt0-large"checkpoint_name = "financial_sentiment_analysis_lora_v1.pt"text_column = "sentence"label_column = "text_label"max_length = 128lr = 1e-3num_epochs = 3batch_size = 8# 搭建modelpeft_config = LoraConfig(task_type=TaskType.SEQ_2_SEQ_LM, inference_mode=False, r=8, lora_alpha=32,lora_dropout=0.1)model = AutoModelForSeq2SeqLM.from_pretrained(model_name_or_path)model = get_peft_model(model, peft_config)model.print_trainable_parameters()# 加载数据dataset = load_dataset("financial_phrasebank", "sentences_allagree")dataset = dataset["train"].train_test_split(test_size=0.1)dataset["validation"] = dataset["test"]del dataset["test"]classes = dataset["train"].features["label"].namesdataset = dataset.map(lambda x: {"text_label": [classes[label] for label in x["label"]]},batched=True,num_proc=1,)# 训练数据预处理tokenizer = AutoTokenizer.from_pretrained(model_name_or_path)def preprocess_function(examples):inputs = examples[text_column]targets = examples[label_column]model_inputs = tokenizer(inputs, max_length=max_length, padding="max_length", truncation=True,return_tensors="pt")labels = tokenizer(targets, max_length=3, padding="max_length", truncation=True, return_tensors="pt")labels = labels["input_ids"]labels[labels == tokenizer.pad_token_id] = -100model_inputs["labels"] = labelsreturn model_inputsprocessed_datasets = dataset.map(preprocess_function,batched=True,num_proc=1,remove_columns=dataset["train"].column_names,load_from_cache_file=False,desc="Running tokenizer on dataset",)train_dataset = processed_datasets["train"]eval_dataset = processed_datasets["validation"]train_dataloader = DataLoader(train_dataset, shuffle=True, collate_fn=default_data_collator, batch_size=batch_size, pin_memory=True)eval_dataloader = DataLoader(eval_dataset, collate_fn=default_data_collator, batch_size=batch_size, pin_memory=True)# 设定优化器和正则项optimizer = torch.optim.AdamW(model.parameters(), lr=lr)lr_scheduler = get_linear_schedule_with_warmup(optimizer=optimizer,num_warmup_steps=0,num_training_steps=(len(train_dataloader) * num_epochs),)# 训练和评估model = model.to(device)# 模型推理预测from peft import PeftModel, PeftConfigpeft_model_id = f"{model_name_or_path}_{peft_config.peft_type}_{peft_config.task_type}"config = PeftConfig.from_pretrained(peft_model_id)model = AutoModelForSeq2SeqLM.from_pretrained(config.base_model_name_or_path)model = PeftModel.from_pretrained(model, peft_model_id)model.eval()i = 0inputs = tokenizer(dataset["validation"][text_column][i], return_tensors="pt")print(dataset["validation"][text_column][i])print(inputs)with torch.no_grad():outputs = model.generate(input_ids=inputs["input_ids"], max_new_tokens=10)print(outputs)print(tokenizer.batch_decode(outputs.detach().cpu().numpy(), skip_special_tokens=True))print("=============test=============")if __name__ == '__main__':# train_model()inference_model()
可以看到上面的LoraConfig参数如下:
peft_config = LoraConfig(task_type=TaskType.SEQ_2_SEQ_LM,inference_mode=False,r=8,lora_alpha=32,lora_dropout=0.1)
task_typeinference_mode:r:lora的秩;lora_A用高斯分布初始化,lora_B用0初始化lora_alpha:lora微调的缩放系数lora_dropout:lora微调的dropout系数learning_rate:adamw优化器的初始学习速率
也可以看LoraConfig源码:
class LoraConfig(PeftConfig):r: int = field(default=8, metadata={"help": "Lora attention dimension"})target_modules: Optional[Union[List[str], str]] = field(default=None,metadata={"help": "List of module names or regex expression of the module names to replace with Lora.""For example, ['q', 'v'] or '.*decoder.*(SelfAttention|EncDecAttention).*(q|v)$' "},)lora_alpha: int = field(default=None, metadata={"help": "Lora alpha"})lora_dropout: float = field(default=None, metadata={"help": "Lora dropout"})fan_in_fan_out: bool = field(default=False,metadata={"help": "Set this to True if the layer to replace stores weight like (fan_in, fan_out)"},)bias: str = field(default="none", metadata={"help": "Bias type for Lora. Can be 'none', 'all' or 'lora_only'"})modules_to_save: Optional[List[str]] = field(default=None,metadata={"help": "List of modules apart from LoRA layers to be set as trainable and saved in the final checkpoint. ""For example, in Sequence Classification or Token Classification tasks, ""the final layer `classifier/score` are randomly initialized and as such need to be trainable and saved."},)init_lora_weights: bool = field(default=True,metadata={"help": "Whether to initialize the weights of the Lora layers."},)def __post_init__(self):self.peft_type = PeftType.LORA
- r (
int): Lora attention dimension. - target_modules (
Union[List[str],str]): The names of the modules to apply Lora to. - lora_alpha (
float): The alpha parameter for Lora scaling. - lora_dropout (
float): The dropout probability for Lora layers. - fan_in_fan_out (
bool): Set this to True if the layer to replace stores weight like (fan_in, fan_out).- For example, gpt-2 uses
Conv1Dwhich stores weights like (fan_in, fan_out) and hence this should be set toTrue.:
- For example, gpt-2 uses
- bias (
str): Bias type for Lora. Can be ‘none’, ‘all’ or ‘lora_only’ - modules_to_save (
List[str]):List of modules apart from LoRA layers to be set as trainable
and saved in the final checkpoint.
Reference
[1] A Survey of Large Language Models. Wayne Xin Zhao
[2] 大模型论文综述介绍
[3] LLaMA类模型没那么难,LoRA将模型微调缩减到几小时
[4] RLHF中的PPO算法原理及其实现
[5] 基于DeepSpeed训练ChatGPT
[6] Prompt-Tuning——深度解读一种新的微调范式
[7] 大模型参数高效微调技术原理综述(七)-最佳实践、总结
[8] chatGLM2-6B模型的全参数微调(改进多轮对话交互质量等):https://github.com/SpongebBob/Finetune-ChatGLM2-6B
[9] 大模型微调样本构造的trick
[10] 大模型参数高效微调技术原理综述(一)-背景、参数高效微调简介(附全量参数微调与参数高效微调对比-表格)
[11] 大模型训练之微调篇.无数据不智能
[12] 理解金融报告:使用大模型.无数据不智能
[13] Scaling Down to Scale Up: A Guide to Parameter-Efficient Fine-Tuning
[14] 低资源微调大模型:LoRA模型思想与BLOOM-LORA代码实现分析
[15] 模型和指令微调方法.山顶夕景
[16] 详谈大模型训练和推理优化技术
[17] LLM+LoRa微调加速技术原理及基于PEFT的动手实践:一些思考和mt0-large+lora完整案例
[18] 再看大模型Lora微调加速是否有效:Full-Parameter全参数微调与LoRA低秩微调的性能对比开源实验介绍
[19] 微调范式对比Freeze、P-Tuning、Lora、full-Finetune开源实现
[20] 基于GLM-6B对话模型的实体属性抽取项目实现解析:对Zero-shot与In-Context Learning的若干思考
[21] 微调实战:DeepSpeed+Transformers实现简单快捷上手百亿参数模型微调
[22] LLaMA:小参数+大数据的开放、高效基础语言模型阅读笔记
[23] 代码角度看LLaMA语言模型
[24] ChatGPT应用端的Prompt解析:从概念、基本构成、常见任务、构造策略到开源工具与数据集
[25] LLM实战:大语言模型BLOOM推理工具测试实践与效果分析实录
[26] 谈langchain大模型外挂知识库问答系统核心部件:如何更好地解析、分割复杂非结构化文本
[27] 看支持32K上下文的ChatGLM2-6B模型:优化点简读及现有开源模型主流训练优化点概述
[28] 极低资源条件下如何微调大模型:LoRA模型思想与BLOOM-LORA代码实现分析
[29] The Power of Scale for Parameter-Efficient Prompt Tuning
[30] https://github.com/mymusise/ChatGLM-Tuning
一种平价的 Chatgpt 实现方案,基于清华的ChatGLM-6B+ LoRA 进行finetune
[31] https://github.com/jxhe/unify-parameter-efficient-tuning
[31] 简单分析LoRA方法
相关文章:
【LLM】金融大模型场景和大模型Lora微调实战
文章目录 一、金融大模型背景二、大模型的研究问题三、大模型技术路线四、LLaMA家族模型五、Lora模型微调的原理六、大模型Lora微调实战Reference 一、金融大模型背景 金融行业需要垂直领域LLM,因为存在金融安全和数据大多数存储在本地,在风控、精度、实…...
途乐证券股市资讯-英伟达,又创历史新高!美股全线上涨
当地时间13日,美股三大股指集体收涨,纳指、标普500指数双双改写2022年4月以来的新高。到收盘,道指涨0.14%,报34395.14点;纳指涨1.58%,报14138.57点;标普500指数涨0.85%,报4510.04点。…...

MySQL表聚合函数
前言 哈喽,各位小伙伴大家好,本篇文章为大家介绍几个MySQL中常用的聚合函数,什么是聚合函数,相信第一次看到这个名词的小伙伴是比较懵的,举个例子,比如说统计表中数据的个数,就可以使用MySQL中提…...
JavaWeb 速通XML
目录 一、XML快速入门 1.基本介绍 : 2.入门案例 : 二、XML语法 0.文件结构 : 1.文档声明 : 2. 元素 : 3.属性 : 4.注释 : 5.CDATA节 : PS : XML转义符 : 三、Dom4j 1.关于XML解析技术 : 2 Dom4j介绍 : 3.Dom4j使用 : 1 获取Document对象的三种方式 2 …...
redis浅析
一 什么是NoSQL? Nosql not only sql(不仅仅是SQL) 关系型数据库:列行,同一个表下数据的结构是一样的。 非关系型数据库:数据存储没有固定的格式,并且可以进行横向扩展。 NoSQL泛指非关系…...

四种缓存的避坑总结
背景 分布式、缓存、异步和多线程被称为互联网开发的四大法宝。今天我总结一下项目开发中常接触的四种缓存实际项目中遇到过的问题。 JVM堆内缓存 JVM堆内缓存因为可以避免memcache、redis等集中式缓存网络通信故障问题,目前还在项目中广泛使用。 堆内缓存需要注…...

flutter开发实战-flutter二维码条形码扫一扫功能实现
flutter开发实战-flutter二维码条形码扫一扫功能实现 flutter开发实战-flutter二维码扫一扫功能实现,要使用到摄像头的原生的功能,使用的是插件:scan 效果图如下 一、扫一扫插件scan # 扫一扫scan: ^1.6.01.1 iOS权限设置 <key>NSCa…...

一篇文章了解Redis分布式锁
Redis分布式锁 什么是分布式锁? redis分布式锁是一种基于redis实现的锁机制,它用于在多并发分布式环境下控制并发访问共享资源。在多个应用程序或是进程访问共享资源时,分布式锁可以确保只有一个进程可以访问该资源,不会发生…...

记录第一次组装电脑遇到的坑
京东装机大师配置清单如下: 主板cpu安装 本次安装拆了两次主板 原因1.主板侧面有个金属板需要从内部安装 2.cpu风扇有个板需要装在主板底下 显卡比较大个要最后装,要不然可能要拆好几次 装系统时候 u盘启动认不出来,他妈的是因为机箱上的usb…...
右键pdf文件没有打印
问题描述 右键点pdf文件,弹出的菜单找不到打印选项。网上找了很多办法,然并卵啊。还是得靠自己慢慢摸索。 原因分析 新安装的win11系统,pdf文件默认可以用windows自带的edge浏览器打开。但是edge浏览器没有能力提供右键打印功能。 解决办法…...

什么是CDN?CDN的原理和作用是什么?
一:什么是CDN CDN全称Content Delivery Network,即内容分发网络。 CDN是Content Delivery Network(内容分发网络)的缩写,是一种利用分布式节点技术,在全球部署服务器,即时地将网站、应用、视频…...
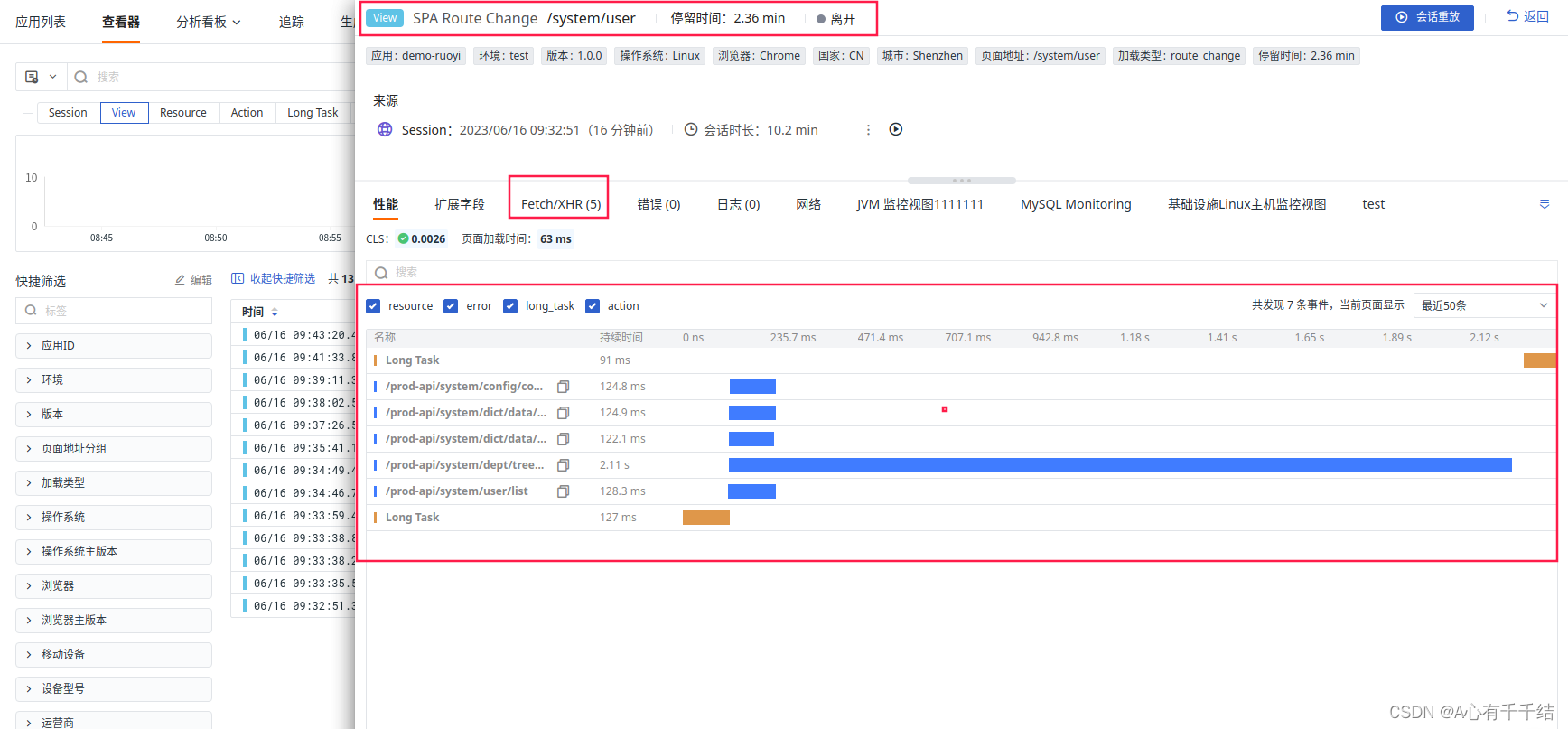
链路传播(Propagate)机制及使用场景
服务间链路追踪传播机制是指在微服务架构中,通过记录和跟踪服务之间的请求和响应信息,来实现对服务间链路的追踪和监控。这种机制可以帮助开发人员快速定位服务间出现的问题,并进行优化和调整。 具体来说,服务间链路追踪传播机制…...

pytorch技巧总结1:学习率调整方法
pytorch技巧总结1:学习率调整方法 前言 这个系列,我会把一些我觉得有用、有趣的关于pytorch的小技巧进行总结,希望可以帮助到有需要的朋友。 免责申明 本人水平有限,若有误写、漏写,请大家温柔的批评指正。 目录…...
谈谈VPN是什么、类型、使用场景、工作原理
作者:Insist-- 个人主页:insist--个人主页 作者会持续更新网络知识和python基础知识,期待你的关注 前言 本文将讲解VPN是什么、以及它的类型、使用场景、工作原理。 目录 一、VPN是什么? 二、VPN的类型 1、站点对站点VPN 2、…...

windows 下载安装Redis,并配置开机自启动
windows 下载安装Redis,并配置开机自启动 1. 下载 地址:https://github.com/tporadowski/redis/releases Redis 支持 32 位和 64 位。这个需要根据你系统平台的实际情况选择,这里我们下载 Redis-x64-xxx.zip压缩包,之后解压 打…...

2. CSS3的新特性
2.1CSS3的现状 ●新增的CSS3特性有兼容性问题, ie9才支持 ●移动端支持优于PC端 ●不断改进中 ●应用相对广泛 ●现阶段主要学习: 新增选择器和盒子模型以及其他特性 CSS3给我们新增了选择器,可以更加便捷,更加自由的选择目标元素: 1.属性选择器 2.结构伪类选择器…...

从零开始训练神经网络
用Keras实现一个简单神经网络 Keras: Keras是由纯python编写的基于theano/tensorflow的深度学习框架。 Keras是一个高层神经网络API,支持快速实验,能够把你的idea迅速转换为结果,如果有如下需 求,可以优先选择Keras&a…...
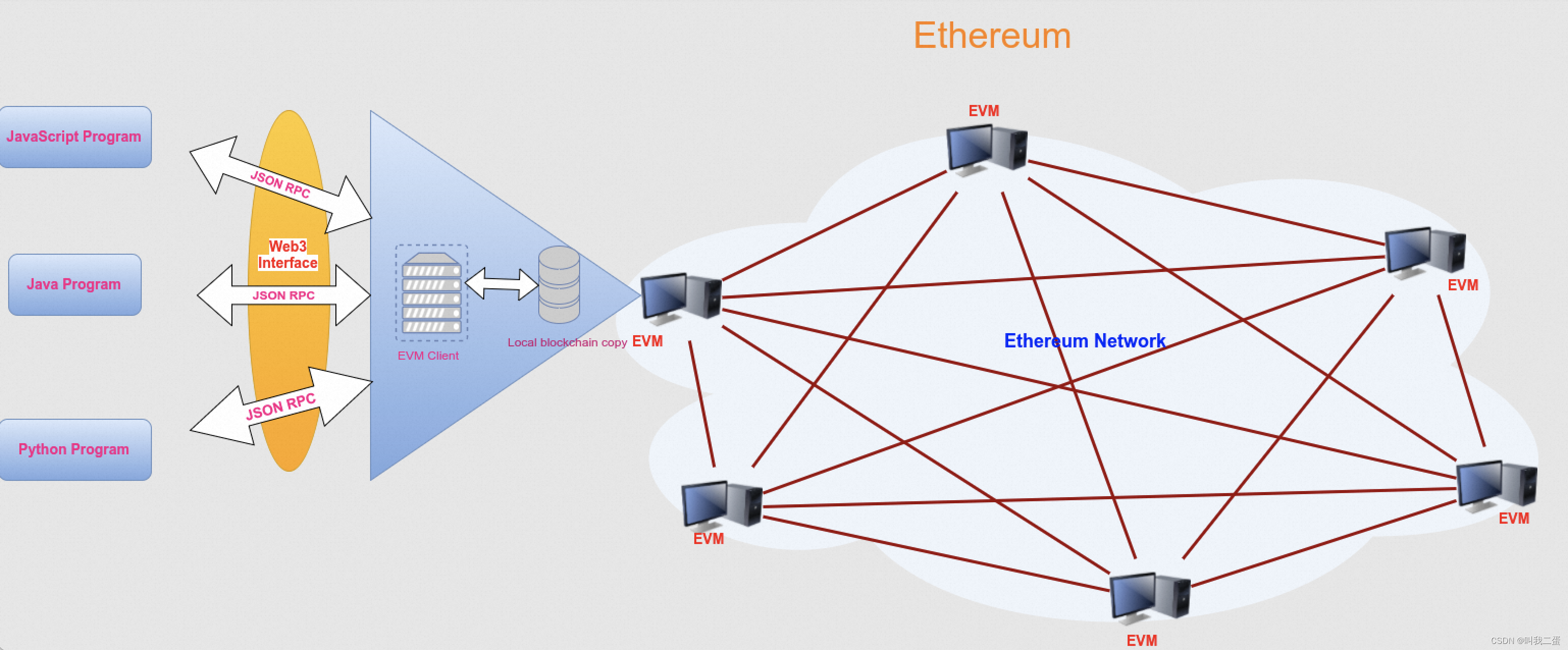
连接区块链节点的 JavaScript 库 web3.js
文章目录 前言web3.js 介绍web3.js安装web3.js库模块介绍连接区块链节点向区块链网络发送数据查询区块链网络数据 前言 通过前面的文章我们可以知道基于区块链开发一个DApp,而DApp结合了智能合约和用户界面(客户端),那客户端是如…...

js:scroll平滑滚动页面或元素到顶部或底部的方案汇总
目录 1、CSS的scroll-behavior2、Element.scrollTop3、Element.scroll()/Window.scroll()4、Element.scrollBy()/Window.scrollBy()5、Element.scrollTo()/Window.scrollTo()6、Element.scrollIntoView()7、自定义兼容性方案8、参考文章 准备知识: scrollWidth: 是…...

【Docker】Docker的部署含服务和应用、多租环境、Linux内核的详细介绍
前言 Docker 是一个开源的应用容器引擎,让开发者可以打包他们的应用以及依赖包到一个可移植的容器中,然后发布到任何流行的Linux或Windows操作系统的机器上,也可以实现虚拟化,容器是完全使用沙箱机制,相互之间不会有任何接口。 📕作者简介:热…...

解锁Dify工作流新潜能:四种并行模式实战解析
1. 为什么需要工作流并行化? 第一次用Dify构建工作流时,我就被它的可视化编排能力惊艳到了。但实际跑了几次发现,当处理复杂任务时,串行执行就像在高速公路上开拖拉机——明明有八车道却只开放一条。比如做新闻情感分析时…...

nli-distilroberta-base案例集锦:12个已落地NLI应用场景与技术实现要点
nli-distilroberta-base案例集锦:12个已落地NLI应用场景与技术实现要点 1. 项目概述 nli-distilroberta-base是一个基于DistilRoBERTa模型的自然语言推理(NLI)Web服务,专门用于判断两个句子之间的关系。这个轻量级但强大的模型能够快速准确地分析句子对…...

OpenClaw飞书机器人:Qwen3-VL:30B多模态应用指南
OpenClaw飞书机器人:Qwen3-VL:30B多模态应用指南 1. 为什么选择OpenClawQwen3-VL:30B组合? 去年冬天,当我第一次尝试用AI助手处理团队飞书群里的图片报销单时,经历了惨痛的失败——要么识别错金额,要么把同事的午餐照…...
】自注意力与多头机制:QKV、缩放与因果掩码)
【大语言模型基础(2)】自注意力与多头机制:QKV、缩放与因果掩码
文章目录摘要1. 为什么需要自注意力2. Q、K、V 到底是什么一个具体例子3. Attention 公式在干什么第一步:计算相似度第二步:做缩放第三步:softmax\mathrm{softmax}softmax 归一化第四步:对 ValueValueValue 做加权平均4. 为什么 G…...

Swin2SR模型可解释性:理解超分决策过程
Swin2SR模型可解释性:理解超分决策过程 1. 引言 当我们使用Swin2SR这样的超分辨率模型时,经常会惊叹于它能够将模糊的低分辨率图像转换为清晰的高分辨率图像。但你是否好奇过,这个"AI显微镜"是如何做出这些决策的?它是…...

FigmaCN:消除语言壁垒的中文界面本地化解决方案
FigmaCN:消除语言壁垒的中文界面本地化解决方案 【免费下载链接】figmaCN 中文 Figma 插件,设计师人工翻译校验 项目地址: https://gitcode.com/gh_mirrors/fi/figmaCN FigmaCN是一款专为中文设计师打造的浏览器插件,通过3800条人工校…...

ModelScope与Hugging Face中文API调用全攻略:从安装到实战代码解析
ModelScope与Hugging Face中文API调用全攻略:从安装到实战代码解析 如果你正在寻找一个能够快速上手ModelScope和Hugging Face API的指南,特别是针对中文开发者的实用教程,那么你来对地方了。这两个平台作为当前最受欢迎的AI模型开源社区&…...

OpenClaw自动化写作实测:Qwen3-32B生成技术博客全流程
OpenClaw自动化写作实测:Qwen3-32B生成技术博客全流程 1. 为什么选择OpenClaw进行自动化写作 作为一个长期与技术文档打交道的开发者,我一直在寻找能够提升写作效率的工具。传统写作流程中,从选题到发布需要经历资料收集、大纲设计、内容填…...
)
从二极管到MOS管:工程师实测对比三种防反接电路的效率与成本(含数据)
从二极管到MOS管:三种防反接电路的全维度工程评估手册 当你的电路板因为电源反接冒出一缕青烟时,那种混合着焦味和绝望的体验,相信每个硬件工程师都记忆犹新。防反接电路看似简单,却直接影响着产品的可靠性、成本和能效表现。本文…...
)
告别规则几何!用Python+Matlab为gprMax创建任意复杂地质模型(附HDF5文件生成代码)
突破几何限制:用PythonMatlab构建gprMax复杂地质模型的完整指南 地质雷达模拟领域的研究者常面临一个尴尬困境:脑海中的地质结构复杂多变,但建模工具却只能生成规则几何体。本文将彻底解决这一矛盾,带您掌握跨平台协作建模技术&am…...