微服务如何治理
 微服务远程调用可能有如下问题:
微服务远程调用可能有如下问题:
注册中心宕机;
服务提供者B有节点宕机;
服务消费者A和注册中心之间的网络不通;
服务提供者B和注册中心之间的网络不通;
服务消费者A和服务提供者B之间的网络不通;
服务提供者B有些节点性能变慢;
服务提供者B短时间内出现问题。
常用的服务治理手段:
节点管理
服务调用失败一般是由两类原因引起的,一类是服务提供者自身出现问题,如服务器宕机、进程意外退出等;一类是网络问题,如服务提供者、注册中心、服务消费者这三者任意两者之间的网络出现问题。
无论是服务提供者自身出现问题还是网络发生问题,都有两种节点管理手段。
1. 注册中心主动摘除机制
这种机制要求服务提供者定时的主动向注册中心汇报心跳,注册中心根据服务提供者节点最近一次汇报心跳的时间与上一次汇报心跳时间做比较,如果超出一定时间,就认为服务提供者出现问题,继而把节点从服务列表中摘除,并把最近的可用服务节点列表推送给服务消费者。
2. 服务消费者摘除机制
虽然注册中心主动摘除机制可以解决服务提供者节点异常的问题,但如果是因为注册中心与服务提供者之间的网络出现异常,最坏的情况是注册中心会把服务节点全部摘除,导致服务消费者没有可用的服务节点调用,但其实这时候服务提供者本身是正常的。所以,将存活探测机制用在服务消费者这一端更合理,如果服务消费者调用服务提供者节点失败,就将这个节点从内存中保存的可用服务提供者节点列表中移除。
负载均衡
一般情况下,服务提供者节点不是唯一的,多是以集群的方式存在,尤其是对于大规模的服务调用来说,服务提供者节点数目可能有上百上千个。由于机器采购批次的不同,不同服务节点本身的配置也可能存在很大差异,新采购的机器CPU和内存配置可能要高一些,同等请求量情况下,性能要好于旧的机器。对于服务消费者而言,在从服务列表中选取可用节点时,如果能让配置较高的新机器多承担一些流量的话,就能充分利用新机器的性能。这就需要对负载均衡算法做一些调整。
常用的负载均衡算法主要包括以下几种。
1. 随机算法
顾名思义就是从可用的服务节点中随机选取一个节点。一般情况下,随机算法是均匀的,也就是说后端服务节点无论配置好坏,最终得到的调用量都差不多。
2. 轮询算法
就是按照固定的权重,对可用服务节点进行轮询。如果所有服务节点的权重都是相同的,则每个节点的调用量也是差不多的。但可以给某些硬件配置较好的节点的权重调大些,这样的话就会得到更大的调用量,从而充分发挥其性能优势,提高整体调用的平均性能。
3. 最少活跃调用算法
这种算法是在服务消费者这一端的内存里动态维护着同每一个服务节点之间的连接数,当调用某个服务节点时,就给与这个服务节点之间的连接数加1,调用返回后,就给连接数减1。然后每次在选择服务节点时,根据内存里维护的连接数倒序排列,选择连接数最小的节点发起调用,也就是选择了调用量最小的服务节点,性能理论上也是最优的。
4. 一致性Hash算法
指相同参数的请求总是发到同一服务节点。当某一个服务节点出现故障时,原本发往该节点的请求,基于虚拟节点机制,平摊到其他节点上,不会引起剧烈变动。
这几种算法的实现难度也是逐步提升的,所以选择哪种节点选取的负载均衡算法要根据实际场景而定。如果后端服务节点的配置没有差异,同等调用量下性能也没有差异的话,选择随机或者轮询算法比较合适;如果后端服务节点存在比较明显的配置和性能差异,选择最少活跃调用算法比较合适。
服务路由
对于服务消费者而言,在内存中的可用服务节点列表中选择哪个节点不仅由负载均衡算法决定,还由路由规则确定。
所谓的路由规则,就是通过一定的规则如条件表达式或者正则表达式来限定服务节点的选择范围。
为什么要制定路由规则呢?主要有两个原因。
1. 业务存在灰度发布的需求
比如,服务提供者做了功能变更,但希望先只让部分人群使用,然后根据这部分人群的使用反馈,再来决定是否做全量发布。这个时候,就可以通过类似按尾号进行灰度的规则限定只有一定比例的人群才会访问新发布的服务节点。
2. 多机房就近访问的需求
据我所知,大部分业务规模中等及以上的互联网公司,为了业务的高可用性,都会将自己的业务部署在不止一个IDC中。这个时候就存在一个问题,不同IDC之间的访问由于要跨IDC,通过专线访问,尤其是IDC相距比较远时延迟就会比较大,比如北京和广州的专线延迟一般在30ms左右,这对于某些延时敏感性的业务是不可接受的,所以就要一次服务调用尽量选择同一个IDC内部的节点,从而减少网络耗时开销,提高性能。这时一般可以通过IP段规则来控制访问,在选择服务节点时,优先选择同一IP段的节点。
那么路由规则该如何配置呢?根据我的实际项目经验,一般有两种配置方式。
1. 静态配置
就是在服务消费者本地存放服务调用的路由规则,在服务调用期间,路由规则不会发生改变,要想改变就需要修改服务消费者本地配置,上线后才能生效。
2. 动态配置
这种方式下,路由规则是存在注册中心的,服务消费者定期去请求注册中心来保持同步,要想改变服务消费者的路由配置,可以通过修改注册中心的配置,服务消费者在下一个同步周期之后,就会请求注册中心来更新配置,从而实现动态更新。
服务容错
服务调用并不总是一定成功的,可能因为服务提供者节点自身宕机、进程异常退出或者服务消费者与提供者之间的网络出现故障等原因。对于服务调用失败的情况,需要有手段自动恢复,来保证调用成功。
常用的手段主要有以下几种。
FailOver:失败自动切换。就是服务消费者发现调用失败或者超时后,自动从可用的服务节点列表总选择下一个节点重新发起调用,也可以设置重试的次数。这种策略要求服务调用的操作必须是幂等的,也就是说无论调用多少次,只要是同一个调用,返回的结果都是相同的,一般适合服务调用是读请求的场景。
FailBack:失败通知。就是服务消费者调用失败或者超时后,不再重试,而是根据失败的详细信息,来决定后续的执行策略。比如对于非幂等的调用场景,如果调用失败后,不能简单地重试,而是应该查询服务端的状态,看调用到底是否实际生效,如果已经生效了就不能再重试了;如果没有生效可以再发起一次调用。
FailCache:失败缓存。就是服务消费者调用失败或者超时后,不立即发起重试,而是隔一段时间后再次尝试发起调用。比如后端服务可能一段时间内都有问题,如果立即发起重试,可能会加剧问题,反而不利于后端服务的恢复。如果隔一段时间待后端节点恢复后,再次发起调用效果会更好。
FailFast:快速失败。就是服务消费者调用一次失败后,不再重试。实际在业务执行时,一般非核心业务的调用,会采用快速失败策略,调用失败后一般就记录下失败日志就返回了。
对服务容错不同策略的描述中,可以看出它们的使用场景是不同的,一般情况下对于幂等的调用,可以选择FailOver或者FailCache,非幂等的调用可以选择FailBack或者FailFast。
相关文章:
微服务如何治理
微服务远程调用可能有如下问题: 注册中心宕机; 服务提供者B有节点宕机; 服务消费者A和注册中心之间的网络不通; 服务提供者B和注册中心之间的网络不通; 服务消费者A和服务提供者B之间的网络不通; 服务提供者…...
一本通1919:【02NOIP普及组】选数
这道题感觉很好玩。 正文: 先放题目: 信息学奥赛一本通(C版)在线评测系统 (ssoier.cn)http://ybt.ssoier.cn:8088/problem_show.php?pid1919 描述 已知 n 个整数 x1,x2,…,xn,以及一个整数 k(k&#…...

Kubernetes 集群管理和编排
文章目录 总纲第一章:引入 Kubernetes什么是容器编排和管理?容器编排和管理的重要性Kubernetes作为容器编排和管理解决方案 Kubernetes 的背景和发展起源和发展历程Kubernetes 项目的目标和动机 Kubernetes 的作用和优势作用优势 Kubernetes 的特点和核心…...

DDS协议--[第六章][Discovery]
DDS协议–Discovery 文章目录 DDS协议--Discovery侦听通告DDS提供发现协议参与者发现阶段(PDP)端点发现阶段(EDP)Fast DDS提供如下四种发现机制:简单发现机制简单发现机制步骤:侦听 侦听定位器用于接收DomainParticipant上的传入流量,是DDS发现机制和数据传输机制的关键…...

如何设置iptables,让网络流量转发给内部容器mysql
1.创建一个mysql ,无法外部访问 docker run -d --name mysql_container -e MYSQL_ROOT_PASSWORDliuyunshengsir -v /path/to/mysql_data:/var/lib/mysql mysql2.设置规则外部直接可访问 要使用 iptables 将网络流量转发给内部容器中的 MySQL 服务,你可…...
数字IC实践项目(7)—CNN加速器的设计和实现(付费项目)
数字IC实践项目(7)—基于Verilog的CNN加速器(付费项目) 写在前面的话项目整体框图神经网络框图完整电路框图 项目简介和学习目的软件环境要求 资源占用&板载功耗总结 写在前面的话 项目介绍: 卷积神经网络硬件加速…...

基于深度学习的高精度80类动物目标检测系统(PyTorch+Pyside6+YOLOv5模型)
摘要:基于深度学习的高精度80类动物目标检测识别系统可用于日常生活中或野外来检测与定位80类动物目标,利用深度学习算法可实现图片、视频、摄像头等方式的80类动物目标检测识别,另外支持结果可视化与图片或视频检测结果的导出。本系统采用YO…...

海康摄像头开发笔记(一):连接防爆摄像头、配置摄像头网段、设置rtsp码流、播放rtsp流、获取rtsp流、调优rtsp流播放延迟以及录像存储
文为原创文章,转载请注明原文出处 本文章博客地址:https://hpzwl.blog.csdn.net/article/details/131679108 红胖子(红模仿)的博文大全:开发技术集合(包含Qt实用技术、树莓派、三维、OpenCV、OpenGL、ffmpeg、OSG、单片机、软硬结…...

【NCNN】NCNN中Mat与CV中Mat的使用区别及相互转换方法
目录 相同点与不同点cv::Mat转ncnn::Matcv::Mat CV_8UC3 -> ncnn::Mat 3 channel swap RGB/BGRcv::Mat CV_8UC3 -> ncnn::Mat 1 channel do RGB2GRAY/BGR2GRAYcv::Mat CV_8UC1 -> ncnn::Mat 1 channel ncnn::Mat转cv::Mancnn::Mat 3 channel -> cv::Mat CV_8UC3 …...

Android 13 设置自动进入wifi adb模式
Android 13 设置自动进入wifi adb模式 文章目录 Android 13 设置自动进入wifi adb模式一、前言:二、解决Android 13 wifi adb每次重启自动重置问题方法1、分析系统中每次重置wifi adb属性的代码2、在开机广播里面进行设置wifi adb 相关属性(1)…...
插入排序)
(笔记)插入排序
插入排序 插入排序是一种简单且常见的排序算法,它通过重复将一个元素插入到已经排好序的一组元素中,来达到排序的目的。在插入排序算法中,将待排序序列分为已排序和未排序两个部分。初始时,已排序部分只包含一个记录,…...
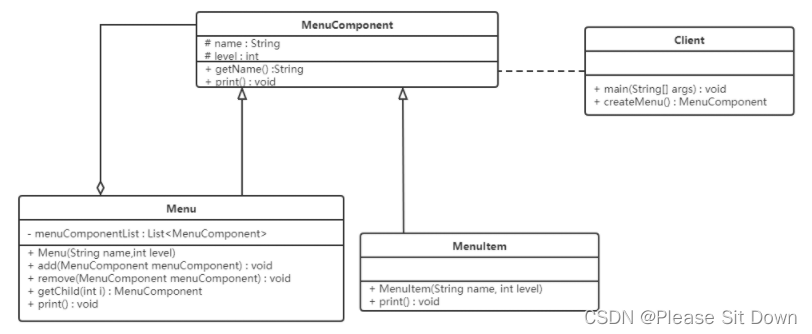
结构型模式 - 组合模式
概述 对于这个图片肯定会非常熟悉,上图我们可以看做是一个文件系统,对于这样的结构我们称之为树形结构。在树形结构中可以通过调用某个方法来遍历整个树,当我们找到某个叶子节点后,就可以对叶子节点进行相关的操作。可以将这颗树理…...
EDM营销过时了?不,这才是跨境电商成功的最佳工具
根据最近的一项研究,电子邮件仍然是最具说服力的营销工具和沟通形式之一。虽然即时通讯等其他渠道正在扎根,但电子邮件仍然是影响最深远的商业交流形式。到2023年,每天发送和接收的电子邮件总数可能会超过333亿封。所以,如果您希望…...

【大数据之Hive】二十五、HQL语法优化之小文件合并
1 优化说明 小文件优化可以从两个方面解决,在Map端输入的小文件合并,在Reduce端输出的小文件合并。 1.1 Map端输入文件合并 合并Map端输入的小文件是指将多个小文件分到同一个切片中,由一个Map Task处理,防止单个小文件启动一个M…...

spring 连接oracle数据库报错{dataSource-1} init error解决,电脑用户名问题
错误描述: 连接oracle数据就报错,同样的代码其他电脑不会报错。 报错如下: {dataSource-1} init error java.sql.SQLRecoverableException: IO 错误: Undefined Error com.alibaba.druid.pool.DruidDataSource-1049[main]ERROR: {dataSourc…...

行业视野::人工智能与机器人
控制和机器人领域非常重要的quote:莫拉维克悖论(Moravecs paradox) It is comparatively easy to make computers exhibit adult level performance on intelligence tests or playing checkers,and difficult or impossible to give them th…...

【Python入门系列】第十七篇:Python大数据处理和分析
【Python入门系列】第十七篇:Python大数据处理和分析 文章目录 前言一、数据处理和分析步骤二、Python大数据处理和分析库三、Python大数据处理和分析应用1、数据清洗和转换2、数据分析和统计3、数据可视化4、机器学习模型训练和预测5、大规模数据处理和分布式计算6…...
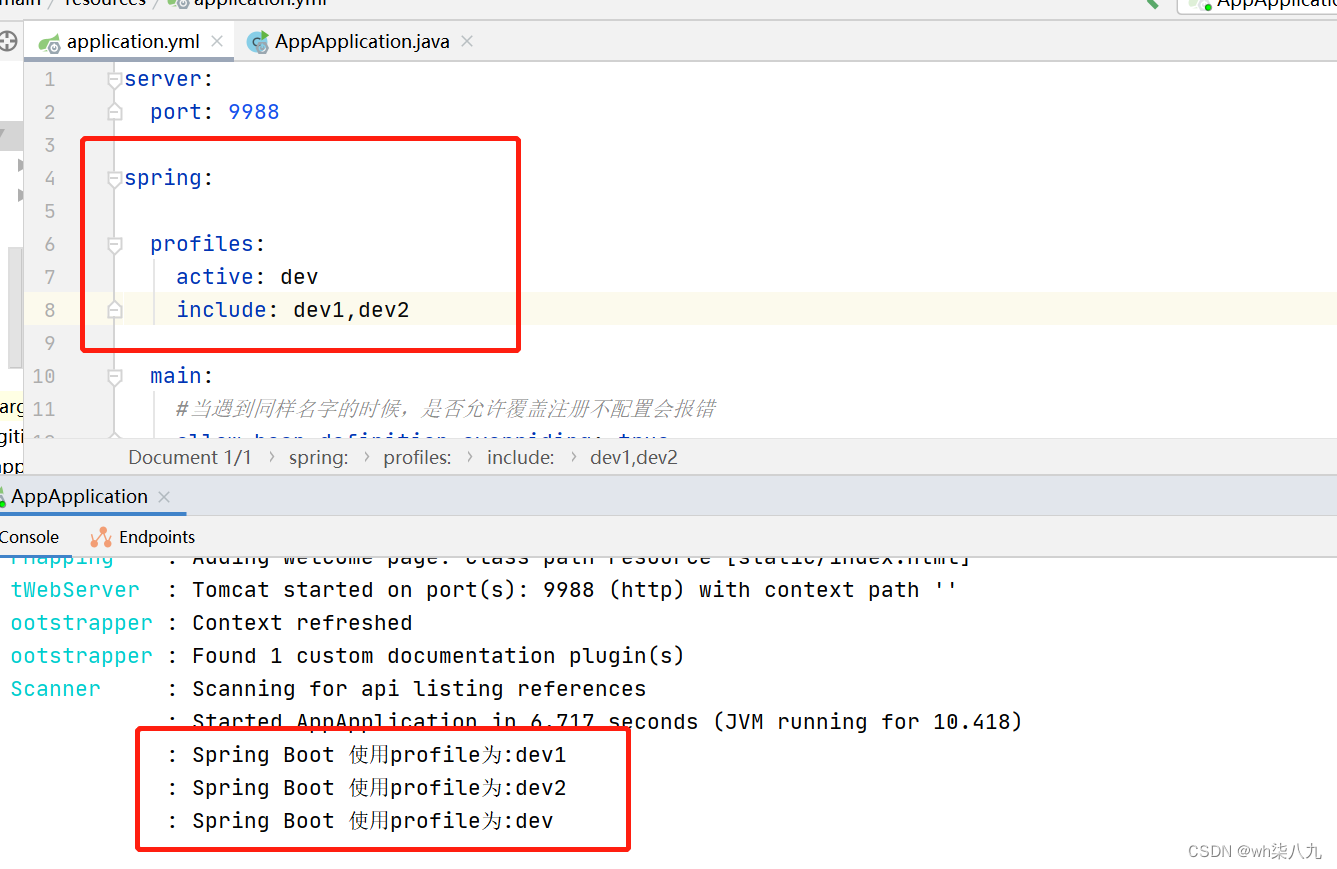
spring.profiles的使用详解
本文来说下spring.profiles.active和spring.profiles.include的使用与区别 文章目录 业务场景spring.profiles.active属性启动时指定 spring.profiles.include属性配置方法配置位置配置区别 用示例来使用和区分测试一测试二测试三 编写程序查看激活的yml文件本文小结 业务场景 …...
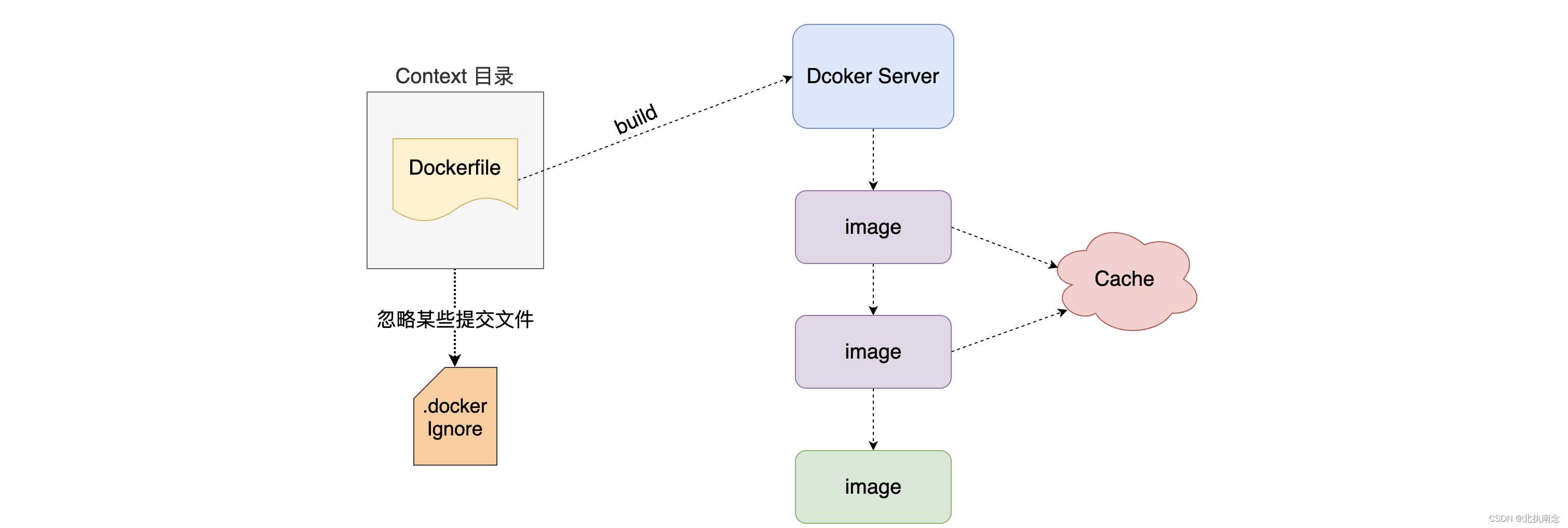
Docker使用总结
Docker 1.什么是 Docker 官网的介绍是“Docker is the world’s leading software container platform.” 官方给Docker的定位是一个应用容器平台。 Docker 是一个容器平台的领导者 Docker 容器平台 Docker 应用容器平台 application项目 Mysql Redis MongoDB ElasticSeacrh …...

MySQL 数据库的备份与还原案例分享 2023.07.12
/** 素材一 备份与还原 **/ 1 创建数据库booksDB mysql> create database booksDB; Query OK, 1 row affected (0.00 sec)2.1 创建booksDB表 mysql> use booksDB Database changed mysql> CREATE TABLE books-> (-> bk_id INT NOT NULL PRIMARY KEY,-> …...

基于STM32F103与HAL库的总线舵机多模式运动控制实战
1. STM32F103与HAL库开发环境搭建 第一次接触STM32F103和HAL库的朋友可能会觉得有点懵,其实搭建开发环境比你想象中简单多了。我当初用STM32CubeMX配置项目时踩过不少坑,现在把这些经验都分享给你。 首先得准备好硬件,你需要一块STM32F103开发…...

终极免费Jable视频下载指南:3步搞定Chrome插件完整教程
终极免费Jable视频下载指南:3步搞定Chrome插件完整教程 【免费下载链接】jable-download 方便下载jable的小工具 项目地址: https://gitcode.com/gh_mirrors/ja/jable-download jable-download是一款专为普通用户设计的免费Jable视频下载工具,通过…...

RWKV7-1.5B-g1a镜像部署教程:CSDN平台一键拉起Web服务,7860端口直连体验
RWKV7-1.5B-g1a镜像部署教程:CSDN平台一键拉起Web服务,7860端口直连体验 1. 模型简介 rwkv7-1.5B-g1a 是基于新一代 RWKV-7 架构的多语言文本生成模型,特别适合中文场景下的轻量级应用。这个1.5B参数的版本在保持较高生成质量的同时&#x…...

Nacos集群启动时,那个神秘的cluster.conf文件到底是怎么被找到和监控的?
Nacos集群启动时cluster.conf文件的寻址与监控机制深度解析 从一次集群配置失效事件说起 上周深夜,我们的分布式系统监控平台突然发出警报——Nacos集群中的三个节点相继失联。紧急排查时发现,明明已经更新了cluster.conf文件新增了两个节点,…...

【Frida Android】实战篇:Frida-Trace 进阶追踪——JNI 函数参数捕获与修改
1. 为什么需要捕获JNI函数参数? 在Android安全分析和逆向工程中,JNI函数往往是关键突破口。很多应用会把核心逻辑放在native层实现,比如加密算法、授权验证、敏感数据处理等。单纯Hook Java层方法可能无法触及这些关键逻辑,这时候…...

水墨江南模型Agent智能体开发:自主中式艺术创作助手
水墨江南模型Agent智能体开发:自主中式艺术创作助手 最近在捣鼓AI绘画,发现一个挺有意思的事儿。很多朋友想用AI画点有中国风味的作品,比如水墨画、山水画,但往往折腾半天,出来的效果总差那么点意思。要么是意境不对&…...
)
别再死记命令了!用EVE-NG模拟器5分钟搞定思科GRE隧道(附OSPF联动配置)
5分钟玩转思科GRE隧道:EVE-NG实战中的高效学习法 第一次在EVE-NG里搭建GRE隧道时,我盯着满屏的命令行发呆——这些配置到底在做什么?为什么tunnel接口要配源和目的地址?OSPF又是怎么和隧道联动的?直到我用Wireshark抓到…...

HP-Socket技术演讲视频描述撰写指南:关键词与吸引力
HP-Socket技术演讲视频描述撰写指南:关键词与吸引力 【免费下载链接】HP-Socket High Performance TCP/UDP/HTTP Communication Component 项目地址: https://gitcode.com/gh_mirrors/hp/HP-Socket HP-Socket是一款高性能跨平台网络通信框架,专为…...

三极管基极下拉电阻在高速电路中的关键作用解析
1. 三极管基极下拉电阻的基础认知 第一次接触三极管电路时,我和很多新手一样,对基极那个看似多余的下拉电阻充满疑惑。明明没有它电路也能工作,为什么工程师们总爱画蛇添足?直到有次调试电机驱动电路,三极管莫名其妙地…...

多层PCB结构与设计技术详解
多层PCB内部结构解析与设计指南1. 多层PCB概述1.1 多层PCB的基本概念现代电子设备对电路板的要求越来越高,多层PCB已成为复杂电子系统的标准配置。与单层或双层PCB相比,多层PCB通过在绝缘基材上叠加多个导电层,实现了更高的布线密度和更优的信…...