【Python入门系列】第十七篇:Python大数据处理和分析
【Python入门系列】第十七篇:Python大数据处理和分析
文章目录
- 前言
- 一、数据处理和分析步骤
- 二、Python大数据处理和分析库
- 三、Python大数据处理和分析应用
- 1、数据清洗和转换
- 2、数据分析和统计
- 3、数据可视化
- 4、机器学习模型训练和预测
- 5、大规模数据处理和分布式计算
- 6、 使用PySpark进行大数据处理和分析
- 总结
前言
大数据处理和分析是指对大规模数据集进行收集、存储、处理和分析的过程。随着互联网和信息技术的发展,我们可以轻松地获取到大量的数据,这些数据包含着宝贵的信息和洞察力。然而,由于数据量庞大、复杂性高和多样性,传统的数据处理和分析方法已经无法胜任。
大数据处理和分析的目标是从大规模数据集中提取有价值的信息和知识,以支持决策制定、业务优化和问题解决。它涉及到数据清洗、数据转换、数据存储、数据挖掘、数据建模和数据可视化等多个环节。
在大数据处理和分析中,我们需要使用一些工具和技术来处理和分析数据。Python是一种常用的编程语言,它在大数据处理和分析领域非常受欢迎。Python提供了许多强大的库和框架,如Pandas、NumPy、PySpark、Scikit-learn和TensorFlow,它们可以帮助我们有效地处理和分析大规模数据集。
一、数据处理和分析步骤
- 数据收集:从各种来源获取数据,如数据库、传感器、日志文件、社交媒体等。
- 数据清洗:处理缺失值、异常值和重复值,使数据符合分析要求。
- 数据转换:对数据进行预处理、特征提取、变换和归一化等操作,以便进行后续分析。
- 数据存储:将数据存储在适当的数据结构中,如数据库、数据仓库或分布式文件系统。
- 数据分析:应用统计分析、机器学习、深度学习等技术对数据进行模式识别、分类、聚类和预测等分析。
- 数据可视化:使用图表、图形和可视化工具将分析结果可视化,以便更好地理解和传达数据洞察。
二、Python大数据处理和分析库
-
Pandas库:Pandas是Python中最常用的数据处理和分析库之一。它提供了高效的数据结构和数据分析工具,可以进行数据清洗、转换、合并、筛选等操作。
-
NumPy库:NumPy是Python中用于科学计算的基础库。它提供了多维数组对象和强大的数学函数,可以高效地处理大规模数据集。
-
Matplotlib库:Matplotlib是Python中常用的数据可视化库,可以创建各种类型的静态和动态图表,用于展示和分析数据。
-
Scikit-learn库:Scikit-learn是Python中用于机器学习的库,提供了多种机器学习算法和工具,可以用于数据挖掘和预测分析。
-
Spark:Spark是一个开源的大数据处理框架,可以与Python集成。它提供了分布式计算和内存计算的能力,适用于处理大规模数据集。
-
SQL数据库:Python可以通过各种数据库连接库(如pymysql、psycopg2等)连接到SQL数据库,进行数据的存储和查询分析。
三、Python大数据处理和分析应用
1、数据清洗和转换
import pandas as pd# 读取CSV文件data = pd.read_csv('data.csv')# 删除缺失值data = data.dropna()# 转换数据类型data['age'] = data['age'].astype(int)
上述代码使用Pandas库进行数据清洗和转换。首先,通过 read_csv 函数读取CSV文件。然后,使用 dropna 函数删除包含缺失值的行。最后,使用 astype 函数将’age’列的数据类型转换为整数。
2、数据分析和统计
import pandas as pd# 读取CSV文件data = pd.read_csv('data.csv')# 计算平均值average_age = data['age'].mean()# 统计频数gender_counts = data['gender'].value_counts()
上述代码使用Pandas库进行数据分析和统计。首先,通过 read_csv 函数读取CSV文件。然后,使用 mean 函数计算’age’列的平均值。接下来,使用 value_counts 函数统计’gender’列中各个值的频数。
3、数据可视化
import pandas as pdimport matplotlib.pyplot as plt# 读取CSV文件data = pd.read_csv('data.csv')# 绘制柱状图data['gender'].value_counts().plot(kind='bar')plt.xlabel('Gender')plt.ylabel('Count')plt.title('Gender Distribution')plt.show()
上述代码使用Pandas和Matplotlib库进行数据可视化。首先,通过 read_csv 函数读取CSV文件。然后,使用 value_counts 函数统计’gender’列中各个值的频数,并使用 plot 函数绘制柱状图。最后,使用 xlabel 、 ylabel 和 title 函数设置图表的标签和标题,并使用 show 函数显示图表。
4、机器学习模型训练和预测
import pandas as pdfrom sklearn.model_selection import train_test_splitfrom sklearn.linear_model import LogisticRegressionfrom sklearn.metrics import accuracy_score# 读取CSV文件data = pd.read_csv('data.csv')# 分割特征和标签X = data.drop('target', axis=1)y = data['target']# 划分训练集和测试集X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 训练逻辑回归模型model = LogisticRegression()model.fit(X_train, y_train)# 预测y_pred = model.predict(X_test)# 计算准确率accuracy = accuracy_score(y_test, y_pred)print("准确率:", accuracy)
上述代码使用Pandas和Scikit-learn库进行机器学习模型的训练和预测。首先,通过 read_csv 函数读取CSV文件。然后,使用 drop 函数分割特征和标签。接下来,使用 train_test_split 函数将数据集划分为训练集和测试集。然后,使用 LogisticRegression 类训练逻辑回归模型,并使用 fit 方法拟合模型。最后,使用 predict 方法对测试集进行预测,并使用 accuracy_score 函数计算准确率。
5、大规模数据处理和分布式计算
from pyspark import SparkContextfrom pyspark.sql import SparkSession# 创建SparkSessionspark = SparkSession.builder \.appName("Big Data Processing") \.getOrCreate()# 读取CSV文件data = spark.read.csv('data.csv', header=True, inferSchema=True)# 执行数据处理和转换操作processed_data = data.filter(data['age'] > 30).groupBy('gender').count()# 显示结果processed_data.show()
上述代码使用PySpark库进行大规模数据处理和分布式计算。首先,通过 SparkSession 创建SparkSession对象。然后,使用 read.csv 方法读取CSV文件,并通过 header 和 inferSchema 参数指定文件包含头部信息和自动推断列的数据类型。接下来,使用 filter 方法过滤年龄大于30的数据,并使用 groupBy 和 count 方法对性别进行分组和计数。最后,使用 show 方法显示处理后的结果。
6、 使用PySpark进行大数据处理和分析
from pyspark.sql import SparkSession# 创建SparkSession对象spark = SparkSession.builder.appName('data_analysis').getOrCreate()# 读取CSV文件data = spark.read.csv('data.csv', header=True)# 查看数据前几行data.show()# 统计数据摘要信息data.describe().show()# 进行数据筛选和过滤filtered_data = data.filter(data['column_name'] > 10)# 进行数据聚合操作aggregated_data = data.groupBy('column_name').sum()# 导出数据到Parquet文件aggregated_data.write.parquet('output.parquet')
上述代码使用PySpark库进行大数据处理和分析。首先,创建一个SparkSession对象,用于连接到Spark集群。然后,使用 spark.read.csv 方法读取CSV文件并将其加载到Spark DataFrame中。接下来,使用 .show() 方法查看数据的前几行,使用 .describe().show() 方法获取数据的摘要信息。可以使用 .filter 方法进行条件筛选和过滤操作,例如 data.filter(data[‘column_name’] > 10) 表示筛选出 column_name 列中大于10的数据。还可以使用 groupBy 方法进行数据聚合操作,例如 data.groupBy(‘column_name’).sum() 表示按 column_name 列进行分组,并对其他列进行求和。最后,使用 .write.parquet 方法将处理后的数据导出到Parquet文件。
总结
Python在大数据处理和分析方面具有广泛的应用。以下是Python在大数据处理和分析中的一些关键点总结:
-
Pandas库:Pandas是Python中最常用的数据处理和分析库之一。它提供了高效的数据结构和数据分析工具,可以轻松处理和操作大型数据集。Pandas库可以用于数据清洗、数据转换、数据聚合和数据可视化等任务。
-
NumPy库:NumPy是Python中用于科学计算的基础库。它提供了高性能的多维数组对象和各种数学函数,适用于处理大规模数据集。NumPy库可以用于数据存储、数据操作和数值计算等任务。
-
PySpark库:PySpark是Python中用于大数据处理和分析的库,它基于Apache Spark框架。PySpark提供了分布式数据处理和分析功能,可以处理大规模数据集。它支持并行计算、数据分片和分布式数据集操作。
-
数据清洗和预处理:在大数据处理和分析中,数据清洗和预处理是非常重要的步骤。Python提供了丰富的库和工具,例如Pandas和PySpark,可以用于数据清洗、缺失值处理、异常值检测和数据转换等任务。
-
数据分析和可视化:Python提供了各种用于数据分析和可视化的库和工具。Pandas库提供了丰富的数据分析功能,例如数据聚合、数据透视表和统计分析。Matplotlib和Seaborn库可用于数据可视化,用于创建各种类型的图表和图形。
-
机器学习和深度学习:Python在机器学习和深度学习领域也有很大的应用。库如Scikit-learn和TensorFlow提供了丰富的机器学习和深度学习算法,可以用于模型训练、特征工程和模型评估等任务。
总之,Python在大数据处理和分析方面具有强大的功能和丰富的库支持。它提供了灵活的数据处理和分析工具,适用于各种大数据场景。无论是数据清洗、数据转换、数据分析还是机器学习,Python都是一个强大且广泛使用的工具。
相关文章:

【Python入门系列】第十七篇:Python大数据处理和分析
【Python入门系列】第十七篇:Python大数据处理和分析 文章目录 前言一、数据处理和分析步骤二、Python大数据处理和分析库三、Python大数据处理和分析应用1、数据清洗和转换2、数据分析和统计3、数据可视化4、机器学习模型训练和预测5、大规模数据处理和分布式计算6…...
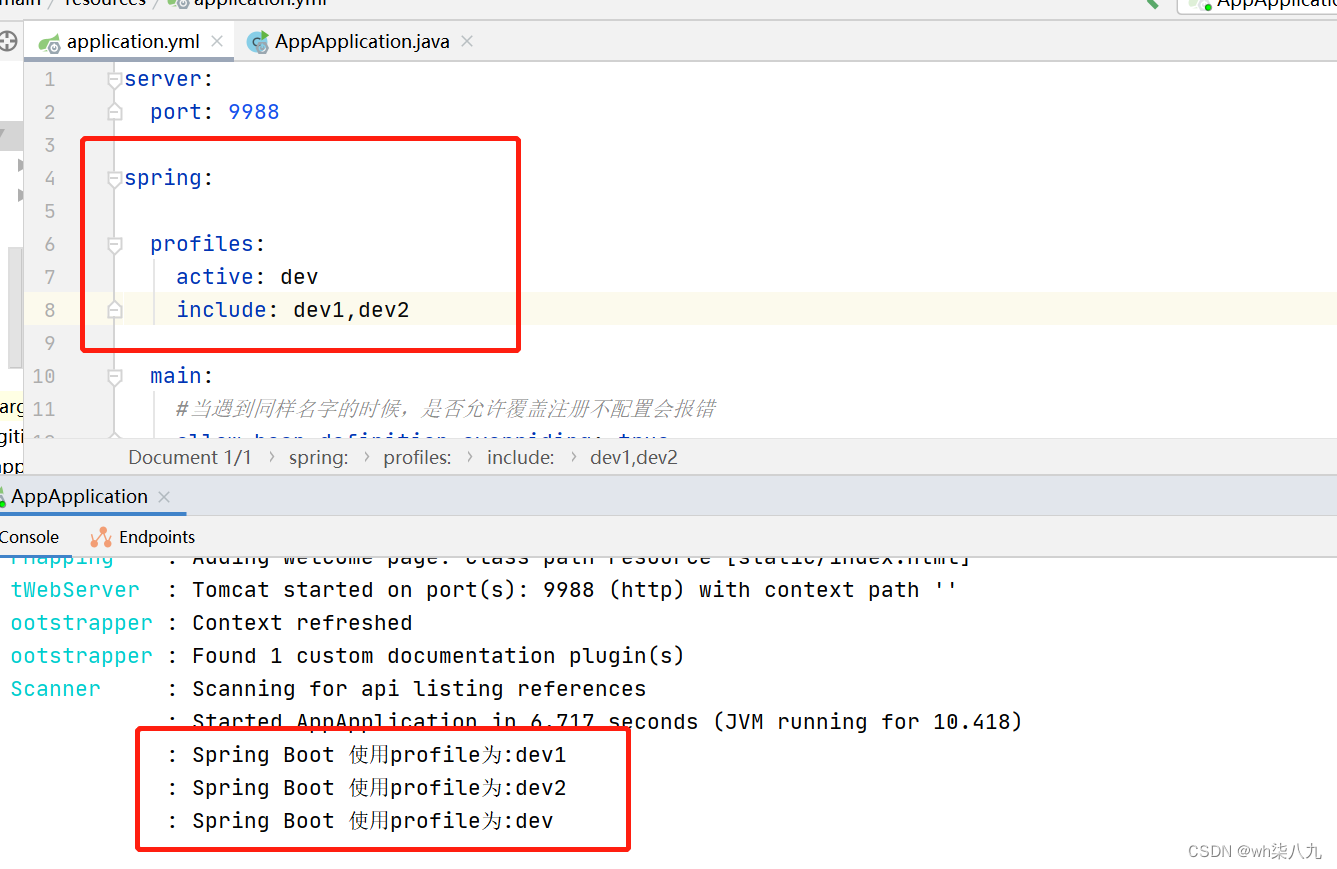
spring.profiles的使用详解
本文来说下spring.profiles.active和spring.profiles.include的使用与区别 文章目录 业务场景spring.profiles.active属性启动时指定 spring.profiles.include属性配置方法配置位置配置区别 用示例来使用和区分测试一测试二测试三 编写程序查看激活的yml文件本文小结 业务场景 …...
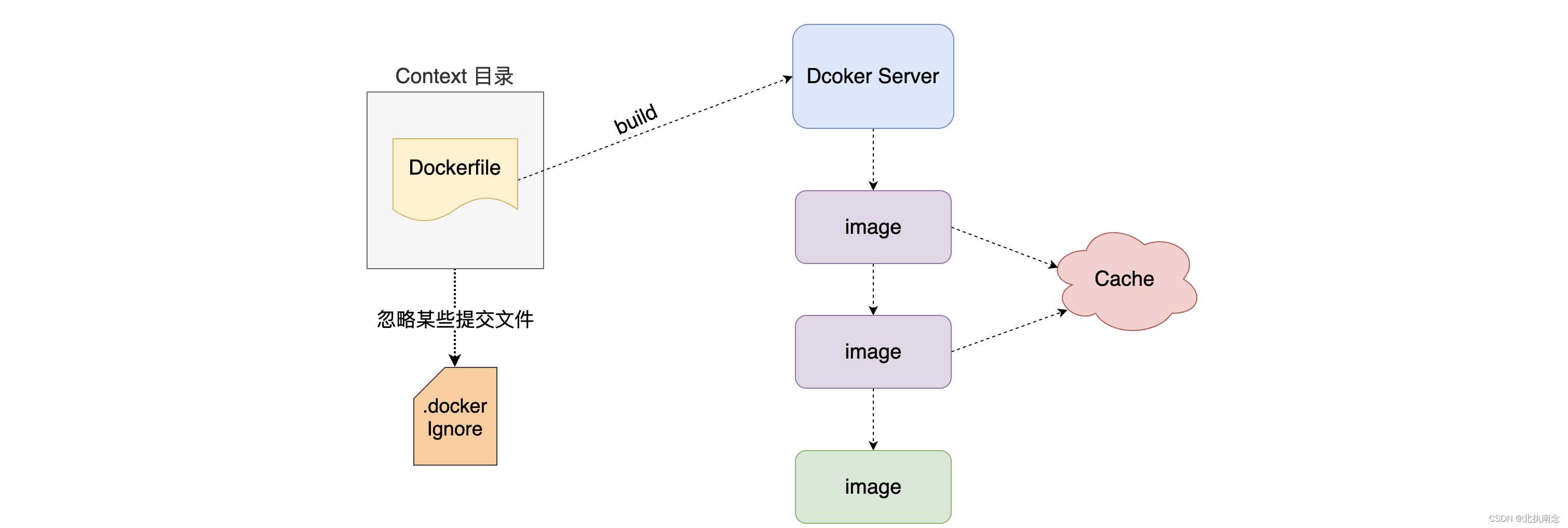
Docker使用总结
Docker 1.什么是 Docker 官网的介绍是“Docker is the world’s leading software container platform.” 官方给Docker的定位是一个应用容器平台。 Docker 是一个容器平台的领导者 Docker 容器平台 Docker 应用容器平台 application项目 Mysql Redis MongoDB ElasticSeacrh …...

MySQL 数据库的备份与还原案例分享 2023.07.12
/** 素材一 备份与还原 **/ 1 创建数据库booksDB mysql> create database booksDB; Query OK, 1 row affected (0.00 sec)2.1 创建booksDB表 mysql> use booksDB Database changed mysql> CREATE TABLE books-> (-> bk_id INT NOT NULL PRIMARY KEY,-> …...
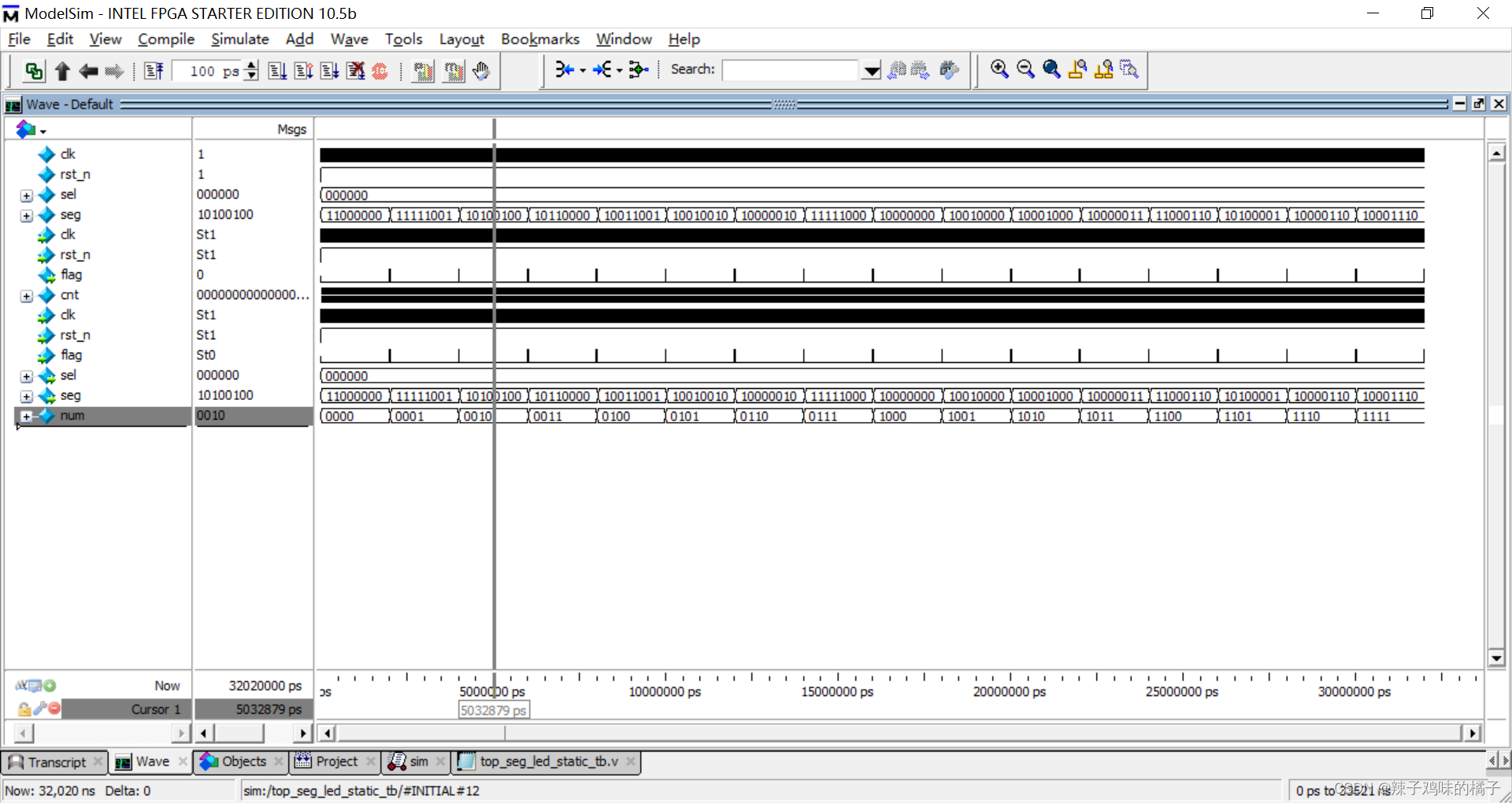
verilog实现数码管静态显示
文章目录 verilog实现数码管静态显示一、任务要求二、实验代码三、仿真代码四、仿真结果五、总结 verilog实现数码管静态显示 一、任务要求 六个数码管同时间隔0.5s显示0-f。要求:使用一个顶层模块,调用计时器模块和数码管静态显示模块。 二、实验代码…...

MySQL-DML-添加数据insert
目录 添加数据:insert insert语法 注意事项 修改数据:update update语法 注意事项: 删除数据:delete 删除语法 注意事项 总结 DML英文全称Data Manipulation Language(数据操作语言),…...
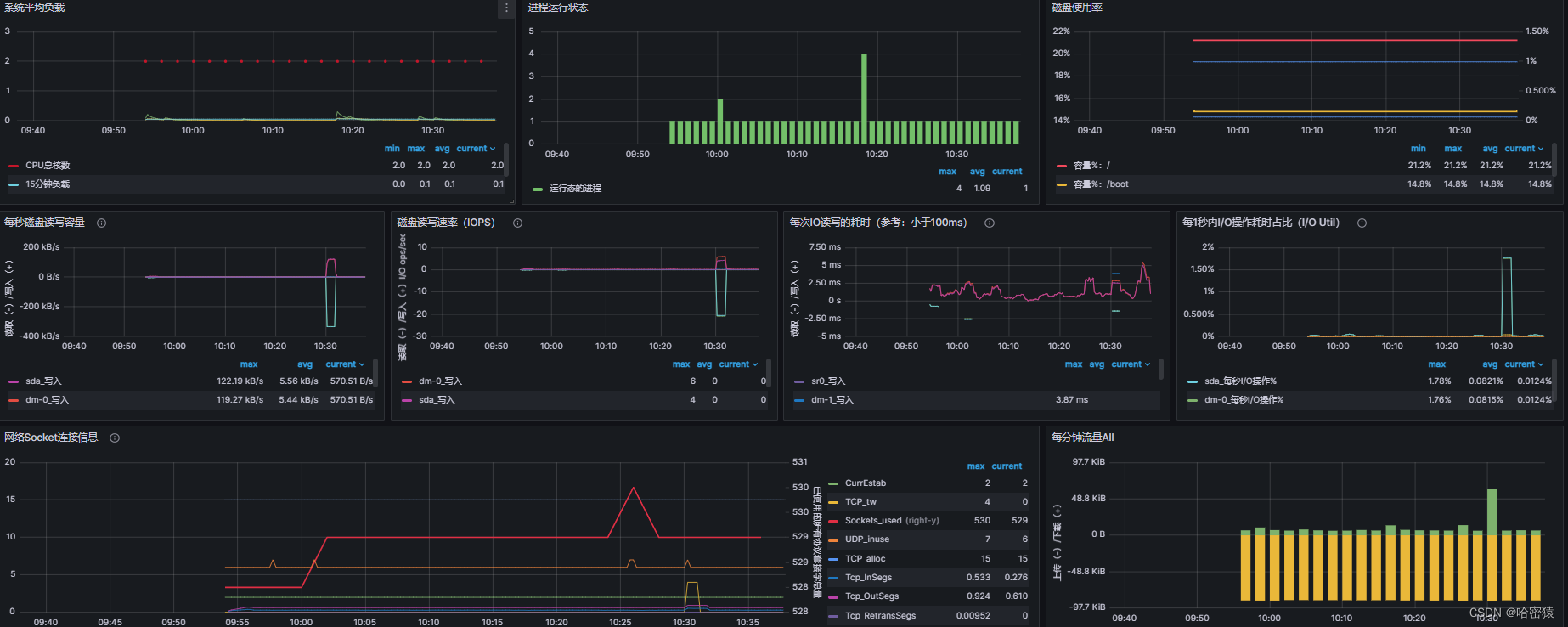
Prometheus、Grafana使用
文章目录 系统性能监控相关命令lscputopfreehtopdstatglancesiftopiptrafnethogs 监控软件Prometheus安装、使用将promethues做成服务监控其他机器 exportergrafana配置、使用密码忘记重置 系统性能监控 相关命令 lscpu lscpu 是一个 Linux 命令,用于显示关于 CP…...

UG\NX二次开发 使用throw重新抛出异常
文章作者:里海 来源网站:https://blog.csdn.net/WangPaiFeiXingYuan 简介: 在异常处理代码中,可以使用 throw 关键字来抛出异常。如果希望在捕获异常后重新抛出该异常,可以使用类似以下的代码: 在 …...
为什么单片机可以直接烧录程序的原因是什么?
单片机(Microcontroller)可以直接烧录程序的原因主要有以下几点: 集成性:单片机是一种高度集成的芯片,内部包含了处理器核心(CPU)、存储器(如闪存、EEPROM、RAM等)、输入…...

使用 uiautomator2+pytest+allure 进行 Android 的 UI 自动化测试
目录 前言: 介绍 pytest uiautomator2 allure 环境搭建 pytest uiautomator2 allure pytest 插件 实例 初始化 driver fixture 机制 数据共享 测试类 参数化 指定顺序 运行指定级别 重试 hook 函数 断言 运行 运行某个文件夹下的用例 运行某…...

Android APP性能及专项测试
Android篇 1. 性能测试 Android性能测试分为两类: 1、一类为rom版本(系统)的性能测试 2、一类为应用app的性能测试Android的app性能测试包括的测试项比如: 1、资源消耗 2、内存泄露 3、电量功耗 4、耗时 5、网络流量消耗 6、移动…...

人工智能自然语言处理:N-gram和TF-IDF模型详解
人工智能自然语言处理:N-gram和TF-IDF模型详解 1.N-gram 模型 N-Gram 是一种基于统计语言模型的算法。它的基本思想是将文本里面的内容按照字节进行大小为 N 的滑动窗口操作,形成了长度是 N 的字节片段序列。 每一个字节片段称为 gram,对所…...
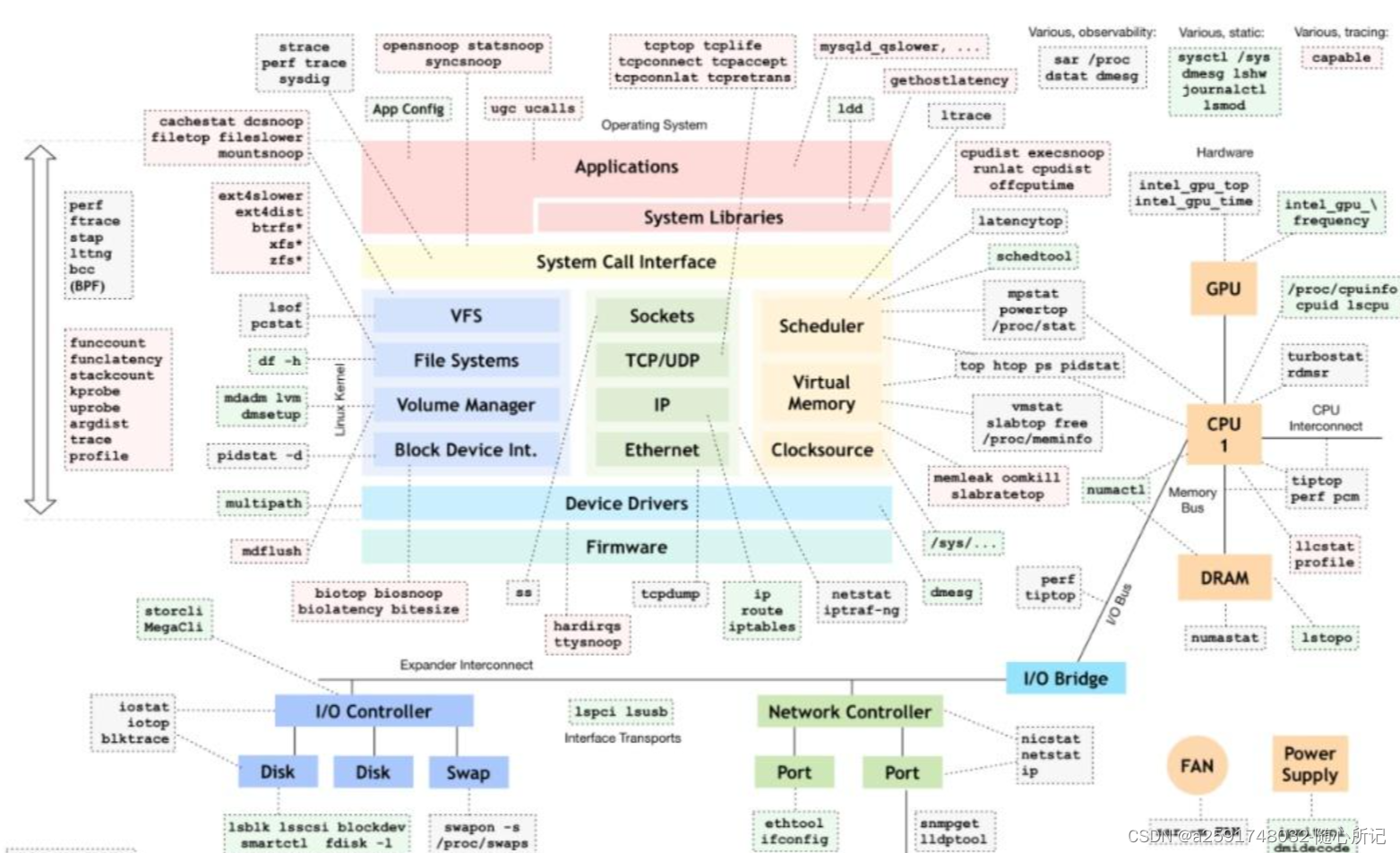
linux内核调试工具记录
Linux性能测试使用的工具在github网站可见,网址如下: slides: http://www.slideshare.net/brendangregg/linux-performance-analysis-new-tools-and-old-secrets video: https://www.usenix.org/conference/lisa14/conference-program/presentation/greg…...

XSS 攻击的检测和修复方法
XSS 攻击的检测和修复方法 XSS(Cross-Site Scripting)攻击是一种最为常见和危险的 Web 攻击,即攻击者通过在 Web 页面中注入恶意代码,使得用户在访问该页面时,恶意代码被执行,从而导致用户信息泄露、账户被…...

Spring后置处理器BeanFactoryPostProcessor与BeanPostProcessor源码解析
文章目录 一、简介1、BeanFactoryPostProcessor2、BeanPostProcessor 二、BeanFactoryPostProcessor 源码解析1、BeanDefinitionRegistryPostProcessor 接口实现类的处理流程2、BeanFactoryPostProcessor 接口实现类的处理流程3、总结 三、BeanPostProcessor 源码解析 一、简介…...
NXP i.MX 6ULL工业开发板硬件说明书( ARM Cortex-A7,主频792MHz)
前 言 本文档主要介绍TLIMX6U-EVM评估板硬件接口资源以及设计注意事项等内容。 创龙科技TLIMX6U-EVM是一款基于NXP i.MX 6ULL的ARM Cortex-A7高性能低功耗处理器设计的评估板,由核心板和评估底板组成。核心板经过专业的PCB Layout和高低温测试验证,稳…...
Ubuntu 放弃了战斗向微软投降
导读这几天看到 Ubuntu 放弃 Unity 和 Mir 开发,转向 Gnome 作为默认桌面环境的新闻,作为一个Linux十几年的老兵和Linux桌面的开发者,内心颇感良多。Ubuntu 做为全世界Linux界的桌面先驱者和创新者,突然宣布放弃自己多年开发的Uni…...
高并发的哲学原理(六)-- 拆分网络单点(下):SDN 如何替代百万人民币的负载均衡硬件
上一篇文章的末尾,我们利用负载均衡器打造了一个五万 QPS 的系统,本篇文章我们就来了解一下负载均衡技术的发展历程,并一起用 SDN(软件定义网络)技术打造出一个能够扛住 200Gbps 的负载均衡集群。 负载均衡发展史 F5 …...

用OpenCV进行图像分割--进阶篇
1. 引言 大家好,我的图像处理爱好者们! 在上一篇幅中,我们简单介绍了图像分割领域中的基础知识,包含基于固定阈值的分割和基于OSTU的分割算法。这一次,我们将通过介绍基于色度的分割来进一步巩固大家的基础知识。 闲…...
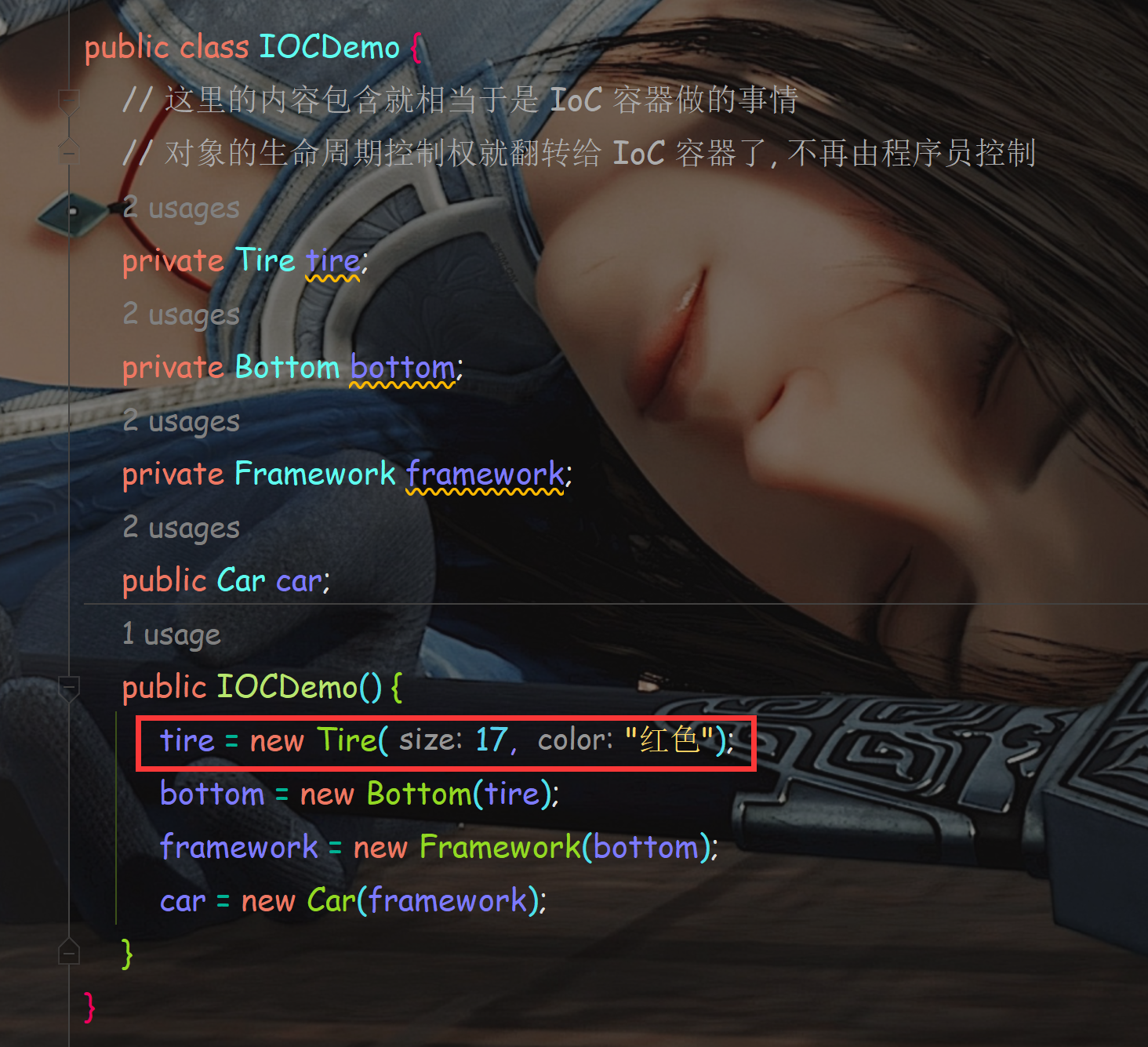
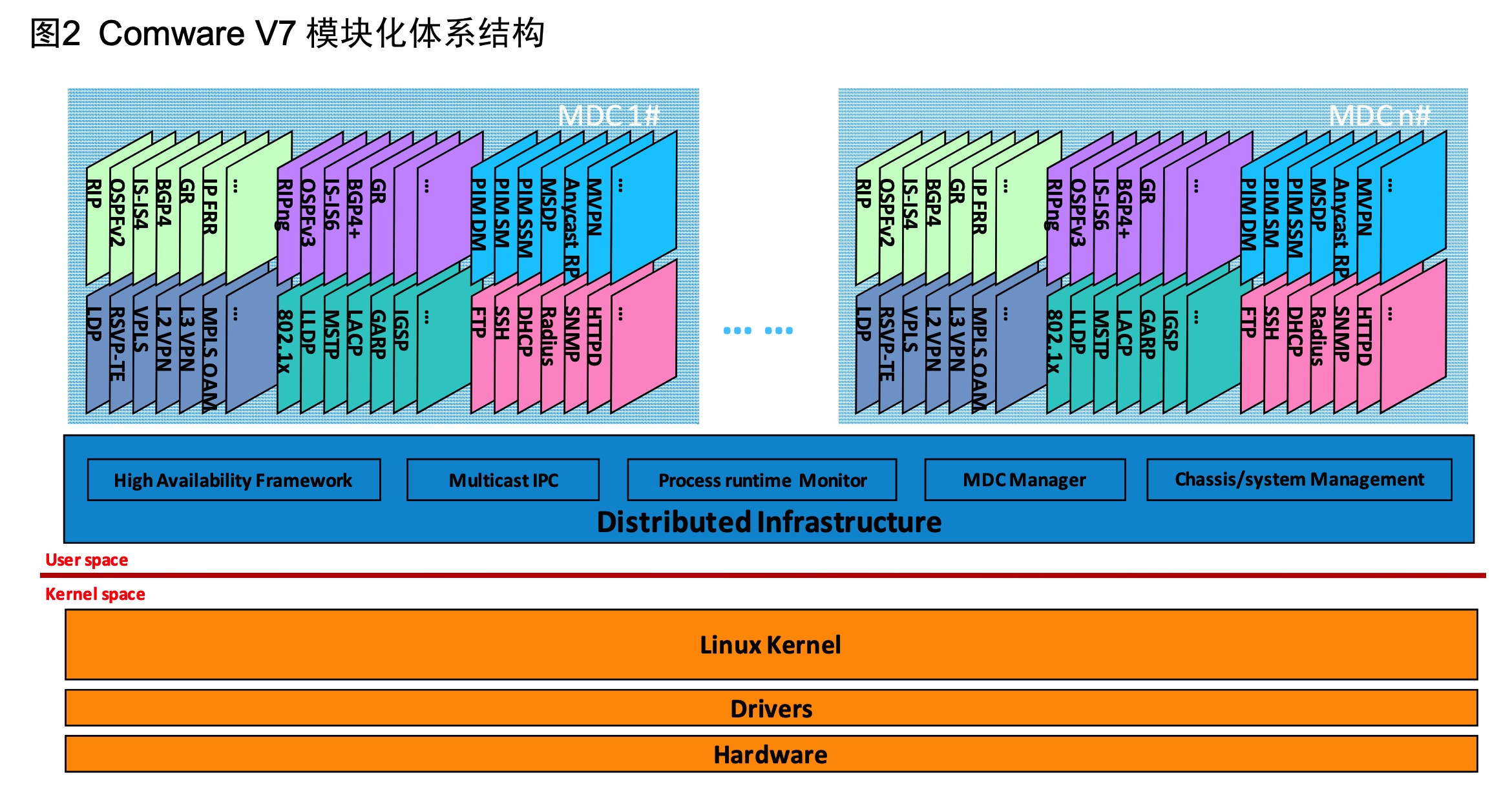
Spring框架概述及核心设计思想
文章目录 一. Spring框架概述1. 什么是Spring框架2. 为什么要学习框架?3. Spring框架学习的难点 二. Spring核心设计思想1. 容器是什么?2. IoC是什么?3. Spring是IoC容器4. DI(依赖注入)5. DL(依赖查找&…...

VRCT:打破虚拟社交语言壁垒的实时翻译解决方案
VRCT:打破虚拟社交语言壁垒的实时翻译解决方案 【免费下载链接】VRCT VRCT(VRChat Chatbox Translator & Transcription) 项目地址: https://gitcode.com/gh_mirrors/vr/VRCT 在全球化的虚拟社交平台VRChat中,语言差异常常成为跨文化交流的最…...

AudioSeal效果展示:实测音频隐形水印,听不出区别但能精准检测
AudioSeal效果展示:实测音频隐形水印,听不出区别但能精准检测 1. 音频水印技术概述 1.1 什么是音频隐形水印 音频隐形水印是一种将数字标识信息嵌入到音频信号中的技术,这些信息对人类听觉系统几乎不可感知,但可以通过专用算法…...

JavaScript动态交互:在网页中实时调整参数并预览LiuJuan生成效果
JavaScript动态交互:在网页中实时调整参数并预览LiuJuan生成效果 你是不是也遇到过这种情况?想用AI模型生成图片,但每次调整参数都要在代码里改来改去,然后重新运行脚本,等半天才能看到效果。整个过程就像在开盲盒&am…...
)
从 0 开始讲透 C++ Lambda(对标 Java)
在写 C 多线程或 STL 时,经常会看到这样的代码:std::thread t([]{ std::cout << "Hello C Thread\n"; });很多人第一反应:这 [] 是什么?为什么和 Java 不一样?一、先给结论(先建立整体认知…...

第4章 编码规范-4.1 命名规范
在Python中,变量、常量、模块、包、函数、类、对象、属性、方法和异常类都具有一定的命名规范。但是,这些命名规范都是通用性规范,而不是强制性规范,所以具体的命名规范还需要以开发项目的要求为主。(1)变量…...

【Frida Android】实战篇:Frida-Trace 进阶追踪——JNI 函数参数捕获与修改
1. 为什么需要捕获JNI函数参数? 在Android安全分析和逆向工程中,JNI函数往往是关键突破口。很多应用会把核心逻辑放在native层实现,比如加密算法、授权验证、敏感数据处理等。单纯Hook Java层方法可能无法触及这些关键逻辑,这时候…...

每日股票分析自动化:基于Ollama的daily_stock_analysis镜像实战教程
每日股票分析自动化:基于Ollama的daily_stock_analysis镜像实战教程 1. 为什么需要本地化AI股票分析工具 在金融投资领域,及时获取准确的股票分析至关重要。传统方式需要人工收集数据、分析图表、撰写报告,整个过程耗时耗力。而基于大语言模…...

SolidWorks2021设计库隐藏技巧:如何自定义Toolbox标准件库满足企业需求
SolidWorks 2021企业级Toolbox深度定制:打造标准化设计引擎 在企业级机械设计环境中,标准化程度直接决定了团队协作效率和设计质量。SolidWorks 2021的Toolbox功能远不止是一个标准件库,当经过深度定制后,它能成为企业设计流程的中…...

天翼网盘网页版绕过50M限制下载大文件?F12开发者工具实战教程
突破网页端下载限制的浏览器开发者工具实战指南 在云存储服务日益普及的今天,许多平台为了推广客户端应用,会在网页端设置各种功能限制。对于技术爱好者而言,这些限制往往可以通过浏览器内置的开发者工具进行突破。本文将详细介绍如何利用F12…...

Cesium使用
Cesium官网:https://cesiumjs.org 官方API文档:https://cesium.com/learn/ion-sdk/ref-doc 中文API文档:https://cesium.xin/cesium/cn/Documentation1.95 https://cesium.xin Cesium中文社区:http://cesiumcn.org …...