如何使用GPT作为SQL查询引擎的自然语言
生成的AI输出并不总是可靠的,但是下面我会讲述如何改进你的代码和查询的方法,以及防止发送敏感数据的方法。与大多数生成式AI一样,OpenAI的API的结果仍然不完美,这意味着我们不能完全信任它们。幸运的是,现在我们可以编写代码询问GPT如何计算响应,然后如果认可该方法,那我们可以自己运行代码。这意味着我们可以提出自然语言问题,比如“去年按地区的总销售额是多少?”,并且对响应的准确性感到可信。下面是一种快速而简单的技术,用于使用GPT设置自己的数据库的自然语言查询:
- 将数据的结构、一些示例行或两者都放入一个文本字符串中。
- 使用该信息加上你的自然语言问题来构建一个“提示”给AI。
- 将提示发送到OpenAI的GPT-3.5-turbo API,并请求一个SQL查询来回答您的问题。在数据集上运行返回的SQL来计算您的答案。
- (可选)创建一个交互式应用程序,以便轻松地使用纯英语查询数据集。
这种方法在处理现实世界的数据时具有几个优点。通过仅发送数据结构和一些示例行(可以包含虚假数据),无需将实际敏感数据发送给OpenAI。如果你的数据超过OpenAI的提示大小限制,也不必担心。通过请求SQL而不是最终答案,检查GPT如何生成答案的能力已经内置到了该过程中。如果真正想要使用生成式AI来开发企业级查询,可以借用一些工具,比如LangChain,它是一个用于处理多个不同的大型语言模型(LLM)的框架,不仅限于OpenAI的GPT。OpenAI最近还宣布了在API请求中包含函数调用的可能性,旨在使查询和类似任务更容易和可靠。但对于快速原型或您自己的使用,这里描述的过程是一个简单的入门方法。我的演示是用R完成的,但这种技术在几乎任何编程语言中都可以使用。
步骤1:将示例数据转换为单个字符字符串
这一步中的示例数据可以包括数据库模式和/或几行数据。将其全部转换为单个字符字符串非常重要,因为它将成为你将发送给GPT 3.5的更大文本字符串查询的一部分。 如果你的数据已经在SQL数据库中,这一步应该很容易。如果不是,我建议将其转换为可查询的SQL格式。为什么?在测试R和SQL代码结果后,我对GPT生成的SQL代码比其R代码更有信心。(我怀疑这是因为LLM在训练时使用了更多的SQL数据而不是R数据。) 在R中,sqldf包允许在R数据框上运行SQL查询,这是我在这个示例中将使用的工具。Python中也有类似的sqldf库。对于性能很重要的大型数据,你还可以查看duckdb项目。以下代码将数据文件导入R,使用sqldf函数查看如果数据框是一个SQL数据库表,SQL模式会是什么样子,使用head函数提取三行示例数据,并将模式和示例数据都转换为字符字符串。补充:ChatGPT编写了将数据转换为单个字符串的基本R部分的代码(通常我会使用paste函数执行这些任务)。
library(rio)
library(dplyr)
library(sqldf)
library(glue)
states <- rio::import("https://raw.githubusercontent.com/smach/SampleData/main/states.csv") |>filter(!is.na(Region))
states_schema <- sqldf("PRAGMA table_info(states)")
states_schema_string <- paste(apply(states_schema, 1, paste, collapse = "\t"), collapse = "\n")
states_sample <- dplyr::sample_n(states, 3)
states_sample_string <- paste(apply(states_sample, 1, paste, collapse = "\t"), collapse = "\n")
步骤2:为LLM创建提示
格式应该类似于“假设你是一名数据科学家。你有一个名为{table_name}的SQLite表,其模式如下:{schema}。前几行数据如下所示:{rows_sample}。基于这些数据,编写一个SQL查询来回答以下问题:{query}。只返回SQL,不包括解释。”。以下函数创建了这种类型格式的查询,接受数据模式、示例行、用户查询和表名作为参数。
create_prompt <- function(schema, rows_sample, query, table_name) {glue::glue("Act as if you're a data scientist. You have a SQLite table named {table_name} with the following schema:
```{schema}```
The first rows look like this:
```{rows_sample}```
Based on this data, write a SQL query to answer the following question: {query}. Return the SQL query ONLY. Do not include any additional explanation."
)
}
步骤3:将数据发送到OpenAI的API
你可以先将数据复制粘贴到OpenAI的Web界面之一中,以在ChatGPT或OpenAI API playground中查看结果。ChatGPT不收费,但无法调整结果。Playground允许设置诸如温度(即回答的“随机性”或创造性程度)和要使用的模型等参数。对于SQL代码,我将温度设置为0。
接下来,我将一个自然语言问题保存到变量question中,使用我的函数创建一个提示,并查看将该提示粘贴到API playground中会发生什么:
> my_query <- "What were the highest and lowest Population changes in 2020 by Division?"
> my_prompt <- get_query(states_schema_string, states_sample_string, my_query, "states")
> cat(my_prompt)
Act as if you're a data scientist. You have a SQLite table named states with the following schema:
```
0 State TEXT 0 NA 0
1 Pop_2000 INTEGER 0 NA 0
2 Pop_2010 INTEGER 0 NA 0
3 Pop_2020 INTEGER 0 NA 0
4 PctChange_2000 REAL 0 NA 0
5 PctChange_2010 REAL 0 NA 0
6 PctChange_2020 REAL 0 NA 0
7 State Code TEXT 0 NA 0
8 Region TEXT 0 NA 0
9 Division TEXT 0 NA 0
```
The first rows look like this:
```Delaware 783600 897934 989948 17.6 14.6 10.2 DE South South Atlantic
Montana 902195 989415 1084225 12.9 9.7 9.6 MT West Mountain
Arizona 5130632 6392017 7151502 40.0 24.6 11.9 AZ West Mountain```
Based on this data, write a SQL query to answer the following question: What were the highest and lowest Population changes in 2020 by Division?. Return the SQL query ONLY. Do not include any additional explanation.
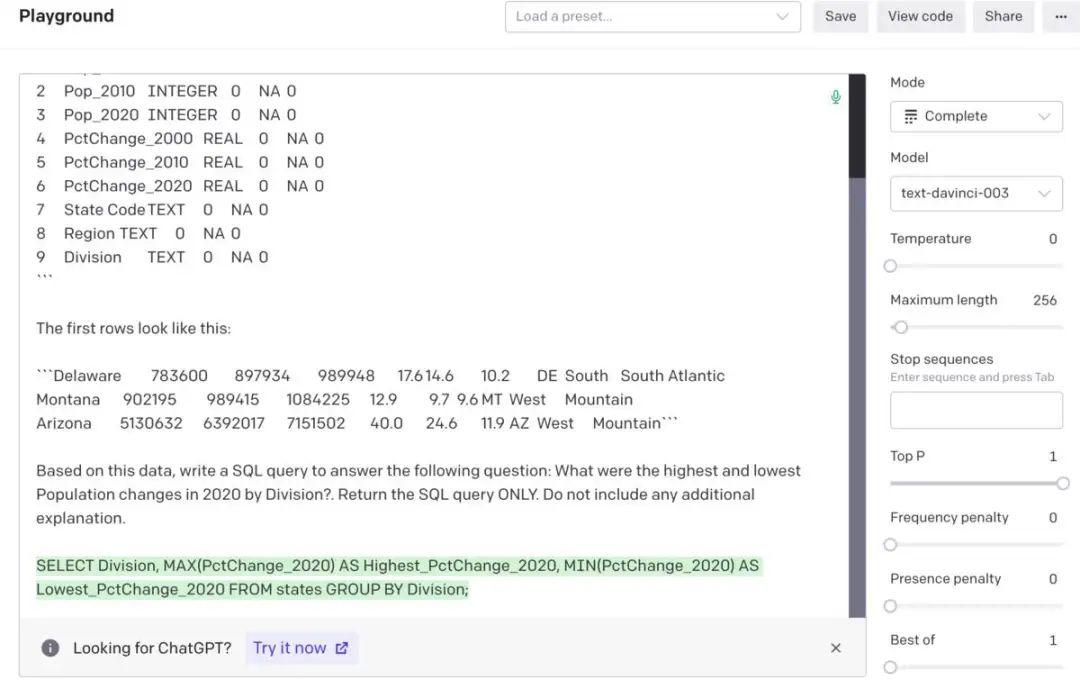
提示输入OpenAI API playground和生成的SQL代码
以下是我运行建议的SQL时的结果:
sqldf("SELECT Division, MAX(PctChange_2020) AS Highest_PctChange_2020, MIN(PctChange_2020) AS Lowest_PctChange_2020 FROM states GROUP BY Division;")Division Highest_PctChange_2020 Lowest_PctChange_2020
1 East North Central 4.7 -0.1
2 East South Central 8.9 -0.2
3 Middle Atlantic 5.7 2.4
4 Mountain 18.4 2.3
5 New England 7.4 0.9
6 Pacific 14.6 3.3
7 South Atlantic 14.6 -3.2
8 West North Central 15.8 2.8
9 West South Central 15.9 2.7
步骤4:执行由GPT返回的SQL代码结果
通过编程方式将数据发送到OpenAI并从中返回会比将其复制粘贴到Web界面中更方便。有一些R包可以用于与OpenAI API进行交互。以下代码块使用该包向API发送提示,存储API响应,提取包含所请求SQL代码的文本部分,复制该代码,并在数据上运行SQL。
library(openai)
my_results <- openai::create_chat_completion(model = "gpt-3.5-turbo", temperature = 0, messages = list(list(role = "user", content = my_prompt)
))
the_answer <- my_results$choices$message.content
cat(the_answer)
SELECT Division, MAX(PctChange_2020) AS Highest_Population_Change, MIN(PctChange_2020) AS Lowest_Population_Change
FROM states
GROUP BY Division;
sqldf(the_answer)Division Highest_Population_Change Lowest_Population_Change
1 East North Central 4.7 -0.1
2 East South Central 8.9 -0.2
3 Middle Atlantic 5.7 2.4
4 Mountain 18.4 2.3
5 New England 7.4 0.9
6 Pacific 14.6 3.3
7 South Atlantic 14.6 -3.2
8 West North Central 15.8 2.8
9 West South Central 15.9 2.7
如果你想使用OpenAI API,你需要一个OpenAI API密钥。对于这个包,密钥应该存储在系统环境变量中,例如。请注意,这个API不是免费使用的,但在我把它变成我的编辑器之前,我一天运行了这个项目十几次,我的总账户使用量是1美分。
步骤5(可选):创建一个交互式应用程序
现在你已经拥有了在R工作流中运行查询的所有所需代码,可以在脚本或终端中使用它。但是,如果你想创建一个用于以自然语言查询数据的交互式应用程序,我提供了一个基本的Shiny应用程序的代码供你使用。如果你打算发布一个供他人使用的应用程序,而不仅仅是自己使用,你需要加固代码以防止恶意查询,添加更好的错误处理和解释性标签,改进样式,并对企业使用进行扩展。 与此同时,以下代码可以帮助开始创建一个用于使用自然语言查询数据集的交互式应用程序:
library(shiny)
library(openai)
library(dplyr)
library(sqldf)
# Load hard-coded dataset
states <- read.csv("states.csv") |>dplyr::filter(!is.na(Region) & Region != "")
states_schema <- sqldf::sqldf("PRAGMA table_info(states)")
states_schema_string <- paste(apply(states_schema, 1, paste, collapse = "\t"), collapse = "\n")
states_sample <- dplyr::sample_n(states, 3)
states_sample_string <- paste(apply(states_sample, 1, paste, collapse = "\t"), collapse = "\n")
# Function to process user input
get_prompt <- function(query, schema = states_schema_string, rows_sample = states_sample_string, table_name = "states") {my_prompt <- glue::glue("Act as if you're a data scientist. You have a SQLite table named {table_name} with the following schema:
```{schema}```
The first rows look like this:
```{rows_sample}```
Based on this data, write a SQL query to answer the following question: {query} Return the SQL query ONLY. Do not include any additional explanation.")print(my_prompt)return(my_prompt)
}
ui <- fluidPage(titlePanel("Query state database"),sidebarLayout(sidebarPanel(textInput("query", "Enter your query", placeholder = "e.g., What is the total 2020 population by Region?"),actionButton("submit_btn", "Submit")),mainPanel(uiOutput("the_sql"),br(),br(),verbatimTextOutput("results")))
)
server <- function(input, output) {
# Create the prompt from the user query to send to GPTthe_prompt <- eventReactive(input$submit_btn, {req(input$query, states_schema_string, states_sample_string)my_prompt <- get_prompt(query = input$query)})
# send prompt to GPT, get SQL, run SQL, print results
observeEvent(input$submit_btn, {req(the_prompt()) # text to send to GPT
# Send results to GPT and get response# withProgress adds a Shiny progress bar. Commas now needed after each statementwithProgress(message = 'Getting results from GPT', value = 0, { # Add Shiny progress messagemy_results <- openai::create_chat_completion(model = "gpt-3.5-turbo", temperature = 0, messages = list(list(role = "user", content = the_prompt()))) the_gpt_sql <- my_results$choices$message.content
# print the SQLsql_html <- gsub("\n", "<br />", the_gpt_sql) sql_html <- paste0("<p>", sql_html, "</p>")
# Run SQL on data to get resultsgpt_answer <- sqldf(the_gpt_sql) setProgress(value = 1, message = 'GPT results received') # Send msg to user that })# Print SQL and resultsoutput$the_sql <- renderUI(HTML(sql_html))
if (is.vector(gpt_answer) ) {output$results <- renderPrint(gpt_answer) } else {output$results <- renderPrint({ print(gpt_answer) }) }
})
}
shinyApp(ui = ui, server = server)
作者: MSharon Machlis
更多技术干货请关注公号“云原生数据库”
squids.cn,目前可体验全网zui低价RDS,免费的迁移工具DBMotion、SQL开发工具等。
相关文章:
如何使用GPT作为SQL查询引擎的自然语言
生成的AI输出并不总是可靠的,但是下面我会讲述如何改进你的代码和查询的方法,以及防止发送敏感数据的方法。与大多数生成式AI一样,OpenAI的API的结果仍然不完美,这意味着我们不能完全信任它们。幸运的是,现在我们可以…...

Servlet3.0上传文件
页面: <!DOCTYPE html> <html> <head> <meta charset"UTF-8"> <title>文件上传</title> </head> <body> <form action"fileup" enctype"multipart/form-data" method"…...

【ARM Cache 系列文章 6 番外篇 – MMU, MPU, SMMU, PMU 差异与关系】
文章目录 MMU 与 MPU 之间的关系MMU 与 SMMU 之间的关系MMU 与 PMU 之间的关系 上篇文章:ARM Cache 系列文章 5 – 内存屏障ISB/DSB/DMB MMU 与 MPU 之间的关系 MMU(Memory Management Unit)和MPU(Memory Protection Unit&#…...

NetSuite ERP顾问的进阶之路
目录 1.修养篇 1.1“道”是什么?“器”是什么? 1.2 读书这件事儿 1.3 十年计划的力量 1.3.1 一日三省 1.3.2 顾问损益表 1.3.3 阶段课题 2.行为篇 2.1协作 2.2交流 2.3文档管理 2.4时间管理 3.成长篇 3.1概念能力 3.1.1顾问的知识结构 …...
js 新浏览器打开页面
博主gzh:“程序员野区”,回复“加群”,可进博主web前端微信群 效果如下 setTimeout(()>{var url "https://blog.csdn.net/xuelang532777032?typeblog"; //要打开的网页地址var features "height500, width800, top100, left100, …...
jmeter软件测试实验(附源码以及配置)
jmeter介绍 JMeter是一个开源的性能测试工具,由Apache软件基金会开发和维护。它主要用于对Web应用程序、Web服务、数据库和其他类型的服务进行性能测试。JMeter最初是为测试Web应用程序而设计的,但现在已经扩展到支持更广泛的应用场景。 JMeter 可对服务…...
ZooKeeper原理剖析
1.ZooKeeper简介 ZooKeeper是一个分布式、高可用性的协调服务。在大数据产品中主要提供两个功能: 帮助系统避免单点故障,建立可靠的应用程序。提供分布式协作服务和维护配置信息。 2.ZooKeeper结构 ZooKeeper集群中的节点分为三种角色:Le…...

【算组合数】CF1833 F
少见地秒了这道1700,要是以后都这样就好了.... Problem - F - Codeforces 题意: 给定一个数列,让你在这个数列里找一个大小为M的子集,使得极差不超过M 思路: 子集,不是子序列,说明和顺序无…...
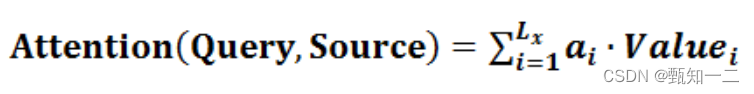
Attention详解(自用)
encoder-decoder 分心模型:没有引入注意力的模型在输入句子比较短的时候问题不大,但是如果输入句子比较长,此时所有语义完全通过一个中间语义向量来表示,单词自身的信息已经消失,可想而知会丢失很多细节信息࿰…...

pptx转pdf工具类
引入依赖 <dependency><groupId>org.apache.poi</groupId><artifactId>poi</artifactId><version>5.0.0</version></dependency><dependency><groupId>org.apache.poi</groupId><artifactId>poi-ooxm…...

2023华为OD统一考试(B卷)题库清单(持续收录中)以及考点说明
目录 专栏导读2023 B卷 “新加题”(100分值)2023Q2 100分2023Q2 200分2023Q1 100分2023Q1 200分2022Q4 100分2022Q4 200分牛客练习题 专栏导读 本专栏收录于《华为OD机试(JAVA)真题(A卷B卷)》。 刷的越多&…...
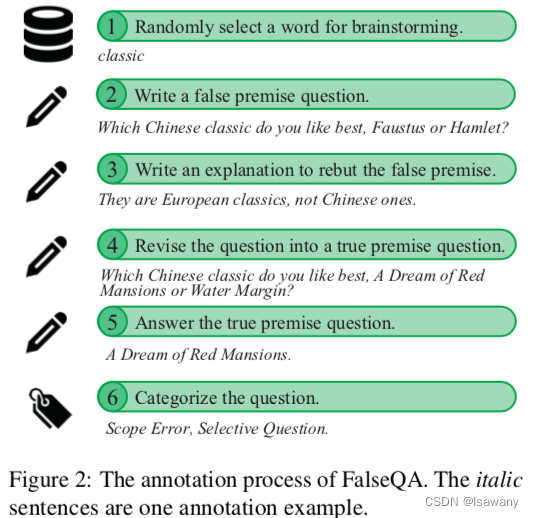
论文笔记--Won’t Get Fooled Again: Answering Questions with False Premises
论文笔记--Won’t Get Fooled Again: Answering Questions with False Premises 1. 文章简介2. 文章概括3 文章重点技术3.1 大模型面对FPQs的表现3.2 False QAs数据集3.3 训练和评估 4. 文章亮点5. 原文传送门 1. 文章简介 标题:Won’t Get Fooled Again: Answerin…...

【Django】include app_name和namespace的区别
app_name 区分不同app的url的name,防止不同app之间,url_name的重名,引用时加入app_name:name namespace 区分不同路由 include同一个view module的情况, 让不同路由进入同一个view中,进行reverse时,根据对…...
(黑客)自学笔记
特别声明: 此教程为纯技术分享!本教程的目的决不是为那些怀有不良动机的人提供及技术支持!也不承担因为技术被滥用所产生的连带责任!本教程的目的在于最大限度地唤醒大家对网络安全的重视,并采取相应的安全措施&#x…...

【期末课程设计】学生成绩管理系统
因其独特,因其始终如一 文章目录 一、学生成绩管理系统介绍 二、学生成绩管理系统设计思路 三、源代码 1. test.c 2. Student Management System.c 3.Stu_System.c 4.Teacher.c 5.Student Management System.h 前言: 学生成绩管理系统含教师…...
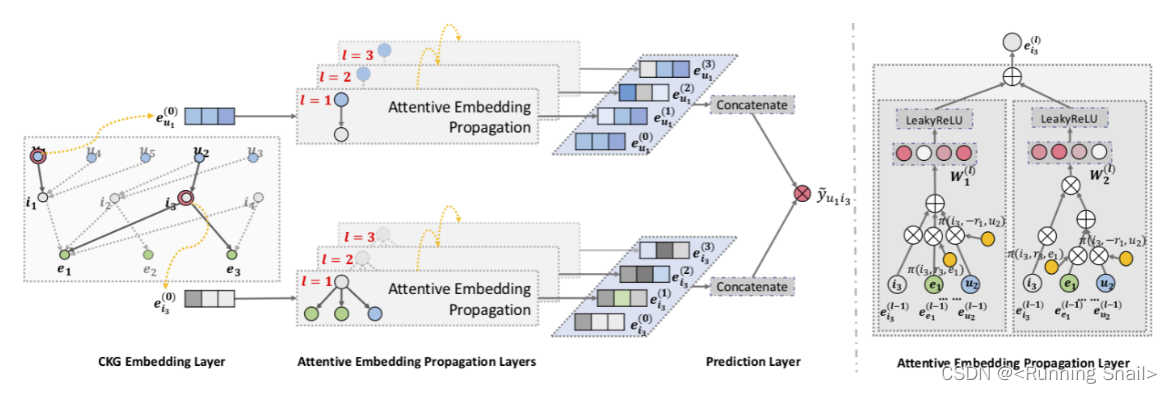
【论文笔记】KDD2019 | KGAT: Knowledge Graph Attention Network for Recommendation
Abstract 为了更好的推荐,不仅要对user-item交互进行建模,还要将关系信息考虑进来 传统方法因子分解机将每个交互都当作一个独立的实例,但是忽略了item之间的关系(eg:一部电影的导演也是另一部电影的演员)…...

ES6:基础使用,积累
一、理解ES6 ES6是ECMAScript 6.0的简称,也被称为ES2015。它是ECMAScript的第六个版本,是JavaScript标准的下一个重大更新。ES6于2015年6月发布,新增了许多新的语言特性和API,包括箭头函数、let和const关键字、模板字符串、解构赋…...

Android端上传文件到Spring Boot后端
准备 确定好服务器端文件保存的位置确定好请求参数名(前后端要保持一致的喔)如果手机是通过usb连接到电脑的,需要执行一下: adb reverse tcp:8080 tcp:8080 AndroidManifest.xml的<application/>节点中加上: android:usesC…...
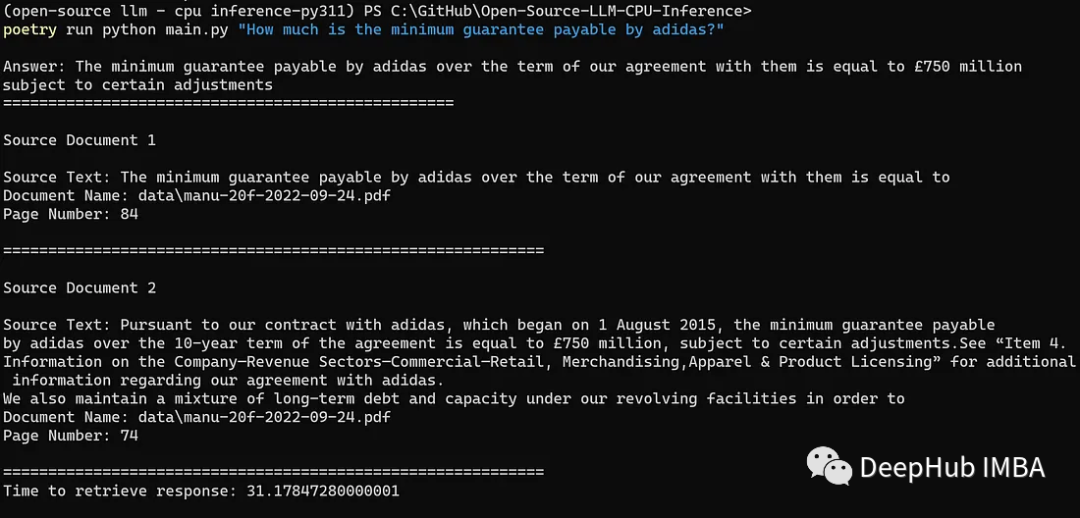
使用GGML和LangChain在CPU上运行量化的llama2
Meta AI 在本周二发布了最新一代开源大模型 Llama 2。对比于今年 2 月发布的 Llama 1,训练所用的 token 翻了一倍,已经达到了 2 万亿,对于使用大模型最重要的上下文长度限制,Llama 2 也翻了一倍。 在本文,我们将紧跟趋…...

微服务基础理论
微服务简介 微服务Microservices之父,马丁.福勒,对微服务大概的概述如下: 就目前而言,对于微服务业界并没有一个统一的、标准的定义(While there is no precise definition of this architectural style ) 。但通在其…...

每日一题 力扣 3548. 等和矩阵分割 II 前缀和 哈希表 C++ 题解
文章目录题目描述思路简述代码实现复杂度分析踩坑记录题目描述 力扣 3548. 等和矩阵分割 II 示例 1: 输入: grid [[1,4],[2,3]] 输出: true 解释: 在第 0 行和第 1 行之间进行水平分割,结果两部分的元素和为 1 4 5…...

终极Ghidra安装指南:5分钟在Ubuntu系统快速部署逆向工程神器
终极Ghidra安装指南:5分钟在Ubuntu系统快速部署逆向工程神器 【免费下载链接】ghidra_installer Helper scripts to set up OpenJDK 11 and scale Ghidra for 4K on Ubuntu 18.04 / 18.10 项目地址: https://gitcode.com/gh_mirrors/gh/ghidra_installer 想要…...

Java中正确比较数组最小值的两种方法
本文旨在解决Java Stream 当API使用min()方法获得数组最小值时,返回optionalint类型导致的直接比较错误。我们将深入探讨这个问题的根源,并提供两个有效的解决方案:一是比较Optionalint的getasint()方法,二是引入apache Commons N…...

毫米波雷达测速的“火眼金睛”:从汽车ACC到手势识别,Doppler FFT如何分辨不同速度的目标?
毫米波雷达测速的“火眼金睛”:从汽车ACC到手势识别,Doppler FFT如何分辨不同速度的目标? 在自动驾驶汽车的前方,一辆卡车突然减速,而右侧车道有摩托车正在加速超车——毫米波雷达如何在这复杂的场景中,准确…...

如何快速使用iOS App Signer:iOS应用签名完整指南
如何快速使用iOS App Signer:iOS应用签名完整指南 【免费下载链接】ios-app-signer DanTheMan827/ios-app-signer: 是一个 iOS 应用的签名工具,适合用于 iOS 开发中,帮助开发者签署和发布他们的 APP。 项目地址: https://gitcode.com/gh_mi…...

三步掌握EdgeRemover:Windows系统Edge浏览器专业卸载方案
三步掌握EdgeRemover:Windows系统Edge浏览器专业卸载方案 【免费下载链接】EdgeRemover PowerShell script to remove Microsoft Edge in a non-forceful manner. 项目地址: https://gitcode.com/gh_mirrors/ed/EdgeRemover 还在为Windows系统中Microsoft Ed…...

百川2-13B-4bits模型微调实践:提升OpenClaw特定任务准确率
百川2-13B-4bits模型微调实践:提升OpenClaw特定任务准确率 1. 为什么需要微调百川模型? 去年冬天,当我第一次用OpenClaw自动整理电脑上的技术文档时,发现了一个尴尬的问题:模型总是把Python代码片段误判为"待办…...

一文搞懂训练大模型的数据怎么准备!
谈到大模型,很多人第一反应都是模型参数大、算力强,但其实数据才是大模型真正的底座。没有足够大、足够干净的数据,再先进的模型也发挥不出威力。今天就从数据层面,把大模型训练的几个关键环节梳理清楚。 数据采集与清洗 大模型训…...

Thorium浏览器架构深度解析:基于Chromium的极致性能优化实践
Thorium浏览器架构深度解析:基于Chromium的极致性能优化实践 【免费下载链接】thorium Chromium fork named after radioactive element No. 90. Windows and MacOS/Raspi/Android/Special builds are in different repositories, links are towards the top of the…...

Windows资源管理器终极美化指南:一键添加惊艳毛玻璃效果
Windows资源管理器终极美化指南:一键添加惊艳毛玻璃效果 【免费下载链接】ExplorerBlurMica Add background Blur effect or Acrylic (Mica for win11) effect to explorer for win10 and win11 项目地址: https://gitcode.com/gh_mirrors/ex/ExplorerBlurMica …...