使用GGML和LangChain在CPU上运行量化的llama2
Meta AI 在本周二发布了最新一代开源大模型 Llama 2。对比于今年 2 月发布的 Llama 1,训练所用的 token 翻了一倍,已经达到了 2 万亿,对于使用大模型最重要的上下文长度限制,Llama 2 也翻了一倍。
在本文,我们将紧跟趋势介绍如何在本地CPU推理上运行量化版本的开源Llama 2。

量化快速入门
我们首先简单介绍一下量化的概念:
量化是一种减少用于表示数字或值的比特数的技术。由于量化减少了模型大小,因此它有利于在cpu或嵌入式系统等资源受限的设备上部署模型。
一种常用的方法是将模型权重从原始的16位浮点值量化为精度较低的8位整数值。

llm已经展示了出色的能力,但是它需要大量的CPU和内存,所以我们可以使用量化来压缩这些模型,以减少内存占用并加速计算推理,并且保持模型性能。我们将通过将权重存储在低精度数据类型中来降低模型参数的精度。
工具和数据
下图是我们将在这个项目中构建的文档知识问答应用程序的体系结构。

我们的测试文件是177页的曼联足球俱乐部2022年年报。
为了演示这个项目的量化结果,我们使用一个AMD Ryzen 5 5600X 6核处理器和16GB RAM (DDR4 3600)。
下面是构建这个应用程序时将使用的软件工具:
1、LangChain
LangChain是一个提供了一组广泛的集成和数据连接器,允许我们链接和编排不同的模块。可以常见聊天机器人、数据分析和文档问答等应用。
2、C Transformers
C transformer是一个Python库,它为使用GGML库并在C/ c++中实现了Transformers模型。
为了解释这个事情我们首先要了解GGML:
GGML库是一个为机器学习设计的张量库,它的目标是使大型模型能够在高性能的消费级硬件上运行。这是通过整数量化支持和内置优化算法实现的。
也就是说,llm的GGML版本(二进制格式的量化模型)可以在cpu上高性能地运行。因为我们最终是使用Python的,所以还需要C Transformers库,它其实就是为GGML模型提供了Python API。
C transformer支持一组选定的开源模型,包括像Llama、GPT4All-J、MPT和Falcon等的流行模型。

3、sentence-transformer
sentence-transformer提供了简单的方法来计算句子、文本和图像的嵌入。它能够计算100多种语言的嵌入。我们将在这个项目中使用开源的all-MiniLM-L6-v2模型。
4、FAISS
Facebook AI相似度搜索(FAISS)是一个为高效相似度搜索和密集向量聚类而设计的库。
给定一组嵌入,我们可以使用FAISS对它们进行索引,然后利用其强大的语义搜索算法在索引中搜索最相似的向量。
虽然它不是传统意义上的成熟的向量存储(如数据库管理系统),但它以一种优化的方式处理向量的存储,以实现有效的最近邻搜索。
5、Poetry
Poetry用于设置虚拟环境和处理Python包管理。相比于venv,Poetry使依赖管理更加高效和无缝。这个不是只做参考,因为conda也可以。
开源LLM
开源LLM领域已经取得了巨大的进步,在HuggingFace的开放LLM排行榜上可以找到模型。为了紧跟时代,我们选择了最新的开源Llama-2-70B-Chat模型(GGML 8位):
1、Llama 2
它是C Transformers库支持的开源模型。根据LLM排行榜排名(截至2023年7月),在多个指标中表现最佳。在原来的Llama 模型设定的基准上有了巨大的改进。
2、模型尺寸:7B
LLM将主要用于总结文档块这一相对简单的任务。因此选择了7B模型,因为我们在技术上不需要过大的模型(例如65B及以上)来完成这项任务。
3、微调版:Llama-2-7B-Chat
lama-2- 7b基本模型是为文本补全而构建的,因此它缺乏在文档问答用例中实现最佳性能所需的微调。而lama-2 - 7b - chat模型是我们的理想候选,因为它是为对话和问答而设计的。该模型被许可(部分)用于商业用途。这是因为经过微调的模型lama-2- chat模型利用了公开可用的指令数据集和超过100万个人工注释。
4、8位量化
考虑到RAM被限制为16GB, 8位GGML版本是合适的,因为它只需要9.6GB的内存而原始的非量化16位模型需要约15gb的内存
8位格式也提供了与16位相当的响应质量,而其他更小的量化格式(即4位和5位)是可用的,但它们是以准确性和响应质量为代价的。
构建步骤指导
我们已经了解了各种组件,接下来让逐步介绍如何构建文档问答应用程序。
由于已经有许多教程了,所以我们不会深入到复杂和一般的文档问答组件的细节(例如,文本分块,矢量存储设置)。在本文中,我们将把重点放在开源LLM和CPU推理方面。
1、数据处理和矢量存储
这一步的任务是:将文本分割成块,加载嵌入模型,然后通过FAISS 进行向量的存储
from langchain.vectorstores import FAISSfrom langchain.text_splitter import RecursiveCharacterTextSplitterfrom langchain.document_loaders import PyPDFLoader, DirectoryLoaderfrom langchain.embeddings import HuggingFaceEmbeddings# Load PDF file from data pathloader = DirectoryLoader('data/',glob="*.pdf",loader_cls=PyPDFLoader)documents = loader.load()# Split text from PDF into chunkstext_splitter = RecursiveCharacterTextSplitter(chunk_size=500,chunk_overlap=50)texts = text_splitter.split_documents(documents)# Load embeddings modelembeddings = HuggingFaceEmbeddings(model_name='sentence-transformers/all-MiniLM-L6-v2',model_kwargs={'device': 'cpu'})# Build and persist FAISS vector storevectorstore = FAISS.from_documents(texts, embeddings)vectorstore.save_local('vectorstore/db_faiss')
运行上面的Python脚本后,向量存储将被生成并保存在名为’vectorstore/db_faiss’的本地目录中,并为语义搜索和检索做好准备。
2、设置提示模板
我们使用lama-2 - 7b - chat模型,所以需要使用的提示模板。
一些chat的模板在这里不起作用,因为我们的Llama 2模型没有针对这种会话界面进行专门优化。所以我们需要使用更加直接的模板,例如:
qa_template = """Use the following pieces of information to answer the user's question.If you don't know the answer, just say that you don't know, don't try to make up an answer.Context: {context}Question: {question}Only return the helpful answer below and nothing else.Helpful answer:"""
需要注意的是,相对较小的LLM(如7B),对格式特别敏感。当改变提示模板的空白和缩进时,可能得到了稍微不同的输出。
3、下载lama-2 - 7b - chat GGML二进制文件
由于我们将在本地运行LLM,所以需要下载量化的lama-2 - 7b - chat模型的二进制文件。
我们可以通过访问TheBloke的Llama-2-7B-Chat GGML页面来实现,然后下载名为Llama-2-7B-Chat .ggmlv3.q8_0.bin的GGML 8位量化文件。

下载的是8位量化模型的bin文件可以保存在合适的项目子文件夹中,如/models。
这个页面还显示了每种量化格式的更多信息和详细信息:

4、LangChain集成
我们将利用C transformer和LangChain进行集成。也就是说将在LangChain中使用CTransformers LLM包装器,它为GGML模型提供了一个统一的接口。
from langchain.llms import CTransformers# Local CTransformers wrapper for Llama-2-7B-Chatllm = CTransformers(model='models/llama-2-7b-chat.ggmlv3.q8_0.bin', # Location of downloaded GGML modelmodel_type='llama', # Model type Llamaconfig={'max_new_tokens': 256,'temperature': 0.01})
这里就可以为LLM定义大量配置设置,例如最大令牌、最高k值、温度和重复惩罚等等,这些参数在我们以前的文章已经介绍过了。
这里我将温度设置为0.01而不是0,因为设置成0时,得到了奇怪的响应。
5、构建并初始化RetrievalQA
准备好提示模板和C Transformers LLM后,我们还需要编写了三个函数来构建LangChain RetrievalQA对象,该对象使我们能够执行文档问答。
from langchain import PromptTemplatefrom langchain.chains import RetrievalQAfrom langchain.embeddings import HuggingFaceEmbeddingsfrom langchain.vectorstores import FAISS# Wrap prompt template in a PromptTemplate objectdef set_qa_prompt():prompt = PromptTemplate(template=qa_template,input_variables=['context', 'question'])return prompt# Build RetrievalQA objectdef build_retrieval_qa(llm, prompt, vectordb):dbqa = RetrievalQA.from_chain_type(llm=llm,chain_type='stuff',retriever=vectordb.as_retriever(search_kwargs={'k':2}),return_source_documents=True,chain_type_kwargs={'prompt': prompt})return dbqa# Instantiate QA objectdef setup_dbqa():embeddings = HuggingFaceEmbeddings(model_name="sentence-transformers/all-MiniLM-L6-v2",model_kwargs={'device': 'cpu'})vectordb = FAISS.load_local('vectorstore/db_faiss', embeddings)qa_prompt = set_qa_prompt()dbqa = build_retrieval_qa(llm, qa_prompt, vectordb)return dbqa
6、代码整合
最后一步就是是将前面的组件组合到main.py脚本中。使用argparse模块是因为我们将从命令行将用户查询传递到应用程序中。
这里为了评估CPU推理的速度,还使用了timeit模块。
import argparseimport timeitif __name__ == "__main__":parser = argparse.ArgumentParser()parser.add_argument('input', type=str)args = parser.parse_args()start = timeit.default_timer() # Start timer# Setup QA objectdbqa = setup_dbqa()# Parse input from argparse into QA objectresponse = dbqa({'query': args.input})end = timeit.default_timer() # End timer# Print document QA responseprint(f'\nAnswer: {response["result"]}')print('='*50) # Formatting separator# Process source documents for better displaysource_docs = response['source_documents']for i, doc in enumerate(source_docs):print(f'\nSource Document {i+1}\n')print(f'Source Text: {doc.page_content}')print(f'Document Name: {doc.metadata["source"]}')print(f'Page Number: {doc.metadata["page"]}\n')print('='* 50) # Formatting separator# Display time taken for CPU inferenceprint(f"Time to retrieve response: {end - start}")
示例查询
现在是时候对我们的应用程序进行测试了。我们用以下命令询问阿迪达斯(曼联的全球技术赞助商)应支付的最低保证金额:
python main.py "How much is the minimum guarantee payable by adidas?"
结果如下:
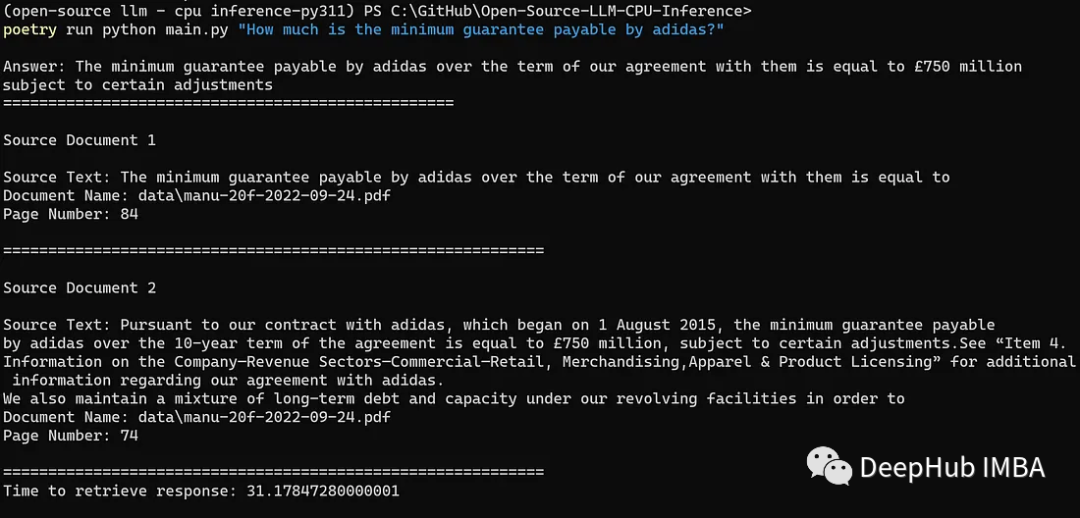
我们成功地获得了正确响应(即£7.5亿),以及语义上与查询相似的相关文档块。
从启动应用程序并生成响应的总时间为31秒,这是相当不错的,因为这只是在AMD Ryzen 5600X(中低档的消费级CPU)上本地运行它。并且在gpu上运行LLM推理(例如,直接在HuggingFace上运行)也需要两位数的时间,所以在CPU上量化运行的结果是非常不错的。
作者:Kenneth Leung
相关资源
https://avoid.overfit.cn/post/9df8822ed2854176b68585226485ee0f
相关文章:
使用GGML和LangChain在CPU上运行量化的llama2
Meta AI 在本周二发布了最新一代开源大模型 Llama 2。对比于今年 2 月发布的 Llama 1,训练所用的 token 翻了一倍,已经达到了 2 万亿,对于使用大模型最重要的上下文长度限制,Llama 2 也翻了一倍。 在本文,我们将紧跟趋…...

微服务基础理论
微服务简介 微服务Microservices之父,马丁.福勒,对微服务大概的概述如下: 就目前而言,对于微服务业界并没有一个统一的、标准的定义(While there is no precise definition of this architectural style ) 。但通在其…...

《向量数据库指南》:向量数据库Pinecone管理数据教程
目录 连接到索引 指定索引端点 调用whoami以检索您的项目名称。 描述索引统计信息 获取向量 更新向量 完整更新 ℹ️注意 部分更新 ⚠️注意 ℹ️注意 删除向量...

以深度为基础的Scikit-learn: 高级特性与最佳实践
Scikit-learn是一个广受欢迎的Python库,它用于解决许多机器学习的问题。在本篇文章中,我们将进一步探索Scikit-learn的高级特性和最佳实践。 一、管道机制 Scikit-learn的Pipeline类是一种方便的工具,它允许你将多个步骤(如数据…...

Autosar MCAL-S32K324Dio配置-基于EB
文章目录 DioPost Build Variant UsedConfig VariantDioConfigDioPortDioChannelDioChannelGroupDioConfigDio Development Error DetectSIUL2 IP Dio Development Error DetectDio Version Info ApiDio Reverse Port BitsDio Flip Channel ApiDio Rea...

【Spring Boot】单元测试
单元测试 单元测试在日常项目开发中必不可少,Spring Boot提供了完善的单元测试框架和工具用于测试开发的应用。接下来介绍Spring Boot为单元测试提供了哪些支持,以及如何在Spring Boot项目中进行单元测试。 1.Spring Boot集成单元测试 单元测试主要用…...
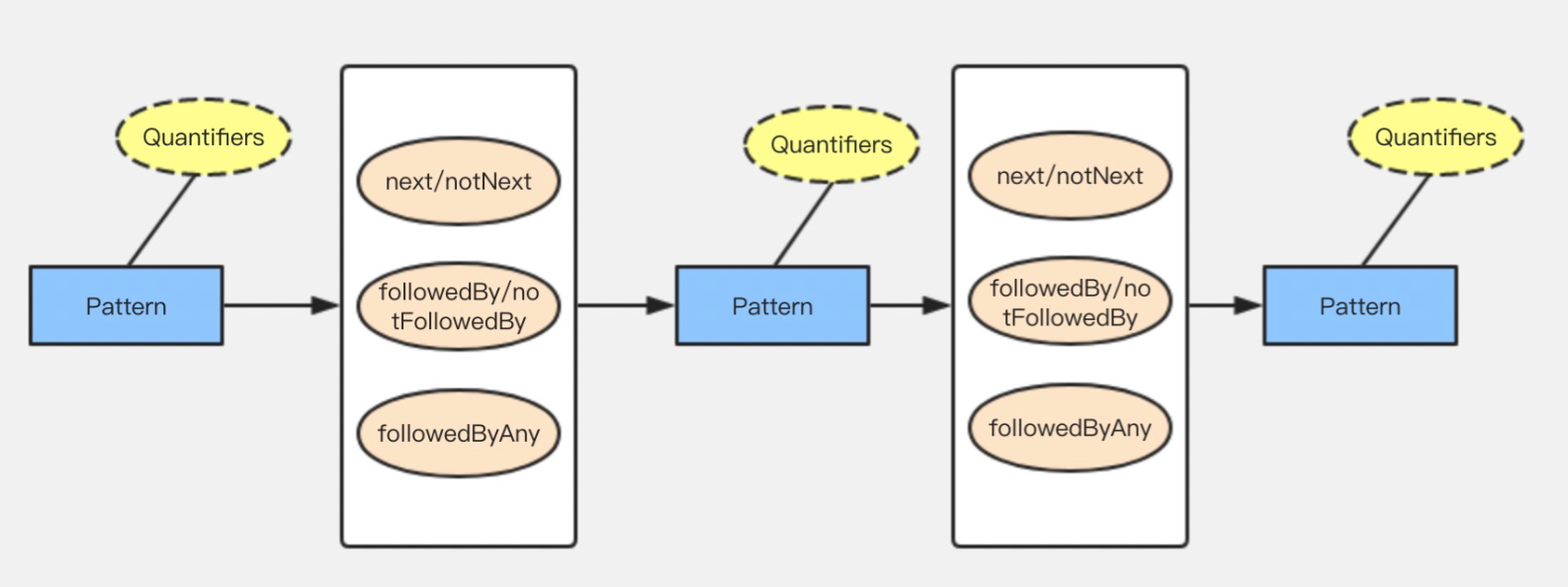
Flink CEP (一)原理及概念
目录 1.Flink CEP 原理 2.Flink API开发 2.1 模式 pattern 2.2 模式 pattern属性 2.3 模式间的关系 1.Flink CEP 原理 Flink CEP内部是用NFA(非确定有限自动机)来实现的,由点和边组成的一个状态图,以一个初始状态作为起点&am…...

vue3+taro+Nutui 开发小程序(二)
上一篇我们初始化了小程序项目,这一篇我们来整理一下框架 首先可以看到我的项目整理框架是这样的: components:这里存放封装的组件 custom-tab-bar:这里存放自己封装的自定义tabbar interface:这里放置了Ts的一些基本泛型,不用…...
Transformer 模型实用介绍:BERT
动动发财的小手,点个赞吧! 在 NLP 中,Transformer 模型架构是一场革命,极大地增强了理解和生成文本信息的能力。 在本教程[1]中,我们将深入研究 BERT(一种著名的基于 Transformer 的模型)&#…...
Spring详解(学习总结)
目录 一、Spring概述 (一)、Spring是什么? (二)、Spring框架发展历程 (三)、Spring框架的优势 (四)、Spring的体系结构 二、程序耦合与解耦合 (一&…...
【JavaEE】Spring中注解的方式去获取Bean对象
【JavaEE】Spring的开发要点总结(3) 文章目录 【JavaEE】Spring的开发要点总结(3)1. 属性注入1.1 Autowired注解1.2 依赖查找 VS 依赖注入1.3 配合Qualifier 筛选Bean对象1.4 属性注入的优缺点 2. Setter注入2.1 Autowired注解2.2…...

【基于CentOS 7 的iscsi服务】
目录 一、概述 1.简述 2.作用 3. iscsi 4.相关名称 二、使用步骤 - 构建iscsi服务 1.使用targetcli工具进入到iscsi服务器端管理界面 2.实现步骤 2.1 服务器端 2.2 客户端 2.2.1 安装软件 2.2.2 在认证文件中生成iqn编号 2.2.3 开启客户端服务 2.2.4 查找可用的i…...

解决安装依赖时报错:npm ERR! code ERESOLVE
系列文章目录 文章目录 系列文章目录前言一、错误原因二、解决方法三、注意事项总结 前言 在使用 npm 安装项目依赖时,有时会遇到错误信息 “npm ERR! code ERESOLVE”,该错误通常发生在依赖版本冲突或者依赖解析问题时。本文将详细介绍出现这个错误的原…...

98、简述Kafka的rebalance机制
简述Kafka的rebalance机制 consumer group中的消费者与topic下的partion重新匹配的过程 何时会产生rebalance: consumer group中的成员个数发生变化consumer 消费超时group订阅的topic个数发生变化group订阅的topic的分区数发生变化 coordinator: 通常是partition的leader节…...
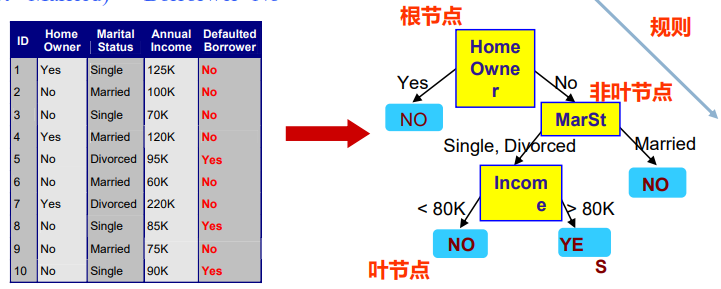
【人工智能】监督学习、分类问题、决策树、信息增益
文章目录 Decision Trees 决策树建立决策树分类模型的流程如何建立决策树?决策树学习表达能力决策树学习信息论在决策树学习中的应用特征选择准则一:信息增益举例结论不足回到餐厅的例子从12个例子中学到的决策树:Decision Trees 决策树 什么是决策树 —— 基本概念 非叶节…...
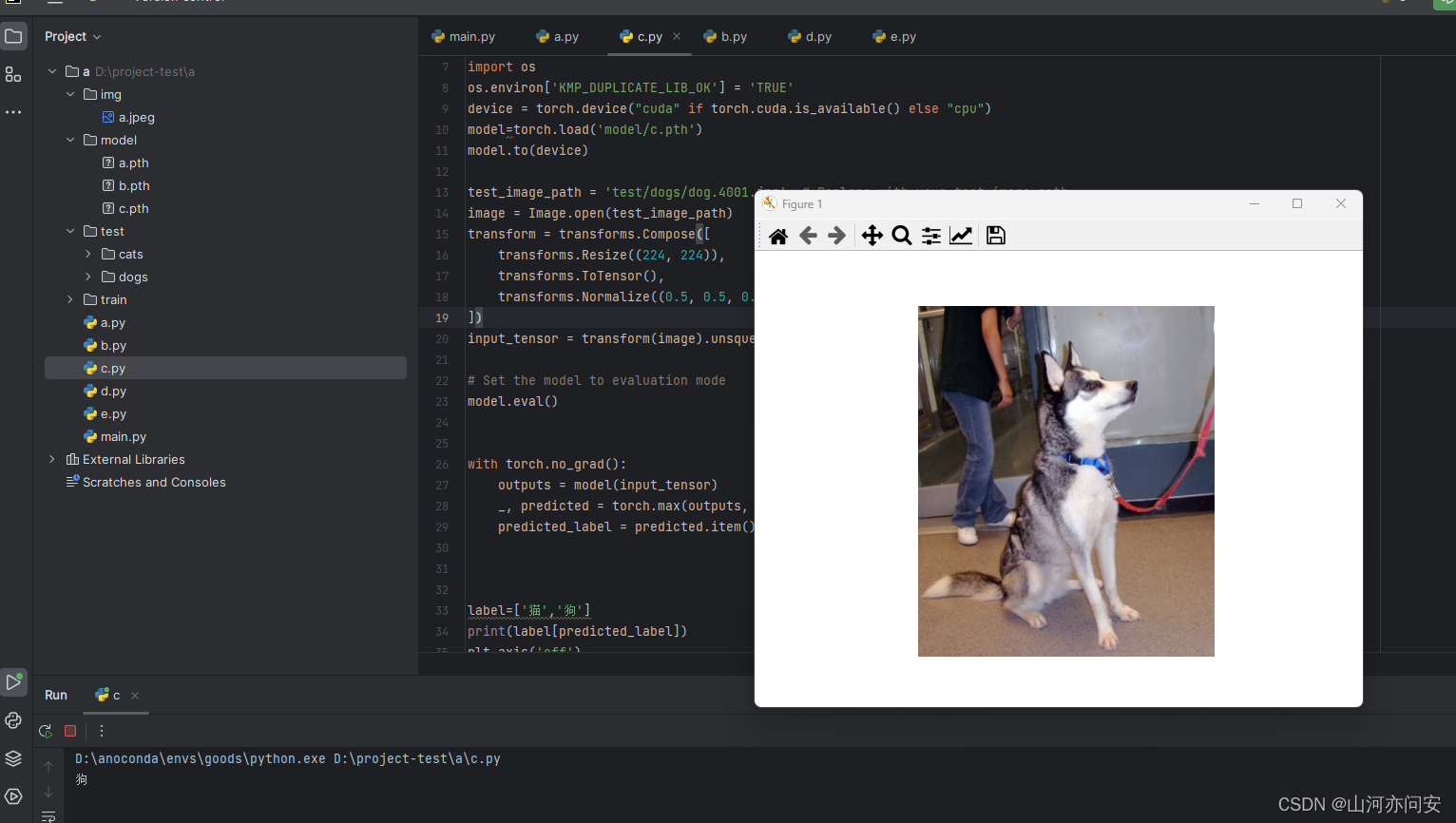
Pytorch迁移学习使用Resnet50进行模型训练预测猫狗二分类
目录 1.ResNet残差网络 1.1 ResNet定义 1.2 ResNet 几种网络配置 1.3 ResNet50网络结构 1.3.1 前几层卷积和池化 1.3.2 残差块:构建深度残差网络 1.3.3 ResNet主体:堆叠多个残差块 1.4 迁移学习猫狗二分类实战 1.4.1 迁移学习 1.4.2 模型训练 1.…...

HTML与XHTML的不同和各自特点
HTML和XHTML都是用于创建Web页面的标记语言。HTML是一种被广泛使用的标记语言,而XHTML是HTML的严格规范化版本。在本文中,我们将探讨HTML与XHTML之间的不同之处,以及它们各自的特点。 HTML与XHTML的不同之处 HTML和XHTML之间最大的不同在于它…...

微服务如何治理
微服务远程调用可能有如下问题: 注册中心宕机; 服务提供者B有节点宕机; 服务消费者A和注册中心之间的网络不通; 服务提供者B和注册中心之间的网络不通; 服务消费者A和服务提供者B之间的网络不通; 服务提供者…...
一本通1919:【02NOIP普及组】选数
这道题感觉很好玩。 正文: 先放题目: 信息学奥赛一本通(C版)在线评测系统 (ssoier.cn)http://ybt.ssoier.cn:8088/problem_show.php?pid1919 描述 已知 n 个整数 x1,x2,…,xn,以及一个整数 k(k&#…...

Kubernetes 集群管理和编排
文章目录 总纲第一章:引入 Kubernetes什么是容器编排和管理?容器编排和管理的重要性Kubernetes作为容器编排和管理解决方案 Kubernetes 的背景和发展起源和发展历程Kubernetes 项目的目标和动机 Kubernetes 的作用和优势作用优势 Kubernetes 的特点和核心…...

致开发者:别再重复造轮子,这个开源商城系统让你把时间花在刀刃上
作为开发者,你是否厌倦了每次新项目都要从零搭建电商后台?商品、订单、会员、营销……这些基础模块耗费了你多少宝贵的创造力?今天,我们想和你聊聊一个能让你“拿来即用,改也不难”的解决方案——CRMEB开源商城系统。它…...

【信号处理】基于预设性能的无模型自适应分数阶快速终端滑模控制在MIMO非线性系统中的研究附matlab代码
✅作者简介:热爱科研的Matlab仿真开发者,擅长毕业设计辅导、数学建模、数据处理、建模仿真、程序设计、完整代码获取、论文复现及科研仿真。🍎 往期回顾关注个人主页:Matlab科研工作室👇 关注我领取海量matlab电子书和…...
)
从 0 开始讲透 C++ Lambda(对标 Java)
在写 C 多线程或 STL 时,经常会看到这样的代码:std::thread t([]{ std::cout << "Hello C Thread\n"; });很多人第一反应:这 [] 是什么?为什么和 Java 不一样?一、先给结论(先建立整体认知…...

轻量级OpenClaw监控:nanobot镜像运行状态仪表盘搭建
轻量级OpenClaw监控:nanobot镜像运行状态仪表盘搭建 1. 为什么需要监控OpenClaw运行状态 上周我在本地部署了基于nanobot镜像的OpenClaw环境,用来对接Qwen3-4B模型实现自动化办公。刚开始使用时一切顺利,直到某天早上发现OpenClaw服务已经停…...

如何5分钟快速安装Ghidra:新手逆向工程终极指南
如何5分钟快速安装Ghidra:新手逆向工程终极指南 【免费下载链接】ghidra_installer Helper scripts to set up OpenJDK 11 and scale Ghidra for 4K on Ubuntu 18.04 / 18.10 项目地址: https://gitcode.com/gh_mirrors/gh/ghidra_installer Ghidra作为美国国…...

如何让实验室管理“更简单”?——King’s LIMS以灵活与智能,重构高效运营新范式
在日常实验室管理中,流程繁琐、数据难溯源、报告生成低效、多场景管控混乱等问题,常成为拖慢运营节奏、抬升运维成本的“隐形阻力”。要打破管理困局、实现轻量化高效运维,选对数字化工具是关键。然而,在选择LIMS的过程中…...

好用还专业!盘点2026年备受推崇的一键生成论文工具
一天写完毕业论文在2026年已不再是天方夜谭。最新实测显示,一键生成论文工具正在颠覆传统写作方式,覆盖选题、文献、写作、降重、排版等核心场景,真正实现高效搞定论文,学生党必备神器。 一、全流程王者:一站式搞定论文…...

雷达点云与相机标定避坑指南:如何用MATLAB Lidar Camera Calibrator提高标定精度
MATLAB Lidar Camera Calibrator实战:高精度标定的7个关键步骤与避坑策略 当激光雷达与相机数据需要融合时,标定精度直接决定了后续感知算法的上限。许多工程师在首次使用MATLAB Lidar Camera Calibrator时,常因自动标定结果不理想而陷入困惑…...

跨语言沟通的革命性突破:FunASR语音翻译系统全解析
跨语言沟通的革命性突破:FunASR语音翻译系统全解析 你是否还在为国际会议中的语言障碍而烦恼?是否因跨国团队协作中的沟通不畅而效率低下?FunASR语音翻译系统将彻底改变这一现状,让跨语言交流如母语般自然流畅。读完本文…...

浏览器兼容性问题汇总
1.IE10版本以上浏览器input标签后面自带一个X问题IE10,IE11浏览器当点击input text文本框时,输入文本后出现一个删除功能的X按钮IE浏览器效果,而谷歌浏览器没有解决方案:给input添加如下CSS样式 input::-ms-clear{display:none;}2…...