Transformer 模型实用介绍:BERT
动动发财的小手,点个赞吧!
在 NLP 中,Transformer 模型架构是一场革命,极大地增强了理解和生成文本信息的能力。
在本教程[1]中,我们将深入研究 BERT(一种著名的基于 Transformer 的模型),并提供一个实践示例来微调基本 BERT 模型以进行情感分析。
BERT简介
BERT 由 Google 研究人员于 2018 年推出,是一种使用 Transformer 架构的强大语言模型。 BERT 突破了早期模型架构(例如 LSTM 和 GRU)单向或顺序双向的界限,同时考虑了过去和未来的上下文。这是由于创新的“注意力机制”,它允许模型在生成表示时权衡句子中单词的重要性。
BERT 模型针对以下两个 NLP 任务进行了预训练:
-
掩码语言模型 (MLM)
-
下一句话预测 (NSP)
通常用作各种下游 NLP 任务的基础模型,例如我们将在本教程中介绍的情感分析。
预训练和微调
BERT 的强大之处在于它的两步过程:
-
预训练是 BERT 在大量数据上进行训练的阶段。因此,它学习预测句子中的屏蔽词(MLM 任务)并预测一个句子是否在另一个句子后面(NSP 任务)。此阶段的输出是一个预训练的 NLP 模型,具有对该语言的通用“理解” -
微调是针对特定任务进一步训练预训练的 BERT 模型。该模型使用预先训练的参数进行初始化,并且整个模型在下游任务上进行训练,从而使 BERT 能够根据当前任务的具体情况微调其对语言的理解。
实践:使用 BERT 进行情感分析
完整的代码可作为 GitHub 上的 Jupyter Notebook 获取
在本次实践练习中,我们将在 IMDB 电影评论数据集(许可证:Apache 2.0)上训练情感分析模型,该数据集
会标记评论是正面还是负面。我们还将使用 Hugging Face 的转换器库加载模型。
让我们加载所有库
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.metrics import confusion_matrix, roc_curve, auc
from datasets import load_dataset
from transformers import AutoTokenizer, AutoModelForSequenceClassification, TrainingArguments, Trainer
# Variables to set the number of epochs and samples
num_epochs = 10
num_samples = 100 # set this to -1 to use all data
首先,我们需要加载数据集和模型标记器。
# Step 1: Load dataset and model tokenizer
dataset = load_dataset('imdb')
tokenizer = AutoTokenizer.from_pretrained('bert-base-uncased')
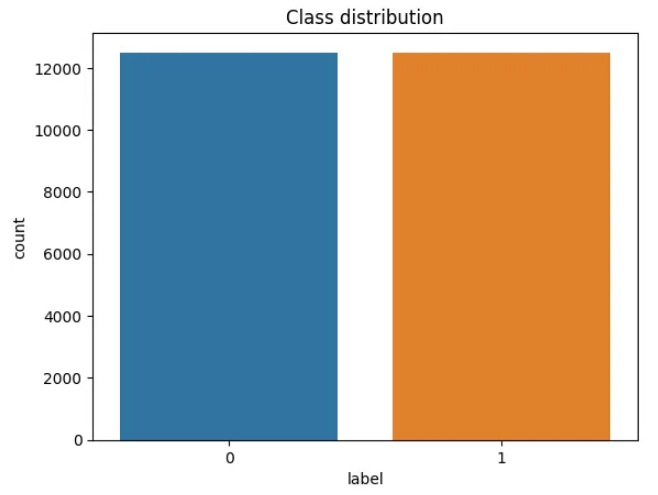
接下来,我们将创建一个绘图来查看正类和负类的分布。
# Data Exploration
train_df = pd.DataFrame(dataset["train"])
sns.countplot(x='label', data=train_df)
plt.title('Class distribution')
plt.show()
接下来,我们通过标记文本来预处理数据集。我们使用 BERT 的标记器,它将文本转换为与 BERT 词汇相对应的标记。
# Step 2: Preprocess the dataset
def tokenize_function(examples):
return tokenizer(examples["text"], padding="max_length", truncation=True)
tokenized_datasets = dataset.map(tokenize_function, batched=True)

之后,我们准备训练和评估数据集。请记住,如果您想使用所有数据,可以将 num_samples 变量设置为 -1。
if num_samples == -1:
small_train_dataset = tokenized_datasets["train"].shuffle(seed=42)
small_eval_dataset = tokenized_datasets["test"].shuffle(seed=42)
else:
small_train_dataset = tokenized_datasets["train"].shuffle(seed=42).select(range(num_samples))
small_eval_dataset = tokenized_datasets["test"].shuffle(seed=42).select(range(num_samples))
然后,我们加载预训练的 BERT 模型。我们将使用 AutoModelForSequenceClassification 类,这是一个专为分类任务设计的 BERT 模型。
# Step 3: Load pre-trained model
model = AutoModelForSequenceClassification.from_pretrained('bert-base-uncased', num_labels=2)
现在,我们准备定义训练参数并创建一个 Trainer 实例来训练我们的模型。
# Step 4: Define training arguments
training_args = TrainingArguments("test_trainer", evaluation_strategy="epoch", no_cuda=True, num_train_epochs=num_epochs)
# Step 5: Create Trainer instance and train
trainer = Trainer(
model=model, args=training_args, train_dataset=small_train_dataset, eval_dataset=small_eval_dataset
)
trainer.train()
结果解释
训练完我们的模型后,让我们对其进行评估。我们将计算混淆矩阵和 ROC 曲线,以了解我们的模型的表现如何。
# Step 6: Evaluation
predictions = trainer.predict(small_eval_dataset)
# Confusion matrix
cm = confusion_matrix(small_eval_dataset['label'], predictions.predictions.argmax(-1))
sns.heatmap(cm, annot=True, fmt='d')
plt.title('Confusion Matrix')
plt.show()
# ROC Curve
fpr, tpr, _ = roc_curve(small_eval_dataset['label'], predictions.predictions[:, 1])
roc_auc = auc(fpr, tpr)
plt.figure(figsize=(1.618 * 5, 5))
plt.plot(fpr, tpr, color='darkorange', lw=2, label='ROC curve (area = %0.2f)' % roc_auc)
plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver operating characteristic')
plt.legend(loc="lower right")
plt.show()
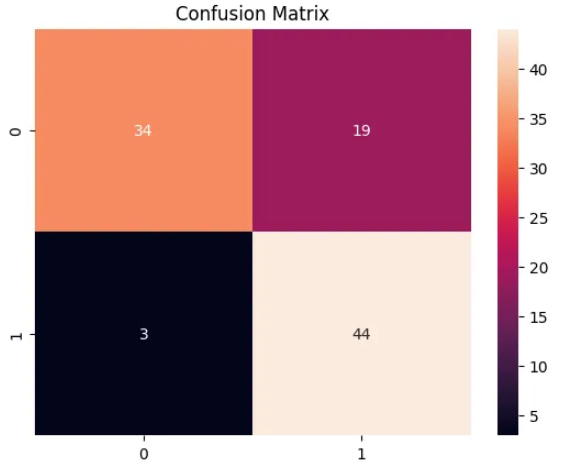
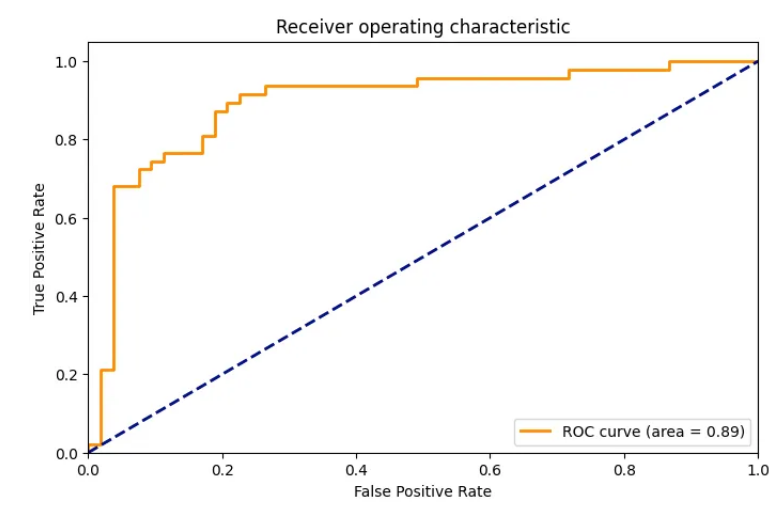
混淆矩阵详细说明了我们的预测如何与实际标签相匹配,而 ROC 曲线则向我们展示了各种阈值设置下真阳性率(灵敏度)和假阳性率(1 - 特异性)之间的权衡。
最后,为了查看我们的模型的实际效果,让我们用它来推断示例文本的情绪。
# Step 7: Inference on a new sample
sample_text = "This is a fantastic movie. I really enjoyed it."
sample_inputs = tokenizer(sample_text, padding="max_length", truncation=True, max_length=512, return_tensors="pt")
# Move inputs to device (if GPU available)
sample_inputs.to(training_args.device)
# Make prediction
predictions = model(**sample_inputs)
predicted_class = predictions.logits.argmax(-1).item()
if predicted_class == 1:
print("Positive sentiment")
else:
print("Negative sentiment")
总结
通过浏览 IMDb 电影评论的情感分析示例,我希望您能够清楚地了解如何将 BERT 应用于现实世界的 NLP 问题。我在此处包含的 Python 代码可以进行调整和扩展,以处理不同的任务和数据集,为更复杂和更准确的语言模型铺平道路。
Reference
Source: https://towardsdatascience.com/practical-introduction-to-transformer-models-bert-4715ed0deede
本文由 mdnice 多平台发布
相关文章:
Transformer 模型实用介绍:BERT
动动发财的小手,点个赞吧! 在 NLP 中,Transformer 模型架构是一场革命,极大地增强了理解和生成文本信息的能力。 在本教程[1]中,我们将深入研究 BERT(一种著名的基于 Transformer 的模型)&#…...
Spring详解(学习总结)
目录 一、Spring概述 (一)、Spring是什么? (二)、Spring框架发展历程 (三)、Spring框架的优势 (四)、Spring的体系结构 二、程序耦合与解耦合 (一&…...
【JavaEE】Spring中注解的方式去获取Bean对象
【JavaEE】Spring的开发要点总结(3) 文章目录 【JavaEE】Spring的开发要点总结(3)1. 属性注入1.1 Autowired注解1.2 依赖查找 VS 依赖注入1.3 配合Qualifier 筛选Bean对象1.4 属性注入的优缺点 2. Setter注入2.1 Autowired注解2.2…...

【基于CentOS 7 的iscsi服务】
目录 一、概述 1.简述 2.作用 3. iscsi 4.相关名称 二、使用步骤 - 构建iscsi服务 1.使用targetcli工具进入到iscsi服务器端管理界面 2.实现步骤 2.1 服务器端 2.2 客户端 2.2.1 安装软件 2.2.2 在认证文件中生成iqn编号 2.2.3 开启客户端服务 2.2.4 查找可用的i…...

解决安装依赖时报错:npm ERR! code ERESOLVE
系列文章目录 文章目录 系列文章目录前言一、错误原因二、解决方法三、注意事项总结 前言 在使用 npm 安装项目依赖时,有时会遇到错误信息 “npm ERR! code ERESOLVE”,该错误通常发生在依赖版本冲突或者依赖解析问题时。本文将详细介绍出现这个错误的原…...

98、简述Kafka的rebalance机制
简述Kafka的rebalance机制 consumer group中的消费者与topic下的partion重新匹配的过程 何时会产生rebalance: consumer group中的成员个数发生变化consumer 消费超时group订阅的topic个数发生变化group订阅的topic的分区数发生变化 coordinator: 通常是partition的leader节…...
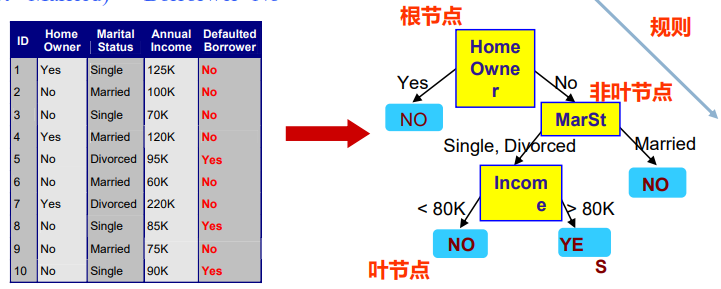
【人工智能】监督学习、分类问题、决策树、信息增益
文章目录 Decision Trees 决策树建立决策树分类模型的流程如何建立决策树?决策树学习表达能力决策树学习信息论在决策树学习中的应用特征选择准则一:信息增益举例结论不足回到餐厅的例子从12个例子中学到的决策树:Decision Trees 决策树 什么是决策树 —— 基本概念 非叶节…...
Pytorch迁移学习使用Resnet50进行模型训练预测猫狗二分类
目录 1.ResNet残差网络 1.1 ResNet定义 1.2 ResNet 几种网络配置 1.3 ResNet50网络结构 1.3.1 前几层卷积和池化 1.3.2 残差块:构建深度残差网络 1.3.3 ResNet主体:堆叠多个残差块 1.4 迁移学习猫狗二分类实战 1.4.1 迁移学习 1.4.2 模型训练 1.…...

HTML与XHTML的不同和各自特点
HTML和XHTML都是用于创建Web页面的标记语言。HTML是一种被广泛使用的标记语言,而XHTML是HTML的严格规范化版本。在本文中,我们将探讨HTML与XHTML之间的不同之处,以及它们各自的特点。 HTML与XHTML的不同之处 HTML和XHTML之间最大的不同在于它…...

微服务如何治理
微服务远程调用可能有如下问题: 注册中心宕机; 服务提供者B有节点宕机; 服务消费者A和注册中心之间的网络不通; 服务提供者B和注册中心之间的网络不通; 服务消费者A和服务提供者B之间的网络不通; 服务提供者…...
一本通1919:【02NOIP普及组】选数
这道题感觉很好玩。 正文: 先放题目: 信息学奥赛一本通(C版)在线评测系统 (ssoier.cn)http://ybt.ssoier.cn:8088/problem_show.php?pid1919 描述 已知 n 个整数 x1,x2,…,xn,以及一个整数 k(k&#…...

Kubernetes 集群管理和编排
文章目录 总纲第一章:引入 Kubernetes什么是容器编排和管理?容器编排和管理的重要性Kubernetes作为容器编排和管理解决方案 Kubernetes 的背景和发展起源和发展历程Kubernetes 项目的目标和动机 Kubernetes 的作用和优势作用优势 Kubernetes 的特点和核心…...

DDS协议--[第六章][Discovery]
DDS协议–Discovery 文章目录 DDS协议--Discovery侦听通告DDS提供发现协议参与者发现阶段(PDP)端点发现阶段(EDP)Fast DDS提供如下四种发现机制:简单发现机制简单发现机制步骤:侦听 侦听定位器用于接收DomainParticipant上的传入流量,是DDS发现机制和数据传输机制的关键…...

如何设置iptables,让网络流量转发给内部容器mysql
1.创建一个mysql ,无法外部访问 docker run -d --name mysql_container -e MYSQL_ROOT_PASSWORDliuyunshengsir -v /path/to/mysql_data:/var/lib/mysql mysql2.设置规则外部直接可访问 要使用 iptables 将网络流量转发给内部容器中的 MySQL 服务,你可…...
数字IC实践项目(7)—CNN加速器的设计和实现(付费项目)
数字IC实践项目(7)—基于Verilog的CNN加速器(付费项目) 写在前面的话项目整体框图神经网络框图完整电路框图 项目简介和学习目的软件环境要求 资源占用&板载功耗总结 写在前面的话 项目介绍: 卷积神经网络硬件加速…...

基于深度学习的高精度80类动物目标检测系统(PyTorch+Pyside6+YOLOv5模型)
摘要:基于深度学习的高精度80类动物目标检测识别系统可用于日常生活中或野外来检测与定位80类动物目标,利用深度学习算法可实现图片、视频、摄像头等方式的80类动物目标检测识别,另外支持结果可视化与图片或视频检测结果的导出。本系统采用YO…...

海康摄像头开发笔记(一):连接防爆摄像头、配置摄像头网段、设置rtsp码流、播放rtsp流、获取rtsp流、调优rtsp流播放延迟以及录像存储
文为原创文章,转载请注明原文出处 本文章博客地址:https://hpzwl.blog.csdn.net/article/details/131679108 红胖子(红模仿)的博文大全:开发技术集合(包含Qt实用技术、树莓派、三维、OpenCV、OpenGL、ffmpeg、OSG、单片机、软硬结…...

【NCNN】NCNN中Mat与CV中Mat的使用区别及相互转换方法
目录 相同点与不同点cv::Mat转ncnn::Matcv::Mat CV_8UC3 -> ncnn::Mat 3 channel swap RGB/BGRcv::Mat CV_8UC3 -> ncnn::Mat 1 channel do RGB2GRAY/BGR2GRAYcv::Mat CV_8UC1 -> ncnn::Mat 1 channel ncnn::Mat转cv::Mancnn::Mat 3 channel -> cv::Mat CV_8UC3 …...

Android 13 设置自动进入wifi adb模式
Android 13 设置自动进入wifi adb模式 文章目录 Android 13 设置自动进入wifi adb模式一、前言:二、解决Android 13 wifi adb每次重启自动重置问题方法1、分析系统中每次重置wifi adb属性的代码2、在开机广播里面进行设置wifi adb 相关属性(1)…...
插入排序)
(笔记)插入排序
插入排序 插入排序是一种简单且常见的排序算法,它通过重复将一个元素插入到已经排好序的一组元素中,来达到排序的目的。在插入排序算法中,将待排序序列分为已排序和未排序两个部分。初始时,已排序部分只包含一个记录,…...

在OpenClaw中配置Taotoken作为Agent任务的模型提供商
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在OpenClaw中配置Taotoken作为Agent任务的模型提供商 基础教程类,指导使用OpenClaw框架的开发者,如何按照T…...

Open-Meteo:气象数据服务的架构革新与开源技术突破
Open-Meteo:气象数据服务的架构革新与开源技术突破 【免费下载链接】open-meteo Free Weather Forecast API for non-commercial use 项目地址: https://gitcode.com/GitHub_Trending/op/open-meteo 在数字化转型浪潮中,气象数据正从传统的封闭服…...

数据中台治理工具2026年排行
一、数据中台的“最后一公里”,卡在治理企业搭建数据中台,底层架构通常不会出大问题——数据湖、数据仓库、调度引擎、计算框架,市面上成熟的方案已经足够多。但真正让企业头疼的,是数据中台“建好之后”的问题:数据确…...

从打火机到火山喷发:一套Unity粒子系统参数,教你调出N种不同风格的火焰效果
从打火机到火山喷发:一套Unity粒子系统参数的艺术化调校指南 火焰在游戏特效中扮演着灵魂角色——从摇曳的烛光到喷薄的岩浆,不同的火焰性格需要完全不同的参数组合。本文将带您深入Unity粒子系统的核心参数层,掌握那些真正影响视觉表现力的&…...

RISC-V DSP开发板实战:从环境搭建到BLDC电机控制全解析
1. 项目概述:一次难得的RISC-V DSP开发板深度体验机会 作为一名在嵌入式领域摸爬滚打了十多年的老工程师,我见证了ARM架构从崭露头角到一统江湖的全过程。然而,近几年开源指令集架构RISC-V的异军突起,让我这个“老顽固”也感受到了…...

Windows上直接运行安卓应用?APK安装器让你告别模拟器时代!
Windows上直接运行安卓应用?APK安装器让你告别模拟器时代! 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 你是否曾经想过在Windows电脑上直接运…...

翻转电饼铛生产厂家:高性价比背后的运营策略深度解析
翻转电饼铛生产厂家:高性价比背后的运营策略深度解析“高性价比不是低价竞争,而是让设备价值与企业需求精准匹配”——这是优质翻转电饼铛生产厂家的核心运营逻辑。很多食品企业在选购翻转电饼铛时,既担心高价设备增加成本,又怕低…...

Kubescape命令行自动补全:提升安全扫描效率的技巧
Kubescape命令行自动补全:提升安全扫描效率的技巧 【免费下载链接】kubescape Kubescape is an open-source Kubernetes security platform for your IDE, CI/CD pipelines, and clusters. It includes risk analysis, security, compliance, and misconfiguration …...

Parsec VDD虚拟显示器驱动深度解析:5大优化策略与实战应用指南
Parsec VDD虚拟显示器驱动深度解析:5大优化策略与实战应用指南 【免费下载链接】parsec-vdd ✨ Perfect virtual display for game streaming 项目地址: https://gitcode.com/gh_mirrors/pa/parsec-vdd Parsec Virtual Display Driver (VDD) 是一款基于Windo…...

designmodel可以输出各种类型的几何模型文件格式,兼容各种主流的CAD绘制软件。
designmodel可以输出各种类型的几何模型文件格式,兼容各种主流的CAD绘制软件。 这是Geom软件的文件格式选择界面,各格式的用途和适用场景如下: DesignModeler Database (*.agdb):ANSYS DesignModeler的原生数据库格式,用于保存几何模型的完整设计数据,支持后续在ANSYS…...