【论文笔记】KDD2019 | KGAT: Knowledge Graph Attention Network for Recommendation

Abstract
为了更好的推荐,不仅要对user-item交互进行建模,还要将关系信息考虑进来
传统方法因子分解机将每个交互都当作一个独立的实例,但是忽略了item之间的关系(eg:一部电影的导演也是另一部电影的演员)
高阶关系:用一个/多个链接属性连接两个item
KG+user-item graph+high order relations—>KGAT
递归传播邻域节点(可能是users、items、attributes)的嵌入来更新自身节点的嵌入,并使用注意力机制来区分邻域节点的重要性
Introduction

u 1 u_1 u1是要向其提供推荐的目标用户。黄色圆圈和灰色圆圈表示通过高阶关系发现但被传统方法忽略的重要用户和项目。
例如,用户 u 1 u_1 u1看了 电影 i 1 i_1 i1,CF方法侧重于同样观看了 i 1 i_1 i1的相似用户的历史,即 u 4 u_4 u4和 u 5 u_5 u5,而监督学习侧重于与 i 1 i_1 i1有相同属性 e 1 e_1 e1的电影 i 2 i_2 i2,显然,这两种信息对于推荐是互补的,但是现有的监督学习未能将这两者统一起来,比如说这里 i 1 i_1 i1和 i 2 i_2 i2的 r 2 r_2 r2属性都是 e 1 e_1 e1,但是它无法通过 r 3 r_3 r3到达 i 3 i_3 i3, i 4 i_4 i4,因为它把它们当成了独立的部分,无法考虑到数据中的高阶关系,比如黄色圈中的用户看了同一个导演 e 1 e_1 e1的其他电影 i 2 i_2 i2,或者灰色圈中的电影也与 e 1 e_1 e1有其他的关系。这些也是作出推荐的重要信息。
u 1 ⟶ r 1 i 1 ⟶ − r 2 e 1 ⟶ r 2 i 2 ⟶ − r 1 { u 2 , u 3 } , u 1 ⟶ r 1 i 1 ⟶ − r 2 e 1 ⟶ r 3 { i 3 , i 4 } , \begin{array}{l} u_{1} \stackrel{r_{1}}{\longrightarrow} i_{1} \stackrel{-r_{2}}{\longrightarrow} e_{1} \stackrel{r_{2}}{\longrightarrow} i_{2} \stackrel{-r_{1}}{\longrightarrow}\left\{u_{2}, u_{3}\right\}, \\ u_{1} \stackrel{r_{1}}{\longrightarrow} i_{1} \stackrel{-r_{2}}{\longrightarrow} e_{1} \stackrel{r_{3}}{\longrightarrow}\left\{i_{3}, i_{4}\right\}, \end{array} u1⟶r1i1⟶−r2e1⟶r2i2⟶−r1{u2,u3},u1⟶r1i1⟶−r2e1⟶r3{i3,i4},
存在问题
利用这种高阶信息是存在挑战的:
1) 与目标用户具有高阶关系的节点随着阶数的增加而急剧增加,这给模型带来了计算压力
2) 高阶关系对预测的贡献不均衡。
为此,论文提出了 Knowledge Graph Attention Network (KGAT) 的模型,它基于节点邻居的嵌入来更新节点的嵌入,并递归地执行这种嵌入传播,以线性时间复杂度捕获高阶连接。另外采用注意力机制来学习传播期间每个邻居的权重。
GNN->KGAT
1、递归嵌入传播,用领域节点嵌入来更新当前节点嵌入
2、使用注意力机制,来学习传播期间每个邻居的权重
优点:
1、与基于路径的方法相比,避免了人工标定路径
2、与基于规则的方法相比,将高阶关系直接融入预测模型
3. 模型框架
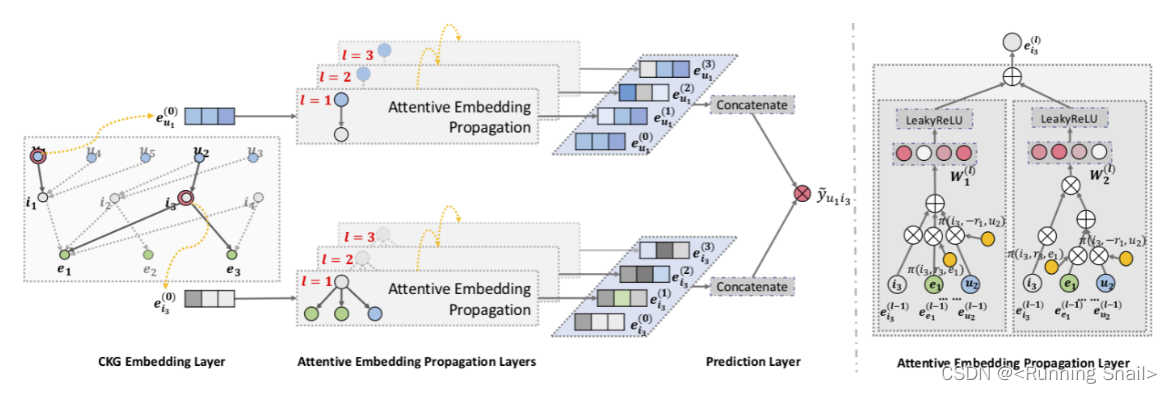
3.1 问题定义
Input:协同知识图 G \mathcal G G, G \mathcal G G由user-item交互数据 G 1 \mathcal G_1 G1和知识图 G 2 \mathcal G_2 G2组成
Output:user u u u点击 item i i i的概率 y ^ u i \hat y_{ui} y^ui
高阶连接:利用高阶连接对于执行高质量的推荐是至关重要的。我们将 L L L阶连接 ( L L L- order connectivtiy) 定义为一个多跳关系路径:
e 0 ⟶ r 1 e 1 ⟶ r 2 . . . ⟶ r L e L e_0 \stackrel {r_1}{\longrightarrow} e_1 \stackrel {r_2}{\longrightarrow} \ ... \ \stackrel {r_L}{\longrightarrow} e_L\\ e0⟶r1e1⟶r2 ... ⟶rLeL
3.2 Embedding Layer
论文在知识图嵌入方面使用了TransR模型,它的主要思想是不同的实体在不同的关系下有着不同的含义,所以需要将实体投影到特定关系空间中,假如 h h h和 t t t具有 r r r关系,那么它们在 r r r关系空间的表示应该接近,否则应该远离,用公式表达则是:
e h r + e r ≈ e t r \mathbf e_h^r + \mathbf e_r \approx \mathbf e_t^r \\ ehr+er≈etr
这里 e h , e t ∈ R d \mathbf e_h, \mathbf e_t \in \mathbb R^d eh,et∈Rd, e r ∈ R k \mathbf e_r \in \mathbb R^k er∈Rk是 h , t , r h ,t ,r h,t,r的embedding。
它的得分为:
g ( h , r , t ) = ∣ ∣ W r e h + e r − W r e t ∣ ∣ 2 2 g(h,r,t)=||\mathbf W_r\mathbf e_h+\mathbf e_r-\mathbf W_r\mathbf e_t||_2^2\\ g(h,r,t)=∣∣Wreh+er−Wret∣∣22
其中 W r ∈ R k × d \mathbf W_r \in \mathbb R^{k\times d} Wr∈Rk×d是关系 r r r的转换矩阵,将实体从 d d d维实体空间投影到 k k k维关系空间中。 g ( h , r , t ) g(h,r,t) g(h,r,t)的值越低,说明该三元组为真的概率越大。
最后,用pairwise ranking loss来衡量效果:
L K G = ∑ ( h , r , t , t ′ ) ∈ τ − l n σ ( g ( h , r , t ′ ) − g ( h , r , t ) ) \mathcal L_{KG} = \sum_{(h,r,t,t^{'})\in \tau} -ln \ \sigma(g(h,r,t^{'})-g(h,r,t))\\ LKG=(h,r,t,t′)∈τ∑−ln σ(g(h,r,t′)−g(h,r,t))
此式子的意思就是让负样本的值减去正样本的值尽可能的大。负样本的选择就是将 t t t随机替换成一个别的。
3.3 Attentive Embedding Propagation Layers
信息传播
考虑实体 h h h,我们使用 N h = { ( h , r , t ) ∣ ( h , r , t ) ∈ G } \mathcal N_h = \{ (h,r,t)|(h,r,t) \in \mathcal G\} Nh={(h,r,t)∣(h,r,t)∈G}表示那些以 h h h为头实体的三元组。计算 h h h的ego-network:
e N h = ∑ ( h , r , t ) ∈ N h π ( h , r , t ) e t \mathbf e_{\mathcal N_h} = \sum _ {(h,r,t) \in \mathcal N_h} \pi(h,r,t) \mathbf e_t\\ eNh=(h,r,t)∈Nh∑π(h,r,t)et
π ( h , r , t ) \pi(h,r,t) π(h,r,t)表示在关系 r r r下从 t t t传到 h h h的信息量。
知识感知注意力
信息传播中的权重 π ( h , r , t ) \pi(h,r,t) π(h,r,t)是通过注意力机制实现的
π ( h , r , t ) = ( W r e t ) T t a n h ( W r e h + e r ) \pi(h,r,t) = (\mathbf W_r \mathbf e_t)^Ttanh(\mathbf W_r \mathbf e_h+\mathbf e_r)\\ π(h,r,t)=(Wret)Ttanh(Wreh+er)
这里使用 t a n h tanh tanh作为激活函数可以使得在关系空间中越接近的 e h \mathbf e_h eh和 e t \mathbf e_t et有更高的注意力分值。采用 s o f t m a x softmax softmax归一化:
π ( h , r , t ) = e x p ( π ( h , r , t ) ) ∑ ( h , r ′ , t ′ ) ∈ N h e x p ( π ( h , r ′ , t ′ ) ) \pi(h,r,t)=\frac{exp(\pi(h,r,t))}{\sum_{(h,r^{'},t^{'}) \in \mathcal N_h} exp(\pi(h,r^{'},t^{'}))}\\ π(h,r,t)=∑(h,r′,t′)∈Nhexp(π(h,r′,t′))exp(π(h,r,t))
最终凭借 π ( h , r , t ) \pi(h,r,t) π(h,r,t)我们可以知道哪些邻居节点应该被给予更多的关注。
信息聚合
最终将 h h h在实体空间中的表示 e h \mathbf e_h eh和其ego-network的表示 e N h \mathbf e_{\mathcal N_h} eNh聚合起来作为 h h h的新表示:
e h ( 1 ) = f ( e h , e N h ) \mathbf e_h^{(1)} = f(\mathbf e_h,\mathbf e_{\mathcal N_h})\\ eh(1)=f(eh,eNh)
f ( ⋅ ) f(·) f(⋅)有以下几种方式:
- GCN Aggregator:
f G C N = L e a k y R e L U ( W ( e h + e N h ) ) f_{GCN}=LeakyReLU(\mathbf W(\mathbf e_h+\mathbf e_{\mathcal N_h})) fGCN=LeakyReLU(W(eh+eNh)) - GraphSage Aggregator:
f G r a p h S a g e = L e a k y R e L U ( W ( e h ∣ ∣ e N h ) ) f_{GraphSage} = LeakyReLU( \mathbf W(\mathbf e_h || \mathbf e_{\mathcal N_h})) fGraphSage=LeakyReLU(W(eh∣∣eNh)) - Bi-Interaction Aggregator:
f B i − I n t e r a c t i o n = L e a k y R e L U ( W 1 ( e h + e N h ) ) + L e a k y R e L U ( W 2 ( e h ⊙ e N h ) ) f_{Bi-Interaction} = LeakyReLU(\mathbf W_1(\mathbf e_h+\mathbf e_{\mathcal N_h}))+LeakyReLU(\mathbf W_2(\mathbf e_h\odot\mathbf e_{\mathcal N_h})) fBi−Interaction=LeakyReLU(W1(eh+eNh))+LeakyReLU(W2(eh⊙eNh))
高阶传播:
我们可以进一步堆叠更多的传播层来探索高阶连通信息,收集从更高跳邻居传播过来的信息,所以在 l l l步中:
e h ( l ) = f ( e h ( l − 1 ) , e N h ( l − 1 ) ) \mathbf e_h^{(l)} = f( \mathbf e_h^{(l-1)},\mathbf e_{\mathcal N_h}^{(l-1)})\\ eh(l)=f(eh(l−1),eNh(l−1))
其中 e N h ( l − 1 ) = ∑ ( h , r , t ) ∈ N h π ( h , r , t ) e t ( l − 1 ) \mathbf e_{\mathcal N_h}^{(l-1)} = \sum_{(h,r,t) \in \mathcal N_h} \pi(h,r,t)\mathbf e_t^{(l-1)} eNh(l−1)=∑(h,r,t)∈Nhπ(h,r,t)et(l−1),而 e t ( l − 1 ) \mathbf e_t^{(l-1)} et(l−1)也是通过上面的步骤从 e t 0 \mathbf e_t^0 et0得到的。
3.4 Prediction layer
在执行 L L L层后,最终我们会得到用户 u u u的多层表示: { e u ( 1 ) , . . . , e u ( L ) } \{\mathbf e_u^{(1)},...,\mathbf e_u^{(L)} \} {eu(1),...,eu(L)},以及item i i i的多层表示: { e i ( 1 ) , . . , e i ( L ) } \{\mathbf e_i^{(1)},..,\mathbf e_i^{(L)} \} {ei(1),..,ei(L)}
将其连接起来,即:
e u ∗ = e u ( 0 ) ∣ ∣ . . . ∣ ∣ e u ( L ) , e i ∗ = e i ( 0 ) ∣ ∣ . . . ∣ ∣ e i ( L ) \mathbf e_u^{*} = \mathbf e_u^{(0)} || ...||\mathbf e_u^{(L)} \ ,\ \mathbf e_i^{*} = \mathbf e_i^{(0)} || ...||\mathbf e_i^{(L)} \\ eu∗=eu(0)∣∣...∣∣eu(L) , ei∗=ei(0)∣∣...∣∣ei(L)
最后通过内积计算相关分数:
y ^ ( u , i ) = e u ∗ T e i ∗ \hat y(u,i) = {\mathbf e_u^*}^T \mathbf e_i^*\\ y^(u,i)=eu∗Tei∗
3.5 损失函数
损失函数使用了BPR loss:
L C F = ∑ ( u , i , j ) ∈ O − l n σ ( y ^ ( u , i ) − y ^ ( u , j ) ) \mathcal L_{CF}=\sum_{(u,i,j) \in O} - ln \ \sigma(\hat y(u,i)-\hat y(u,j))\\ LCF=(u,i,j)∈O∑−ln σ(y^(u,i)−y^(u,j))
其中 O = { ( u , i , j ) ∣ ( u , i ) ∈ R + , ( u , j ) ∈ R − } O = \{(u,i,j)|(u,i) \in \mathcal R^+, (u,j) \in \mathcal R^- \} O={(u,i,j)∣(u,i)∈R+,(u,j)∈R−}, R + \mathcal R^+ R+表示正样本, R − \mathcal R^- R−表示负样本。
最终:
L K G A T = L K G + L C F + λ ∣ ∣ Θ ∣ ∣ 2 2 \mathcal L_{KGAT} = \mathcal L_{KG} + \mathcal L_{CF} + \lambda||\Theta||_2^2\\ LKGAT=LKG+LCF+λ∣∣Θ∣∣22
相关文章:
【论文笔记】KDD2019 | KGAT: Knowledge Graph Attention Network for Recommendation
Abstract 为了更好的推荐,不仅要对user-item交互进行建模,还要将关系信息考虑进来 传统方法因子分解机将每个交互都当作一个独立的实例,但是忽略了item之间的关系(eg:一部电影的导演也是另一部电影的演员)…...

ES6:基础使用,积累
一、理解ES6 ES6是ECMAScript 6.0的简称,也被称为ES2015。它是ECMAScript的第六个版本,是JavaScript标准的下一个重大更新。ES6于2015年6月发布,新增了许多新的语言特性和API,包括箭头函数、let和const关键字、模板字符串、解构赋…...

Android端上传文件到Spring Boot后端
准备 确定好服务器端文件保存的位置确定好请求参数名(前后端要保持一致的喔)如果手机是通过usb连接到电脑的,需要执行一下: adb reverse tcp:8080 tcp:8080 AndroidManifest.xml的<application/>节点中加上: android:usesC…...
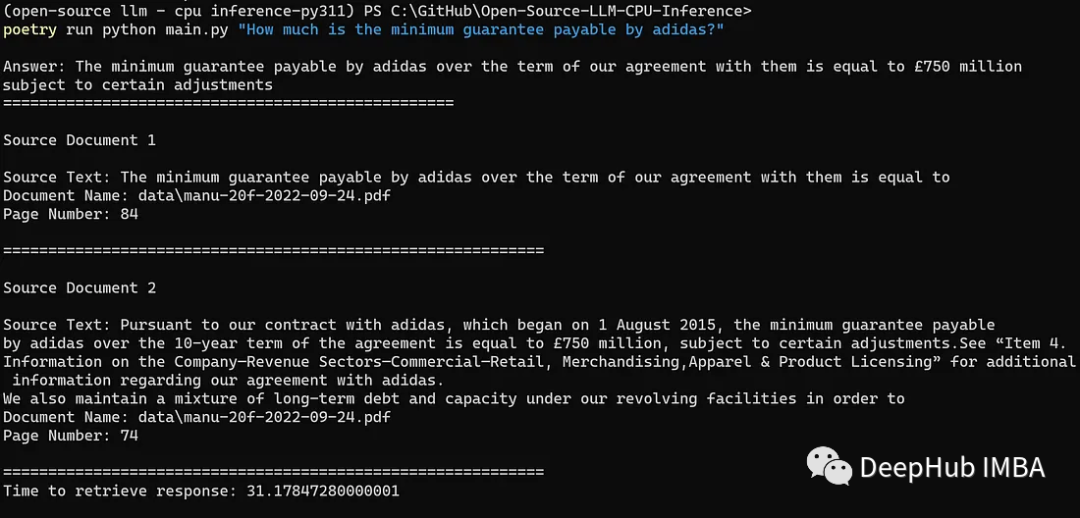
使用GGML和LangChain在CPU上运行量化的llama2
Meta AI 在本周二发布了最新一代开源大模型 Llama 2。对比于今年 2 月发布的 Llama 1,训练所用的 token 翻了一倍,已经达到了 2 万亿,对于使用大模型最重要的上下文长度限制,Llama 2 也翻了一倍。 在本文,我们将紧跟趋…...

微服务基础理论
微服务简介 微服务Microservices之父,马丁.福勒,对微服务大概的概述如下: 就目前而言,对于微服务业界并没有一个统一的、标准的定义(While there is no precise definition of this architectural style ) 。但通在其…...

《向量数据库指南》:向量数据库Pinecone管理数据教程
目录 连接到索引 指定索引端点 调用whoami以检索您的项目名称。 描述索引统计信息 获取向量 更新向量 完整更新 ℹ️注意 部分更新 ⚠️注意 ℹ️注意 删除向量...

以深度为基础的Scikit-learn: 高级特性与最佳实践
Scikit-learn是一个广受欢迎的Python库,它用于解决许多机器学习的问题。在本篇文章中,我们将进一步探索Scikit-learn的高级特性和最佳实践。 一、管道机制 Scikit-learn的Pipeline类是一种方便的工具,它允许你将多个步骤(如数据…...

Autosar MCAL-S32K324Dio配置-基于EB
文章目录 DioPost Build Variant UsedConfig VariantDioConfigDioPortDioChannelDioChannelGroupDioConfigDio Development Error DetectSIUL2 IP Dio Development Error DetectDio Version Info ApiDio Reverse Port BitsDio Flip Channel ApiDio Rea...

【Spring Boot】单元测试
单元测试 单元测试在日常项目开发中必不可少,Spring Boot提供了完善的单元测试框架和工具用于测试开发的应用。接下来介绍Spring Boot为单元测试提供了哪些支持,以及如何在Spring Boot项目中进行单元测试。 1.Spring Boot集成单元测试 单元测试主要用…...
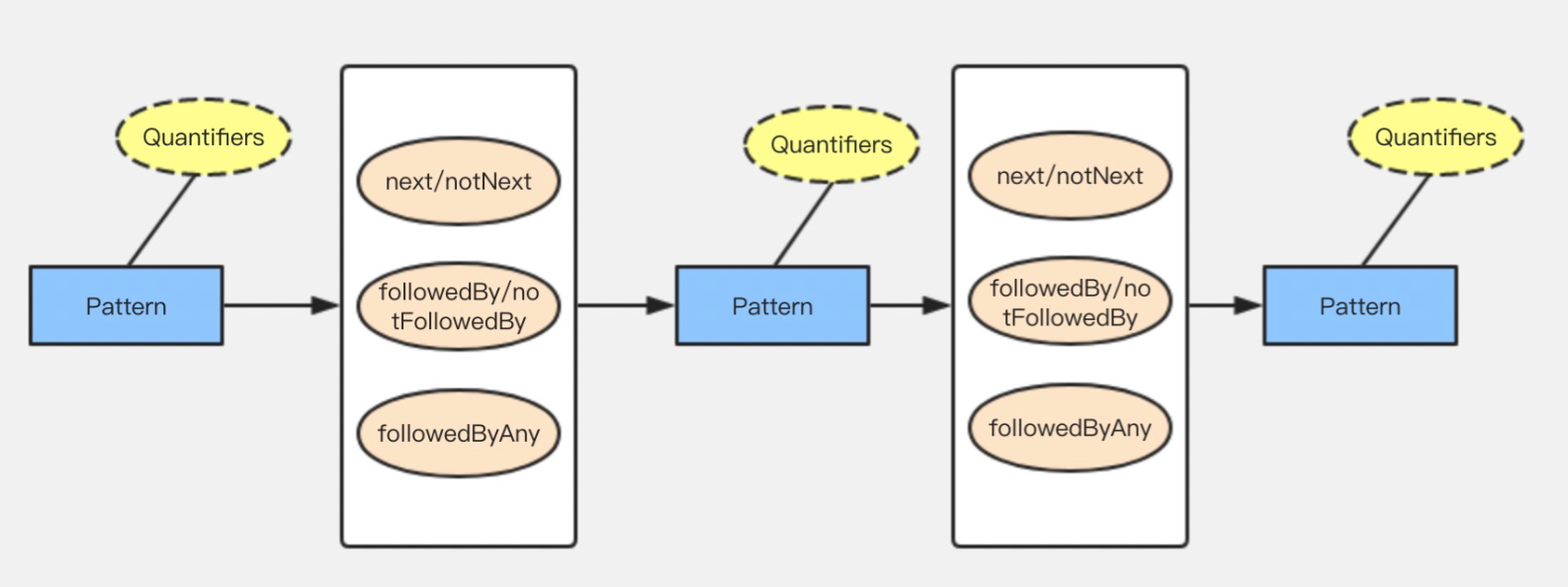
Flink CEP (一)原理及概念
目录 1.Flink CEP 原理 2.Flink API开发 2.1 模式 pattern 2.2 模式 pattern属性 2.3 模式间的关系 1.Flink CEP 原理 Flink CEP内部是用NFA(非确定有限自动机)来实现的,由点和边组成的一个状态图,以一个初始状态作为起点&am…...

vue3+taro+Nutui 开发小程序(二)
上一篇我们初始化了小程序项目,这一篇我们来整理一下框架 首先可以看到我的项目整理框架是这样的: components:这里存放封装的组件 custom-tab-bar:这里存放自己封装的自定义tabbar interface:这里放置了Ts的一些基本泛型,不用…...
Transformer 模型实用介绍:BERT
动动发财的小手,点个赞吧! 在 NLP 中,Transformer 模型架构是一场革命,极大地增强了理解和生成文本信息的能力。 在本教程[1]中,我们将深入研究 BERT(一种著名的基于 Transformer 的模型)&#…...
Spring详解(学习总结)
目录 一、Spring概述 (一)、Spring是什么? (二)、Spring框架发展历程 (三)、Spring框架的优势 (四)、Spring的体系结构 二、程序耦合与解耦合 (一&…...
【JavaEE】Spring中注解的方式去获取Bean对象
【JavaEE】Spring的开发要点总结(3) 文章目录 【JavaEE】Spring的开发要点总结(3)1. 属性注入1.1 Autowired注解1.2 依赖查找 VS 依赖注入1.3 配合Qualifier 筛选Bean对象1.4 属性注入的优缺点 2. Setter注入2.1 Autowired注解2.2…...

【基于CentOS 7 的iscsi服务】
目录 一、概述 1.简述 2.作用 3. iscsi 4.相关名称 二、使用步骤 - 构建iscsi服务 1.使用targetcli工具进入到iscsi服务器端管理界面 2.实现步骤 2.1 服务器端 2.2 客户端 2.2.1 安装软件 2.2.2 在认证文件中生成iqn编号 2.2.3 开启客户端服务 2.2.4 查找可用的i…...

解决安装依赖时报错:npm ERR! code ERESOLVE
系列文章目录 文章目录 系列文章目录前言一、错误原因二、解决方法三、注意事项总结 前言 在使用 npm 安装项目依赖时,有时会遇到错误信息 “npm ERR! code ERESOLVE”,该错误通常发生在依赖版本冲突或者依赖解析问题时。本文将详细介绍出现这个错误的原…...

98、简述Kafka的rebalance机制
简述Kafka的rebalance机制 consumer group中的消费者与topic下的partion重新匹配的过程 何时会产生rebalance: consumer group中的成员个数发生变化consumer 消费超时group订阅的topic个数发生变化group订阅的topic的分区数发生变化 coordinator: 通常是partition的leader节…...
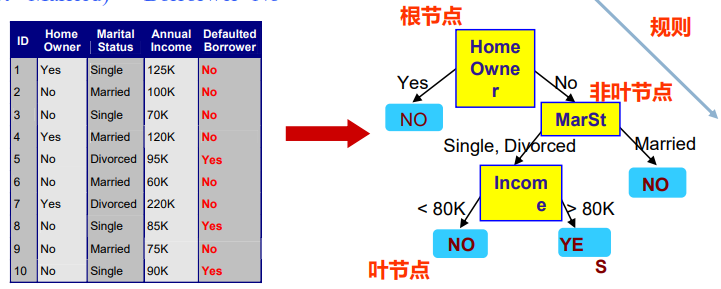
【人工智能】监督学习、分类问题、决策树、信息增益
文章目录 Decision Trees 决策树建立决策树分类模型的流程如何建立决策树?决策树学习表达能力决策树学习信息论在决策树学习中的应用特征选择准则一:信息增益举例结论不足回到餐厅的例子从12个例子中学到的决策树:Decision Trees 决策树 什么是决策树 —— 基本概念 非叶节…...
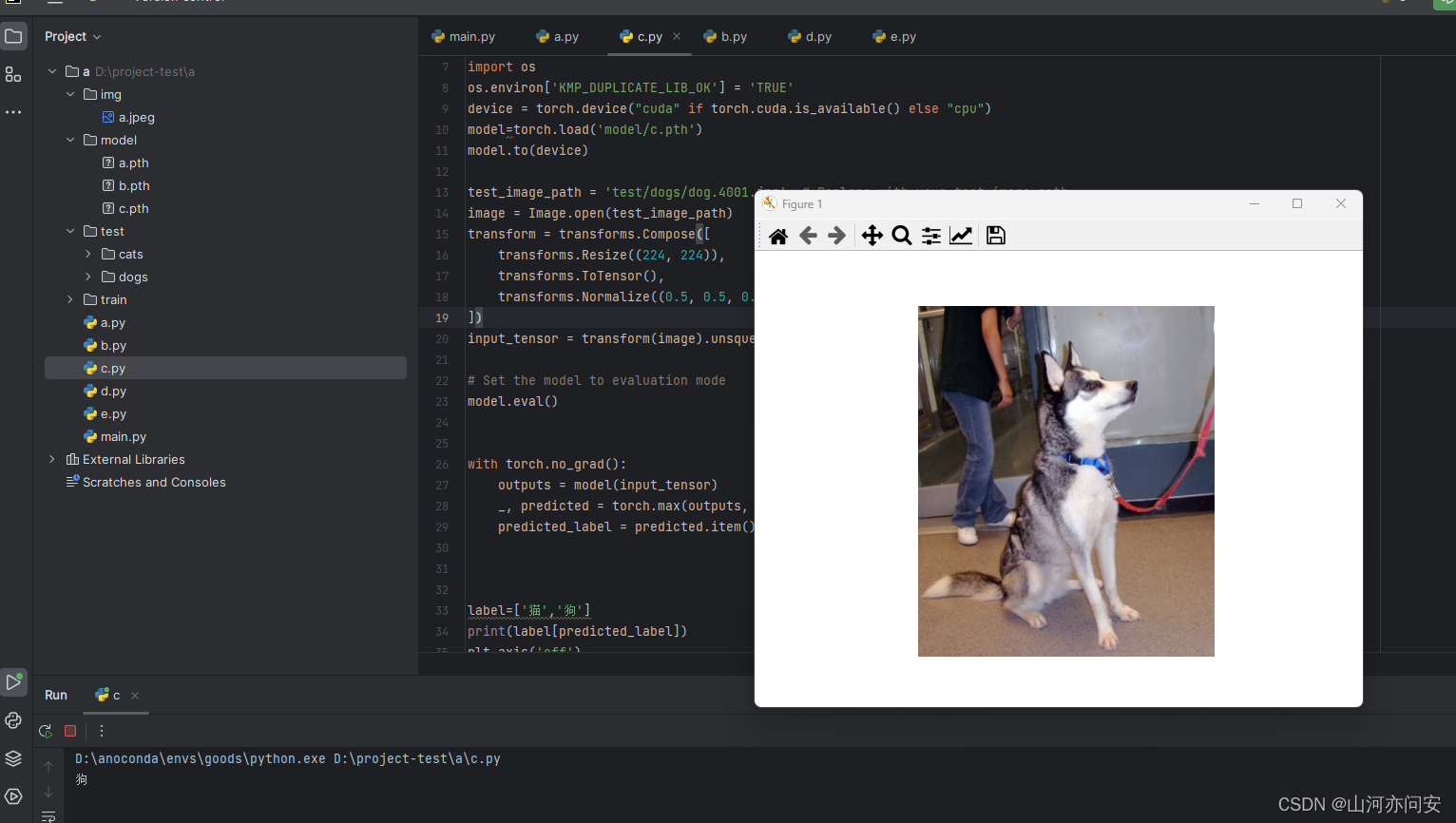
Pytorch迁移学习使用Resnet50进行模型训练预测猫狗二分类
目录 1.ResNet残差网络 1.1 ResNet定义 1.2 ResNet 几种网络配置 1.3 ResNet50网络结构 1.3.1 前几层卷积和池化 1.3.2 残差块:构建深度残差网络 1.3.3 ResNet主体:堆叠多个残差块 1.4 迁移学习猫狗二分类实战 1.4.1 迁移学习 1.4.2 模型训练 1.…...

HTML与XHTML的不同和各自特点
HTML和XHTML都是用于创建Web页面的标记语言。HTML是一种被广泛使用的标记语言,而XHTML是HTML的严格规范化版本。在本文中,我们将探讨HTML与XHTML之间的不同之处,以及它们各自的特点。 HTML与XHTML的不同之处 HTML和XHTML之间最大的不同在于它…...

初识Verilog
...

【实战指南】从零上手Praat:语音信号处理核心参数解析与调优
1. Praat入门:语音分析的瑞士军刀 第一次打开Praat时,我完全被它复古的界面吓到了——这玩意儿真的能分析语音?但用久了才发现,这个看似简陋的软件简直是语音学家的瑞士军刀。作为一款免费开源的语音分析工具,Praat能完…...

终极指南:5分钟快速免费解锁Cursor AI编程助手Pro功能完整教程
终极指南:5分钟快速免费解锁Cursor AI编程助手Pro功能完整教程 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached …...

零代码AI自动化测试:Midscene.js让每个人都能成为测试专家
零代码AI自动化测试:Midscene.js让每个人都能成为测试专家 【免费下载链接】midscene AI-powered, vision-driven UI automation for every platform. 项目地址: https://gitcode.com/GitHub_Trending/mid/midscene 你是否曾经为复杂的UI自动化测试感到头疼&…...

3步解锁百度网盘SVIP极速下载:告别限速困扰的完整指南
3步解锁百度网盘SVIP极速下载:告别限速困扰的完整指南 【免费下载链接】BaiduNetdiskPlugin-macOS For macOS.百度网盘 破解SVIP、下载速度限制~ 项目地址: https://gitcode.com/gh_mirrors/ba/BaiduNetdiskPlugin-macOS 还在为百度网盘那蜗牛般的下载速度而…...

Validity90图像格式揭秘:从原始数据到PNG指纹图像
Validity90图像格式揭秘:从原始数据到PNG指纹图像 【免费下载链接】Validity90 Reverse engineering of Validity/Synaptics 138a:0090, 138a:0094, 138a:0097, 06cb:0081, 06cb:009a fingerprint readers protocol 项目地址: https://gitcode.com/gh_mirrors/va/…...

LLMFarm性能优化技巧:提升模型推理速度和内存效率的10个方法
LLMFarm性能优化技巧:提升模型推理速度和内存效率的10个方法 【免费下载链接】LLMFarm llama and other large language models on iOS and MacOS offline using GGML library. 项目地址: https://gitcode.com/gh_mirrors/ll/LLMFarm LLMFarm是一款在iOS和ma…...
)
Spring Boot项目对接公司AD域,手把手搞定用户登录和密码重置(附SSL证书避坑指南)
Spring Boot企业级AD域集成实战:从登录到密码重置的全链路解决方案 当企业IT系统发展到一定规模,统一身份认证就成了刚需。上周我接手了一个内部ERP系统的改造项目,要求对接公司Active Directory实现员工单点登录——听起来简单,但…...

如何在Mac上免费实现NTFS磁盘完整读写:终极解决方案指南
如何在Mac上免费实现NTFS磁盘完整读写:终极解决方案指南 【免费下载链接】Free-NTFS-for-Mac Nigate: An open-source NTFS utility for Mac. It supports all Mac models (Intel and Apple Silicon), providing full read-write access, mounting, and management …...

掌控AMD Ryzen性能:5步精通SMUDebugTool硬件调试技巧
掌控AMD Ryzen性能:5步精通SMUDebugTool硬件调试技巧 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: https://git…...