PyTorch从零开始实现Transformer
文章目录
- 自注意力
- Transformer块
- 编码器
- 解码器块
- 解码器
- 整个Transformer
- 参考来源
- 全部代码(可直接运行)
自注意力
计算公式

代码实现
class SelfAttention(nn.Module):def __init__(self, embed_size, heads):super(SelfAttention, self).__init__()self.embed_size = embed_sizeself.heads = headsself.head_dim = embed_size // headsassert (self.head_dim * heads == embed_size), "Embed size needs to be div by heads"self.values = nn.Linear(self.head_dim, self.head_dim, bias=False)self.keys = nn.Linear(self.head_dim, self.head_dim, bias=False)self.queries = nn.Linear(self.head_dim, self.head_dim, bias=False)self.fc_out = nn.Linear(heads*self.head_dim, embed_size)def forward(self, values, keys, query, mask):N = query.shape[0] # the number of training examplesvalue_len, key_len, query_len = values.shape[1], keys.shape[1], query.shape[1]# Split embedding into self.heads piecesvalues = values.reshape(N, value_len, self.heads, self.head_dim)keys = keys.reshape(N, key_len, self.heads, self.head_dim)queries = query.reshape(N, query_len, self.heads, self.head_dim)values = self.values(values)keys = self.keys(keys)queries = self.queries(queries)energy = torch.einsum("nqhd,nkhd->nhqk", [queries, keys]) # 矩阵乘法,使用爱因斯坦标记法# queries shape: (N, query_len, heads, heads_dim)# keys shape: (N, key_len, heads, heads_dim)# energy shape: (N, heads, query_len, key_len)if mask is not None:energy = energy.masked_fill(mask==0, float("-1e20")) #Fills elements of self tensor with value where mask is Trueattention = torch.softmax(energy / (self.embed_size ** (1/2)), dim=3)out = torch.einsum("nhql, nlhd->nqhd", [attention, values]).reshape(N, query_len, self.heads*self.head_dim) # 矩阵乘法,使用爱因斯坦标记法einsum# attention shape: (N, heads, query_len, key_len)# values shape: (N, value_len, heads, head_dim)# after einsum (N, query_len, heads, head_dim) then flatten last two dimensionsout = self.fc_out(out)return out
Transformer块
我们把Transfomer块定义为如下图所示的结构,这个Transformer块在编码器和解码器中都有出现过。
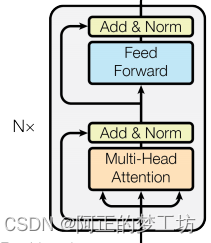
代码实现
class TransformerBlock(nn.Module):def __init__(self, embed_size, heads, dropout, forward_expansion):super(TransformerBlock, self).__init__()self.attention = SelfAttention(embed_size, heads)self.norm1 = nn.LayerNorm(embed_size)self.norm2 = nn.LayerNorm(embed_size)self.feed_forward = nn.Sequential(nn.Linear(embed_size, forward_expansion*embed_size),nn.ReLU(),nn.Linear(forward_expansion*embed_size, embed_size))self.dropout = nn.Dropout(dropout)def forward(self, value, key, query, mask):attention = self.attention(value, key, query, mask)x = self.dropout(self.norm1(attention + query))forward = self.feed_forward(x)out = self.dropout(self.norm2(forward + x))return out
编码器
编码器结构如下所示,Inputs经过Input Embedding 和Positional Encoding之后,通过多个Transformer块
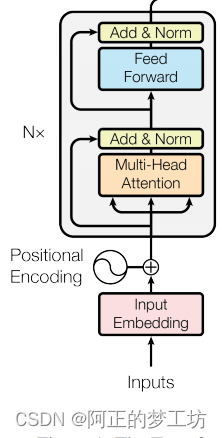
代码实现
class Encoder(nn.Module):def __init__(self, src_vocab_size,embed_size,num_layers,heads,device,forward_expansion,dropout,max_length):super(Encoder, self).__init__()self.embed_size = embed_sizeself.device = deviceself.word_embedding = nn.Embedding(src_vocab_size, embed_size)self.position_embedding = nn.Embedding(max_length, embed_size)self.layers = nn.ModuleList([TransformerBlock(embed_size,heads,dropout=dropout,forward_expansion=forward_expansion)for _ in range(num_layers)])self.dropout = nn.Dropout(dropout)def forward(self, x, mask):N, seq_lengh = x.shapepositions = torch.arange(0, seq_lengh).expand(N, seq_lengh).to(self.device)out = self.dropout(self.word_embedding(x) + self.position_embedding(positions))for layer in self.layers:out = layer(out, out, out, mask)return out
解码器块
解码器块结构如下图所示
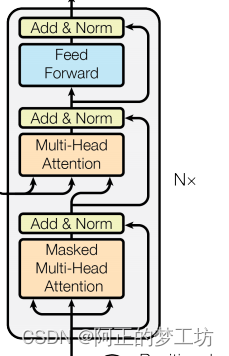
代码实现
class DecoderBlock(nn.Module):def __init__(self, embed_size, heads, forward_expansion, dropout, device):super(DecoderBlock, self).__init__()self.attention = SelfAttention(embed_size, heads)self.norm = nn.LayerNorm(embed_size)self.transformer_block = TransformerBlock(embed_size, heads, dropout, forward_expansion)self.dropout = nn.Dropout(dropout)def forward(self, x, value, key, src_mask, trg_mask):attention = self.attention(x, x, x, trg_mask)query = self.dropout(self.norm(attention + x))out = self.transformer_block(value, key, query, src_mask)return out
解码器
解码器块加上word embedding 和 positional embedding之后构成解码器
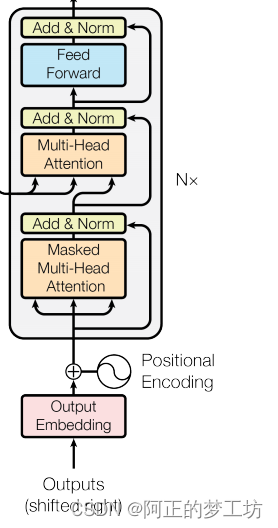
代码实现
class Decoder(nn.Module):def __init__(self, trg_vocab_size, embed_size, num_layers, heads, forward_expansion, dropout, device, max_length):super(Decoder, self).__init__()self.device = deviceself.word_embedding = nn.Embedding(trg_vocab_size, embed_size)self.position_embedding = nn.Embedding(max_length, embed_size)self.layers = nn.ModuleList([DecoderBlock(embed_size, heads, forward_expansion, dropout, device)for _ in range(num_layers)])self.fc_out = nn.Linear(embed_size, trg_vocab_size)self.dropout = nn.Dropout(dropout)def forward(self, x, enc_out, src_mask, trg_mask):N, seq_length = x.shapepositions = torch.arange(0, seq_length).expand(N, seq_length).to(self.device)x = self.dropout((self.word_embedding(x) + self.position_embedding(positions)))for layer in self.layers:x = layer(x, enc_out, enc_out, src_mask, trg_mask)out = self.fc_out(x)return out
整个Transformer
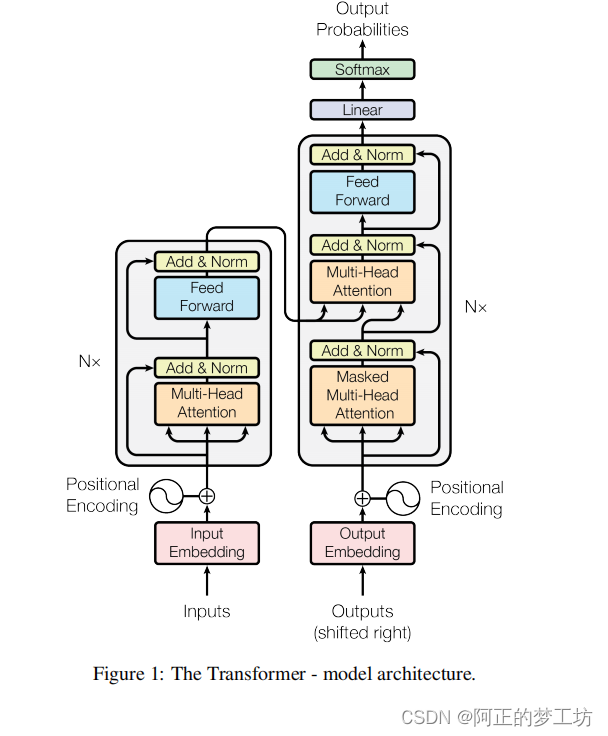
代码实现
class Transformer(nn.Module):def __init__(self,src_vocab_size, trg_vocab_size,src_pad_idx,trg_pad_idx,embed_size=256,num_layers=6,forward_expansion=4,heads=8,dropout=0,device="cuda",max_length=100):super(Transformer, self).__init__()self.encoder = Encoder(src_vocab_size,embed_size,num_layers,heads,device,forward_expansion,dropout,max_length)self.decoder = Decoder(trg_vocab_size,embed_size,num_layers,heads,forward_expansion,dropout,device,max_length)self.src_pad_idx = src_pad_idxself.trg_pad_idx = trg_pad_idxself.device = devicedef make_src_mask(self, src):src_mask = (src != self.src_pad_idx).unsqueeze(1).unsqueeze(2)#(N, 1, 1, src_len)return src_mask.to(self.device)def make_trg_mask(self, trg):N, trg_len = trg.shapetrg_mask = torch.tril(torch.ones((trg_len, trg_len))).expand(N, 1, trg_len, trg_len)return trg_mask.to(self.device)def forward(self, src, trg):src_mask = self.make_src_mask(src)trg_mask = self.make_trg_mask(trg)enc_src = self.encoder(src, src_mask)out = self.decoder(trg, enc_src, src_mask, trg_mask)return out参考来源
[1] https://www.youtube.com/watch?v=U0s0f995w14
[2] https://github.com/aladdinpersson/Machine-Learning-Collection/blob/master/ML/Pytorch/more_advanced/transformer_from_scratch/transformer_from_scratch.py
[3] https://arxiv.org/abs/1706.03762
[4] https://www.youtube.com/watch?v=pkVwUVEHmfI
全部代码(可直接运行)
import torch
import torch.nn as nnclass SelfAttention(nn.Module):def __init__(self, embed_size, heads):super(SelfAttention, self).__init__()self.embed_size = embed_sizeself.heads = headsself.head_dim = embed_size // headsassert (self.head_dim * heads == embed_size), "Embed size needs to be div by heads"self.values = nn.Linear(self.head_dim, self.head_dim, bias=False)self.keys = nn.Linear(self.head_dim, self.head_dim, bias=False)self.queries = nn.Linear(self.head_dim, self.head_dim, bias=False)self.fc_out = nn.Linear(heads*self.head_dim, embed_size)def forward(self, values, keys, query, mask):N = query.shape[0] # the number of training examplesvalue_len, key_len, query_len = values.shape[1], keys.shape[1], query.shape[1]# Split embedding into self.heads piecesvalues = values.reshape(N, value_len, self.heads, self.head_dim)keys = keys.reshape(N, key_len, self.heads, self.head_dim)queries = query.reshape(N, query_len, self.heads, self.head_dim)values = self.values(values)keys = self.keys(keys)queries = self.queries(queries)energy = torch.einsum("nqhd,nkhd->nhqk", [queries, keys])# queries shape: (N, query_len, heads, heads_dim)# keys shape: (N, key_len, heads, heads_dim)# energy shape: (N, heads, query_len, key_len)if mask is not None:energy = energy.masked_fill(mask==0, float("-1e20")) #Fills elements of self tensor with value where mask is Trueattention = torch.softmax(energy / (self.embed_size ** (1/2)), dim=3)out = torch.einsum("nhql, nlhd->nqhd", [attention, values]).reshape(N, query_len, self.heads*self.head_dim)# attention shape: (N, heads, query_len, key_len)# values shape: (N, value_len, heads, head_dim)# after einsum (N, query_len, heads, head_dim) then flatten last two dimensionsout = self.fc_out(out)return outclass TransformerBlock(nn.Module):def __init__(self, embed_size, heads, dropout, forward_expansion):super(TransformerBlock, self).__init__()self.attention = SelfAttention(embed_size, heads)self.norm1 = nn.LayerNorm(embed_size)self.norm2 = nn.LayerNorm(embed_size)self.feed_forward = nn.Sequential(nn.Linear(embed_size, forward_expansion*embed_size),nn.ReLU(),nn.Linear(forward_expansion*embed_size, embed_size))self.dropout = nn.Dropout(dropout)def forward(self, value, key, query, mask):attention = self.attention(value, key, query, mask)x = self.dropout(self.norm1(attention + query))forward = self.feed_forward(x)out = self.dropout(self.norm2(forward + x))return outclass Encoder(nn.Module):def __init__(self, src_vocab_size,embed_size,num_layers,heads,device,forward_expansion,dropout,max_length):super(Encoder, self).__init__()self.embed_size = embed_sizeself.device = deviceself.word_embedding = nn.Embedding(src_vocab_size, embed_size)self.position_embedding = nn.Embedding(max_length, embed_size)self.layers = nn.ModuleList([TransformerBlock(embed_size,heads,dropout=dropout,forward_expansion=forward_expansion)for _ in range(num_layers)])self.dropout = nn.Dropout(dropout)def forward(self, x, mask):N, seq_lengh = x.shapepositions = torch.arange(0, seq_lengh).expand(N, seq_lengh).to(self.device)out = self.dropout(self.word_embedding(x) + self.position_embedding(positions))for layer in self.layers:out = layer(out, out, out, mask)return outclass DecoderBlock(nn.Module):def __init__(self, embed_size, heads, forward_expansion, dropout, device):super(DecoderBlock, self).__init__()self.attention = SelfAttention(embed_size, heads)self.norm = nn.LayerNorm(embed_size)self.transformer_block = TransformerBlock(embed_size, heads, dropout, forward_expansion)self.dropout = nn.Dropout(dropout)def forward(self, x, value, key, src_mask, trg_mask):attention = self.attention(x, x, x, trg_mask)query = self.dropout(self.norm(attention + x))out = self.transformer_block(value, key, query, src_mask)return outclass Decoder(nn.Module):def __init__(self, trg_vocab_size, embed_size, num_layers, heads, forward_expansion, dropout, device, max_length):super(Decoder, self).__init__()self.device = deviceself.word_embedding = nn.Embedding(trg_vocab_size, embed_size)self.position_embedding = nn.Embedding(max_length, embed_size)self.layers = nn.ModuleList([DecoderBlock(embed_size, heads, forward_expansion, dropout, device)for _ in range(num_layers)])self.fc_out = nn.Linear(embed_size, trg_vocab_size)self.dropout = nn.Dropout(dropout)def forward(self, x, enc_out, src_mask, trg_mask):N, seq_length = x.shapepositions = torch.arange(0, seq_length).expand(N, seq_length).to(self.device)x = self.dropout((self.word_embedding(x) + self.position_embedding(positions)))for layer in self.layers:x = layer(x, enc_out, enc_out, src_mask, trg_mask)out = self.fc_out(x)return outclass Transformer(nn.Module):def __init__(self,src_vocab_size, trg_vocab_size,src_pad_idx,trg_pad_idx,embed_size=256,num_layers=6,forward_expansion=4,heads=8,dropout=0,device="cuda",max_length=100):super(Transformer, self).__init__()self.encoder = Encoder(src_vocab_size,embed_size,num_layers,heads,device,forward_expansion,dropout,max_length)self.decoder = Decoder(trg_vocab_size,embed_size,num_layers,heads,forward_expansion,dropout,device,max_length)self.src_pad_idx = src_pad_idxself.trg_pad_idx = trg_pad_idxself.device = devicedef make_src_mask(self, src):src_mask = (src != self.src_pad_idx).unsqueeze(1).unsqueeze(2)#(N, 1, 1, src_len)return src_mask.to(self.device)def make_trg_mask(self, trg):N, trg_len = trg.shapetrg_mask = torch.tril(torch.ones((trg_len, trg_len))).expand(N, 1, trg_len, trg_len)return trg_mask.to(self.device)def forward(self, src, trg):src_mask = self.make_src_mask(src)trg_mask = self.make_trg_mask(trg)enc_src = self.encoder(src, src_mask)out = self.decoder(trg, enc_src, src_mask, trg_mask)return outif __name__ == "__main__":device = torch.device("cuda" if torch.cuda.is_available() else "cpu")print(device)x = torch.tensor([[1, 5, 6, 4, 3, 9, 5, 2, 0], [1, 8, 7, 3, 4, 5, 6, 7, 2]]).to(device)trg = torch.tensor([[1, 7, 4, 3, 5, 9, 2, 0], [1, 5, 6, 2, 4, 7, 6, 2]]).to(device)src_pad_idx = 0trg_pad_idx = 0src_vocab_size = 10trg_vocab_size = 10model = Transformer(src_vocab_size, trg_vocab_size, src_pad_idx, trg_pad_idx, device=device).to(device)out = model(x, trg[:, :-1])print(out.shape)相关文章:
PyTorch从零开始实现Transformer
文章目录 自注意力Transformer块编码器解码器块解码器整个Transformer参考来源全部代码(可直接运行) 自注意力 计算公式 代码实现 class SelfAttention(nn.Module):def __init__(self, embed_size, heads):super(SelfAttention, self).__init__()self.e…...

运动蓝牙耳机什么牌子的好用、最好用的运动蓝牙耳机推荐
音乐是运动的灵魂,而一款优秀的运动耳机则是让音乐与我们的身体完美融合的关键。今天,我推荐五款备受运动爱好者喜爱的耳机,它们以卓越的音质、舒适的佩戴和出色的稳定性能脱颖而出,助你在运动中创造最佳状态。 1、NANK南卡Runne…...
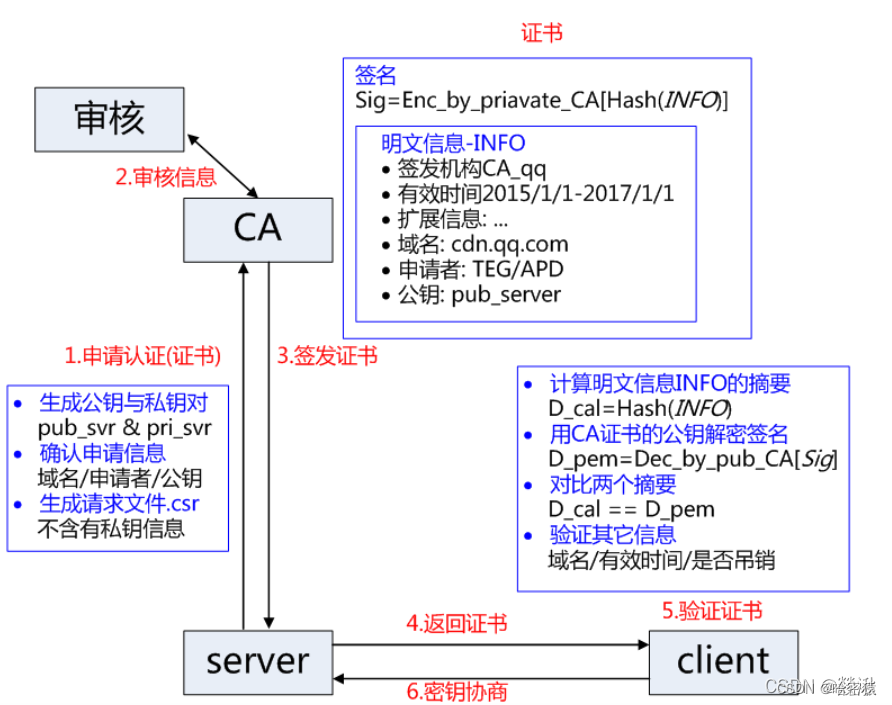
HTTP、HTTPS协议详解
文章目录 HTTP是什么报文结构请求头部响应头部 工作原理用户点击一个URL链接后,浏览器和web服务器会执行什么http的版本持久连接和非持久连接无状态与有状态Cookie和Sessionhttp方法:get和post的区别 状态码 HTTPS是什么ssl如何搞到证书nginx中的部署 加…...

【算法与数据结构】222、LeetCode完全二叉树的节点个数
文章目录 一、题目二、一般遍历解法三、利用完全二叉树性质四、完整代码 所有的LeetCode题解索引,可以看这篇文章——【算法和数据结构】LeetCode题解。 一、题目 二、一般遍历解法 思路分析:利用层序遍历,然后用num记录节点数量。其他的例如…...

登录和注册表单的11个HTML最佳实践
原文:11 HTML best practices for login & sign-up forms 原作者:Andrey Sitnik 翻译已获原文作者许可,禁止转载和商用 大多数网站都有登录或注册表单;它们是业务转换的关键部分。然而,即使是流行的站点也没有实现本文中提到的…...

Mysql删除历史数据
Mysql定时删除历史数据 实现 1.创建存储过程(函数) SQL DROP PROCEDURE IF EXISTS KeepDatasWith30Days CREATE PROCEDURE KeepDatasWith30Days() BEGINSELECT maxId:max(Id) FROM tableName WHERE CreateTime<DATE(DATE_SUB(NOW(),INTERVAL 31 D…...

Python—数据结构(一)
先放一张自己学习和整理归纳的思维导图,以便让大家都知道我自己的整体学习路线。 数据结构的学习路上内容枯燥,但坚持下来一定有很大的收获!加油💪🏻! 数据结构 数据的概念数据元素: 若干基本…...

离线环境安装flask依赖包
找到当前版本需要的所有依赖包,生产flask项目生成项目依赖包文件requirements.txt 1)在当前项目目录下 生成requirements文件:pip freeze >requirements.txt 执行requirements文件,安装依赖包:pip install -r requirements.t…...
ChatGPT与Claude对比分析
一 简介 1、ChatGPT: 访问地址:https://chat.openai.com/ 由OpenAI研发,2022年11月发布。基于 transformer 结构的大规模语言模型,包含1750亿参数。训练数据集主要是网页文本,聚焦于流畅的对话交互。对话风格友好,回复通顺灵活,富有创造性。存在一定的安全性问题,可…...

登录和注册页面 - 验证码功能的实现
目录 1. 生成验证码 2. 将本地验证码发布成 URL 3. 后端返回验证码的 URL 给前端 4. 前端将用户输入的验证码传给后端 5. 后端验证验证码 1. 生成验证码 使用hutool 工具生成验证码. 1.1 添加 hutool 验证码依赖 <!-- 验证码 --> <dependency><groupId…...

HDFS的文件块大小(重点)
HDFS 中的文件在物理上是分块存储 (Block ) , 块的大小可以通过配置参数( dfs.blocksize)来规定,默认大小在Hadoop2.x/3.x版本中是128M,1.x版本中是64M。 如果一个文件文件小于128M,该文件会占…...
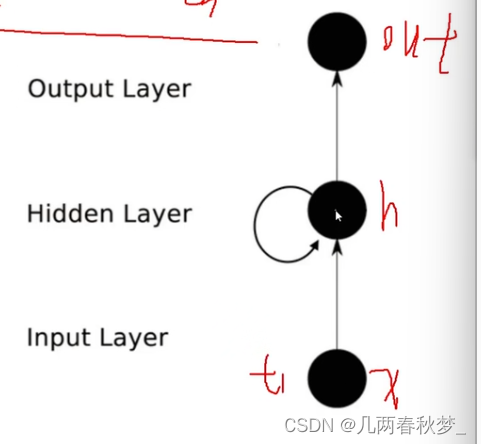
深度学习(二)
目录 一、神经网络 整体架构: 架构细节: 神经元个数的影响: 神经网络过拟合解决: 卷积网络 整体架构: 卷积层 边缘填充 特征尺寸计算 池化层 特征图变化 递归神经网络 一、神经网络 整体架构: 图中分别为输入层、隐层1、隐层2、输出层 通过输入层输入某数值…...
方法函数)
无涯教程-jQuery - wrapInner( html )方法函数
wrapInner(html)方法使用HTML结构包装每个匹配元素(包括文本节点)的内部子内容。 wrapInner( html ) - 语法 selector.wrapInner( html ) 这是此方法使用的所有参数的描述- html - 将动态创建并环绕目标的HTML字符串。 wrapInner( html ) - 示例 以下是一个简单的示例…...
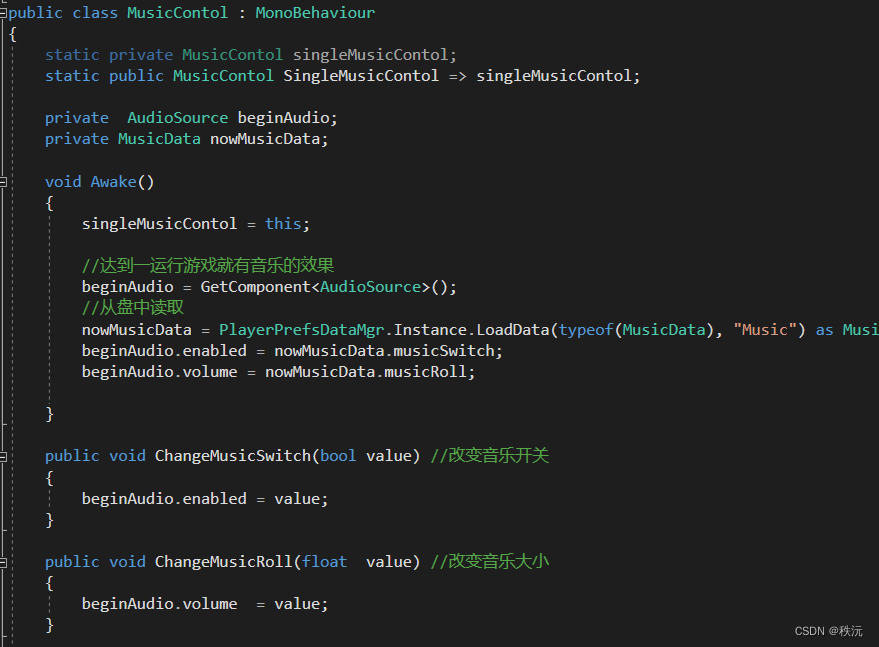
【unity之IMGUI实践】单例模式管理数据存储【二】
👨💻个人主页:元宇宙-秩沅 👨💻 hallo 欢迎 点赞👍 收藏⭐ 留言📝 加关注✅! 👨💻 本文由 秩沅 原创 👨💻 收录于专栏:uni…...

【C++】开源:Linux端ALSA音频处理库
😏★,:.☆( ̄▽ ̄)/$:.★ 😏 这篇文章主要介绍Linux端ALSA音频处理库。 无专精则不能成,无涉猎则不能通。。——梁启超 欢迎来到我的博客,一起学习,共同进步。 喜欢的朋友可以关注一下,…...

【Linux | Shell】结构化命令2 - test命令、方括号测试条件、case命令
目录 一、概述二、test 命令2.1 test 命令2.2 方括号测试条件2.3 test 命令和测试条件可以判断的 3 类条件2.3.1 数值比较2.3.2 字符串比较 三、复合条件测试四、if-then 的高级特性五、case 命令 一、概述 上篇文章介绍了 if 语句相关知识。但 if 语句只能执行命令,…...

基于单片机的语音识别智能垃圾桶垃圾分类的设计与实现
功能介绍 以51单片机作为主控系统;液晶显示当前信息和状态;通过语音识别模块对当前垃圾种类进行语音识别; 通过蜂鸣器进行声光报警提醒垃圾桶已满;采用舵机控制垃圾桶打开关闭;超声波检测当前垃圾桶满溢程度࿱…...
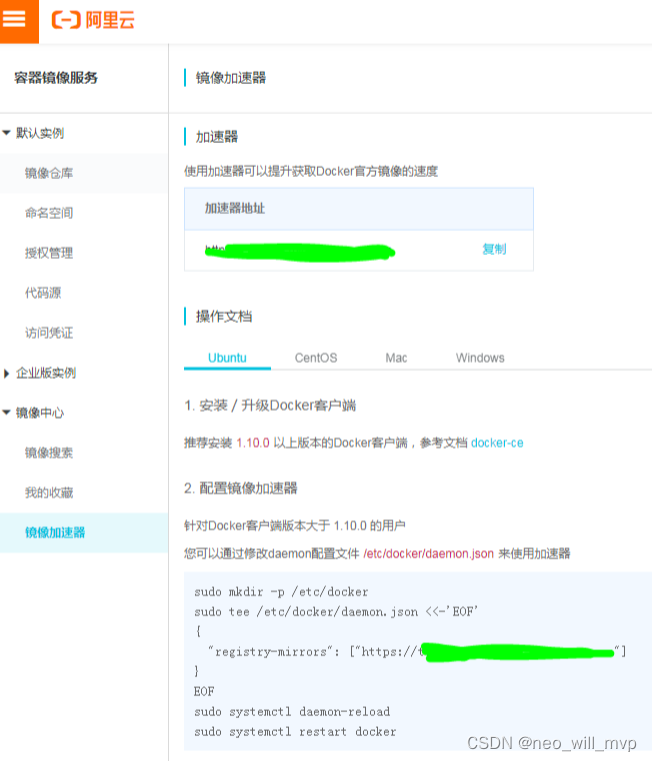
最新版本docker 设置国内镜像源 加速办法
解决问题:加速 docker 设置国内镜像源 目录: 国内加速地址 修改方法 国内加速地址 1.Docker中国区官方镜像 https://registry.docker-cn.com 2.网易 http://hub-mirror.c.163.com 3.ustc https://docker.mirrors.ustc.edu.cn 4.中国科技大学 https://docker.mirrors…...
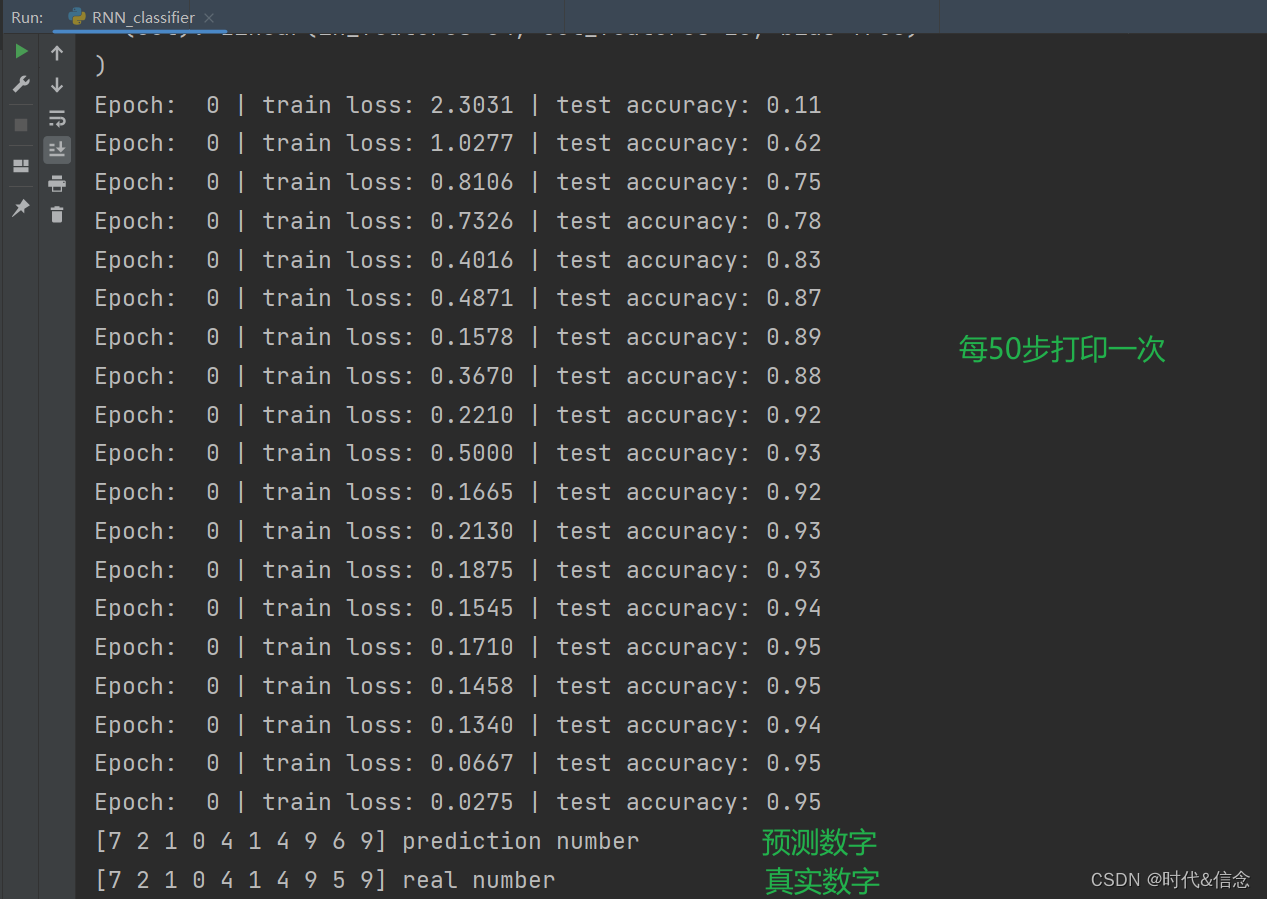
深度学习——LSTM解决分类问题
RNN基本介绍 概述 循环神经网络(Recurrent Neural Network,RNN)是一种深度学习模型,主要用于处理序列数据,如文本、语音、时间序列等具有时序关系的数据。 核心思想 RNN的关键思想是引入了循环结构,允许…...
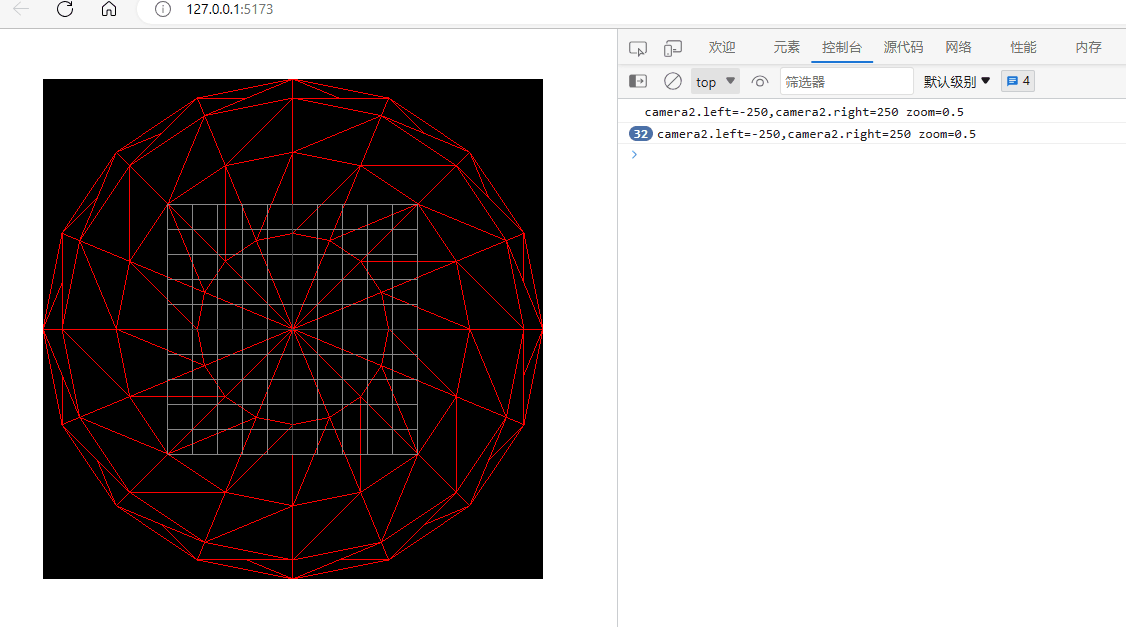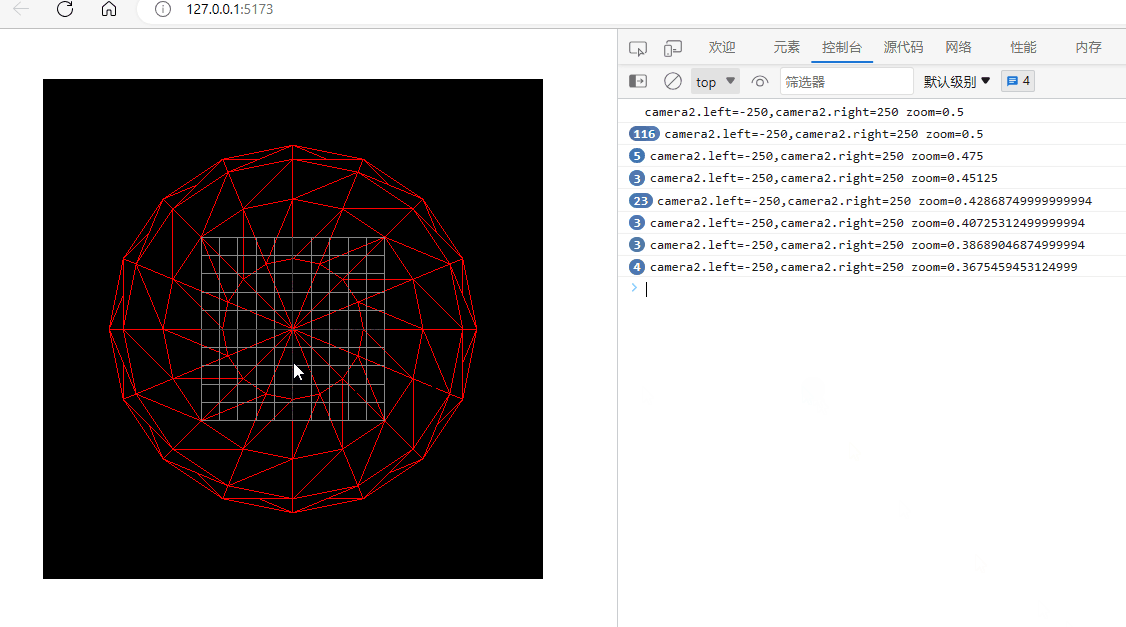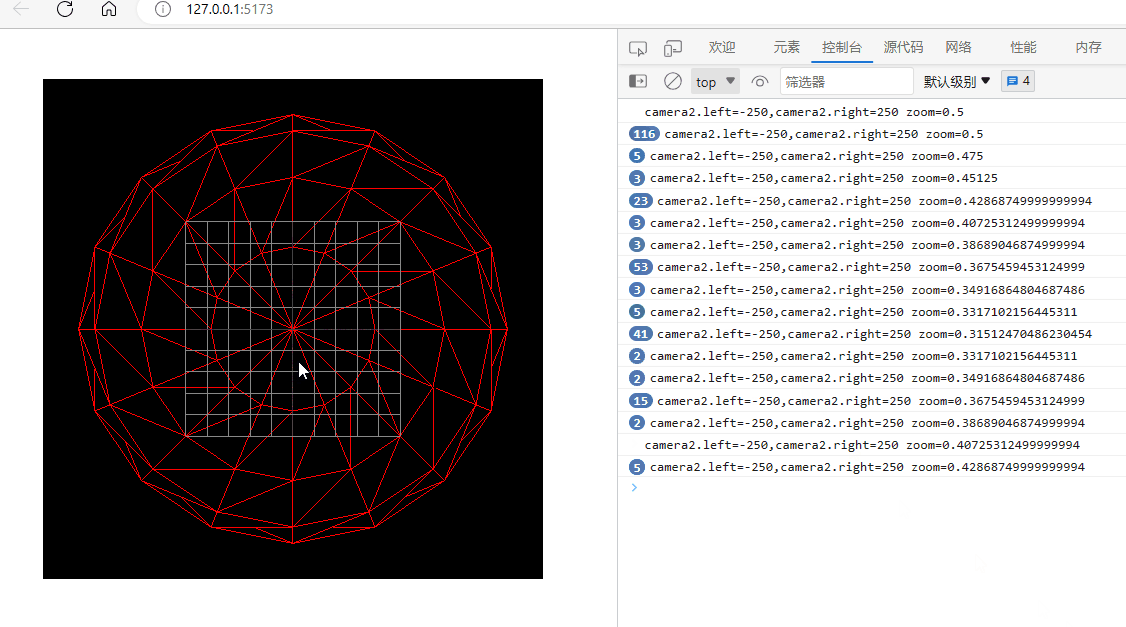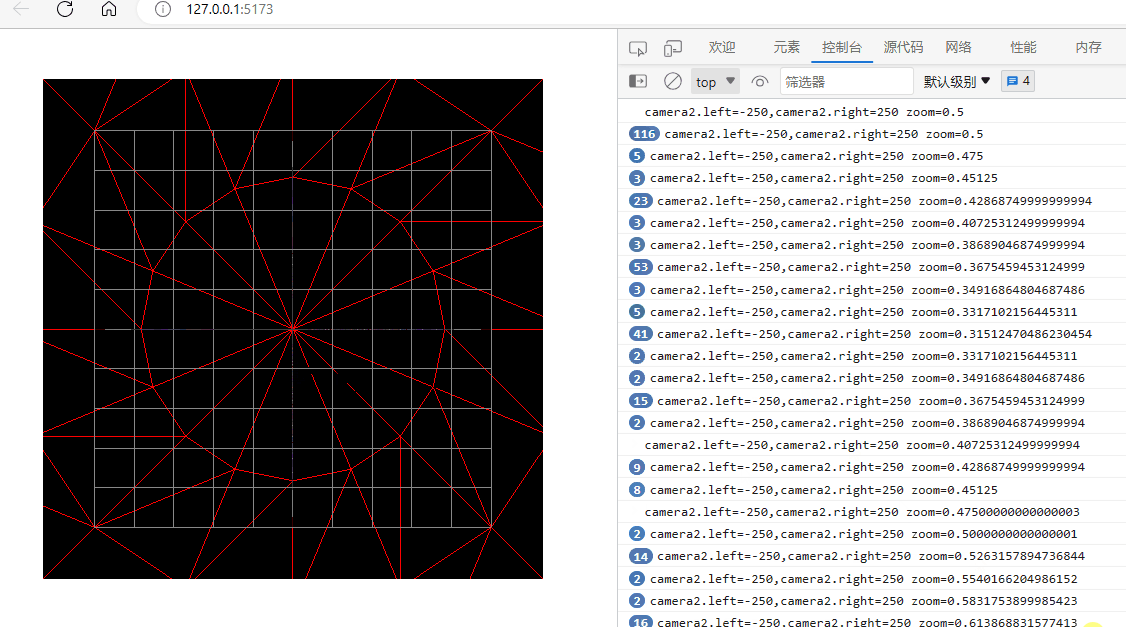
three.js入门二:相机的zoom参数
环境: threejs:129 (在浏览器的控制台下输入: window.__THREE__即可查看版本)vscodewindowedge 透视相机或正交相机都有一个zoom参数,它可以用来将相机排到的内容在canvas上缩放显示。 注意:…...

3步掌握Blender 3MF插件:构建高效3D打印工作流
3步掌握Blender 3MF插件:构建高效3D打印工作流 【免费下载链接】Blender3mfFormat Blender add-on to import/export 3MF files 项目地址: https://gitcode.com/gh_mirrors/bl/Blender3mfFormat 在3D打印和数字制造领域,模型格式转换是连接设计与…...

《第一大道》铺前路,《凰标》立后世千年文化准则@凤凰标志
任何一场完整的文化复兴,必然包含两个阶段: 先破局开路,再立序定规。 无破局,则无出路;无定规,则无长存。一破 一立破局立规《第一大道》《凰标》武 突围 开荒 破弊文 守正 定调 传世让众生有路可走…...

合肥全屋定制,真的能满足我的独特需求吗?
在合肥,全屋定制大概率能满足您的独特需求,但这并非绝对,关键在于您的具体要求、预算以及选择的品牌。✅ 合肥市场能满足的“独特需求”个性化风格与功能设计合肥的定制品牌已相当成熟,能够承接各种个性化需求,而非简单…...

HiveWE:现代化魔兽争霸III地图编辑器完全指南
HiveWE:现代化魔兽争霸III地图编辑器完全指南 【免费下载链接】HiveWE A Warcraft III world editor. 项目地址: https://gitcode.com/gh_mirrors/hi/HiveWE 还在为魔兽争霸III原版地图编辑器缓慢的加载速度和复杂的操作而烦恼吗?HiveWE作为一款专…...

开源任务恢复工具openclaw-task-recovery:轻量级断点续做解决方案
1. 项目概述:一个关于任务恢复的开源工具最近在整理自己的自动化脚本和任务调度系统时,遇到了一个老生常谈但又非常棘手的问题:任务中断后的恢复。无论是数据处理流水线、爬虫任务,还是长时间运行的批处理作业,网络抖动…...

物联网数据完整性保障的多层级架构设计与实践
1. 物联网数据完整性的核心挑战在传统IT系统中,数据流动遵循着严格的请求-响应模式,服务器和客户端之间的交互是可预测且有序的。但物联网环境彻底颠覆了这一范式——数以亿计的终端设备以异步、不可预测的方式产生数据流,这种特性使得数据完…...

光耦LED寿命评估与可靠性设计实践
1. 光耦LED寿命评估的核心价值 在工业自动化控制系统中,我曾亲眼目睹一个价值数百万的生产线因为光耦器件失效导致整个控制系统误动作。故障排查时发现,正是光耦内部的LED光源经过5年连续工作后出现严重光衰,使得信号传输出现错误。这个教训让…...

AI代理如何通过MCP协议实现DeFi自动化操作与安全交互
1. 项目概述:当DeFi遇上AI代理,一场链上金融的自动化革命如果你和我一样,在DeFi(去中心化金融)世界里摸爬滚打了好几年,从早期的流动性挖矿到后来的各种收益聚合器,一个深刻的体会是:…...

Meta与斯坦福:字节级AI实现逐字节生成瓶颈突破与速度提升能力
这项由Meta人工智能基础研究团队(FAIR at Meta)与斯坦福大学、华盛顿大学联合开展的研究,于2026年5月发表,论文预印本编号为arXiv:2605.08044v1。感兴趣的读者可以通过该编号在arXiv平台上查阅完整论文。现代语言模型的工作方式&a…...

流水线插件开发从3天缩短到10分钟:嘉为蓝鲸AI技能实战
流水线插件开发从3天缩短到10分钟:嘉为蓝鲸AI技能实战 在企业 DevOps 落地中,流水线插件是工具对接、流程沉淀、平台扩展的核心。但插件开发往往面临门槛高、周期长、质量不稳定等问题。一个简单插件,两三天就这么耗进去了。01 插件开发的真实…...