实训笔记7.25
实训笔记7.25
- 7.25笔记
- 一、MapReduce的特殊使用场景
- 1.1 通过MapReduce程序实现多文件Join操作
- 1.1.1 通过在Reduce端实现join操作
- 1.1.2 通过在Map端实现join操作
- 1.2 MapReduce中的计数器的使用
- 1.2.1 计数器使用两种方式
- 1.3 MapReduce实现数据清洗
- 二、MapReduce的OutputFormat机制
- 三、MapReduce整体流程涉及到一些核心组件
- 四、MapReduce的调优相关知识点
- 4.1 针对磁盘IO问题,MR程序出现了一种压缩和解压缩机制,可以解决MR程序运行中涉及到大量磁盘IO的问题
- 4.1.1 常用的压缩算法的适用场景
- 4.1.2 MapReduce程序可以压缩数据的位置
- 4.1.3 在MapReduce中开启压缩机制
- 五、Hadoop的第三大组成--YARN框架
- 5.1 YARN的基本架构组成
- 5.1.1 ResourceManager:YARN集群的管理者
- 5.1.2 NodeManager
- 5.1.3 Container
- 5.1.4 ApplicationMaster
- 5.2 YARN的详细工作流程--运行MapReduce
- 六、YARN的资源调度器问题
- 6.1 YARN中一共三种的资源调度器
- 6.1.1 FIFIO资源调度器
- 6.1.2 容量调度器
- 6.1.3 公平调度器
- 6.1.4 修改:yarn-site.xml
- 6.2 默认使用的容量调度器,容量调度器可以有多个队列,每一个队列占用集群的部分资源,默认情况下容量调度只有一个队列default,队列占有集群的所有资源,如果配置容量调度器的第二个队列:capacity-scheduler.xml
- 七、YARN的web网站问题
- 7.1 存在问题
- 7.2 解决上述问题的方案
- 代码示例
7.25笔记
一、MapReduce的特殊使用场景
1.1 通过MapReduce程序实现多文件Join操作
1.1.1 通过在Reduce端实现join操作
核心思路是将多个文件读取之后,以多文件的关联字段为key,剩余为value发送给reduce,reduce通过关联字段将value聚合,随后进行join操作
Reduce端join非常容易出现数据倾斜问题
1.1.2 通过在Map端实现join操作
核心思路将多文件中的这些小文件(几十兆或者几十KB左右)在驱动程序中把数据文件缓存起来,只对大文件数据进行切片处理,在map处理数据时,现在setup方法中对缓存的小文件进行读取缓存(缓存的时候以关联字段为key进行缓存)
1.2 MapReduce中的计数器的使用
计数器在MapReduce中是用来统计分布式计算程序中一些感兴趣数据的一些数值。计数器MR程序运行中已经给我们提供了很多的计数器,如果我们觉得这些计数中没有我们所需要的数据的数值,我们可以自定义计数器去使用。
1.2.1 计数器使用两种方式
-
使用普通的字符串
context,getCounter(String groupName,String counterName).increment(num); -
使用枚举类
context.getCounter(Enum的对象).increment(num)
1.3 MapReduce实现数据清洗
数据清洗就是我们把原始数据中一些不合法非法,不感兴趣的数据清洗处理掉
因此数据清洗一般只需要map阶段即可,在map阶段只需要对合法的数据进行context,write操作,不合法的数据直接舍弃
二、MapReduce的OutputFormat机制
TextOutputFormat:输出的是纯文本文档数据,key-value之间以\t分割的,一个kv使用占用一行
SequenceFileOutputFormat:输出是一个SequenceFile文件格式的数据,SequenceFile文件特殊在文件是一个普通的文件,但是文件中的数据是二进制的并且可以被压缩的数据 文件没有被压缩,只是数据被压缩了,数据压缩还有三种模式:none、record、block
默认情况下一个reduceTask输出一个文件,文件名固定的part-r/m-xxxxx
自定义OutputFormat实现相关数据的写出
三、MapReduce整体流程涉及到一些核心组件
- InputFormat组件
- 切片机制
- 读取kv机制
- Mapper组件处理一个切片的数据
- Partitioner组件map阶段的输出的数据计算分区使用
- WritableComparable组件进行输出数据排序,三次排序
- Combiner组件(可选组件)进行map端输出数据的局部合并
- Reduce组件处理一个分区的数据,聚合处理
- OutputFormat组件输出最终的结果数据
四、MapReduce的调优相关知识点
MapReduce运行中,可能会产生很多影响MR计算效率的一些问题:数据倾斜问题、大量的磁盘IO、小文件过多…
4.1 针对磁盘IO问题,MR程序出现了一种压缩和解压缩机制,可以解决MR程序运行中涉及到大量磁盘IO的问题
压缩和解压缩是MR程序提供的一种,在Map输出或者reduce输出,或者map输入之前,可以通过指定的压缩算法对文件或者中间数据进行压缩,这样的话可以减少磁盘IO的数据量,如果我们在map的中间输出指定了压缩,那么reduce拉取会数据之后,会根据指定的压缩机制对压缩的数据进行解压缩。
压缩机制确实可以提升我们MR程序的运行效率,但是也是有成本的,压缩因为使用专门的算法,算法越复杂,压缩的时候程序的CPU的负载越大。
压缩适用于IO密集的MR程序,计算密集的MR程序不适用
4.1.1 常用的压缩算法的适用场景
-
gzip
- 压缩的文件无法被MapReduce切片
- 压缩效率和压缩速度都相对而言比较快,如果一个文件压缩之后在128兆左右的话可以适用这个压缩机制
-
bzip2
- 压缩的文件支持切片的
- 压缩效率很高,但是压缩速度非常慢,如果我们MR程序对时间要求不高,但是数据量非常庞大的情况下
-
lzo
-
压缩的文件支持切片,但是如果要支持切片是非常复杂的,MR程序支持适用lzo算法,但是MR程序没有自带这个算法
-
压缩效率不高,胜在速度非常快
-
使用比较麻烦的,因为Hadoop没有自带这个算法,使用的话得需要下载插件,引入依赖…
-
-
snappy
- 压缩文件不支持切片
- 压缩速度非常快,是所有压缩算法中最快的了,压缩的效率比gzip低
4.1.2 MapReduce程序可以压缩数据的位置
- Map的输入采用一些支持切片的压缩机制:bzip2、lzogzip和snappy也可以用,只不过最好保证数据压缩之后在128兆左右
- map的输出snappy机制
- reduce的输出最好也是支持切片的压缩机制
4.1.3 在MapReduce中开启压缩机制
在MR中使用压缩机制,不需要我们去进行手动的压缩和解压缩,只需要在MR的合适的位置指定我们使用的是何种压缩机制,MR程序会自动的调用设置的压缩和解压缩算法进行自动化操作。
-
mapper的输入开启压缩
只需要在Configuration或者core-site.xml文件增加如下一行配置即可:
配置名:io.compression.codecs 配置值:org.apache.hadoop.io.compress.DefaultCodec, org.apache.hadoop.io.compress.GzipCodec, org.apache.hadoop.io.compress.BZip2Codec,org.apache.hadoop.io.compress.Lz4Codec,org.apache.hadoop.io.compress.SnappyCodec 只需要把上述配置配置好,MR程序在处理输入文件时,如果输入文件是上述配置的压缩的后缀 -
mapper的输出可以开启压缩
mapreduce.map.output.compress true/false mapreduce.map.output.compress.codec org.apache.hadoop.io.compress.GzipCodec -
reduce的输出可以开启压缩
FileOutputFormat.setCompressOutput(job,true);//是否开启输出压缩 FileOutputFormat.setOutputCompressorClass(job, GzipCodec.class);//reduce输出压缩使用的压缩机制.
可以使用如下命令检查Hadoop集群目前本身不需要安装插件就支持的压缩算法
hadoop checknative
五、Hadoop的第三大组成–YARN框架
YARN是一个分布式资源调度系统,专门用来给分布式计算程序提供计算资源的,而且YARN只负责进行资源的提供,不管计算程序的逻辑,因此YARN这个软件非常的成功,因为YARN不关注程序计算逻辑,因此只要是分布式计算程序,只要满足YARN的运行要求,那么就可以在YARN上进行运行,由YARN进行资源调度。spark、flink等等分布式计算程序都可以在YARN上运行。
5.1 YARN的基本架构组成
YARN之所以提供分布式计算资源,主要原因就是因为YARN的设计架构
5.1.1 ResourceManager:YARN集群的管理者
1、负责进行资源的配置
2、负责整个集群的状态
3、接受客户端或者applicationmaster的资源申请
5.1.2 NodeManager
1、负责接受RM给NM分配的task任务(就是资源的打包任务)
2、负责启动Container容器(打包的计算程序所需的运行资源)
5.1.1~5.1.2:YARN启动之后就会有的进程
5.1.3 Container
封装了一组计算资源的容器,包含了计算程序所需的资源,资源的具体的配额都是客户端或者ApplicationMaster去向RM申请
5.1.4 ApplicationMaster
任何一个分布式计算程序如果想在YARN上运行,分布式计算程序必须能启动一个ApplicationMaster进程,比如MR程序在YARN上运行就会启动MRAppcationMaster。这个进程不是由YARN自带的,而是分布式计算程序想在YARN上运行,分布式计算程序必须得有这么一个进程。
YARN的工作核心,YARN之所以不知道分布式计算程序的计算逻辑,还能给分布式计算程序提供资源,全凭借ApplicationMaster的存在,ApplicationMaster是分布式程序运行的核心,监控分布式计算程序有没有运行成功、负责向RM申请分布式程序运行的资源。
5.1.3~5.1.4:当有分布式计算程序在YARN上运行的时候,才会出现这两个进程
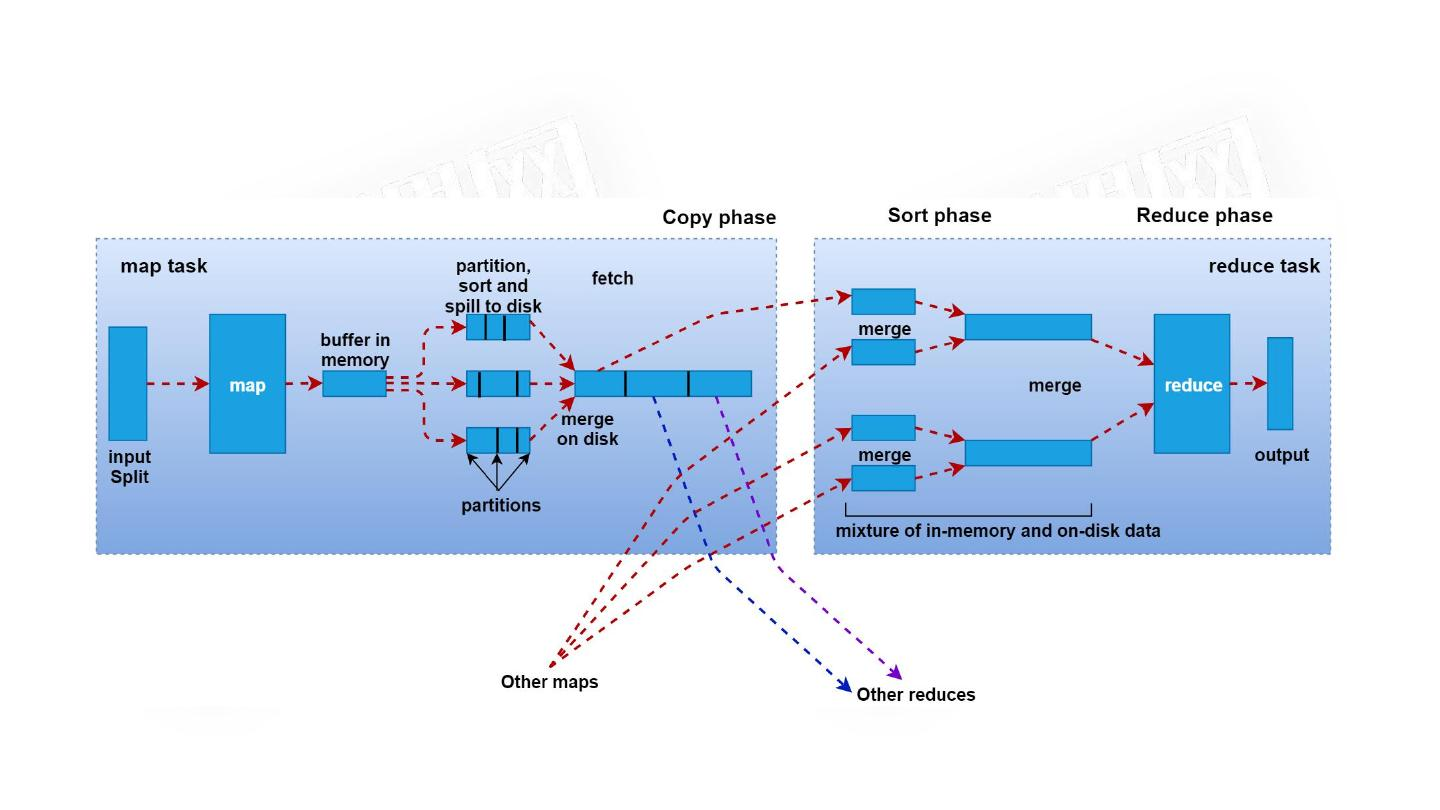
5.2 YARN的详细工作流程–运行MapReduce
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Ye5VNQhS-1690280574965)(./7.25/9a563b4f928b184013a5ed9db62ea27b8079d59039a6596d7fed9a7b01bfbdab.png)]](https://img-blog.csdnimg.cn/2d3b9d2f2a0e4ca69c603067516f0803.png)
六、YARN的资源调度器问题
YARN在进行资源分配的时候,RM需要先将client或者AM申请的资源初始化成为一个task任务,资源的task任务不是直接下发给NM,而是先把task任务给加入到一个RM的调度器当中,由调度器在合适的时机下发任务给NM。
6.1 YARN中一共三种的资源调度器
6.1.1 FIFIO资源调度器
是一种队列调度器,每一个任务加入到调度器中,按照时间的先后依次排列,给NM下发任务的时候,是先来的先分配,后来等待集群资源充足继续分配。 只有一个队列,队列使用的集群中所有的资源
特点: 如果有些任务比较重要,必须排队,只有得到队列中你排到了最前面了才会给你分配
Hadoop1.x版本YARN默认的调度器机制
6.1.2 容量调度器
也是一个队列调度器,但是多个队列并行进行分配,每一个队列具备YARN集群中的部分资源。在同一个时刻,可以下发多个任务
Hadoop2.x和hadoop3.x默认调度器
6.1.3 公平调度器
也是可以具备多个队列,每个队列具备集群中的部分资源,不一样的地方在于每一个队列中的任务不等待,每一个任务都会启动,均匀的享有集群的资源。
6.1.4 修改:yarn-site.xml
yarn.resourcemanager.scheduler.class
org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler
6.2 默认使用的容量调度器,容量调度器可以有多个队列,每一个队列占用集群的部分资源,默认情况下容量调度只有一个队列default,队列占有集群的所有资源,如果配置容量调度器的第二个队列:capacity-scheduler.xml
<property> <name>yarn.scheduler.capacity.root.queues</name> <value>default,queueA</value> <description> The queues at the this level (root is the root queue). </description>
</property>
容量调度器有几个队列
<!-- default 队列占用的资源容量百分比 40% -->
<property> <name>yarn.scheduler.capacity.root.default.capacity</name> <value>40</value> </property> <!-- default 队列占用的最大资源容量百分比 60%-->
<property> <name>yarn.scheduler.capacity.root.default.maximum-capacity</name> <value>60</value>
</property>
如果要配置多个队列,保证多个队列的capacity加起来是100,每一个队列的最大占用容量要大于等于配置队列容量
七、YARN的web网站问题
YARN提供一个web网站,yarn,通过这个web网站,可以查看YARN集群的资源信息和队列信息,以及可以查看YARN上运行的分布式计算程序的状态以及运行的日志输出
7.1 存在问题
- YARN记录的分布式运行程序,只是本次开启有效,如果YARN关闭重启了,那么以前在YARN上运行的日志全部消失了
- YARN记录的分布式运行程序,在网站上看不到详细的日志信息,因此后期维护或者查看MR运行信息就很麻烦了
7.2 解决上述问题的方案
- 第一步:配置MapReduce的历史服务器JobHistory,可以帮助YARN记忆以前开启的时候运行的MR程序 历史服务器的配置主要在mapred-site.xml文件中配置,主要配置两项
<property> <name>mapreduce.jobhistory.address</name> <value>single:10020</value> </property> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>single:19888</value>
</property>
如果使用历史服务器,必须启动历史服务器,如果不启动,历史服务器不会记录YARN上运行的分布式计算程序 mr-jobhistory-daemon.sh start historyserver
- 第二步:配置YARN聚合MapReduce运行日志信息–可以在YARN的web界面查看MR的详细日志 配置yarn-site.xml文件
<!-- 日志聚集功能启动 -->
<property> <name>yarn.log-aggregation-enable</name> <value>true</value> </property>
<!-- 日志保留时间设置7天 -->
<property> <name>yarn.log-aggregation.retain-seconds</name> <value>604800</value>
</property>
<property> <name>yarn.log.server.url</name> <value>http://single:19888/jobhistory/logs</value>
</property>
代码示例
package com.sxuek.wordcount;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.*;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.SQLException;public class WCDriver {public static void main(String[] args) throws IOException, URISyntaxException, InterruptedException, ClassNotFoundException {//1、准备一个配置文件对象Configuration configuration = new Configuration();configuration.set("fs.defaultFS","hdfs://192.168.68.101:9000");//2、创建一个封装MR程序使用Job对象Job job = Job.getInstance(configuration);job.setJarByClass(WCDriver.class);//指定输入文件路径 输入路径默认是本地的,如果你想要是HDFS上的 那么必须配置fs.defaultFS 指定HDFS的路径FileInputFormat.setInputPaths(job,new Path("/wordcount.txt"));/*** 4、封装Mapper阶段*/job.setMapperClass(WCMapper.class);job.setMapOutputKeyClass(Text.class);job.setMapOutputValueClass(LongWritable.class);/*** 6、封装Reducer阶段*/job.setReducerClass(WCReducer.class);job.setOutputKeyClass(Text.class);job.setOutputValueClass(LongWritable.class);job.setNumReduceTasks(1);/*** 7、封装指定的OutputFormat,如果没有指定OutputFormat 默认使用TextOutputFormat*/Path path = new Path("/output");FileSystem fs = FileSystem.get(new URI("hdfs://192.168.68.101:9000"), configuration, "root");if (fs.exists(path)){fs.delete(path,true);}job.setOutputFormatClass(WCOutputFormat.class);FileOutputFormat.setOutputPath(job,path);/*** 8、提交程序运行* 提交的时候先进行切片规划,然后将配置和代码提交给资源调度器*/boolean b = job.waitForCompletion(true);System.exit(b?0:1);}
}class WCMapper extends Mapper<LongWritable, Text,Text,LongWritable>{@Overrideprotected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, LongWritable>.Context context) throws IOException, InterruptedException {String line = value.toString();String[] words = line.split(" ");for (String word : words) {context.write(new Text(word),new LongWritable(1L));}}
}class WCReducer extends Reducer<Text,LongWritable,Text,LongWritable>{@Overrideprotected void reduce(Text key, Iterable<LongWritable> values, Reducer<Text, LongWritable, Text, LongWritable>.Context context) throws IOException, InterruptedException {long sum =0l;for (LongWritable value : values) {sum += value.get();}context.write(key,new LongWritable(sum));}
}class WCOutputFormat extends FileOutputFormat<Text,LongWritable>{@Overridepublic RecordWriter<Text, LongWritable> getRecordWriter(TaskAttemptContext job) throws IOException, InterruptedException {return new WCRecordWriter();}
}class WCRecordWriter extends RecordWriter<Text,LongWritable>{private Connection connection;private PreparedStatement preparedStatement;public WCRecordWriter(){/*** 在无参构造器中先连接上MySQL*/try {Class.forName("com.mysql.cj.jdbc.Driver");connection = DriverManager.getConnection("jdbc:mysql://localhost:3306/mr?serverTimezone=UTC&useUnicode=true&characterEncoding=UTF-8","root","root");String sql = "insert into wordcount(word,count) values(?,?)";preparedStatement = connection.prepareStatement(sql);} catch (ClassNotFoundException e) {throw new RuntimeException(e);} catch (SQLException e) {throw new RuntimeException(e);}}@Overridepublic void write(Text key, LongWritable value) throws IOException, InterruptedException {String word = key.toString();Long count = value.get();try {preparedStatement.setString(1,word);preparedStatement.setInt(2,count.intValue());preparedStatement.executeUpdate();} catch (SQLException e) {throw new RuntimeException(e);}}@Overridepublic void close(TaskAttemptContext context) throws IOException, InterruptedException {if (preparedStatement != null){try {preparedStatement.close();} catch (SQLException e) {throw new RuntimeException(e);}}if (connection != null){try {connection.close();} catch (SQLException e) {throw new RuntimeException(e);}}}
}
package com.sxuek.compress;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.compress.CompressionOutputStream;
import org.apache.hadoop.io.compress.DefaultCodec;
import org.apache.hadoop.util.ReflectionUtils;import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;/*** 压缩和解压缩其实就是使用IO流的形式对数据读取和写出* Hadoop的default压缩算法的使用* 165s* 96%*/
public class Demo01 {public static void main(String[] args) throws IOException {DefaultCodec defaultCodec = ReflectionUtils.newInstance(DefaultCodec.class, new Configuration());FileOutputStream fos = new FileOutputStream("f://CentOS-7-x86_64-DVD-1708.iso"+defaultCodec.getDefaultExtension());CompressionOutputStream outputStream = defaultCodec.createOutputStream(fos);FileInputStream fis = new FileInputStream("f://CentOS-7-x86_64-DVD-1708.iso");long time = System.currentTimeMillis();IOUtils.copyBytes(fis,outputStream,1*1024*1024);long time1 = System.currentTimeMillis();System.out.println(time1-time);}
}package com.sxuek.compress;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.compress.CompressionOutputStream;
import org.apache.hadoop.io.compress.DefaultCodec;
import org.apache.hadoop.io.compress.GzipCodec;
import org.apache.hadoop.util.ReflectionUtils;import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;/*** gzip* 179s* 96%*/
public class Demo02 {public static void main(String[] args) throws IOException {GzipCodec gzipCodec = ReflectionUtils.newInstance(GzipCodec.class, new Configuration());FileOutputStream fos = new FileOutputStream("f://CentOS-7-x86_64-DVD-1708.iso"+gzipCodec.getDefaultExtension());CompressionOutputStream outputStream = gzipCodec.createOutputStream(fos);FileInputStream fis = new FileInputStream("f://CentOS-7-x86_64-DVD-1708.iso");long time = System.currentTimeMillis();IOUtils.copyBytes(fis,outputStream,1*1024*1024);long time1 = System.currentTimeMillis();System.out.println(time1-time);}
}package com.sxuek.compress;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.compress.BZip2Codec;
import org.apache.hadoop.io.compress.CompressionOutputStream;
import org.apache.hadoop.io.compress.GzipCodec;
import org.apache.hadoop.util.ReflectionUtils;import java.io.FileInputStream;
import java.io.FileOutputStream;/*** bzip*/
public class Demo03 {public static void main(String[] args) throws Exception {BZip2Codec bZip2Codec = ReflectionUtils.newInstance(BZip2Codec.class, new Configuration());FileOutputStream fos = new FileOutputStream("f://CentOS-7-x86_64-DVD-1708.iso"+bZip2Codec.getDefaultExtension());CompressionOutputStream outputStream = bZip2Codec.createOutputStream(fos);FileInputStream fis = new FileInputStream("f://CentOS-7-x86_64-DVD-1708.iso");long time = System.currentTimeMillis();IOUtils.copyBytes(fis,outputStream,1*1024*1024);long time1 = System.currentTimeMillis();System.out.println(time1-time);}
}package com.sxuek.compress;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.compress.BZip2Codec;
import org.apache.hadoop.io.compress.CompressionOutputStream;
import org.apache.hadoop.io.compress.SnappyCodec;
import org.apache.hadoop.util.ReflectionUtils;import java.io.FileInputStream;
import java.io.FileOutputStream;/*** snappy*/
public class Demo04 {public static void main(String[] args) throws Exception{SnappyCodec snappyCodec = ReflectionUtils.newInstance(SnappyCodec.class, new Configuration());FileOutputStream fos = new FileOutputStream("f://CentOS-7-x86_64-DVD-1708.iso"+snappyCodec.getDefaultExtension());CompressionOutputStream outputStream = snappyCodec.createOutputStream(fos);FileInputStream fis = new FileInputStream("f://CentOS-7-x86_64-DVD-1708.iso");long time = System.currentTimeMillis();IOUtils.copyBytes(fis,outputStream,1*1024*1024);long time1 = System.currentTimeMillis();System.out.println(time1-time);}
}相关文章:
实训笔记7.25
实训笔记7.25 7.25笔记一、MapReduce的特殊使用场景1.1 通过MapReduce程序实现多文件Join操作1.1.1 通过在Reduce端实现join操作1.1.2 通过在Map端实现join操作 1.2 MapReduce中的计数器的使用1.2.1 计数器使用两种方式 1.3 MapReduce实现数据清洗 二、MapReduce的OutputFormat…...
全方位对比 Postgres 和 MongoDB (2023 版)
本文为「数据库全方位对比系列」第二篇,该系列的首部作品为「全方位对比 Postgres 和 MySQL (2023 版)」 为何对比 Postgres 和 MongoDB 根据 2023 年 Stack Overflow 调研,Postgres 已经成为最受欢迎和渴望的数据库了。 MongoDB 曾连续 4 年 (2017 - …...

本地部署中文LLaMA模型实战教程,民间羊驼模型
羊驼实战系列索引 博文1:本地部署中文LLaMA模型实战教程,民间羊驼模型(本博客) 博文2:本地训练中文LLaMA模型实战教程,民间羊驼模型 博文3:精调训练中文LLaMA模型实战教程,民间羊驼模型 简介 LLaMA大部分是英文语料训练的,讲中文能力很弱。如果我们想微调训练自己的…...
全志F1C200S嵌入式驱动开发(spi-nor image制作)
【 声明:版权所有,欢迎转载,请勿用于商业用途。 联系信箱:feixiaoxing @163.com】 一般soc系统里面添加spi-nor flash芯片,特别是对linux soc来说,都是把它当成文件系统来使用的。spi-nor flash和spi-nand flash相比,虽然空间小了点,但是胜在稳定,这是很多工业…...

JSON格式Python,Java,PHP等封装图片识别商品数据API方法
淘宝是一个网上购物平台,售卖各类商品,包括服装、鞋类、家居用品、美妆产品、电子产品等。要获取淘宝天猫图片识别商品数据,您可以通过开放平台的接口或者直接访问淘宝天猫商城的网页来获取图片识别商品数据。以下是两种常用方法的介绍&#…...

Vue应用案例
项目一:记事本 <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8" /><title>title</title></head> <body><div id"app"><h2 >记事本</h2><input …...

GPT-3.5:ChatGPT的奇妙之处和革命性进步
🌷🍁 博主 libin9iOak带您 Go to New World.✨🍁 🦄 个人主页——libin9iOak的博客🎐 🐳 《面试题大全》 文章图文并茂🦕生动形象🦖简单易学!欢迎大家来踩踩~ἳ…...
【Hadoop 01】简介
目录 1 Hadoop 简介 2 下载并配置Hadoop 2.1 修改/etc/profile 2.2 修改hadoop-env.sh 2.3 修改core-site.xml 2.4 修改hdfs-site.xml 2.5 修改mapred-site.xml 2.6 修改yarn-site.xml 2.7 修改workers 2.8 修改start-dfs.sh、stop-dfs.sh 2.9 修改start-yarn.sh、s…...

【C++】开源:跨平台轻量日志库easyloggingpp
😏★,:.☆( ̄▽ ̄)/$:.★ 😏 这篇文章主要介绍跨平台轻量日志库easyloggingpp。 无专精则不能成,无涉猎则不能通。。——梁启超 欢迎来到我的博客,一起学习,共同进步。 喜欢的朋友可以关注一下&am…...
spring-websocket在SpringBoot(包含SpringSecurity)项目中的导入
✅作者简介:大家好,我是 Meteors., 向往着更加简洁高效的代码写法与编程方式,持续分享Java技术内容。 🍎个人主页:Meteors.的博客 🥭本文内容:spring-websocket在SpringBoot(包含SpringSecurity…...
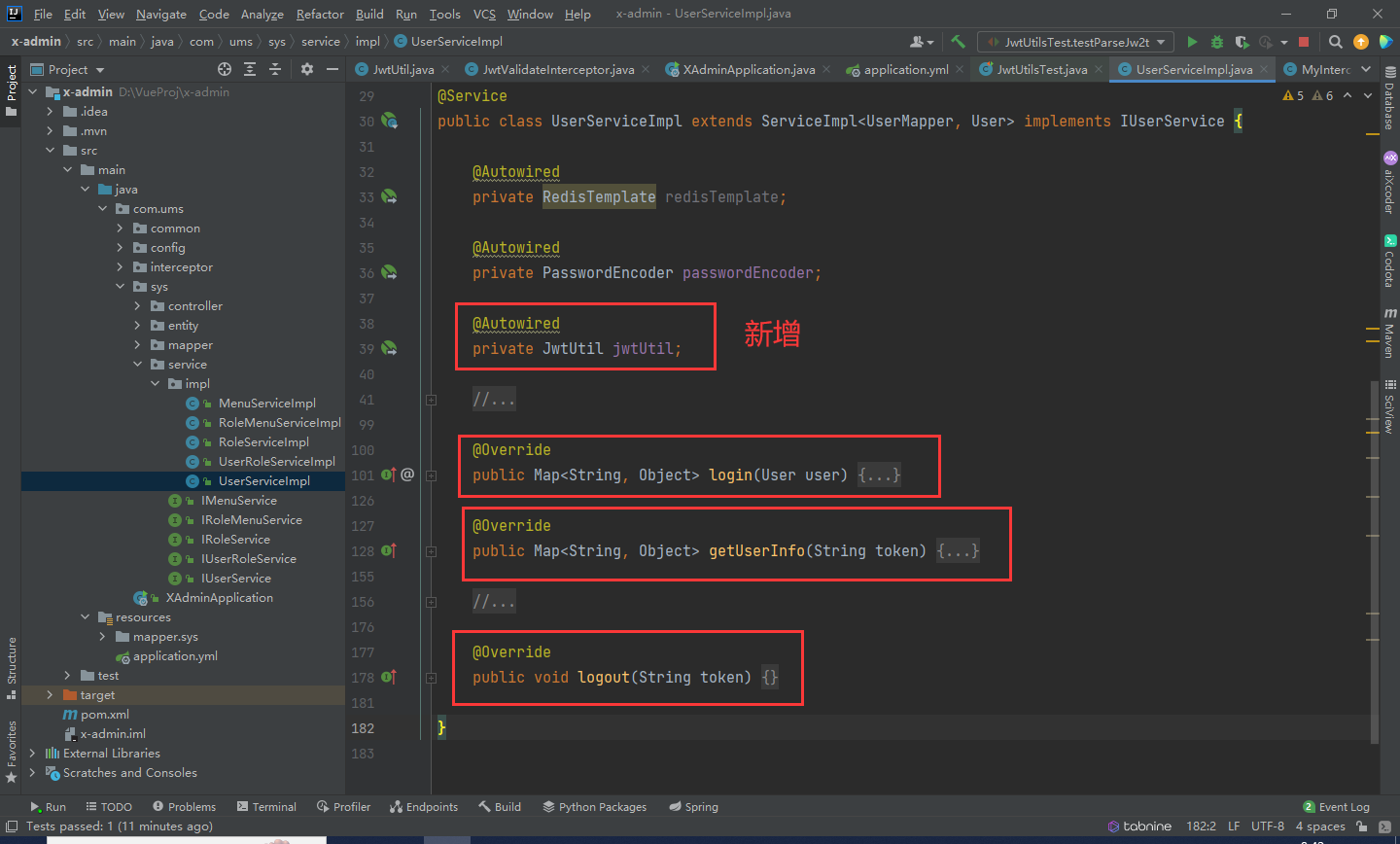
SpringBoot + Vue前后端分离项目实战 || 六:Jwt加密整合配置
文章目录 回顾添加依赖Jwt依赖Jwt配置定义Jwt拦截器注册Jwt拦截器,配置需要验证token的URL 测试Jwt修改登录等逻辑 回顾 在之前的系统中,我们利用UUID配合Redis以达到角色登录的功能。 当前整个系统存在一个问题:人为修改token值后…...

WPF 如何设置全局的订阅发布事件
文章目录 前言代码逻辑修改 总结 前言 我们需要一个全局事件订阅发布功能,实现页面通讯。使两个毫无关系的页面通过一个中间量进行通讯。 代码 IEventAggregator:消息订阅集合 这个是Prism提供的消息订阅功能。使用如下 设置订阅类型,即…...

STM32 USB使用记录:HID类设备(前篇)
文章目录 目的基础说明HID类演示代码分析总结 目的 USB是目前最流行的接口,现在很多个人用的电子设备也都是USB设备。目前大多数单片机都有USB接口,使用USB接口作为HID类设备来使用是非常常用的,比如USB鼠标、键盘都是这一类。这篇文章将简单…...
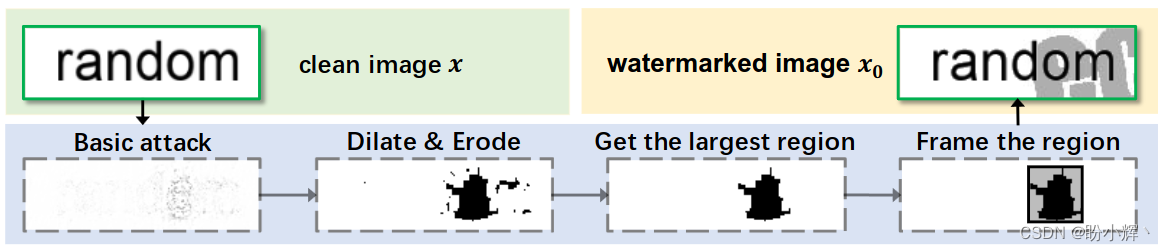
探索AI图像安全,助力可信AI发展
探索AI图像安全,助力可信AI发展 0. 前言1. 人工智能发展与安全挑战1.1 人工智能及其发展1.2 人工智能安全挑战 2. WAIC 2023 多模态基础大模型的可信 AI2.1 WAIC 2023 专题论坛2.2 走进合合信息 3. AI 图像安全3.1 图像篡改检测3.2 生成式图像鉴别3.3 OCR 对抗攻击技…...

vue 学习笔记 【ElementPlus】el-menu 折叠后图标不见了
项目当前版本 {"dependencies": {"element-plus/icons-vue": "^2.1.0","types/js-cookie": "^3.0.3","types/nprogress": "^0.2.0","axios": "^1.4.0","core-js": &quo…...
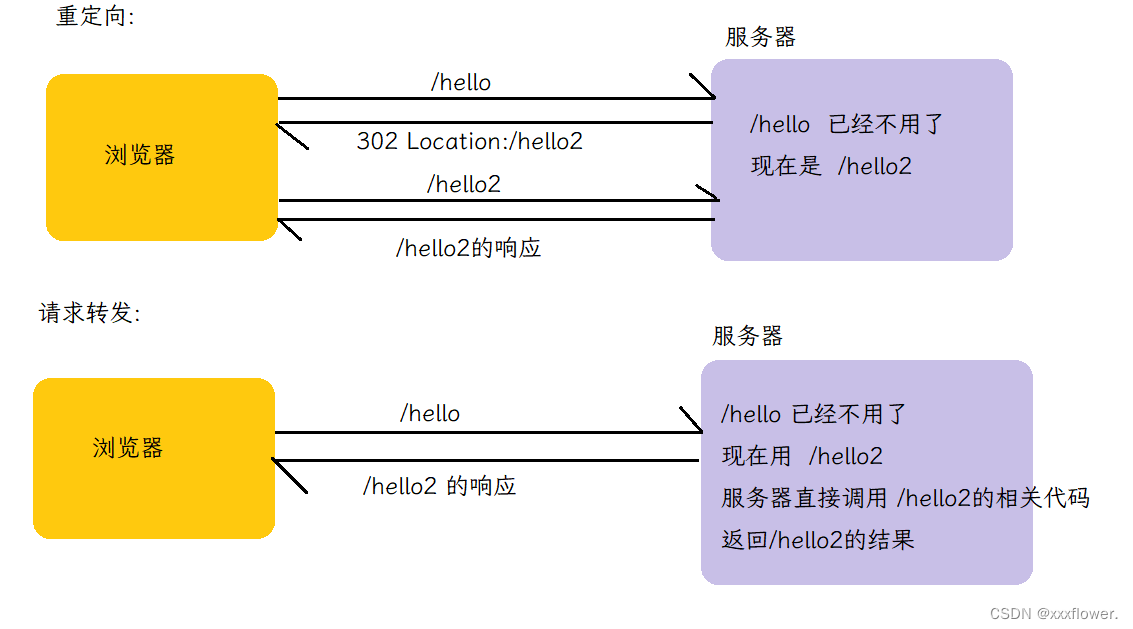
【JavaEE初阶】HTTP协议
文章目录 1. HTTP概述和fiddler的使用1.1 HTTP是什么1.2 抓包工具fiddler的使用1.2.1 注意事项1.2.2 fiddler的使用 2. HTTP协议格式2.1 HTTP请求格式2.1.1 基本格式2.1.2 认识URL2.1.3 方法 2.2 请求报头关键字段2.3 HTTP响应格式2.3.1 基本格式2.3.2状态码 1. HTTP概述和fidd…...
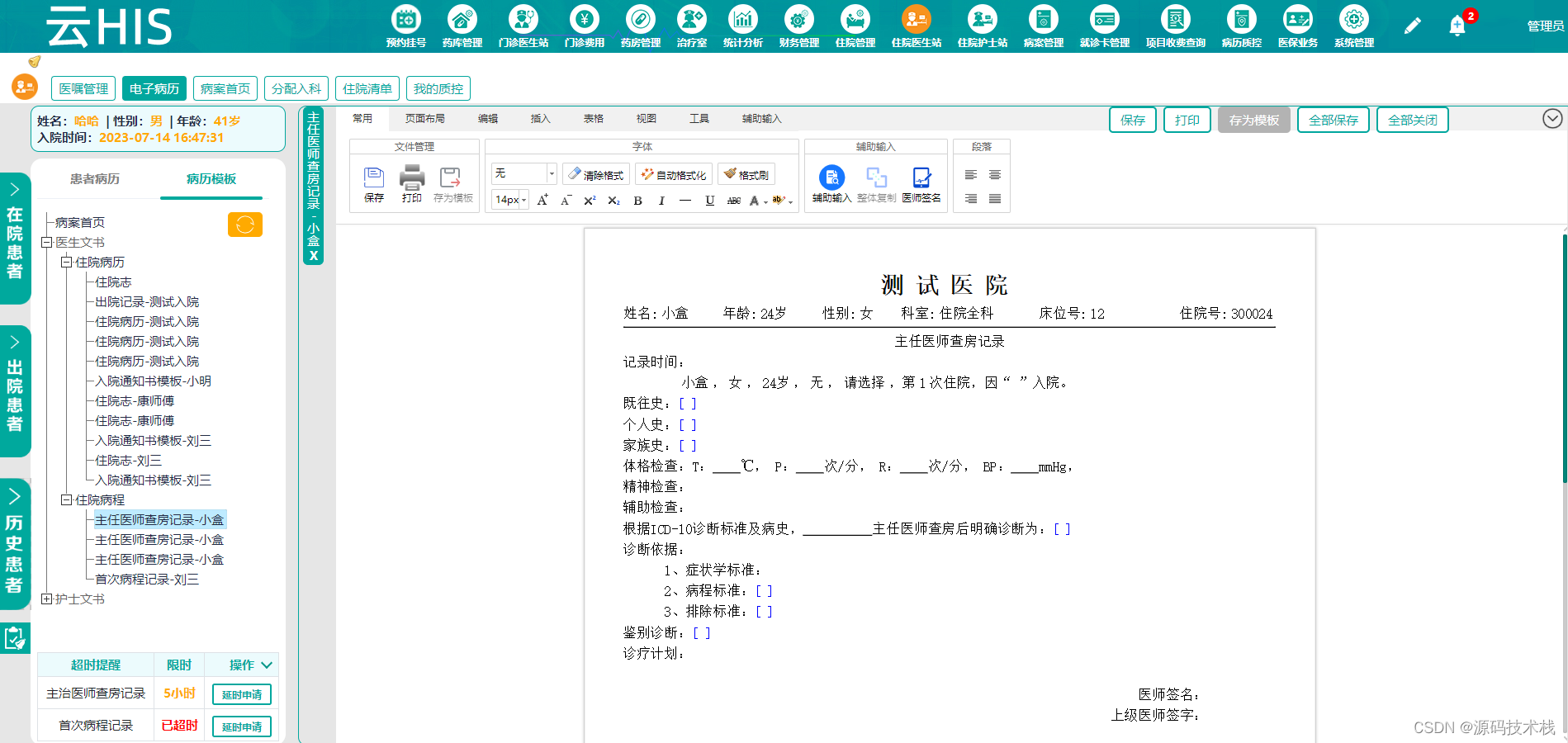
基于SaaS模式的Java基层卫生健康云HIS系统源码【运维管理+运营管理+综合监管】
云HIS综合管理平台 一、模板管理 模板分为两种:病历模板和报表模板。模板管理是运营管理的核心组成部分,是基层卫生健康云中各医疗机构定制电子病历和报表的地方,各医疗机构可根据自身特点特色定制电子病历和报表,制作的电子病历…...

effective c++ 条款2
条款2 常量(const)替换宏(#define)指针常量类成员常量 枚举(enum)替换宏(#define)模板函数(template inline)替换宏函数 尽量用const,enum,inline替换#define 总结就是: 常量(const)替换宏(#define) // uppercase names are usually for macros #define ASPECT_R…...

Python爬虫之Scrapy框架系列(23)——分布式爬虫scrapy_redis浅实战【XXTop250部分爬取】
目录: 1.实战讲解(XXTop250完整信息的爬取):1.1 使用之前做的完整的XXTOP250项目,但是设置为只爬取一页(共25个电影),便于观察1.2 配置settings文件中使用scrapy_redis的必要配置,并…...

html基于onmouse事件让元素变颜色
最近,在书写div块时,遇到一个小问题,这个小问题我搞了将近一个小时多才慢慢解决。问题是这样子的,有一个div块,我想让鼠标移上去变成蓝色,移开变成灰色,当鼠标按下去时让他变成深蓝色。于是就单…...

E-Hentai-Downloader:高效漫画资源本地化解决方案
E-Hentai-Downloader:高效漫画资源本地化解决方案 【免费下载链接】E-Hentai-Downloader Download E-Hentai archive as zip file 项目地址: https://gitcode.com/gh_mirrors/eh/E-Hentai-Downloader 核心价值:重新定义漫画资源管理 E-Hentai-Do…...

Windows风扇智能调速实战指南:从噪音难题到散热优化
Windows风扇智能调速实战指南:从噪音难题到散热优化 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Trending/fa/F…...

破局MIDI控制困境:SendMIDI让命令行成为音乐创作的神经中枢
破局MIDI控制困境:SendMIDI让命令行成为音乐创作的神经中枢 【免费下载链接】SendMIDI Multi-platform command-line tool to send out MIDI messages 项目地址: https://gitcode.com/gh_mirrors/se/SendMIDI 在数字音乐制作的世界里,MIDI&#x…...

【开题答辩全过程】以 个性化电影推荐系统为例,包含答辩的问题和答案
个人简介一名14年经验的资深毕设内行人,语言擅长Java、php、微信小程序、Python、Golang、安卓Android等开发项目包括大数据、深度学习、网站、小程序、安卓、算法。平常会做一些项目定制化开发、代码讲解、答辩教学、文档编写、也懂一些降重方面的技巧。感谢大家的…...

从零搭建:4阶段实现wvp-GB28181-pro视频监控平台的容器化部署
从零搭建:4阶段实现wvp-GB28181-pro视频监控平台的容器化部署 【免费下载链接】wvp-GB28181-pro 项目地址: https://gitcode.com/GitHub_Trending/wv/wvp-GB28181-pro 在当今安防监控领域,GB28181协议作为国家标准被广泛应用于视频监控系统中。w…...

Qwen3-VL-WEBUI效果实测:对比其他模型,看看优势在哪里
Qwen3-VL-WEBUI效果实测:对比其他模型,看看优势在哪里 1. 引言:当AI不仅能“看”,还能“做” 想象一下,你给AI看一张软件界面的截图,它不仅能告诉你界面上有什么,还能一步步指导你如何操作&am…...
)
保姆级教程:用STM32CubeMX配置TIM1的PA8和PA11输出PWM波(STM32F103C8T6)
STM32CubeMX实战:从零配置TIM1的PA8/PA11输出PWM驱动电机 当你第一次拿到STM32F103C8T6这块蓝色的小板子时,可能会被密密麻麻的引脚吓到——但别担心,今天我们要用STM32CubeMX这个神器,像搭积木一样轻松配置出精准的PWM波形。我清…...

零基础玩转OpenClaw:Qwen3-32B镜像快速入门5个示例
零基础玩转OpenClaw:Qwen3-32B镜像快速入门5个示例 1. 为什么选择OpenClawQwen3-32B组合? 去年冬天,当我第一次看到同事用自然语言命令电脑自动整理桌面文件时,仿佛打开了新世界的大门。经过两周的折腾,我终于在本地…...

C# .NET 周刊|2026年3月1期
国内文章.NET 11 预览版1:CoreCLR 在 WebAssembly 上的全面集成与性能突破https://www.cnblogs.com/shanyou/p/19629649.NET 11 Preview 1 正式发布,标志着 CoreCLR 运行时能原生支持 WebAssembly。这是微软在跨平台战略上的重大进展。CoreCLR 提供更优性…...

FastAdmin二次开发指南:如何基于这套开源CMS源码定制你的专属内容模型?
FastAdmin二次开发实战:从零构建自定义内容模型 在开源CMS领域,FastAdmin以其基于ThinkPHP的优雅架构和丰富的功能模块,成为众多开发者快速构建后台管理系统的首选。但真正体现其价值的,往往是在面对个性化业务需求时的二次开发能…...