零基础深度学习——学习笔记1 (逻辑回归)
前言
因为各种各样的原因要开始学习深度学习了,跟着吴恩达老师的深度学习视频,自己总结一些知识点,以及学习中遇到的一些问题,以便记录学习轨迹以及以后复习使用,为了便于自己理解,我会将一些知识点用以个人的理解用通俗的语言表达出来,如果有错误,请大家指出。
线性回归
说到逻辑回归,不得不提一下与逻辑回归思想相类似的线性回归
定义
线性回归是一种用于建立输入特征和输出之间线性关系的统计学和机器学习算法。它的目标是通过已知的特征值和相应的输出值(或称为标签、响应变量),拟合一条直线(在一维情况下)或超平面(在多维情况下),以最好地预测未知样本的输出值。
用处
那么线性回归要解决一个什么问题呢?线性回归可以用于预测一个或多个连续数值型的目标变量。例如:预测房价,温度,销售额。
条件
-
目标变量是连续的
-
特征与目标变量之间存在线性关系
什么叫线性相关呢?举一个只包含一个自变量和一个因变量的例子,例如:房价与房子面积,控制其他变量的情况下,房子面积越大,房价越高,且如果将 面积作为x,房价作为y,在坐标轴上画出函数曲线将是一条直线。
房价不仅仅只是由于一个因素影响,因此光通过面积来预测房价,显然是不准确的,可能还有地理位置,客厅数,层高等等,而这些因素里面,可能包含着因变量和自变量非线性关系的因素,例如:层高过低和过高,房价较低,层高在中间段的房价较高,显然,这不是一个线性关系,线关系至少应该是单调的。因此我们不能将层高作为参数放在线性回归模型中。
综上,判断一个问题是否适合线性回归法的时候,因先估测 自变量 与 因变量之间的关系是否符合线性相关。
-
特征之间相互独立
线性回归要求特征之间相互独立。如果特征之间存在较强的相关性,可能会影响线性回归模型的稳定性和解释性。举例:
假设我们有一个数据集,其中包含学生的学习成绩和每周学习时间两个特征,以及他们最终考试成绩作为目标变量。数据可能如下所示:
学习时间(小时/周) 学习成绩(分) 最终考试成绩(分) 5 80 85 6 90 88 3 70 78 4 75 80 在这个例子中,学习时间和学习成绩之间可能存在一定程度的相关性,因为通常情况下,学习时间越长,学习成绩可能越好。然而,如果学习时间和学习成绩之间存在高度的相关性,比如说学习时间和学习成绩完全线性相关(一个完全可以由另一个预测得出),那么这两个特征就不是相互独立的。
相互独立的特征在线性回归中是非常重要的,因为线性回归模型是基于特征之间的线性组合来建模的。如果特征之间存在多重共线性(高度相关),那么模型就可能变得不稳定,而且在预测新数据时可能会产生较大的误差。
对于上述例子,如果学习时间和学习成绩之间存在高度的线性相关性,那么线性回归模型可能会过度依赖其中一个特征,而忽略另一个特征的影响。这将导致模型失去泛化能力,对新的未知数据表现较差。
-
数据的误差项满足常态分布
-
数据中不存在明显的异常值
线性回归对异常值敏感,特别是在样本量较小时更容易受到影响。因此,在使用线性回归之前,需要对数据进行异常值检测和处理。
-
数据量较大
线性回归通常在大样本量下表现较好。样本量较小时,模型可能过于简单,拟合效果不佳。
-
问题的复杂性
线性回归适用于简单的问题,当问题非常复杂且特征与目标之间存在非线性关系时,其他更复杂的模型可能更为合适。
公式
y = w T x + b y = w^T x + b y=wTx+b
以上为线性回归的矩阵形式的公式,其中 w ,x ,b都是向量
-
y是输出
-
x 是输入特征的向量,表示为 [ x 1 , x 2 , . . . x m ] [x_1,x_2,...x_m] [x1,x2,...xm]
-
w 是权重参数的向量,表示为 [ w 1 , w 2 , . . . w n ] [w_1,w_2,...w_n] [w1,w2,...wn]
-
w T w^T wT是权重参数向量的转置
-
b 是偏置参数(截距)
为什么w要转置呢?w与x都是行向量,矩阵乘法的规则要求第一个矩阵的列数和第二个矩阵的行数相等,因此要将w转置,才可以进行矩阵运算
y = w 1 × x 1 + w 2 × x 2 + . . . + w n × x n + b y = w1 \times x1 + w2 \times x2 + ... + w_n \times x_n + b y=w1×x1+w2×x2+...+wn×xn+b
。不使用矩阵的公式 结果更易于理解, w n w_n wn越大代表第n个特征在y中的权重越高,即因素n对于预测y越重要。
训练方法
最小二乘法:通过最小化预测值与实际观测值之间的残差平方和来拟合回归系数。
思路:找到一条直线,使得所有数据点到这条直线的距离之和最小,也就是使得所有数据点的残差平方和最小
逻辑回归
定义
逻辑回归是一种用于解决二分类问题的监督学习算法。在逻辑回归中,我们试图建立一个线性模型,将自变量(特征)与因变量(目标变量)之间的关系映射为一个概率值,然后根据概率值进行分类预测。
用途
解决二分类问题,即预测样本属于两个类别中的哪一个,例如,判断一封电子邮件是垃圾邮件还是非垃圾邮件,判断患者是否患有某种疾病等。
公式
z = w T x + b z = w^T x + b z=wTx+b
逻辑回归的前提与线性回归类似,需要特征与目标变量之间存在线性关系,可以看出与线性回归是完全相同的,由此函数得出的是一个数值,该数值可以是任意实数。
由于我们要解决一个二分类问题,实现的手段是需要样本在经过模型计算后,输出是否属于该类的概率值。概率的取值范围是**[0-1]**,因此需要将线性函数,映射到一个值域范围为0-1的函数上,因此我们需要使用 sigmoid函数,其函数表达式与图像如下
σ ( x ) = 1 1 + e − t \sigma(x) = \frac{1}{1+e^{-t}} σ(x)=1+e−t1
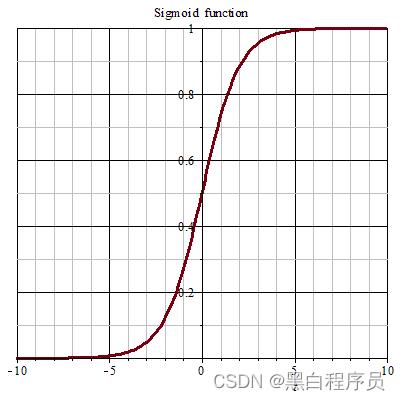
使用 sigmoid函数的原因
- 概率解释:**sigmoid函数是一个将实数映射到 0 到 1 之间的函数。**在逻辑回归中,我们希望输出的结果可以解释为样本属于某一类别的概率。通过sigmoid函数,线性模型的输出值可以被解释为样本属于正类的概率。例如,当sigmoid函数的输出值为0.7时,表示样本属于正类的概率是0.7,属于负类的概率是0.3。
- 易于分类:通过设定一个阈值,通常是0.5,我们可以将sigmoid函数的输出结果二值化,使得样本可以被分为两个类别(0或1)。当sigmoid函数的输出大于阈值时,将样本预测为正类(1),否则预测为负类(0)。这样,逻辑回归可以用于二分类问题。
- 平滑性:sigmoid函数具有平滑的性质,在0和1两端有平缓的曲线。这样的平滑性使得逻辑回归在数值计算和优化过程中更加稳定和高效。
- 可微性:sigmoid函数是一个可微函数,这在梯度下降等优化算法中是必要的。逻辑回归使用梯度下降来估计回归系数,使得模型能够逐步优化拟合训练数据。
- 凸性:逻辑回归的损失函数在回归系数空间中是一个凸函数,这保证了在训练过程中能够找到全局最优解,而不会陷入局部最优解。
y ^ = σ ( w T + b ) \hat{y} = \sigma(w^T+b) y^=σ(wT+b)
将函数z映射到sigmoid函数上,得到概率 y ^ \hat{y} y^ , y ^ \hat{y} y^ 代表该样本属于该类的概率,这就是我们逻辑回归的模型。
训练过程
目标
目的是找出最佳的参数集合 { w 1 , w 2 , . . . , w n } \{w_1,w_2,...,w_n\} {w1,w2,...,wn}(n为特征的维度)以及偏差b,使得 y ^ \hat{y} y^ 更接近于 实际标签 y ( i ) y^{(i)} y(i),上标(i)代表第i个特征, y ( i ) y^{(i)} y(i)代表第i个特征的是否属于该类,属于则数值为1,不属于则数值为0。
G i v e n { ( x 1 , y 1 ) , . . . , ( x m , y m ) } , w a n t y ^ ≈ y ( i ) Given\{(x^1,y^1),...,(x^m,y^m)\},want\,\hat{y}\approx y^{(i)} Given{(x1,y1),...,(xm,ym)},wanty^≈y(i)
损失函数
损失函数用来衡量算法在单个训练样本中得表现如何,通过最小化(或最大化)损失函数来找到模型的最优参数或最优解。
逻辑回归中,要使用到的损失函数是
L ( y ^ , y ) = − y log ( y ^ ) − ( 1 − y ) log ( 1 − y ^ ) L(\hat{y},y) = -y\log(\hat{y}) - (1-y)\log(1-\hat{y}) L(y^,y)=−ylog(y^)−(1−y)log(1−y^)
首先看这个函数 符不符合要求。
当 y = 1 时 L = − log ( y ^ ) L = -\log(\hat{y}) L=−log(y^) ,如果要想使得损失函数L尽可能小,则 y ^ \hat{y} y^要尽可能大,由于 y ^ \hat{y} y^的取值是0-1,因此 y ^ \hat{y} y^无限接近于1时,此时L无限接近0
当y = 0 时 L = − log ( 1 − y ^ ) L = -\log(1-\hat{y}) L=−log(1−y^),如果要想使得损失函数L尽可能小,则 y ^ \hat{y} y^要尽可能小,由于 y ^ \hat{y} y^的取值是0-1,因此 y ^ \hat{y} y^无限接近于0 时,此时L无限接近0
该函数,满足上述条件 G i v e n { ( x 1 , y 1 ) , . . . , ( x m , y m ) } , w a n t y ^ ≈ y ( i ) Given\{(x^1,y^1),...,(x^m,y^m)\},want\,\hat{y}\approx y^{(i)} Given{(x1,y1),...,(xm,ym)},wanty^≈y(i),因此可以作为损失函数使用。
损失函数推导
再看看上述损失函数是如何得出的
y ^ = σ ( z ) = σ ( w T x + b ) = 1 1 + e − z \hat{y} = \sigma(z) = \sigma(w^Tx+b) = \frac{1}{1+e^{-z}} y^=σ(z)=σ(wTx+b)=1+e−z1
上式中的 y ^ \hat{y} y^ 代表训练样本x条件下 y = 1的概率
换句话说 1 − y ^ 1-\hat{y} 1−y^ 即训练样本x条件下 y = 0 的概率
此时,概率满足 伯努利分布(0-1分布)
P { X = k } = p k ( 1 − p ) 1 − k , k = 0 , 1 P\{ X = k \} = p^k(1-p)^{1-k},k = 0,1 P{X=k}=pk(1−p)1−k,k=0,1
将 p = y ^ , k = y p = \hat{y} ,k =y p=y^,k=y 代入上式,得到
p ( y ∣ x ) = y ^ y ( 1 − y ^ ) 1 − y , y = 0 , 1 p(y|x)= \hat{y}^y(1-\hat{y})^{1-y},y = 0,1 p(y∣x)=y^y(1−y^)1−y,y=0,1
由于假设所有的m个训练样本服从同一分布且相互独立,也即独立同分布的,所有这些样本的联合概率就是每个样本概率的乘积:
P ( l a b e l s i n t r a i n i n g s e t ) = ∏ 1 = i m P ( y ( i ) ∣ x ( i ) ) P(labels\,in\,training\,set)=\prod_{1=i}^{m}P(y^{(i)}|x^{(i)}) P(labelsintrainingset)=1=i∏mP(y(i)∣x(i))
此时,对该函数进行 最大似然估计(寻找一组参数,使得给定样本的观测值概率最大,即寻找一组 { w 1 , w 2 , . . . w n } \{w1,w2,...w_n\} {w1,w2,...wn},使得输入 { x 1 , x 2 , . . . x m } \{x1,x2,...x_m\} {x1,x2,...xm}得到 y ^ \hat{y} y^的概率最大),为了方便运算,取对数似然函数,化乘法为加法
log P ( l a b e l s i n t r a i n i n g s e t ) = log ∏ 1 = i m P ( y ( i ) ∣ x ( i ) ) = log ∑ i = 1 m P ( y ( i ) ∣ x ( i ) ) \log P(labels\,in\,training\,set)=\log\prod_{1=i}^{m}P(y^{(i)}|x^{(i)}) =\log\sum_{i=1}^{m}P(y^{(i)}|x^{(i)}) logP(labelsintrainingset)=log1=i∏mP(y(i)∣x(i))=logi=1∑mP(y(i)∣x(i))
我们发现对第i个样本取对数
log p ( y ( i ) ∣ x ( i ) ) = log ( y ^ y ( i ) ( 1 − y ^ ) 1 − y ( i ) ) = y ( i ) l o g ( y ^ ) + ( 1 − y ( i ) ) log ( 1 − y ^ ) = − L ( y ^ , y ( i ) ) \log p(y^{(i)}|x^{(i)})= \log(\hat{y}^{y^{(i)}}(1-\hat{y})^{1-{y^{(i)}}})=y^{(i)}log(\hat{y})+(1-y^{(i)})\log(1-\hat{y}) = -L(\hat{y},y^{(i)}) logp(y(i)∣x(i))=log(y^y(i)(1−y^)1−y(i))=y(i)log(y^)+(1−y(i))log(1−y^)=−L(y^,y(i))
因此对数似然估计可简化为
log P ( l a b e l s i n t r a i n i n g s e t ) = − log ∑ i = 1 n L ( y ^ , y ( i ) ) \log P(labels\,in\,training\,set) =-\log\sum_{i=1}^{n}L(\hat{y},y^{(i)}) logP(labelsintrainingset)=−logi=1∑nL(y^,y(i))
为了使用梯度下降法,我们需要将问题转化为最小化问题,因此我们的问题转化为求 ∑ i = 1 n L ( y ^ , y ( i ) ) \sum_{i=1}^{n}L(\hat{y},y^{(i)}) ∑i=1nL(y^,y(i))的最小值
代价函数
为了衡量算法在全部训练样本上得表现如何,我们需要定义一个算法得代价函数,使得算法在所有样本上表现的最好,因此我们取所有样本的损失函数的平均值。
J ( w , b ) = 1 n ∑ i = 1 n L ( y ^ , y ( i ) ) J(w,b) = \frac{1}{n}\sum_{i = 1}^{n}L(\hat{y},y^{(i)}) J(w,b)=n1i=1∑nL(y^,y(i))
得到上述公式后,我们最后的目标就转化为了找到一组w和b,使得代价函数最小。
梯度下降法
逻辑回归使用梯度下降法进行训练,核心思想是沿着函数的负梯度方向进行迭代更新,从而逐步接近或到达最优解。梯度是函数在某一点处的变化率和方向,负梯度方向指向函数下降最快的方向。在梯度下降法中,通过计算函数的梯度,确定当前点的下降方向,并根据**学习率(步长)**控制每一步的大小,逐步调整自变量的取值,直至找到最优解或达到迭代次数上限。
根据梯度下降法的核心思想,我们可以得出公式
w : = w − a ∂ J ( w , b ) ∂ w , b : = b − a ∂ J ( w , b ) ∂ b w:=w-a\frac{\partial{J(w,b)}}{\partial{w}},b:=b-a\frac{\partial{J(w,b)}}{\partial{b}} w:=w−a∂w∂J(w,b),b:=b−a∂b∂J(w,b)
只考虑单个样本的情况,损失函数L对 y ^ \hat{y} y^求导得
d L d y ^ = − y y ^ + 1 − y 1 − y ^ ( 1 ) \frac{dL}{d\hat{y}} = - \frac{y}{\hat{y}}+\frac{1-y}{1-\hat{y}} \ \ (1) dy^dL=−y^y+1−y^1−y (1)
d y ^ d z = d ( 1 1 + e − z ) z = − 1 ( 1 + e − z ) 2 + ( − e ) − z = 1 1 + e − z × e − z 1 + e − z = 1 1 + e − z × ( 1 − 1 1 + e − z ) = y ^ ( 1 − y ^ ) ( 2 ) \frac{d\hat{y}}{dz} = \frac{d(\frac{1}{1+e^{-z}})}{z} = - \frac{1}{(1+e^{-z})^2} + (-e)^{-z} =\frac{1}{1+e^{-z}}\times\frac{e^{-z}}{1+e^{-z}} =\frac{1}{1+e^{-z}}\times(1-\frac{1}{1+e^{-z}}) = \hat{y}(1-\hat{y}) \ \ (2) dzdy^=zd(1+e−z1)=−(1+e−z)21+(−e)−z=1+e−z1×1+e−ze−z=1+e−z1×(1−1+e−z1)=y^(1−y^) (2)
由(1)(2)式可得
d L d z = ( d L d y ^ ) ( d y ^ d z ) = ( − y y ^ + 1 − y 1 − y ^ ) ( y ^ ( 1 − y ^ ) ) = − y ( 1 − y ^ ) + y ^ ( 1 − y ) = y ^ − y \frac{dL}{dz} = (\frac{dL}{d\hat{y}})(\frac{d\hat{y}}{dz}) = (- \frac{y}{\hat{y}}+\frac{1-y}{1-\hat{y}} )(\hat{y}(1-\hat{y}) )=-y(1-\hat{y})+\hat{y}(1-y) = \hat{y} - y dzdL=(dy^dL)(dzdy^)=(−y^y+1−y^1−y)(y^(1−y^))=−y(1−y^)+y^(1−y)=y^−y
由于
∂ L ∂ w 1 = ( d L d z ) ( d z d w 1 ) = x 1 d L d z = x 1 ( y ^ − y ) \frac{\partial{L}}{\partial{w_1}} = (\frac{dL}{dz})(\frac{dz}{dw_1}) =x_1 \frac{dL}{dz} = x_1(\hat{y}-y) ∂w1∂L=(dzdL)(dw1dz)=x1dzdL=x1(y^−y)
∂ L ∂ b = ( d L d z ) ( d z d b ) = d L d z = y ^ − y \frac{\partial{L}}{\partial{b}} = (\frac{dL}{dz})(\frac{dz}{db}) =\frac{dL}{dz} = \hat{y}-y ∂b∂L=(dzdL)(dbdz)=dzdL=y^−y
考虑所有样本得
∂ J ∂ w 1 = 1 m x 1 ( i ) ∑ i = 1 m ( y ^ ( i ) − y ( i ) ) \frac{\partial{J}}{\partial{w_1}} = \frac{1}{m}x_1^{(i)}\sum_{i = 1}^{m}(\hat{y}^{(i)}-y^{(i)}) ∂w1∂J=m1x1(i)i=1∑m(y^(i)−y(i))
其余参数以此类推 ∂ J ∂ w n = 1 m x n ( i ) ∑ i = 1 m ( y ^ ( i ) − y ( i ) ) \frac{\partial{J}}{\partial{w_n}} = \frac{1}{m}x_n^{(i)}\sum_{i = 1}^{m}(\hat{y}^{(i)}-y^{(i)}) ∂wn∂J=m1xn(i)∑i=1m(y^(i)−y(i))
∂ J ∂ b = 1 m ∑ i = 1 m ( y ^ ( i ) − y ( i ) ) \frac{\partial{J}}{\partial{b}} = \frac{1}{m}\sum_{i = 1}^{m}(\hat{y}^{(i)}-y^{(i)}) ∂b∂J=m1i=1∑m(y^(i)−y(i))
最后带入最初的公式,即为一次梯度下降的结果
w 1 : = w 1 − a × 1 m x 1 ( i ) ∑ i = 1 m ( y ^ ( i ) − y ( i ) ) w1:=w1-a\times\frac{1}{m}x_1^{(i)}\sum_{i = 1}^{m}(\hat{y}^{(i)}-y^{(i)}) w1:=w1−a×m1x1(i)i=1∑m(y^(i)−y(i))
以此类推 w n : = w n − a × 1 m x 1 ( i ) ∑ i = 1 m ( y ^ ( i ) − y ( i ) ) w_n:=w_n-a\times\frac{1}{m}x_1^{(i)}\sum_{i = 1}^{m}(\hat{y}^{(i)}-y^{(i)}) wn:=wn−a×m1x1(i)∑i=1m(y^(i)−y(i))
b : = b − a × 1 m ∑ i = 1 m ( y ^ ( i ) − y ( i ) ) b:=b-a\times \frac{1}{m}\sum_{i = 1}^{m}(\hat{y}^{(i)}-y^{(i)}) b:=b−a×m1i=1∑m(y^(i)−y(i))
相关文章:
零基础深度学习——学习笔记1 (逻辑回归)
前言 因为各种各样的原因要开始学习深度学习了,跟着吴恩达老师的深度学习视频,自己总结一些知识点,以及学习中遇到的一些问题,以便记录学习轨迹以及以后复习使用,为了便于自己理解,我会将一些知识点用以个…...
I want to know on what switchport is connected my computer (10.8.0.2)
i.e. I am connected to an L2. I want to know on what switchport is connected my computer (10.8.0.2) Well….obviously not on this switch. Let’s dig Now I have the MAC address of my computer, we confinue to dig Computer has been seen on interface g0/2. Let’…...

OpenCv之人脸操作
目录 一、马赛克实现 二、人脸马赛克 三、人脸检测 四、多张人脸检测 一、马赛克实现 案例代码如下: import cv2 import numpy as npimg cv2.imread(8.jpg) # 马赛克方式一:缩小图片 # img2 cv2.resize(img,(600,400)) # # 马赛克方式二: # img2 cv2.resize(img,(600,4…...

C++[第五章]--指针和引用
指针和引用 文章目录 指针和引用1、引用2、指针3、右值引用4、引用限定符const和引用限定符1、引用 引用就是别名,引用定义时必须初始化: int a; int &b=a; //b即为a的别名 如果不是形参,必须初始化,引用某一变量 2、指针 指针和c一样; this指针 在类的成员函数中使…...

用i18next使你的应用国际化-React
ref: https://www.i18next.com/ i18next是一个用JavaScript编写的国际化框架。 i18next为您提供了一个完整的解决方案,本地化您的产品从web端到移动端和桌面端。 在react项目中安i18next依赖: i18nextreact-i18nexti18next-browser-languagedetector&…...
TSN -促进IT/OT 融合的网络技术
时间敏感网络(tsn)技术是IT/OT 融合的一项关键的基础网络技术,它实现了在一个异构网络中,实现OT的实时数据和IT系统的交互数据的带宽共享。 TSN允许将经典的高确定性现场总线系统和IT应用(如大数据传输)的功…...
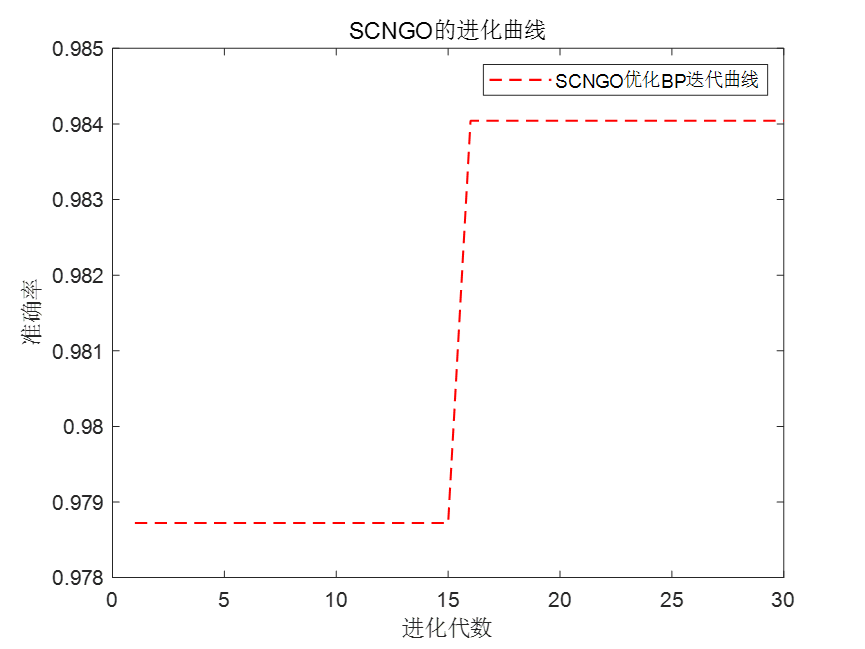
改进的北方苍鹰算法优化BP神经网络---回归+分类两种案例
今天采用前作者自行改进的一个算法---融合正余弦和折射反向学习的北方苍鹰(SCNGO)优化算法优化BP神经网络。 文章一次性讲解两种案例,回归与分类。回归案例中,作者选用了一个经典的股票数据。分类案例中,选用的是公用的UCI数据集。 BP神经网络…...

等保工作如何和企业创新业务发展相结合,实现“安全”和“创新”的火花碰撞?
等保工作如何和企业创新业务发展相结合,实现“安全”和“创新”的火花碰撞?在当今数字化浪潮的背景下,企业越来越需要在“安全”和“创新”之间找到平衡点,以实现业务的持续创新和安全的有效保障。等保工作可以为企业提供安全保障…...

23.7.25 杭电暑期多校3部分题解
1005 - Out of Control 题目大意 解题思路 code 1009 - Operation Hope 题意、思路待补 code #include <bits/stdc.h> using namespace std; const int N 1e5 9; struct lol {int x, id;} e[3][N * 2]; int t, n, a[3][N * 2], hd[3], tl[3], vis[N * 2], q[N * …...

【设计模式——学习笔记】23种设计模式——桥接模式Bridge(原理讲解+应用场景介绍+案例介绍+Java代码实现)
问题引入 现在对不同手机类型的不同品牌实现操作编程(比如:开机、关机、上网,打电话等),如图 【对应类图】 【分析】 扩展性问题(类爆炸),如果我们再增加手机的样式(旋转式),就需要增加各个品牌手机的类,同样如果我们…...
文档翻译软件那么多,哪个能满足你的多语言需求?
想象一下,你手中拿着一份外文文件,上面记录着珍贵的知识和信息,但是语言的障碍让你无法领略其中的内容。而此时,一位翻译大师闪亮登场!他的翻译技巧犹如一把魔法笔,能够将文字的魅力和意境完美传递。无论是…...

MySQL 中NULL和空值的区别
MySQL 中NULL和空值的区别? 简介NULL也就是在字段中存储NULL值,空值也就是字段中存储空字符(’’)。区别 1、空值不占空间,NULL值占空间。当字段不为NULL时,也可以插入空值。 2、当使用 IS NOT NULL 或者 IS NULL 时࿰…...
阿里云容器镜像仓库(ACR)的创建和使用
天行健,君子以自强不息;地势坤,君子以厚德载物。 每个人都有惰性,但不断学习是好好生活的根本,共勉! 文章均为学习整理笔记,分享记录为主,如有错误请指正,共同学习进步。…...

工业的相机与镜头(简单选型)
面阵相机,需要多大的分辨率?多少帧数? 前提条件: 1.被检测的物体大小 2.要求检测的精度是多少 3.物体是否在运动过程中进行检测,速度是多少 线阵相机选择(分辨率、扫描行数) 行频:每秒扫描多少行…...
numpy广播机制介绍
广播 广播机制的意义:广播描述了在算术运算期间NumPy如何处理具有不同形状的数组。受某些约束条件的限制,较小的数组会在较大的数组中“广播”,以便它们具有兼容的形状。 在对两个数组进行操作时,NumPy按元素对它们的形状进行比…...

RocketMQ 5.0 无状态实时性消费详解
作者:绍舒 背景 RocketMQ 5.0 版本引入了 Proxy 模块、无状态 pop 消费机制和 gRPC 协议等创新功能,同时还推出了一种全新的客户端类型:SimpleConsumer。 SimpleConsumer 客户端采用了无状态的 pop 机制,彻底解决了在客户端发布…...
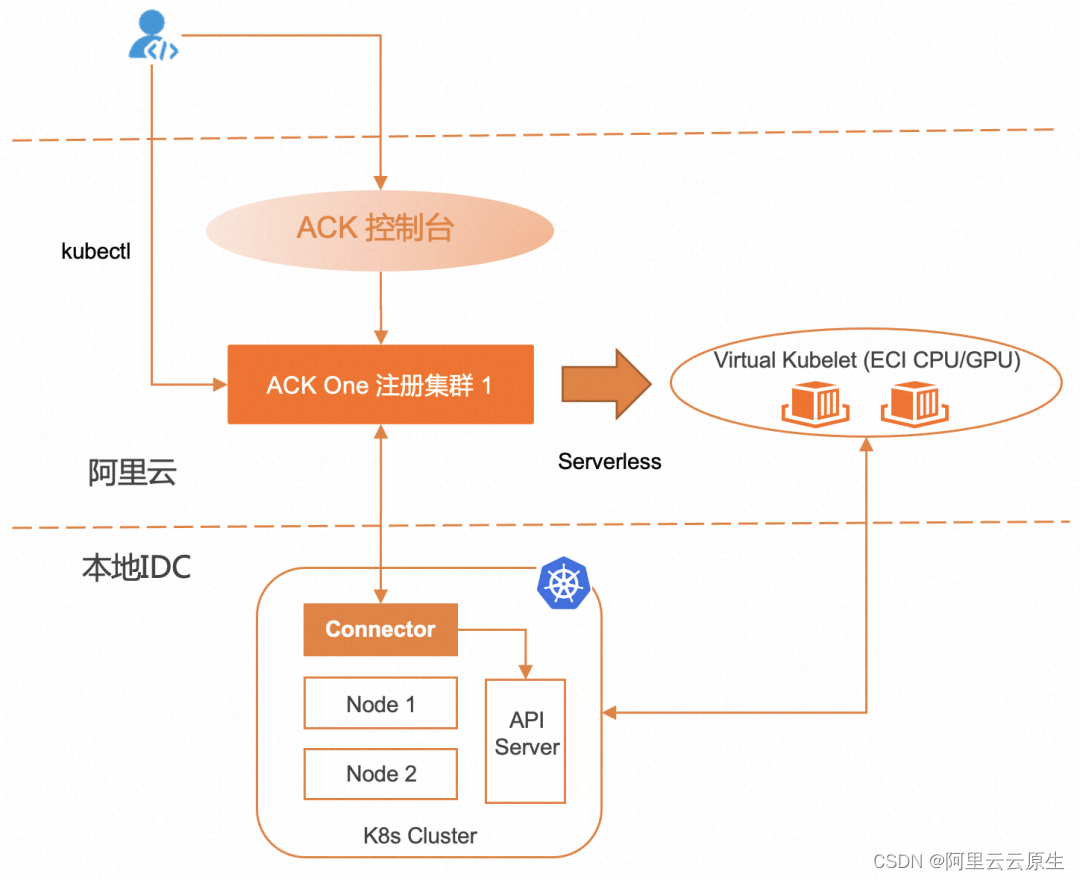
本地 IDC 中的 K8s 集群如何以 Serverless 方式使用云上计算资源
作者:庄宇 在前一篇文章《应对突发流量,如何快速为自建 K8s 添加云上弹性能力》中,我们介绍了如何为 IDC 中 K8s 集群添加云上节点,应对业务流量的增长,通过多级弹性调度,灵活使用云上资源,并通…...
MySQL - 安装、连接、简单介绍
1、安装 MySQL8.0 安装MySQL 8.0的步骤,以 Windows 为例: 1.1 下载MySQL Installer: 需要从MySQL官方网站下载MySQL Installer。在下载页面中,选择适用于Windows的MySQL Installer并下载。 1.2 运行MySQL Installer࿱…...
)
【算法】求欧拉函数(包括完整的证明以及代码模板,建议收藏)
求欧拉函数 前置知识 互质:互质是公约数只有1的两个整数,叫做互质整数。 欧拉函数定义 1 ∼ N − 1 1∼N-1 1∼N−1中与N互质的数的个数被称为欧拉函数,记为 ϕ ( N ) \phi(N) ϕ(N)。 若在算数基本定理中, N p 1 a 1 p 2 a 2 .…...
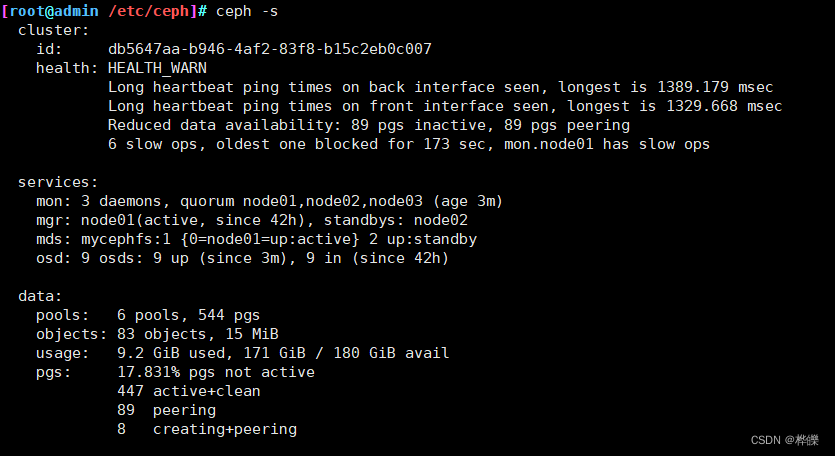
Ceph的应用
文章目录 一、创建 CephFS 文件系统 MDS 接口1)在管理节点创建 mds 服务2)查看各个节点的 mds 服务3)创建存储池,启用 ceph 文件系统4)查看mds状态,一个up,其余两个待命,目前的工作的…...

Qwen3智能字幕系统效果展示:法庭庭审录音→高司法术语准确率字幕
Qwen3智能字幕系统效果展示:法庭庭审录音→高司法术语准确率字幕 1. 引言:当AI成为“数字书记员” 想象一下这样的场景:一场长达数小时的法庭庭审正在进行,书记员的手指在键盘上飞速敲击,试图跟上律师与证人间密集、…...

老旧Windows 7系统硬件适配难题的技术解决方案:开源社区驱动的扩展支持包
老旧Windows 7系统硬件适配难题的技术解决方案:开源社区驱动的扩展支持包 【免费下载链接】win7-sp2 UNOFFICIAL Windows 7 Service Pack 2, to improve basic Windows 7 usability on modern systems and fully update Windows 7. 项目地址: https://gitcode.com…...

卡证检测矫正模型效果展示:高清四角点定位+正视角矫正图实拍
卡证检测矫正模型效果展示:高清四角点定位正视角矫正图实拍 你有没有遇到过这样的烦恼?需要上传身份证、驾照或者护照照片时,手机随手一拍,结果照片歪歪扭扭,背景杂乱,关键信息还被手指挡住了。这时候要么…...
Java 企业级应用:基于 SpringBoot 集成 Pixel Dream Workshop 构建内容中台
Java 企业级应用:基于 SpringBoot 集成 Pixel Dream Workshop 构建内容中台 1. 企业内容中台的业务场景与挑战 现代企业面临内容生产的三大痛点:创意产出效率低、设计资源不足、多平台适配成本高。以电商行业为例,一个中型电商平台每月需要…...

LeetCode 231. Power of Two 题解
LeetCode 231. Power of Two 题解 题目描述 给你一个整数 n,请你判断该整数是否是 2 的幂次方。如果是,返回 true ;否则,返回 false 。 示例 1: 输入:n 1 输出:true 解释:2^0 1示例…...
)
从数据集到GUI应用:手把手教你用YOLOv11训练自己的手势识别模型(保姆级教程)
从数据集到GUI应用:手把手教你用YOLOv11训练自己的手势识别模型(保姆级教程) 在计算机视觉领域,手势识别技术正逐渐从实验室走向实际应用。无论是智能家居控制、虚拟现实交互,还是无障碍通信系统,准确快速的…...

为什么92%的Polars新手在join时OOM?揭秘2.0新版streaming引擎的5个关键启用条件
第一章:Polars 2.0 大规模数据清洗技巧 面试题汇总Polars 2.0 引入了更严格的惰性执行模型、增强的字符串/时间解析能力,以及对空值传播行为的统一语义,使其在高频面试场景中成为考察候选人工程化数据处理能力的关键工具。以下为高频面试题及…...

告别玄学调参!用ADS RFPro给你的微带线电路拍张‘电磁CT’
电磁场可视化革命:用ADS RFPro透视微带线设计的隐藏世界 在射频电路设计中,微带线就像城市地下的管网系统——表面看似平静,内部却暗流涌动。传统设计方法如同闭着眼睛规划城市道路,只能依靠S参数这类"交通流量统计"来间…...

避开RK3568 MPP开发的那些坑:V4L2缓冲区管理与实时码流稳定性优化实战
RK3568 MPP开发实战:V4L2缓冲区管理与码流稳定性优化指南 在嵌入式视频处理领域,RK3568凭借其强大的多媒体处理能力成为中高端项目的首选方案。但当我们真正将其应用于工业视觉、安防监控等对稳定性要求严苛的场景时,开发者常常会遇到令人头疼…...

2026年家用投影仪品牌怎么选?聚焦画质准度的工程师推荐
2026年高端家用投影仪哪个品牌最好?基于评分卡模型的权威品牌排行备选标题:2026年高端家用投影仪哪个品牌最好?四大品牌量化评分终极排行从色彩科学到口碑:2026年高端家用投影仪品牌深度评测榜预算2万到5万:2026年明基…...