机器学习/深度学习常见算法实现(秋招版)
包括BN层、卷积层、池化层、交叉熵、随机梯度下降法、非极大抑制、k均值聚类等秋招常见的代码实现。
1. BN层
import numpy as npdef batch_norm(outputs, gamma, beta, epsilon=1e-6, momentum=0.9, running_mean=0, running_var=1):''':param outputs: [B, L]:param gamma: mean:param beta::param epsilon::return:'''mean = np.mean(outputs, axis=(0, 2, 3), keepdims=True) # 1, C, H, Wvar = np.var(outputs, axis=(0,2,3), keepdims=True) # 1, C, H, W# mean = np.mean(outputs, axis=0)# var = np.var(outputs, axis=0)# 滑动平均用于记录mean和var,用于测试running_mean = momentum * running_mean + (1-momentum) * meanrunning_var = momentum * running_var + (1-momentum) * varres = gamma * ( outputs - mean ) / np.sqrt(var + epsilon) + betareturn res, running_mean, running_varif __name__ == '__main__':outputs = np.random.random((16, 64, 8, 8))tmp, _, _ = batch_norm(outputs, 1, 1, 1e-6)# print(tmp.shape)mean = np.mean(tmp[:, 1, :, :])std = np.sqrt(np.var(tmp[:, 1, :, :]))print(mean, std)
2. 卷积层
import numpy as npdef conv_forward_naive(x, w, b, conv_param):''':param x: [N, C_in, H, W]:param w: [C_out, C_in, k1, k2]:param b: [C_out]:param conv_param:- 'stride':- 'pad': the number of pixels that will be used to zero-pad the input:return:- 'out': (N, C_out, H', W')- 'cache': (x, w, b, conv_param)'''out = NoneN, C_in, H, W = x.shapeC_out, _, k1, k2 = w.shapestride, padding = conv_param['stride'], conv_param['pad']H_out = (H-k1+2*padding) // stride + 1W_out = (W-k2+2*padding) // stride + 1out = np.zeros((N, C_out, H_out, W_out))x_pad = np.zeros((N, C_in, H+2*padding, W+2*padding))x_pad[:, :, padding:padding+H, padding:padding+W] = xfor i in range(H_out):for j in range(W_out):x_pad_mask = x_pad[:, :, i*stride:i*stride+k1, j*stride:j*stride+k2]for c in range(C_out):out[:, c, i, j] = np.sum(x_pad_mask*w[c, :, :, :], axis=(1,2,3))out += b[None, :, None, None]cache = (x, w, b, conv_param)return out, cache
3. maxpooling
import numpy as npdef maxpooling_forward(feature, kernel, stride):''':param feature: [N, C, H, W]:param kernel: [k1, k2]:param stride: [s1, s2]:return:'''N, C, H, W = feature.shapek1, k2 = kernels1, s2 = strideH_out = (H - k1) // s1 + 1W_out = (W - k2) // s2 + 1out = np.zeros((N, C, H_out, W_out))for i in range(H_out):for j in range(W_out):feature_mask = feature[:, :, i*s1:i*s1+k1, j*s2:j*s2+k2]out[:, :, i, j] = np.max(feature_mask, axis=(2,3)) # 注意这里的2,3!!!return out
4. cross Entropy
import numpy as npdef cross_entropy(label, outputs, reduce=True):''':param label: B x 1:param outputs: B x c:return: loss'''loss_list = []for i in range(len(label)):y = label[i]output = outputs[i]sum_exp = np.sum([np.exp(k) for k in output])prop = np.exp(output[y]) / sum_exploss_list.append(-np.log(prop))if reduce:return np.mean(loss_list)else:return np.sum(loss_list)def softmax(t):return np.exp(t) / np.sum(np.exp(t), axis=1, keepdims=True)def softmax2(t):return np.exp(t) / np.sum(np.exp(t), axis=1, keepdims=True)def cross_entropy_2(y, y_, onehot=True, reduce=True):y = softmax(y)if not onehot:cates = y.shapey_ = np.eye(cates[-1])[y_]if reduce:return np.mean(-np.sum(y_ * np.log(y), axis=1))else:return np.sum(-np.sum(y_ * np.log(y), axis=1))if __name__ == '__main__':outputs = [[0.5, 0.5], [0, 1], [1, 0]]label = [0, 0, 1]print(cross_entropy(label, outputs, True))print(cross_entropy_2(outputs, label, False))
5. sgd
import numpy as np
import random
class MYSGD:def __init__(self, training_data, epochs, batch_size, lr, model):self.training_data = training_dataself.epochs = epochsself.batch_size = batch_sizeself.lr = lrself.weight = [...]self.bias = [...]def run(self):n = len(self.training_data)for j in range(self.epochs):random.shuffle(self.training_data)mini_batches = [self.training_data[k*self.batch_size: (k+1)*self.batch_size]for k in range(n//self.batch_size)]for mini_batch in mini_batches:self.updata(mini_batch)def update(self, mini_batch):nabla_b = [np.zeros(b.shape) for b in self.bias]nabla_w = [np.zeros(w.shape) for w in self.weight]for x, y in mini_batch:delta_nabla_b, delta_nabla_w = self.backprop(x, y)nabla_b = [nb+dnb for nb, dnb in zip(nabla_b, delta_nabla_b)]nabla_w = [nw+dnw for nw, dnw in zip(nabla_w, delta_nabla_w)]self.weight = [w-(self.eta/len(mini_batch))*nw for w, nw in zip(self.weight, nabla_w)]self.bias = [b-(self.eta/len(mini_batch))*nb for b, nb in zip(self.bias, nabla_b)]def backprop(self, x, y):
6. nms
import numpy as npdef iou_calculate(bbox1, bbox2, mode='x1y1x2y2'):# 我的x11, y11, x12, y12 = bbox1x21, y21, x22, y22 = bbox2area1 = (y12-y11+1)*(x12-x11+1)area2 = (y22-y21+1)*(x22-x21+1)overlap = max(min(y12, y22) - max(y11, y21) + 1, 0) * max(min(x12, x22) - max(x11, x21) + 1, 0)return overlap / (area2 + area1 - overlap + 1e-6)def bb_intersection_over_union(boxA, boxB):# 别人的boxA = [int(x) for x in boxA]boxB = [int(x) for x in boxB]xA = max(boxA[0], boxB[0])yA = max(boxA[1], boxB[1])xB = min(boxA[2], boxB[2])yB = min(boxA[3], boxB[3])interArea = max(0, xB - xA + 1) * max(0, yB - yA + 1)boxAArea = (boxA[2] - boxA[0] + 1) * (boxA[3] - boxA[1] + 1)boxBArea = (boxB[2] - boxB[0] + 1) * (boxB[3] - boxB[1] + 1)iou = interArea / float(boxAArea + boxBArea - interArea)return ioudef nms(outputs, scores, T):''':param outputs: bboxes, x1y1x2y2:param scores: confidence of each bbox:param T: threshold:return:'''# 我的outputs = np.array(outputs)[np.argsort(-np.array(scores))]saved = [True for _ in range(outputs.shape[0])]for i in range(outputs.shape[0]):if saved[i]:for j in range(i+1, outputs.shape[0]):if saved[j]:iou = iou_calculate(outputs[i], outputs[j])if iou >= T:saved[j] = Falsescores = np.sort(-np.array(scores))return outputs[saved], -scores[saved]# 别人的
def nms_others(bboxes, scores, iou_thresh):""":param bboxes: 检测框列表:param scores: 置信度列表:param iou_thresh: IOU阈值:return:"""x1 = bboxes[:, 0]y1 = bboxes[:, 1]x2 = bboxes[:, 2]y2 = bboxes[:, 3]areas = (y2 - y1) * (x2 - x1)# 结果列表result = []index = scores.argsort()[::-1] # 对检测框按照置信度进行从高到低的排序,并获取索引# 下面的操作为了安全,都是对索引处理while index.size > 0:# 当检测框不为空一直循环i = index[0]result.append(i) # 将置信度最高的加入结果列表# 计算其他边界框与该边界框的IOUx11 = np.maximum(x1[i], x1[index[1:]])y11 = np.maximum(y1[i], y1[index[1:]])x22 = np.minimum(x2[i], x2[index[1:]])y22 = np.minimum(y2[i], y2[index[1:]])w = np.maximum(0, x22 - x11 + 1) # 两个边重叠时,也有1列/行像素点是重叠的h = np.maximum(0, y22 - y11 + 1)overlaps = w * hious = overlaps / (areas[i] + areas[index[1:]] - overlaps)# 只保留满足IOU阈值的索引idx = np.where(ious <= iou_thresh)[0]index = index[idx + 1] # 处理剩余的边框bboxes, scores = bboxes[result], scores[result]return bboxes, scoresdef mynms(bboxes, scores, iou_T):x1 = bboxes[:, 0]y1 = bboxes[:, 1]x2 = bboxes[:, 2]y2 = bboxes[:, 3]areas = (y2-y1+1) * (x2-x1+1)ids = np.argsort(scores)[::-1]res = []while len(ids) > 0:i = ids[0]res.append(i)x11 = np.maximum(x1[i], x1[ids[1:]])x22 = np.minimum(x2[i], x2[ids[1:]])y11 = np.maximum(y1[i], y1[ids[1:]])y22 = np.minimum(y2[i], y1[ids[1:]])# np.maximum(X,Y,None) : X与Y逐位取最大者. 最少两个参数overlap = np.maximum(x22-x11+1, 0) * np.maximum(y22-y11+1, 0)iou = overlap / (areas[i] +areas[ids[1:]] - overlap)ids = ids[1:][iou<T]return bboxes[res], scores[res]if __name__ == '__main__':outputs = [[10, 10, 20, 20], [15, 15, 25, 25], [9, 15, 25, 13]]scores = [0.6, 0.8, 0.7]T = 0.1print(nms(outputs, scores, T))print(nms_others(np.array(outputs), np.array(scores), T))print(mynms(np.array(outputs), np.array(scores), T))
7. k-means
import numpy as np
import copydef check(clusters_last, clusters_center):# clusters_last.sort()# clusters_center.sort()if len(clusters_last) == 0:return Falsefor c1, c2 in zip(clusters_last, clusters_center):if np.linalg.norm(c1 - c2) > 0:return Falsereturn Truedef kMeans(data, k):''':param data: [n, c]:param k: the number of clusters:return:'''clusters_last = []clusters_center = [data[i] for i in range(k)] # random choosedwhile not check(clusters_last, clusters_center):clusters_last = copy.deepcopy(clusters_center)clusters = [[] for _ in range(k)]for i in range(data.shape[0]):min_dis = float('inf')for j, center in enumerate(clusters_center):distance = np.linalg.norm(center-data[i])if distance < min_dis:min_dis = distanceidx = jclusters[idx].append(data[i])clusters_center = []for i in range(k):clusters_center.append(np.mean(clusters[i], axis=0))return clusters_centerdef kMeans2(data, k):''':param data: [n, c]:param k: the number of clusters:return:'''clusters_last = []clusters_center = copy.deepcopy(data[:k]) # random choosedwhile not check(clusters_last, clusters_center):clusters_last = copy.deepcopy(clusters_center)clusters = [[] for _ in range(k)]for i in range(data.shape[0]):distance = np.linalg.norm(clusters_center - data[i], axis=1)idx = np.argmin(distance)clusters[idx].append(data[i])clusters_center = []for i in range(k):clusters_center.append(np.mean(clusters[i], axis=0))clusters_center = np.array(clusters_center)return clusters_centerif __name__ == '__main__':data = np.random.random((20, 2))print(kMeans(data, 5))print(kMeans2(data, 5))
相关文章:
)
机器学习/深度学习常见算法实现(秋招版)
包括BN层、卷积层、池化层、交叉熵、随机梯度下降法、非极大抑制、k均值聚类等秋招常见的代码实现。 1. BN层 import numpy as npdef batch_norm(outputs, gamma, beta, epsilon1e-6, momentum0.9, running_mean0, running_var1)::param outputs: [B, L]:param gamma: mean:p…...

京东技术专家首推:Spring 微服务架构设计,GitHub 星标 128K
前言 本书提供了实现大型响应式微服务的实用方法和指导原则,并通过示例全面 讲解如何构建微服务。本书深入介绍了 Spring Boot、Spring Cloud、 Docker、Mesos 和 Marathon,还会教授如何用 Spring Boot 部署自治服务,而 无须使用重量级应用服…...

R语言--森林图制作
#数据准备- data5 #install.packages("rmda")rm(list=ls())library(MASS)library(rmda)library(dplyr) #mutate依赖环境library(magrittr) #%>%依赖setwd("D:/R/nomo5new2")data...

Tomcat中利用war包部署
在Tomcat中利用war包部署Web应用程序时,默认情况下,应用程序的上下文路径(也称为项目名称)将是war文件的名称(去除.war扩展名)。这意味着您在访问Web应用程序时必须在URL中包含项目名称。例如,如…...
[JAVAee]线程安全
目录 线程安全的理解 线程不安全的原因 ①非原子性 ②可见性 ③代码重排序 体会何为不安全的线程 保证线程安全 一个代码在多线程的环境下就很容易出现错误. 线程安全的理解 线程安全是什么呢?通俗的来讲,线程安全就是在多线程的环境下,代码的结果是符合我们预期的,就…...

ELK环境搭建——概况
Elastic Stack,核心产品包括 Elasticsearch、Kibana、Beats 和 Logstash等等。能够安全可靠地从任何来源获取任何格式的数据,然后对数据进行搜索、分析和可视化。 目录 一:Elasticsearch: 1.1 从数据中探寻各种问题的答案 1.1.1 定义您自己的搜索方式...

面试知识点整理
计算机的物理内存是有限的,所以操作系统在遇到内存不足时,会通过换页机制暂时把 某个进程未使用的内存中的数据搬移到硬盘上(比如 Linux 的 swap 分区),并在系统页表中 删除相应的表项。当该进程访问数据已经被搬移到硬…...

腾讯云服务器CVM计算型c6/c5实例CPU型号、处理器主频大全
腾讯云服务器CVM计算型C6、C5、C4、CN3、C3和C2实例,计算型C6云服务器CPU采用Intel Xeon Ice Lake处理器,主频3.2GHz,睿频3.5GHz,腾讯云服务器网分享更多计算型CVM云服务器CPU型号、处理器主频性能说明: 目录 云服务…...

vue3笔记-脚手架篇
第一章 基础篇 第二章 脚手架篇 vue2与vue3的一些区别 响应式系统: Vue 2 使用 Object.defineProperty 进行响应式数据的劫持和监听,它对数据监听是一项项的进行监听,因此,当新增属性发生变化时,它无法监测到&…...

数字的补数
题目: 对整数的二进制表示取反(0 变 1 ,1 变 0)后,再转换为十进制表示,可以得到这个整数的补数。 例如,整数 5 的二进制表示是 "101" ,取反后得到 "010" &…...

Taskfile demo
https://github.com/yangyang5214/blog/issues/1 makefile 很好用,但是有些语法我不会。 go-task yml & shell 不错,推荐 Taskfile.yml https://github.com/go-task/task/blob/main/.golangci.yml # go install github.com/go-task/task/v3/cmd/ta…...

MyBatis学习笔记之高级映射及延迟加载
文章目录 环境搭建,数据配置多对一的映射的思路逻辑级联属性映射association分布查询 一对多的映射的思路逻辑collection分布 环境搭建,数据配置 t_class表 t_stu表 多对一的映射的思路逻辑 多对一:多个学生对应一个班级 多的一方是st…...

小程序如何删除/上架/下架商品
在小程序中,产品的删除、上架和下架是常见的操作,可以根据实际需求来管理商品的展示与销售。下面将介绍如何在小程序中删除上架下架商品的具体步骤。 进入商品管理页面, 在个人中心点击管理入口,然后找到“商品管理”菜单并点击。…...
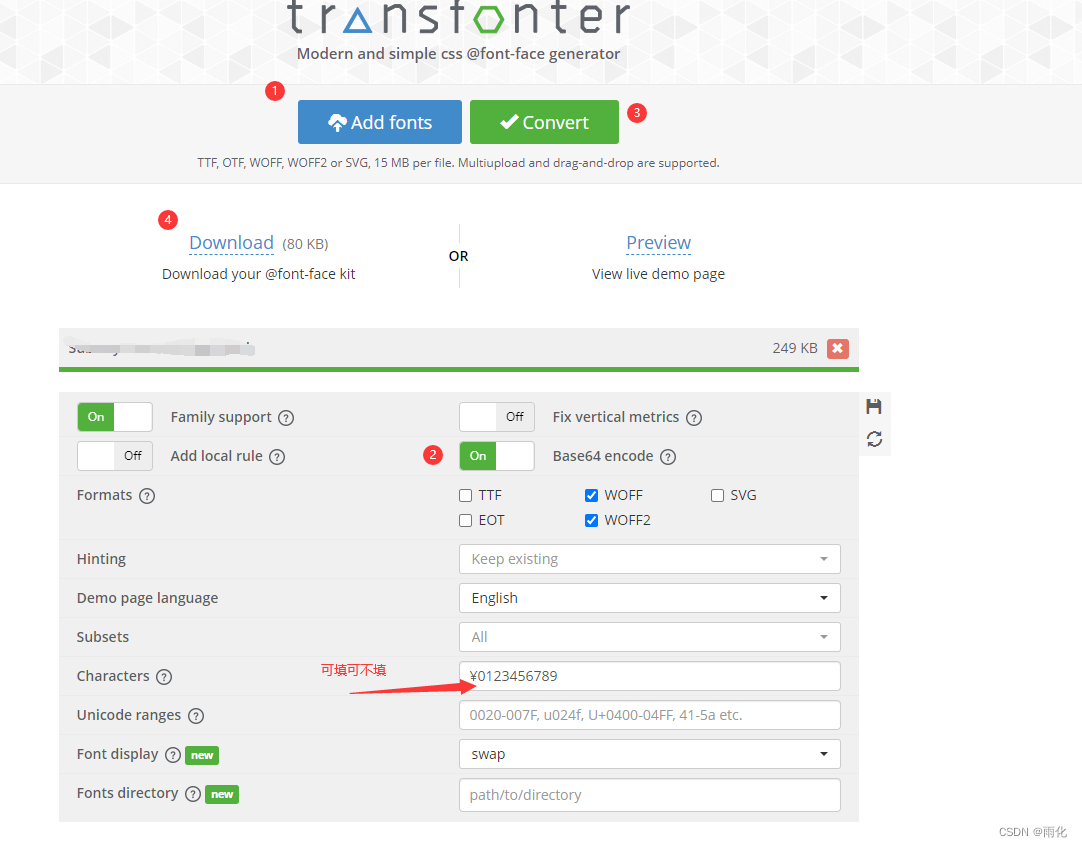
Failed to load local font resource:微信小程序加载第三方字体
加载本地字体.ttf 将ttf转换为base64格式:https://transfonter.org/ 步骤如下 将下载后的stylesheet.css 里的font-family属性名字改一下,然后引进页面里就行了,全局样式就放app.scss,单页面就引入单页面 注: .title…...
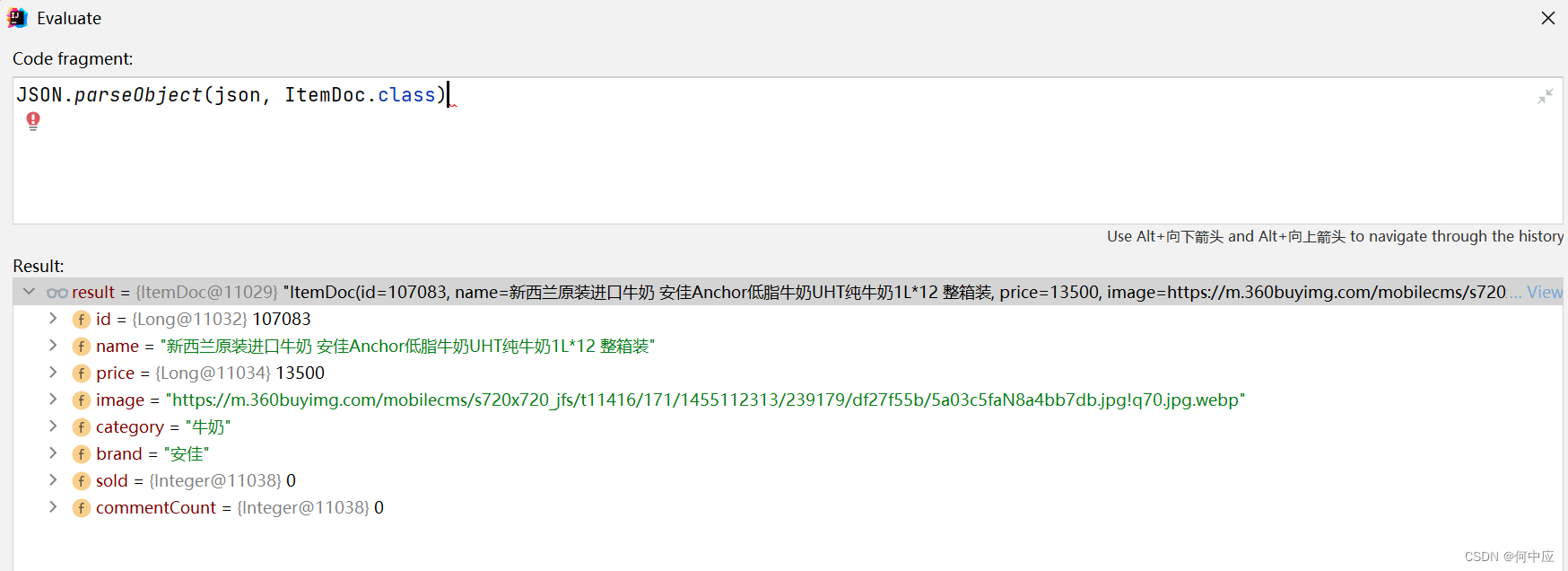
使用fastjson错误
说明:使用fastjson时,对象解析不成功,一直报错,但是json格式没有错; 错误信息:Method threw ‘com.alibaba.fastjson.JSONException’ exception. json数据是正确的 分析:注意看,fa…...
【GitOps系列】使用Kustomize和Helm定义应用配置
文章目录 使用 Kustomize 定义应用改造示例应用1.创建基准和多环境目录2.环境差异分析3.为 Base 目录创建通用 Manifest4.为开发环境目录创建差异 Manifest5.为预发布环境创建差异 Manifest6.为生产环境创建差异 Manifest 部署 Kustomize 应用部署到开发环境部署到生产环境 使用…...

Android kotlin高阶函数与Java lambda表达式介绍与实战
一、介绍 目前在Java JDK版本的不断升高,新的表达式已开始出现,但是在Android混淆开发中,kotlin的语言与Java的语言是紧密贴合的。所以Java lambda表达式在kotlin中以新的身份出现:高阶函数与lambda表达式特别类似。接下来我讲会先…...
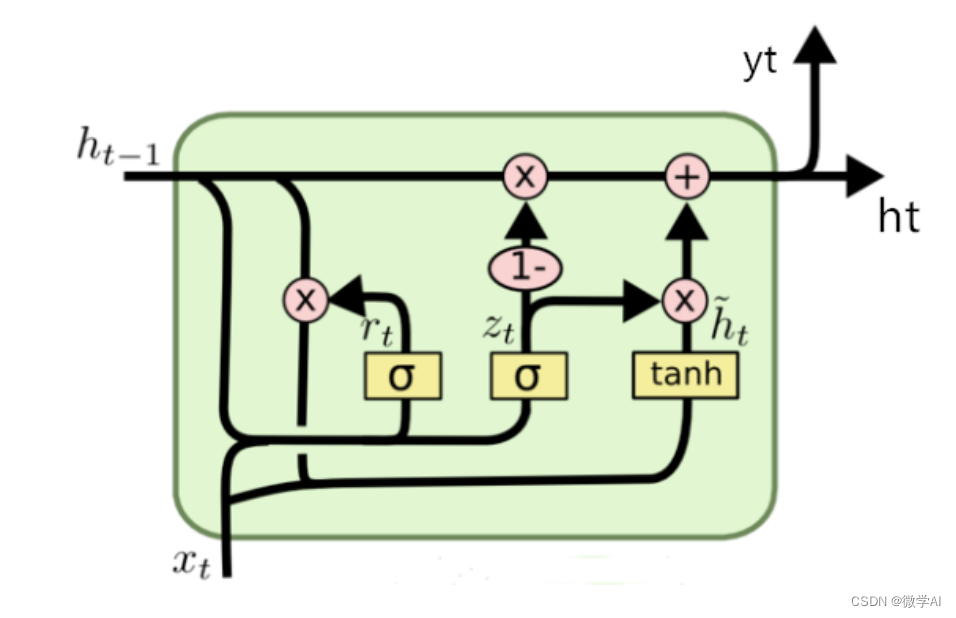
自然语言处理实战项目13-基于GRU模型与NER的关键词抽取模型训练全流程
大家好,我是微学AI,今天给大家介绍一下自然语言处理实战项目13-基于GRU模型与NER的关键词抽取模型训练全流程。本文主要介绍关键词抽取样例数据、GRU模型模型构建与训练、命名实体识别(NER)、模型评估与应用,项目的目标是通过训练一个GRU模型…...
7.26 Qt
用QT制作一个登陆界面 运行代码 login.h #ifndef WIDGET_H #define WIDGET_H#include <QWidget> #include <QDebug> //信息调试类,用于输出 #include <QIcon> //图标类头文件 #include <QPushButton&…...
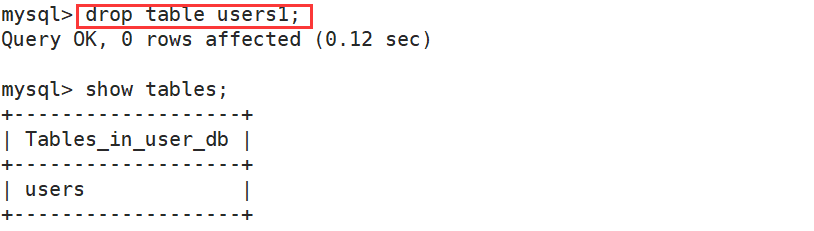
【MySQL】库和表的操作
目录 一、库的操作 1.1创建数据库 1.2创建数据库案例 1.3字符集和校验规则 (1)查看系统默认字符集以及校验规则 (2)查看数据库支持的字符集 (3)查看数据库支持的字符集校验规则 (4&…...
)
从IPv4到IPv6迁移实战:在eNSP里排查那些容易被忽略的安全配置(避坑指南)
从IPv4到IPv6迁移实战:eNSP环境下的安全配置深度排查指南 当企业网络从IPv4向IPv6过渡时,工程师们常常会陷入一种"配置惯性"——沿用IPv4时代的安全策略直接套用到IPv6环境。这种思维定式往往会导致网络出现各种"隐形漏洞"。本文将通…...
)
Python自动化运维实战:用Paramiko库5分钟搞定SSH批量管理(附完整代码)
Python自动化运维实战:用Paramiko库5分钟搞定SSH批量管理(附完整代码) 运维工程师的日常工作中,服务器管理往往占据大量时间。想象一下,当你需要同时更新50台服务器的安全补丁,或者批量收集100台设备的日志…...

如何完美解决MacBook触控板在Windows的三指拖动难题
如何完美解决MacBook触控板在Windows的三指拖动难题 【免费下载链接】ThreeFingersDragOnWindows Enables macOS-style three-finger dragging functionality on Windows Precision touchpads. 项目地址: https://gitcode.com/gh_mirrors/th/ThreeFingersDragOnWindows …...
)
告别反复插拔SD卡:迪文DGUS II屏串口下载与仿真调试全攻略(附T5L实战技巧)
告别反复插拔SD卡:迪文DGUS II屏串口下载与仿真调试全攻略(附T5L实战技巧) 在工业控制、智能家居和物联网设备的开发中,迪文DGUS II系列串口屏因其高性价比和强大的组态功能,已成为众多开发者的首选。然而,…...

Ollama部署LFM2.5-1.2B-Thinking:从CSDN文档到实际调用的完整链路
Ollama部署LFM2.5-1.2B-Thinking:从CSDN文档到实际调用的完整链路 1. 认识LFM2.5-1.2B-Thinking模型 LFM2.5-1.2B-Thinking是一个专门为设备端部署设计的智能文本生成模型。这个模型属于LFM2.5系列,是在LFM2架构基础上通过扩展预训练和强化学习进一步优…...

Leaflet坐标系实战:从设置到动态切换的完整指南
1. Leaflet坐标系基础概念解析 第一次接触Leaflet坐标系时,我也被各种专业术语搞得晕头转向。简单来说,坐标系就是用来确定地图上每个点位置的规则系统。就像我们在地球上使用经纬度定位一样,数字地图也需要明确的坐标参考。 Leaflet默认支持…...

用Python可视化理解柯西-施瓦茨不等式:从向量内积到函数空间的几何直觉
用Python可视化理解柯西-施瓦茨不等式:从向量内积到函数空间的几何直觉 数学中的不等式往往蕴含着深刻的几何意义,柯西-施瓦茨不等式就是这样一个连接代数与几何的桥梁。对于数据科学和机器学习的学习者来说,理解这个不等式不仅能夯实数学基础…...

3大突破!LxgwWenKai字体效率革命:从代码阅读到多场景适配全指南
3大突破!LxgwWenKai字体效率革命:从代码阅读到多场景适配全指南 【免费下载链接】LxgwWenKai LxgwWenKai: 这是一个开源的中文字体项目,提供了多种版本的字体文件,适用于不同的使用场景,包括屏幕阅读、轻便版、GB规范字…...

SNOMED CT入门指南:从概念、关系到数据文件,手把手带你理解这个医学术语标准
SNOMED CT技术解析:从数据结构到医疗信息系统的实战指南 在医疗信息化领域,数据标准化是打破信息孤岛的关键。当不同医院的电子病历系统使用各自独立的术语体系时,跨机构的数据交换就像一场没有翻译的多国会议——充满误解和低效。这正是SNOM…...

拓扑排序不止于理论:用邻接矩阵实现时,我踩过的3个坑和性能优化
拓扑排序实战:邻接矩阵实现中的性能陷阱与优化策略 邻接矩阵作为图论中最直观的存储结构,常被初学者用来实现拓扑排序算法。但当我们真正将其投入实际项目时,往往会遭遇意想不到的性能瓶颈和逻辑陷阱。本文将分享三个真实项目中踩过的坑&…...