自然语言处理实战项目13-基于GRU模型与NER的关键词抽取模型训练全流程
大家好,我是微学AI,今天给大家介绍一下自然语言处理实战项目13-基于GRU模型与NER的关键词抽取模型训练全流程。本文主要介绍关键词抽取样例数据、GRU模型模型构建与训练、命名实体识别(NER)、模型评估与应用,项目的目标是通过训练一个GRU模型来实现准确和鲁棒的关键词抽取,并通过集成NER模型提高关键词抽取的效果。这个项目提供了一个完整的流程,可以根据实际需求进行调整和扩展。
目录:
1.GRU模型介绍
2.NER方式提取关键词
3.NER方式的代码实现
4.总结
1.GRU模型介绍
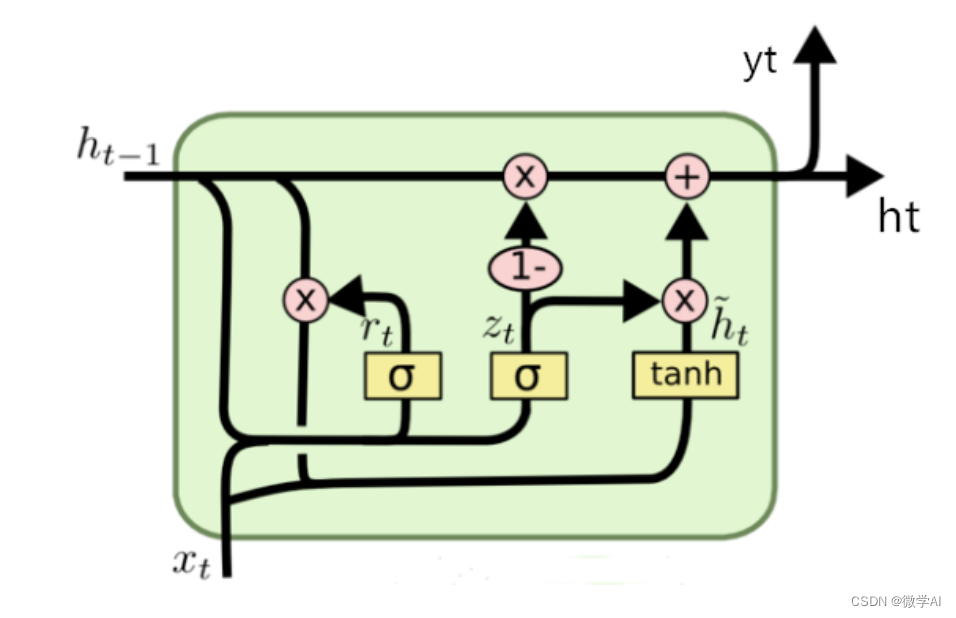
GRU是一种递归神经网络的变种,用于处理序列数据的建模任务。与传统的RNN结构相比,GRU引入了门控机制,以解决长期依赖问题,并减轻了梯度消失和爆炸问题。
GRU模型的主要组成部分包括:
1.输入门(Input Gate):决定了输入信息中有哪些部分需要被更新到隐藏状态。它通过一个sigmoid函数将输入数据与先前的隐藏状态进行组合,输出一个介于0和1之间的值,表示更新的权重。
2.更新门(Update Gate):控制是否更新隐藏状态的值。它通过一个sigmoid函数评估当前输入和先前隐藏状态,以确定是否将新信息与之前的隐藏状态进行组合。
3.重置门(Reset Gate):评估当前输入和先前隐藏状态,决定隐藏状态中要保留的信息和要忽略的信息。该门可以通过一个sigmoid函数和一个tanh函数获得两个不同的输出,然后将它们相乘,得到最终的重置门结果。
4.隐藏状态(Hidden State):用于存储序列中的信息,并在每个时间步传递和更新。隐藏状态根据输入和先前的隐藏状态进行更新。通过使用输入门和重置门对先前隐藏状态进行加权组合,然后使用tanh函数得到新的候选隐藏状态。最后,更新门确定如何将新的候选隐藏状态与先前的隐藏状态进行组合来获得最终的隐藏状态。
GRU模型在序列建模任务中具有以下优势:
处理长期依赖:GRU模型通过使用门控机制可以选择性地更新和保留序列中的信息,从而更好地处理长期依赖关系。
减轻梯度问题:由于门控机制的存在,GRU模型能够有效地减轻梯度消失和梯度爆炸等问题,提高模型的训练效果和稳定性。
参数较少:相比长短时记忆网络(LSTM),GRU模型的参数更少,更容易训练和调整。
2.NER方式提取关键词
NER可以用于关键词抽取,通过识别文本中的命名实体,从中提取出关键词。与传统的关键词抽取方法相比,NER具有以下优势:
1.精确性:NER可以准确定位文本中的具体实体,提供更精确的关键词抽取结果。
2.上下文理解:NER不仅仅是简单地提取词语,还能够根据上下文理解实体的含义,提高关键词抽取的准确性。
3.适应多领域:由于NER对上下文的理解能力,它可以用于不同领域的关键词抽取,如新闻、医学、法律等。
NER的工作流程通常包括以下步骤:
1.数据准备:收集并准备标注好的训练数据,其中标注好的数据应包含实体的起始位置和对应的标签。
2.特征提取:从文本中选择适当的特征来表示实体,如词性、上下文等。这些特征通常用于训练模型。
3.模型训练:使用标注好的训练数据,训练一个机器学习模型,如条件随机场(Conditional Random Field, CRF)、循环神经网络(Recurrent Neural Networks, RNN)等。
4.标注预测:使用训练好的模型,对新的文本进行预测,并标注出实体的位置和类别。
5.后处理:根据任务需求,对NER的结果进行后处理,如过滤掉不相关的实体、合并相邻的实体等。
6.关键词抽取:从提取出的实体中,选择具有关键意义的实体作为关键词。
3.NER方式的代码实现
import torch
import torch.nn as nn
from torch.optim import Adam# 定义模型
class KeywordExtractor(nn.Module):def __init__(self, input_size, hidden_size, output_size):super(KeywordExtractor, self).__init__()self.hidden_size = hidden_sizeself.embedding = nn.Embedding(input_size, hidden_size)self.gru = nn.GRU(hidden_size, hidden_size)self.linear = nn.Linear(hidden_size, output_size)def forward(self, input):embedded = self.embedding(input)output, hidden = self.gru(embedded)output = self.linear(output.view(-1, self.hidden_size))return output.view(len(input), -1, output.size(1))# 准备训练数据
train_data = [("我 爱 北京", ["O", "O", "B-LOC"]),("张三 是 中国 人", ["B-PER", "O", "B-LOC", "O"]),("李四 是 美国 人", ["B-PER", "O", "B-LOC", "O"]),("我 来自 北京", ["O", "O", "B-LOC"]),("我 来自 广州", ["O", "O", "B-LOC"]),("王五 去 英国 玩", ["B-PER", "O", "B-LOC", "O"]),("我 喜欢 上海", ["O", "O", "B-LOC"]),("刘东 是 北京 人", ["B-PER", "O", "B-LOC", "O"]),("李明 来自 深圳", ["B-PER", "O", "B-LOC"]),("我 计划 去 香港 旅行", ["O", "O","O", "B-LOC", "O"]),("你 想去 法国 吗", ["O", "O", "B-LOC", "O"]),("福州 是 你的 家乡 吗", ["B-LOC", "O", "O", "O", "O"]),("张伟 和 王芳 一起 去 新加坡", ["B-PER", "O", "B-PER", "O", "O", "B-LOC"]),# 其他训练样本...
]# 构建词汇表
word2idx = {"<PAD>": 0, "<UNK>": 1}
tag2idx = {"O": 0, "B-LOC": 1, "B-PER":2}
for sentence, tags in train_data:for word in sentence.split():if word not in word2idx:word2idx[word] = len(word2idx)for tag in tags:if tag not in tag2idx:tag2idx[tag] = len(tag2idx)
idx2word = {idx: word for word, idx in word2idx.items()}
idx2tag = {idx: tag for tag, idx in tag2idx.items()}# 超参数
input_size = len(word2idx)
output_size = len(tag2idx)
hidden_size = 128
num_epochs = 100
batch_size = 2
learning_rate = 0.001# 实例化模型和损失函数
model = KeywordExtractor(input_size, hidden_size, output_size)
criterion = nn.CrossEntropyLoss()# 定义优化器
optimizer = Adam(model.parameters(), lr=learning_rate)# 准备训练数据的序列张量和标签张量
def prepare_sequence(seq, to_idx):idxs = [to_idx.get(token, to_idx["<UNK>"]) for token in seq.split()]return torch.tensor(idxs, dtype=torch.long)# 填充数据
def pad_sequences(data):# 计算最长句子的长度max_length = max(len(item[0].split()) for item in data)aligned_data = []for sentence, tags in data:words = sentence.split()word_s = words + ['O'] * (max_length - len(tags))sentence = ' '.join(word_s)aligned_tags = tags + ['O'] * (max_length - len(tags))aligned_data.append((sentence, aligned_tags))return aligned_data# 训练模型
for epoch in range(num_epochs):for i in range(0, len(train_data), batch_size):batch_data = train_data[i:i + batch_size]batch_data = pad_sequences(batch_data)inputs = torch.stack([prepare_sequence(sentence, word2idx) for sentence, _ in batch_data])targets = torch.LongTensor([tag2idx[tag] for _, tags in batch_data for tag in tags])# 前向传播outputs = model(inputs)loss = criterion(outputs.view(-1, output_size), targets)# 反向传播和优化optimizer.zero_grad()loss.backward()optimizer.step()print('Epoch [{}/{}], Step [{}/{}], Loss: {:.4f}'.format(epoch + 1, num_epochs, i + 1, len(train_data) // batch_size, loss.item()))# 测试模型
test_sentence = "李明 想去 北京 游玩"
with torch.no_grad():inputs = prepare_sequence(test_sentence, word2idx).unsqueeze(0)outputs = model(inputs)_, predicted = torch.max(outputs.data, 2)tags = [idx2tag[idx.item()] for idx in predicted.squeeze()]print('输入句子:', test_sentence)print('关键词标签:', tags)运行结果:
Epoch [99/100], Step [3/6], Loss: 0.0006
Epoch [99/100], Step [5/6], Loss: 0.0002
Epoch [99/100], Step [7/6], Loss: 0.0002
Epoch [99/100], Step [9/6], Loss: 0.0006
Epoch [99/100], Step [11/6], Loss: 0.0006
Epoch [99/100], Step [13/6], Loss: 0.0009
Epoch [100/100], Step [1/6], Loss: 0.0003
Epoch [100/100], Step [3/6], Loss: 0.0006
Epoch [100/100], Step [5/6], Loss: 0.0002
Epoch [100/100], Step [7/6], Loss: 0.0002
Epoch [100/100], Step [9/6], Loss: 0.0005
Epoch [100/100], Step [11/6], Loss: 0.0006
Epoch [100/100], Step [13/6], Loss: 0.0009输入句子: 李明 想去 北京 游玩
关键词标签: ['B-PER', 'O', 'B-LOC', 'O']
4.总结
命名实体识别(NER)是自然语言处理中的一项技术,目的是从文本中识别和提取出具有特定意义的命名实体。这些命名实体可以是人名、地名、组织机构名、时间、日期等具有特定含义的词汇。
NER的任务是将文本中的每个词标注为预定义的命名实体类别,常见的类别有人名(PERSON)、地名(LOCATION)、组织机构名(ORGANIZATION)等。通过NER技术,可以提取出文本中的关键信息,帮助理解文本的含义和上下文。
NER的核心思想是结合机器学习和自然语言处理技术,利用训练好的模型对文本进行分析和处理。通常使用的方法包括基于规则的方法、统计方法和基于机器学习的方法。其中,基于机器学习的方法在大规模标注好的数据集上进行训练,通过学习识别命名实体的模式和规律,从而提高识别的准确性。
NER在实际应用中有广泛的应用场景,包括信息抽取、智能搜索、问答系统等。通过NER技术提取出的关键词可以被用于进一步的信息处理和分析,有助于提高对文本的理解和处理效果。
总之,命名实体识别(NER)是一项重要的自然语言处理技术,能够从文本中提取出具有特定含义的命名实体。它在各种应用场景中发挥着重要作用,为文本分析和信息提取提供了有力的支持。
相关文章:
自然语言处理实战项目13-基于GRU模型与NER的关键词抽取模型训练全流程
大家好,我是微学AI,今天给大家介绍一下自然语言处理实战项目13-基于GRU模型与NER的关键词抽取模型训练全流程。本文主要介绍关键词抽取样例数据、GRU模型模型构建与训练、命名实体识别(NER)、模型评估与应用,项目的目标是通过训练一个GRU模型…...
7.26 Qt
用QT制作一个登陆界面 运行代码 login.h #ifndef WIDGET_H #define WIDGET_H#include <QWidget> #include <QDebug> //信息调试类,用于输出 #include <QIcon> //图标类头文件 #include <QPushButton&…...
【MySQL】库和表的操作
目录 一、库的操作 1.1创建数据库 1.2创建数据库案例 1.3字符集和校验规则 (1)查看系统默认字符集以及校验规则 (2)查看数据库支持的字符集 (3)查看数据库支持的字符集校验规则 (4&…...
(五)RabbitMQ-进阶 死信队列、延迟队列、防丢失机制
Lison <dreamlison163.com>, v1.0.0, 2023.06.23 RabbitMQ-进阶 死信队列、延迟队列、防丢失机制 文章目录 RabbitMQ-进阶 死信队列、延迟队列、防丢失机制死信队列延迟队列延迟队列介绍**延迟队列_死信队列_的实现**延迟队列_插件实现下载插件RabbitMQ 配置类RabbitMQ …...

windows下面的python配置
安装包选择exe后缀的 链接:https://pan.baidu.com/s/1sTzQdHMqI4KZwyJHl79Q3w 提取码:1111 PIP安装脚本 python版本pip安装脚本下载地址n3.6https://bootstrap.pypa.io/pip/3.6/get-pip.py3.7及以上https://bootstrap.pypa.io/get-pip.py 控制面板新…...
vue3中 状态管理pinia得使用
在做项目中 vue2改造vue3项目时的vuex 发生得一些变化 vue3项目中 先看下 stores.jsimport { defineStore } from pinia 引入方法注册方法 import { getListFieldLevel } from ..api/index.jsexport const useScreenStore defineStore(screen, {state: () > ({fieldList:…...
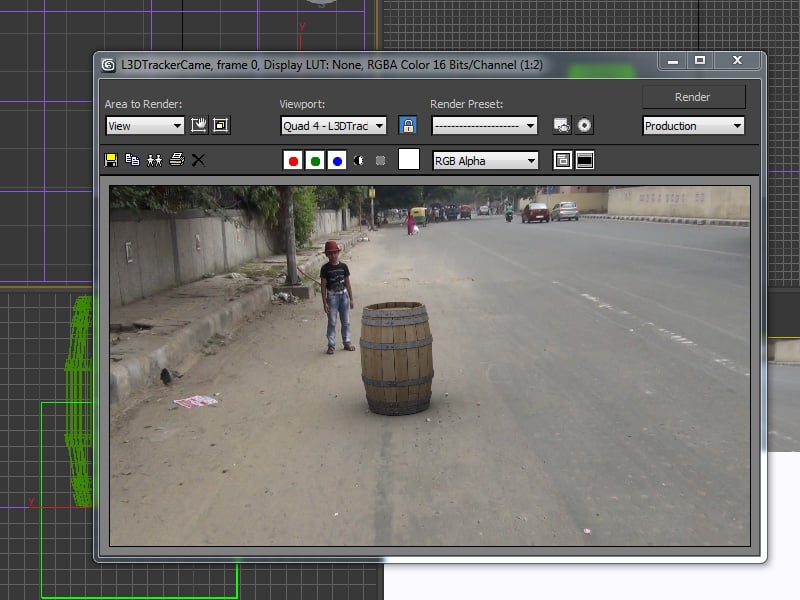
如何使用 After Effects 导出摄像机跟踪数据到 3ds Max
推荐: NSDT场景编辑器助你快速搭建可二次开发的3D应用场景 在本教程中,我将展示如何在After Effects中跟踪实景场景,然后将相机数据导出到3ds Max。 1. 项目设置 步骤 1 打开“后效”。 打开后效果 步骤 2 转到合成>新合成以创建新合…...

【iOS】懒加载
文章目录 前言一、懒加载的意义二、懒加载的原理三、懒加载优缺点 前言 iOS懒加载(Lazy Loading)是一种延迟加载的技术,它允许在需要的时候才初始化对象或执行某些操作,而不是在对象创建的时候立即执行。懒加载主要用于优化应用程…...

《脱离“一支笔、一双手、一道力扣”困境的秘诀》:突破LeetCode难题的五个关键步骤
导言: 在解决LeetCode等编程题时,不少人会陷入“一支笔、一双手、一道力扣(LeetCode)做一宿”的困境。尽管已经掌握了相关知识和算法,但在实际挑战中却无从下手。本文将分享如何摆脱这一困境的秘诀,让你在面…...
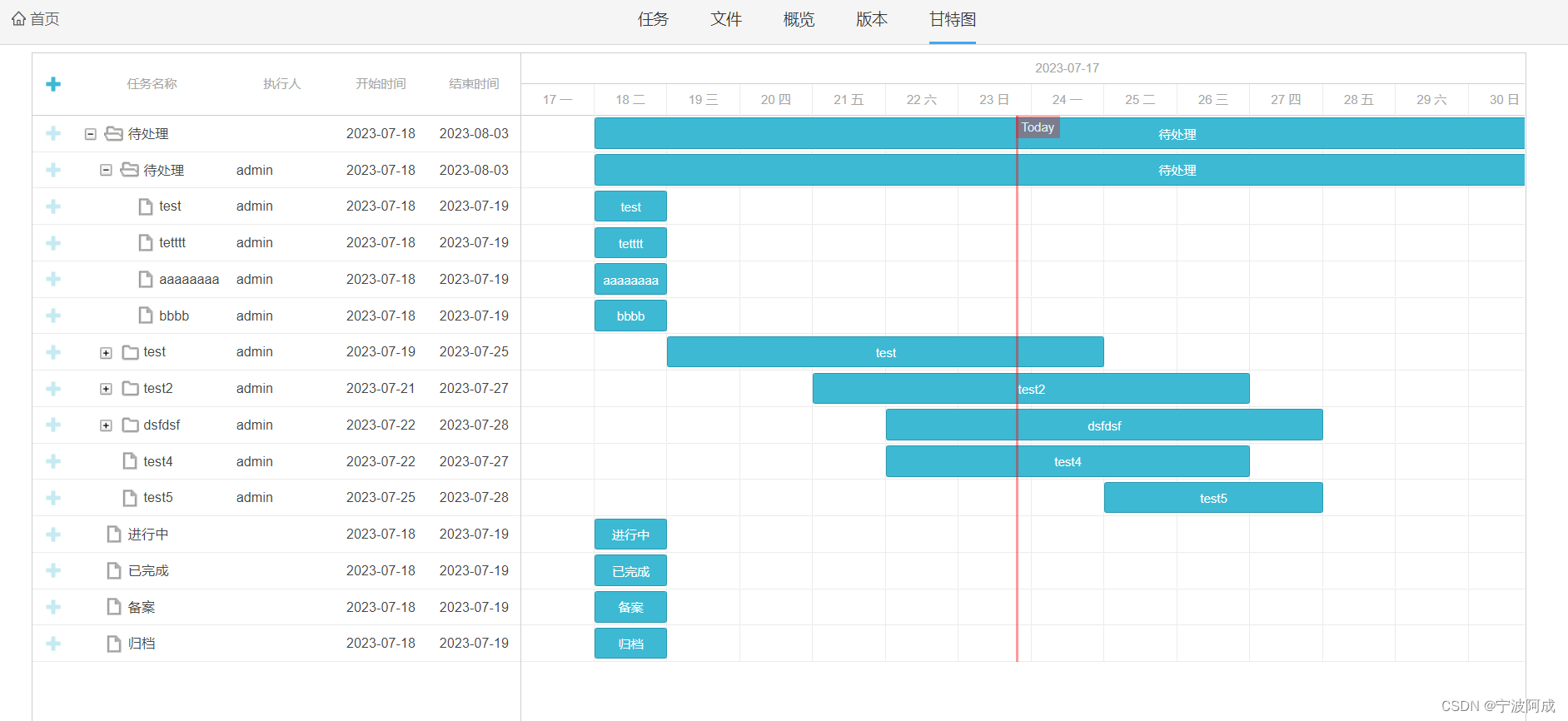
基于jeecg-boot的任务甘特图显示
更多功能看演示系统 gitee源代码地址 后端代码: https://gitee.com/nbacheng/nbcio-boot 前端代码:https://gitee.com/nbacheng/nbcio-vue.git 在线演示(包括H5) : http://122.227.135.243:9888 基于项目的任务显…...

docker export,import后无法运行,如java命令找不到,运行后容器内编码有问题
为什么用docker export呢,😔~由于客户环境太恶心了,测试一次更是麻烦,所以什么都得在本地调试完成,争取每次测试上线一次通过才行,说多了都是泪。 由于踩坑几次了,每次都忘记,且每次…...
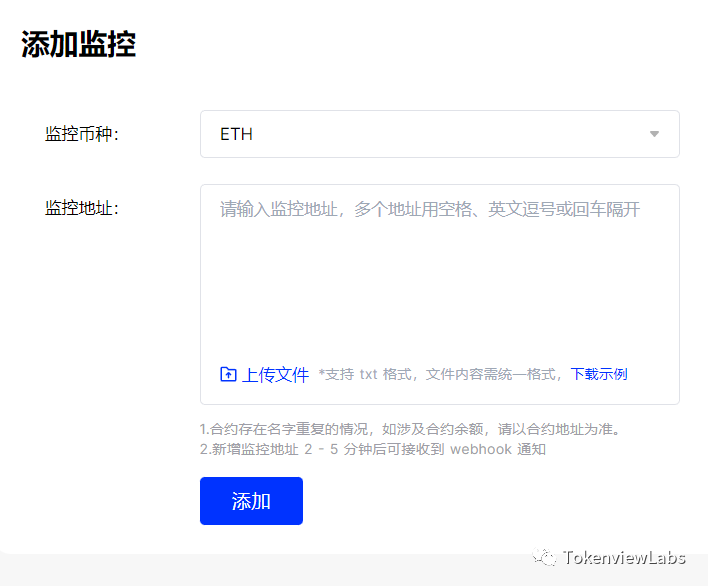
Web3教程| 什么是地址监控?如何使用地址监控追踪黑客地址?
在当今Web3世界里,保护个人资产安全至关重要。据报道在2023年上半年,Web3领域因黑客攻击事件造成的损失高达4.794亿美元。 此外,10多个公链遭受黑客攻击,其中以太坊链遭受的损失最多,约为2.87亿美元。这些黑客的存在迫…...
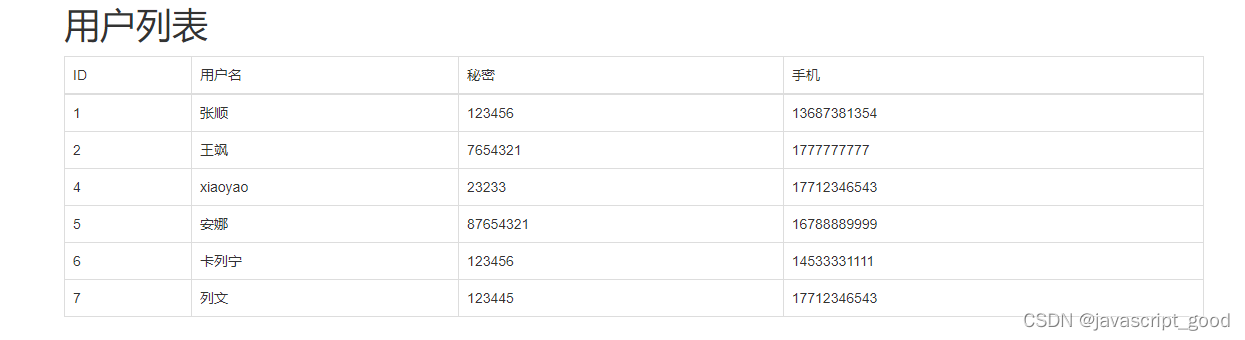
flask结合mysql实现用户的添加和获取
1、数据库准备 已经安装好数据库,并且创建数据库和表 create database unicom DEFAULT CHARSET utf8 COLLATE utf8_general_ci; CREATE TABLE admin( id int not null auto_increment primary key, username VARCHAR(16) not null, password VARCHAR(64) not null…...
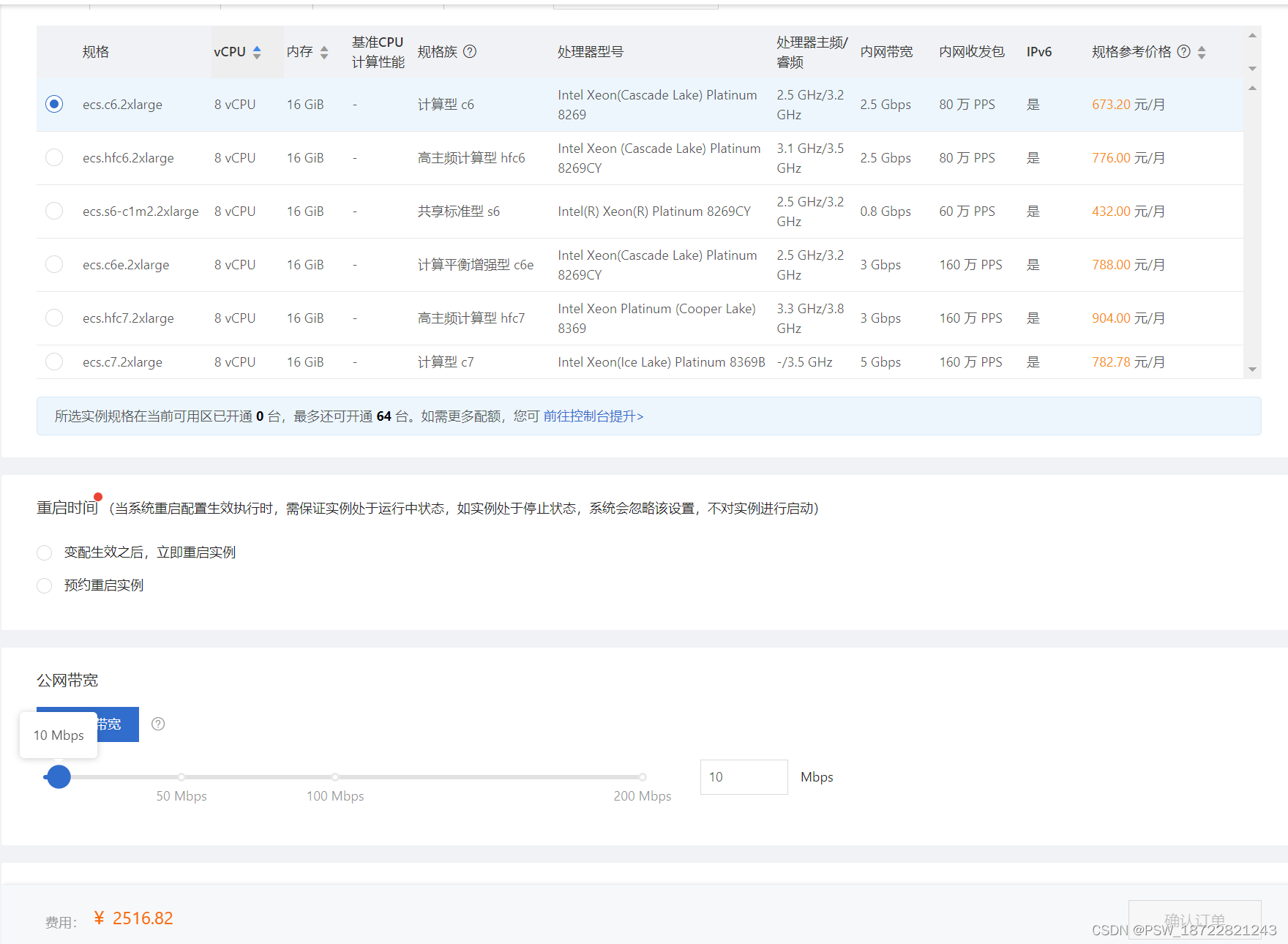
阿里云服务器配置 内存,cpu等等
实例升配,https://help.aliyun.com/document_detail/25438.html?spma2c4g.11174283.6.780.2cbf4c070oeino#title-a5t-gg2-...

PHP注册、登陆、6套主页-带Thinkphp目录解析-【强撸项目】
强撸项目系列总目录在000集 PHP要怎么学–【思维导图知识范围】 文章目录 本系列校训本项目使用技术 上效果图主页注册,登陆 phpStudy 设置导数据库项目目录如图:代码部分:控制器前台的首页 其它配套页面展示直接给第二套方案的页面吧第三套…...

android Activity设置背景为半透明的时候会显示上一个activity的内容
在弹出PopupWindow时将当前Activity设置成了半透明: WindowManager.LayoutParams lp = this.activity.getWindow().getAttributes();lp.alpha = 0.5f; //0.0-1.0this...
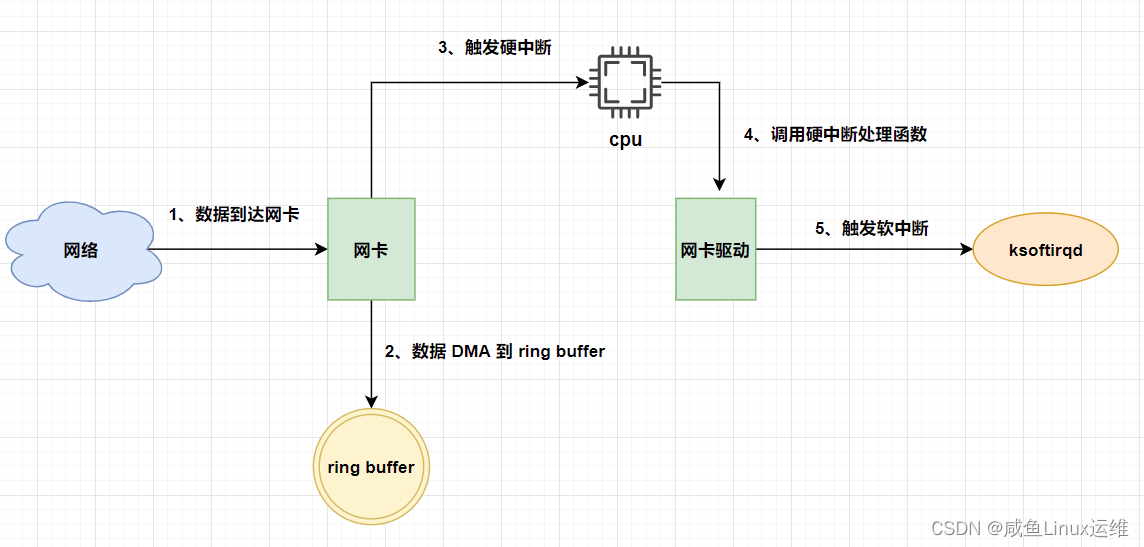
Linux 网络收包流程
哈喽大家好,我是咸鱼 我们在跟别人网上聊天的时候,有没有想过你发送的信息是怎么传到对方的电脑上的 又或者我们在上网冲浪的时候,有没有想过 HTML 页面是怎么显示在我们的电脑屏幕上的 无论是我们跟别人聊天还是上网冲浪,其实…...

flex: 0 0 273px的意思
flex: 0 0 273px; 是一条CSS属性,用于设置flexible box布局(flexbox)中的flex子项的灵活性和尺寸。 这条属性包含三个值,分别是: flex-grow: 表示弹性增长因子,指定当有多余空间时,子项能够增长…...
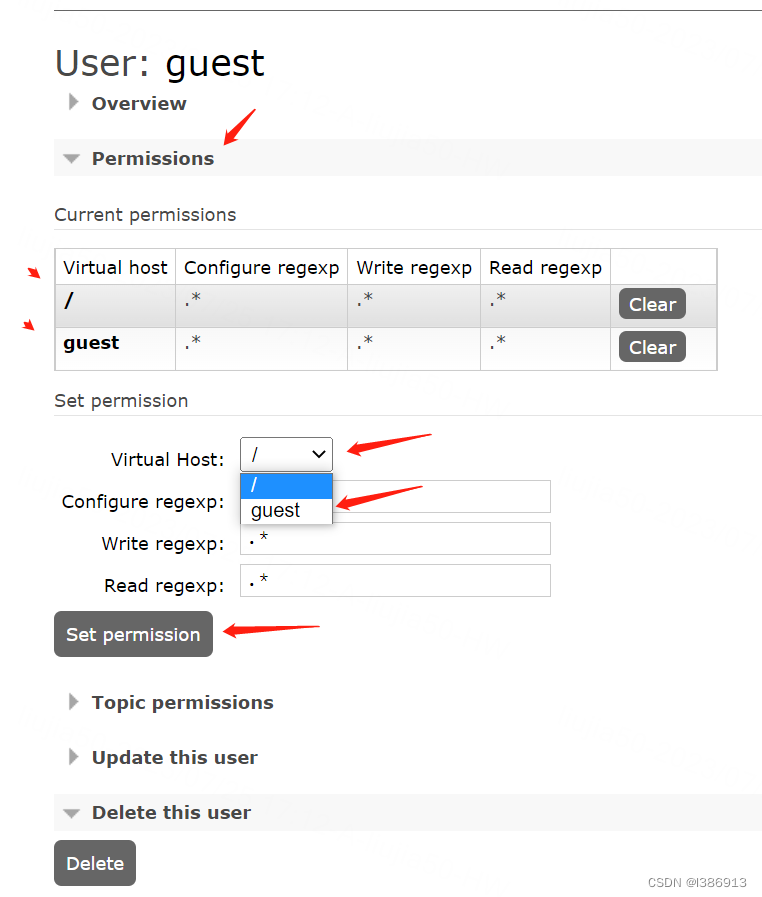
helm部署rabbitmq
1.添加rabbitmq仓库并下载包 helm repo add bitnami https://charts.bitnami.com/bitnami helm pull bitnami/rabbitmq --version 10.1.4 tar -zxvf rabbitmq-10.1.4.tgz mv values.yaml values.yaml.back grep -v "#" values.yaml.back > values.yaml2.helm部署…...
Java版Spring Cloud+Spring Boot+Mybatis+uniapp知识付费平台讲解
提供私有化部署,免费售后,专业技术指导,支持PC、APP、H5、小程序多终端同步,支持二次开发定制,源码交付。 Java版知识付费-轻松拥有知识付费平台 多种直播形式,全面满足直播场景需求 公开课、小班课、独…...

别再让地图‘飘’了!深入浅出解析Cesium中GCJ-02、BD-09坐标偏移原理与DVGIS库实战
解密国内地图坐标系:从原理到实战解决Cesium中的“飘移”问题 你是否曾在Cesium中加载不同来源的地图数据时,发现明明标注的是同一个位置,却出现了明显的偏移?这种“飘移”现象背后,隐藏着国内地图坐标系复杂的加密体系…...

关于【进程池阻塞 + 子进程未回收问题】
续接上文:进程间通信(二):实现一个高可用的进程池-CSDN博客 目录 一、先看现象:两个核心问题 二、核心原因:文件描述符泄漏(管道读端没关干净) 1. 管道的核心规则回顾 2. 后果&a…...

PDF-Parser-1.0零售业应用:促销海报信息提取
PDF-Parser-1.0零售业应用:促销海报信息提取 1. 引言 零售行业的促销活动总是让人又爱又恨。爱的是能带来销量增长,恨的是每次活动都要处理海量的促销海报——设计、印刷、分发,最后还要手动录入成千上万的商品信息、价格数据和活动规则。一…...

告别数据孤岛:用RTKLIB str2str打通GNSS设备与上位机的通信全链路
高精度定位系统集成实战:RTKLIB str2str的数据枢纽架构设计 在自动驾驶测试场,一台搭载多传感器阵列的无人车正以厘米级精度重复着轨迹跟踪。工程师们通过监控屏观察着实时定位数据流——Ublox接收机的原始观测值、Septentrio的RTCM差分信号、IMU的惯性数…...

Qwen3-ASR-1.7B与QT集成:开发跨平台语音识别桌面应用
Qwen3-ASR-1.7B与QT集成:开发跨平台语音识别桌面应用 1. 引言 想象一下,你正在开发一个需要语音输入功能的桌面应用。传统的语音识别方案要么需要联网调用云端API,要么识别准确率不够理想。现在,有了Qwen3-ASR-1.7B这个强大的开…...

Source Han Serif CN:7种字重如何改变你的中文排版体验?
Source Han Serif CN:7种字重如何改变你的中文排版体验? 【免费下载链接】source-han-serif-ttf Source Han Serif TTF 项目地址: https://gitcode.com/gh_mirrors/so/source-han-serif-ttf 你是否曾为寻找合适的中文字体而烦恼?商业字…...
秒杀“朋友圈”和“岛屿数量”这类题目(附Python/Java代码))
LeetCode刷题实战:用并查集(Union-Find)秒杀“朋友圈”和“岛屿数量”这类题目(附Python/Java代码)
并查集实战:用Union-Find高效解决LeetCode朋友圈与岛屿问题 在算法面试中,并查集(Union-Find)是一种常被忽视却威力巨大的数据结构。它能在近乎常数时间内完成集合合并与查询操作,特别适合处理动态连通性问题。本文将以…...

OpenClaw+GLM-4.7-Flash:个人财务管理自动化方案
OpenClawGLM-4.7-Flash:个人财务管理自动化方案 1. 为什么需要自动化财务管理? 作为一个长期被个人账务困扰的技术从业者,我每个月最头疼的就是整理各种消费记录。银行卡、支付宝、微信支付、信用卡账单分散在不同平台,手动统计…...

IndexTTS 2.0情感控制效果:用自然语言描述生成对应语气语音
IndexTTS 2.0情感控制效果:用自然语言描述生成对应语气语音 1. 引言:语音合成的革命性突破 想象一下这样的场景:你正在制作一部动画短片,主角需要说一句"我受够了!"——但你不只是想让它"说出来"…...

OpenClaw+GLM-4.7-Flash:自动化测试脚本生成器
OpenClawGLM-4.7-Flash:自动化测试脚本生成器 1. 为什么需要自动化测试脚本生成 作为一名长期奋战在一线的开发者,我深知测试环节的重要性与繁琐程度。每当项目进入测试阶段,编写测试用例和脚本往往要占据整个开发周期的30%-40%时间。更令人头…...