golang waitgroup
案例
WaitGroup 可以解决一个 goroutine 等待多个 goroutine 同时结束的场景,这个比较常见的场景就是例如 后端 worker 启动了多个消费者干活,还有爬虫并发爬取数据,多线程下载等等。
我们这里模拟一个 worker 的例子
package mainimport ("fmt""sync"
)func worker(i int) {fmt.Println("worker: ", i)
}func main() {var wg sync.WaitGroupfor i := 0; i < 10; i++ {wg.Add(1)go func(i int) {defer wg.Done()worker(i)}(i)}wg.Wait()
}
问题: 反过来支持多个 goroutine 等待一个 goroutine 完成后再干活吗? 看我们接下来的源码分析你就知道了
源码分析
type WaitGroup struct {noCopy noCopy// 64-bit value: high 32 bits are counter, low 32 bits are waiter count.// 64-bit atomic operations require 64-bit alignment, but 32-bit// compilers do not ensure it. So we allocate 12 bytes and then use// the aligned 8 bytes in them as state, and the other 4 as storage// for the sema.state1 [3]uint32
}
WaitGroup 结构十分简单,由 nocopy 和 state1 两个字段组成,其中 nocopy 是用来防止复制的
type noCopy struct{}// Lock is a no-op used by -copylocks checker from `go vet`.
func (*noCopy) Lock() {}
func (*noCopy) Unlock() {}
由于嵌入了 nocopy 所以在执行 go vet 时如果检查到 WaitGroup 被复制了就会报错。这样可以一定程度上保证 WaitGroup 不被复制,对了直接 go run 是不会有错误的,所以我们代码 push 之前都会强制要求进行 lint 检查,在 ci/cd 阶段也需要先进行 lint 检查,避免出现这种类似的错误。
~/project/Go-000/Week03/blog/06_waitgroup/02 main*
❯ go run ./main.go~/project/Go-000/Week03/blog/06_waitgroup/02 main*
❯ go vet .
# github.com/mohuishou/go-training/Week03/blog/06_waitgroup/02
./main.go:7:9: assignment copies lock value to wg2: sync.WaitGroup contains sync.noCopy
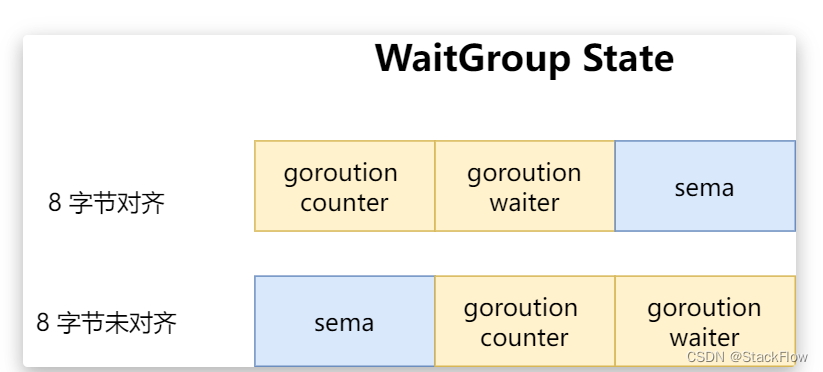
state1 的设计非常巧妙,这是一个是十二字节的数据,这里面主要包含两大块,counter 占用了 8 字节用于计数,sema 占用 4 字节用做信号量
可以看出 state1 是一个元素个数为 3 个数组,且每个元素都是 占 32 bits
在 64 位系统里面,64位原子操作需要64位对齐
那么高位的 32 bits 对应的是 counter 计数器,用来表示目前还没有完成任务的协程个数
低 32 bits 对应的是 waiter 的数量,表示目前已经调用了 WaitGroup.Wait 的协程个数
那么剩下的一个 32 bits 就是 sema 信号量的了(后面的源码中会有体现)
为什么要这么搞呢?直接用两个字段一个表示 counter,一个表示 sema 不行么?
不行,我们看看注释里面怎么写的。
// 64-bit value: high 32 bits are counter, low 32 bits are waiter count. > // 64-bit atomic operations require 64-bit alignment, but 32-bit > // compilers do not ensure it. So we allocate 12 bytes and then use > // the aligned 8 bytes in them as state, and the other 4 as storage > // for the sema.
这段话的关键点在于,在做 64 位的原子操作的时候必须要保证 64 位(8 字节)对齐,如果没有对齐的就会有问题,但是 32 位的编译器并不能保证 64 位对齐所以这里用一个 12 字节的 state1 字段来存储这两个状态,然后根据是否 8 字节对齐选择不同的保存方式。
此处我们可以看到 , state 函数是 返回存储在 wg.state1 中的状态和 sema字段 的指针
这里需要重点注意 state() 函数的实现,有 2 种情况
第 1 种 情况是,在 64 位系统下面,返回 sema字段 的指针取的是 &wg.state1[2] ,说明 64 位系统时,state1 数据排布是 : counter , waiter,sema
第 2 种情况是,32 位系统下面,返回 sema字段 的指针取的是 &wg.state1[0] ,说明 64 位系统时,state1 数据排布是 : sema ,counter , waiter
在 32 位机器上,uint64 类型的变量通常会被编译器按照 4 字节对齐,而不是 8 字节对齐。因此,如果 uint64
类型的变量没有按照 4 字节对齐,就可能会导致原子操作失败。在 32 位机器上,64 位原子操作需要使用两个 32 位的寄存器来完成,如果 uint64 类型的变量没有按照 4字节对齐,那么在读取或者写入 uint64 类型变量时,就可能会跨越两个 32位寄存器,从而导致原子操作失败。这种情况下,编译器可能会将多个 32 位读写操作组合成一个 64 位操作,或者使用特殊的汇编指令来实现原子性,但这样会增加代码的复杂度和性能开销。
为了避免这种问题,sync.WaitGroup 在 32 位机器上使用了一个包含 3 个 uint32
元素的数组来表示状态,其中前两个元素占用了 8 字节,可以按照 uint64 对齐,从而可以使用 64
位原子操作来保证状态的原子性。这种设计方式既可以在 32 位机器上保证状态的原子性,也可以在 64 位机器上提高程序的性能。
这个操作巧妙在哪里呢?
- 如果是 64 位的机器那肯定是 8 字节对齐了的,所以是上面第一种方式
- 如果在 32 位的机器上
- 如果恰好 8 字节对齐了,那么也是第一种方式取前面的 8 字节数据
- 如果是没有对齐,但是 32 位 4 字节是对齐了的,所以我们只需要后移四个字节,那么就 8 字节对齐了,所以是第二种方式
所以通过 sema 信号量这四个字节的位置不同,保证了 counter 这个字段无论在 32 位还是 64 为机器上都是 8 字节对齐的,后续做 64 位原子操作的时候就没问题了。
这个实现是在 state 方法实现的
golang 这样用,主要原因是 golang 把 counter 和 waiter 合并到一起统一看成是 1 个 64位的数据了,因此在不同的操作系统中
由于字节对齐的原因,64位系统时,前面 2 个 32 位数据加起来,正好是 64 位,正好对齐
对于 32 位系统,则是 第 1 个 32 位数据放 sema 更加合适,后面的 2 个 32 位数据就可以统一取出,作为一个 64 位变量
为什么要counter和waiter合一起?不能用三个变量吗
- 在并发编程中,多个 goroutine可能会同时访问共享的变量,这种并发访问可能会导致竞态条件,从而导致程序出现意料之外的结果。为了保证并发程序的正确性,需要使用同步原语来协调不同
- 首先,sync.WaitGroup 的状态包含两个值:计数器和等待的 goroutine 数量。在并发程序中,对于这两个值的修改必须是原子的,否则会导致竞态条件。如果使用两个单独的 uint32 变量来表示这两个值,那么在对它们进行增减操作时,必须使用互斥锁或原子操作来保证它们的原子性。而使用一个 uint32 数组,则可以使用原子操作来同时修改这两个值,从而避免了互斥锁的开销。
- goroutine 的访问,其中原子操作是一种常用的同步原语。
原子操作是一种基本的操作,它可以在一个步骤内完成读取和修改操作,从而保证了操作的原子性。在 Go 中,原子操作主要通过
sync/atomic 包提供。sync/atomic 包提供了一系列原子操作,包括原子读写、原子增减、原子比较交换等等。这些原子操作可以被多个 goroutine
并发调用,而不会导致竞态条件。在底层实现上,sync/atomic 包使用了 CPU 提供的原子指令,通过锁总线或者其他硬件机制来保证多个
CPU 同时访问一个共享变量时的原子性。
func (wg *WaitGroup) state() (statep *uint64, semap *uint32) {if uintptr(unsafe.Pointer(&wg.state1))%8 == 0 {return (*uint64)(unsafe.Pointer(&wg.state1)), &wg.state1[2]} else {return (*uint64)(unsafe.Pointer(&wg.state1[1])), &wg.state1[0]}
}
state 方法返回 counter 和信号量,通过 uintptr(unsafe.Pointer(&wg.state1))%8 == 0 来判断是否 8 字节对齐
Add
func (wg *WaitGroup) Add(delta int) {// 先从 state 当中把数据和信号量取出来statep, semap := wg.state()// 在 waiter 上加上 delta 值state := atomic.AddUint64(statep, uint64(delta)<<32)// 取出当前的 counterv := int32(state >> 32)// 取出当前的 waiter,正在等待 goroutine 数量w := uint32(state)// counter 不能为负数if v < 0 {panic("sync: negative WaitGroup counter")}// 这里属于防御性编程// w != 0 说明现在已经有 goroutine 在等待中,说明已经调用了 Wait() 方法// 这时候 delta > 0 && v == int32(delta) 说明在调用了 Wait() 方法之后又想加入新的等待者// 这种操作是不允许的if w != 0 && delta > 0 && v == int32(delta) {panic("sync: WaitGroup misuse: Add called concurrently with Wait")}// 如果当前没有人在等待就直接返回,并且 counter > 0if v > 0 || w == 0 {return}// 这里也是防御 主要避免并发调用 add 和 waitif *statep != state {panic("sync: WaitGroup misuse: Add called concurrently with Wait")}// 唤醒所有 waiter,看到这里就回答了上面的问题了*statep = 0for ; w != 0; w-- {runtime_Semrelease(semap, false, 0)}
}
Add 函数主要功能是将 counter +delta ,增加等待协程的个数:
我们可以看到 Add 函数,通过 state 函数获取到 上述 64位的变量(counter 和 waiter) 和 sema 信号量后,通过 atomic.AddUint64 函数 将 delta 数据 加到 counter 上面
这里为什么是 delta 要左移 32 位呢?
上面我们有说到嘛, state 函数拿出的 64 位变量,高 32 bits 是 counter,低 32 bits 是waiter,此处的 delta 是要加到 counter 上,因此才需要 delta 左移 32 位
Wait
wait 主要就是等待其他的 goroutine 完事之后唤醒
func (wg *WaitGroup) Wait() {// 先从 state 当中把数据和信号量的地址取出来statep, semap := wg.state()for {// 这里去除 counter 和 waiter 的数据state := atomic.LoadUint64(statep)v := int32(state >> 32)w := uint32(state)// counter = 0 说明没有在等的,直接返回就行if v == 0 {// Counter is 0, no need to wait.return}// waiter + 1,调用一次就多一个等待者,然后休眠当前 goroutine 等待被唤醒if atomic.CompareAndSwapUint64(statep, state, state+1) {runtime_Semacquire(semap)if *statep != 0 {panic("sync: WaitGroup is reused before previous Wait has returned")}return}}
}
Done
这个只是 add 的简单封装
func (wg *WaitGroup) Done() {wg.Add(-1)
}
总结
WaitGroup可以用于一个 goroutine 等待多个 goroutine 干活完成,也可以多个 goroutine 等待一个 goroutine 干活完成,是一个多对多的关系- 多个等待一个的典型案例是 singleflight,这个在后面将微服务可用性的时候还会再讲到,感兴趣可以看看源码
Add(n>0)方法应该在启动 goroutine 之前调用,然后在 goroution 内部调用Done方法WaitGroup必须在Wait方法返回之后才能再次使用Done只是Add的简单封装,所以实际上是可以通过一次加一个比较大的值减少调用,或者达到快速唤醒的目的。
相关文章:
golang waitgroup
案例 WaitGroup 可以解决一个 goroutine 等待多个 goroutine 同时结束的场景,这个比较常见的场景就是例如 后端 worker 启动了多个消费者干活,还有爬虫并发爬取数据,多线程下载等等。 我们这里模拟一个 worker 的例子 package mainimport (…...

单列模式多学两遍
单例模式 单例模式(Singleton Pattern,也称为单件模式),使用最广泛的设计模式之一。其意图是保证一个类仅有一个实例,并提供一个访问它的全局访问点,该实例被所有程序模块共享。 定义单例类 ● 私有化它的构造函数,…...
Spring Cloud【SkyWalking网络钩子Webhooks、SkyWalking钉钉告警、SkyWalking邮件告警】(十六)
目录 分布式请求链路追踪_SkyWalking网络钩子Webhooks 分布式请求链路追踪_SkyWalking钉钉告警 分布式请求链路追踪_SkyWalking邮件告警 分布式请求链路追踪_SkyWalking网络钩子Webhooks Wbhooks网络钩子 Webhok可以简单理解为是一种Web层面的回调机制。告警就是一个事件&a…...
【力扣每日一题】2023.7.25 将数组和减半的最少操作次数
目录 题目: 示例: 分析: 代码运行结果: 题目: 示例: 分析: 题目给我们一个数组,我们每次可以将任意一个元素减半,问我们操作几次之后才可以将整个数组的和减半&…...

Docker-Compose 轻松搭建 Grafana+InfluxDb 实用 Jmeter 监控面板
目录 前言: 1、背景 2、GranfanaInfluxDB 配置 2.1 服务搭建 2.2 配置 Grafana 数据源 2.3 配置 Grafana 面板 3、Jmeter 配置 3.1 配置 InfluxDB 监听器 3.2 实际效果 前言: Grafana 和 InfluxDB 是两个非常流行的监控工具,它们可…...
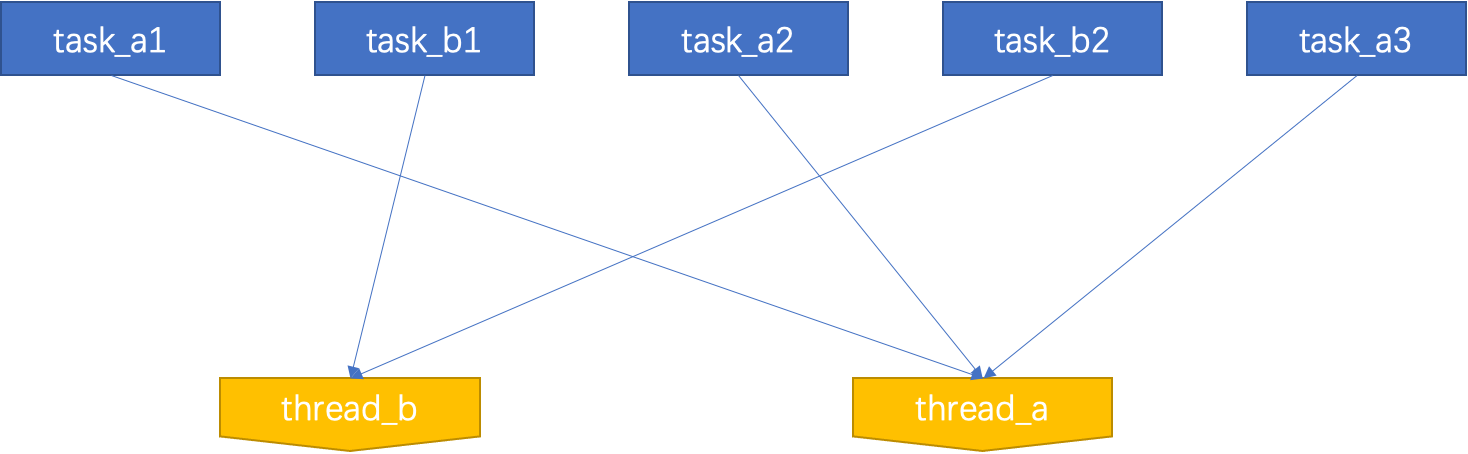
异构线程池的c++实现方案
概要 通常线程池是同质的,每个线程都可以执行任意的task(每个线程中的task顺序执行),如下图所示: 但本文所介绍的线程和task之间有绑定关系,如A task只能跑在A thread上(因此称为异构线程池&am…...
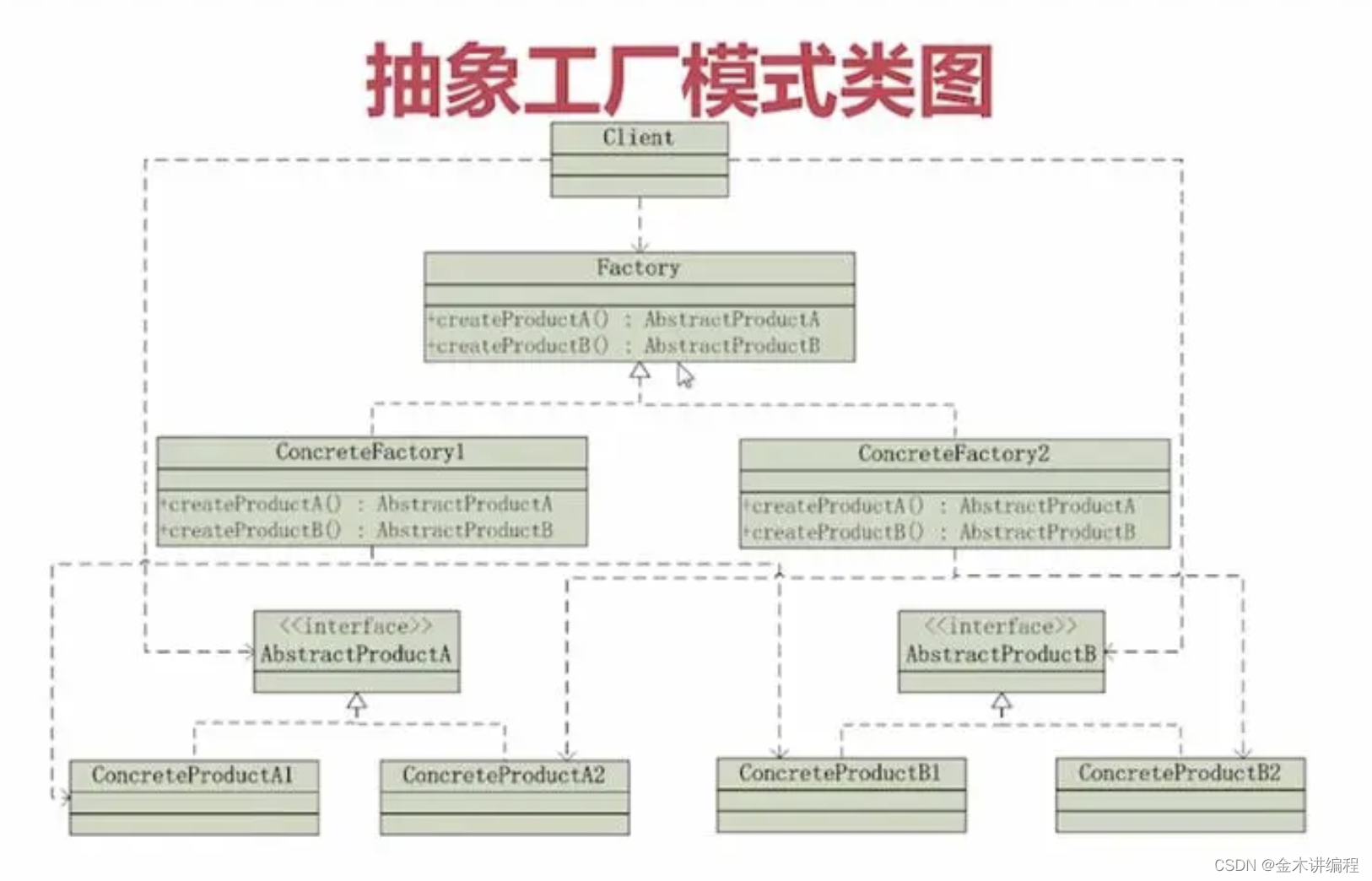
Python实现抽象工厂模式
抽象工厂模式是一种创建型设计模式,用于创建一系列相关或依赖对象的家族,而无需指定具体类。在Python中,可以通过类和接口的组合来实现抽象工厂模式。 下面是一个简单的Python实现抽象工厂模式的示例: # 抽象产品接口 class Abs…...

@vue/cli安装
vue/cli安装 1、全局安装vue/cli包2、查看是否成功 1、全局安装vue/cli包 yarn global add vue/cli2、查看是否成功 vue -V...

用友全版本任意文件上传漏洞复现
声明 本文仅用于技术交流,请勿用于非法用途 由于传播、利用此文所提供的信息而造成的任何直接或者间接的后果及损失,均由使用者本人负责,文章作者不为此承担任何责任。 文章作者拥有对此文章的修改和解释权。如欲转载或传播此文章,…...

程序员面试系列,MySQL常见面试题?
原文链接 一、索引相关的面试题 (1)索引失效的情况有哪些 在MySQL查询时,以下情况可能会导致索引失效,无法使用索引进行高效的查询: 数据类型不匹配:如果查询条件中的数据类型与索引列的数据类型不匹配&…...
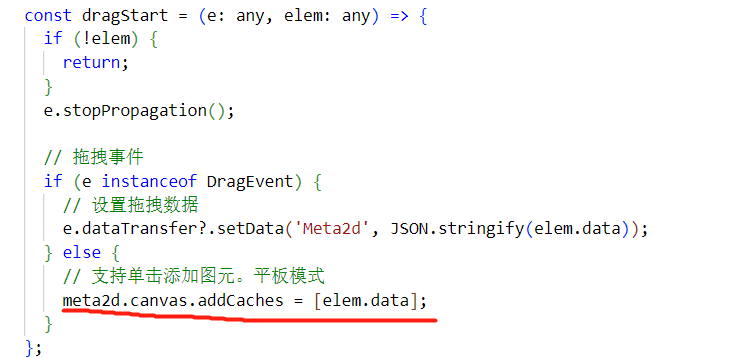
前端Web实战:从零打造一个类Visio的流程图拓扑图绘图工具
前言 大家好,本系列从Web前端实战的角度,给大家分享介绍如何从零打造一个自己专属的绘图工具,实现流程图、拓扑图、脑图等类Visio的绘图工具。 你将收获 免费好用、专属自己的绘图工具前端项目实战学习如何从0搭建一个前端项目等基础框架项…...

2023牛客暑期多校第二场部分题解
索引 ABCDEFGHIK A 队友开的题,说是其实就是问能不能用若干个数异或出来某个数。 应该就是线性基板子,然后他写了一下就过了。 B 一开始看没什么人过不是很敢开,结果到后面一看题——这不是最大权闭合子图板子吗??…...
20230724将真我Realme手机GT NEO3连接到WIN10的电脑的步骤
20230724将真我Realme手机GT NEO3连接到WIN10的电脑的步骤 2023/7/24 23:23 缘起:因为找使用IMX766的手机,找到Realme手机GT NEO3了。 同样使用IMX766的还有:Redmi Note12Pro 5G IMX766 旗舰影像 OIS光学防抖 OLED柔性直屏 8GB256GB时光蓝 现…...
黑马 pink h5+css3+移动端前端
网页概念 网页是网站的一页,网页有很多元素组成,包括视频图片文字视频链接等等,以.htm和.html后缀结尾,俗称html文件 HTML 超文本标记语言,描述网页语言,不是编程语言,是标记语言,有标签组成 超文本指的是不光文本,还有图片视频等等标签 常用浏览器 firefox google safari…...

Docker的七项优秀实践
众所周知,作为一个文本文档,Dockerfile包含了用户创建镜像的所有命令和说明。Docker可以通过读取Dockerfile中指令的方式,去自动构建镜像。因此,大家往往认为编写Dockerfile理应非常简单,只需从互联网上选择一个示例&a…...

【数据结构】24王道考研笔记——图
六、图 目录 六、图定义及基本术语图的定义有向图以及无向图简单图以及多重图度顶点-顶点间关系连通图、强连通图子图连通分量强连通分量生成树生成森林边的权、带权网/图特殊形态的图 图的存储及基本操作邻接矩阵邻接表法十字链表邻接多重表分析对比图的基本操作 图的遍历广度…...
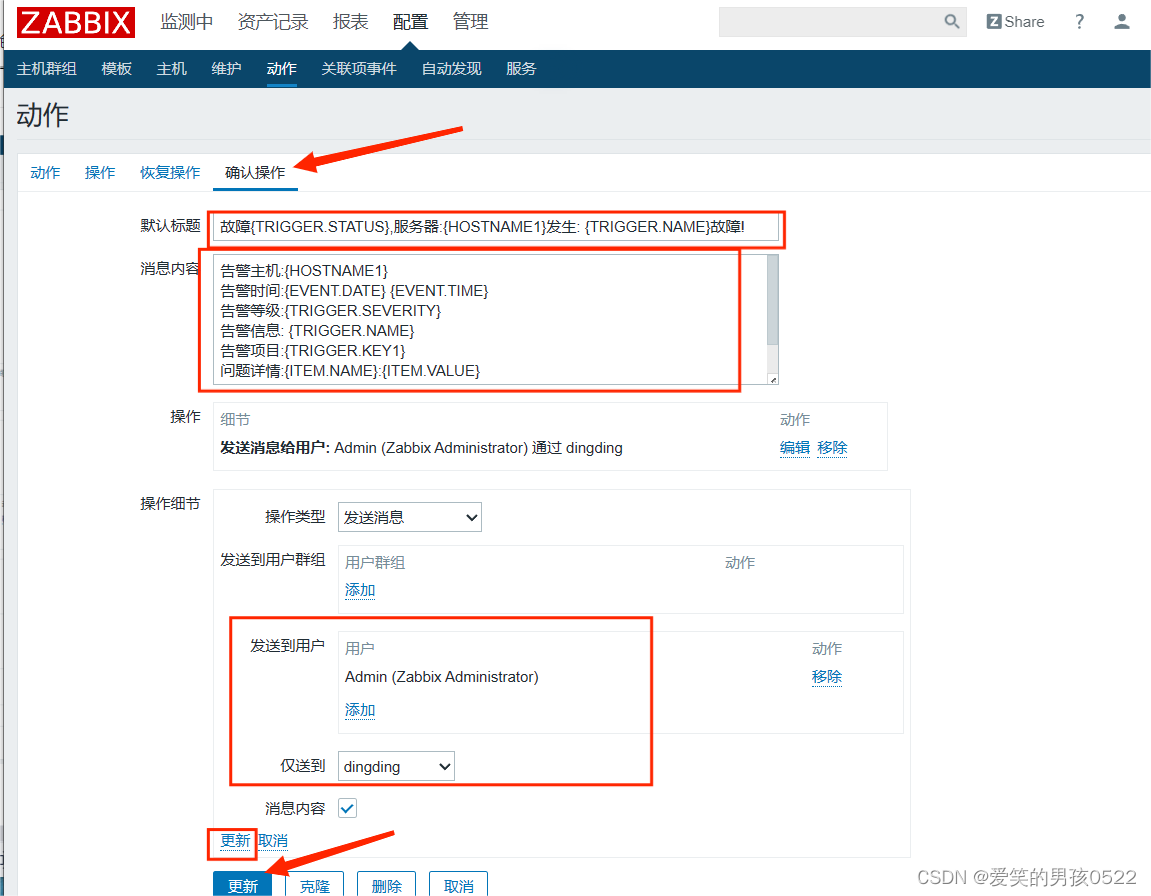
zabbix钉钉报警
登录钉钉客户端,创建一个群,把需要收到报警信息的人员都拉到这个群内. 然后点击群右上角 的"群机器人"->"添加机器人"->"自定义", 记录该机器人的webhook值。 添加机器人 在钉钉群中,找到只能群助手 添加机器人 选择自定义机…...
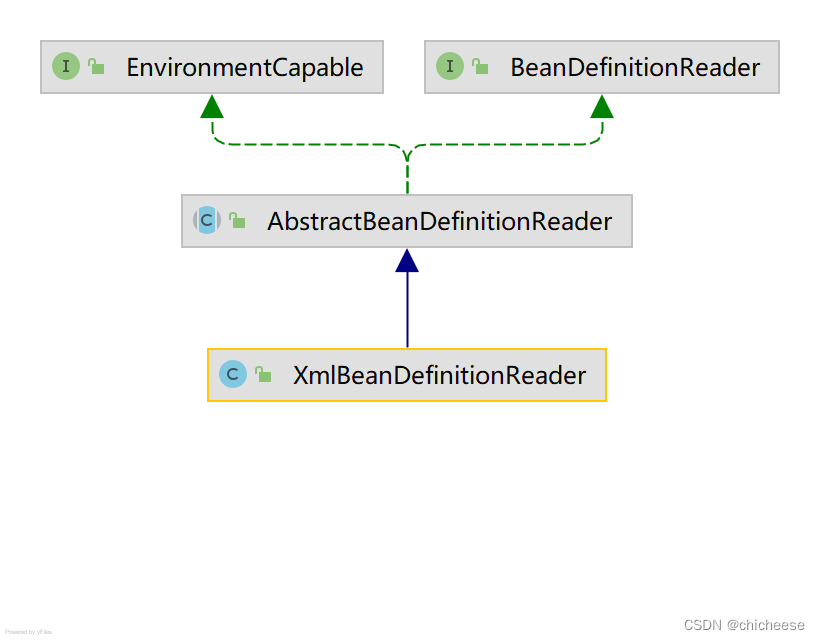
Spring 源码解读
1、Spring 的结构组成 1.1、核心类介绍 Spring 中有两个最核心的类 1 DefaultListableBeanFactory XmlBeanFactory 继承自 DefaultListableBeanFactory,而DefaultListableBeanFactory 是整个 bean加载的核心部分,是 Spring 注册及加载 bean 的默认实现…...
练习时长两年半的网络安全防御“first”
1.网络安全常识及术语 下边基于这次攻击演示我们介绍一下网络安全的一些常识和术语。 资产 任何对组织业务具有价值的信息资产,包括计算机硬件、通信设施、 IT 环境、数据库、软件、文档资料、信息服务和人员等。 网络安全 网络安全是指网络系统的硬件、软件及…...

HttpRunner自动化测试之响应中文乱码处理
响应中文乱码: 当调用接口,响应正文返回的中文是乱码时,一般是响应正文的编码格式不为 utf-8 导致,此时需要根据实际的编码格式处理 示例: 图1中 extract 提取title标题,output 输出 title 变量值&#x…...

ESP8266高速移位寄存器驱动库:3.8μs级GPIO直控
1. FastEsp8266ShiftRegister 库概述FastEsp8266ShiftRegister 是一款专为 ESP8266 微控制器深度优化的高速移位寄存器驱动库。其核心设计目标是突破传统软件模拟 SPI 或标准 GPIO 操作在 ESP8266 上的性能瓶颈,实现接近硬件 SPI 时序精度、但具备更高灵活性的并行/…...

技术深度解析:Fritzing电路仿真与自动布线实现原理
技术深度解析:Fritzing电路仿真与自动布线实现原理 【免费下载链接】fritzing-app Fritzing desktop application 项目地址: https://gitcode.com/gh_mirrors/fr/fritzing-app Fritzing作为一款开源的电子设计自动化工具,其核心价值在于将复杂的电…...

ESP8266轻量Web服务器库myWebServerESP深度解析
1. myWebServerESP:面向ESP8266/NODEMCU的轻量级嵌入式Web服务器库深度解析1.1 项目定位与工程价值myWebServerESP是一个专为 ESP8266 系列芯片(含 NodeMCU 开发板)设计的轻量级、可配置 Web 服务框架,运行于 Arduino IDE 生态下。…...

ESP32高精度低延迟ADC自定义库:寄存器级模拟读取优化
1. 项目概述ESP32AnalogRead Custom是由嵌入式开发者 Khrisna Ijlal Bachri 针对 ESP32 系列微控制器定制优化的模拟输入读取库。该库并非官方 ESP-IDF ADC 驱动的简单封装,而是聚焦于解决实际工程中高频采样、多通道同步、噪声抑制与低功耗场景下的典型痛点。其核心…...

C++动态内存/内存管理
文章目录 前言 一、内存分区 二、C 语言动态内存(标准库函数) 1.核心函数 2.代码示例 3.关键注意点 三、C 动态内存(关键字 / 操作符) 1.核心用法 (1)单个对象 (2)数组对象…...

UE5 GAS调试技巧:巧用ASC的‘Attribute Test’面板,5分钟搞定角色属性配置与验证
UE5 GAS高效调试指南:利用Attribute Test面板快速验证角色属性配置 在虚幻引擎5的游戏开发中,Gameplay Ability System (GAS)作为构建复杂角色能力与属性的核心框架,其调试效率直接影响着RPG类项目的开发进度。本文将深入探讨如何利用Ability…...

AI_NovelGenerator:如何在7天内完成传统写作需要3个月的长篇小说创作
AI_NovelGenerator:如何在7天内完成传统写作需要3个月的长篇小说创作 【免费下载链接】AI_NovelGenerator 使用ai生成多章节的长篇小说,自动衔接上下文、伏笔 项目地址: https://gitcode.com/GitHub_Trending/ai/AI_NovelGenerator 问题诊断&…...

别再只用Billboard了!用Cesium Entity实现高性能动态告警点的3个优化技巧
突破性能瓶颈:Cesium Entity动态告警点的高阶优化实战 当三维场景中需要同时呈现数百个闪烁的告警点时,许多开发者会发现原本流畅的界面开始变得卡顿。这不是Cesium的局限性,而是我们可能还没有完全掌握其性能优化的精髓。本文将带您深入探索…...
)
告别Moom!用Hammerspoon实现Mac窗口精准控制(附完整快捷键表+配置文件)
用Hammerspoon打造Mac高效工作流:从窗口管理到自动化脚本 每次看到同事花十几秒拖动窗口调整大小,或者在不同显示器间来回切换应用时,我总忍不住想分享这个改变我工作效率的神器。Hammerspoon——这个完全免费的开源工具,让我彻底…...

避开RK3568 MPP开发的那些坑:V4L2缓冲区管理与实时码流稳定性优化实战
RK3568 MPP开发实战:V4L2缓冲区管理与码流稳定性优化指南 在嵌入式视频处理领域,RK3568凭借其强大的多媒体处理能力成为中高端项目的首选方案。但当我们真正将其应用于工业视觉、安防监控等对稳定性要求严苛的场景时,开发者常常会遇到令人头疼…...