我在VScode学Python(Python函数,Python模块导入)
我的个人博客主页:如果’'真能转义1️⃣说1️⃣的博客主页
(1)关于Python基本语法学习---->可以参考我的这篇博客《我在VScode学Python》
(2)pip是必须的在我们学习python这门语言的过程中Python ---->> PiP 的重要性
本篇补充《我在VScode学Python》的内容
文章目录
- Py函数
- Chat:
- 解题【找出列表中满足条件的所有成员组合及其对应的下标组合】:
- 代码
- Py函数的定义
- Py函数怎么调用
- 嵌套调用
- 在使用Python函数时,有一些注意事项需要注意:
- Python函数的参数调用有以下几种方式:
- 注意:
- 返回值【函数在执行完成后,返回给调用者的结果】
- None的价值:【一个特殊的字面量,其类型是:<class NoneType'>。无返回值的函数,实际上就是返回了: None这个字面量】
- 代码:
- 多个返回值:
- python参数的使用方式有哪几种:
- 1. 位置参数(Positional Arguments):这是最常见的参数传递方式。当你调用一个函数时,按照函数定义的顺序,将参数依次传递给函数。例如:
- 2. 关键字参数【键--值】(Keyword Arguments):在函数调用时,通过指定参数名和值的方式传递参数。==这样可以不用按照顺序传递参数,提高了代码的可读性。==例如:
- 使用关键字传参可以不按照固定顺序传递参数,使得函数调用更加灵活和清晰的代码举例:
- 3. 默认参数(Default Arguments):在定义函数时,可以为某些参数指定默认值。如果在函数调用时未提供这些参数的值,将使用默认值。例如:
- 4. 可变长参数:Python中有两种可变长参数,分别是:
- 5 缺省参数(Default Arguments):
- 6 不定长参数(可变长参数):
- 当涉及到不定长参数,Python提供了两种方式:不定位置参数(*args)和不定关键字参数(**kwargs)。
- 匿名函数(lambda函数):
- 匿名函数和普通的定义的对比:
- Python模块
- 模块的导入方式
- 对比:
- 1和3
- 在模块导入的速度方面,通常情况下,第2种导入方式(`from 模块名 import 类、变量、方法等`)会比第3种方式(`from 模块名 import *`)更快。
- 整体分析优缺点;
- 自定义模块:
- 以下是一个自定义模块的示例:
- 注意事项:
- 要避免这种情况,可以采用以下方法:
- __main__变量:
- __all__:
- python包怎么导入:
Py函数
def user_info(name, age, gender="未知"):print(f"您的名字是: {name},年龄是: {age},性别是: {gender}")
print(type(user_info))

函数是一段可重用的代码块,用于执行特定的任务或完成特定的操作。函数可以接收输入参数,对其进行处理,并返回输出结果。
函数是模块化编程的重要概念,它可以将复杂的程序拆分成多个小的、独立的部分,每个部分都完成自己的工作。函数可以提高代码的可读性、可维护性和可重用性。
在Python中,函数是一类对象,可以传递给其他函数、嵌套在其他函数中、赋值给变量等。Python中的函数还支持默认参数、可变参数、关键字参数等高级特性,可以更灵活地满足不同的需求。
Chat:
在Python中,函数是一等公民(First-class Citizens),这意味着函数可以像其他数据类型(整数、字符串、列表等)一样,作为参数传递给其他函数。将函数作为参数传递给其他函数,是一种常见的函数式编程技巧,它使得代码更加灵活、模块化,能够更好地支持抽象和重用。
让我们通过一个例子来说明函数作为参数传递的概念。假设我们有一个函数apply_operation,它接受两个参数:一个操作函数和两个操作数,并将这两个操作数传递给操作函数进行处理。
def add(x, y):return x + ydef subtract(x, y):return x - ydef apply_operation(operation, x, y):return operation(x, y)result_add = apply_operation(add, 3, 5)
result_subtract = apply_operation(subtract, 8, 3)print(result_add) # Output: 8 (3 + 5)
print(result_subtract) # Output: 5 (8 - 3)
在这个例子中,我们定义了两个函数add和subtract,它们分别执行加法和减法操作。然后,我们定义了一个函数apply_operation,该函数接受一个操作函数和两个操作数,然后调用操作函数将这两个操作数传递给它,并返回操作的结果。
在调用apply_operation函数时,我们将add和subtract函数作为参数传递给了apply_operation函数。这样,apply_operation函数可以根据传入的操作函数来执行不同的操作,实现了一种策略模式(Strategy Pattern)的应用。
通过将函数作为参数传递,我们可以在不修改apply_operation函数的情况下,通过不同的操作函数来实现不同的行为。这种技巧可以让我们的代码更加灵活,降低代码的重复性,提高代码的可读性和维护性。
解题【找出列表中满足条件的所有成员组合及其对应的下标组合】:
找出列表中满足条件的所有成员组合及其对应的下标组合:
输入: nums = [2,2,7,6,1,7,3,6,2,3],target = 9输出:
所有成员组合:[(2,7),(2,7),(2,7),(2,7),(7,2),(6,3),(6,3),(7,2),(3,6),(6,3)]
成员下标组合:[(0,2),(0,5),(1,2),(1,5),(2,8),(3,6),(3,9),(5,8),(6,7).(7,9)]
解释:满足条件的两两成员进行组合
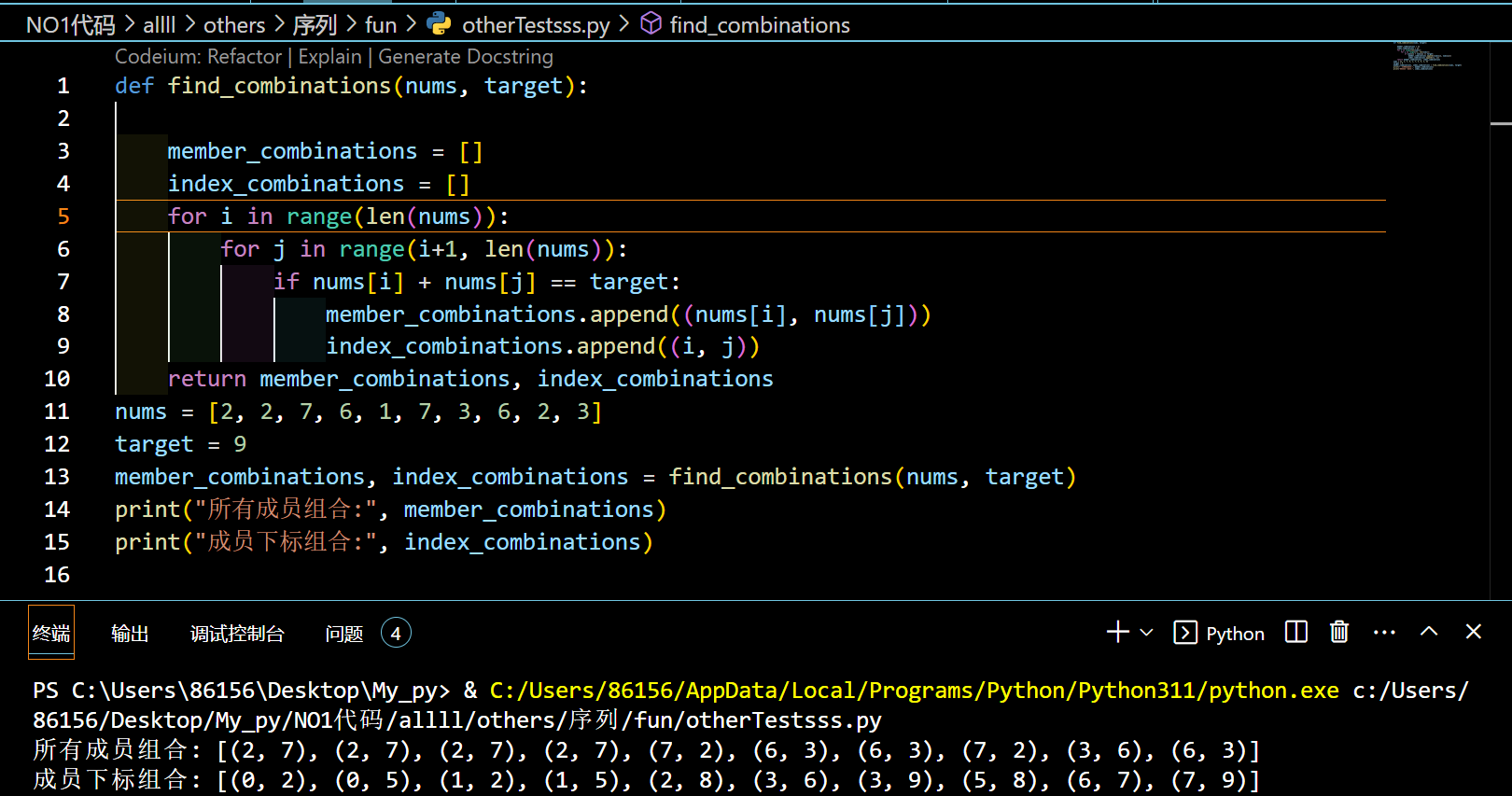
代码
def find_combinations(nums, target):member_combinations = []index_combinations = []for i in range(len(nums)):for j in range(i+1, len(nums)):if nums[i] + nums[j] == target:member_combinations.append((nums[i], nums[j]))index_combinations.append((i, j))return member_combinations, index_combinations
nums = [2, 2, 7, 6, 1, 7, 3, 6, 2, 3]
target = 9
member_combinations, index_combinations = find_combinations(nums, target)
print("所有成员组合:", member_combinations)
print("成员下标组合:", index_combinations)
Py函数的定义
Python的函数定义格式如下:
def function_name(parameters):"""docstring"""# function bodyreturn [expression]
其中,def关键字用来定义函数,function_name是函数名,parameters是函数的参数列表(可以为空),用圆括号括起来。
函数体开始的字符串是文档字符串,用于描述函数的作用和用法,可选项。函数体中包含了函数的主要逻辑。return语句用于返回函数的结果(可以为空)。
Py函数怎么调用
在Python中,调用函数需要使用函数名和一对括号,括号中可以传递参数。例如,我们有一个求和函数:
def add(x, y):return x + y
我们可以通过以下方式调用这个函数:
result = add(3, 5)
print(result) # 输出8
在调用函数时,需要将参数传递给函数。在上面的例子中,我们将3和5作为参数传递给add函数,然后将函数的返回值赋值给变量result,并输出结果。
如果函数返回None,我们可以直接调用函数而不对其返回值进行任何操作,例如:
def print_hello():print("Hello")print_hello() # 输出Hello
在调用函数时,不要忘记将参数传递给函数,并将函数的返回值存储在需要的变量中,以便进一步处理。
嵌套调用
函数的嵌套调用是指在一个函数的执行过程中,调用了另一个函数。具体实现可以在函数的代码中,直接在需要调用的函数后添加括号,并将需要传递给该函数的参数作为括号中的参数传递进去。例如:
def function_a(x):result = x * 2return resultdef function_b(y):result = y + 1return resultdef function_c(z):result_a = function_a(z)result_b = function_b(result_a)return result_bprint(function_c(3)) # 输出结果为 7
在上面的代码中,函数 function_c 调用了函数 function_a 和函数 function_b,并将其中一个函数的返回值作为另一个函数的参数传递进去,最终返回了 function_b 的结果。这种方式可以使程序的结构更加清晰,逻辑更加简单,也可以增加代码的复用性。
在使用Python函数时,有一些注意事项需要注意:
-
函数名不能与Python内置函数或关键字相同。如果名字相同会导致程序运行出错。
-
在函数定义中,参数名应该具有描述性,而且应该具有一致的命名约定。例如,如果函数接收一个字符串参数,参数名应该以“str”结尾。
-
函数的参数传递可以是位置参数(按照定义顺序传递)或关键字参数(使用参数名传递),但是一旦使用关键字参数,后续的所有参数都必须使用关键字参数。
-
在函数定义中,如果一个参数有一个默认值,那么它必须是最后一个参数。否则,会导致错误。
-
Python中的函数可以返回多个值,这些值将作为元组返回。
-
函数内部执行完毕之后,局部变量会被自动销毁。如果需要在函数之间共享变量,可以将变量定义为全局变量。
-
函数应该尽可能地简洁明了,只做一件事情并确保它做得很好。
-
函数应该被文档化,以便用户更好地了解它们的特性和使用方法。可以使用函数注释来描述函数的输入和输出参数,以及函数的目的和行为。
-
在Python中,函数可以嵌套定义,即一个函数可以在另一个函数内定义。嵌套函数可以访问父函数的变量和参数。
Python函数的参数调用有以下几种方式:
- 位置参数:按照函数定义的顺序将参数传递给函数即可。例如:
def greet(name, message):print(message, name)greet('Alice', 'Hello') # 输出:Hello Alice
- 关键字参数:使用参数名来指定传递的参数值。例如:
def greet(name, message):print(message, name)greet(message='Hello', name='Alice') # 输出:Hello Alice
- 默认参数:在函数定义中指定一个默认参数值。如果在函数调用中未提供该参数,将使用默认值。例如:
def greet(name, message='Hello'):print(message, name)greet('Alice') # 输出:Hello Alice
greet('Alice', 'Hi') # 输出:Hi Alice
- 可变参数:在函数定义中使用
*args可以接受任意数量的位置参数,并将它们放入一个元组中。例如:
def greet(*names):for name in names:print('Hello', name)greet('Alice', 'Bob', 'Charlie') # 输出:Hello Alice,Hello Bob,Hello Charlie
- 关键字可变参数:在函数定义中使用
**kwargs可以接受任意数量的关键字参数,并将它们放入一个字典中。例如:
def greet(**kwargs):for name, message in kwargs.items():print(message, name)greet(Alice='Hello', Bob='Hi', Charlie='Hey') # 输出:Hello Alice,Hi Bob,Hey Charlie
需要注意的是,参数的调用方式必须与函数定义中的顺序或名称一致,并且参数的数量必须与函数定义中一致。
注意:
函数定义时的参数被称为形式参数,因为它们只存在于函数的定义中,用于表示在函数调用时需要传入的参数的类型和数量。形式参数通常作为函数签名的一部分,在函数定义中指定。
函数调用时传递给函数的参数被称为实际参数。实际参数的数量和类型必须与函数定义中的形式参数匹配,否则会导致编译错误。
在Python中,函数的参数数量不限,使用逗号分隔开。当调用函数时,要将传入的实际参数与形式参数一一对应,逗号隔开它们。如果函数有多个参数,则必须按照函数定义中参数的顺序传递参数。例如,如果函数定义为def my_function(a, b, c):,则函数调用应该是my_function(value_for_a, value_for_b, value_for_c),其中value_for_a、value_for_b和value_for_c是传递给函数的实际参数。
返回值【函数在执行完成后,返回给调用者的结果】
函数体在遇到return后就结束了,所以写在return后的代码不会执行。
Python函数的返回值是指函数执行完毕后所返回的结果。在函数体内,可以使用关键字return来指定函数的返回值。当调用函数时,函数会执行其中的代码,并将return语句后面的表达式计算出的值作为返回值返回给调用者。如果函数没有明确指定return语句,或者return语句没有指定返回值,则默认返回None。对于有返回值的函数,调用者可以接收并使用该返回值进行后续操作。
None的价值:【一个特殊的字面量,其类型是:<class NoneType’>。无返回值的函数,实际上就是返回了: None这个字面量】
定义变量,但暂时不需要变量有具体值,可以用None来代替
None在Python中是一个特殊的对象,表示空值或缺失值。它通常用作函数没有明确返回值时默认的返回值。
None具有以下用途和价值:
-
表示函数没有返回值:当函数没有指定
return语句或者return语句没有指定返回值时,默认返回None。这可以告诉调用者函数执行完毕并且没有返回任何结果。 -
初始化变量:可以将变量初始化为
None,表示该变量当前没有具体的值。后续可以根据需要给变量赋予其他的值。 -
判断条件:
None可以用于条件判断,例如检查一个变量是否为None来确定是否有有效的值。 -
默认参数值:函数定义时可以指定参数的默认值,常见的默认值就是
None。这样在调用函数时如果没有提供相应的参数,就会使用默认值None。 -
占位符:在开发中,有时候需要先声明一个变量或占位符,但还没有具体的值或计算结果。这时可以使用
None来表示,避免出现错误或异常。
总之,None是在Python中用来表示缺失值、空值或未定义状态的特殊对象,具有一定的实用价值。
代码:
当一个函数没有明确的返回值时,它会默认返回`None`。以下是一个简单的例子:```python
def greet(name):print("Hello, " + name)result = greet("Alice")
print(result)
输出:
Hello, Alice
None
在上面的例子中,greet函数接受一个参数 name,并打印出问候语。但函数没有指定返回值,因此默认返回None。在调用greet("Alice")后,会打印出Hello, Alice,然后将返回值赋给变量result。最后,通过打印result可以看到它的值为None。这表明函数执行完毕后没有返回具体的结果。
请注意,None是Python中的一个常量,表示空值,通常用于表示一个不存在或无效的情况。
多个返回值:
python如何接受多个返回值、
要在Python中接受多个返回值,可以使用元组(tuple)的方式。当函数返回多个值时,可以将这些值封装在一个元组中,并通过解包的方式将其赋值给多个变量。
def get_values():return 1, 2, 3a, b, c = get_values()print(a) # 输出: 1
print(b) # 输出: 2
print(c) # 输出: 3
解包分别赋值给变量 a、b 和 c。最后,我们分别打印了这三个变量的值。
python参数的使用方式有哪几种:
在Python中,参数的使用方式有以下几种:
1. 位置参数(Positional Arguments):这是最常见的参数传递方式。当你调用一个函数时,按照函数定义的顺序,将参数依次传递给函数。例如:
一 一 对 应
def greet(name, greeting):print(f"{greeting}, {name}!")greet("John", "Hello") # Output: Hello, John!
2. 关键字参数【键–值】(Keyword Arguments):在函数调用时,通过指定参数名和值的方式传递参数。==这样可以不用按照顺序传递参数,提高了代码的可读性。==例如:
def greet(name, greeting):print(f"{greeting}, {name}!")greet(greeting="Hello", name="John") # Output: Hello, John!
使用关键字传参可以不按照固定顺序传递参数,使得函数调用更加灵活和清晰的代码举例:
使用缺省参数(Default Arguments)和关键字传参(Keyword Arguments)来实现更灵活的函数调用。这样可以使函数调用更加清晰、容易使用,并且消除了参数的顺序需求。
def user_info(name, age, gender="未知"):print(f"您的名字是: {name},年龄是: {age},性别是: {gender}")# 使用关键字传参,不需要按照固定顺序
user_info(name="小明", age=20, gender="男")# 也可以不指定性别参数,将使用缺省参数的默认值
user_info(name="小红", age=25)# 可以和位置参数混用,但位置参数必须在前,且匹配参数顺序
user_info("小刚", age=18, gender="男")
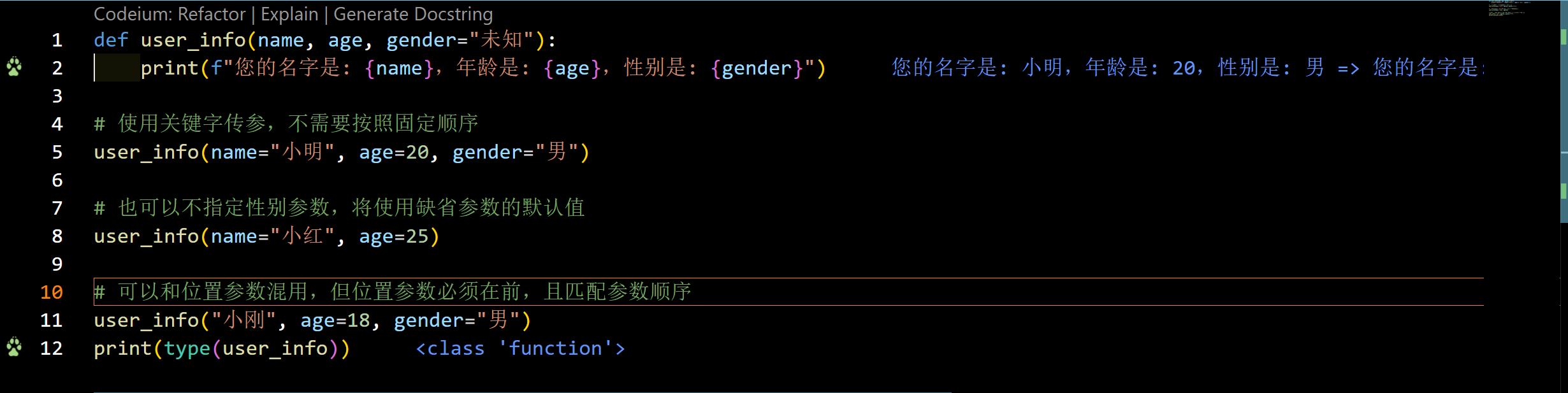
在这个示例中,我们为user_info函数的gender参数设置了默认值"未知"。这样在函数调用时,如果没有指定性别参数,就会使用默认值。同时,使用关键字传参可以不按照固定顺序传递参数,使得函数调用更加灵活和清晰。
请注意,当使用关键字传参时,必须将位置参数放在前面,并且按照函数定义的参数顺序进行匹配。这样既能利用关键字传参的灵活性,又能兼容位置参数的使用。
3. 默认参数(Default Arguments):在定义函数时,可以为某些参数指定默认值。如果在函数调用时未提供这些参数的值,将使用默认值。例如:
def greet(name, greeting="Hello"):print(f"{greeting}, {name}!")greet("John") # Output: Hello, John!
greet("Jane", "Hi") # Output: Hi, Jane!
4. 可变长参数:Python中有两种可变长参数,分别是:
- *args:用于接收任意数量的位置参数,它将参数打包成一个元组(tuple)。
- **kwargs:用于接收任意数量的关键字参数,它将参数打包成一个字典(dict)。
def sum_numbers(*args):total = 0for num in args:total += numreturn totalprint(sum_numbers(1, 2, 3, 4)) # Output: 10def print_info(**kwargs):for key, value in kwargs.items():print(f"{key}: {value}")print_info(name="John", age=30, city="New York")
# Output:
# name: John
# age: 30
# city: New York
5 缺省参数(Default Arguments):
缺省参数允许你在函数定义时为某些参数指定默认值,这样在函数调用时,如果没有提供相应参数的值,将会使用默认值。这样可以简化函数调用,同时给函数提供了更大的灵活性。在函数定义时,将希望具有默认值的参数放在参数列表的末尾。
def greet(name, greeting="Hello"):print(f"{greeting}, {name}!")greet("John") # Output: Hello, John! (默认使用"greeting"参数的默认值)
greet("Jane", "Hi") # Output: Hi, Jane! (使用指定的"greeting"参数值)
6 不定长参数(可变长参数):
不定长参数允许你定义能够接收任意数量参数的函数。在Python中,有两种不定长参数:
- *args:用于接收任意数量的位置参数,它将这些参数打包成一个元组(tuple)。
- **kwargs:用于接收任意数量的关键字参数,它将这些参数打包成一个字典(dict)。
使用不定长参数可以处理传递数量未知的参数,让函数更加灵活。在函数定义时,使用"*args"和"**kwargs"来声明不定长参数。
def sum_numbers(*args):total = 0for num in args:total += numreturn totalprint(sum_numbers(1, 2, 3, 4)) # Output: 10def print_info(**kwargs):for key, value in kwargs.items():print(f"{key}: {value}")print_info(name="John", age=30, city="New York")
# Output:
# name: John
# age: 30
# city: New York
在使用函数时,可以结合缺省参数和不定长参数,让函数调用更加简洁,并处理不同的参数传递情况。
当涉及到不定长参数,Python提供了两种方式:不定位置参数(*args)和不定关键字参数(**kwargs)。
-
不定位置参数(*args):
不定位置参数允许函数接受任意数量的位置参数,并将这些参数打包成一个元组(tuple)。在函数定义时,使用*args来声明不定位置参数。这样,在函数调用时,我们可以传递任意数量的位置参数给函数,它们将被自动打包成一个元组。def print_arguments(*args):for arg in args:print(arg)print_arguments("apple", "banana", "orange") # Output: # apple # banana # orange在这个例子中,
print_arguments函数接受不定数量的位置参数,并将这些参数打包成一个元组。在函数调用时,我们传递了三个位置参数,它们被打包成了一个元组进行输出。 -
不定关键字参数(**kwargs):
不定关键字参数允许函数接受任意数量的关键字参数,并将这些参数打包成一个字典(dict)。在函数定义时,使用**kwargs来声明不定关键字参数。在函数调用时,我们可以传递任意数量的关键字参数给函数,它们将被自动打包成一个字典。def print_info(**kwargs):for key, value in kwargs.items():print(f"{key}: {value}")print_info(name="John", age=30, city="New York") # Output: # name: John # age: 30 # city: New York在这个例子中,
print_info函数接受不定数量的关键字参数,并将这些参数打包成一个字典。在函数调用时,我们传递了三个关键字参数,它们被打包成了一个字典进行输出。 -
混合使用不定位置和不定关键字参数:
当函数需要同时接受任意数量的位置参数和关键字参数时,我们可以混合使用*args和**kwargs。def mixed_arguments(*args, **kwargs):print("Positional arguments:")for arg in args:print(arg)print("Keyword arguments:")for key, value in kwargs.items():print(f"{key}: {value}")mixed_arguments("apple", "banana", "orange", country="USA", city="New York") # Output: # Positional arguments: # apple # banana # orange # Keyword arguments: # country: USA # city: New York在这个例子中,
mixed_arguments函数接受不定数量的位置参数和关键字参数。它将位置参数打包成元组,并将关键字参数打包成字典,然后按照不同类型输出。
不定位置参数和不定关键字参数为我们提供了很大的灵活性,使得函数能够处理各种不同数量和类型的参数,从而更加通用和适用于各种场景。
匿名函数(lambda函数):
匿名函数是一种在编程中常用的简单函数形式,也称为lambda函数(lambda expressions)。它是一种用于创建小型、临时的、无需命名的函数的一种方式。与常规的函数定义(def语句)不同,匿名函数使用lambda关键字进行定义,通常在需要一个简单函数而又不想定义一个完整函数的情况下使用。
匿名函数的语法如下:
lambda arguments: expression
其中,arguments是函数参数列表,expression是函数体的简单表达式。匿名函数返回的是表达式的结果,没有显式的return语句。
以下是一个例子,使用匿名函数计算两个数的和:
add = lambda x, y: x + y
result = add(3, 5)
print(result) # Output: 8
在这个例子中,我们定义了一个匿名函数add,它接受两个参数x和y,并返回它们的和。然后,我们调用匿名函数add(3, 5),返回的结果为8。
匿名函数适用于那些只需短暂使用、较为简单的函数场景,由于其简洁性,常用于函数式编程或某些特定的场合。需要注意的是,匿名函数的使用应当遵循适当的场景和合适的规模,过于复杂或需要多行代码逻辑的情况,应当使用普通的命名函数(def语句)。
匿名函数和普通的定义的对比:
匿名函数(lambda函数)和普通函数(使用def语句定义的函数)是Python中两种不同的函数定义方式。它们在使用场景、语法和功能上有一些区别。让我们对它们进行对比:
-
语法:
- 普通函数:使用
def语句来定义,可以有函数名、参数列表和函数体。 - 匿名函数:使用
lambda关键字来定义,只能包含一个表达式,并没有函数名,仅用于简单的函数场景。
- 普通函数:使用
-
可读性:
- 普通函数:由于有函数名和较为完整的语法结构,通常比较容易理解和阅读。
- 匿名函数:由于没有函数名,以及只能包含简单的表达式,可读性相对较差。通常用于较短的、简单的函数需求。
-
参数个数:
- 普通函数:可以有任意数量的参数,可以使用默认参数和可变长参数。
- 匿名函数:只能接受有限的参数,通常用于只有几个简单参数的场景。
-
使用场景:
- 普通函数:适用于复杂的函数逻辑,可读性要求较高,需要多次调用或复用的场合。
- 匿名函数:适用于一次性或临时使用的简单函数,特别是在函数作为参数传递给其他函数或在函数式编程中使用。
下面是一个示例,比较了普通函数和匿名函数的使用:
# 普通函数
def add(x, y):return x + y# 调用普通函数
result1 = add(3, 5)
print(result1) # Output: 8# 匿名函数
add_lambda = lambda x, y: x + y# 调用匿名函数
result2 = add_lambda(3, 5)
print(result2) # Output: 8
在这个例子中,我们定义了一个普通函数add和一个匿名函数add_lambda,它们的功能相同,都是实现加法操作。使用匿名函数能够更简洁地定义一个简单的函数,但在可读性方面可能稍逊于普通函数。
综上所述,匿名函数是一种简化的函数定义形式,适用于简单的、一次性的函数需求,而普通函数更适用于复杂的、需要多次调用或复用的函数逻辑。选择合适的函数定义方式取决于具体的编程场景和需求。
Python模块
Python模块是一种组织和重用代码的方式,它是一个包含Python定义和语句的文件。模块可以包含函数、变量和类等,它们可以在其他Python程序中被导入和使用。使用模块的好处之一是可以将代码拆分为逻辑单元,提高代码的可维护性和复用性。
模块的导入方式
[from 模块名] import [模块 类 变量函数] [as 别名]
import 模块名:
这是最基本的导入方式,它将整个模块导入到当前的命名空间中。要使用模块中的功能,需要使用模块名.功能名的方式访问。例如:import math,然后使用math.sqrt()调用平方根函数。
import math
print(math.sqrt(16)) # 调用math模块的sqrt()函数计算平方根from 模块名 import 类、变量、方法等:
使用此方式,可以选择性地导入模块中的特定类、变量或方法等到当前命名空间,而不是整个模块。可以直接使用导入的名称,而无需使用模块名作为前缀。例如:from math import sqrt, pi,然后可以直接使用sqrt()和pi。
from math import sqrt, pi
print(sqrt(16)) # 直接调用sqrt()函数计算平方根
print(pi) # 直接输出导入的pi常量的值from 模块名 import *:
这种方式将导入模块中的所有公开(没有以_开头的)名称到当前命名空间中。尽管它方便了访问,但容易导致名称冲突和代码不易维护,因此不推荐在生产代码中使用。
from math import *
print(sqrt(16)) # 直接调用sqrt()函数计算平方根
print(pi) # 直接输出导入的pi常量的值import 模块名 as 别名:
使用as关键字,可以为模块指定一个别名,这样在代码中可以使用别名来引用模块。这在避免名称冲突或简化模块名时很有用。例如:import numpy as np,然后可以使用np.array()调用NumPy的数组函数。
import numpy as np
arr = np.array([1, 2, 3]) # 使用别名np调用NumPy模块的array()函数创建数组from 模块名 import 功能名 as 别名:
这种方式将导入模块中的特定功能,并且给它们指定别名。可以直接使用别名来调用这些功能,而无需使用原始的名称或模块名作为前缀。例如:from math import sqrt as square_root,然后可以使用square_root()代替sqrt()。
from math import sqrt as square_root
print(square_root(16)) # 使用别名square_root调用sqrt()函数计算平方根
注意:在实际编程中,建议使用import 模块名或from 模块名 import 功能名的形式,避免使用from 模块名 import *,因为后者可能导致不可预料的问题。同时,为了代码的可读性和维护性,建议为导入的模块和功能使用有意义的别名。
对比:
1和3
区别如下:
-
import 模块名:
这种导入方式将整个模块导入到当前命名空间中。需要使用模块名.功能名的方式来访问模块中的功能。例如,import math导入了math模块,然后使用math.sqrt()来调用平方根函数。 -
from 模块名 import *:
这种导入方式将导入模块中的所有公开(没有以_开头的)名称到当前命名空间中。公开的意思是模块中的所有变量、函数、类等,除了以_开头的私有成员。这样,可以直接使用导入的名称,而无需使用模块名作为前缀。例如,from math import *将导入math模块中的所有公开成员,然后可以直接使用sqrt()和pi,而不需要写成math.sqrt()和math.pi。
主要区别:
- 在第1种方式中,需要使用
模块名.功能名的方式来访问模块中的功能,而在第3种方式中,可以直接使用导入的名称来访问功能,避免了使用模块名前缀。 - 第1种方式比第3种方式更安全,因为在第3种方式中导入了模块中的所有公开成员,容易导致命名冲突,不推荐在生产代码中使用。第1种方式只导入了整个模块,并且使用模块名前缀,避免了命名冲突的问题。
因此,为了代码的可读性和维护性,建议使用第1种方式(import 模块名)或第2种方式(from 模块名 import 功能名),而不是第3种方式。
在模块导入的速度方面,通常情况下,第2种导入方式(from 模块名 import 类、变量、方法等)会比第3种方式(from 模块名 import *)更快。
原因如下:
- 第2种方式明确指定了要导入的类、变量或方法等,因此Python解释器只会导入指定的内容,减少了导入的工作量和内存占用。
- 第3种方式将导入模块中的所有公开成员,如果模块很大或者有许多功能,可能会导致较多的内存使用和加载时间。
- 在第2种方式中,只有明确指定的功能会被导入到当前命名空间中,这样可以避免导入不需要的功能,提高了代码的清晰度和可维护性。
虽然第2种方式在速度方面可能会更快,但在实际使用中,导入速度通常不是主要的性能瓶颈。更重要的是要选择适合代码清晰性和可读性的导入方式。因此,建议在生产代码中使用第2种方式,并明确指定要导入的功能,避免使用第3种方式导入所有内容。这样可以保持代码的整洁性和性能表现。
整体分析优缺点;
让我们对这五种导入方式进行对比:
-
import 模块名:- 导入整个模块,需要使用模块名前缀访问其中的功能。
- 可以在代码中多次使用该方式导入同一个模块,不会造成冲突。
- 适用于模块较大或需要多个功能的情况。
-
from 模块名 import 类、变量、方法等:- 选择性导入模块中的特定功能,无需使用模块名前缀,直接使用导入的名称即可访问。
- 可以一次导入多个功能,提高代码的简洁性。
- 避免了使用模块名前缀,适用于只需要少量功能的情况。
-
from 模块名 import *:- 导入模块中的所有公开名称,不推荐在生产代码中使用。
- 容易导致名称冲突和代码维护困难,避免使用此方式。
-
import 模块名 as 别名:- 给模块指定别名,使用别名来引用模块中的功能。
- 适用于模块名较长或需要避免名称冲突的情况。
-
from 模块名 import 功能名 as 别名:- 导入模块中的特定功能,并指定别名,直接使用别名调用功能。
- 可以简化代码,避免使用原始的名称或模块名前缀。
综合来看,第1种和第2种方式是最常用的。第1种方式适用于导入整个模块,第2种方式适用于选择性导入特定功能。第3种方式不推荐使用,因为它可能带来潜在的问题。第4种和第5种方式适用于需要别名的情况,可以提高代码的可读性和简洁性。总体上,选择合适的导入方式取决于具体的情况和代码的需求。
自定义模块:
自定义模块是指由用户创建的包含Python代码的文件,它可以包含函数、类、变量等可重用的代码块。自定义模块的主要目的是将代码组织成逻辑单元,以便在不同的Python程序中进行导入和使用,提高代码的可维护性和复用性。
自定义模块的创建步骤如下:
- 编写Python代码并保存为以
.py为扩展名的文件,文件名将成为模块的名称。 - 将保存好的文件放在Python解释器能够找到的目录中,比如当前工作目录或者Python标准库搜索路径。
以下是一个自定义模块的示例:
假设我们创建了一个名为my_utils.py的自定义模块,其中包含一些实用的函数:
# my_utils.pydef square(x):"""计算一个数的平方"""return x * xdef add(a, b):"""计算两个数的和"""return a + bPI = 3.14159
然后我们可以在其他Python程序中导入并使用这个自定义模块:
# 导入整个模块
import my_utilsprint(my_utils.square(5)) # 输出:25
print(my_utils.add(3, 7)) # 输出:10
print(my_utils.PI) # 输出:3.14159# 导入特定的函数和变量
from my_utils import square, PIprint(square(8)) # 输出:64
print(PI) # 输出:3.14159
注意事项:
- 自定义模块的文件名应该以
.py结尾,例如my_utils.py。 - 确保自定义模块与使用它的Python程序在相同的目录或正确的Python搜索路径下。
- 使用
import语句导入整个模块时,需要使用模块名前缀访问模块中的函数和变量。 - 使用
from 模块名 import 功能名形式导入特定的函数和变量时,可以直接使用功能名,无需使用模块名前缀。
注意事项:
当导入多个模块时,并且这些模块内部存在重名的函数、类、或变量等,可能会引起名称冲突的情况。这时,Python解释器可能无法区分具体使用哪个模块中的重名功能,从而导致代码出现错误或产生意外的结果。
在Python中,如果不同的模块导入了同名的功能(函数、类等),并且这些模块都被成功导入到同一个脚本中,后导入的模块将会覆盖先导入的模块中的同名功能。这种行为被称为"名称冲突"(name conflict)。
当存在名称冲突时,后导入的模块中的同名功能会覆盖先导入的模块中的同名功能。这意味着在脚本中使用该功能时,实际上会使用最后被导入的模块中的版本。
让我们通过一个示例来说明这个概念。假设有两个模块module_a.py和module_b.py,它们都定义了同名的函数common_function:
# module_a.py
def common_function():print("This is common function from module_a")# module_b.py
def common_function():print("This is common function from module_b")
现在,我们在一个脚本中导入这两个模块,并调用common_function:
from module_a import common_function
from module_b import common_functioncommon_function()
输出将会是:
This is common function from module_b
因为module_b.py最后被导入,并且它的common_function覆盖了module_a.py中的同名函数。这是由于后导入的模块会覆盖先导入的模块中的同名成员。
为了避免这种名称冲突问题,建议遵循以下几个最佳实践:
-
使用别名:当导入同名功能时,可以给其中一个或多个功能指定别名,以避免名称冲突。例如:
from module_a import common_function as a_function。 -
明确导入:尽量避免使用
from module import *这种方式,而是明确导入需要的功能。例如:from module_a import common_function和from module_b import common_function。 -
命名空间:如果模块的名称很常见并且可能与其他模块发生冲突,可以使用模块的命名空间来调用其中的功能。例如:
import module_a和import module_b,然后使用module_a.common_function()和module_b.common_function()来调用相应的功能。
要避免这种情况,可以采用以下方法:
- 使用完整模块名:
在调用重名功能时,可以使用完整的模块名作为前缀,明确指定使用哪个模块中的功能,避免冲突。
示例:
import module1
import module2print(module1.some_function()) # 调用module1中的函数
print(module2.some_function()) # 调用module2中的函数
- 使用别名(as 别名):
为导入的模块或重名功能指定别名,使用别名来区分不同模块中的重名功能。
示例:
import module1 as m1
import module2 as m2print(m1.some_function()) # 调用module1中的函数
print(m2.some_function()) # 调用module2中的函数
- 使用from-import语句:
如果只需要导入部分功能,并且这些功能重名,可以使用from-import语句,并为导入的功能指定别名。
示例:
from module1 import some_function as func1
from module2 import some_function as func2print(func1()) # 调用module1中的函数
print(func2()) # 调用module2中的函数
使用上述方法之一,可以避免模块之间的名称冲突,确保代码能够正确运行并得到预期的结果。在实际编程中,建议为导入的模块和功能使用有意义的别名,以增加代码的可读性和易于维护性。
__main__变量:
在Python中,__main__是一个特殊的内置变量(built-in variable),用于指示当前执行的脚本是否为主程序(main program)。当Python解释器运行一个脚本时,它会为这个脚本设置一些特定的变量,其中包括__name__。如果一个Python脚本被直接运行,那么__name__变量的值将被设置为__main__,否则,如果这个脚本作为模块被导入到其他脚本中,__name__的值将是模块的名称。
更具体地说,当你在命令行中直接运行一个Python脚本时,Python解释器会将这个脚本的__name__变量设置为__main__,以表示这个脚本是主程序。这样,你可以通过检查__name__的值来执行特定的代码块。这在构建可重用的模块和脚本时非常有用,因为它允许你在不同的上下文中运行不同的代码。
举个例子,假设有一个名为example.py的脚本,其内容如下:
def do_something():print("Doing something!")print("This will always be executed!")if __name__ == "__main__":print("This will only be executed when the script is run directly.")do_something()
如果你在命令行中执行python example.py,你会得到以下输出:
This will always be executed!
This will only be executed when the script is run directly.
Doing something!
但是,如果你在另一个脚本中导入example.py,if __name__ == "__main__":块中的代码将不会执行。例如,假设有一个名为main.py的脚本,其内容如下:
import exampleprint("This is the main program.")
如果你执行python main.py,你会得到以下输出:
This will always be executed!
This is the main program.
可以看到,example.py中的if __name__ == "__main__":块中的代码没有执行,因为它在main.py中被导入为一个模块。
总结一下,__main__变量是Python中的一个特殊内置变量,用于判断当前脚本是否为主程序。通过检查__name__的值,你可以在脚本作为主程序执行时运行特定的代码块,而在作为模块导入时不执行这些代码块。
all:
__all__是另一个Python中的特殊变量。它是一个可选的列表,用于定义模块中哪些成员(变量、函数、类等)应该在使用from module import *语句时被导入。这个特性主要用于控制模块的公共接口,以避免意外地导入不必要的成员。
当你在一个模块中定义了__all__变量时,它会限制在使用from module import *语句导入时所导入的内容。如果没有定义__all__变量,使用from module import *将导入模块中所有没有以下划线开头的全局名称(即公共成员),但这不是一个推荐的做法,因为它会导入太多不必要的内容,可能引起名称冲突或不良影响。
来看一个示例,假设有一个名为example_module.py的模块,其内容如下:
# example_module.pydef function_a():print("Function A")def function_b():print("Function B")def _private_function():print("Private Function")__all__ = ["function_a", "function_b"]
在上述示例中,__all__变量被设置为包含"function_a"和"function_b"两个字符串元素的列表。这意味着当使用from example_module import *语句导入模块时,只有function_a和function_b这两个函数会被导入,而_private_function不会被导入,因为它以下划线开头,被视为私有函数。
在另一个脚本中,我们可以这样使用example_module:
from example_module import *function_a() # Output: Function A
function_b() # Output: Function B
_private_function() # NameError: name '_private_function' is not defined
请注意,虽然使用__all__可以限制导入的内容,但它仅在使用from module import *语句时生效。推荐的做法是明确导入需要的成员,例如:from example_module import function_a, function_b,而不是使用from example_module import *。这样可以避免命名冲突,并使代码更加清晰和可维护。
python包怎么导入:
在Python中,要导入一个包(package),你可以使用import语句。一个包是包含多个模块的目录,它允许你组织和管理相关的功能模块。包目录下必须包含一个名为__init__.py的文件,这个文件可以是空文件,也可以包含包的初始化代码。
假设你有一个名为my_package的包,它的目录结构如下:
my_package/__init__.pymodule_a.pymodule_b.pysubpackage/__init__.pymodule_c.py
现在,我们来看看如何导入这个包和包中的模块:
- 导入整个包或子包:
import my_package# 使用包中的模块
my_package.module_a.some_function()
my_package.subpackage.module_c.another_function()
- 导入特定的模块:
from my_package import module_a, subpackage.module_c# 使用特定的模块
module_a.some_function()
subpackage.module_c.another_function()
- 使用
as关键字给导入的包或模块指定别名:
import my_package as mpmp.module_a.some_function()
mp.subpackage.module_c.another_function()
- 使用
from ... import ...语法导入包或模块中的特定成员:
from my_package.module_a import some_function
from my_package.subpackage.module_c import another_functionsome_function()
another_function()
请根据你的实际需求选择适合的导入方式。使用包可以帮助你更好地组织代码,防止命名冲突,并提供更高级别的模块管理。
相关文章:
我在VScode学Python(Python函数,Python模块导入)
我的个人博客主页:如果’真能转义1️⃣说1️⃣的博客主页 (1)关于Python基本语法学习---->可以参考我的这篇博客《我在VScode学Python》 (2)pip是必须的在我们学习python这门语言的过程中Python ---->&a…...

【目标跟踪】1、基础知识
文章目录 一、卡尔曼滤波二、匈牙利匹配 一、卡尔曼滤波 什么是卡尔曼滤波?——状态估计器 卡尔曼滤波用于在包含不确定信息的系统中做出预测,对系统下一步要做什么进行推测,且会结合推测值和观测值来得到修正后的最优值卡尔曼滤波就是利用…...

33. 搜索旋转排序数组
题目描述 整数数组 nums 按升序排列,数组中的值 互不相同 。 在传递给函数之前,nums 在预先未知的某个下标 k(0 < k < nums.length)上进行了 旋转,使数组变为 [nums[k], nums[k1], ..., nums[n-1], nums[0], n…...

接口自动化测试要做什么?8个步骤讲的明明白白(小白也能看懂系列)
先了解下接口测试流程: 1、需求分析 2、Api文档分析与评审 3、测试计划编写 4、用例设计与评审 5、环境搭建(工具) 6、执行用例 7、缺陷管理 8、测试报告 那"接口自动化测试"怎么弄?只需要在上篇文章的基础上再梳理下就…...

Flutter 自定义 虚线 分割线
学习使用Flutter 进行 虚线 自定义控件 练习 // 自定义虚线 (默认是垂直方向) class DashedLind extends StatelessWidget {final Axis axis; // 虚线方向final double dashedWidth; // 根据虚线的方向确定自己虚线的宽度final double dashedHeight; //…...

Java毕业设计—爱宠医院管理系统设计与实现
爱宠医院管理系统 获取数论文、代码、答辩PPT、安装包,可以查看文章底部 一、 如何安装及配置环境 要运行整个爱宠医院管理系统需要安装数据库:MySQL 5.5,开发工具:JDK 1.8,开发语开发平台:Eclipse&…...
AI时代带来的图片造假危机,该如何解决
一、前言 当今,图片造假问题非常泛滥,已经成为现代社会中一个严峻的问题。随着AI技术不断的发展,人们可以轻松地通过图像编辑和AI智能生成来篡改和伪造图片,使其看起来真实而难以辨别,之前就看到过一对硕士夫妻为了骗…...
【动态规划】简单多状态
文章目录 动态规划(简单多状态)1. 按摩师2. 打家劫舍 ||3. 删除并获得点数4. 粉刷房子5. 最佳买卖股票时机含冷冻期6. 买卖股票的最佳时机含手续费7. 买卖股票的最佳时机 |||8. 买卖股票的最佳时机 IV 动态规划(简单多状态) 1. 按…...

科技资讯|苹果计划本月推出Vision Pro头显开发套件,电池有重大更新
根据消息源 aaronp613 分享的信息,苹果计划本月底面向开发者,发布 Vision Pro 头显开发套件。消息源还指出苹果更新了 Vision Pro 头显电池组的代号,共有 A2781,A2988 和 A2697 三种不同的型号,目前尚不清楚三者之间的…...

k8s 将pod节点上的文件拷贝到本地
要将 Kubernetes(k8s)中 Pod 节点上的文件拷贝到本地,可以通过使用 kubectl cp 命令来实现。kubectl cp 命令允许你在本地系统和 Pod 之间复制文件和目录。 下面是使用 kubectl cp 命令的语法: kubectl cp <namespace>/&l…...

Git简介与工作原理:了解Git的基本概念、版本控制系统和分布式版本控制的工作原理
🌷🍁 博主 libin9iOak带您 Go to New World.✨🍁 🦄 个人主页——libin9iOak的博客🎐 🐳 《面试题大全》 文章图文并茂🦕生动形象🦖简单易学!欢迎大家来踩踩~ἳ…...

java篇 类的进阶0x02:方法重载
文章目录 方法重载 overload方法签名返回值不属于方法签名的原因: 重载的参数匹配规则 方法重载 overload 多个方法功能很相似,但不完全一样,可以考虑使用方法的重载。 同一个类中,方法可以重名,但是签名不可以重复。…...

Android11 相机拍照权限,以及解决resolveActivity返回null
一、配置拍照和读写权限 <uses-permission android:name"android.permission.CAMERA"/> <uses-feature android:name"android.hardware.camera" /><uses-permission android:name"android.permission.WRITE_EXTERNAL_STORAGE"/&…...
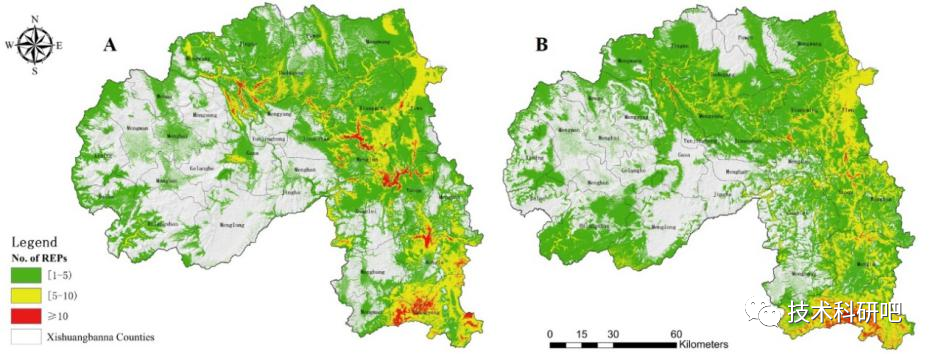
MAXENT模型的生物多样性教程
详情点击链接:基于MAXENT模型的生物多样性生境模拟与保护优先区甄选、自然保护区布局优化及未来气候变化下评估中的应用及论文写作 一:生物多样性保护格局与自然保护区格局优化 1.我国生物多样性格局与分布; 2.我国自然保护区格局与分布&…...
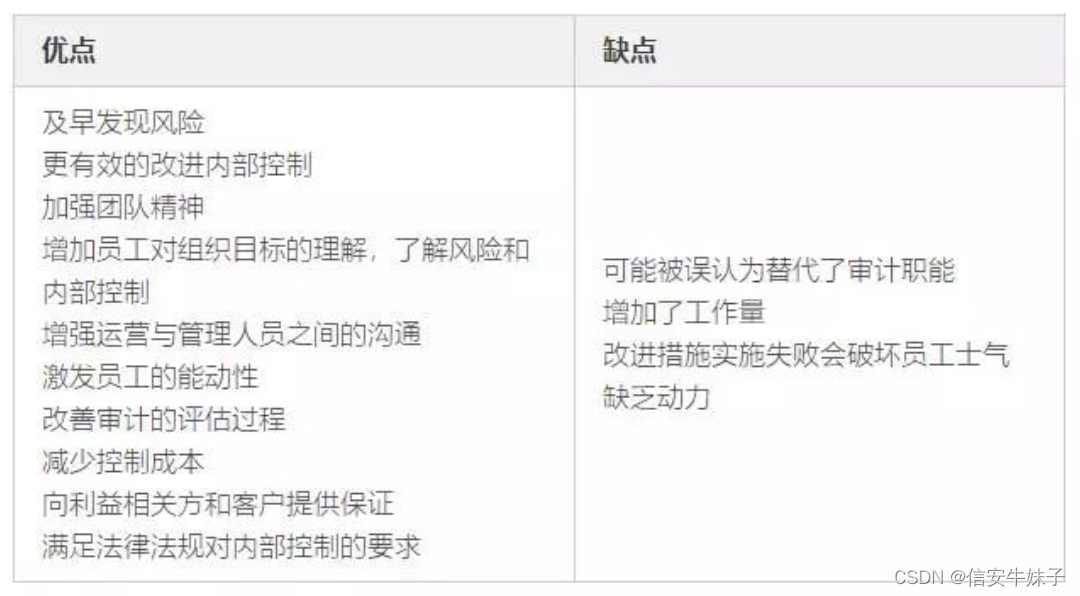
CISA学习笔记-第一章、信息系统审计过程
传统的审计三方关系理论指明,审计作为独立于会计记录之外的一项重要职能,是公司财务信息公允可靠的有力保障,制约着会计行为,制衡了会计权力。 1. IS审计和保障标准、指南、工具 职业道德规范 信息技术保证框架(ITAF&a…...
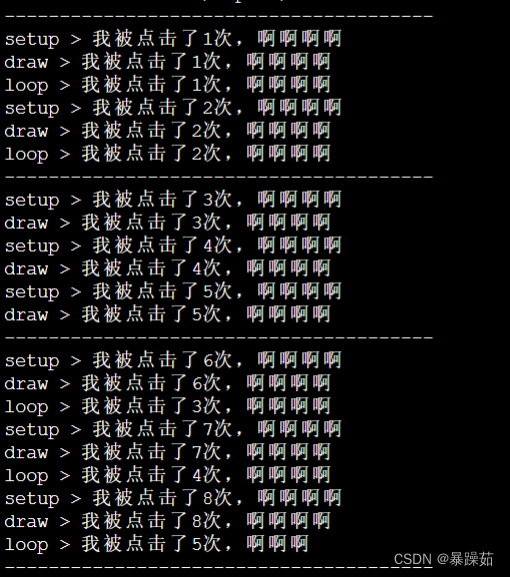
回调函数的使用:案例一:c语言简单信号与槽机制。
系列文章目录 文章目录 系列文章目录前言一、回调函数1.1 回调函数基本概念1.2 简单实现 二、代码案例1.代码示例 总结 前言 了解回调函数的基本概念,函数指针的使用、简单信号与槽的实现机制; 一、回调函数 1.1 回调函数基本概念 回调函数就是一个通…...

python matplotlib库 设置字体字号等
主要是记录字体、字号对应的参数。注意字符串类型的参数要加引号 1.字体: fontname 常见参数: # 常用 Times New Roman、Dejavu sans、TeX Gyre Schola中文字体 黑体:SimHei 微软雅黑:Microsoft YaHei 微软正黑体:M…...
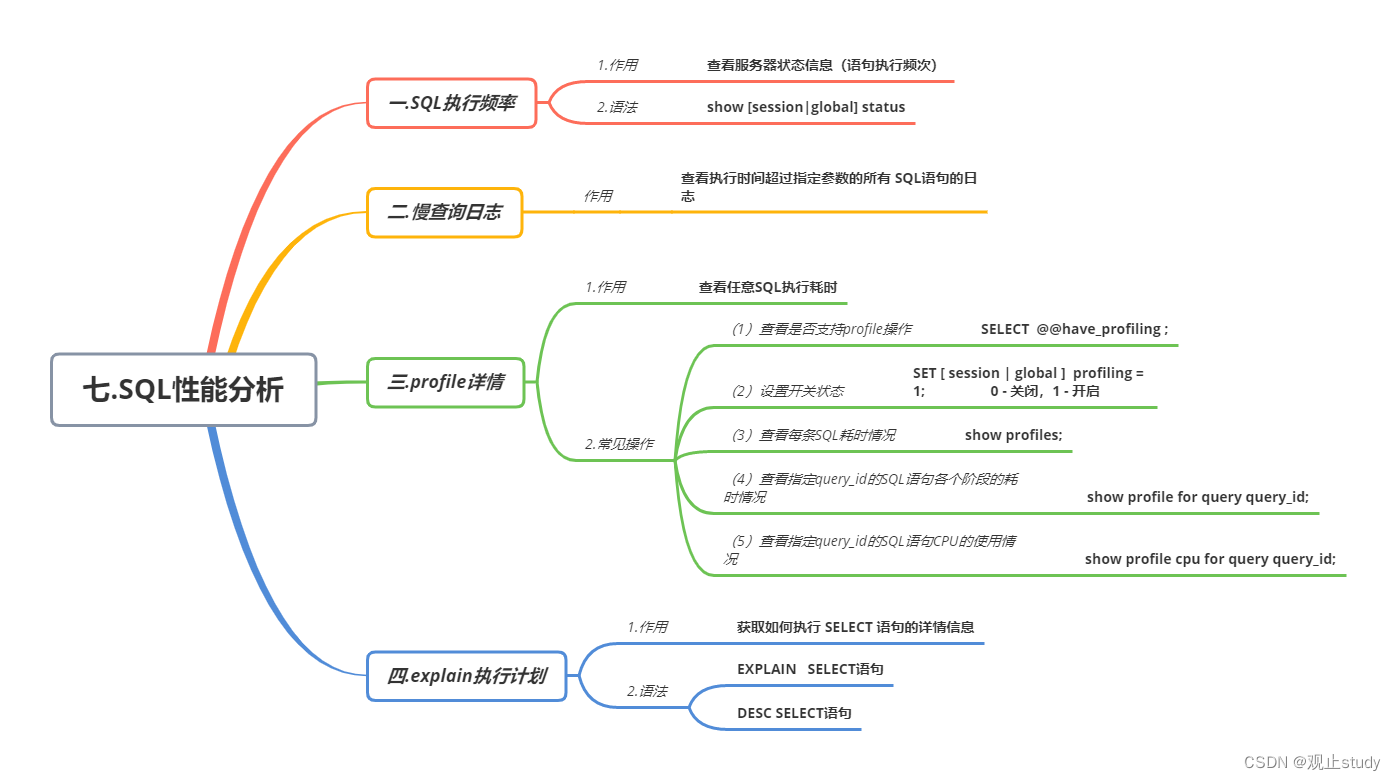
【MySQL】SQL性能分析 (七)
🚗MySQL学习第七站~ 🚩本文已收录至专栏:MySQL通关路 ❤️文末附全文思维导图,感谢各位点赞收藏支持~ 假如我们需要对SQL进行优化,我们就必须对他足够的了解,比如 对哪一类SQL进行优化(增删改查…...

超越想象的GPT医疗 20230723
7月份读完了这本书,趁着周末写下读书笔记吧 这本书 作者:【美】彼得.李 Peter Lee 【美】凯丽.戈德伯格CareyGoldberg 著 【美】伊萨克.科恩Isaac Kohane 芦义 译 在AI风起云涌时代,在这刚刚过去的新冠三年,“超越想象的GPT医…...

【N32L40X】学习笔记03-gpio输出库
gpio输出 该函数库的目的就是在统一的地方配置,将配置的不同项放置在一个结构体内部使用一个枚举来定义一个的别名 led.c #include <stdio.h> #include "led/bsp_led.h"static led_t leds[LED_NUM]{{GPIOB,GPIO_PIN_2,RCC_APB2_PERIPH_GPIOB},{GP…...
排查中的常见思维盲区)
从一次“意外”发现flag说起:复盘uWSGI目录穿越漏洞(CVE-2018-7490)排查中的常见思维盲区
从"Not Found"到flag:uWSGI目录穿越漏洞实战思维全解析 当浏览器返回"Not Found"时,大多数人的第一反应是漏洞利用失败。但真正的安全测试往往始于这些看似失败的瞬间。去年在内部红队演练中,我遇到一个经典场景&#x…...

老旧设备重生计划:Windows 11绕过系统限制的安全安装指南
老旧设备重生计划:Windows 11绕过系统限制的安全安装指南 【免费下载链接】rufus The Reliable USB Formatting Utility 项目地址: https://gitcode.com/GitHub_Trending/ru/rufus 想让你的老旧电脑也能流畅运行Windows 11吗?本文将为你提供一套完…...

HunyuanVideo-Foley高效部署:FFmpeg集成音视频后处理完整指南
HunyuanVideo-Foley高效部署:FFmpeg集成音视频后处理完整指南 1. 镜像概述与核心能力 HunyuanVideo-Foley是一款专为视频生成与音效合成设计的AI模型,本镜像针对RTX 4090D 24GB显存显卡进行了深度优化。通过预置完整运行环境和加速库,用户无…...

终极CoreUI Bootstrap管理模板:5个导航组件实战技巧提升用户体验
终极CoreUI Bootstrap管理模板:5个导航组件实战技巧提升用户体验 【免费下载链接】coreui-free-bootstrap-admin-template coreui/coreui-free-bootstrap-admin-template: CoreUI-Free-Bootstrap-Admin-Template 是一套免费的Bootstrap 4/5管理模板,包含…...

Qwen3-Embedding-0.6B新手指南:从零开始玩转文本嵌入
Qwen3-Embedding-0.6B新手指南:从零开始玩转文本嵌入 1. 什么是文本嵌入?为什么你需要它? 想象一下,你有一个装满各种文档、网页和笔记的文件夹。当你想找“如何用Python做数据分析”的资料时,你只能靠记忆或者手动翻…...

为什么你需要KKS-HF_Patch?解锁Koikatsu Sunshine完整游戏体验的终极指南
为什么你需要KKS-HF_Patch?解锁Koikatsu Sunshine完整游戏体验的终极指南 【免费下载链接】KKS-HF_Patch Automatically translate, uncensor and update Koikatsu Sunshine! 项目地址: https://gitcode.com/gh_mirrors/kk/KKS-HF_Patch 你是否曾经因为语言障…...

FLUX.1-dev-fp8-dit文生图开发:C++高性能推理加速实践
FLUX.1-dev-fp8-dit文生图开发:C高性能推理加速实践 文生图模型的推理速度一直是开发者关注的焦点,特别是在需要批量生成或实时应用的场景中。今天我们来聊聊如何用C对FLUX.1-dev-fp8-dit模型进行深度优化,实现40%以上的推理加速。 1. 为什么…...

OpenClaw浏览器自动化:Qwen3-32B-Chat实现智能爬虫与数据分析
OpenClaw浏览器自动化:Qwen3-32B-Chat实现智能爬虫与数据分析 1. 为什么需要智能化的浏览器自动化? 上个月我需要收集某个垂直领域的行业报告,手动复制粘贴了十几个网页后,突然意识到:这种重复劳动不正是AI该解决的问…...

Tessent Shell双Pass插入策略深度解读:为什么MemoryBIST要先于EDT/OCC插入?
Tessent Shell双Pass插入策略:MemoryBIST优先于EDT/OCC的技术本质解析 在芯片测试领域,Tessent Shell的双Pass插入流程(Two-Pass Insertion Process)是一个被广泛采用却鲜少深入探讨的核心方法论。当工程师首次接触"先Memory…...

granite-4.0-h-350m从部署到应用:Ollama本地大模型在法律文书处理中的案例
granite-4.0-h-350m从部署到应用:Ollama本地大模型在法律文书处理中的案例 1. 快速上手:granite-4.0-h-350m模型部署 granite-4.0-h-350m是一个轻量级的指令跟随模型,专门为本地部署和特定领域应用而设计。这个模型只有3.5亿参数࿰…...