【MySQL】基本查询(插入查询结果、聚合函数、分组查询)
目录
- 一、插入查询结果
- 二、聚合函数
- 三、分组查询(group by & having)
- 四、SQL查询的执行顺序
- 五、OJ练习
一、插入查询结果
语法:
INSERT INTO table_name [(column [, column ...])] SELECT ...
案例:删除表中重复数据
--创建初始重复表
mysql> CREATE TABLE duplicate_table (id int, name varchar(20));
Query OK, 0 rows affected (0.03 sec)
--插入重复数据
mysql> INSERT INTO duplicate_table VALUES-> (100, 'aaa'),-> (100, 'aaa'),-> (200, 'bbb'),-> (200, 'bbb'),-> (200, 'bbb'),-> (300, 'ccc');
Query OK, 6 rows affected (0.00 sec)
Records: 6 Duplicates: 0 Warnings: 0
--查询表中数据
mysql> select * from duplicate_table;
+------+------+
| id | name |
+------+------+
| 100 | aaa |
| 100 | aaa |
| 200 | bbb |
| 200 | bbb |
| 200 | bbb |
| 300 | ccc |
+------+------+
6 rows in set (0.00 sec)
--新建一个相同表结构的空表
mysql> create table no_duplicate_table like duplicate_table;
Query OK, 0 rows affected (0.02 sec)
--把去重后的结果插入空表中
mysql> insert into no_duplicate_table select distinct *from duplicate_table;
Query OK, 3 rows affected (0.01 sec)
Records: 3 Duplicates: 0 Warnings: 0
//查询表内数据
mysql> select * from no_duplicate_table;
+------+------+
| id | name |
+------+------+
| 100 | aaa |
| 200 | bbb |
| 300 | ccc |
+------+------+
3 rows in set (0.00 sec)
//修改两个表名,把去重后的表该为该名字
mysql> rename table duplicate_table to old_duplicate_table,no_duplicate_table to duplicate_table;
Query OK, 0 rows affected (0.02 sec)mysql> select * from duplicate_table;
+------+------+
| id | name |
+------+------+
| 100 | aaa |
| 200 | bbb |
| 300 | ccc |
+------+------+
3 rows in set (0.00 sec)这里通过rename修改表名是为了等表的操作结束后,统一放入,更新,生效,节省时间
二、聚合函数
MySQL中的聚合函数常用于对数据进行计算和统计,以下是几种常见的聚合函数
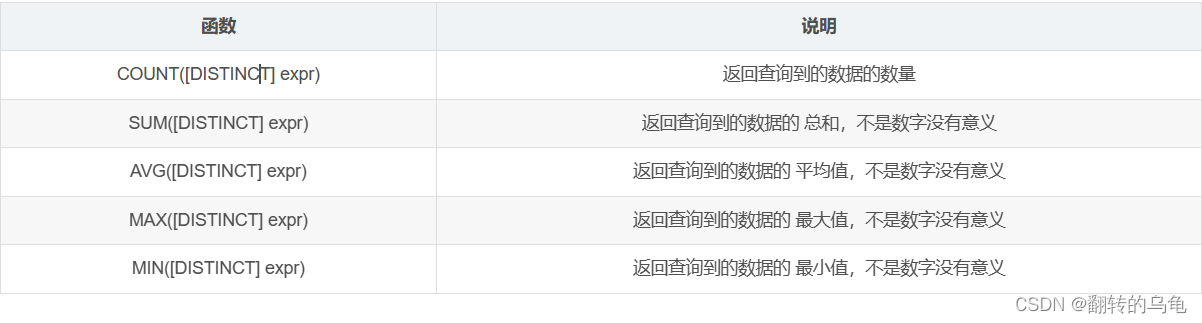
案例:
- 统计班级共有多少同学
mysql> select * from exam_result;
+----+-----------+---------+------+---------+
| id | name | chinese | math | english |
+----+-----------+---------+------+---------+
| 1 | 唐三藏 | 134 | 98 | 56 |
| 3 | 猪悟能 | 176 | 98 | 90 |
| 4 | 曹孟德 | 140 | 90 | 67 |
| 5 | 刘玄德 | 110 | 115 | 45 |
| 6 | 孙权 | 140 | 73 | 78 |
| 7 | 宋公明 | 150 | 95 | 30 |
+----+-----------+---------+------+---------+
6 rows in set (0.00 sec)mysql> select count(*) from exam_result;
+----------+
| count(*) |
+----------+
| 6 |
+----------+
1 row in set (0.00 sec)mysql> select count(1) from exam_result;
+----------+
| count(1) |
+----------+
| 6 |
+----------+
1 row in set (0.00 sec)-- 统计班级的数学成绩有多少个(去重)
mysql> select math from exam_result;
+------+
| math |
+------+
| 98 |
| 98 |
| 90 |
| 115 |
| 73 |
| 95 |
+------+
6 rows in set (0.01 sec)mysql> select count(distinct math) from exam_result;
+----------------------+
| count(distinct math) |
+----------------------+
| 5 |
+----------------------+
1 row in set (0.00 sec)-- 统计数学成绩总分
mysql> select sum(math) from exam_result;
+-----------+
| sum(math) |
+-----------+
| 569 |
+-----------+
1 row in set (0.00 sec)--统计数学成绩的平均分
mysql> select avg(math) from exam_result;
+-------------------+
| avg(math) |
+-------------------+
| 94.83333333333333 |
+-------------------+
1 row in set (0.00 sec)--统计英语成绩不及格的人数
mysql> select count(*) from exam_result where english<60;
+----------+
| count(*) |
+----------+
| 3 |
+----------+
1 row in set (0.00 sec)--返回英语最高分
mysql> select max(english) from exam_result;
+--------------+
| max(english) |
+--------------+
| 90 |
+--------------+
1 row in set (0.00 sec)--返回 > 70 分以上的数学最低分
mysql> select min(math) from exam_result where math>70;
+-----------+
| min(math) |
+-----------+
| 73 |
+-----------+
1 row in set (0.00 sec)
三、分组查询(group by & having)
分组的目的是为了方便进行聚合统计
在select中使用group by 子句可以对指定列进行分组查询
select column1, column2, .. from table group by column;
案例:
EMP员工表
DEPT部门表
SALGRADE工资等级表
- 显示每个部门的平均工资和最高工资
group by ‘列名’:分组是以同一列不同行数据来进行分组的;分组过后,每组内的【分组列名如deptno】,一定是一样的,可以被聚合压缩
mysql> select deptno,avg(sal) 平均工资, max(sal) '最高工资' from emp group by deptno;
+--------+--------------+--------------+
| deptno | 平均工资 | 最高工资 |
+--------+--------------+--------------+
| 10 | 2916.666667 | 5000.00 |
| 20 | 2175.000000 | 3000.00 |
| 30 | 1566.666667 | 2850.00 |
+--------+--------------+--------------+
3 rows in set (0.00 sec)- 显示每个部门的每种岗位的平均工资和最低工资
mysql> select deptno, job,avg(sal) 平均工资, min(sal)最低工资 from emp group by deptno, job;
+--------+-----------+--------------+--------------+
| deptno | job | 平均工资 | 最低工资 |
+--------+-----------+--------------+--------------+
| 10 | CLERK | 1300.000000 | 1300.00 |
| 10 | MANAGER | 2450.000000 | 2450.00 |
| 10 | PRESIDENT | 5000.000000 | 5000.00 |
| 20 | ANALYST | 3000.000000 | 3000.00 |
| 20 | CLERK | 950.000000 | 800.00 |
| 20 | MANAGER | 2975.000000 | 2975.00 |
| 30 | CLERK | 950.000000 | 950.00 |
| 30 | MANAGER | 2850.000000 | 2850.00 |
| 30 | SALESMAN | 1400.000000 | 1250.00 |
+--------+-----------+--------------+--------------+
9 rows in set (0.00 sec)注意事项:在group by之后出现的字段是可以在select 之后出现的,还有聚合函数,正常分组出现的字段在聚合条件中可以输出,其他会报错
select ename,deptno,job,avg(sal)平均,min(sal) 最低 from emp group by deptno,job;
上面的代码因为分组条件中没有用到ename 所以报错
- 显示平均工资低于2000的部门和它的平均工资
mysql> select deptno,avg(sal) deptavg from emp group by deptno having deptavg<2000;
+--------+-------------+
| deptno | deptavg |
+--------+-------------+
| 30 | 1566.666667 |
+--------+-------------+
1 row in set (0.00 sec)- 除SMITH外,显示平均工资低于2000的每个部门的每种岗位的和它的平均工资
mysql> select deptno,job,avg(sal) deptavg from emp where ename!='SMITH' group by deptno,job having deptavg<2000;
+--------+----------+-------------+
| deptno | job | deptavg |
+--------+----------+-------------+
| 10 | CLERK | 1300.000000 |
| 20 | CLERK | 1100.000000 |
| 30 | CLERK | 950.000000 |
| 30 | SALESMAN | 1400.000000 |
+--------+----------+-------------+
4 rows in set (0.00 sec)四、SQL查询的执行顺序
SQL查询中各个关键字的执行先后顺序 :from > on> join > where > group by > with > having > select>distinct > order by > limit
五、OJ练习
1.批量插入数据
答案:
insert into actor values(1,'PENELOPE','GUINESS','2006-02-15 12:34:33'),(2,'NICK','WAHLBERG','2006-02-15 12:34:33');

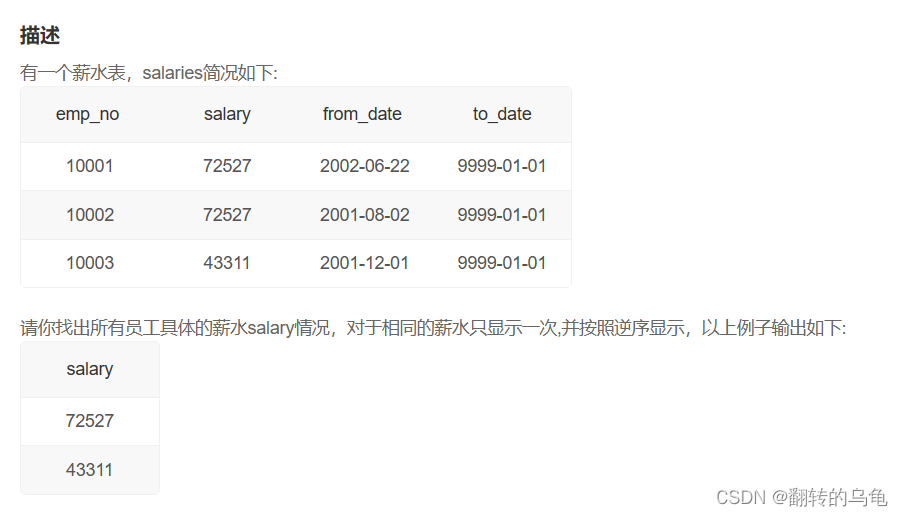
2.找出所有员工薪水情况
答案:
select distinct salary from salaries order by salary desc;
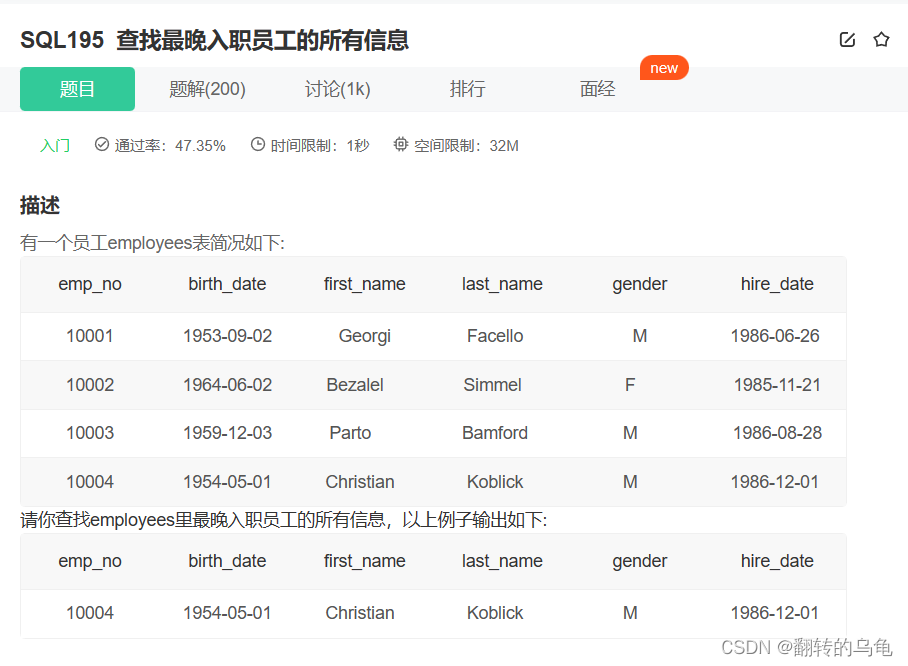
3.查找最晚入职员工的所有信息
答案:
select * from employees order by hire_date desc limit 1;
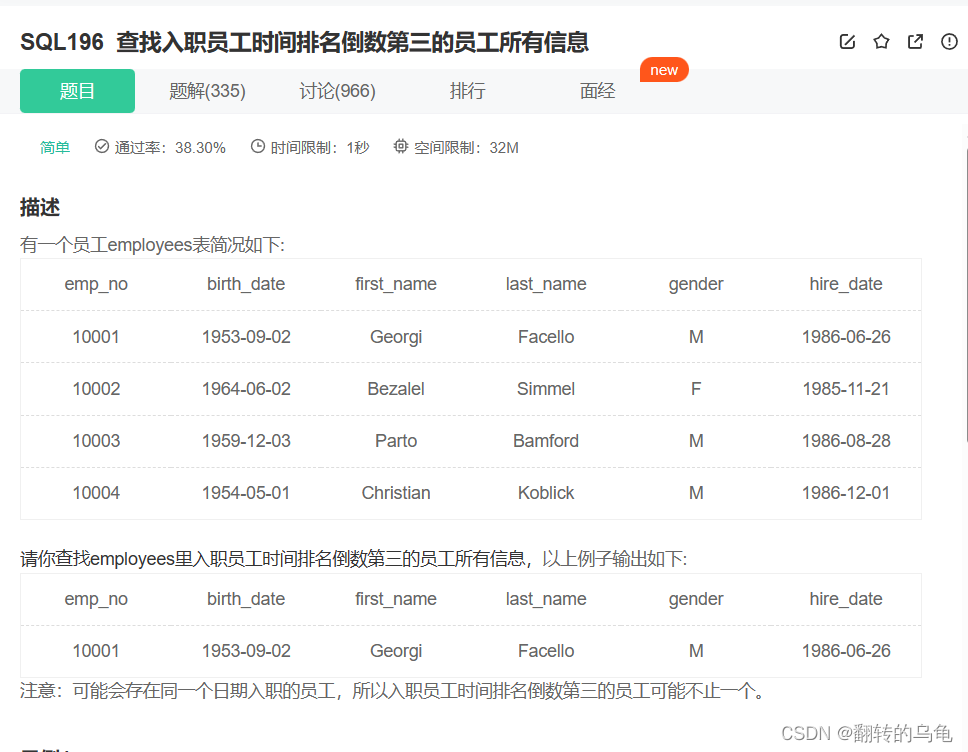
4.查找入职员工时间排名倒数第三的员工所有信息
答案:
select * from employees where hire_date=(select distinct hire_date from employees order by hire_date desc limit 2,1);
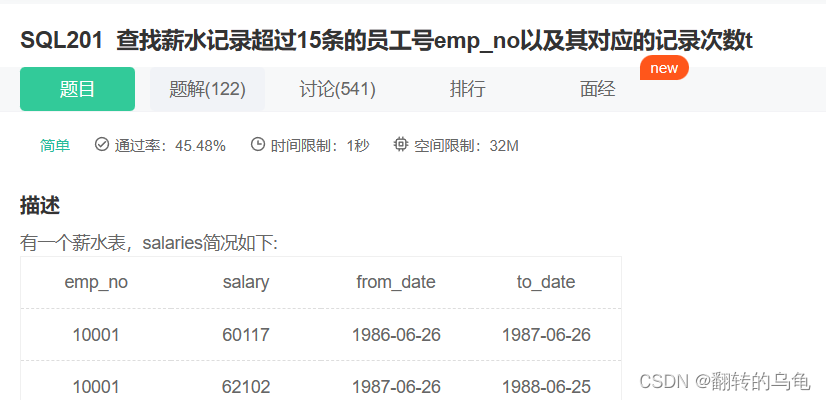
5.查找薪水记录超过15条的员工号emp_no以及其对应的记录次数t
分组+聚合函数
答案:
select emp_no,count(*) t from salaries group by emp_no having t>15;
6.获取所有部门薪水
答案:
SELECT dm.dept_no, dm.emp_no, s.salary
FROM dept_manager dm
JOIN salaries s ON dm.emp_no = s.emp_no
WHERE dm.to_date = '9999-01-01' AND s.to_date = '9999-01-01'
ORDER BY dm.dept_no ASC;--或者
SELECTdm.dept_no,dm.emp_no,(SELECT s.salaryFROM salaries sWHERE s.emp_no = dm.emp_noAND s.to_date = '9999-01-01'LIMIT 1) AS salary
FROMdept_manager dm
WHEREdm.to_date = '9999-01-01'
ORDER BYdm.dept_no ASC;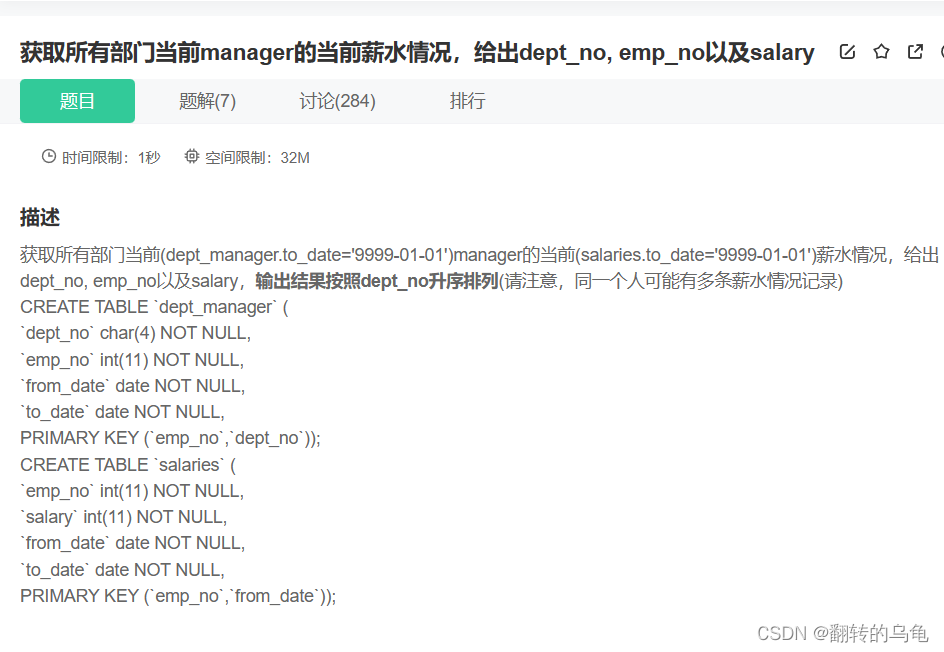
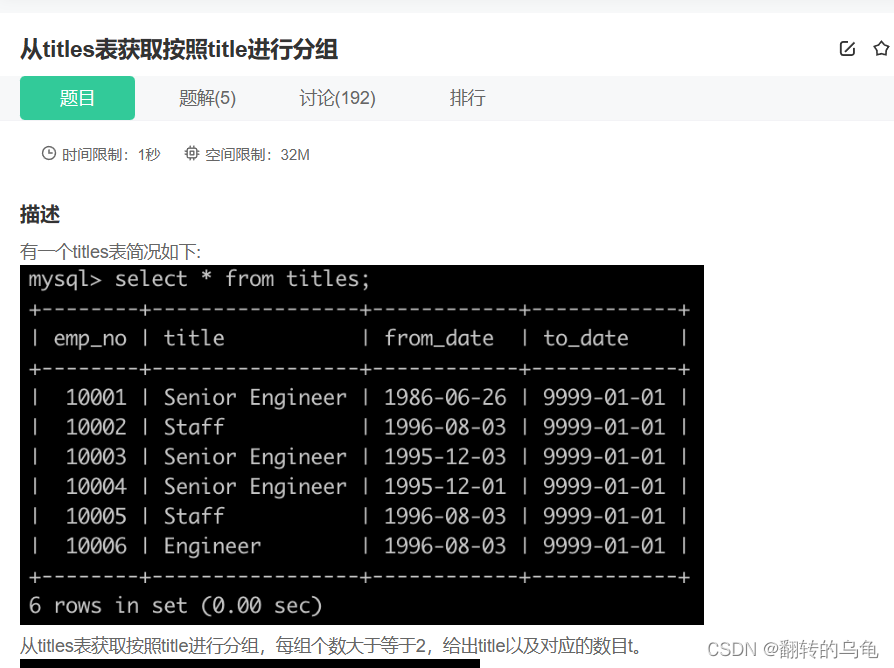
7.从titles表获取按照title进行分组
答案:
select title,count(title) t from titles group by title having t>=2;
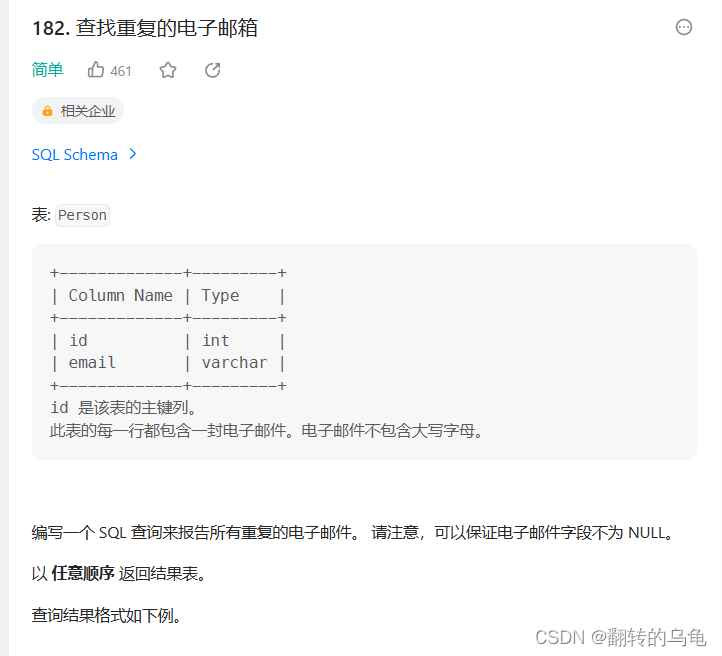
8.查找重复数据
答案
select email from Person group by email having count(email)>1;
9.查找大国
select name,population,area from World where area>=3000000 or population>=25000000;
10.给定一个Employee表,要找出其中第N高的薪资(Salary)
CREATE FUNCTION getNthHighestSalary(N INT) RETURNS INT
BEGINSET N = N - 1;RETURN (select distinct(Salary) as getNthHighestSalaryfrom EmployeeGROUP BY Salary ORDER BY Salary DESC limit 1 offset N);
END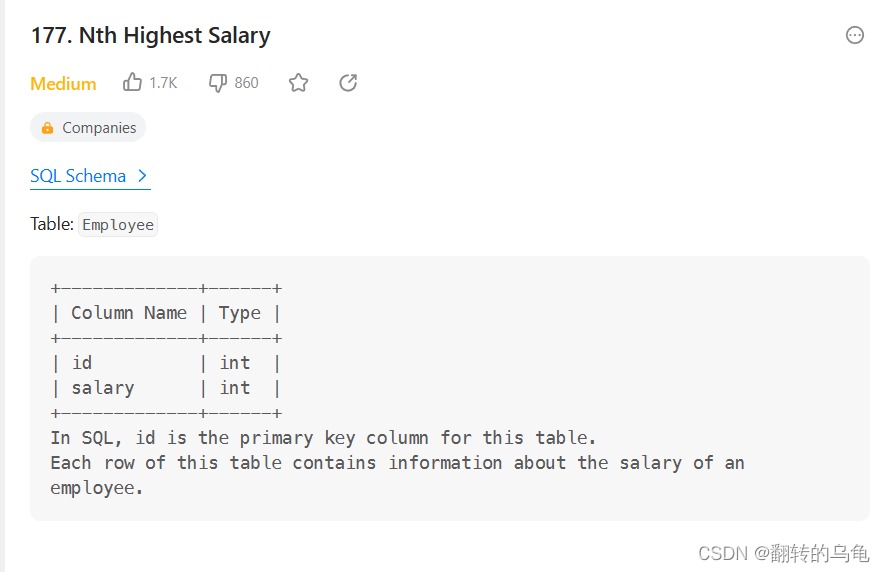
相关文章:
【MySQL】基本查询(插入查询结果、聚合函数、分组查询)
目录 一、插入查询结果二、聚合函数三、分组查询(group by & having)四、SQL查询的执行顺序五、OJ练习 一、插入查询结果 语法: INSERT INTO table_name [(column [, column ...])] SELECT ...案例:删除表中重复数据 --创建…...
【Go语言】Golang保姆级入门教程 Go初学者介绍chapter1
Golang 开山篇 Golang的学习方向 区块链研发工程师: 去中心化 虚拟货币 金融 Go服务器端、游戏软件工程师 : C C 处理日志 数据打包 文件系统 数据处理 很厉害 处理大并发 Golang分布式、云计算软件工程师:盛大云 cdn 京东 消息推送 分布式文…...

mysql 自增长键值增量设置
参考文章 MySQL中auto_increment的初值和增量值设置_auto_increment怎么设置_linda公馆的博客-CSDN博客 其中关键语句 show VARIABLES like %auto_increment% set auto_increment_increment4; set auto_increment_offset2;...
【pytho】request五种种请求处理为空和非空处理以及上传excel,上传图片处理
一、python中请求处理 request.args获取的是个字典,所以可以通过get方式获取请求参数和值 request.form获取的也是个字典,所以也可以通过get方式获取请求的form参数和值 request.data,使用过JavaScript,api调用方式进行掺入jso…...

【全面解析】Windows 如何使用 SSH 密钥远程连接 Linux 服务器
创建密钥 创建 linux 服务器端的终端中执行命令 ssh-keygen,之后一直按Enter即可,这样会在将在 ~/.ssh/ 路径下生成公钥(id_rsa.pub)和私钥(id_rsa) 注意:也可以在 windows 端生成密钥,只需要保证公钥在服务器端,私钥…...

解锁新技能《基于logback的纯java版本SDK实现》
开源SDK: <!--Java通用日志组件SDK--> <dependency><groupId>io.github.mingyang66</groupId><artifactId>oceansky-logger</artifactId><version>4.3.6</version> </dependency> <!-- Java基于logback的…...
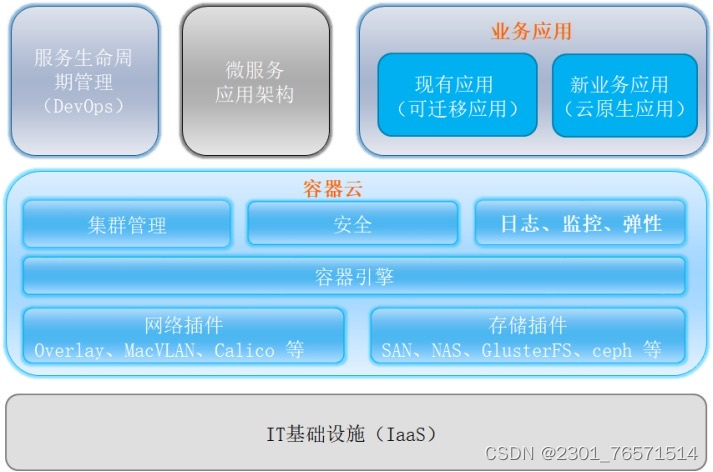
你需要知道的云原生架构体系内容
云原生(Cloud-Native)的概念在国内提及的越来越多,但大部分人对云原生的认识仅限于容器、微服务、DevOps等内容,把容器、微服务、 DevOps就等同于云原生,这显然是不对的。CNCF从其自身的角度定义了云原生技术ÿ…...
安全渗透--正则表达式
什么是正则表达式? 正则表达式是一组由字母和符号组成的特殊文本,它可以用来从文本中找出满足你想要的格式的句子。 一个正则表达式是一种从左到右匹配主体字符串的模式。 “Regular expression”这个词比较拗口,我们常使用缩写的术语“regex…...
git如何撤销commit(未push)
文章目录 前言undo commitreset current branch to here Undo Commit,Revert Commit,Drop Commit的区别 是否删除对代码的修改是否删除Commit记录是否会新增Commit记录Undo Commit不会未Push会,已Push不会不会Revert Commit会不会会Drop Com…...

Vue数组与字符串互转
一、数组转换成字符串的方法 join() var arr [A, B, C]; var str arr.join(、); console.log(str); // 输出 A、B、C toString() var arr [A, B, C]; var str arr.toString(); console.log(str); // 输出 A, B, C JSON.stringify() var arr [A, B, C]; var str JSO…...

Java编程实现遍历两个MAC地址之间所有MAC的方法
Java编程实现遍历两个MAC地址之间所有MAC的方法 本文实例讲述了java编程实现遍历两个MAC地址之间所有MAC的方法。分享给大家供大http://家参考,具体如下: 在对发放的设备进行后台管理时,很多时候会用到设备MAC这个字段,它可以标识唯一一个设备。然而在数…...

用AXIS2发布WebService的方法
Axis2+tomcat6.0 实现webService 服务端发布与客户端的调用。 Aixs2开发webService的方法有很多,在此只介绍一种比较简单的实现方法。 第一步:首先要下载开发所需要的jar包 下载:axis2-1.6.1-war.zip http://www.apache.org/dist//axis/axis2/java/core/1.6.1/ 下载…...
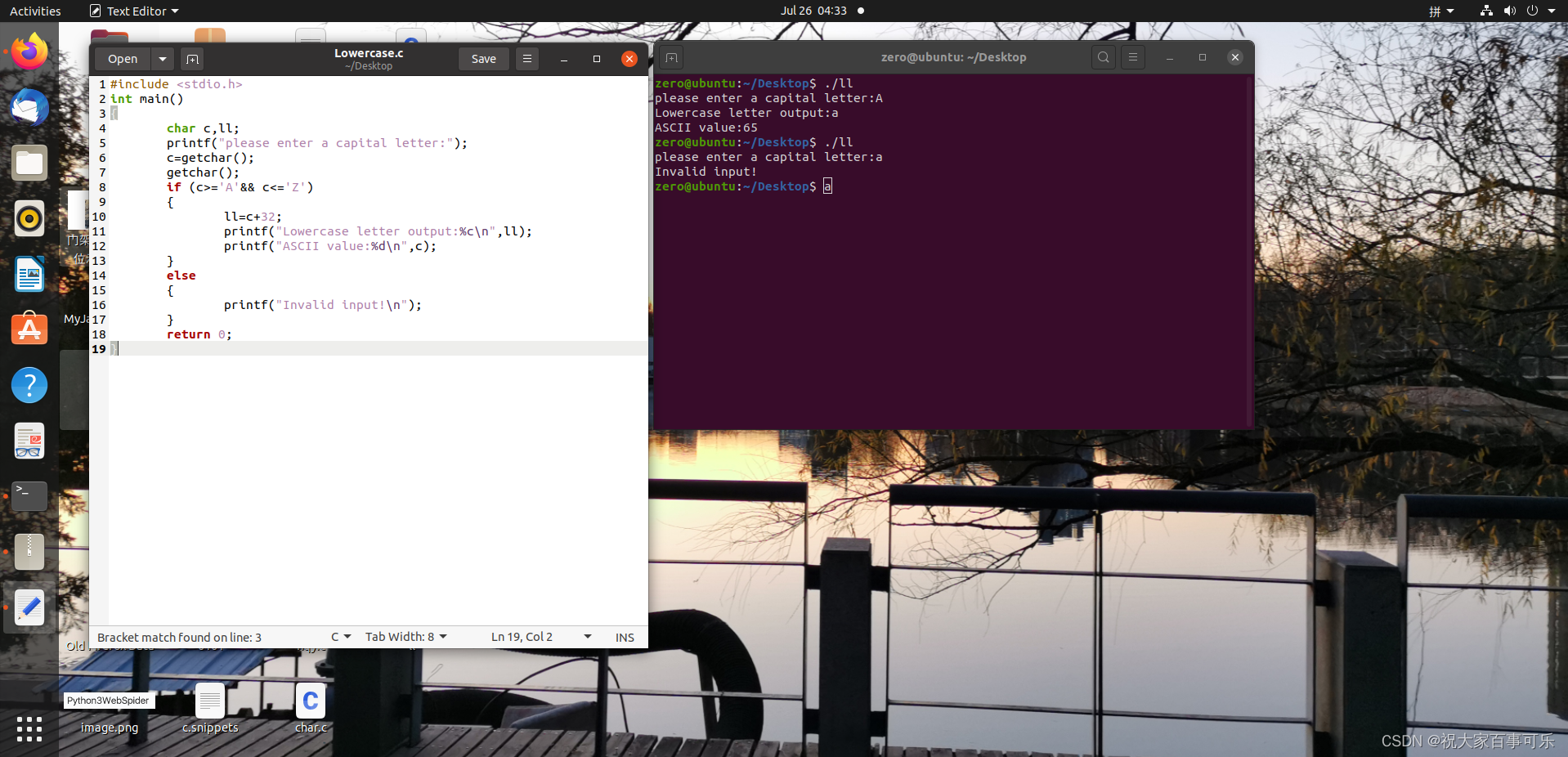
嵌入式学习_Day 003
程序功能介绍 c #include <stdio.h> int main() {char c,ll;printf("please enter a capital letter:");cgetchar();getchar();if (c>A&& c<Z) {llc32;printf("Lowercase letter output:%c\n",ll);printf("ASCII value:%d\n"…...
常用的数据结构 JAVA
目录 1、线性表2、栈:3、队列: 1、线性表 List<Object> narnat new ArrayList<>();ArrayList:动态数组 1、可以嵌套使用 2、add(x)添加元素x,remove(index)删除某个位置的元素 3、注意list是指向性的,…...
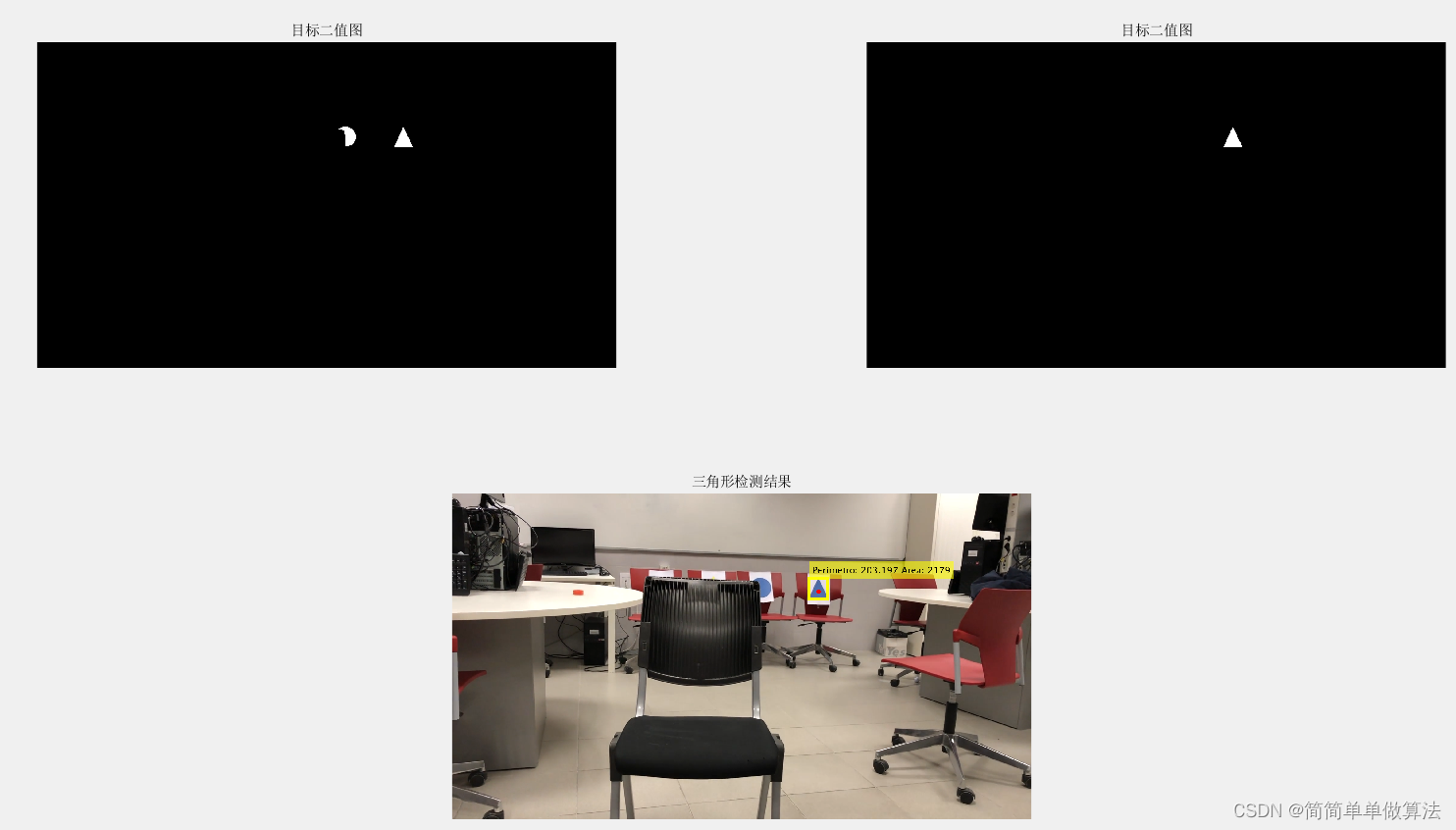
基于机器视觉工具箱和形态学处理的视频中目标形状检测算法matlab仿真
目录 1.算法理论概述 2.部分核心程序 3.算法运行软件版本 4.算法运行效果图预览 5.算法完整程序工程 1.算法理论概述 目标形状检测是计算机视觉领域的重要任务之一,旨在从视频序列中自动检测和识别特定目标的形状。本文介绍一种基于机器视觉工具箱和形态学处理…...
小白入门:sentence-transformer 提取embedding模型转onnx
文章目录 序言原理讲解哪些部分可转onnx 代码区0. 安装依赖1. 路径配置2. 测试数据3. 准备工作3.1迁移保存目标文件 4. model转onnx-gpu5. 测试一下是否出错以及速度5.1 测试速度是否OK5.2测试结果是否OK 6. tar 这些文件 序言 本文适合小白入门,以自己训练的句子e…...

数据库应用:Redis持久化
目录 一、理论 1.Redis 高可用 2.Redis持久化 3.RDB持久化 4.AOF持久化(支持秒级写入) 5.RDB和AOF的优缺点 6.RDB和AOF对比 7.Redis性能管理 8.Redis的优化 二、实验 1.RDB持久化 2.AOF持久化 3.Redis性能管理 4.Redis的优化 三、总结 一、…...
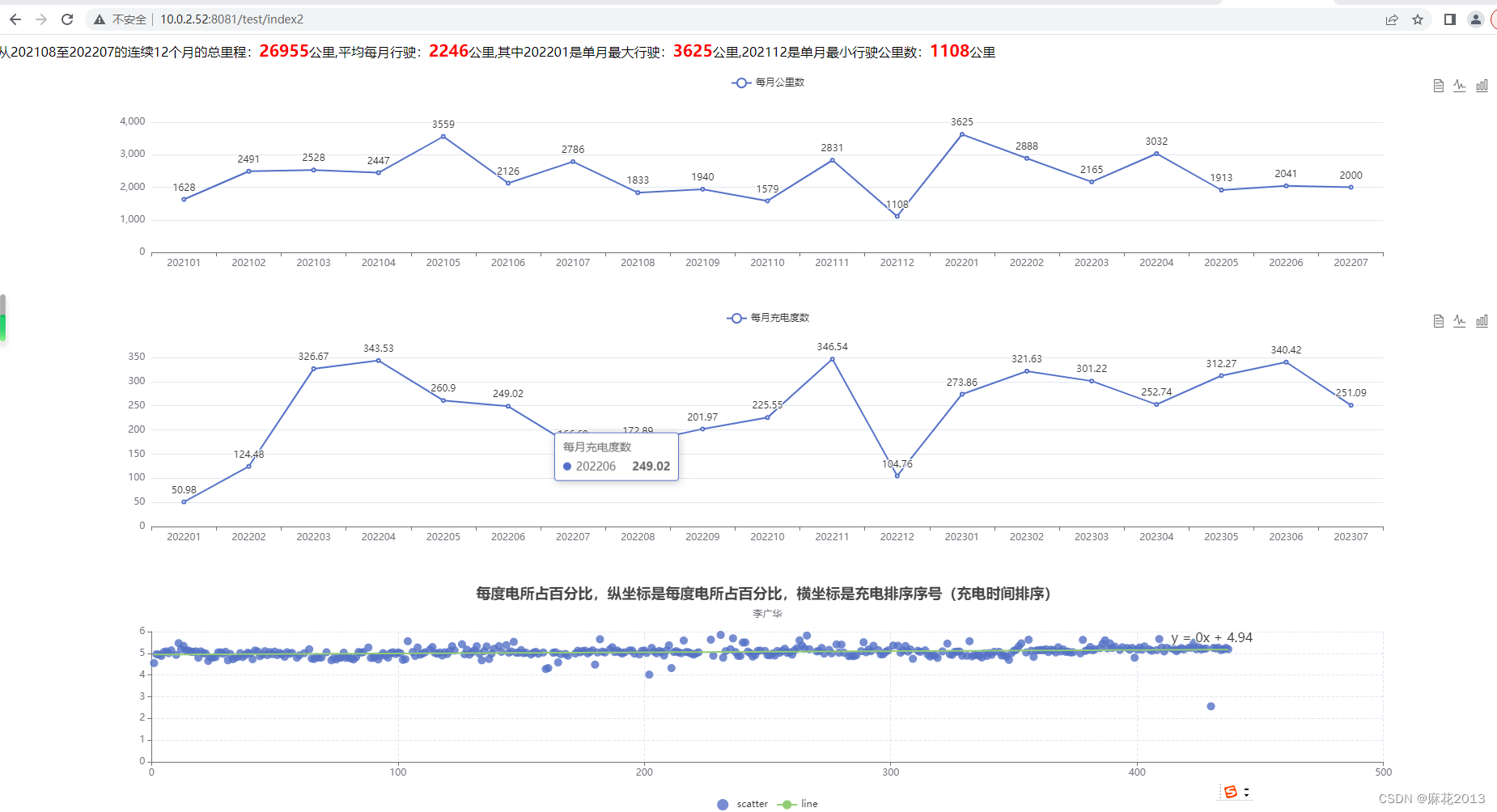
js版计算比亚迪行驶里程连续12个月计算不超3万公里改进版带echar
<!DOCTYPE html> <html lang"zh-CN" style"height: 100%"> <head> <meta charset"utf-8" /> <title>连续12个月不超3万公里计算LIGUANGHUA</title> <style> .clocks { …...
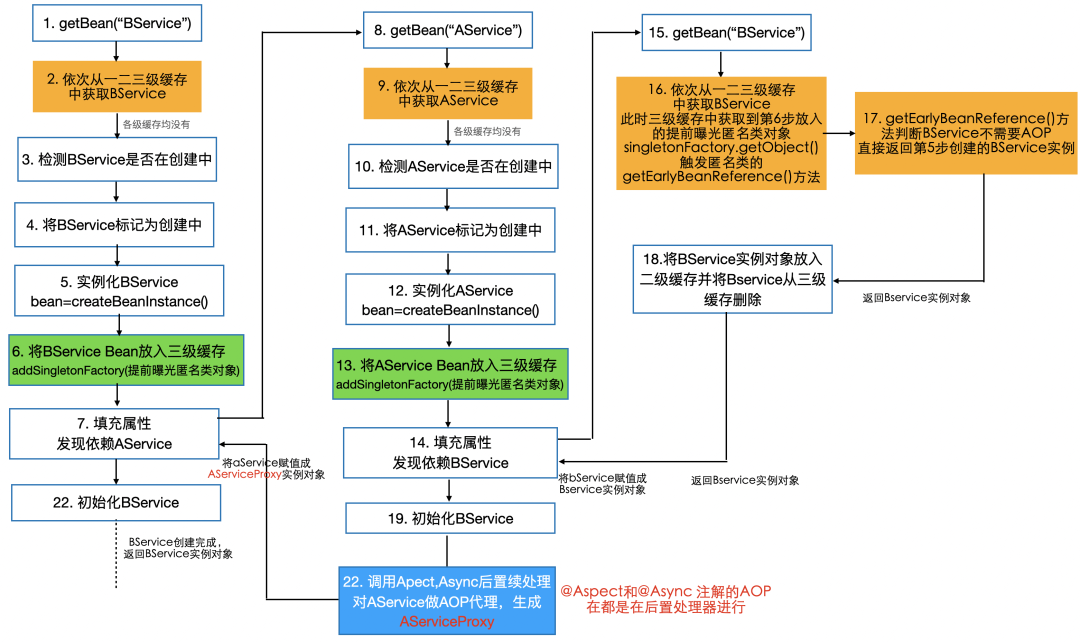
一文详解Spring Bean循环依赖
一、背景 有好几次线上发布老应用时,遭遇代码启动报错,具体错误如下: Caused by: org.springframework.beans.factory.BeanCurrentlyInCreationException: Error creating bean with name xxxManageFacadeImpl: Bean with name xxxManageFa…...
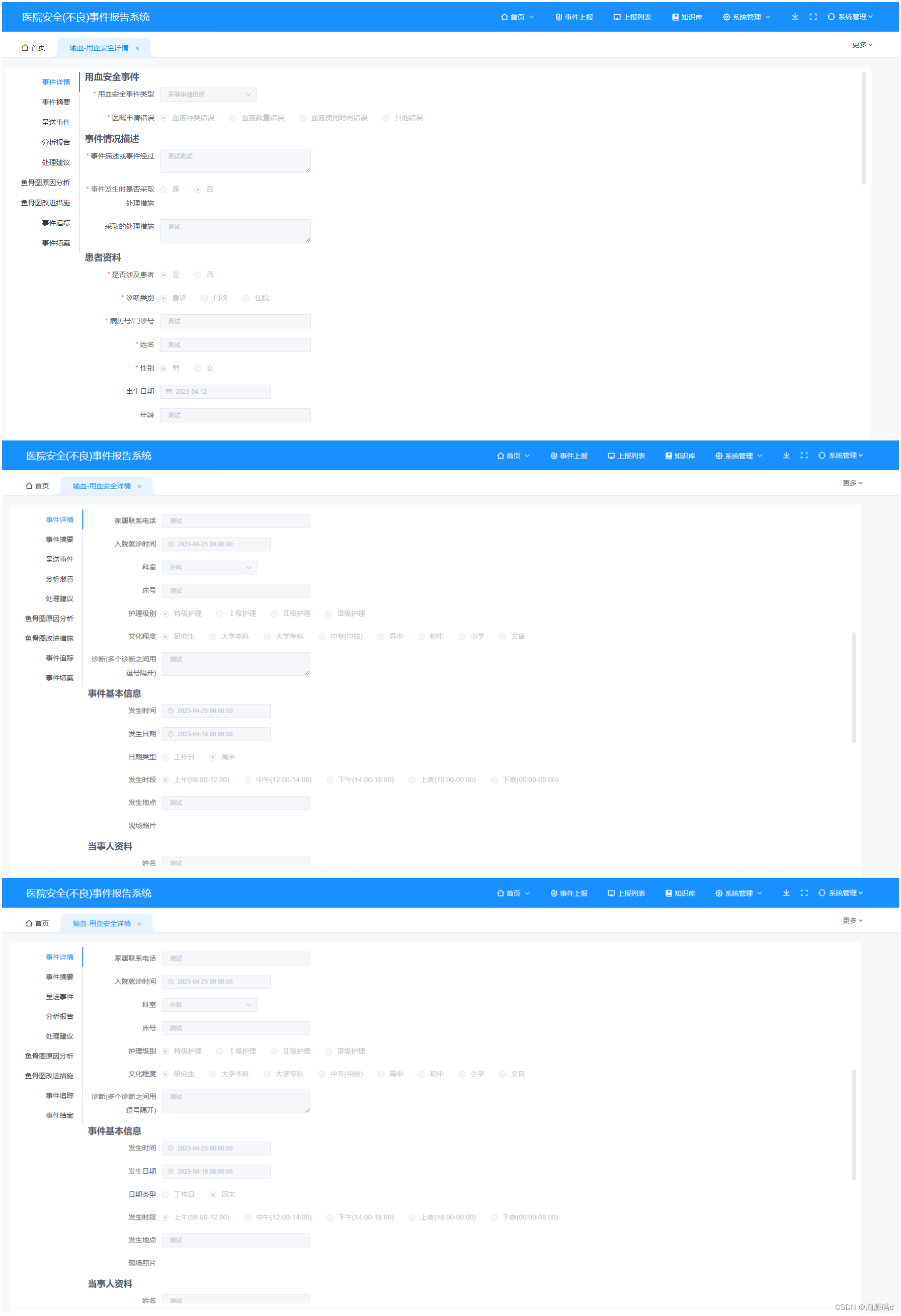
基于PHP+ vue2 + element +mysql自主研发的医院不良事件上报系统
医院不良事件上报管理系统源码 不良事件上报是为了响应卫生部下发的等级医院评审细则中第三章第9条规定:医院要有主动报告医疗安全(不良)事件的制度与工作流程。由医疗机构医院或医疗机构报告医疗安全不良事件信息,利用报告进行研…...

猫抓插件:革新性浏览器资源捕获工具,让媒体下载效率倍增
猫抓插件:革新性浏览器资源捕获工具,让媒体下载效率倍增 【免费下载链接】cat-catch 猫抓 chrome资源嗅探扩展 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 在数字内容爆炸的时代,如何高效获取网页中的视频、音频和图…...
)
手机拍照为啥总感觉差点意思?聊聊藏在ISP里的那些‘魔法’算法(从RawNR到TNR)
手机拍照为啥总感觉差点意思?聊聊藏在ISP里的那些‘魔法’算法(从RawNR到TNR) 每次看到别人用同款手机拍出的大片,再看看自己相册里灰蒙蒙的夜景照,是不是总觉得少了点什么?这背后其实藏着一整套名为ISP&am…...

2026必看:八款热门AI编程工具横评
一、AI编程工具榜单综述当下AI技术全面渗透软件开发领域,各类AI编程工具大幅降低了开发门槛、提升了编码效率,成为开发者必备的效率神器。本次横评精选海内外8款主流产品,覆盖AI原生IDE、插件式编程助手等不同形态,全方位盘点各工…...

如何高效配置Unity插件框架:BepInEx完整实战指南
如何高效配置Unity插件框架:BepInEx完整实战指南 【免费下载链接】BepInEx Unity / XNA game patcher and plugin framework 项目地址: https://gitcode.com/GitHub_Trending/be/BepInEx BepInEx是一款专为Unity游戏设计的插件框架和补丁工具,能够…...

音频标注:从原理到产业,AI听懂世界的“翻译官”
音频标注:从原理到产业,AI听懂世界的“翻译官” 引言 在人工智能的浪潮中,计算机视觉的“看”和自然语言处理的“读”已广为人知,而让机器学会“听”——理解并解析复杂的声音世界,正成为新的前沿。这一切的基石&…...

3个AI脚本让Illustrator设计效率提升300%:从重复劳动到创意爆发
3个AI脚本让Illustrator设计效率提升300%:从重复劳动到创意爆发 【免费下载链接】illustrator-scripts Adobe Illustrator scripts 项目地址: https://gitcode.com/gh_mirrors/il/illustrator-scripts 作为设计师,你是否每天花费40%以上时间在重复…...
附Matlab代码)
【图像加密解密】基于Halton 序列图像加密解密位置扰乱和像素扰乱(含相关性分析)附Matlab代码
作者简介:热爱科研的Matlab仿真开发者,擅长数据处理、建模仿真、程序设计、完整代码获取、论文复现及科研仿真关注我领取海量matlab电子书和数学建模资料 🍊个人信条:格物致知,完整Matlab代码获取及仿真咨询内容私信。ὒ…...
)
别再纠结模型了!用Python+Simulink快速搭建四旋翼无人机仿真(附完整代码)
用PythonSimulink快速搭建四旋翼无人机仿真实战指南 四旋翼无人机开发中最令人头疼的环节,往往不是控制算法设计,而是如何快速搭建一个可靠的仿真环境。我曾见过不少团队在模型选择上耗费数周时间,最终却陷入理论完美主义陷阱——他们反复纠结…...

【生产环境实录】Mojo嵌入Python解释器时core dump突增300%:我们如何通过LLVM IR层Hook定位并修复内存所有权越界
第一章:【生产环境实录】Mojo嵌入Python解释器时core dump突增300%:我们如何通过LLVM IR层Hook定位并修复内存所有权越界问题现象与紧急响应 上线后72小时内,Mojo服务在调用 PyRun_String 执行动态Python代码片段时,core dump率从…...

避开这些坑!高德DragRoute插件获取路线坐标的5个常见问题解决方案
高德地图DragRoute插件实战:路线坐标获取的深度避坑指南 当开发者需要在地图上绘制复杂路线时,高德地图的DragRoute插件无疑是个强大工具。但在实际项目中,从简单的A到B路径绘制,到包含多个途经点的复杂路线坐标获取,开…...