数据库应用:Redis持久化
目录
一、理论
1.Redis 高可用
2.Redis持久化
3.RDB持久化
4.AOF持久化(支持秒级写入)
5.RDB和AOF的优缺点
6.RDB和AOF对比
7.Redis性能管理
8.Redis的优化
二、实验
1.RDB持久化
2.AOF持久化
3.Redis性能管理
4.Redis的优化
三、总结
一、理论
1.Redis 高可用
(1)概念
在web服务器中,高可用是指服务器可以正常访问的时间,衡量的标准是在多长时间内可以提供正常服务(99.9%、99.99%、99.999%等等)。
但是在Redis语境中,高可用的含义似乎要宽泛一些,除了保证提供正常服务( 如主从分离、快速容灾技术),还需要考虑数据容量的扩展、数据安全不会丢失等。
(2)Redis的高可用技术
在Redis中,实现高可用的技术主要包括持久化、主从复制、哨兵和cluster集群,下面分别说明它们的作用,以及解决了什么样的问题。
①持久化: 持久化是最简单的高可用方法(有时甚至不被归为高可用的手段),主要作用是数据备份,即将数据存储在硬盘,保证数据不会因进程退出而丢失。
②主从复制: 主从复制是高可用Redis的基础,哨兵和集群都是在主从复制基础上实现高可用的。主从复制主要实现了数据的多机备份(和同步),以及对于读操作的负载均衡和简单的故障恢复。
缺陷:故障恢复无法自动化;写操作无法负载均衡;存储能力受到单机的限制。
③哨兵: 在主从复制的基础上,哨兵实现了自动化的故障恢复。(主挂了,找一个从成为新的主,哨兵节点进行监控)
缺陷: 写操作无法负载均衡;存储能力受到单机的限制。
④Cluster集群: 通过集群,Redis解决了写操作无法负载均衡,以及存储能力受到单机限制的问题,实现了较为完善的高可用方案。(6台起步,成双成对,3主3从)
2.Redis持久化
(1)持久化的功能
① 持久化的功能: Redis是内存数据库,数据都是存储在内存中,为了避免服务器断电等原因导致Redis进程异常退出后数据的永久丢失,需要定期将Redis中的数据以某种形式(数据或命令)从内存保存到硬盘;当下次Redis重启时,利用持久化文件实现数据恢复。除此之外,为了进行灾难备份,可以将持久化文件拷贝到一个远程位置。
② 灾难备份: 一般做异地备份,发生灾难后切换节点。例如本来使用上海的数据库,现在使用切换到重庆的。
(2)两种持久化方式
① RDB持久化:原理是将Reids在内存中的数据库记录定时保存到磁盘上。(定时对内存中的数据生成快照,以文件形式保存在硬盘中)
② AOF持久化(append only file):原理是将Reids 的操作日志以追加的方式写入文件,类似于MySQL的binlog。(类似于Mysql的二进制日志)(以追加的方式将写和删的操作命令记录到AOF文件中)
由于AOF持久化的实时性更好,即当进程意外退出时丢失的数据更少,因此AOF是目前主流的持久化方式,不过RDB持 久化仍然有其用武之地。(RDB体积小,恢复速度更快。对性能影响较小。)
3.RDB持久化
(1)概念
RDB持久化是指在指定的时间间隔内将内存中当前进程中的数据生成快照保存到硬盘(因此也称作快照持久化),用二进制压缩存储,保存的文件后缀是rdb;当Redis重新启动时,可以读取快照文件恢复数据。
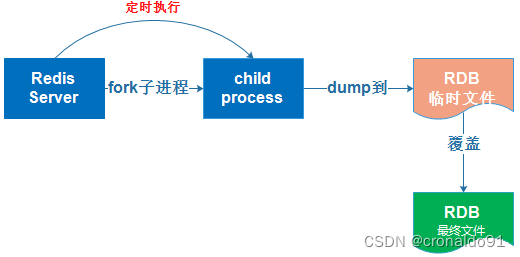
在 Redis 运行时, RDB 将当前内存中的数据库生成一个 Snapshot 快照保存到磁盘文件中, 在 Redis 重启动时, RDB 可以通过载入 RDB 文件来还原数据库的状态。
(2)触发条件
RDB持久化的触发分为手动触发和自动触发两种。
①手动触发
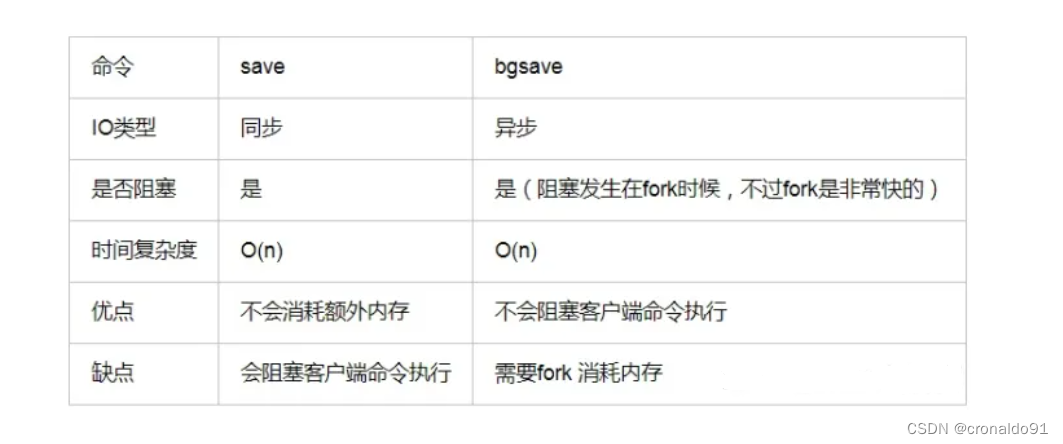
1)save命令和bgsave命令都可以生成RDB文件。
2)save命令会阻塞Redis服务器进程,直到RDB文件创建完毕为止,在Redis服务器阻塞期间,服务器不能处理任何命令请求。
而bgsave命令会创建一个子进程,由子进程来负责创建RDB文件,父进程(即Redis主进程)则继续处理请求。
3)bgsave命令执行过程中,只有fork子进程时会阻塞服务器,而对于save命令,整个过程都会阻塞服务器,因此save已基本被废弃,线上环境要杜绝save的使用。
区别如下:
②自动触发
在自动触发RDB持久化时,Redis 也会选择bgsave而不是save来进行持久化。
自动触发最常见的情况是在配置文件中通过 save m n 指定当m秒内发生n次变化时,会触发bgsave。
vim /etc/redis/6379.conf #编辑配置文件----219行--以下三个save条件满足任意一一个时,都会引起bgsave的调用save 900 1 #当时间到900秒时,如果redis数据发生了至少1次变化,则执行bgsavesave 300 10 #当时间到300秒时,如果redis数据发生了至少10次变化,则执行bgsavesave 60 10000 #当时间到60秒时,如果redis数据发生了至少10000次变化, 则执行bgsave----242行--是否开启RDB文件压缩rdbcompression yes----254行--指定RDB文件名dbfilename dump.rdb----264行--指定RDB文件和AOF文件所在目录dir /var/lib/redis/6379
由此可看出RDB持久化的问题:
实时性不够,最快也要60秒备份一次,如果50多秒时服务器宕机,则备份失败。
③ 其他自动触发机制
除了savemn以外,还有一些其他情况会触发bgsave:
1)在主从复制场景下,如果从节点执行全量复制操作,则主节点会执行bgsave命令,并将rdb文件发送给从节点。
2)执行shutdown命令时,自动执行rdb持久化。
(3)bgsave执行流程
①Redis父进程首先判断:当前是否在执行save,或 bgsave/ bgrewriteaof 的子进程,如果在执行则bgsave命令直接返回。
bgsave/bgrewriteaof 的子进程不能同时执行,主要是基于性能方面的考虑:两个并发的子进程同时执行大量的磁盘写操作,可能引起严重的性能问题。
②父进程执行fork操作创建子进程,这个过程中父进程是阻塞的,Redis不能执行来自客户端的任何命令。
③父进程fork后,bgsave 命令返回"Background saving started" 信息并不再阻塞父进程,并可以响应其他命令。
④子进程创建RDB文件,根据父进程内存快照生成临时快照文件,完成后对原有文件进行原子替换。(原子替换:文件整体替换,要么都发生,要么都不发生)
⑤子进程发送信号给父进程表示完成,父进程更新统计信息。

(4)启动时加载
① RDB文件的载入工作是在服务器启动时自动执行的,并没有专门的命令。但是由于AOF的优先级更高,因此当AOF开启时,Redis会优先载入AOF文件来恢复数据;只有当AOF关闭时,才会在Redis服务器启动时检测RDB文件,并自动载入。 服务器载入RDB文件期间处于阻塞状态,直到载入完成为止。
② Redis载入RDB文件时,会对RDB文件进行校验,如果文件损坏,则日志中会打印错误,Redis启动失败。
4.AOF持久化(支持秒级写入)
(1)概念
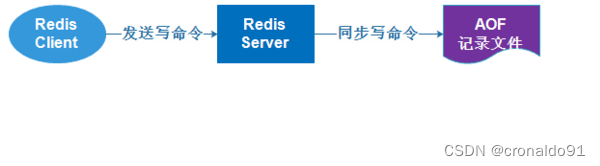
① RDB持久化是将进程数据写入文件,而AOF持久化,则是将Redis执行的每次写、删除命令记录到单独的日志文件中,查询操作不会记录。
② 当Redis重启时再次执行AOF文件中的命令来恢复数据。(重放命令进行恢复)
③ 与RDB相比,AOF的实时性更好, 因此已成为主流的持久化方案。
(2)开启AOF
Redis服务器默认开启RDB,关闭AOF的, 要开启AOF,需要在 /etc/redis/6379.conf 配置文件中配置。
vim /etc/redis/6379.conf----700行---修改,开启AOFappendonly yes----704行---指定AOF文件名称appendfilename "appendonly.aof"----796行---是否忽略最后一条可能存在问题的指令aof-load-truncated yes #Redis恢复时,发现AOF文件的末尾被截断了,会忽略最后一条可能存在问题的指令。默认值yes。即在aof写入时,可能发生redis机器运行崩溃,AOF文件的末尾被截断了,这种情况下,yes会继续执行并恢复尽量多的数据,而no会直接恢复失败报错退出。/etc/init.d/redis_6379 restart #重启redisls /var/lib/redis/6379/ #查看是否生成了aof文件
(3)执行流程
由于需要记录Redis的每条写命令,因此AOF不需要触发,下面介绍AOF的执行流程。
AOF的执行流程包括:
表1 AOF的执行流程
| 序号 | 流程 | 描述 |
| 1 | 命令追加(append) | 将Redis的写 命令追加到缓冲区aof_ buf |
| 2 | 文件写入(write)和文件同步(sync) | 根据不同的同步策略将aof_buf中的内容同步到硬盘 |
| 3 | 文件重写(rewrite) | 定期重写AOF文件,达到压缩的目的。(将过期数据、无效命令、多条命令,进行压缩或删除) |
① 命令追加(append)
1)Redis先将写命令追加到缓冲区,而不是直接写入文件,主要是为了避免每次有写命令都直接写入硬盘,导致硬盘IO成为Redis负载的瓶颈。
2)命令追加的格式是Redis命令请求的协议格式,它是一种纯文本格式,具有兼容性好、可读性强、容易处理、操作简单避免二次开销等优点。
3)在AOF文件中,除了用于指定数据库的select命令(如select 0为选中0号数据库)是由Redis添加的, 其他都是客户端发送来的写命令。
② 文件写入(write)和文件同步(sync)
Redis提供了多种AOF缓存区的同步文件策略,策略涉及到操作系统的write函数和fsync函数,说明如下:
1)为了提高文件写入效率,在现代操作系统中,当用户调用write函数将数据写入文件时,操作系统通常会将数据暂存到一个内存缓冲区里,当缓冲区被填满或超过了指定时限后,才真正将缓冲区的数据写入到硬盘里。
2)这样的操作虽然提高了效率,但也带来了安全问题:如果计算机停机,内存缓冲区中的数据会丢失。因此系统同时提供了fsync、fdatasync等同步函数,可以强制操作系统立刻将缓冲区中的数据写入到硬盘里,从而确保数据的安全性。
AOF缓存区的同步文件策略存在三种同步方式,它们分别是:
表2 AOF缓存区的同步文件策略
| 序号 | 策略 | 描述 |
| 1 | appendfsync always | 命令写入aof_buf后立即调用系统fsync操作同步到AOF文件。安全性高,性能低。 |
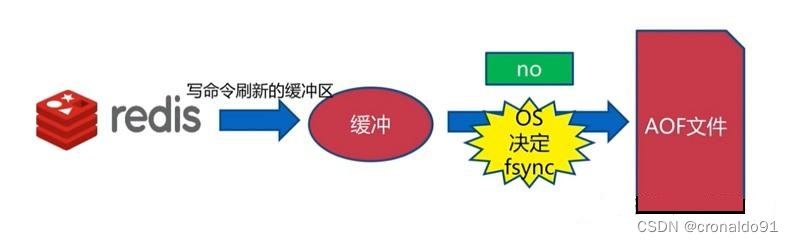
| 2 | appendfsync no | 当缓冲区被填满或超过了指定时限后(默认30秒),才将缓冲区的数据写入到硬盘里。性能高,但安全性低。 |
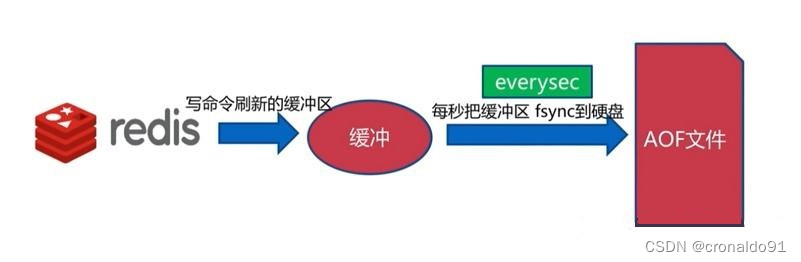
| 3 | appendfsync everysec | 每秒同步一次,是性能和数据安全性的平衡,因此是Redis的默认配置。 |
vim /etc/redis/6379.conf----729行----729 # appendfsync always730 appendfsync everysec731 # appendfsync no------------------------以下是注释----------------------------------------------------● appendfsync always:#命令写入aof_buf后立即调用系统fsync操作同步到AOF文件,fsync完成后线程返回。这种情况下,每次有写命令都要同步到AOF文件,硬盘IO成为性能瓶颈,Redis只能支持大约几百TPS写入,严重降低了Redis的性能;即便是使用固态硬盘(SSD) ,每秒大约也只能处理几万个命令,而且会大大降低SSD的寿命。(安全性高,性能低。)● appendfsync no:#命令写入aof_buf后调用系统write操作,不对AOF文件做fsync同步;同步由操作系统负责,通常同步周期为30秒。这种情况下,文件同步的时间不可控,且缓冲区中堆积的数据会很多,数据安全性无法保证。(当缓冲区被填满或超过了指定时限后,才将缓冲区的数据写入到硬盘里。性能高,但安全性低。)● appendfsync everysec:#命令写入aof_buf后调用系统write操作,write完成后线程返回; fsync同步文件操作由专门的线程每秒调用一次。everysec是前述两种策略的折中,是性能和数据安全性的平衡,因此是Redis的默认配置,也是我们推荐的配置。(同时保证了数据安全和性能的需求)
【1】always: 每次写入一条数据就立即将这个数据对应的写日志 fsync 到磁盘上去,虽然可以确保 Redis 里的数据一条都不丢,但是性能非常差,吞吐量很低。

【2】everysec:每秒将缓冲中的数据 fsync 到磁盘,这个比较最常用的,生产环境一般都这么配置,而且性能很高。但是缺点就是不像 always 那样保证每个命令都会记录,Redis 服务器出现故障有可能会丢失一秒钟的数据。
【3】no: 仅仅 redis 负责将数据写入缓冲区,什么时候刷新到磁盘中是根据操作系统自己决定。这种一般不会使用。
【4】三种策略对比

③文件重写(rewrite)
1) 概念
【1】随着时间流逝,Redis服务器执行的写命令越来越多,AOF文件也会越来越大;过大的AOF文件不仅会影响服务器的正常运行,也会导致数据恢复需要的时间过长。
【2】文件重写是指定期重写AOF文件,减小AOF文件的体积。需要注意的是,AOF 重写是把Redis进程内的数据转化为写命令,同步到新的AOF文件;不会对旧的AOF文件进行任何读取、写入操作!
【3】关于文件重写需要注意的另一点是:对于AOF持久化来说,文件重写虽然是强烈推荐的,但并不是必须的;即使没有文件重写,数据也可以被持久化并在Redis启动的时候导入。因此在一些现实中,会关闭自动的文件重写,然后通过定时任务在每天的某一时刻定时执行。
注意:
重写会消耗性能,影响业务,不能在业务高峰期进行重写。所以一般会关闭自动重写,由定时任务在每天的某一时刻定时执行重写功能。
2)文件重写能够压缩AOF文件
原因在于:
表3 重写压缩AOF文件
| 序号 | 原因 |
| 1 | 过期的数据不再写入文件。 |
| 2 | 无效的命令不再写入文件:如有些数据被重复设值(set mykey v1, set mykey v2)、 有些数据被删除了(set myset vl, del myset)等。 |
| 3 | 多条命令可以合并为一个:如sadd myset v1, sadd myset v2, sadd myset v3可以合并为sadd myset v1 v2 v3。(sadd添加集合) |
rewrite之后aof文件会保存keys的最后状态,清除掉之前冗余的,来缩小这个文件。
通过上述内容可以看出,由于重写后AOF执行的命令减少了,文件重写既可以减少文件占用的空间,也可以加快恢复速度。
3)文件重写的触发
分为手动触发和自动触发:
表4 文件重写触发
| 序号 | 除法类型 | 描述 |
| 1 | 手动触发 | 直接调用bgrewriteaof命令,该命令的执行与bgsave有些类似:都是fork子进程进行具体的工作,且都只有在fork时阻塞。 |
| 2 | 自动触发 | 通过设置auto-aof-rewrite-min-size选项和auto-aof-rewrite-percentage选项来自动执行BGREWRITEAOF。 只有当auto-aof-rewrite-min-size和auto-aof-rewrite-percentage两个选项同时满足时,才会自动触发AOF重写,即bgrewriteaof操作。 |
vim /etc/redis/6379.conf----771行----771 auto-aof-rewrite-percentage 100772 auto-aof-rewrite-min-size 64mb-----------------------以下是注释--------------------------------● auto-aof-rewrite-percentage 100 #文件的大小超过基准百分之多少后触发bgrewriteaof。默认这个值设置为100,意味着当前aof是基准大小的两倍的时候触发bgrewriteaof。把它设置为0可以禁用自动触发的功能。#即当前AOF文件大小(即aof_current_size)是上次日志重写时AOF文件大小(aof_base_size)两倍时,发生BGREWRITEAOF操作。#注意:例如上次文件达到100M进行重写,那么这次需要达到200M时才进行重写。文件需要越来越大,所以一般不使用自动重写。如果使用自动重写,需要定期手动重写干预一次,让文件要求恢复到100M。● auto-aof-rewrite-min-size 64mb #当文件大于64M时才会进行重写#当前aof文件大于多少字节后才触发。#当前AOF文件执行BGREWRITEAOF命令的最小值,避免刚开始启动Reids时由于文件尺寸较小导致频繁的BGREWRITEAOF
4)关于文件重写的流程有两点需要特别注意:
【1】重写由父进程fork子进程进行。
【2】重写期间Redis执行的写命令,需要追加到新的AOF文件中,为此Redis引入了aof_rewrite_buf缓存。
5)文件重写的流程如下
表5 文件重写流程
| 序号 | 详细流程 |
| (1) | Redis父进程首先判断当前是否存在正在执行bgsave/bgrewriteaof的子进程,如果存在则bgrewriteaof命令直接返回,如果存在bgsave命令则等bgsave执行完成后再执行。(正常情况下使用AOF就会使用AOF进行记录,不会使用RDB。主从复制时会自动触发bgsave命令) |
| (2) | 父进程执行fork操作创建子进程,这个过程中父进程是阻塞的(无法接受任何客户端的请求)。 |
| (3.1) | 父进程fork后,bgrewriteaof 命令返回"Background append only file rewrite started" 信息并不再阻塞父进程,并可以响应其他命令。Redis的所有写命令依然写入AOF缓冲区,并根据appendfsync策略同步到硬盘,保证原有AOF机制的正确。 |
| (3.2) | 由于fork操作使用写时复制技术,子进程只能共享fork操作时的内存数据。由于父进程依然在响应命令,因此Redis使用AOF重写缓冲区(aof_rewrite_ buf)保存这部分数据,防止新AOF文件生成期间丢失这部分数据。也就是说,bgrewriteaof执行期间,Redis的写命令同时追加到aof_ buf和aof_rewirte_ buf两个缓冲区。(保证新写入的数据不丢失) |
| (4) | 子进程根据内存快照,按照命令合并规则写入到新的AOF文件。 |
| (5.1) | 子进程写完新的AOF文件后,向父进程发信号,父进程更新统计信息,具体可以通过info persistence查看。 |
| (5.2) | 父进程把AOF重写缓冲区的数据写入到新的AOF文件,这样就保证了新AOF文件所保存的数据库状态和服务器当前状态一致。 |
| (5.3) | 使用新的AOF文件替换老文件,完成AOF重写。(替换是原子性的) |
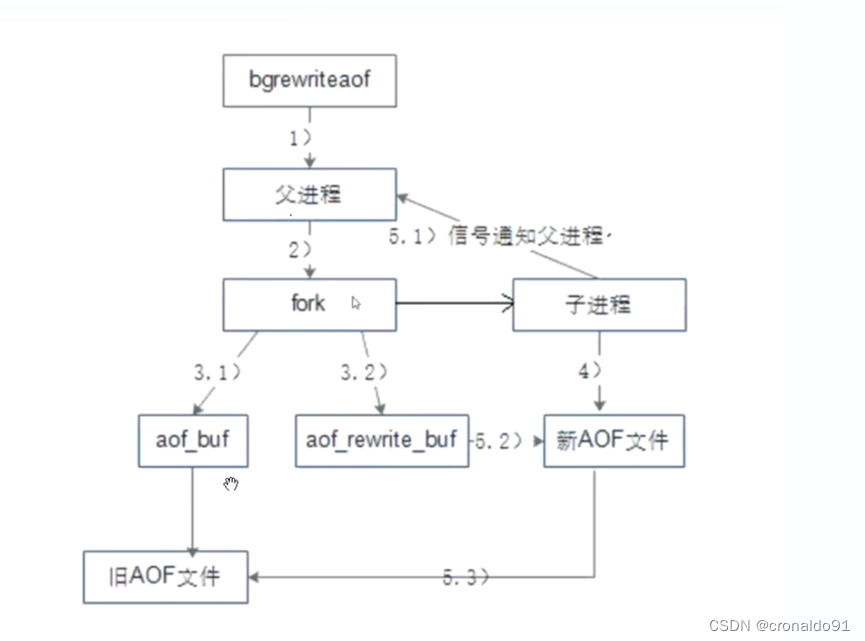
(4)启动时加载
① 当AOF开启时,Redis启动时会优先载入AOF文件来恢复数据;只有当AOF关闭时,才会载入RDB文件恢复数据。
② 当AOF开启,但AOF文件不存在时,即使RDB文件存在也不会加载。
③ Redis载入AOF文件时,会对AOF文件进行校验,如果文件损坏,则日志中会打印错误,Redis启动失败。但如果是AOF文件结尾不完整(机器突然宕机等容易导致文件尾部不完整),且aof-load-truncated参数开启,则日志中会输出警告,Redis忽略掉AOF文件的尾部,启动成功。aof-load-truncated参数默认是开启的。
5.RDB和AOF的优缺点
(1) RDB持久化的优缺点
① 优点:
RDB文件紧凑,体积小,网络传输快,适合全量复制;恢复速度比AOF快很多。当然,与AOF相比, RDB最 重要的优点之一是对性能的影响相对较小。(体积小,恢复速度更快,对性能影响较小。)
② 缺点:
RDB文件的致命缺点在于其数据快照的持久化方式决定了必然做不到实时持久化,而在数据越来越重要的今天,数据的大量丢失很多时候是无法接受的,因此AOF持久化成为主流。
此外,RDB文 件需要满足特定格式,兼容性差(如老版本的Redis不兼容新版本的RDB文件)。
对于RDB持久化,一方面是bgsave在进行fork操作时Redis主进程会阻塞,另一方面,子进程向硬盘写数据也会带来IO压力。
(实时性差、兼容性差、在fork子进程时会阻塞父进程。)
(2) AOF持久化的优缺点
① 与RDB持久化相对应,AOF的优点在于支持秒级持久化、实时性好、兼容性好,缺点是文件大、恢复速度慢、对性能影响大。
② 对于AOF持久化,向硬盘写数据的频率大大提高(everysec策略下为秒级),IO压力更大,甚至可能造成AOF追加阻塞问题。
③ AOF文件的重写与RDB的bgsave类似,会有fork时的阻塞和子进程的Io压力问题。相对来说,由于AOF向硬盘中写数据的频率更高,因此对Redis主进程性能的影响会更大。
6.RDB和AOF对比
(1)持久化对比
表6 持久化对比
| RDB持久化 | AOF持久化 |
|---|---|
| 全量备份,一次保存整个数据库。 | 增量备份,一次只保存一个修改数据库的命令。 |
| 每次执行持久化操作的间隔时间较长。 | 保存的间隔默认为一秒钟(Everysec) |
| 数据保存为二进制格式,其还原速度快。 | 使用文本格式还原数据,所以数据还原速度一般。 |
| 执行 SAVE 命令时会阻塞服务器,但手动或者自动触发的 BGSAVE 不会阻塞服务器 | AOF持久化无论何时都不会阻塞服务器。 |
7.Redis性能管理
(1)查看Redis内存使用
方法一:进入redis数据库查看redis-cli127.0.0.1:6379> info memory方法二:命令行查看redis-cli info memory | grep ratio
(2)内存碎片
① 内存碎片率如何计算:
内存碎片率=Redis向操作系统申请的内存 / Redis中的数据占用的内存
mem_fragmentation_ratio = used_memory_rss / used_memory
mem_fragmentation_ratio:内存碎片率。
used_memory_rss:是Redis向操作系统申请的内存。
used_memory:是Redis中的数据占用的内存。
used_memory_peak:redis内存使用的峰值。
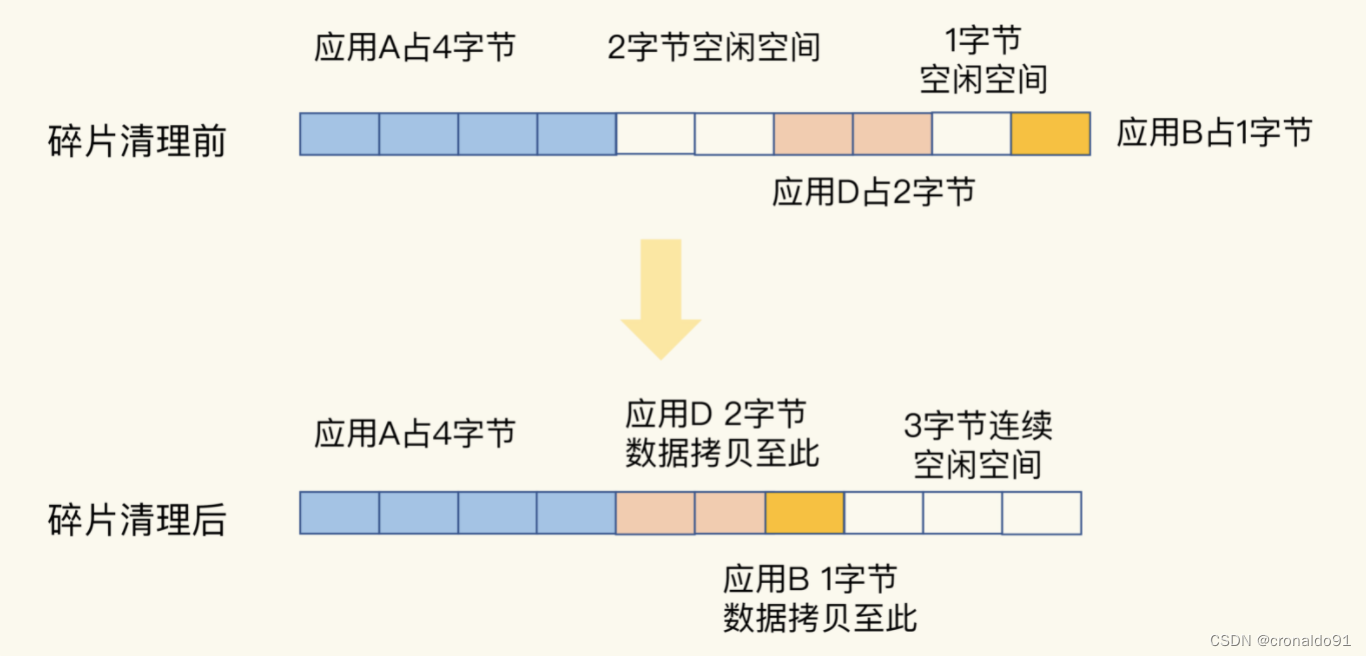
②内存碎片产生原因
1) Redis内部有自已的内存管理器,为了提高内存使用的效率,来对内存的申请和释放进行管理。
2) Redis中的值删除的时候,并没有把内存直接释放、交还给操作系统,而是交给了Redis内部有内存管理器。
3) Redis中申请内存的时候,也是先看自己的内存管理器中是否有足够的内存可用。
4) Redis的这种机制,提高了内存的使用率,但是会使Redis中有部分自己没在用,却不释放的内存,导致了内存碎片的发生。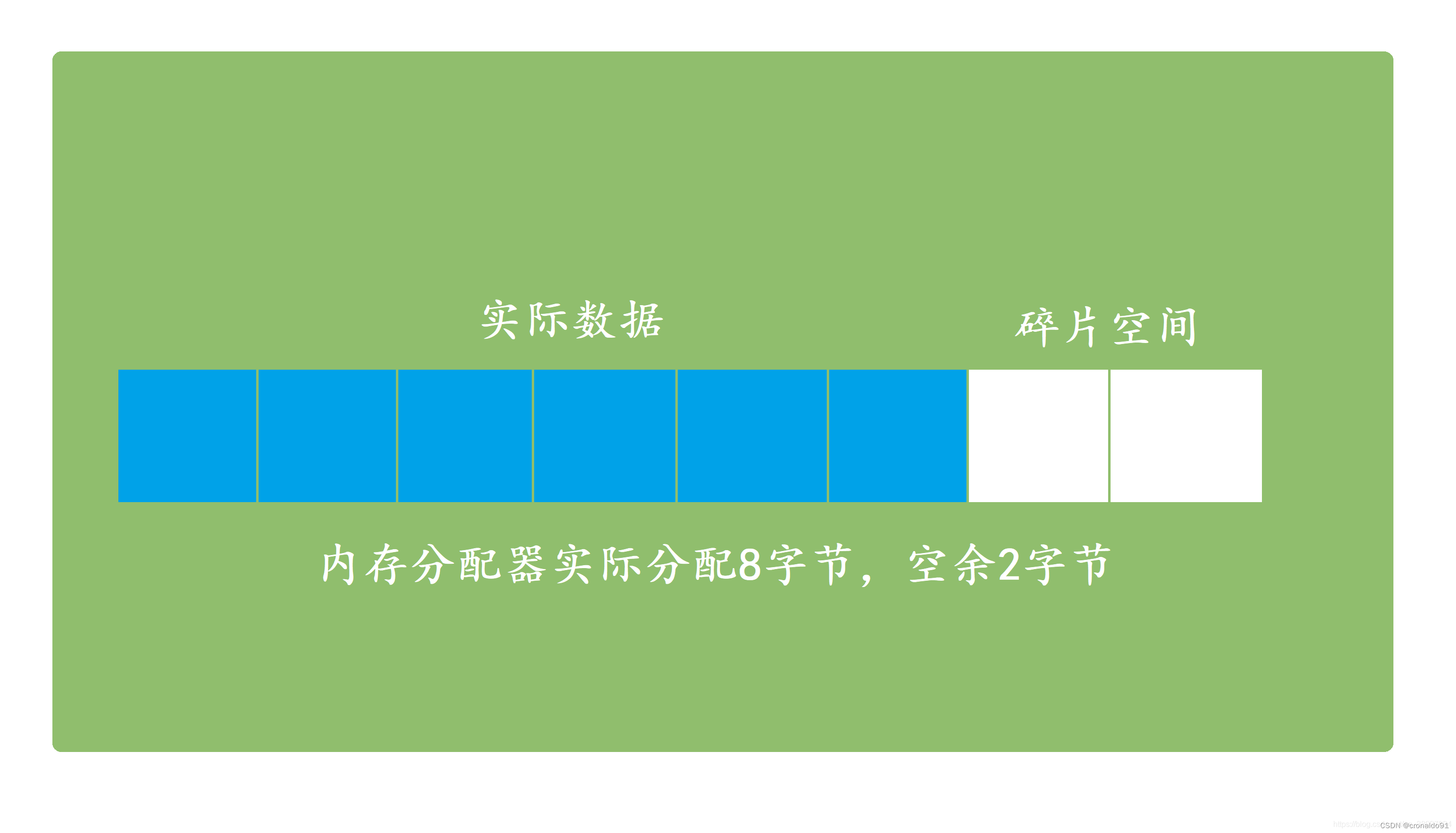
③跟踪内存碎片率
跟踪内存碎片率,对理解Redis实例的资源性能是非常重要的:
1) 内存碎片率在1到1.5之间是正常的,这个值表示内存碎片率比较低,也说明Redis 没有发生内存交换。
2) 内存碎片率超过1.5,说明Redis消耗了实际需要的物理内存的150%,其中50%是内存碎片率。
3)内存碎片率低于1的,说明Redis内存分配超出了物理内存,操作系统正在进行内存交换(使用虚拟内存,会降低性能)。需要增加可用物理内存或减少Redis内存占用。
④ 解决碎片率大的问题
1) 如果你的Redis版本是4.0以下的,需要在redis-cli 工具上输入shutdown save命令,让Redis数据库执行保存操作并关闭Redis服务,再重启服务器。Redis服务器重启后,Redis 会将没用的内存归还给操作系统,碎片率会降下来。
2) Redis4.0版本开始,可以在不重启的情况下,线上整理内存碎片,将未使用的内存归还给操作系统。
config set activedefrag yes #自动碎片清理memory purge #手动碎片清理
(3)内存使用率
redis实例的内存使用率超过可用最大内存,操作系统将开始进行内存与swap空间交换。
1)避免内存交换发生的方法:
【1】针对缓存数据大小选择安装Redis 实例
【2】尽可能的使用Hash数据结构存储
【3】设置key的过期时间
2) 内回收key
内存清理策略,保证合理分配redis有限的内存资源。
当内存使用达到设置的最大阀值时,需选择一种key的回收策略,默认情况下回收策略是禁止删除(noenviction)。
配置文件中修改 maxmemory-policy 属性值:
vim /etc/redis/6379.conf---599行----maxmemory-policy noenviction #修改max-memory-policy属性值##回收策略有以下几种:##●volatile-lru#使用LRU算法从已设置过期时间的数据集合中淘汰数据(移除最近最少使用的key,针对设置了TTL的key)●volatile-ttl#从已设置过期时间的数据集合中挑选即将过期的数据淘汰(移除最近过期的key)●volatile-random#从已设置过期时间的数据集合中随机挑选数据淘汰(在设置了TTL的key里随机移除)●allkeys-lru#使用LRU算法 从所有数据集合中淘汰数据(移除最少使用的key,针对所有的key)●allkeys-random#从数据集合中任意选择数据淘汰(随机移除key)●noenviction#禁止淘汰数据(不删除直到写满时报错)
8.Redis的优化
设置客户端连接超时时间、客户端最大连接数、自动碎片清理、最大内存阀值、key回收策略。
(1)设置Redis客户端连接的超时时间
vim /etc/redis/6379.conf-----114行------114 timeout 0 #单位为秒(s),取值范围为0~100000。默认值为0,表示无限制,即Redis不会主动断开连接,即使这个客户端已经空闲了很长时间。#例如可设置为600,则客户端空闲10分钟后,Redis会主动断开连接。#注意:在实际运行中,为了提高性能,Redis不一定会精确地按照timeout的值规定的时间来断开符合条件的空闲连接,例如设置timeout为10s,但空闲连接可能在12s后,服务器中新增很多连接时才会被断开。
(2)设置 redis客户端最大连接数
1)redis客户端最大连接数默认为10000。
vim /etc/redis/6379.conf-----540行------540 # maxclients 10000 #若不设置,默认是10000
2)查看 redis 当前连接数:
[root@localhost ~]# redis-cli127.0.0.1:6379> info clients #查看redis当前连接数# Clientsconnected_clients:1 #redis当前连接数的为1 client_recent_max_input_buffer:2client_recent_max_output_buffer:0blocked_clients:0
3)查看 redis 允许的最大连接数:
127.0.0.1:6379> config get maxclients1) "maxclients" 2) "10000" #redis允许的最大连接数默认为10000
(3)设置redis自动碎片清理
config set activedefrag yes #自动碎片清理memory purge #手动碎片清理
(4)设置redis最大内存阀值
内存阀值如果不设置,则没有限制,直到把服务器的内存干满、之后会使用交换分区。
设置内存阀值后,不会使用swap交换分区。且如果设置了key回收策略,当内存使用达到设置的最大阀值时,系统会进行key回收。
vim /etc/redis/6379.conf-----567行------567 # maxmemory <bytes>568 maxmemory 1gb #例如设置最大内存阀值为1gb
(5)设置key回收策略
当内存使用达到设置的最大阀值时,需选择一种key的回收策略,默认情况下回收策略是禁止删除(noenviction)。
设置key回收策略后,则当redis内存使用达到设置的最大阀值时,系统会进行key回收,释放一部分内存。
vim /etc/redis/6379.conf---599行----maxmemory-policy noenviction #需要修改max-memory-policy属性值##回收策略有以下几种:##●volatile-lru#使用LRU算法从已设置过期时间的数据集合中淘汰数据(移除最近最少使用的key,针对设置了TTL的key)●volatile-ttl#从已设置过期时间的数据集合中挑选即将过期的数据淘汰(移除最近过期的key)●volatile-random#从已设置过期时间的数据集合中随机挑选数据淘汰(在设置了TTL的key里随机移除)●allkeys-lru#使用LRU算法 从所有数据集合中淘汰数据(移除最少使用的key,针对所有的key)●allkeys-random#从数据集合中任意选择数据淘汰(随机移除key)●noenviction#禁止淘汰数据(不删除直到写满时报错)
二、实验
1.RDB持久化
(1)自动触发
在自动触发RDB持久化时,Redis 也会选择bgsave而不是save来进行持久化。
自动触发最常见的情况是在配置文件中通过 save m n 指定当m秒内发生n次变化时,会触发bgsave。

当时间到900秒时,如果redis数据发生了至少1次变化,则执行bgsave;
当时间到300秒时,如果redis数据发生了至少10次变化,则执行bgsave;
当时间到60秒时,如果redis数据发生了至少10000次变化, 则执行bgsave。

开启RDB文件压缩

指定RDB文件名

重启后查看是否生成了rdb文件

2.AOF持久化
(1)自动触发

开启AOF

指定AOF文件名称

是否忽略最后一条可能存在问题的指令

重启后 查看是否生成了aof文件
(2)AOF缓存区的同步文件策略

(3)文件重写的触发
文件的大小超过基准百分之100后触发bgrewriteaof。
当文件大于64M时才会进行重写

3.Redis性能管理
(1)查看Redis内存使用
方法一:进入redis数据库查看
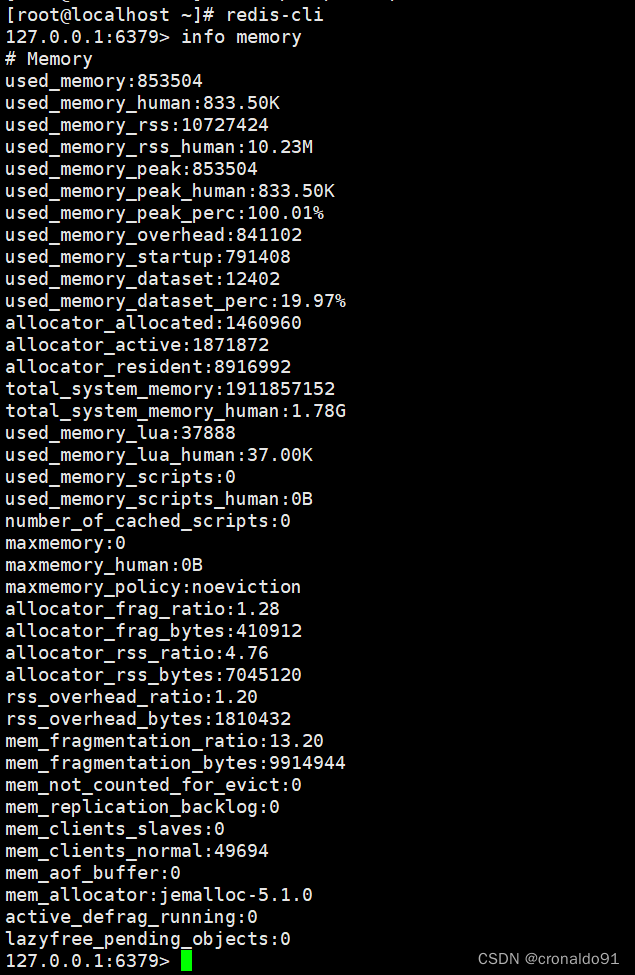
方法二:命令行查看
(2)内存碎片
config set activedefrag yes #自动碎片清理
memory purge #手动碎片清理
(3)内存使用率
禁止淘汰数据(不删除直到写满时报错)

可以设置最大内存阀值
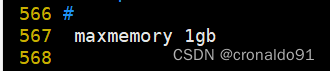
4.Redis的优化
(1)设置Redis客户端连接的超时时间
(2)设置 redis客户端最大连接数
① redis客户端最大连接数默认为10000。
若不设置,默认是10000

② 查看 redis 当前连接数

③ 查看 redis 允许的最大连接数

(3)设置redis自动碎片清理

(4)设置redis最大内存阀值
(5)设置key回收策略

三、总结
Redis群集有三种模式,分别是主从同步/复制、哨兵模式、Cluster。
Redis 提供两种方式进行持久化:RDB类似于Mysql dump快照,AOF则类似于mysql binlog。
RDB触发方式:
RDB持久化的触发分为手动触发和自动触发两种。
(1)手动触发
① save命令
redis-cli
redis> save
OK② bigsave命令
redis-cli -p 6379 -h 127.0.0.1
127.0.0.1:6379> bgsave
Background saving started(2)自动触发
在自动触发RDB持久化时,Redis 也会选择bgsave而不是save来进行持久化。
自动触发最常见的情况是在配置文件中通过 save m n 指定当m秒内发生n次变化时,会触发bgsave。
vim /etc/redis/6379.conf #编辑配置文件----219行--以下三个save条件满足任意一一个时,都会引起bgsave的调用save 900 1 #当时间到900秒时,如果redis数据发生了至少1次变化,则执行bgsavesave 300 10 #当时间到300秒时,如果redis数据发生了至少10次变化,则执行bgsavesave 60 10000 #当时间到60秒时,如果redis数据发生了至少10000次变化, 则执行bgsave----242行--是否开启RDB文件压缩rdbcompression yes----254行--指定RDB文件名dbfilename dump.rdb----264行--指定RDB文件和AOF文件所在目录dir /var/lib/redis/6379
RDB恢复数据:
#如果需要恢复数据,只需将备份文件 (dump.rdb) 移动到 redis 安装目录并启动服务即可。获取 redis 目录可以使用 CONFIG 命令,如下所示:redis 127.0.0.1:6379> CONFIG GET dir1) "dir"2) "/usr/local/redis/bin"
redis 127.0.0.1:6379> CONFIG GET dir1) "dir"2) "/usr/local/redis/bin"
AOF触发方式:
AOF持久化的触发分为手动触发和自动触发两种。
(1)手动触发
① #向Redis发送命令来触发AOF重写
redis-cli
redis> bgrewriteaof
Background append only file rewriting started② #修改Redis配置文件中的来手动触发AOF持久化
vim /etc/redis/6379.conf
--700行--修改,开启AOF
appendonly yes
--704行--指定AOF文件名称
appendfilename "appendonly.aof"
--796行--是否忽略最后一条可能存在问题的指令
aof-load-truncated yes(2)自动触发
① #rewrite-min-size和auto-aof-rewrite-percentage两个选项同时满足时,才会自动触发AOF重写,即bgrewriteaof操作。vim /etc/redis/6379.conf
--729--
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb ② AOF缓存区的同步文件策略:
vim /etc/redis/6379.conf----729行----# 每条语句同步执行持久化(强一致性场景)
appendfsync always# 每秒进行一次AOF持久化(均衡性场景)
appendfsync everysec# 从不进行持久化
appendfsync no内存回收key :
vim /etc/redis/6379.conf
--598--
maxmemory-policy noenviction
●volatile-lru:使用LRU算法从已设置过期时间的数据集合中淘汰数据(移除最近最少使用的key,针对设置了TTL的key)
●volatile-ttl:从已设置过期时间的数据集合中挑选即将过期的数据淘汰(移除最近过期的key)
●volatile-random:从已设置过期时间的数据集合中随机挑选数据淘汰(在设置了TTL的key里随机移除)
●allkeys-lru:使用LRU算法从所有数据集合中淘汰数据(移除最少使用的key,针对所有的key)
●allkeys-random:从数据集合中任意选择数据淘汰(随机移除key)
●noenviction:禁止淘汰数据(不删除直到写满时报错)相关文章:
数据库应用:Redis持久化
目录 一、理论 1.Redis 高可用 2.Redis持久化 3.RDB持久化 4.AOF持久化(支持秒级写入) 5.RDB和AOF的优缺点 6.RDB和AOF对比 7.Redis性能管理 8.Redis的优化 二、实验 1.RDB持久化 2.AOF持久化 3.Redis性能管理 4.Redis的优化 三、总结 一、…...
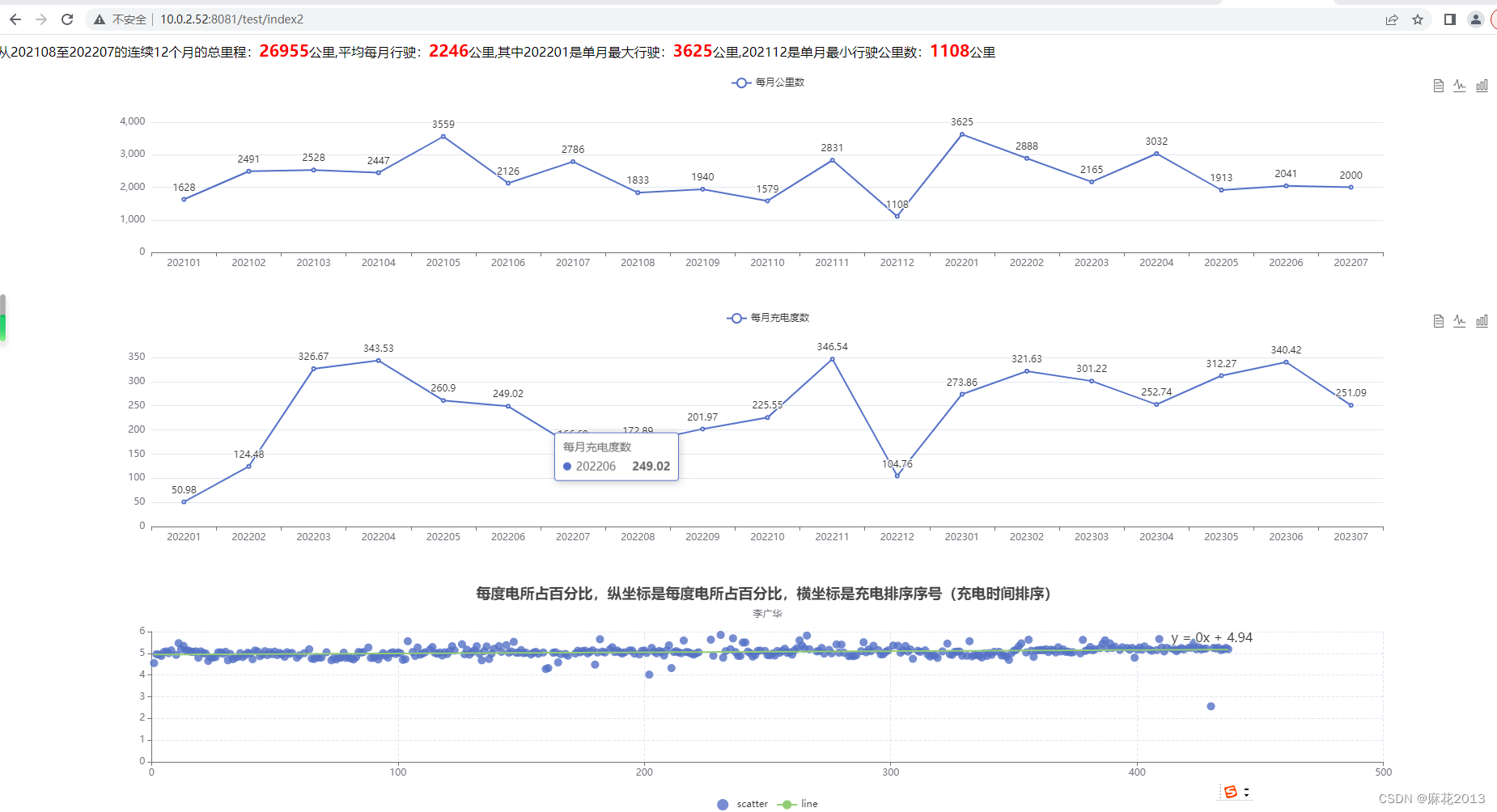
js版计算比亚迪行驶里程连续12个月计算不超3万公里改进版带echar
<!DOCTYPE html> <html lang"zh-CN" style"height: 100%"> <head> <meta charset"utf-8" /> <title>连续12个月不超3万公里计算LIGUANGHUA</title> <style> .clocks { …...
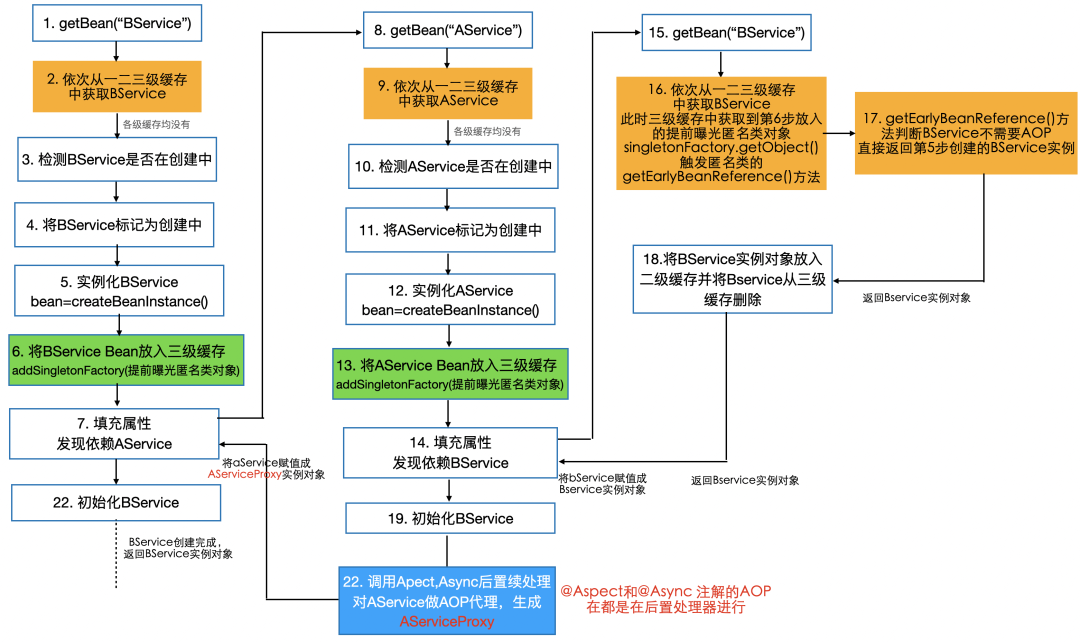
一文详解Spring Bean循环依赖
一、背景 有好几次线上发布老应用时,遭遇代码启动报错,具体错误如下: Caused by: org.springframework.beans.factory.BeanCurrentlyInCreationException: Error creating bean with name xxxManageFacadeImpl: Bean with name xxxManageFa…...
基于PHP+ vue2 + element +mysql自主研发的医院不良事件上报系统
医院不良事件上报管理系统源码 不良事件上报是为了响应卫生部下发的等级医院评审细则中第三章第9条规定:医院要有主动报告医疗安全(不良)事件的制度与工作流程。由医疗机构医院或医疗机构报告医疗安全不良事件信息,利用报告进行研…...
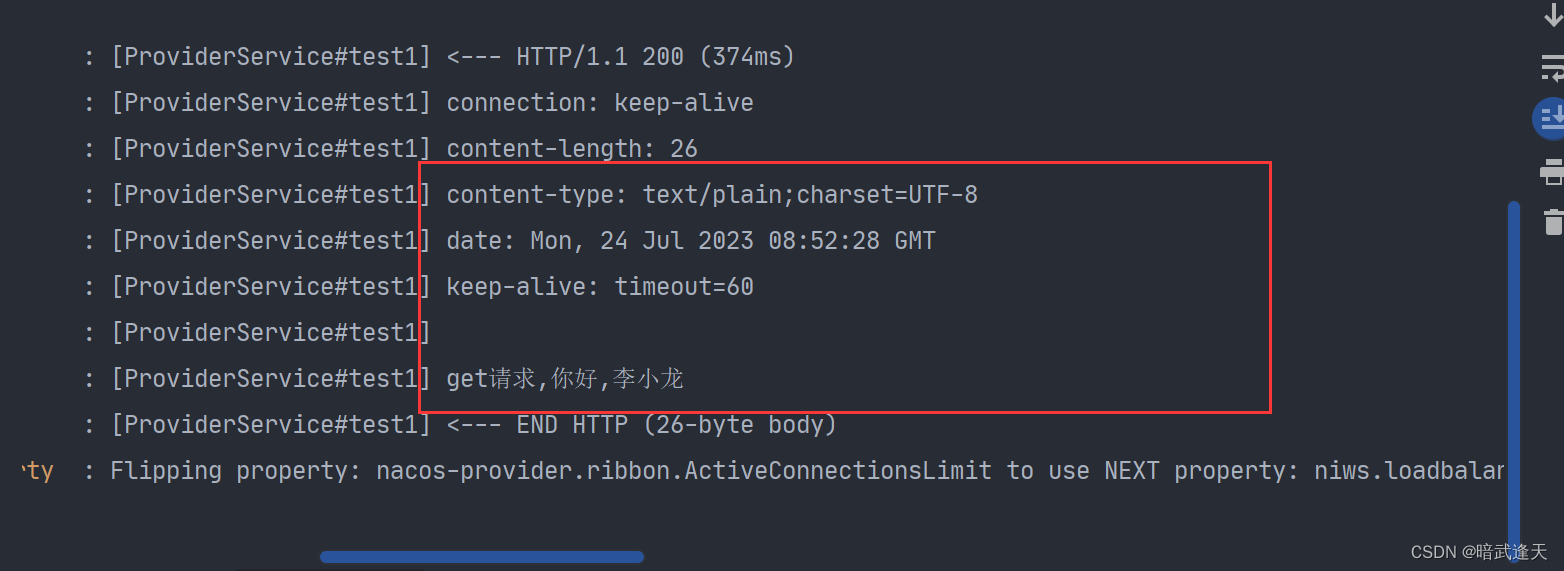
微服务远程调用openFeign简单回顾(内附源码示例)
目录 一. OpenFeign简介 二. OpenFeign原理 演示使用 provider模块 消费者模块 配置全局feign日志 示例源代码: 一. OpenFeign简介 OpenFeign是SpringCloud服务调用中间件,可以帮助代理服务API接口。并且可以解析SpringMVC的RequestMapping注解下的接口&#x…...

【云计算小知识】云环境是什么意思?有什么优点?
随着云计算的快速发展,了解云计算相关知识也是运维人员必备的。那你知道云环境是什么意思?有什么优点?云环境安全威胁有哪些?如何保证云环境的运维安全?这里我们就来简单聊聊。 云环境是什么意思? 云环境是…...

【搜索引擎Solr】Apache Solr 神经搜索
Sease[1] 与 Alessandro Benedetti(Apache Lucene/Solr PMC 成员和提交者)和 Elia Porciani(Sease 研发软件工程师)共同为开源社区贡献了 Apache Solr 中神经搜索的第一个里程碑。 它依赖于 Apache Lucene 实现 [2] 进行 K-最近邻…...

PostgreSQL 设置时区,时间/日期函数汇总
文章目录 前言查看时区修改时区时间/日期操作符和函数时间/日期操作符日期/时间函数:extract,date_part函数支持的field 数据类型格式化函数用于日期/时间格式化的模式: 扩展 前言 本文基于 PostgreSQL 12.6 版本,不同版本的函数…...

性能测试Ⅱ(压力测试与负载测试详解)
协议 性能理论:并发编程 ,系统调度,调度算法 监控 压力测试与负载测试的区别是什么? 负载测试 在被测系统上持续不断的增加压力,直到性能指标(响应时间等)超过预定指标或者某种资源(CPU&内存)使用已达到饱和状…...
【Python入门系列】第十八篇:Python自然语言处理和文本挖掘
文章目录 前言一、Python常用的NLP和文本挖掘库二、Python自然语言处理和文本挖掘1、文本预处理和词频统计2、文本分类3、命名实体识别4、情感分析5、词性标注6、文本相似度计算 总结 前言 Python自然语言处理(Natural Language Processing,简称NLP&…...

【GD32F103】自定义程序库08-DMA+ADC
DMA 自定义函数库说明: 将DMA先关的变量方式在一个机构体中封装起来,主要参数有 dma外设,时钟,通道,外设寄存器地址,数据传输宽度,数据方向,外设是能dma传输使能回调函数,扫描模式中断编号dma中断使能传输完成标志数据存储空间使用一个枚举类型指明每个DMA绑定到那个…...
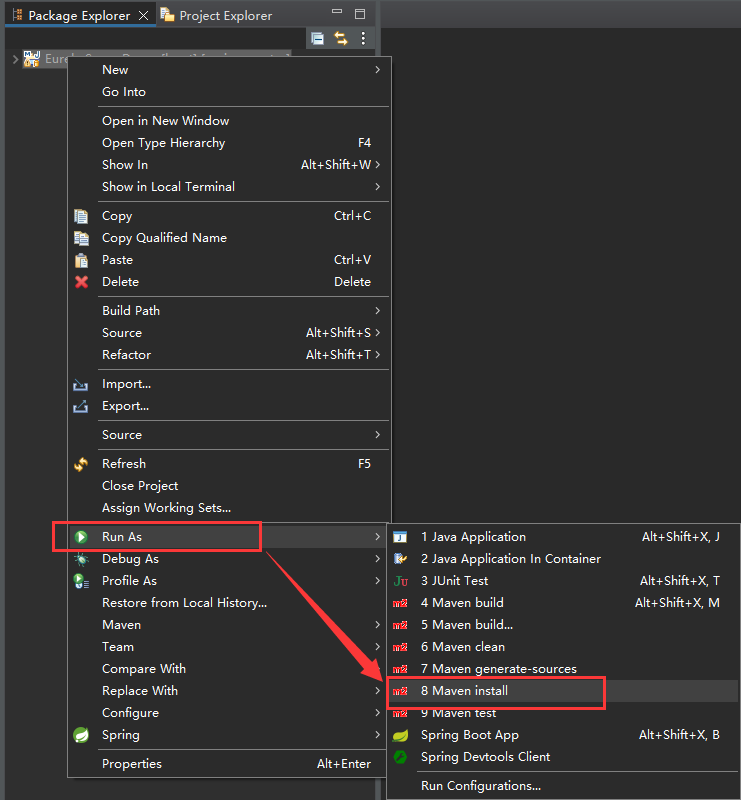
集成了Eureka的应用启动失败,端口号变为8080
问题 报错:集成了Eureka的应用启动失败,端口号变为8080。 原来运行的项目,突然报错,端口号变为8080: Tomcat initialized with port(s): 8080 (http)并且,还有如下的错误提示: RedirectingE…...
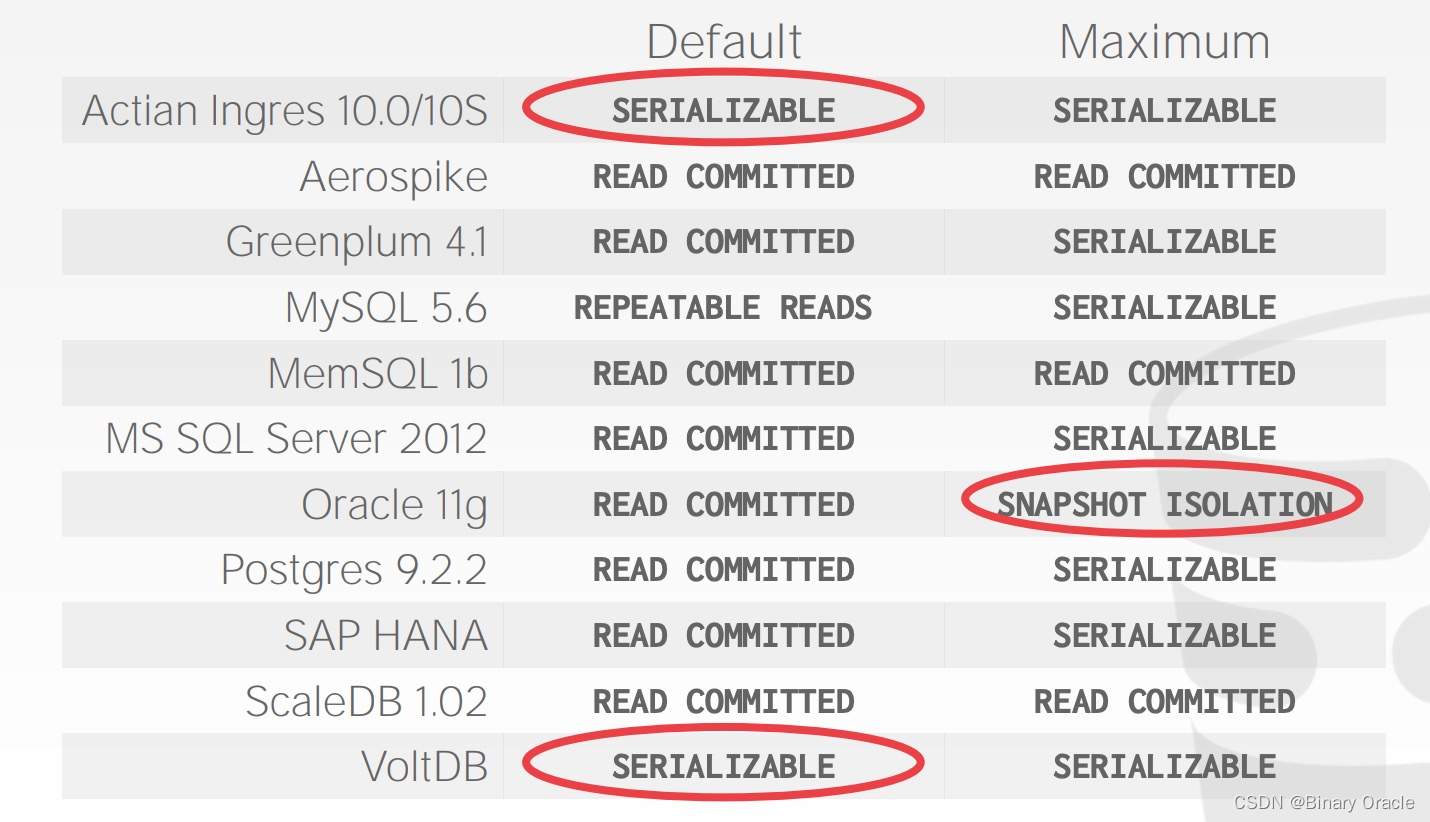
CMU 15-445 -- Timestamp Ordering Concurrency Control - 15
CMU 15-445 -- Timestamp Ordering Concurrency Control - 15 引言Basic T/OBasic T/O ReadsBasic T/O WritesBasic T/O - Example #1Basic T/O - Example #2 Basic T/O SummaryRecoverable Schedules Optimistic Concurrency Control (OCC)OCC - ExampleSERIAL VALIDATIONOCC …...

MURF2080CT/MURF2080CTR-ASEMI快恢复对管
编辑:ll MURF2080CT/MURF2080CTR-ASEMI快恢复对管 型号:MURF2080CT/MURF2080CTR 品牌:ASEMI 芯片个数:2 芯片尺寸:102MIL*2 封装:TO-220F 恢复时间:50ns 工作温度:-50C~150C…...

去除 idea warn Raw use of parameterized class ‘Map‘
去除 idea warn Raw use of parameterized class ‘Map’ 文档:Raw use of parameterized class ‘Map’… 链接:http://note.youdao.com/noteshare?id99bf4003db8cc5ae9813ee11e58c4d13&sub5856371AEFA740AF8FA4D8935B4F6912 添加链接描述 public…...

使用BERT分类的可解释性探索
最近尝试了使用BERT将告警信息当成一个文本去做分类,从分类的准召率上来看,还是取得了不错的效果(非结构化数据强标签训练,BERT确实是一把大杀器)。但准召率并不是唯一追求的目标,在安全场景下,…...

web APIs-练习二
轮播图点击切换: <!DOCTYPE html> <html lang"en"><head><meta charset"UTF-8" /><meta http-equiv"X-UA-Compatible" content"IEedge" /><meta name"viewport" content"…...

rpc通信原理浅析
rpc通信原理浅析 rpc(remote procedure call),即远程过程调用,广泛用于分布式或是异构环境下的通信,数据格式一般采取protobuf。 protobuf(protocol buffer)是google 的一种数据交换的格式,它独立于平台语…...
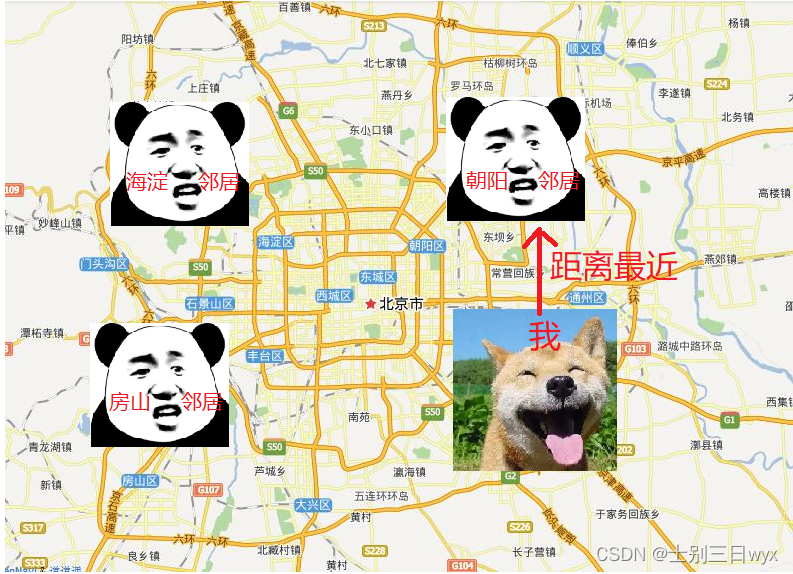
【机器学习】分类算法 - KNN算法(K-近邻算法)KNeighborsClassifier
「作者主页」:士别三日wyx 「作者简介」:CSDN top100、阿里云博客专家、华为云享专家、网络安全领域优质创作者 「推荐专栏」:零基础快速入门人工智能《机器学习入门到精通》 K-近邻算法 1、什么是K-近邻算法?2、K-近邻算法API3、…...

Spring Security 6.x 系列【64】扩展篇之多线程支持
有道无术,术尚可求,有术无道,止于术。 本系列Spring Boot 版本 3.1.0 本系列Spring Security 版本 6.1.0 本系列Spring Authorization Server 版本 1.1.0 源码地址:https://gitee.com/pearl-organization/study-spring-security-demo 文章目录 1. 问题演示2. 解决方案:…...

SpringBoot+Vue员工绩效系统实战:从数据库设计到权限控制的完整避坑指南
SpringBootVue员工绩效系统实战:从数据库设计到权限控制的完整避坑指南 在数字化转型浪潮下,企业绩效管理系统正从传统的Excel表格升级为智能化平台。本文将带您从零构建一个具备多维度考核、动态权限控制和可视化分析的绩效系统,重点解决实际…...
Pixel Fashion Atelier惊艳案例:‘赛博神社’主题皮装在明亮城镇UI下的生成
Pixel Fashion Atelier惊艳案例:‘赛博神社’主题皮装在明亮城镇UI下的生成 1. 项目概览 Pixel Fashion Atelier(像素时装锻造坊)是一款基于Stable Diffusion与Anything-v5的图像生成工作站。与传统AI工具不同,它采用了复古日系…...

AS_BH1750库:BH1750FVI环境光传感器嵌入式驱动设计与工程实践
1. AS_BH1750库概述:面向嵌入式系统的BH1750FVI环境光传感器驱动设计与工程实践BH1750FVI是由ROHM Semiconductor推出的高精度数字环境光传感器(Ambient Light Sensor, ALS),采用IC接口,具备宽动态范围(0.1…...

别再瞎装了!用NVIDIA-SMI一键查CUDA版本,保姆级PyTorch 2.6.0安装避坑指南
深度学习环境搭建实战:从CUDA版本诊断到PyTorch 2.6.0完美安装 刚接触深度学习的新手最常遇到的"入门杀"问题,往往不是模型调参或代码编写,而是环境搭建这个看似简单的环节。我见过太多人在安装PyTorch时直接复制粘贴网上的pip命令…...

避坑指南:如何在torch 2.4.0 + CUDA 12.1环境下成功安装llamafactory及其依赖
深度避坑:PyTorch 2.4.0与CUDA 12.1环境下的Llamafactory全栈部署实战 当开发者尝试在PyTorch 2.4.0和CUDA 12.1环境下部署Llamafactory时,往往会陷入依赖地狱——从Torch版本误装到vllm模块缺失,每个环节都可能成为耗时数小时的深坑。本文将…...

新手福音:免安装claude code,在快马平台开启你的ai编程第一课
作为一个刚接触编程的新手,最近想尝试用AI辅助写代码,但光是安装本地工具就让我头疼不已。直到发现了InsCode(快马)平台,才发现原来AI编程可以这么简单——不用配环境、不用解决依赖冲突,打开网页就能直接开玩。今天就把我的入门体…...

手把手教你用丹青识画:智能影像雅鉴系统保姆级入门教程
手把手教你用丹青识画:智能影像雅鉴系统保姆级入门教程 1. 认识丹青识画系统 "以科技之眼,点画意之睛。"这句话完美诠释了丹青识画系统的核心理念。这是一款将人工智能技术与东方美学相结合的创新工具,能够自动分析图像内容并生成…...

zotero-style:智能文献管理在学术研究中的创新实践
zotero-style:智能文献管理在学术研究中的创新实践 【免费下载链接】zotero-style zotero-style - 一个 Zotero 插件,提供了一系列功能来增强 Zotero 的用户体验,如阅读进度可视化和标签管理,适合研究人员和学者。 项目地址: ht…...

AIGlasses_for_navigation免配置环境:预置ffmpeg+opencv+torchvision全栈
AIGlasses_for_navigation免配置环境:预置ffmpegopencvtorchvision全栈 1. 引言:让AI视觉开发变得简单 如果你曾经尝试过搭建一个完整的AI视觉处理环境,一定知道那是个多么痛苦的过程:安装CUDA、配置ffmpeg、编译OpenCV、处理各…...

OpCore-Simplify:如何用四步自动化流程解决黑苹果配置的三大核心挑战
OpCore-Simplify:如何用四步自动化流程解决黑苹果配置的三大核心挑战 【免费下载链接】OpCore-Simplify A tool designed to simplify the creation of OpenCore EFI 项目地址: https://gitcode.com/GitHub_Trending/op/OpCore-Simplify 对于黑苹果爱好者来说…...