【搜索引擎Solr】Apache Solr 神经搜索
Sease[1] 与 Alessandro Benedetti(Apache Lucene/Solr PMC 成员和提交者)和 Elia Porciani(Sease 研发软件工程师)共同为开源社区贡献了 Apache Solr 中神经搜索的第一个里程碑。
它依赖于 Apache Lucene 实现 [2] 进行 K-最近邻搜索。
特别感谢 Christine Poerschke、Cassandra Targett、Michael Gibney 和所有其他在贡献的最后阶段提供了很大帮助的审稿人。即使是一条评论也受到了高度赞赏,如果我们取得进展,总是要感谢社区。
让我们从简短的介绍开始,介绍神经方法如何改进搜索。
我们可以将搜索概括为四个主要领域:
-
生成指定信息需求的查询表示
-
生成捕获包含的信息的文档的表示
-
匹配来自信息语料库的查询和文档表示
-
为每个匹配的文档分配一个分数,以便根据结果中的相关性建立一个有意义的文档排名
神经搜索是神经信息检索[3] 学术领域的行业衍生产品,它专注于使用基于神经网络的技术改进这些领域中的任何一个。
人工智能、深度学习和向量表示
我们越来越频繁地听到人工智能(从现在开始是人工智能)如何渗透到我们生活的许多方面。
当我们谈论人工智能时,我们指的是一组使机器能够学习和显示与人类相似的智能的技术。
随着最近计算机能力的强劲和稳定发展,人工智能已经复苏,现在它被用于许多领域,包括软件工程和信息检索(管理搜索引擎和类似系统的科学)。
特别是,深度学习 [4] 的出现引入了使用深度神经网络来解决对经典算法非常具有挑战性的复杂问题。
就这篇博文而言,只要知道深度学习可用于在信息语料库中生成查询和文档的向量表示就足够了。
密集向量表示
可以认为传统的倒排索引将文本建模为“稀疏”向量,其中语料库中的每个词项对应一个向量维度。在这样的模型中(另见词袋方法),维数对应于术语字典基数,并且任何给定文档的向量大部分包含零(因此它被称为稀疏,因为只有少数术语存在于整个字典中将出现在任何给定的文档中)。
密集向量表示与基于术语的稀疏向量表示形成对比,因为它将近似语义意义提取为固定(和有限)数量的维度。
这种方法的维数通常远低于稀疏情况,并且任何给定文档的向量都是密集的,因为它的大部分维数都由非零值填充。
与稀疏方法(标记器用于直接从文本输入生成稀疏向量)相比,生成向量的任务必须在 Apache Solr 外部的应用程序逻辑中处理。
BERT[5] 等各种深度学习模型能够将文本信息编码为密集向量,用于密集检索策略。
有关更多信息,您可以参考我们的这篇博文。
近似最近邻
给定一个对信息需求进行建模的密集向量 v,提供密集向量检索的最简单方法是计算 v 与代表信息语料库中文档的每个向量 d 之间的距离(欧几里得、点积等)。
这种方法非常昂贵,因此目前正在积极研究许多近似策略。
近似最近邻搜索算法返回结果,其与查询向量的距离最多为从查询向量到其最近向量的距离的 c 倍。
这种方法的好处是,在大多数情况下,近似最近邻几乎与精确最近邻一样好。
特别是,如果距离测量准确地捕捉到用户质量的概念,那么距离的微小差异应该无关紧要[6]
分层导航小图
在 Apache Lucene 中实现并由 Apache Solr 使用的策略基于 Navigable Small-world 图。
它为高维向量提供了一种有效的近似最近邻搜索[7][8][9][10]。
Hierarchical Navigable Small World Graph (HNSW) 是一种基于邻近邻域图概念的方法:
与信息语料库相关联的向量空间中的每个向量都唯一地与一个
vertex
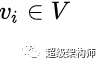
in the graph

.
顶点基于它们的接近度通过边缘连接,更近的(根据距离函数)连接。
构建图受超参数的影响,这些超参数调节每层要构建多少个连接以及要构建多少层。
在查询时,邻居结构被导航以找到离目标最近的向量,从种子节点开始,随着我们越来越接近目标而迭代。
我发现这个博客对于深入研究该主题非常有用。
Apache Lucene 实现
首先要注意的是当前的 Lucene 实现不是分层的。
所以图中只有一层,请参阅原始 Jira 问题中的最新评论,跟踪开发进度[11]。
主要原因是为了在 Apache Lucene 生态系统中为这种简化的实现找到更容易的设计、开发和集成过程。
一致认为,引入分层分层结构将在低维向量管理和查询时间(减少候选节点遍历)方面带来好处。
该实施正在进行中[12]。
那么,与 Navigable Small World Graph 和 K-Nearest Neighbors 功能相关的 Apache Lucene 组件有哪些?
让我们探索代码:
注:如果您对 Lucene 内部结构和编解码器不感兴趣,可以跳过这一段
org.apache.lucene.document.KnnVectorField 是入口点:
它在索引时需要向量维度和相似度函数(构建 NSW 图时使用的向量距离函数)。
这些是通过 #setVectorDimensionsAndSimilarityFunction 方法在 org.apache.lucene.document.FieldType 中设置的。
更新文档字段架构 org.apache.lucene.index.IndexingChain#updateDocFieldSchema 时,信息从 FieldType 中提取并保存在 org.apache.lucene.index.IndexingChain.FieldSchema 中。
并且从 FieldSchema KnnVectorField 配置最终到达 org.apache.lucene.index.IndexingChain#initializeFieldInfo 中的 org.apache.lucene.index.FieldInfo。
现在,Lucene 编解码器具有构建 NSW 图形所需的所有特定于字段的配置。
让我们看看如何:
首先,从 org.apache.lucene.codecs.lucene90.Lucene90Codec#Lucene90Codec 你可以看到 KNN 向量的默认格式是 org.apache.lucene.codecs.lucene90.Lucene90HnswVectorsFormat。
关联的索引编写器是 org.apache.lucene.codecs.lucene90.Lucene90HnswVectorsWriter。
该组件可以访问之前在将字段写入 org.apache.lucene.codecs.lucene90.Lucene90HnswVectorsWriter#writeField 中的索引时初始化的 FieldInfo。
在编写 KnnVectorField 时,涉及到 org.apache.lucene.util.hnsw.HnswGraphBuilder,最后是
org.apache.lucene.util.hnsw.HnswGraph 已构建。
Apache Solr 实现
可从 Apache Solr 9.0 获得
预计 2022 年第一季度
这第一个贡献允许索引单值密集向量场并使用近似距离函数搜索 K-最近邻。
当前特点:
-
DenseVectorField 类型
-
Knn 查询解析器
密集向量场(DenseVectorField)
密集向量字段提供了索引和搜索浮点元素的密集向量的可能性。
例如
[1.0, 2.5, 3.7, 4.1]以下是 DenseVectorField 应如何在模式中配置:
<fieldType name="knn_vector" class="solr.DenseVectorField"
vectorDimension="4" similarityFunction="cosine"/>
<field name="vector" type="knn_vector" indexed="true" stored="true"/>-----------------------------------------------------------------------------------------------------
|Parameter Name | Required | Default | Description |Accepted values|
-----------------------------------------------------------------------------------------------------
|vectorDimension | True | |The dimension of the dense
vector to pass in. |Integer < = 1024|
—————————————————————————————————————————
|similarityFunction | False | euclidean |Vector similarity function;
used in search to return top K most similar vectors to a target vector.
| euclidean, dot_product or cosine.
———————————————————————————————————————-
欧几里得:欧几里得距离
-
dot_product:点积。注意:这种相似性旨在作为执行余弦相似性的优化方式。为了使用它,所有向量必须是单位长度的,包括文档向量和查询向量。对非单位长度的向量使用点积可能会导致错误或搜索结果不佳。
-
余弦:余弦相似度。注意:执行余弦相似度的首选方法是将所有向量归一化为单位长度,而不是使用 DOT_PRODUCT。只有在需要保留原始向量且无法提前对其进行归一化时,才应使用此函数。
DenseVectorField 支持属性:索引、存储。
注:目前不支持多值
自定义索引编解码器
要使用以下自定义编解码器格式的高级参数和 HNSW 算法的超参数,请确保在 solrconfig.xml 中设置此配置:
<codecFactory class="solr.SchemaCodecFactory"/>
...
以下是如何使用高级编解码器超参数配置 DenseVectorField:<fieldType name="knn_vector" class="solr.DenseVectorField"
vectorDimension="4"similarityFunction="cosine"
codecFormat="Lucene90HnswVectorsFormat" hnswMaxConnections="10" hnswBeamWidth="40"/>
<field name="vector" type="knn_vector" indexed="true" stored="true"/>| Parameter Name | Required | Default | Description | Accepted values |
codecFormat | False |
| Specifies the knn codec implementation to use |
|
hnswMaxConnections | False | 16 | Lucene90HnswVectorsFormat only:Controls how many of the nearest neighbor candidates are connected to the new node. It has the same meaning as M from the paper[8]. | Integer |
hnswBeamWidth | False | 100 | Lucene90HnswVectorsFormat only: It is the number of nearest neighbor candidates to track while searching the graph for each newly inserted node.It has the same meaning as efConstruction from the paper[8]. | Integer |
请注意,codecFormat 接受的值可能会在未来版本中更改。
注意 Lucene 索引向后兼容仅支持默认编解码器。如果您选择在架构中自定义 codecFormat,升级到 Solr 的未来版本可能需要您切换回默认编解码器并优化索引以在升级之前将其重写为默认编解码器,或者重新构建整个索引升级后从头开始。
对于 HNSW 实现的超参数,详见[8]。
如何索引向量
下面是 DenseVectorField 应该如何被索引:
JSON
[{ "id": "1",
"vector": [1.0, 2.5, 3.7, 4.1]
},
{ "id": "2",
"vector": [1.5, 5.5, 6.7, 65.1]
}
]XML
<field name="id">1
<field name="vector">1.0
<field name="vector">2.5
<field name="vector">3.7
<field name="vector">4.1<field name="id">2
<field name="vector">1.5
<field name="vector">5.5
<field name="vector">6.7
<field name="vector">65.1Java – SolrJ
final SolrClient client = getSolrClient();final SolrInputDocument d1 = new SolrInputDocument();
d1.setField("id", "1");
d1.setField("vector", Arrays.asList(1.0f, 2.5f, 3.7f, 4.1f));final SolrInputDocument d2 = new SolrInputDocument();
d2.setField("id", "2");
d2.setField("vector", Arrays.asList(1.5f, 5.5f, 6.7f, 65.1f));client.add(Arrays.asList(d1, d2));knn 查询解析器
knn K-Nearest Neighbors 查询解析器允许根据给定字段中的索引密集向量查找与目标向量最近的 k 文档。
它采用以下参数:
| Parameter Name | Required | Default | Description |
f | True | The DenseVectorField to search in. | |
topK | False | 10 | How many k-nearest results to return. |
以下是运行 KNN 搜索的方法:
&q={!knn f=vector topK=10}[1.0, 2.0, 3.0, 4.0]
检索到的搜索结果是输入 [1.0, 2.0, 3.0, 4.0] 中与向量最近的 K-nearest,由在索引时配置的similarityFunction 排序。
与过滤查询一起使用
knn 查询解析器可用于过滤查询:
&q=id:(1 2 3)&fq={!knn f=vector topK=10}[1.0, 2.0, 3.0, 4.0]
knn 查询解析器可以与过滤查询一起使用:
&q={!knn f=vector topK=10}[1.0, 2.0, 3.0, 4.0]&fq=id:(1 2 3)
重要:
在这些场景中使用 knn 时,请确保您清楚地了解过滤器查询在 Apache Solr 中的工作方式:
由主查询 q 产生的文档 ID 排名列表与从每个过滤器查询派生的文档 ID 集合相交 fq.egRanked List from q=[ID1, ID4, ID2, ID10] Set from fq={ID3, ID2 , ID9, ID4} = [ID4,ID2]
用作重新排序查询
knn 查询解析器可用于重新排列第一遍查询结果:
&q=id:(3 4 9 2)&rq={!rerank reRankQuery=$rqq reRankDocs=4 reRankWeight=1}
&rqq={!knn f=vector topK=10}[1.0, 2.0, 3.0, 4.0]
重要:
在重新排序中使用 knn 时,请注意 topK 参数。
仅当来自第一遍的文档 d 在要搜索的目标向量的 K 最近邻(在整个索引中)内时,才计算第二遍分数(从 knn 派生)。
这意味着无论如何都会在整个索引上执行第二遍 knn,这是当前的限制。
最终排序的结果列表将第一次通过分数(主查询 q)加上第二次通过分数(到要搜索的目标向量的近似相似度函数距离)乘以乘法因子(reRankWeight)。
因此,如果文档 d 不存在于 knn 结果中,即使与目标查询向量的距离向量计算不为零,您对原始分数的贡献也为零。
有关使用 ReRank 查询解析器的详细信息,请参阅 Apache Solr Wiki[13] 部分。
| 本文 :https://jiagoushi.pro/apache-solr-neural-search | ||
| 讨论:知识星球【首席架构师圈】或者加微信小号【ca_cto】或者加QQ群【792862318】 | ||
| 公众号 | 【jiagoushipro】 【超级架构师】 精彩图文详解架构方法论,架构实践,技术原理,技术趋势。 我们在等你,赶快扫描关注吧。 | |
| 微信小号 | 【ca_cea】 50000人社区,讨论:企业架构,云计算,大数据,数据科学,物联网,人工智能,安全,全栈开发,DevOps,数字化. | |
| QQ群 | 【285069459】深度交流企业架构,业务架构,应用架构,数据架构,技术架构,集成架构,安全架构。以及大数据,云计算,物联网,人工智能等各种新兴技术。 加QQ群,有珍贵的报告和干货资料分享。 | |
| 视频号 | 【超级架构师】 1分钟快速了解架构相关的基本概念,模型,方法,经验。 每天1分钟,架构心中熟。 | |
| 知识星球 | 【首席架构师圈】向大咖提问,近距离接触,或者获得私密资料分享。 | |
| 喜马拉雅 | 【超级架构师】路上或者车上了解最新黑科技资讯,架构心得。 | 【智能时刻,架构君和你聊黑科技】 |
| 知识星球 | 认识更多朋友,职场和技术闲聊。 | 知识星球【职场和技术】 |
| 领英 | Harry | https://www.linkedin.com/in/architect-harry/ |
| 领英群组 | 领英架构群组 | https://www.linkedin.com/groups/14209750/ |
| 微博 | 【超级架构师】 | 智能时刻 |
| 哔哩哔哩 | 【超级架构师】 | |
| 抖音 | 【cea_cio】超级架构师 | |
| 快手 | 【cea_cio_cto】超级架构师 | |
| 小红书 | 【cea_csa_cto】超级架构师 | |
| 网站 | CIO(首席信息官) | https://cio.ceo |
| 网站 | CIO,CTO和CDO | https://cioctocdo.com |
| 网站 | 架构师实战分享 | https://architect.pub |
| 网站 | 程序员云开发分享 | https://pgmr.cloud |
| 网站 | 首席架构师社区 | https://jiagoushi.pro |
| 网站 | 应用开发和开发平台 | https://apaas.dev |
| 网站 | 开发信息网 | https://xinxi.dev |
| 网站 | 超级架构师 | https://jiagou.dev |
| 网站 | 企业技术培训 | https://peixun.dev |
| 网站 | 程序员宝典 | https://pgmr.pub |
| 网站 | 开发者闲谈 | https://blog.developer.chat |
| 网站 | CPO宝典 | https://cpo.work |
| 网站 | 首席安全官 | https://cso.pub |
| 网站 | CIO酷 | https://cio.cool |
| 网站 | CDO信息 | https://cdo.fyi |
| 网站 | CXO信息 | https://cxo.pub |
谢谢大家关注,转发,点赞和点在看。
相关文章:
【搜索引擎Solr】Apache Solr 神经搜索
Sease[1] 与 Alessandro Benedetti(Apache Lucene/Solr PMC 成员和提交者)和 Elia Porciani(Sease 研发软件工程师)共同为开源社区贡献了 Apache Solr 中神经搜索的第一个里程碑。 它依赖于 Apache Lucene 实现 [2] 进行 K-最近邻…...

PostgreSQL 设置时区,时间/日期函数汇总
文章目录 前言查看时区修改时区时间/日期操作符和函数时间/日期操作符日期/时间函数:extract,date_part函数支持的field 数据类型格式化函数用于日期/时间格式化的模式: 扩展 前言 本文基于 PostgreSQL 12.6 版本,不同版本的函数…...

性能测试Ⅱ(压力测试与负载测试详解)
协议 性能理论:并发编程 ,系统调度,调度算法 监控 压力测试与负载测试的区别是什么? 负载测试 在被测系统上持续不断的增加压力,直到性能指标(响应时间等)超过预定指标或者某种资源(CPU&内存)使用已达到饱和状…...
【Python入门系列】第十八篇:Python自然语言处理和文本挖掘
文章目录 前言一、Python常用的NLP和文本挖掘库二、Python自然语言处理和文本挖掘1、文本预处理和词频统计2、文本分类3、命名实体识别4、情感分析5、词性标注6、文本相似度计算 总结 前言 Python自然语言处理(Natural Language Processing,简称NLP&…...

【GD32F103】自定义程序库08-DMA+ADC
DMA 自定义函数库说明: 将DMA先关的变量方式在一个机构体中封装起来,主要参数有 dma外设,时钟,通道,外设寄存器地址,数据传输宽度,数据方向,外设是能dma传输使能回调函数,扫描模式中断编号dma中断使能传输完成标志数据存储空间使用一个枚举类型指明每个DMA绑定到那个…...
集成了Eureka的应用启动失败,端口号变为8080
问题 报错:集成了Eureka的应用启动失败,端口号变为8080。 原来运行的项目,突然报错,端口号变为8080: Tomcat initialized with port(s): 8080 (http)并且,还有如下的错误提示: RedirectingE…...
CMU 15-445 -- Timestamp Ordering Concurrency Control - 15
CMU 15-445 -- Timestamp Ordering Concurrency Control - 15 引言Basic T/OBasic T/O ReadsBasic T/O WritesBasic T/O - Example #1Basic T/O - Example #2 Basic T/O SummaryRecoverable Schedules Optimistic Concurrency Control (OCC)OCC - ExampleSERIAL VALIDATIONOCC …...

MURF2080CT/MURF2080CTR-ASEMI快恢复对管
编辑:ll MURF2080CT/MURF2080CTR-ASEMI快恢复对管 型号:MURF2080CT/MURF2080CTR 品牌:ASEMI 芯片个数:2 芯片尺寸:102MIL*2 封装:TO-220F 恢复时间:50ns 工作温度:-50C~150C…...

去除 idea warn Raw use of parameterized class ‘Map‘
去除 idea warn Raw use of parameterized class ‘Map’ 文档:Raw use of parameterized class ‘Map’… 链接:http://note.youdao.com/noteshare?id99bf4003db8cc5ae9813ee11e58c4d13&sub5856371AEFA740AF8FA4D8935B4F6912 添加链接描述 public…...

使用BERT分类的可解释性探索
最近尝试了使用BERT将告警信息当成一个文本去做分类,从分类的准召率上来看,还是取得了不错的效果(非结构化数据强标签训练,BERT确实是一把大杀器)。但准召率并不是唯一追求的目标,在安全场景下,…...

web APIs-练习二
轮播图点击切换: <!DOCTYPE html> <html lang"en"><head><meta charset"UTF-8" /><meta http-equiv"X-UA-Compatible" content"IEedge" /><meta name"viewport" content"…...

rpc通信原理浅析
rpc通信原理浅析 rpc(remote procedure call),即远程过程调用,广泛用于分布式或是异构环境下的通信,数据格式一般采取protobuf。 protobuf(protocol buffer)是google 的一种数据交换的格式,它独立于平台语…...
【机器学习】分类算法 - KNN算法(K-近邻算法)KNeighborsClassifier
「作者主页」:士别三日wyx 「作者简介」:CSDN top100、阿里云博客专家、华为云享专家、网络安全领域优质创作者 「推荐专栏」:零基础快速入门人工智能《机器学习入门到精通》 K-近邻算法 1、什么是K-近邻算法?2、K-近邻算法API3、…...

Spring Security 6.x 系列【64】扩展篇之多线程支持
有道无术,术尚可求,有术无道,止于术。 本系列Spring Boot 版本 3.1.0 本系列Spring Security 版本 6.1.0 本系列Spring Authorization Server 版本 1.1.0 源码地址:https://gitee.com/pearl-organization/study-spring-security-demo 文章目录 1. 问题演示2. 解决方案:…...

Elasticsearch 简单搜索查询案例
1.MySql表结构/数据 SET FOREIGN_KEY_CHECKS0;-- ---------------------------- -- Table structure for user_lables -- ---------------------------- DROP TABLE IF EXISTS user_lables; CREATE TABLE user_lables (id varchar(255) DEFAULT NULL COMMENT 用户唯一标识,age…...
【RabbitMQ(day1)】RabbitMQ的概述和安装
入门RabbitMQ 一、RabbitMQ的概述二、RabbitMQ的安装三、RabbitMQ管理命令行四、RabbitMQ的GUI界面 一、RabbitMQ的概述 MQ(Message Queue)翻译为消息队列,通过典型的【生产者】和【消费者】模型,生产者不断向消息队列中生产消息&…...

Too many files with unapproved license: 2 See RAT report
解决方案 mvn -Prelease-nacos -Dmaven.test.skiptrue -Dpmd.skiptrue -Dcheckstyle.skiptrue -Drat.numUnapprovedLicenses100 clean install 或者 mvn -Prelease-nacos -Dmaven.test.skiptrue -Drat.numUnapprovedLicenses100 clean install...
Windows11的VTK安装:VS201x+Qt5/Qt6 +VTK7.1/VTK9.2.6
需要提前安装好VS2017和VS2019和Qt VS开发控件以及Qt VS-addin。 注意Qt6.2.4只能跟VTK9.2.6联合编译(目前VTK9和Qt6的相互支持版本)。 首先下载VTK,需要下载源码和data: Download | VTKhttps://vtk.org/download/ 然后这两个文…...

大数据时代个人信息安全保护小贴士
个人信息安全保护小贴士 1. 朋友圈“五不晒”2. 手机使用“四要”、“六不要”3. 电脑使用“七注意”4. 日常上网“七注意”5. 日常生活“五注意” 互联网就像公路,用户使用它,就会留下脚印。 每个人都在无时不刻的产生数据,在消费数据的同时…...
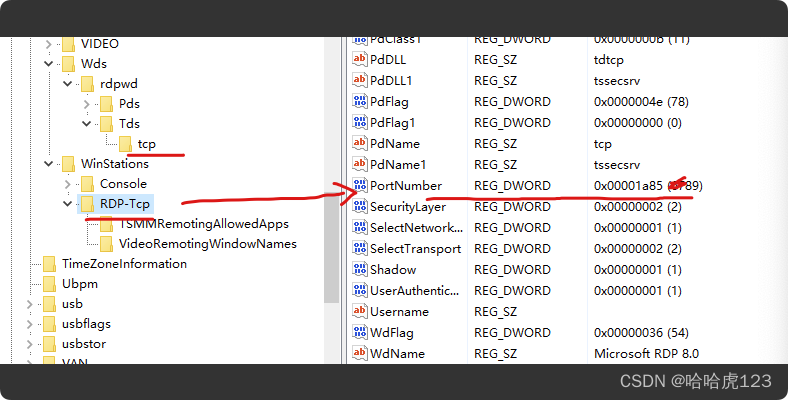
windows 修改 RDP 远程桌面端口号
打开 PowerShell , 执行regedit 依次展开 PortNumber HKEY_LOCAL_MACHINE \SYSTEM \CurrentControlSet \Control \Terminal Server \WinStations \RDP-Tcp 右边找到 PortNumber ,对应修改自己的端口号 HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Co…...
跨平台中文Zip压缩与解压实战指南(附多线程优化))
Unity 工具之(SharpZipLib)跨平台中文Zip压缩与解压实战指南(附多线程优化)
1. 为什么选择SharpZipLib处理Unity中的Zip文件 在Unity项目开发中,资源打包和网络传输经常需要处理压缩文件。SharpZipLib作为.NET平台的老牌压缩库,相比Unity内置的压缩方案有三个不可替代的优势: 首先是对中文路径的完美支持。很多开发者都…...

Vivado初始化设计慢?可能是这3个隐藏设置惹的祸
Vivado初始化设计慢?可能是这3个隐藏设置惹的祸 当你在深夜赶项目进度,Vivado却卡在"Initializing Design"界面转圈超过15分钟,那种焦虑感堪比考试时笔没水。作为Xilinx FPGA开发的核心工具,Vivado的初始化速度直接影响…...

OpenRocket全栈实战手册:从仿真引擎到航天教育生态构建
OpenRocket全栈实战手册:从仿真引擎到航天教育生态构建 【免费下载链接】openrocket Model-rocketry aerodynamics and trajectory simulation software 项目地址: https://gitcode.com/GitHub_Trending/op/openrocket 价值定位:重新定义航天工程…...

ChineseChess-AlphaZero技术架构与实践指南:从环境搭建到模型训练
ChineseChess-AlphaZero技术架构与实践指南:从环境搭建到模型训练 【免费下载链接】ChineseChess-AlphaZero Implement AlphaZero/AlphaGo Zero methods on Chinese chess. 项目地址: https://gitcode.com/gh_mirrors/ch/ChineseChess-AlphaZero 副标题&…...

汽车电子测试人的 Prompt 工程
专栏:《AI 汽车电子测试实战》第 17 篇 作者:一线汽车电子测试工程师 适合人群:所有使用 AI 的测试工程师、想提升 AI 使用效率的测试人员开篇:为什么需要学 Prompt? 这是我上个月在某车企的 AI 培训项目中的真实经历。…...

从按键消抖到I2C通信:深入浅出聊聊MCU上拉/下拉电阻与开漏输出的那些坑
从按键消抖到I2C通信:深入浅出聊聊MCU上拉/下拉电阻与开漏输出的那些坑 在嵌入式系统开发中,GPIO配置看似简单,却暗藏玄机。记得第一次调试I2C总线时,通信速率始终上不去,最后发现竟是上拉电阻选型不当;另一…...

别再只会用PS修图了!用Python的Richardson-Lucy算法,5分钟搞定模糊老照片修复
用Python拯救模糊老照片:零基础也能上手的Richardson-Lucy算法实战 翻箱倒柜找到一张泛黄的老照片,却发现画面模糊得连人脸都看不清?别急着叹气,更不用花大价钱找专业修图师。今天我要分享一个连Python新手都能轻松上手的黑科技—…...

BiliTools:跨平台资源管理与高效解析的哔哩哔哩工具箱
BiliTools:跨平台资源管理与高效解析的哔哩哔哩工具箱 【免费下载链接】BiliTools A cross-platform bilibili toolbox. 跨平台哔哩哔哩工具箱,支持视频、音乐、番剧、课程下载……持续更新 项目地址: https://gitcode.com/GitHub_Trending/bilit/Bili…...

ai辅助开发:让快马生成智能助手,链接notepad下载与个性化代码推荐
今天想和大家分享一个有趣的实践:如何用AI辅助开发的方式,让Notepad这个老牌文本编辑器焕发新生。我们平时下载Notepad可能只是简单获取软件,但如果结合AI能力,就能把"下载-使用"的流程升级成"智能助手"体验。…...

Charticulator:数据可视化的自由创作平台与技术革命
Charticulator:数据可视化的自由创作平台与技术革命 【免费下载链接】charticulator Interactive Layout-Aware Construction of Bespoke Charts 项目地址: https://gitcode.com/gh_mirrors/ch/charticulator 当数据分析师面对预设模板无法表达复杂数据关系时…...