【机器学习】分类算法 - KNN算法(K-近邻算法)KNeighborsClassifier
「作者主页」:士别三日wyx
「作者简介」:CSDN top100、阿里云博客专家、华为云享专家、网络安全领域优质创作者
「推荐专栏」:零基础快速入门人工智能《机器学习入门到精通》
K-近邻算法
- 1、什么是K-近邻算法?
- 2、K-近邻算法API
- 3、K-近邻算法实际应用
- 3.1、获取数据集
- 3.2、划分数据集
- 3.3、特征标准化
- 3.4、KNN处理并评估
1、什么是K-近邻算法?
K-近邻算法的核心思想是根据「邻居」来「推断」你的类别。
K-近邻算法的思路其实很简单,比如我在北京市,想知道自己在北京的哪个区。K-近邻算法就会找到和我距离最近的‘邻居’,邻居在朝阳区,就认为我大概率也在朝阳区。
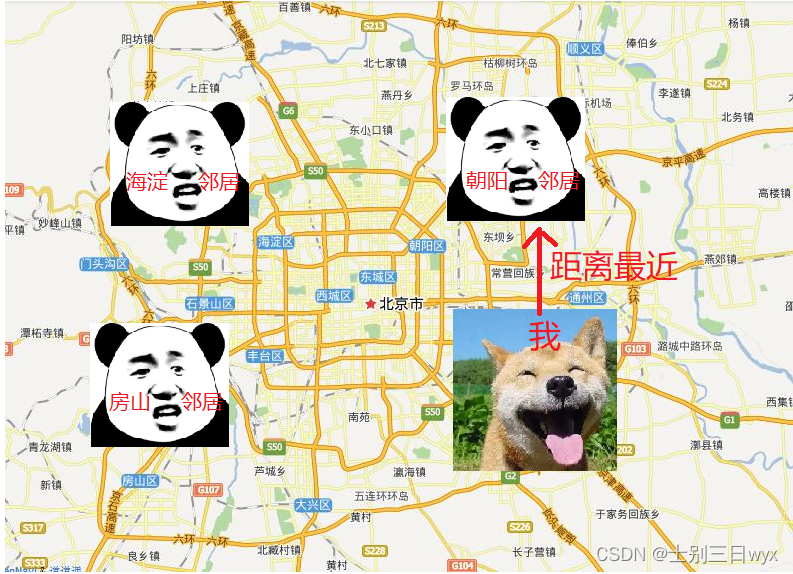
其中 K 是邻居个数的意思
- 邻居个数「太少」,容易受到异常值的影响
- 邻居个数「太多」,容易受到样本不均衡的影响。
2、K-近邻算法API
sklearn.neighbors.KNeighborsClassifier( n_neighbors=5, algorithm=‘auto’ ) 是实现K-近邻算法的API
- n_neighbors:(可选,int)指定邻居(K)数量,默认值 5
- algorithm:(可选,{ ‘auto’,‘ball_tree’,‘kd_tree’,‘brute’})计算最近邻居的算法,默认值 ‘auto’。
算法解析
- brute:蛮力搜索,也就是线性扫描,训练集越大,消耗的时间越多。
- kd_tree:构造kd树(也就是二叉树)存储数据以便对其进行快速检索,以中值切分构造的树,每个结点是一个超矩形,在维数小于20时效率高
- ball_tree:用来解决kd树高维失效的问题,以质心C和半径r分割样本空间,每个节点是一个超球体。
- auto:自动决定最合适的算法
函数
- KNeighborsClassifier.fit( x_train, y_train):接收训练集特征 和 训练集目标
- KNeighborsClassifier.predict(x_test):接收测试集特征,返回数据的类标签。
- KNeighborsClassifier.score(x_test, y_test):接收测试集特征 和 测试集目标,返回准确率。
- KNeighborsClassifier.get_params():获取接收的参数(就是 n_neighbors 和 algorithm 这种参数)
- KNeighborsClassifier.set_params():设置参数
- KNeighborsClassifier.kneighbors():返回每个相邻点的索引和距离
- KNeighborsClassifier.kneighbors_graph():返回每个相邻点的权重
3、K-近邻算法实际应用
3.1、获取数据集
这里使用sklearn自带的鸢尾花「数据集」,它是分类最常用的分类试验数据集。
from sklearn import datasets# 1、获取数据集(实例化)
iris = datasets.load_iris()print(iris.data)
输出:
[[5.1 3.5 1.4 0.2][4.9 3. 1.4 0.2][4.7 3.2 1.3 0.2]
从打印的数据集可以看到,鸢尾花数据集有4个「属性」,这里解释一下属性的含义
- sepal length:萼片长度(厘米)
- sepal width:萼片宽度(厘米)
- petal length:花瓣长度(厘米)
- petal width:花瓣宽度(厘米)
3.2、划分数据集
接下来对鸢尾花的特征值(iris.data)和目标值(iris.target)进行「划分」,测试集为60%,训练集为40%。
from sklearn import datasets
from sklearn import model_selection# 1、获取数据集
iris = datasets.load_iris()
# 2、划分数据集
x_train, x_test, y_train, y_test = model_selection.train_test_split(iris.data, iris.target, random_state=6)
print('训练集特征值:', len(x_train))
print('测试集特征值:',len(x_test))
print('训练集目标值:',len(y_train))
print('测试集目标值:',len(y_test))
输出:
训练集特征值: 112
测试集特征值: 38
训练集目标值: 112
测试集目标值: 38
从打印结果可以看到,测试集的样本数是38,训练集的样本数是112,划分比例符合预期。
3.3、特征标准化
接下来,对训练集和测试集的特征值进行「标准化」处理(训练集和测试集所做的处理必须完全「相同」)。
from sklearn import datasets
from sklearn import model_selection
from sklearn import preprocessing# 1、获取数据集
iris = datasets.load_iris()
# 2、划分数据集
# x_train:训练集特征,x_test:测试集特征,y_train:训练集目标,y_test:测试集目标
x_train, x_test, y_train, y_test = model_selection.train_test_split(iris.data, iris.target, random_state=6)
# 3、特征标准化
ss = preprocessing.StandardScaler()
x_train = ss.fit_transform(x_train)
x_test = ss.fit_transform(x_test)
print(x_train)
输出:
[[-0.18295405 -0.192639 0.25280554 -0.00578113][-1.02176094 0.51091214 -1.32647368 -1.30075363][-0.90193138 0.97994624 -1.32647368 -1.17125638]
从打印结果可以看到,特征值发生了相应的变化。
3.4、KNN处理并评估
接下来,将训练集特征 和 训练集目标 传给 KNN,然后评估处理结果的「准确率」。
from sklearn import datasets
from sklearn import model_selection
from sklearn import preprocessing
from sklearn import neighbors# 1、获取数据集
iris = datasets.load_iris()
# 2、划分数据集
# x_train:训练集特征,x_test:测试集特征,y_train:训练集目标,y_test:测试集目标
x_train, x_test, y_train, y_test = model_selection.train_test_split(iris.data, iris.target, random_state=6)
# 3、特征标准化
ss = preprocessing.StandardScaler()
x_train = ss.fit_transform(x_train)
x_test = ss.fit_transform(x_test)
# 4、KNN算法处理
knn = neighbors.KNeighborsClassifier(n_neighbors=2)
knn.fit(x_train, y_train)
# 5、评估结果
y_predict = knn.predict(x_test)
print('真实值和预测值对比:', y_predict == y_test)
score = knn.score(x_test, y_test)
print('准确率:', score)
输出:
真实值和预测值对比: [ True True True True True True False True True True False TrueTrue True True False True True True True True True True TrueTrue True True True True True True True True True False TrueTrue True]
准确率: 0.8947368421052632
从输出结果可以很容易看出,准确率是89%;真实值和预测值对比的结果中,True越多,表示准确率越高。
相关文章:
【机器学习】分类算法 - KNN算法(K-近邻算法)KNeighborsClassifier
「作者主页」:士别三日wyx 「作者简介」:CSDN top100、阿里云博客专家、华为云享专家、网络安全领域优质创作者 「推荐专栏」:零基础快速入门人工智能《机器学习入门到精通》 K-近邻算法 1、什么是K-近邻算法?2、K-近邻算法API3、…...

Spring Security 6.x 系列【64】扩展篇之多线程支持
有道无术,术尚可求,有术无道,止于术。 本系列Spring Boot 版本 3.1.0 本系列Spring Security 版本 6.1.0 本系列Spring Authorization Server 版本 1.1.0 源码地址:https://gitee.com/pearl-organization/study-spring-security-demo 文章目录 1. 问题演示2. 解决方案:…...

Elasticsearch 简单搜索查询案例
1.MySql表结构/数据 SET FOREIGN_KEY_CHECKS0;-- ---------------------------- -- Table structure for user_lables -- ---------------------------- DROP TABLE IF EXISTS user_lables; CREATE TABLE user_lables (id varchar(255) DEFAULT NULL COMMENT 用户唯一标识,age…...
【RabbitMQ(day1)】RabbitMQ的概述和安装
入门RabbitMQ 一、RabbitMQ的概述二、RabbitMQ的安装三、RabbitMQ管理命令行四、RabbitMQ的GUI界面 一、RabbitMQ的概述 MQ(Message Queue)翻译为消息队列,通过典型的【生产者】和【消费者】模型,生产者不断向消息队列中生产消息&…...

Too many files with unapproved license: 2 See RAT report
解决方案 mvn -Prelease-nacos -Dmaven.test.skiptrue -Dpmd.skiptrue -Dcheckstyle.skiptrue -Drat.numUnapprovedLicenses100 clean install 或者 mvn -Prelease-nacos -Dmaven.test.skiptrue -Drat.numUnapprovedLicenses100 clean install...
Windows11的VTK安装:VS201x+Qt5/Qt6 +VTK7.1/VTK9.2.6
需要提前安装好VS2017和VS2019和Qt VS开发控件以及Qt VS-addin。 注意Qt6.2.4只能跟VTK9.2.6联合编译(目前VTK9和Qt6的相互支持版本)。 首先下载VTK,需要下载源码和data: Download | VTKhttps://vtk.org/download/ 然后这两个文…...

大数据时代个人信息安全保护小贴士
个人信息安全保护小贴士 1. 朋友圈“五不晒”2. 手机使用“四要”、“六不要”3. 电脑使用“七注意”4. 日常上网“七注意”5. 日常生活“五注意” 互联网就像公路,用户使用它,就会留下脚印。 每个人都在无时不刻的产生数据,在消费数据的同时…...
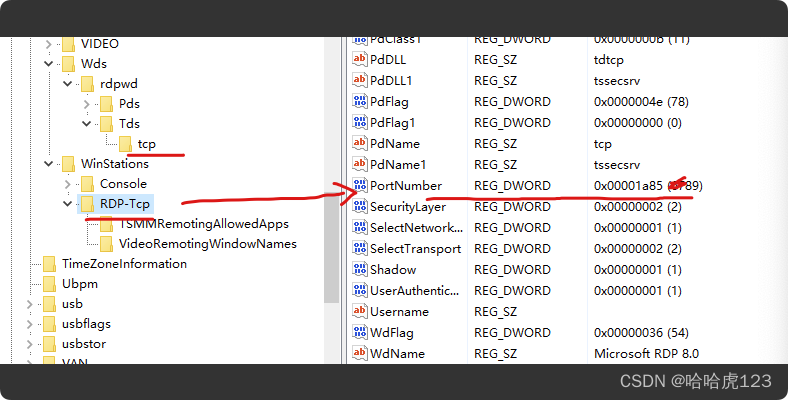
windows 修改 RDP 远程桌面端口号
打开 PowerShell , 执行regedit 依次展开 PortNumber HKEY_LOCAL_MACHINE \SYSTEM \CurrentControlSet \Control \Terminal Server \WinStations \RDP-Tcp 右边找到 PortNumber ,对应修改自己的端口号 HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Co…...
:如何在 TypeScript 中使用类和继承?)
面试题-TS(四):如何在 TypeScript 中使用类和继承?
面试题-TS(4):如何在 TypeScript 中使用类和继承? 在TypeScript中,类是一种重要的概念,它允许我们使用面向对象的编程风格来组织和管理代码。类提供了一种模板,用于创建具有相同属性和行为的对象。通过继承࿰…...

React之JSX的介绍与使用步骤,注意事项,条件渲染,列表渲染以及css样式处理
React之JSX的介绍与使用 一、JSX的介绍二、JSX使用步骤三、JSX注意事项四、JSX中使用JavaScript表达式五、条件渲染六、列表渲染七、CSS样式处理八、JSX 总结 一、JSX的介绍 简介 JSX是JavaScript XML的简写,表示了在Javascript代码中写XML(HTML)格式的代码 优势 声…...
)
sql进阶:求满足某列数值相加无限接近90%的行(90分位)
sql 一、案例分析二、思路三、代码实现一、案例分析 表中有某个id列和数值列,求数值列占比为90%的id,如有个用户表,存储id和消费金额order_cnt,求一条sql查出消费占比无限接近90%的所有客户,如表中总消费为10000,占比最高的是4000、3000、2800,对应A、B、C用户,查出A、B、C用户…...
设计模式大白话——观察者模式
文章目录 一、概述二、示例三、模式定义四、其他 一、概述 与其叫他观察者模式,我更愿意叫他叫 订阅-发布模式 ,这种模式在我们生活中非常常见,比如:追番了某个电视剧,当电视剧有更新的时候会第一时间通知你。当你…...

机器学习小记-序
机器学习是人工智能的一个重要分支,根据学习任务的不同,可以将机器学习分为以下几类: 监督学习(Supervised Learning): 应用场景:监督学习适用于已标记数据集的任务,其中每个样本都有…...
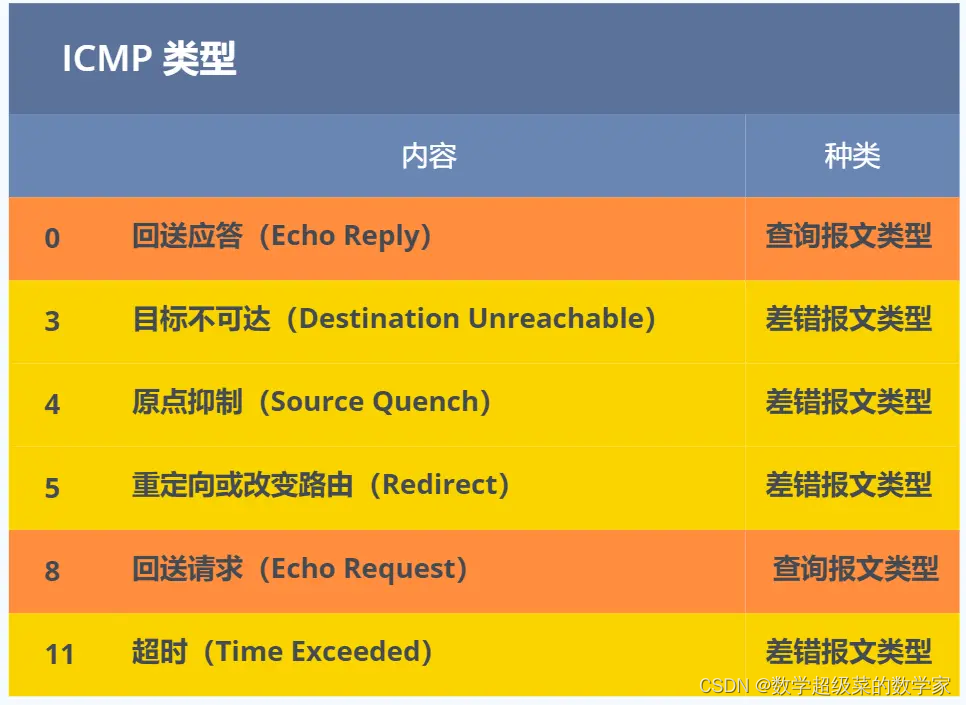
IP基础知识总结
IP他负责的是把IP数据包在不同网络间传送,这是网络设计相关的,与操作系统没有关系。所以这部分知识,不是网络的重点。IP和路由交换技术联系紧密。但是要作为基本知识点记住。 一、基本概念 网络层作用:实现主机与主机之间通信。 …...

Java设计模式-单例模式
单例模式 1.单例模式含义 单例模式就是保证一个类仅有一个实例,并提供一个访问它的全局访问点。 其实单例模式很好理解,当我们new一个对象实例的时候,这个对象会被放到一个内存中,当我们再次new同一个对象的实例的时候…...
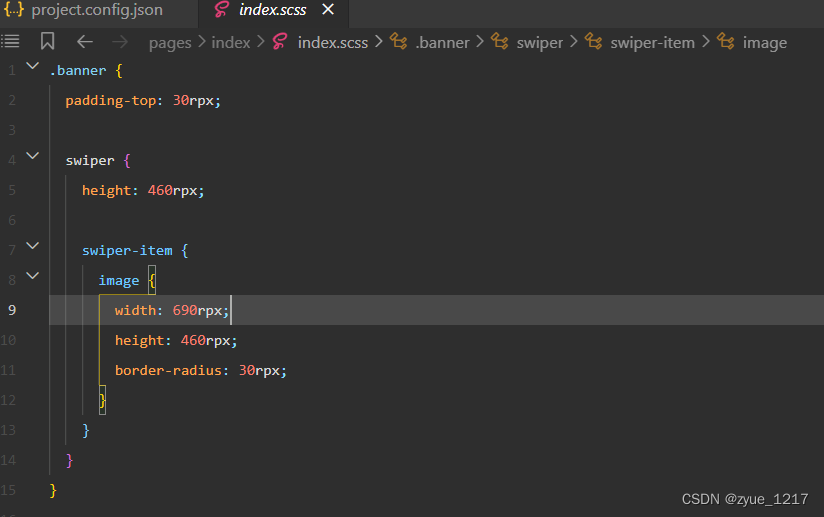
小程序----配置原生内置编译插件支持sass
修改project.config.json配置文件 在 project.config.json 文件中,修改setting 下的 useCompilerPlugins 字段为 ["sass"], 即可开启工具内置的 sass 编译插件。 目前支持三个编译插件:typescript、less、sass 修改之后可以将原.w…...

GitLab 删除项目
1.点击头像 2.点击Profile 3.选择要删除的项目点进去 4.settings-general-Advances-expand 5.然后在弹出框中输入你要删除的项目名称即可...

Mac m1 下eclipse下载及jdk环境变量配置
一、安装eclipse 1、下载eclipse Eclipse downloads - Select a mirror | The Eclipse Foundation 此版本为m1芯片适用版本 2、下载后下一步安装即可 安装成功后,可以看到图标: 二、安装jdk 1、下载jdk 下载此版本即可,下载完成之后一直…...

Java中List与数组之间的相互转换
一、List列表与对象数组 List列表中存储对象,如List<Integer>、List<String>、List<Person>,对象数组中同样存储相应的对象,如Integer[]、String[]、Person[],对象数组与对象List的转换可通过如下方式实现&…...
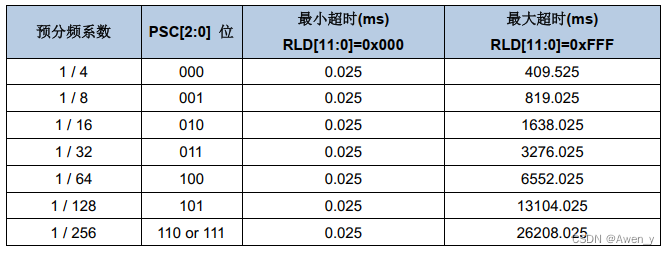
嵌入式_GD32看门狗配置
嵌入式_GD32独立看门狗配置与注意事项 文章目录 嵌入式_GD32独立看门狗配置与注意事项前言一、什么是独立看门狗定时器(FWDGT)二、独立看门狗定时器原理三、独立看门狗定时器配置过程与注意事项总结 前言 使用GD3单片机时,为了提供了更高的安…...

咱们今天来唠唠机器人轨迹规划那点事儿。不少小伙伴在玩机械臂的时候总会遇到关节空间和笛卡尔空间轨迹规划的抉择困难症,这俩货到底有什么区别?直接上硬核代码
matlab笛卡尔空间和关节空间轨迹规划 关节空间机器臂多项式轨迹规划定做,353和333多项式轨迹规划和优化关节空间规划有个大杀器——多项式插值。比如要让机械臂从A点平滑运动到B点,咱们可以玩三次多项式(3-3-3)或者五次多项式&…...

OpenAI推安全漏洞赏金计划,应对AI潜在风险
OpenAI启动公共安全漏洞赏金计划,剑指AI潜在风险品玩3月26日消息,OpenAI正式推出公共安全漏洞赏金计划,此计划意在识别并修复其产品中潜在的AI滥用与安全风险。该计划是对现有安全漏洞赏金项目的补充,专门接纳那些虽不构成传统技术…...

嵌入式Linux开发必备远程连接工具详解
1. 嵌入式Linux开发常用远程连接工具技术解析1.1 远程连接工具在嵌入式开发中的重要性嵌入式Linux开发过程中,开发人员经常需要远程访问目标设备进行调试、文件传输或系统监控。由于嵌入式设备通常资源有限且缺乏本地交互界面,远程连接工具成为开发流程中…...

YOLOv8目标检测新玩法:用VMamba替换C2f模块,我在DDSM医疗数据集上mAP涨到了0.724
YOLOv8与VMamba融合:医疗影像目标检测的突破实践 在医疗影像分析领域,目标检测技术正经历着从传统卷积神经网络到新型架构的转变。最近,我们将YOLOv8模型中的C2f模块替换为VMamba模块,在DDSM乳腺X光数据集上取得了mAP 0.724的显著…...

新手福音:利用快马平台生成你的第一个数学公式编辑器入门项目
最近在自学前端开发,一直想尝试做个数学公式编辑器来练手。作为一个完全的新手,从零开始写这种项目确实有点无从下手。不过我发现用InsCode(快马)平台可以很轻松地生成基础代码框架,再根据自己的需求调整完善,特别适合像我这样的初…...
)
用FastMCP中间件给你的AI应用加把锁:手把手实现MySQL数据库鉴权(附完整代码)
用FastMCP中间件构建企业级AI服务安全网关 当团队内部的AI工具从原型走向生产环境时,安全往往成为最容易被忽视的环节。上周我接手了一个金融数据分析平台的审计工作,发现开发团队竟然直接将未加密的股票查询接口暴露在公网,仅通过IP白名单控…...

4个步骤掌握高频交易策略:High-Frequency-Trading-Model-with-IB实战指南
4个步骤掌握高频交易策略:High-Frequency-Trading-Model-with-IB实战指南 【免费下载链接】High-Frequency-Trading-Model-with-IB A high-frequency trading model using Interactive Brokers API with pairs and mean-reversion in Python 项目地址: https://gi…...

vLLM-v0.17.1详细步骤:vLLM + Triton Ensemble实现多模型协同推理
vLLM-v0.17.1详细步骤:vLLM Triton Ensemble实现多模型协同推理 1. vLLM框架简介 vLLM是一个专为大型语言模型(LLM)设计的高性能推理和服务库,以其出色的吞吐量和易用性著称。这个项目最初由加州大学伯克利分校的天空计算实验室开发,现在已…...

开发提效新组合:用Cursor生成代码片段,在快马一键集成与部署
最近在做一个数据整理的小工具时,发现了一个特别高效的工作流组合:先用Cursor快速生成核心代码片段,再用InsCode(快马)平台一键整合部署。整个过程就像搭积木一样顺畅,特别适合需要快速实现功能模块的场景。 需求分析 我们经常要处…...

3步轻松上手BepInEx:Unity插件框架新手必备指南
3步轻松上手BepInEx:Unity插件框架新手必备指南 【免费下载链接】BepInEx Unity / XNA game patcher and plugin framework 项目地址: https://gitcode.com/GitHub_Trending/be/BepInEx BepInEx是一款专为Unity游戏设计的插件框架,能帮助开发者轻…...