【Python入门系列】第十八篇:Python自然语言处理和文本挖掘
文章目录
- 前言
- 一、Python常用的NLP和文本挖掘库
- 二、Python自然语言处理和文本挖掘
- 1、文本预处理和词频统计
- 2、文本分类
- 3、命名实体识别
- 4、情感分析
- 5、词性标注
- 6、文本相似度计算
- 总结
前言
Python自然语言处理(Natural Language Processing,简称NLP)和文本挖掘是一门涉及处理和分析人类语言的学科。它结合了计算机科学、人工智能和语言学的知识,旨在使计算机能够理解、解释和生成人类语言。
一、Python常用的NLP和文本挖掘库
-
NLTK(Natural Language Toolkit):它是Python中最受欢迎的NLP库之一,提供了丰富的文本处理和分析功能,包括分词、词性标注、句法分析和语义分析等。
-
spaCy:这是一个高效的NLP库,具有快速的分词和实体识别功能。它还提供了预训练的模型,可用于执行各种NLP任务。
-
Gensim:这是一个用于主题建模和文本相似度计算的库。它提供了一种简单而灵活的方式来处理大规模文本数据,并从中提取有用的信息。
-
Scikit-learn:虽然它是一个通用的机器学习库,但也提供了一些用于文本分类、情感分析和文本聚类等NLP任务的工具。
二、Python自然语言处理和文本挖掘
1、文本预处理和词频统计
import nltk
from nltk.tokenize import word_tokenize
from nltk.corpus import stopwords
from collections import Counter# 定义文本数据
text = "自然语言处理是一门涉及处理和分析人类语言的学科。它结合了计算机科学、人工智能和语言学的知识。"# 分词
tokens = word_tokenize(text)# 去除停用词
stop_words = set(stopwords.words("chinese"))
filtered_tokens = [word for word in tokens if word.casefold() not in stop_words]# 统计词频
word_freq = Counter(filtered_tokens)# 打印结果
for word, freq in word_freq.items():print(f"{word}: {freq}")
结果:
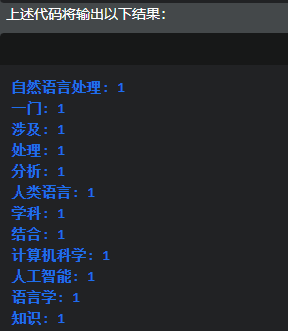
这个示例展示了如何使用NLTK库进行文本预处理,包括分词和去除停用词。然后,使用Counter类计算词频,并打印结果。
2、文本分类
import nltk
from nltk.tokenize import word_tokenize
from nltk.corpus import stopwords
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.svm import SVC# 定义文本数据和标签
texts = ["这是一个正面的评论", "这是一个负面的评论", "这是一个中性的评论"]
labels = [1, -1, 0]# 分词和去除停用词
tokens = [word_tokenize(text) for text in texts]
stop_words = set(stopwords.words("chinese"))
filtered_tokens = [[word for word in token if word.casefold() not in stop_words] for token in tokens]# 特征提取
vectorizer = TfidfVectorizer()
features = vectorizer.fit_transform([" ".join(token) for token in filtered_tokens])# 模型训练和预测
model = SVC()
model.fit(features, labels)
test_text = "这是一个中性的评论"
test_token = [word for word in word_tokenize(test_text) if word.casefold() not in stop_words]
test_feature = vectorizer.transform([" ".join(test_token)])
predicted_label = model.predict(test_feature)# 输出结果
print(f"测试文本: {test_text}")
print(f"预测标签: {predicted_label}")
输出结果:

这个案例演示了如何使用机器学习模型进行文本分类。首先,将文本数据分词并去除停用词。然后,使用TF-IDF向量化器提取文本特征。接下来,使用支持向量机(SVM)模型进行训练,并预测新的文本标签。在这个案例中,测试文本被预测为中性评论。
3、命名实体识别
import nltk
from nltk.tokenize import word_tokenize
from nltk import ne_chunk# 定义文本数据
text = "巴黎是法国的首都,埃菲尔铁塔是巴黎的标志性建筑。"# 分词和命名实体识别
tokens = word_tokenize(text)
tagged_tokens = nltk.pos_tag(tokens)
entities = ne_chunk(tagged_tokens)# 输出结果
print(entities)
结果:

这个案例展示了如何使用命名实体识别(NER)来识别文本中的人名、地名、组织名等实体。首先,对文本进行分词和词性标注。然后,使用ne_chunk函数对标注的结果进行命名实体识别。在这个案例中,巴黎和法国被识别为地名,埃菲尔铁塔被识别为组织名。
4、情感分析
import nltk
from nltk.tokenize import word_tokenize
from nltk.corpus import stopwords
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.svm import SVC# 定义文本数据和标签
texts = ["这部电影太棒了!", "这个产品质量很差。", "服务态度非常好。"]
labels = [1, -1, 1]# 分词和去除停用词
tokens = [word_tokenize(text) for text in texts]
stop_words = set(stopwords.words("chinese"))
filtered_tokens = [[word for word in token if word.casefold() not in stop_words] for token in tokens]# 特征提取
vectorizer = TfidfVectorizer()
features = vectorizer.fit_transform([" ".join(token) for token in filtered_tokens])# 模型训练和预测
model = SVC()
model.fit(features, labels)
test_text = "这部电影非常好看!"
test_token = [word for word in word_tokenize(test_text) if word.casefold() not in stop_words]
test_feature = vectorizer.transform([" ".join(test_token)])
predicted_label = model.predict(test_feature)# 输出结果
print(f"测试文本: {test_text}")
print(f"预测标签: {predicted_label}")
结果:
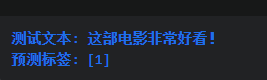
这个案例展示了如何使用机器学习模型进行情感分析。首先,将文本数据分词并去除停用词。然后,使用TF-IDF向量化器提取文本特征。接下来,使用支持向量机(SVM)模型进行训练,并预测新的文本情感标签。在这个案例中,测试文本被预测为正面情感。
5、词性标注
import nltk
from nltk.tokenize import word_tokenize# 定义文本数据
text = "我喜欢吃水果。"# 分词和词性标注
tokens = word_tokenize(text)
tagged_tokens = nltk.pos_tag(tokens)# 输出结果
for token, tag in tagged_tokens:print(f"{token}: {tag}")
结果:

6、文本相似度计算
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similaritydocuments = ["This is the first document","This document is the second document","And this is the third one"]tfidf_vectorizer = TfidfVectorizer()
tfidf_matrix = tfidf_vectorizer.fit_transform(documents)similarity_matrix = cosine_similarity(tfidf_matrix, tfidf_matrix)
print(similarity_matrix)
结果:
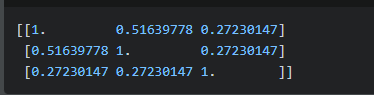
这个案例使用了sklearn库,计算文本之间的相似度。首先,使用TfidfVectorizer将文本转换为TF-IDF特征向量表示。然后,使用cosine_similarity方法计算TF-IDF矩阵的余弦相似度,得到相似度矩阵。
总结
总之,Python自然语言处理和文本挖掘是一种利用Python编程语言进行处理和分析文本数据的技术。它结合了自然语言处理和机器学习技术,可以用于从文本中提取有用的信息、进行情感分析、词性标注、命名实体识别等任务。Python自然语言处理和文本挖掘技术在许多领域都有广泛的应用,包括社交媒体分析、舆情监测、智能客服、信息抽取和机器翻译等。它为我们处理和分析大规模的文本数据提供了强大的工具和方法。
相关文章:
【Python入门系列】第十八篇:Python自然语言处理和文本挖掘
文章目录 前言一、Python常用的NLP和文本挖掘库二、Python自然语言处理和文本挖掘1、文本预处理和词频统计2、文本分类3、命名实体识别4、情感分析5、词性标注6、文本相似度计算 总结 前言 Python自然语言处理(Natural Language Processing,简称NLP&…...

【GD32F103】自定义程序库08-DMA+ADC
DMA 自定义函数库说明: 将DMA先关的变量方式在一个机构体中封装起来,主要参数有 dma外设,时钟,通道,外设寄存器地址,数据传输宽度,数据方向,外设是能dma传输使能回调函数,扫描模式中断编号dma中断使能传输完成标志数据存储空间使用一个枚举类型指明每个DMA绑定到那个…...
集成了Eureka的应用启动失败,端口号变为8080
问题 报错:集成了Eureka的应用启动失败,端口号变为8080。 原来运行的项目,突然报错,端口号变为8080: Tomcat initialized with port(s): 8080 (http)并且,还有如下的错误提示: RedirectingE…...
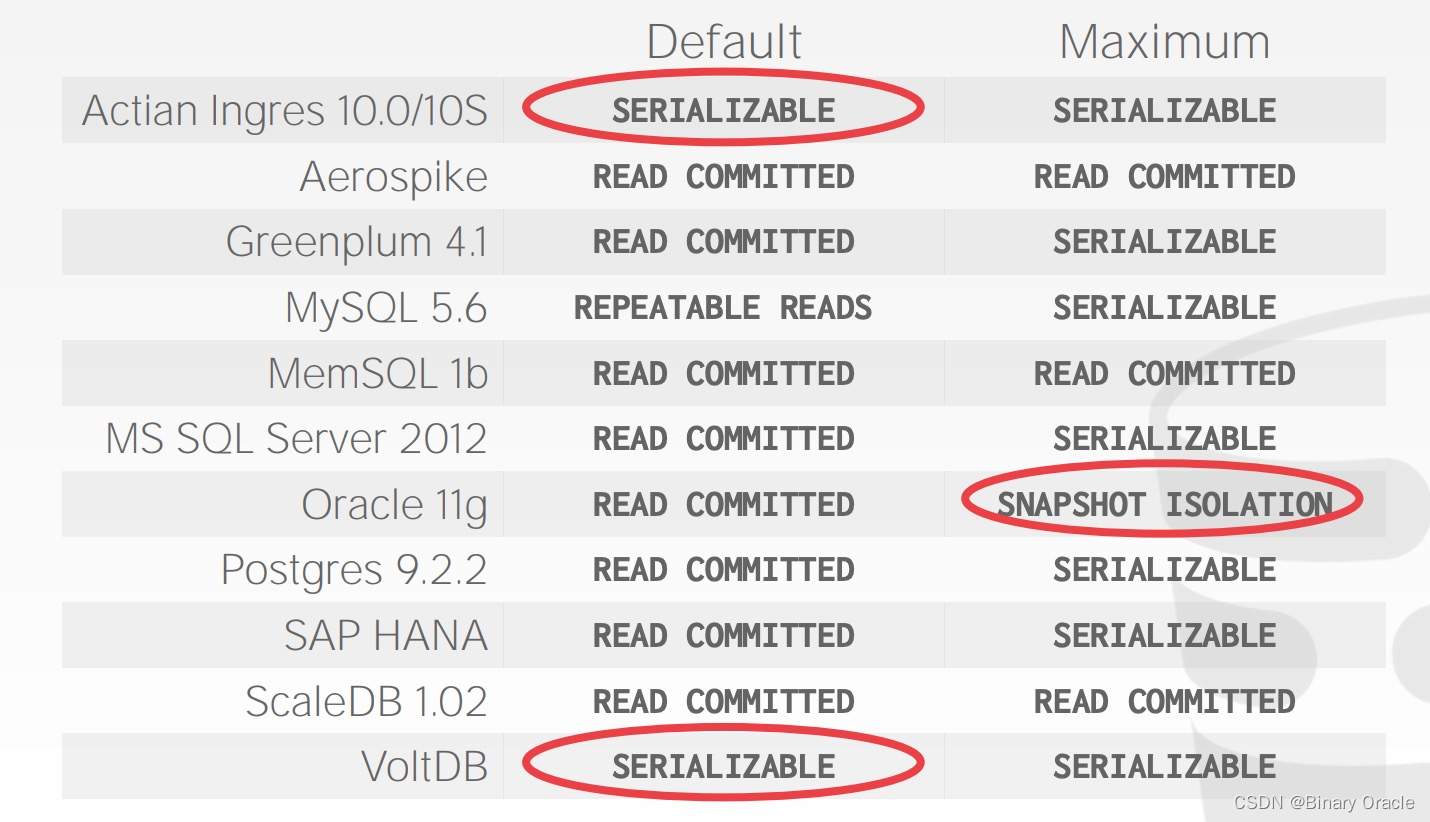
CMU 15-445 -- Timestamp Ordering Concurrency Control - 15
CMU 15-445 -- Timestamp Ordering Concurrency Control - 15 引言Basic T/OBasic T/O ReadsBasic T/O WritesBasic T/O - Example #1Basic T/O - Example #2 Basic T/O SummaryRecoverable Schedules Optimistic Concurrency Control (OCC)OCC - ExampleSERIAL VALIDATIONOCC …...

MURF2080CT/MURF2080CTR-ASEMI快恢复对管
编辑:ll MURF2080CT/MURF2080CTR-ASEMI快恢复对管 型号:MURF2080CT/MURF2080CTR 品牌:ASEMI 芯片个数:2 芯片尺寸:102MIL*2 封装:TO-220F 恢复时间:50ns 工作温度:-50C~150C…...

去除 idea warn Raw use of parameterized class ‘Map‘
去除 idea warn Raw use of parameterized class ‘Map’ 文档:Raw use of parameterized class ‘Map’… 链接:http://note.youdao.com/noteshare?id99bf4003db8cc5ae9813ee11e58c4d13&sub5856371AEFA740AF8FA4D8935B4F6912 添加链接描述 public…...

使用BERT分类的可解释性探索
最近尝试了使用BERT将告警信息当成一个文本去做分类,从分类的准召率上来看,还是取得了不错的效果(非结构化数据强标签训练,BERT确实是一把大杀器)。但准召率并不是唯一追求的目标,在安全场景下,…...

web APIs-练习二
轮播图点击切换: <!DOCTYPE html> <html lang"en"><head><meta charset"UTF-8" /><meta http-equiv"X-UA-Compatible" content"IEedge" /><meta name"viewport" content"…...

rpc通信原理浅析
rpc通信原理浅析 rpc(remote procedure call),即远程过程调用,广泛用于分布式或是异构环境下的通信,数据格式一般采取protobuf。 protobuf(protocol buffer)是google 的一种数据交换的格式,它独立于平台语…...
【机器学习】分类算法 - KNN算法(K-近邻算法)KNeighborsClassifier
「作者主页」:士别三日wyx 「作者简介」:CSDN top100、阿里云博客专家、华为云享专家、网络安全领域优质创作者 「推荐专栏」:零基础快速入门人工智能《机器学习入门到精通》 K-近邻算法 1、什么是K-近邻算法?2、K-近邻算法API3、…...

Spring Security 6.x 系列【64】扩展篇之多线程支持
有道无术,术尚可求,有术无道,止于术。 本系列Spring Boot 版本 3.1.0 本系列Spring Security 版本 6.1.0 本系列Spring Authorization Server 版本 1.1.0 源码地址:https://gitee.com/pearl-organization/study-spring-security-demo 文章目录 1. 问题演示2. 解决方案:…...

Elasticsearch 简单搜索查询案例
1.MySql表结构/数据 SET FOREIGN_KEY_CHECKS0;-- ---------------------------- -- Table structure for user_lables -- ---------------------------- DROP TABLE IF EXISTS user_lables; CREATE TABLE user_lables (id varchar(255) DEFAULT NULL COMMENT 用户唯一标识,age…...
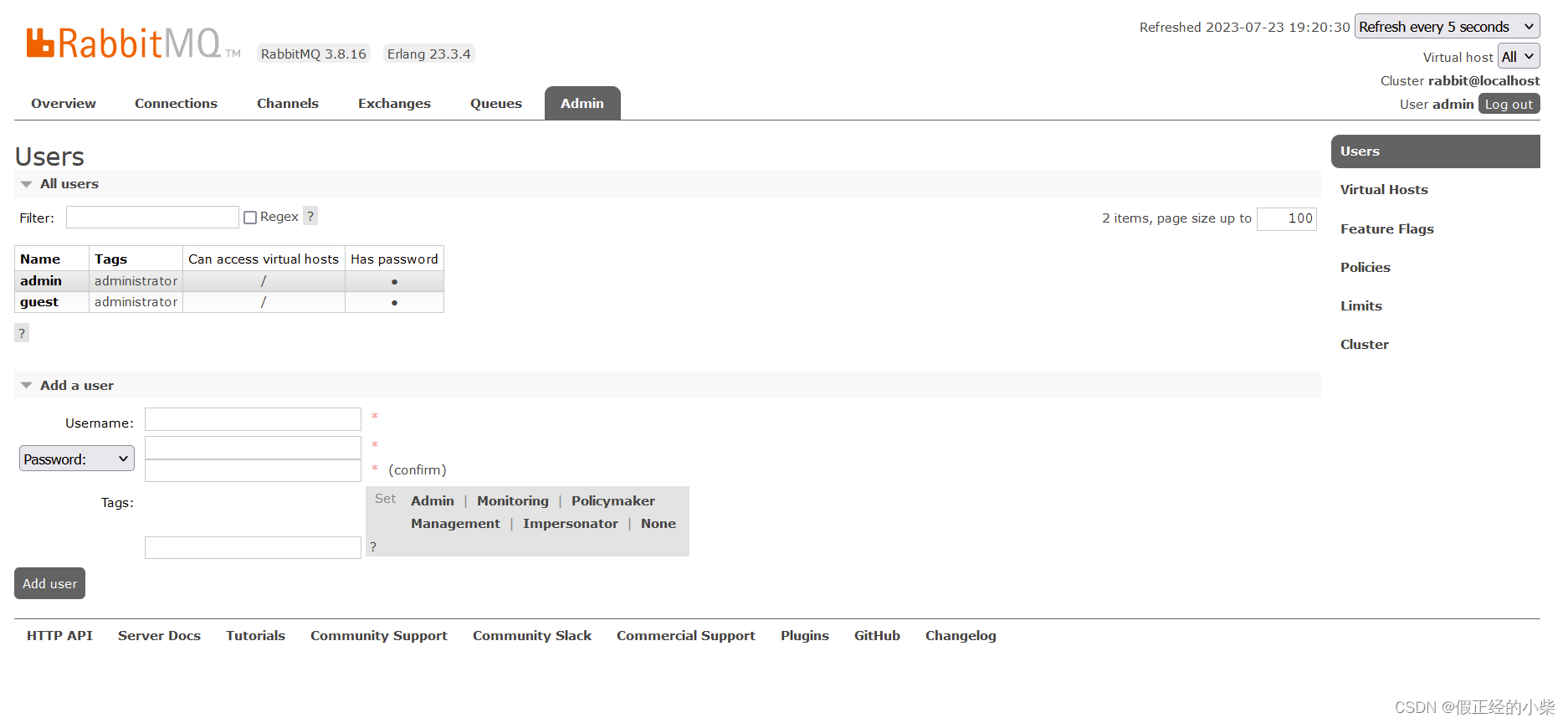
【RabbitMQ(day1)】RabbitMQ的概述和安装
入门RabbitMQ 一、RabbitMQ的概述二、RabbitMQ的安装三、RabbitMQ管理命令行四、RabbitMQ的GUI界面 一、RabbitMQ的概述 MQ(Message Queue)翻译为消息队列,通过典型的【生产者】和【消费者】模型,生产者不断向消息队列中生产消息&…...

Too many files with unapproved license: 2 See RAT report
解决方案 mvn -Prelease-nacos -Dmaven.test.skiptrue -Dpmd.skiptrue -Dcheckstyle.skiptrue -Drat.numUnapprovedLicenses100 clean install 或者 mvn -Prelease-nacos -Dmaven.test.skiptrue -Drat.numUnapprovedLicenses100 clean install...
Windows11的VTK安装:VS201x+Qt5/Qt6 +VTK7.1/VTK9.2.6
需要提前安装好VS2017和VS2019和Qt VS开发控件以及Qt VS-addin。 注意Qt6.2.4只能跟VTK9.2.6联合编译(目前VTK9和Qt6的相互支持版本)。 首先下载VTK,需要下载源码和data: Download | VTKhttps://vtk.org/download/ 然后这两个文…...

大数据时代个人信息安全保护小贴士
个人信息安全保护小贴士 1. 朋友圈“五不晒”2. 手机使用“四要”、“六不要”3. 电脑使用“七注意”4. 日常上网“七注意”5. 日常生活“五注意” 互联网就像公路,用户使用它,就会留下脚印。 每个人都在无时不刻的产生数据,在消费数据的同时…...
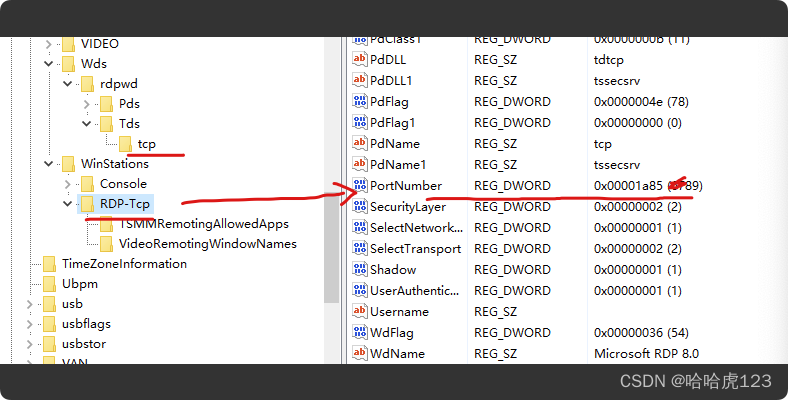
windows 修改 RDP 远程桌面端口号
打开 PowerShell , 执行regedit 依次展开 PortNumber HKEY_LOCAL_MACHINE \SYSTEM \CurrentControlSet \Control \Terminal Server \WinStations \RDP-Tcp 右边找到 PortNumber ,对应修改自己的端口号 HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Co…...
:如何在 TypeScript 中使用类和继承?)
面试题-TS(四):如何在 TypeScript 中使用类和继承?
面试题-TS(4):如何在 TypeScript 中使用类和继承? 在TypeScript中,类是一种重要的概念,它允许我们使用面向对象的编程风格来组织和管理代码。类提供了一种模板,用于创建具有相同属性和行为的对象。通过继承࿰…...

React之JSX的介绍与使用步骤,注意事项,条件渲染,列表渲染以及css样式处理
React之JSX的介绍与使用 一、JSX的介绍二、JSX使用步骤三、JSX注意事项四、JSX中使用JavaScript表达式五、条件渲染六、列表渲染七、CSS样式处理八、JSX 总结 一、JSX的介绍 简介 JSX是JavaScript XML的简写,表示了在Javascript代码中写XML(HTML)格式的代码 优势 声…...
)
sql进阶:求满足某列数值相加无限接近90%的行(90分位)
sql 一、案例分析二、思路三、代码实现一、案例分析 表中有某个id列和数值列,求数值列占比为90%的id,如有个用户表,存储id和消费金额order_cnt,求一条sql查出消费占比无限接近90%的所有客户,如表中总消费为10000,占比最高的是4000、3000、2800,对应A、B、C用户,查出A、B、C用户…...

ssm+java2026年毕设私教预约系统【源码+论文】
本系统(程序源码)带文档lw万字以上 文末可获取一份本项目的java源码和数据库参考。系统程序文件列表开题报告内容一、选题背景关于会议管理问题的研究,现有研究主要以传统纸质登记和简单的OA系统为主,专门针对智能化、全流程会议预…...

【LAMMPS实战】从文献到模拟:精准定位与获取ReaxFF反应力场参数文件
1. 初识ReaxFF反应力场:为什么我们需要它? 第一次接触分子动力学模拟时,我完全被各种力场搞晕了。直到遇到需要模拟化学反应的情况,才发现普通的力场根本不够用。这时候ReaxFF反应力场就像救命稻草一样出现了。简单来说࿰…...

气候降尺度全流程实战:从 CMIP6 数据到极端气候预估,科研人一站式通关
做水文气象、气候学、地理遥感、生态环境等领域的科研人,是不是都逃不过这些噩梦:尺度鸿沟难跨越:GCM 粗网格(>100km)和流域 / 城市精细尺度(<10km)不匹配,动力降尺度成本太高…...
)
哲学家吃饭问题没搞懂?用Python模拟信号量帮你彻底理解进程同步(附可运行代码)
用Python动态模拟哲学家进餐问题:从死锁到解决方案的完整实践指南 在操作系统的学习中,哲学家进餐问题堪称进程同步与死锁的"经典案例"。这个看似简单的场景却蕴含着并发编程中最棘手的挑战——如何协调多个进程对有限资源的访问。本文将带你…...

DML实战:价格弹性预测的经济学与机器学习融合之道
1. 价格弹性预测:经济学与机器学习的碰撞 第一次听说价格弹性还能用机器学习预测时,我的反应和大多数经济学背景的同事一样:"这不就是个回归问题吗?"直到亲眼看到某电商平台用DML模型把促销预算节省了23%,才…...

英飞凌AURIX TC3XX GPIO驱动配置与LED呼吸灯实现
1. 认识AURIX TC3XX的GPIO模块 第一次接触英飞凌AURIX TC3XX系列MCU时,我被它强大的GPIO功能惊艳到了。这不仅仅是一个简单的数字输入输出接口,而是集成了多种高级特性的硬件模块。在实际汽车电子项目中,比如氛围灯控制、状态指示灯等场景&a…...

LazyLLM架构设计揭秘:低代码如何支撑复杂多Agent系统
LazyLLM架构设计揭秘:低代码如何支撑复杂多Agent系统 【免费下载链接】LazyLLM 项目地址: https://gitcode.com/gh_mirrors/la/LazyLLM 在当今AI应用开发领域,构建复杂的多Agent系统往往需要大量的工程投入和专业知识。然而,LazyLLM框…...

3步释放华硕笔记本潜能:G-Helper轻量化控制工具的极致优化指南
3步释放华硕笔记本潜能:G-Helper轻量化控制工具的极致优化指南 【免费下载链接】g-helper Lightweight Armoury Crate alternative for Asus laptops. Control tool for ROG Zephyrus G14, G15, G16, M16, Flow X13, Flow X16, TUF, Strix, Scar and other models …...

终极文档处理方案:AnythingLLM如何实现PDF/TXT/DOCX全格式智能解析
终极文档处理方案:AnythingLLM如何实现PDF/TXT/DOCX全格式智能解析 【免费下载链接】anything-llm 这是一个全栈应用程序,可以将任何文档、资源(如网址链接、音频、视频)或内容片段转换为上下文,以便任何大语言模型&am…...

FPGA信号调试必备:Quartus中keep、preserve、noprune的正确用法与避坑指南
FPGA信号调试必备:Quartus中keep、preserve、noprune的正确用法与避坑指南 在FPGA开发过程中,信号调试是最令人头疼的环节之一。特别是当你发现仿真时明明存在的关键信号,在综合后却神秘消失时,那种挫败感简直难以言表。作为一名长…...