[NLP]LLaMA与LLamMA2解读
摘要
Meta最近提出了LLaMA(开放和高效的基础语言模型)模型参数包括从7B到65B等多个版本。最值得注意的是,LLaMA-13B的性能优于GPT-3,而体积却小了10倍以上,LLaMA-65B与Chinchilla-70B和PaLM-540B具有竞争性。
一、引言
一般而言,模型越大,效果越好。然而有文献指出[1],当给定计算量的预算之后,最好的performance,并不是最大的模型,而是在一个小模型上用更多的数据进行训练。针对给定的计算量预算,scaling laws可以计算如何选择数据量的大小和模型的大小。然而这忽略了inference的预算,而这一点在模型推理时非常关键。当给定一个模型performance目标之后,最好的模型不是训练最快的模型,而是推理最快的模型。尽管在这种情况下,训练一个更大的模型成本会更低。
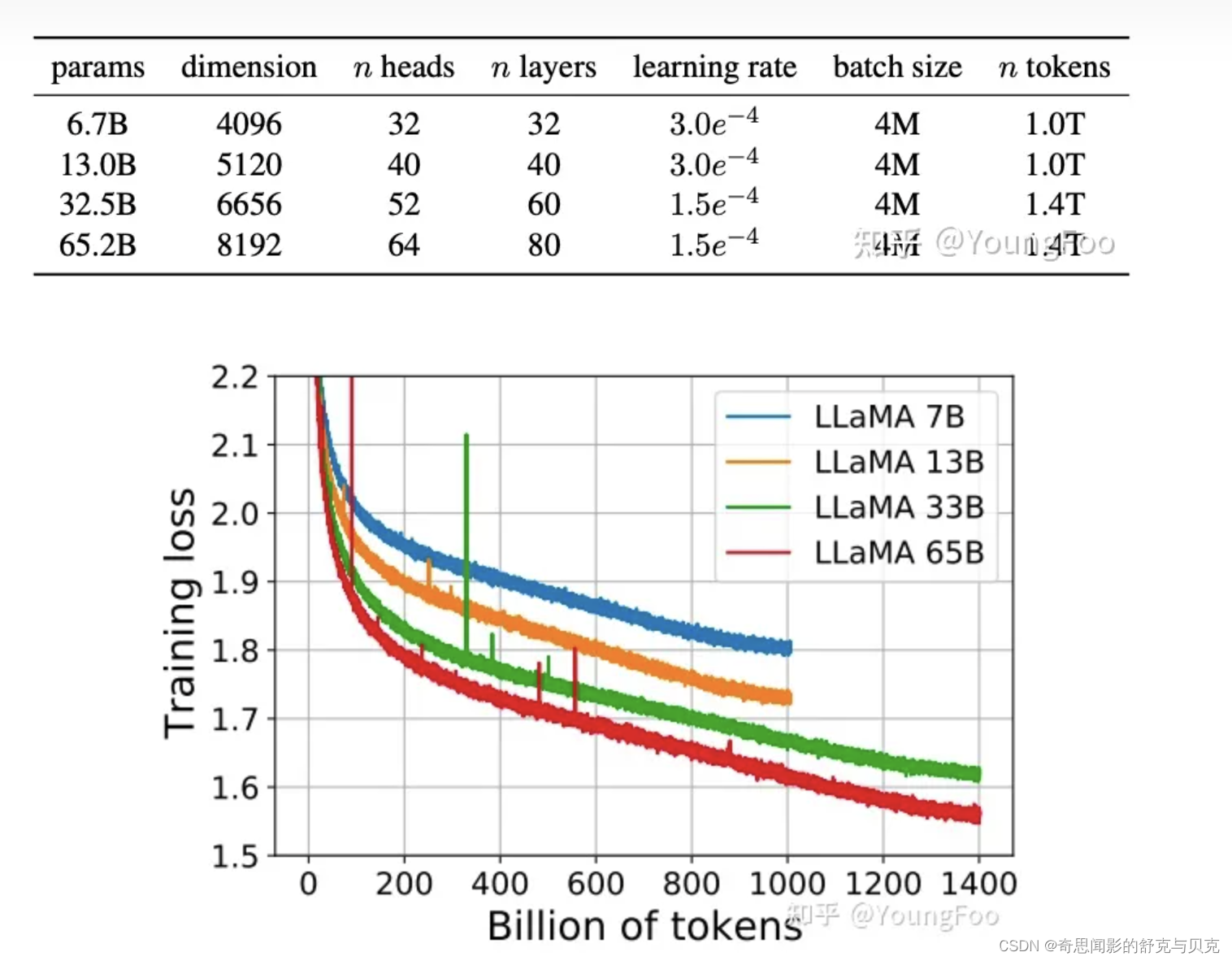
文献[2]中推荐,训练一个 10B 的模型,需要 200B 的 tokens,而本文的实验发现,一个7B的模型,经过 1T tokens 训练之后,performance 仍然在增加。本文的目标在于,通过在超大规模的数据上训练,给出一系列可能最好 performance 的 LLM。
二、预训练数据
2.1 数据集
训练语料是混合的开源语料,中文占比很低,几乎不支持中文。详细占比为:CommonCrawl 67%, C4 15%, GitHub 4.5%, Wikipedia 4.5%, Books 4.5%, ArXiv 2.5%, Stack Exchange 2%.
一共有1.4T的tokens,大部分的训练数据都只用了一次,除了Wikipedia 和 Books 使用了大概2个epochs。

2.2 Tokenizer
使用byte pair encoding (BPE) 算法,使用的是Sentence-Piece的实现。所有数字被拆分为单独的digit,所有未知的UTF-8 字符,回退到字节来进行分解。因此,LLaMA 可以通过byte 的方式,构造出很多不在 vocab 中的字符,从而也具有较好的多语言能力。
三、网络结构改进
优化器
论文的模型使用AdamW优化器(Loshchilov和Hutter,2017)进行训练,具有以下超参数:
 使用余弦学习率计划,使得最终学习率等于最大学习率的10%。论文使用0.1的权重衰减和1.0的梯度剪裁。使用2000个预热步骤,并随着模型的大小而改变学习率和批次大小。
使用余弦学习率计划,使得最终学习率等于最大学习率的10%。论文使用0.1的权重衰减和1.0的梯度剪裁。使用2000个预热步骤,并随着模型的大小而改变学习率和批次大小。
使用了基于transformer的架构,并做了如下3点改进:
3.1 Pre-normalization
为了提高训练的稳定性,对每个transformer层的输入进行归一化,而不是输出进行归一化。
同时,使用 RMS Norm 归一化函数。RMS Norm 的全称为 Root Mean Square layer normalization。与 layer Norm 相比,RMS Norm的主要区别在于去掉了减去均值的部分,计算公式为:
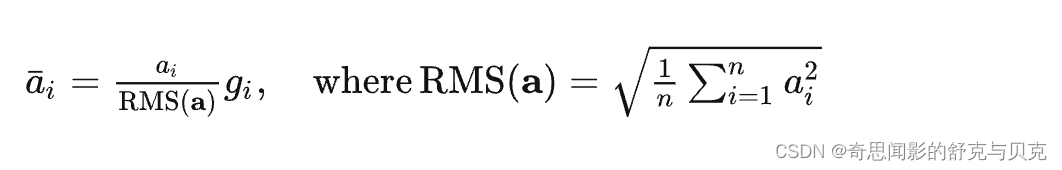
RMS Norm 的作者认为这种模式在简化了Layer Norm 的计算,可以在减少约 7%∼64% 的计算时间[3]。
class LlamaRMSNorm(nn.Module):def __init__(self, hidden_size, eps=1e-6):"""LlamaRMSNorm is equivalent to T5LayerNorm"""super().__init__()self.weight = nn.Parameter(torch.ones(hidden_size))self.variance_epsilon = epsdef forward(self, hidden_states):input_dtype = hidden_states.dtypevariance = hidden_states.to(torch.float32).pow(2).mean(-1, keepdim=True)hidden_states = hidden_states * torch.rsqrt(variance + self.variance_epsilon)return (self.weight * hidden_states).to(input_dtype)3.2 SwiGLU
使用SwiGLU替代了ReLU作为激活函数。和PaLM中不同,维度采用 234� 而不是 4� 。
SwiGLU 在论文[4] 中提出,相比于其他的激活函数变体,可以取得 log-perplexity 的最优值(和 GEGLU 并列)。

class LlamaMLP(nn.Module):def __init__(self,hidden_size: int,intermediate_size: int,hidden_act: str,):super().__init__()self.gate_proj = nn.Linear(hidden_size, intermediate_size, bias=False)self.down_proj = nn.Linear(intermediate_size, hidden_size, bias=False)self.up_proj = nn.Linear(hidden_size, intermediate_size, bias=False)# config 中 hidden_act = 'silu'# 'silu' 和 'swish' 对应的激活函数均为:SiLUActivation # https://github.com/huggingface/transformers/blob/717dadc6f36be9f50abc66adfd918f9b0e6e3502/src/transformers/activations.py#L229self.act_fn = ACT2FN[hidden_act]def forward(self, x):# 对应上述公式的 SwiGLUreturn self.down_proj(self.act_fn(self.gate_proj(x)) * self.up_proj(x))
从代码可以看到 LlamaMLP 中一共有 3 个 Linear 层,原因就在于 SwiGLU 激活函数比类似 ReLU 的激活函数,需要多一个 Linear 层进行门控。
3.3 RoPE
RoPE 的核心思想是“通过绝对位置编码的方式实现相对位置编码”,可以说是具备了绝对位置编码的方便性,同时可以表示不同 token 之间的相对位置关系。[5] 不同于原始 Transformers 论文中,将 pos embedding 和 token embedding 进行相加,RoPE 是将位置编码和 query (或者 key) 进行相乘。具体如下:
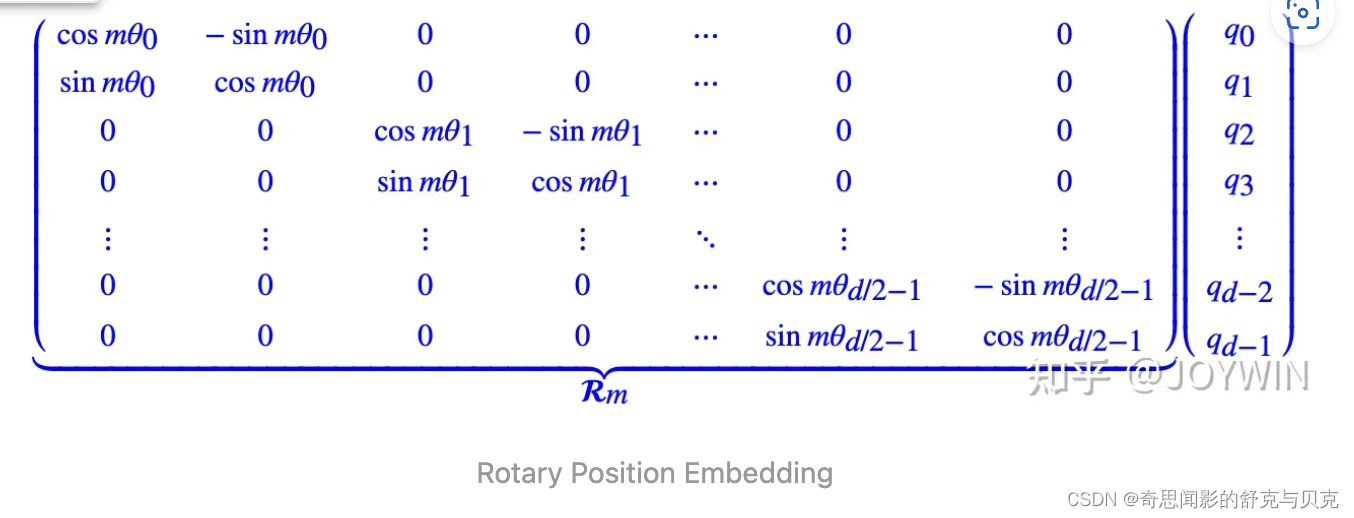

# 代码增加了注释,可以看到和原始公式的对应关系。
class LlamaRotaryEmbedding(torch.nn.Module):def __init__(self, dim, max_position_embeddings=2048, base=10000, device=None):super().__init__()# 此处 inv_freq 对应公式中的 thetainv_freq = 1.0 / (base ** (torch.arange(0, dim, 2).float().to(device) / dim))self.register_buffer("inv_freq", inv_freq)self.max_seq_len_cached = max_position_embeddingst = torch.arange(self.max_seq_len_cached, device=self.inv_freq.device, dtype=self.inv_freq.dtype)# 此处 freqs 对应公式中的 m * theta, t 对应公式中的 m,表示位置freqs = torch.einsum("i,j->ij", t, self.inv_freq)# Different from paper, but it uses a different permutation in order to obtain the same calculation# 此处和原始公式不同,theta_0 和 theta_0 不再相邻# 而是分在向量的前半部分和后半部分emb = torch.cat((freqs, freqs), dim=-1)dtype = torch.get_default_dtype()self.register_buffer("cos_cached", emb.cos()[None, None, :, :].to(dtype), persistent=False)self.register_buffer("sin_cached", emb.sin()[None, None, :, :].to(dtype), persistent=False)def forward(self, x, seq_len=None):# x: [bs, num_attention_heads, seq_len, head_size]if seq_len > self.max_seq_len_cached:self.max_seq_len_cached = seq_lent = torch.arange(self.max_seq_len_cached, device=x.device, dtype=self.inv_freq.dtype)freqs = torch.einsum("i,j->ij", t, self.inv_freq)# Different from paper, but it uses a different permutation in order to obtain the same calculationemb = torch.cat((freqs, freqs), dim=-1).to(x.device)self.register_buffer("cos_cached", emb.cos()[None, None, :, :].to(x.dtype), persistent=False)self.register_buffer("sin_cached", emb.sin()[None, None, :, :].to(x.dtype), persistent=False)# 大部分情况下,直接从这里返回return (self.cos_cached[:, :, :seq_len, ...].to(dtype=x.dtype),self.sin_cached[:, :, :seq_len, ...].to(dtype=x.dtype),)def rotate_half(x):"""Rotates half the hidden dims of the input."""# 此次和原始推导中不同,正负号不是间隔的,而是分前半部分和后半部分。但对于结果没有影响x1 = x[..., : x.shape[-1] // 2]x2 = x[..., x.shape[-1] // 2 :]return torch.cat((-x2, x1), dim=-1)def apply_rotary_pos_emb(q, k, cos, sin, position_ids):# The first two dimensions of cos and sin are always 1, so we can `squeeze` them.cos = cos.squeeze(1).squeeze(0) # [seq_len, dim]sin = sin.squeeze(1).squeeze(0) # [seq_len, dim]cos = cos[position_ids].unsqueeze(1) # [bs, 1, seq_len, dim]sin = sin[position_ids].unsqueeze(1) # [bs, 1, seq_len, dim]# 对应上图中 RoPE 的简化计算q_embed = (q * cos) + (rotate_half(q) * sin)k_embed = (k * cos) + (rotate_half(k) * sin)return q_embed, k_embed四、高效实现
加速训练:
- 使用 随机多头注意力机制(causal multi-head attention) 提高模型的训练速度。该机制的实现借用了xformers库,它的思路是不存储注意力权重,不计算其中注意力得分
- 手动实现了Transformer的激活函数,而没有用pytorch库的autograd,以得到更优的训练速度。同时使用了并行化技术提高训练速度。
- 减少了activation checkpointing 中,重新计算 activation 的计算量。手动实现 transformer 层的反向传递函数,保存了计算成本高的 activations,例如线性层的输出。
- 通过使用 model parallelism 和 sequence parallelism 来减少显存的使用量。
- 尽可能地将 activations 的计算和GPU之间的通讯进行并行。
加速效果:
- 65B的模型,在2048个80G的A100 GPU上,可以达到380 tokens/sec/GPU的速度。训练1.4T tokens需要21天。
五、主要结果与结论
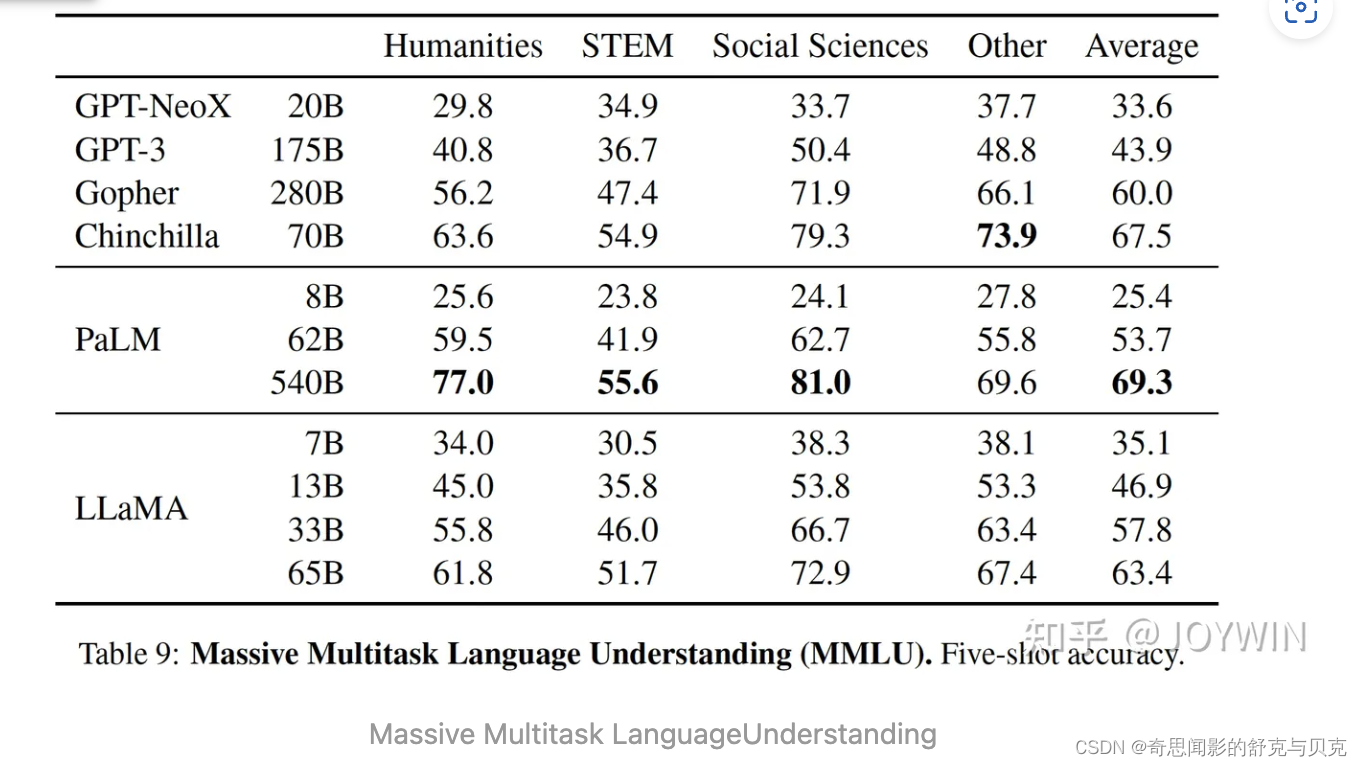
LLaMA-13B 优于 GPT-3,尽管只有1/10大小。 LLaMA-65B 是可以与 Chinchilla-70B 和 PaLM-540B 这种最佳的LLM相竞争的模型。经过微调之后,LLaMA的效果有显著的提升。
未来打算发布在更大的语料上预训练上的更大的模型,因为随着数据和模型的增大,可以看到 performance 的稳定提升。
五、高效实现
LLaMA2的开源地址:https://github.com/facebookresearch/llama/blob/main/MODEL_CARD.md
LLaMA2的下载地址:https://ai.meta.com/resources/models-and-libraries/llama-downloads/
LLaMA2的官方博客地址:https://ai.meta.com/resources/models-and-libraries/llama/
技术细节记录:
- 模型尺寸:LLaMA 2提供了三种不同的模型尺寸:7B、13B和70B。其中,7B和13B的架构与LLaMA 1相同,可直接用于商业应用。
- 训练:LLaMA 2模型经过了2万亿个标记的训练,其上下文长度是LLaMA 1的两倍。此外,LLaMA-2-chat模型还接受了超过100万个新的人类注释的训练。LLaMA 2的训练语料比LLaMA 1多出40%,上下文长度从2048增加到4096,使其能够理解和生成更长的文本。
- 预训练:LLaMA 2使用公开的在线数据进行预训练,然后通过监督微调创建LLaMA-2-chat的初始版本。接下来,LLaMA-2-chat使用人类反馈强化学习(RLHF)进行迭代细化,其中包括拒绝采样和近端策略优化(PPO)。
- 模型架构:LLaMA 2采用了LLaMA 1的大部分预训练设置和模型架构,使用标准Transformer架构,使用RMSNorm应用预归一化、使用SwiGLU激活函数和旋转位置嵌入RoPE。与LLaMA 1的主要架构差异包括增加了上下文长度和分组查询注意力(GQA)。
- 分组查询注意力(GQA):这是一个新的注意力机制,可以提高大模型的推理可扩展性。它的工作原理是将键和值投影在多个头之间共享,而不会大幅降低性能。可以使用具有单个KV投影的原始多查询格式(MQA)或具有8KV投影的分组查询注意力变体(GQA)。
- 超参数:使用AdamW优化器进行训练,其中β1=0.9,β2=0.95,eps=10−5。使用余弦学习率计划,预热2000步,衰减最终学习率降至峰值学习率的10%。使用0.1的权重衰减和1.0的梯度裁剪。
- 分词器:LLaMA 2使用与LLaMA 1相同的分词器;它采用字节对编码(BPE)算法,使用SentencePiece实现。与LLaMA 1一样,将所有数字拆分为单独的数字,并使用字节来分解未知的UTF-8字符。总数词汇量为32k个token。
- 微调:LLaMA 2-Chat是数月实验研究和对齐技术迭代应用的结果,包括指令微调和RLHF,需要大量的计算和数据标注资源。有监督微调指令数据质量非常重要,包括多样性,注重隐私安全不包含任何元用户数据。
- 安全性:该研究使用三个常用基准评估了Llama 2的安全性,针对三个关键维度:真实性,指语言模型是否会产生错误信息,采用TruthfulQA基准;毒性,指语言模型是否会产生「有毒」、粗鲁、有害的内容,采用ToxiGen基准;偏见,指语言模型是否会产生存在偏见的内容,采用BOLD基准。
参考
- Training Compute-Optimal Large Language Models https://arxiv.org/abs/2203.15556
- ^Training Compute-Optimal Large Language Models https://arxiv.org/abs/2203.15556
- ^Root Mean Square Layer Normalization https://arxiv.org/pdf/1910.07467.pdf
- ^GLU Variants Improve Transformer https://arxiv.org/pdf/2002.05202.pdf
- ^Transformer升级之路:2、博采众长的旋转式位置编码 Transformer升级之路:2、博采众长的旋转式位置编码 - 科学空间|Scientific Spaces
- ^https://github.com/huggingface/transformers/blob/main/src/transformers/models/llama/modeling_llama.py#L91
相关文章:
[NLP]LLaMA与LLamMA2解读
摘要 Meta最近提出了LLaMA(开放和高效的基础语言模型)模型参数包括从7B到65B等多个版本。最值得注意的是,LLaMA-13B的性能优于GPT-3,而体积却小了10倍以上,LLaMA-65B与Chinchilla-70B和PaLM-540B具有竞争性。 一、引言 一般而言࿰…...
后端一次返回大量数据,前端做分页处理
问题描述:后端接口返回大量数据,没有做分页处理,不支持传参pageNum,pageSize 本文为转载文章,原文章:后端一次返回大量数据,前端做分页处理 1.template中 分页 <el-paginationsize-chang…...
卷积神经网络识别人脸项目—使用百度飞桨ai计算
卷积神经网络识别人脸项目的详细过程 整个项目需要的准备文件: 下载链接: 链接:https://pan.baidu.com/s/1WEndfi14EhVh-8Vvt62I_w 提取码:7777 链接:https://pan.baidu.com/s/10weqx3r_zbS5gNEq-xGrzg 提取码&#x…...
vue中预览静态pdf文件
方法 // pdf预览 viewFileCompare() { const pdfUrl "/static/wjbd.pdf"; window.open(pdfUrl); }, // 下载 downloadFile(){ var a document.createElement("a"); a.href "/static/wjbd.pdf"; a.…...
)
Java多进程(详细)
进程的含义 简单理解是正在跑起来的程序,正在运行的程序。没有正在运行的程序不叫进程,同一个程序,运行多次,就可能产生多个进程。 平时所说的程序,值的是一些exe的可执行文件,得把程序跑起来才会涉及到进程…...

OpenCV 4.0+Python机器学习与计算机视觉实战
💂 个人网站:【办公神器】【游戏大全】【神级源码资源网】🤟 前端学习课程:👉【28个案例趣学前端】【400个JS面试题】💅 寻找学习交流、摸鱼划水的小伙伴,请点击【摸鱼学习交流群】 目录 前言第一部分&…...
自学网络安全(黑客)全笔记
一、什么是网络安全 网络安全可以基于攻击和防御视角来分类,我们经常听到的 “红队”、“渗透测试” 等就是研究攻击技术,而“蓝队”、“安全运营”、“安全运维”则研究防御技术。 无论网络、Web、移动、桌面、云等哪个领域,都有攻与防两面…...
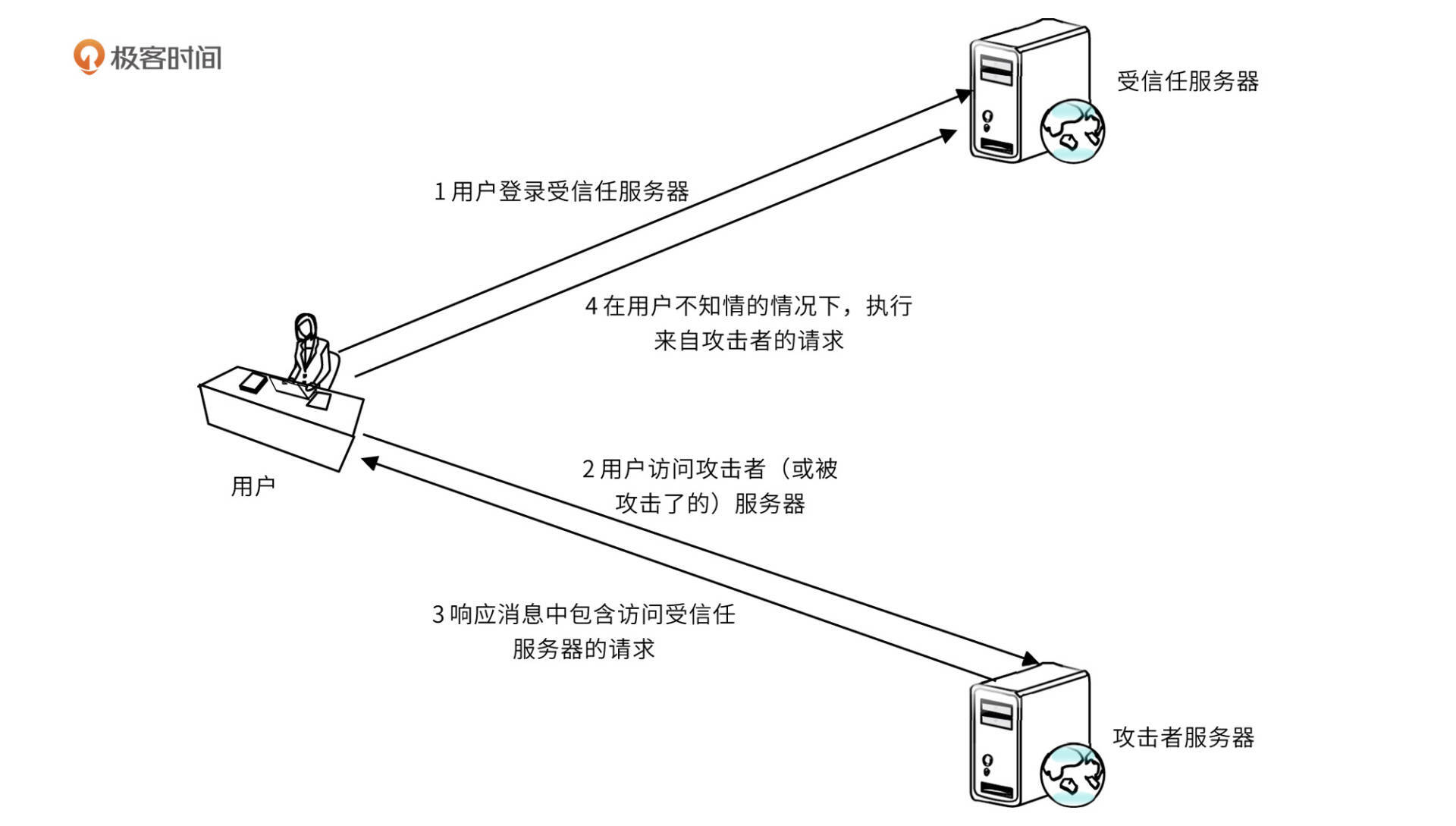
WAF/Web应用安全(拦截恶意非法请求)
Web 应用防火墙(Web Application Firewall, WAF)通过对 HTTP(S) 请求进行检测,识别并阻断 SQL 注入、跨站脚本攻击、跨站请求伪造等攻击,保护 Web 服务安全稳定。 Web 安全是所有互联网应用必须具备的功能,…...

Windows环境下git客户端中的git-bash和MinGW64
我们在 Windows10 操作系统下,安装了 git 客户端之后,可以通过 git-bash.exe 打开一个 shell: 执行一些 linux 系统里的命令: 注意到上图紫色的 MINGW64. Mingw-w64 是原始 mingw.org 项目的改进版,旨在支持 Window…...
欧姆龙CX系列PLC串口转以太网欧姆龙cp1hplc以太网连接电脑
你是否还在为工厂设备信息采集困难而烦恼?捷米特JM-ETH-CX转以太网通讯处理器为你解决这个问题! 捷米特JM-ETH-CX转以太网通讯处理器专门为满足工厂设备信息化需求而设计,可以用于欧姆龙多个系列PLC的太网数据采集,非常方便构建生…...

Vue3笔记
1. Vue2 选项式 API vs Vue3 组合式API <script> export default { data(){ return { count:0 } }, methods:{ addCount(){ this.count } } } </script> <script setup> import { ref } from vue const count ref(0) c…...
git相关
gerrit用户指南: 资料:Gerrit 用户指南 gerrit-user-guide 上述有介绍如何review,review并非修改代码之后如何重新提交等操作 jenkins介绍 Jenkins详细教程 - 知乎 一、jenkins是什么? Jenkins是一个开源的、提供友好操作界…...
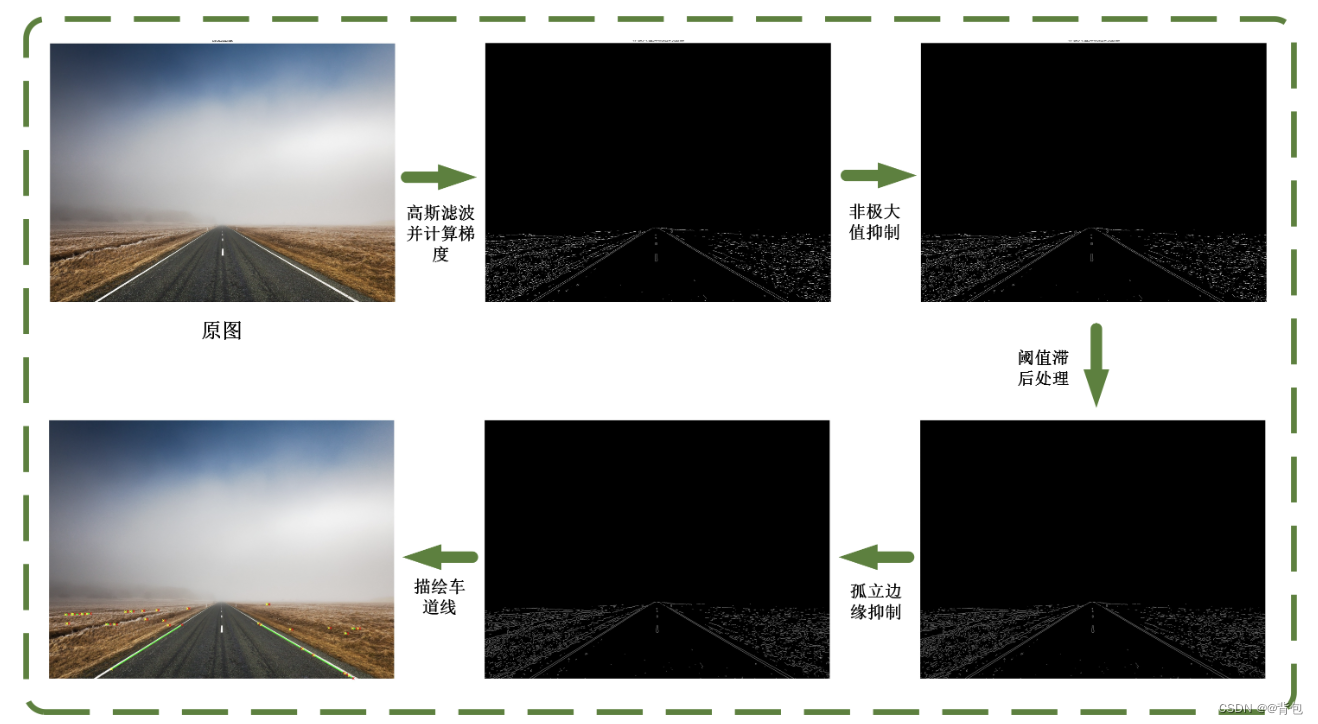
车道线检测|利用边缘检测的原理对车道线图片进行识别
前言 那么这里博主先安利一些干货满满的专栏了! 这两个都是博主在学习Linux操作系统过程中的记录,希望对大家的学习有帮助! 操作系统Operating Syshttps://blog.csdn.net/yu_cblog/category_12165502.html?spm1001.2014.3001.5482Linux S…...

C++—static关键字详解
引言: C的static有两种用法:面向过程程序设计中的static和面向对象程序设计中的static。前者应用于普通变量和函数,不涉及类;后者主要说明static在类中的作用。 一.面向过程中的static 1.静态全局变量 静态全局变量有以下特点…...

CS144学习笔记(1):Internet and IP
1.网络应用 网络应用可以在世界范围内交换数据,例如你可以通过浏览器读取出版社服务器提供的文章。网络应用的基本模型:两台主机各自在本地运行一个程序,程序通过网络来通信。 最常用的通信模型使用双向可靠字节流,通信的两台主机…...
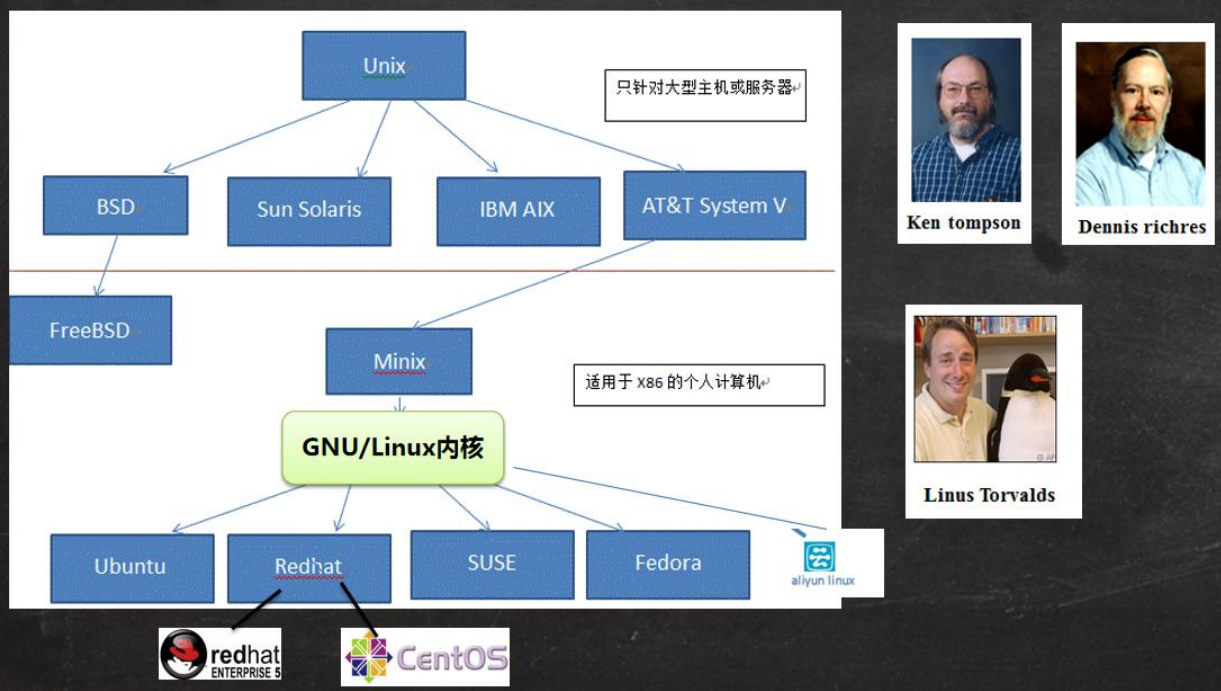
2 Linux基础篇-Linux入门
2Linux基础篇-Linux入门 文章目录 2Linux基础篇-Linux入门2.1 Linux介绍2.2 Linux和Unix的关系 学习视频来自于B站 【小白入门 通俗易懂】2021韩顺平 一周学会Linux。 2.1 Linux介绍 常见的操作系统有 Windows、MacOS、Android、ios、Linux、Unix等。而其中,Linux是…...

分享200+个关于AI的网站
分享200个关于AI的网站 欢迎大家访问:https://tools.haiyong.site/ai 快速导航 AI 应用AI 写作AI 编程AI 设计AI 作图AI 训练模型AI 影音编辑AI 效率助手 AI 应用 文心一言: https://yiyan.baidu.com/ 百度出品的人工智能语言模型 ChatGPT: https://chat.openai.c…...

静态 链接
1、空间与地址的分配 现在的链接器空间分配的策略基本上都采用 “相似段合并” 的方式。通过将所有相同类型的 section 合并到一起,例如将所有输入目标文件的 .text 合并(按顺序合并)到输出文件的 .text 节中;然后,链接…...
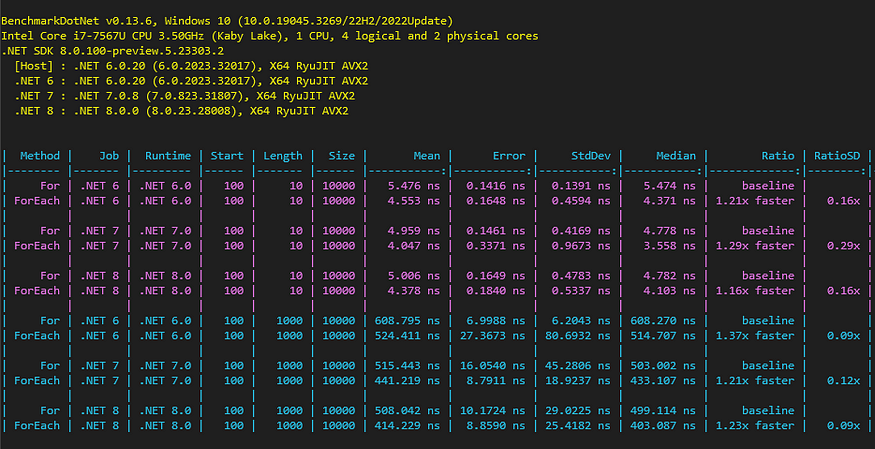
【C#性能】C# 语言中的数组迭代
一、说明 可迭代性,是数组等操作的根本;在C程序开发过程中,可迭代操作是非常普遍、非常广泛的,然而,对这种操作知道多少,又不知道多少,都将影响开发灵活性、开发的进度。因此,本文干…...
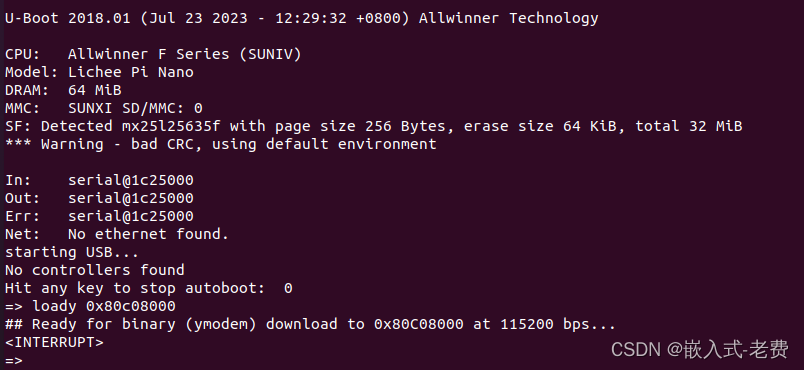
全志F1C200S嵌入式驱动开发(解决spi加载过慢的问题)
【 声明:版权所有,欢迎转载,请勿用于商业用途。 联系信箱:feixiaoxing @163.com】 之前的几个章节当中,我们陆续解决了spi-nor驱动的问题、uboot支持spi-nor的问题。按道理来说,下面要做的应该就是用uboot的loady命令把kernel、dtb、rootfs这些文件下载到ddr,然…...

OpCore-Simplify终极指南:15分钟完成黑苹果EFI配置的智能工具
OpCore-Simplify终极指南:15分钟完成黑苹果EFI配置的智能工具 【免费下载链接】OpCore-Simplify A tool designed to simplify the creation of OpenCore EFI 项目地址: https://gitcode.com/GitHub_Trending/op/OpCore-Simplify 黑苹果配置一直是技术爱好者…...

技术深度:G-Helper实现华硕笔记本精准散热控制与性能调优的架构解析
技术深度:G-Helper实现华硕笔记本精准散热控制与性能调优的架构解析 【免费下载链接】g-helper Lightweight, open-source control tool for ASUS laptops and ROG Ally. Manage performance modes, fans, GPU, battery, and RGB lighting across Zephyrus, Flow, T…...

解密MyBatis拦截器:从插件机制到实战应用
1. MyBatis拦截器基础入门 第一次接触MyBatis拦截器时,我完全被它强大的功能震撼到了。简单来说,拦截器就像是在MyBatis执行SQL过程中的"关卡",可以在特定时机插入自定义逻辑。想象一下,你正在通过一条高速公路…...

小米笔记本Hackintosh无线网卡终极解决方案:Intel Wi-Fi驱动 vs 更换模块
小米笔记本Hackintosh无线网卡终极解决方案:Intel Wi-Fi驱动 vs 更换模块 【免费下载链接】XiaoMi-Pro-Hackintosh XiaoMi NoteBook Pro Hackintosh 项目地址: https://gitcode.com/gh_mirrors/xia/XiaoMi-Pro-Hackintosh 想要在小米笔记本上完美运行macOS系…...
中的时序约束映射)
深入解析Standard Delay Format(SDF)中的时序约束映射
1. 什么是Standard Delay Format(SDF)? Standard Delay Format(标准延迟格式)是数字电路设计中用于描述时序信息的标准文件格式。简单来说,它就像电路设计的"时间说明书",告诉EDA工具信号在电路中传播需要多…...

利用快马平台与ccswitch快速构建可切换功能模块的web应用原型
今天想和大家分享一个快速验证前端功能模块切换方案的小技巧。最近在做一个需要动态切换不同功能模块的项目,尝试了用ccswitch工具配合InsCode(快马)平台来搭建原型,效果出乎意料地好。 为什么选择ccswitch ccswitch是一个轻量级的JavaScript工具&…...

颠覆式角色定制:开源工具Diablo Edit2如何重塑暗黑破坏神2游戏体验
颠覆式角色定制:开源工具Diablo Edit2如何重塑暗黑破坏神2游戏体验 【免费下载链接】diablo_edit Diablo II Character editor. 项目地址: https://gitcode.com/gh_mirrors/di/diablo_edit 在暗黑破坏神2的冒险旅程中,每位玩家都曾面临存档管理的…...

CefFlashBrowser终极指南:5个步骤让Flash内容在现代系统重生
CefFlashBrowser终极指南:5个步骤让Flash内容在现代系统重生 【免费下载链接】CefFlashBrowser Flash浏览器 / Flash Browser 项目地址: https://gitcode.com/gh_mirrors/ce/CefFlashBrowser 当Adobe在2020年正式终止Flash Player支持时,无数经典…...

WeKnora知识沉淀方法论:构建企业数字资产的完整流程
WeKnora知识沉淀方法论:构建企业数字资产的完整流程 1. 引言 在信息爆炸的时代,企业每天产生大量文档、报告、邮件等知识资产,但这些宝贵资源往往散落在各个角落,难以有效利用。传统的关键词搜索已经无法满足企业对知识管理的需…...

程序员必看!高质量免费源码网推荐
在数字化浪潮席卷全球的今天,代码已成为驱动创新的核心动力。无论是初创企业快速搭建商业平台,还是开发者优化项目架构,高质量的源码资源都能显著缩短研发周期、降低开发成本。然而,面对网络上鱼龙混杂的源码平台,如何…...