Redis概述及安装、使用和管理
目录
一、NoSQL非关系型数据库
1.NoSQL概述
2.关系型数据库和非关系型数据库区别
(1)数据存储方式不同
(2)扩展方式不同
(3)对事务性的支持不同
3.非关系型数据库使用场景
二、Redis概述
1.简介
2.优点
3.Redis读写快的原因
4.适用场景
三、Redis安装配置
四、Redis的使用
1.命令行工具redis-cli(登录)
2.测试工具redis-benchmark(测试)
3.redis命令的使用
4.Redis多库常用命令
五、Redis性能管理
1.查看内存使用
2.清理内存碎片
(1)内存碎片如何产生
(2)内存碎片率
(3)清理内存碎片
3.内存使用率
4.内回收key
一、NoSQL非关系型数据库
1.NoSQL概述
NoSQL (Not Only SQL),是非关系型数据库的总称。除了主流的关系型数据库外的数据库,都认为是非关系型。
不需要预先建库建表定义数据存储表结构,每条记录可以有不同的数据类型和字段个数(比如微信群聊里的文字、图片、视频、音乐等)。
主流的 NoSQL数据库有 Redis、MongBD、Hbase、Memcached、ElasticSearch、TSD等。
2.关系型数据库和非关系型数据库区别
(1)数据存储方式不同
关系型和非关系型数据库的主要差异是数据存储的方式。
SQL数据库天然就是表格式的,因此存储在数据表的行和列中。数据表可以彼此关联协作存储,也很容易提取数据。
NoSQL型数据不适合存储在数据表的行和列中,而是大块组合在一起。非关系型数据通常存储在数据集中,就像文档、键值对或者图结构。你的数据及其特性是选择数据存储和提取方式的首要影响因素。
(2)扩展方式不同
关系型和非关系型数据库最大的差别是在扩展方式上,要支持日益增长的需求当然要扩展。
SQL数据库是纵向扩展,也就是说提高处理能力,使用速度更快速的计算机,这样处理相同的数据集就更快了。因为数据存储在关系表中,操作的性能瓶颈可能涉及很多个表,这都需要通过提高计算机性能来克服。虽然sql数据库有很大扩展空间,但最终肯定会达到纵向扩展的上限。
NoSQL数据库是横向扩展的。因为非关系型数据存储天然就是分布式的,NoSQL数据库的扩展可以通过给资源池添加更多普通的数据库服务器:节点)来分担负载。
(3)对事务性的支持不同
如果数据操作需要高事务性或者复杂数据查询需要控制执行计划,那么传统的SQL数据库从性能和稳定性方面考虑是你的最佳选择。
SQL数据库支持对事务原子性细粒度控制,并且易于回滚事务。
虽然NoSQL数据库也可以使用事务操作,但稳定性方面没法和关系型数据库比较。所以它们真正闪亮的价值是在操作的扩展性和大数据量处理方面。
3.非关系型数据库使用场景
可用于应对web2.0纯动态网站类型的三高问题(高并发、高性能、高可用)。
- High performance——对数据库高并发读写需求;
- Huge Storage——对海量数据高效存储与访问需求;
- High Scalability and High Availability——对数据库高可扩展性与高可用性需求。
关系型数据库和非关系型数据库都有各自的特点与应用场景,两者的紧密结合将会给web2.0的数据库发展带来新的思路:
关系型数据库关注在关系和对数据的一致性保障上;
非关系型数据库关注在存储和高效率上。
例如:在读写分离的Mysql数据库环境中,可以把经常访问的数据存储在非关系型数据库中,提升访问速度。
二、Redis概述
1.简介
Redis(远程字典服务器)是一个开源的、使用c语言编写的 NoSQL数据库。
Redis基于内存运行并支持持久化,采用key-value(键值对)的存储形式,是目前分布式架构中不可或缺的一环。
Redis服务器程序是单进程模型,也就是在一台服务器上可以同时启动多个Redis进程,Redis的实际处理速度则是完全依靠主进程的执行效率。
2.优点
具有极高的数据读写速度:数据读取的速度最高可达到110000 次/s,数据写入速度最高可达到 81000 次/s。
支持丰富的数据类型:支持 key-value、Strings、Lists、Hashes、Sets 及 Sorted Sets等数据类型操作。
支持数据的持久化:可以将内存中的数据保存在磁盘中,重启的时候可以再次加载进行使用。
原子性:Redis 所有操作都是原子性的。
支持数据备份:即支持 master-salve 模式的数据备份。
3.Redis读写快的原因
Redis基于内存运行,避免了磁盘I/O等耗时操作。
Redis命令处理的核心模块为单线程,减少了锁竞争,以及频繁创建线程和销毁线程的代价,减少了线程上下文切换的消耗。
注:在Redis 6.0 中新增加的多线程也只是针对处理网络请求过程采用了多线性,而数据的读写命令,仍然是单线程处理的。
采用了I/O多路复用机制,减少网络I/O消耗,大大提升了并发效率。
4.适用场景
Redis作为基于内存运行的数据库,是一个高性能的缓存,一般应用在session缓存、队列
、排行榜、计数器、最近最热文章、最近最热评论、发布订阅等。
Redis 适用于数据实时性要求高、数据存储有过期和淘汰特征的、不需要持久化或者只需
要保证弱一致性、逻辑简单的场景。
三、Redis安装配置
#将安装包放在/opt下
cd /opt
tar xf redis-5.0.7.tar.gz
cd redis-5.0.7/#编译
make#安装到指定目录
make install PREFIX=/usr/local/redis
还需要到安装包中的utils/下,执行install_server.sh

再在配置文件/etc/redis/6379.conf中修改监听地址


四、Redis的使用
| 工具 | 作用 |
|---|---|
| redis-server | 用于启动redis的工具 |
| redis-benchmark | 用于检测redis在本机的运行效率 |
| redis-check-aof | 修复AOF持久化文件 |
| redis-check-rdb | 修复RDB持久化文件 |
| redis-cli | redis命令行工具 |
1.命令行工具redis-cli(登录)

2.测试工具redis-benchmark(测试)
redis-benchmark [选项] [选项值]
-h 指定服务器主机名
-p 指定服务器端口
-s 指定服务器 socket
-c 指定并发连接数
-n 指定请求数
-d 以字节的形式指定SET/GET值的数据大小
-k 1代表keep alive保持连接 ;0代表reconnect重连
-r SET、GET、INCR 使用随机key ;SADD使用随机值
-P 通过管道传输<numreg>请求
-q 强制退出redis 仅显示query/sec值
--csv 以CSV格式(,分割字段的文本)输出
-l 生成循环,永久执行测试
-t 仅运行以逗号分隔的测试命令列表
-I Idle模式(仅打开N个idle连接并等待)
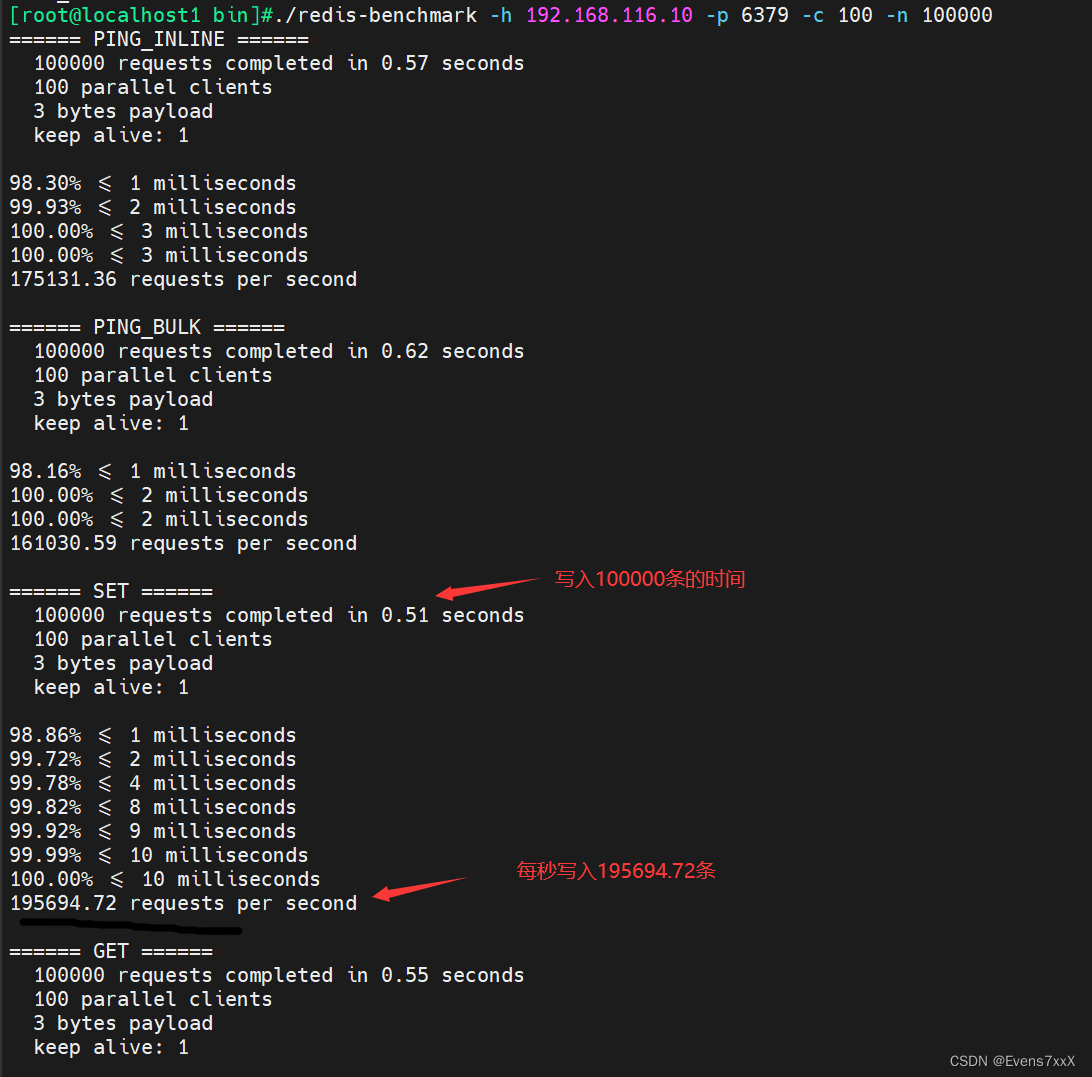
#向IP地址为192.168.109.133、端口为6379的Redis服务器发送100个并发连接与100000个请求测试性能
redis-benchmark -h 192.168.116.10 -p 6379 -c 100 -n 100000
#测试存取大小为100字节的数据包的性能
redis-benchmark -h 192.168.116.10 -p 6379 -q -d 100
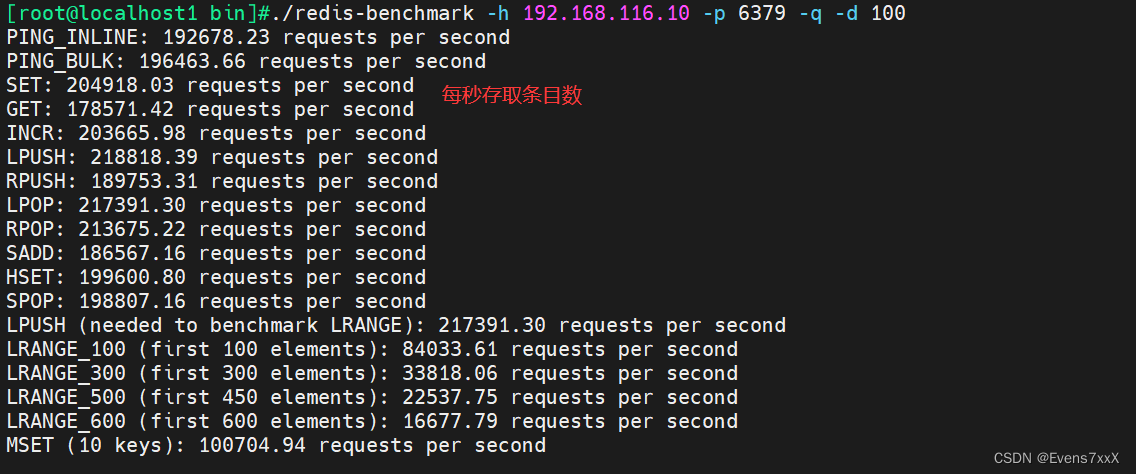
#测试本机上Redis服务在进行set与lpush操作时的性能
redis-benchmark -t set,lpush -n 100000 -q
3.redis命令的使用
(1)存入键值对
SET 键 值

(2)获取键的值
GET 键

(3)判断键的数据类型(redis默认数据类型为string)
TYPE 键

Redis中的五大数据类型
| 名称 | 类型 |
|---|---|
| String | 字符串 |
| List | 列表 |
| Hash | 散列 |
| Set | 无序集合 |
| Sorted Set | 有序集合 |
(4)查看键
KEYS * 查看所有键
KEYS 通配符 查看通配符匹配的指定键

(5)判断键是否存在
EXISTS 键

(6)删除键
DEL 键

(7)修改键名
RENAME 原键名 新键名
若要更改的新键名已存在,则会覆盖此键名的值(建议改名前先exists一下)或使用:
RENAMENX 原键名 新键名 //修改前判断新键名是否存在,存在则返回0,不存在则返回1并执行修改



(8)统计键数量
DBSIZE

(9)设置密码
CONFIG SET REQUIREPASS 密码
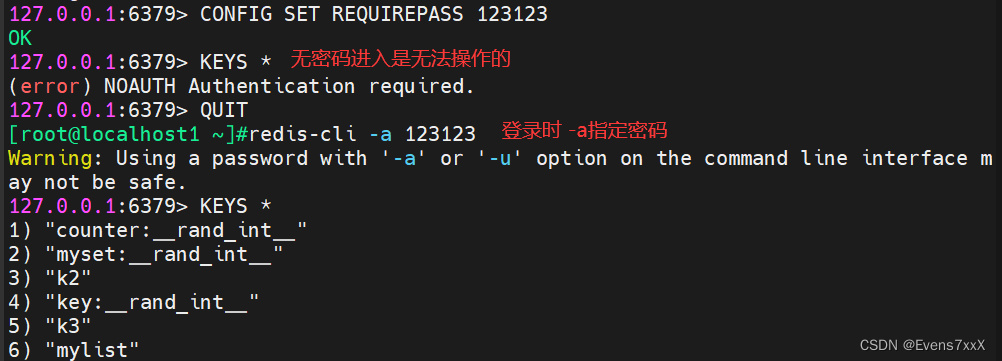
AUTH 密码 登入后做验证

(10)查看当前密码
CONFIG GET REQUIREPASS

(11)删除密码
CONFIG SET REQUIREPASS ''

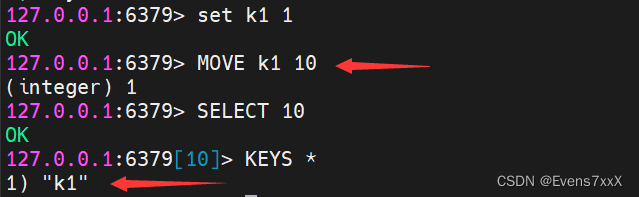
4.Redis多库常用命令
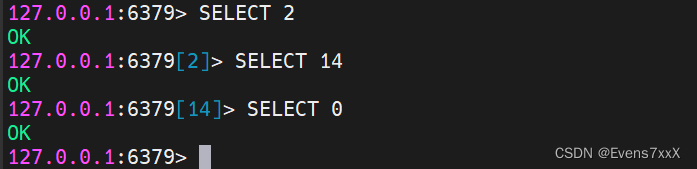
Redis 支持多数据库,Redis默认情况下包含16个数据库,数据库名称是用数字0-15来依次命名的(默认登入是0号数据库)。多数据库相互独立,互不干扰。
(1)切换数据库
SELECT 库号
(2) 将数据移动到指定库
MOVE 键 库号
五、Redis性能管理
1.查看内存使用
info memory
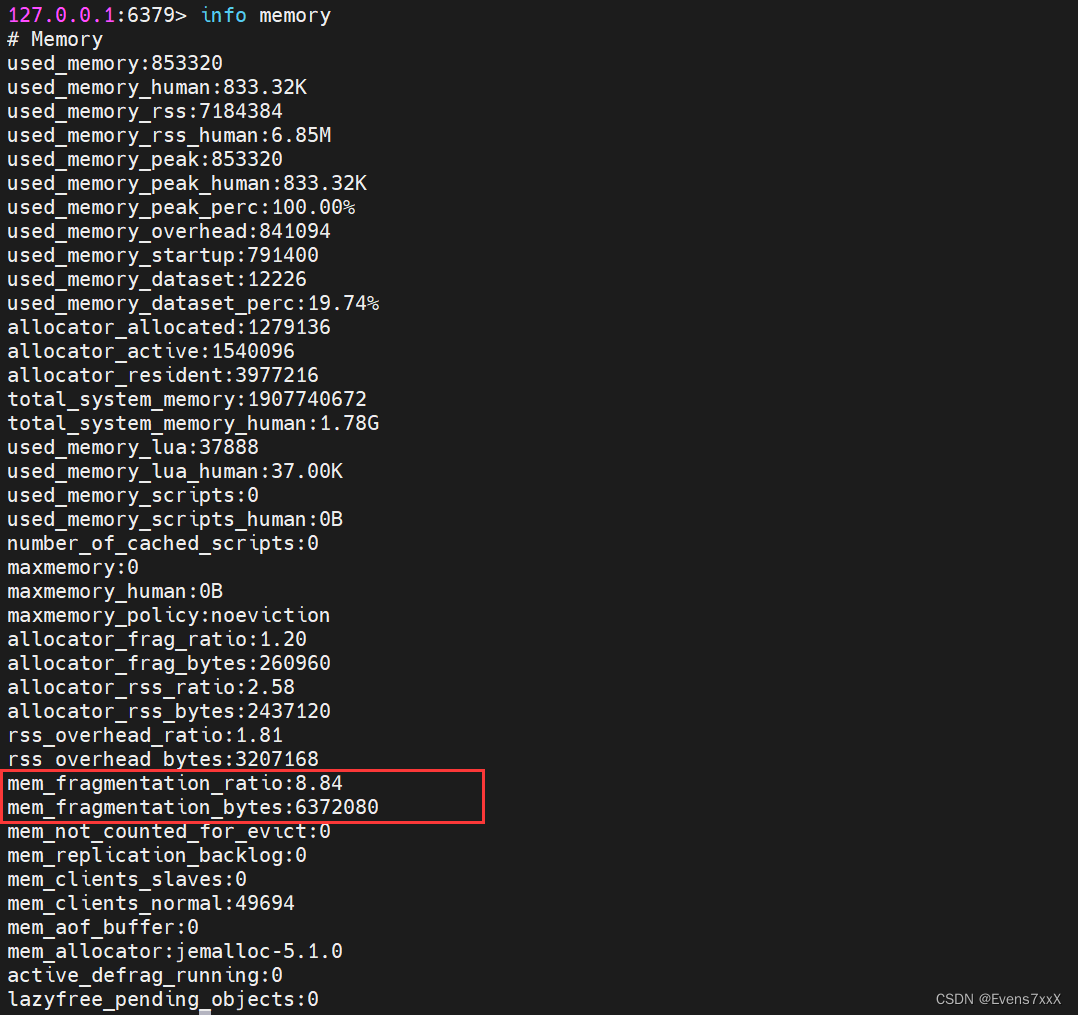
mem fragmentation _ratio #内存碎片率 = used memory_rss / used memoryused
memory _rss #是Redis向操作系统申请的内存。
used memory #是Redis中的数据占用的内存。
used memory peak # redis内存使用的峰值。
2.清理内存碎片
(1)内存碎片如何产生
Redis内部有自己的内存管理器,为了提高内存使用的效率,来对内存的申请和释放进行管理。
Redis中的值删除的时候,并没有把内存直接释放,交还给操作系统,而是交给了Redis内部有内存管理器。
Redis中申请内存的时候,也是先看自己的内存管理器中是否有足够的内存可用。
Redis的这种机制,提高了内存的使用率,但是会使Redis中有部分自己没在用,却不释放的内存,导致了内存碎片的发生。
(2)内存碎片率
跟踪内存碎片率对理解Redis实例的资源性能是非常重要的
- 内存碎片率在1到1.5之间是正常的,这个值表示内存碎片率比较低,也说明Redis没有发生内存交换。
- 内存碎片率超过1.5,说明Redis消耗了实际需要物理内存的150%,其中50%是内存碎片率。
- 内存碎片率低于1的,说明Redis内存分配超出了物理内存,操作系统正在进行内存交换。需要增加可用物理内存或减少Redis内存占用。
(3)清理内存碎片
Redis版本4.0以下
需要在 redis-cli工具上输入shutdown save 命令,让Redis数据库执行保存操作并关闭Redis服务,再重启服务器。Redis服务器重启后,Redis会将没用的内存归还给操作系统,碎片率会降下来。
Redis4.0版本以上
执行 config set activedefrag yes,开启自动碎片清理;
执行 memory purge,手动碎片清理。
3.内存使用率
redis实例的内存使用率超过可用最大内存,操作系统将开始进行内存与swap空间交换,导致性能大大降低。
避免内存交换发生的方法
- 针对缓存数据大小选择安装 Redis实例
- 尽可能的使用Hash数据结构存储
- 设置key的TTL生命周期(setex 键名 时间(s) 值)
4.内回收key
内存清理策略,保证合理分配redis有限的内存资源。默认情况下回收策略是禁止删除,当达到设置的最大阀值时,需选择一种key的回收策略。
配置文件中修改maxmemory-policy属性值
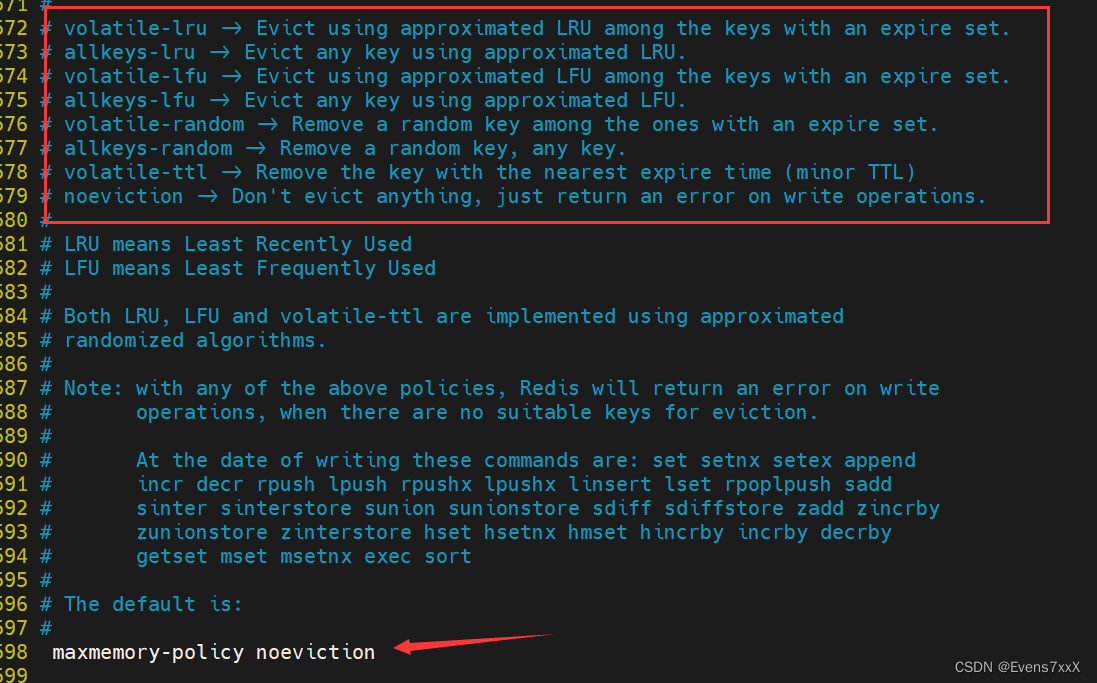
| volatile-lru | 使用LRU算法从已设置过期时间的数据集合中淘汰数据(移除最近最少使用的key,针对设置了TTL的key) |
| volatile-ttl | 从已设置过期时间的数据集合中挑选即将过期的数据淘汰(移除最近过期的key) |
| volatile-random | 从已设置过期时间的数据集合中随机挑选数据淘汰(在设置了TTL的key里随机移除) |
| allkeys-lru | 使用LRU算法从所有数据集合中淘汰数据(移除最少使用的key,针对所有的key) |
| allkeys-random | 从数据集合中任意选择数据淘汰(随机移除key) |
| noenviction | 禁止淘汰数据(不删除直到写满报错) |
相关文章:
Redis概述及安装、使用和管理
目录 一、NoSQL非关系型数据库 1.NoSQL概述 2.关系型数据库和非关系型数据库区别 (1)数据存储方式不同 (2)扩展方式不同 (3)对事务性的支持不同 3.非关系型数据库使用场景 二、Redis概述 1.简介 2…...

【算法第十一天7.25】二叉树前、中、后递归、非递归遍历
链接:力扣94-二叉树中序遍历 链接:力扣144-二叉树前序遍历 链接:力扣145-二叉树后序遍历 树的结构 * public class TreeNode {* int val;* TreeNode left;* TreeNode right;* TreeNode() {}* TreeNode(int val) { thi…...
Linux搭建Promtail + Loki + Grafana 轻量日志监控系统
一、简介 日志监控告警系统,较为主流的是ELK(Elasticsearch 、 Logstash和Kibana核心套件构成),虽然优点是功能丰富,允许复杂的操作。但是,这些方案往往规模复杂,资源占用高,操作苦…...

[PyTorch][chapter 44][RNN]
简介 循环神经网络(Recurrent Neural Network, RNN)是一类以序列(sequence)数据为输入,在序列的演进方向进行递归(recursion)且所有节点(循环单元)按链式连接的递归神经网…...

20230726----重返学习-vue3项目实战-知乎日报第3天-TS-简历
day-121-one-hundred-and-twenty-one-20230726-vue3项目实战-知乎日报第3天-TS-简历 vue3项目实战-知乎日报第3天 封装按钮组件 jsx函数式组件 只能做静态页面,内部没有方法让它自动更新。 封装第三方按钮-非计算属性版 封装第三方按钮-不使用计算属性 src/c…...

TypeScript 在前端开发中的应用实践
TypeScript 在前端开发中的应用实践 TypeScript 已经成为前端开发领域越来越多开发者的首选工具。它是一种静态类型的超集,由 Microsoft 推出,为开发者提供了强大的静态类型检查、面向对象编程和模块化开发的特性,解决了 JavaScript 的动态类…...

商业密码应用安全性评估量化评估规则2023版更新点
《商用密码应用安全性评估量化评估规则》(2023版)已于2023年7月发布,将在8月1日正式执行。相比较2021版,新版本有多处内容更新,具体包括5处微调和5处较大更新。 微调部分(5处) 序号2021版本202…...
【软件测试】单元测试工具---Junit详解
1.junit 1.1 junit是什么 JUnit是一个Java语言的单元测试框架。 虽然我们已经学习了selenium测试框架,但是有的时候测试用例很多,我们需要一个测试工具来管理这些测试用例,Junit就是一个很好的管理工具,简单来说Junit是一个针对…...

【算法基础:搜索与图论】3.4 求最短路算法(Dijkstrabellman-fordspfaFloyd)
文章目录 求最短路算法总览Dijkstra朴素 Dijkstra 算法(⭐原理讲解!⭐重要!)(用于稠密图)例题:849. Dijkstra求最短路 I代码1——使用邻接表代码2——使用邻接矩阵 补充:稠密图和稀疏…...
)
【Matlab】基于卷积神经网络的数据分类预测(Excel可直接替换数据)
【Matlab】基于卷积神经网络的数据分类预测(Excel可直接替换数据) 1.模型原理2.数学公式3.文件结构4.Excel数据5.分块代码6.完整代码7.运行结果1.模型原理 基于卷积神经网络(Convolutional Neural Network,CNN)的数据分类预测是一种常见的深度学习方法,广泛应用于图像识…...

【C++ 重要知识点总结】自定义类型-枚举和联合
复杂类型 除了类之外还有Union、Enum连个特殊的类型。 Union 概念 union即为联合,它是一种特殊的类。通过关键字union进行定义,一个union可以有多个数据成员。 union Token{char cval;int ival;double dval; };用法 互斥赋值。在任意时刻,…...

Centos MySql安装,手动安装保姆级教程
1.删除原有的mariadb,不然mysql装不进去 查询MAriaDB命令 rpm -qa|grep mariadb 删除 rpm -e --nodeps mariadb-libs-5.5.60-1.el7_5.x86_64 (yum -y remove mysql 如需要清除服务器上以前安装过的MySQL可执行此命令,执行前一…...
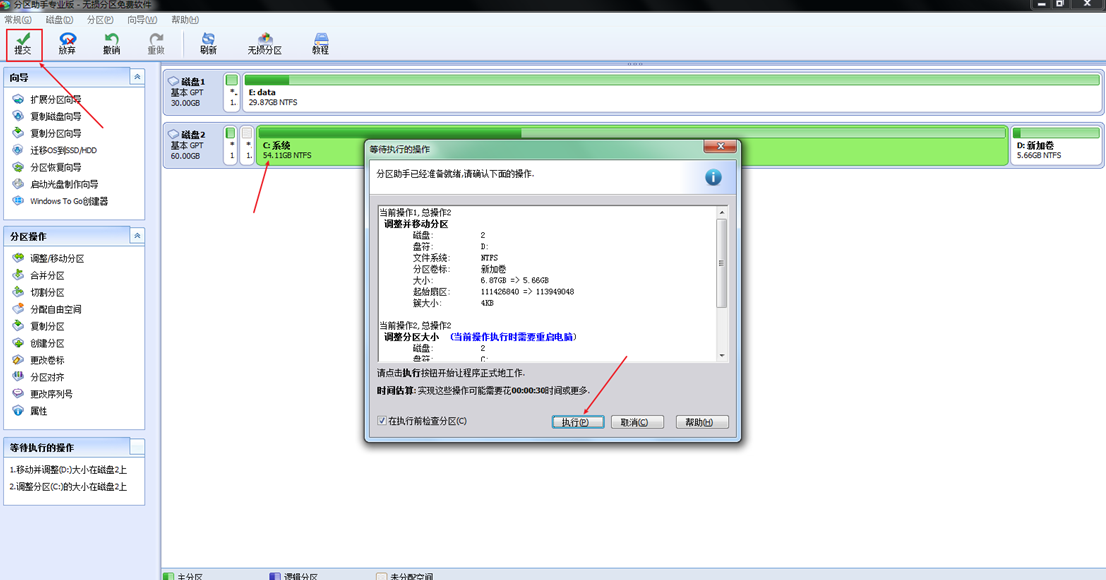
电脑C盘空间大小调整 --- 扩容(扩大/缩小)--磁盘分区大小调整/移动
概述: 此方法适合C盘右边没有可分配空间(空闲空间)的情况,D盘有数据不方便删除D盘分区的情况下,可以使用傲梅分区助手软件进行跨分区调整分区大小,不会损坏数据。反之可直接使用系统的磁盘管理工具进行调整…...

centos7设置网桥网卡
安装bridge-utils yum install bridge-utils修改ens33 网卡 TYPEEthernet BOOTPROTOnone DEFROUTEyes IPV4_FAILURE_FATALno IPV6INITyes IPV6_AUTOCONFyes IPV6_DEFROUTEyes IPV6_FAILURE_FATALno NAMEens33 UUID04b97484-25c8-45c7-8c8c-e335e8080e10 DEVICEens33 ONBOOTye…...

TCP模型和工作沟通方式
我们如何与客户沟通?理科生和技术人员可能在沟通技巧方面有所欠缺。 那么我们如何理解和掌握沟通的原则和技巧呢?我发现TCP网络交互模型很好的描述了沟通的原则和要点。下面我们就从TCP来讲沟通的过程。 TCP的客户端就像客户(甲方ÿ…...

Langchain 的 ConversationSummaryBufferMemory
Langchain 的 ConversationSummaryBufferMemory ConversationSummaryBufferMemory 在内存中保留最近交互的缓冲区,但不仅仅是完全刷新旧的交互,而是将它们编译成摘要并使用两者。但与之前的实现不同的是,它使用令牌长度而不是交互次数来确定何…...

【Rust 基础篇】Rust 通道实现单个消费者多个生产者模式
导言 在 Rust 中,我们可以使用通道(Channel)来实现单个消费者多个生产者模式,简称为 MPMC。MPMC 是一种常见的并发模式,适用于多个线程同时向一个通道发送数据,而另一个线程从通道中消费数据的场景。本篇博…...

HTTP协议各版本介绍
HTTP协议是一种用于传输Web页面和其他资源的协议。 下面详细介绍一下HTTP的各个版本: 1.HTTP/0.9 这是最早的HTTP版本,于1991年发布。它非常简单,只能传输HTML格式的文本,并且不支持其他类型的资源、请求头和状态码。 2.HTTP/1…...
玩转ChatGPT:Custom instructions (vol. 1)
一、写在前面 据说GPT-4又被削了,前几天让TA改代码,来来回回好几次才成功。 可以看到之前3小时25条的限制,现在改成了3小时50条,可不可以理解为:以前一个指令能完成的任务,现在得两条指令? 可…...

黄东旭:The Future of Database,掀开 TiDB Serverless 的引擎盖
在 PingCAP 用户峰会 2023 上, PingCAP 联合创始人兼 CTO 黄东旭 分享了“The Future of Database”为主题的演讲, 介绍了 TiDB Serverless 作为未来一代数据库的核心设计理念。黄东旭 通过分享个人经历和示例,强调了数据库的服务化而非服务化…...

uniapp实战:uview Collapse组件动态数据加载后高度异常的3种解决方案
Uniapp实战:uView Collapse组件动态数据加载后高度异常的深度解决方案 在Uniapp开发中,uView UI库的Collapse折叠面板组件因其简洁易用而广受欢迎。但当我们需要动态加载数据并展开面板时,经常会遇到一个棘手的问题:面板高度计算不…...

如何在浏览器中实现实时人物移除:TensorFlow.js完整指南
如何在浏览器中实现实时人物移除:TensorFlow.js完整指南 【免费下载链接】Real-Time-Person-Removal Removing people from complex backgrounds in real time using TensorFlow.js in the web browser 项目地址: https://gitcode.com/gh_mirrors/re/Real-Time-Pe…...

2025最权威的AI辅助写作平台推荐榜单
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 人工智能工具在学术写作范畴,已然成了提高效率的关键辅助,以下推举五…...

贪心算法解决区间问题:合并、选点、覆盖、最大不相交
一、前言 区间问题是贪心算法中的高频考点,而贪心算法是解决这类问题的 “黄金搭档”。本文将系统讲解基于贪心算法的四类经典区间问题:区间合并、区间选点、区间覆盖、最大不相交区间数量,帮助你彻底掌握这类问题的解题思路。 二、核心思想…...

内页SEO优化与网站整体优化的关系是什么_网站内页的图片优化需要注意哪些
内页SEO优化与网站整体优化的关系是什么 在当前竞争激烈的互联网环境中,网站的整体优化和内页SEO优化密不可分。内页SEO优化是提升网站整体排名的关键环节,而网站整体优化则为内页SEO提供了坚实的基础。这两者之间的关系可以从多个方面进行探讨…...

实战应用:用快马生成生产级服务器巡检与故障排查工具,告别xshell单点操作
最近在团队里负责服务器运维工作,经常需要处理各种突发故障。每次打开xshell手动敲命令排查问题,不仅效率低,还容易遗漏关键检查项。于是我用InsCode(快马)平台开发了一个自动化巡检工具,彻底告别了单点操作的时代。分享下这个实战…...

欧拉法数值求解
18650锂电池高温热失控「啪」的一声炸响,我的无人机突然从半空坠落。拆开焦黑的外壳,罪魁祸首是那颗鼓包的18650电池——它经历了教科书般的热失控。这种广泛应用于笔记本电脑、充电宝的圆柱形锂电池,在高温下就像被点燃引线的火药桶。当电池…...

SteamAutoCrack终极指南:三步实现Steam游戏离线自由运行
SteamAutoCrack终极指南:三步实现Steam游戏离线自由运行 【免费下载链接】Steam-auto-crack Steam Game Automatic Cracker 项目地址: https://gitcode.com/gh_mirrors/st/Steam-auto-crack 对于众多Steam游戏玩家来说,你是否曾遇到过这样的困境&…...

JavaScript中全局执行上下文与函数上下文的生成过程
全局执行上下文在JS引擎启动时创建,函数执行上下文在每次调用时创建;前者作用域链仅含全局环境,后者在创建阶段就基于定义位置固定作用域链;var和function声明被提升并初始化,let/const仅注册于词法环境而处于暂时性死…...

猫抓浏览器资源嗅探扩展:专业配置与高效下载指南
猫抓浏览器资源嗅探扩展:专业配置与高效下载指南 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 猫抓(cat-catch࿰…...