MySQL DQL语法
MySQL DQL语法
DQL语法简介
DQL(Data Query Language)语句是一种用于从数据库中检索数据的语言。它主要用于数据查询和数据分析,而不是对数据库中的数据进行更新、插入或删除。DQL语句通常用于获取特定条件下的数据,进行聚合计算、排序、过滤和连接等操作。
DQL语句的主要目的是从数据库中检索和查询数据,并根据特定的需求对数据进行分析和处理。通过灵活使用DQL语句,可以满足不同的数据查询和分析需求,从而提取有用的信息和洞察力。
DQL 基本查询语法
-
查询语句(SELECT):
-
查询语句(SELECT)用于从数据库表中检索所需的数据行。下面是查询语句的详细说明:
-
原型:SELECT 列1, 列2, … FROM 表名 WHERE 条件
-
参数:
- 列1, 列2, …:要查询的列名称,可选参数。如果不指定列,将返回表中所有列的数据。
- 表名:要查询数据的数据库表名称。
- 条件:指定要检索的数据行的条件,可选参数。只有满足条件的数据行才会被检索。
-
选项:
- 可以根据条件来检索满足条件的数据行。
- 如果不指定条件,则将检索表中的所有行。
- 可以使用关键字ORDER BY来指定查询结果的排序顺序。
- 可以使用关键字DISTINCT来排除重复的结果。
示例:
假设我们有一个存储学生信息的表名为"students",包含列名id、name和age。我们要检索年龄大于等于20的学生的姓名和年龄,并按照姓名进行升序排序。查询语句如下所示:SELECT name, age FROM students WHERE age >= 20 ORDER BY name;这个语句将从"students"表中检索年龄大于等于20的学生姓名和年龄,并按照姓名进行升序排序。
-
DQL 进阶语法
除了基本的SELECT语句,DML语句SELECT还提供了一些扩展功能和选项,用于更灵活和精确地检索所需的数据。下面是一些常用的扩展功能:-
条件筛选:
-
原型:SELECT 列1, 列2, … FROM 表名 WHERE 条件
-
参数:
- 列1, 列2, …:指定要选择的列名称或表达式,用于返回所需的数据。
- 表名:要查询数据的数据库表名称。
- 条件:指定要筛选的数据行的条件,根据条件判断返回行是否满足要求。条件可以使用比较操作符(如=、<、>、IN、BETWEEN等)和逻辑操作符(如AND、OR、NOT)进行组合。
-
选项:
- WHERE子句必须在FROM子句之后,在GROUP BY子句或ORDER BY子句之前。
- 可以使用多个条件组合使用,并用逻辑操作符连接条件,以构建更复杂的条件筛选。
示例:
- 等于(=)操作符:
SELECT * FROM table WHERE column = value;例如:
SELECT * FROM customers WHERE age = 25;
这个查询将返回customers表中年龄为25岁的所有顾客信息。- 小于(<)操作符:
SELECT * FROM table WHERE column < value;例如:
SELECT * FROM products WHERE price < 50;
这个查询将返回products表中价格低于50的所有产品信息。- 大于(>)操作符:
SELECT * FROM table WHERE column > value;例如:
SELECT * FROM orders WHERE total_amount > 1000;
这个查询将返回orders表中总金额超过1000的所有订单信息。- IN操作符:
SELECT * FROM table WHERE column IN (value1, value2, ...);例如:
SELECT * FROM customers WHERE id IN (1, 2, 3);
这个查询将返回customers表中ID为1、2、3的顾客信息。- BETWEEN操作符:
SELECT * FROM table WHERE column BETWEEN value1 AND value2;例如:
SELECT * FROM orders WHERE order_date BETWEEN '2021-01-01' AND '2021-01-31';
这个查询将返回orders表中订单日期在2021年1月1日到2021年1月31日期间的订单信息。- AND逻辑运算符:
SELECT * FROM table WHERE condition1 AND condition2;例如:
SELECT * FROM products WHERE price < 50 AND stock > 0;
这个查询将返回products表中价格低于50且库存大于0的产品信息。- OR逻辑运算符:
SELECT * FROM table WHERE condition1 OR condition2;例如:
SELECT * FROM customers WHERE age < 18 OR age > 65;
这个查询将返回customers表中年龄小于18岁或大于65岁的顾客信息。- NOT逻辑运算符:
SELECT * FROM table WHERE NOT condition;例如:
SELECT * FROM orders WHERE NOT status = 'Completed';
这个查询将返回orders表中状态不是"Completed"的所有订单信息。- 别名定义:
-
可以使用AS关键字为选择的列指定别名,以便在结果中显示具有更具描述性的列名。别名可以通过给列名或表达式使用AS关键字来定义,例如:SELECT 列名 AS 别名 FROM 表名。
-
-
排序:
-
排序是DML语句SELECT中一个常用的扩展功能,它允许我们按照特定的列或表达式对查询结果进行升序(ASC)或降序(DESC)排序。排序可以根据需要对数据进行正确的排列,以便更好地理解和分析结果。以下是排序的详细说明:
-
原型:SELECT 列1, 列2, … FROM 表名 ORDER BY 列1 [ASC|DESC], 列2 [ASC|DESC], …
-
参数:
- 列1, 列2, …:要排序的列名称或表达式,用于定义排序顺序。可以指定多个列,按照列的顺序进行排序。
- 表名:要查询数据的数据库表名称。
- ASC:指定升序排序方式(可选,默认排序方式)。
- DESC:指定降序排序方式(可选)。
-
选项:
- ORDER BY子句必须在SELECT语句中紧随FROM子句之后,在GROUP BY子句之前。
- 可以对一个或多个列进行排序,列名之间用逗号分隔。
- 可以使用ASC或DESC关键字指定排序方式,默认为升序排序。
示例:
假设我们有一个存储学生信息的表名为"students",该表包含列名name、age和grade。我们希望将学生信息按照年龄进行升序排序,并在年龄相同的情况下按照姓名进行升序排序。排序的查询语句如下所示:SELECT name, age, grade FROM students ORDER BY age ASC, name ASC;这个查询语句将从"students"表中选择学生姓名(name)、年龄(age)和年级(grade),并按照年龄(升序)和姓名(升序)的顺序进行排序。首先根据学生的年龄进行升序排序,年龄相同时再根据姓名进行升序排序。
-
-
-
分页查询:
-
分页查询是DML语句SELECT中常用的一种扩展功能,它允许我们在查询结果中限制返回的数据行数,以便在大型数据集中分页显示数据或限制结果集的大小。分页查询可以方便地浏览和展示大量数据
-
以下是分页查询在MySQL中的语法示例:
SELECT 列1, 列2, ... FROM 表名 LIMIT 起始行索引, 每页行数;- 参数:
- 列1, 列2, …:要选择的列名称或表达式,用于返回所需的数据。
- 表名:要查询数据的数据库表名称。
- 起始行索引:指定起始行的索引位置,通常表示为第一行为0或1,具体取决于数据库。
- 每页行数:指定每页返回的数据行数。
示例:
假设我们有一个存储学生信息的表名为"students",包含列名id、name和age。我们希望在每页显示10条数据,并获取第3页的数据。分页查询的查询语句如下所示:SELECT id, name, age FROM students LIMIT 20, 10;这个查询将从"students"表中选择学生的id、姓名和年龄,并限制返回从第21行开始的10行数据(即第3页的数据)。
- 参数:
-
-
聚合函数:
-
聚合函数(Aggregate functions)是DML语句SELECT中用于对结果集进行汇总、计算和统计的函数。通过使用聚合函数,我们可以对选定的列或表达式进行统计操作,例如计算总和、平均值、最大值、最小值等。以下是常用的聚合函数以及它们的功能:
- SUM:计算指定列的总和。
SELECT SUM(column) FROM table;例如:
SELECT SUM(sales) FROM orders;将计算"orders"表中sales列的总和。- COUNT:计算指定列中的行数(不包括NULL值)。
SELECT COUNT(column) FROM table;例如:
SELECT COUNT(*) FROM customers;将计算"customers"表中的总行数。- AVG:计算指定列的平均值。
SELECT AVG(column) FROM table;例如:
SELECT AVG(price) FROM products;将计算"products"表中price列的平均值。- MAX:返回指定列中的最大值。
SELECT MAX(column) FROM table;例如:
SELECT MAX(quantity) FROM inventory;将返回"inventory"表中quantity列的最大值。- MIN:返回指定列中的最小值。
SELECT MIN(column) FROM table;例如:
SELECT MIN(age) FROM employees;将返回"employees"表中age列的最小值。
-
-
分组合计:
-
分组合计是DML语句SELECT中常用的一种扩展功能,它允许我们根据指定的列或表达式进行分组,并对每个分组应用聚合函数,计算每个分组的统计值。通过分组合计,我们可以在查询结果中获取按照特定分类进行汇总的数据。以下是分组合计的详细说明:
-
原型:SELECT 列1, 列2, …, 聚合函数(column) FROM 表名 GROUP BY 列1, 列2, …
-
参数:
- 列1, 列2, …:用于选择的列名称或表达式。
- 聚合函数(column):要应用的聚合函数,可以是SUM、COUNT、AVG、MAX、MIN等。
- 表名:要查询数据的数据库表名称。
- GROUP BY 列1, 列2, …:根据指定列或表达式进行分组,以计算每个分组的聚合计算结果。
-
选项:
- GROUP BY子句必须在SELECT语句中紧随FROM子句之后,并在WHERE子句之前。
- 可以根据需要指定多个列或表达式作为分组标准,多个分组标准之间用逗号分隔。
- 分组的结果集中,每个组将包含具有相同分组值的行。
示例:
假设我们有一个存储销售订单的表名为"orders",该表包含列名order_id、customer_id和order_total。我们希望按照customer_id对订单进行分组,并计算每个客户的订单总额。分组合计的查询语句如下所示:SELECT customer_id, SUM(order_total) AS total_amount FROM orders GROUP BY customer_id;这个查询语句将从"orders"表中选择customer_id,并使用SUM函数计算每个客户的订单总额。使用GROUP BY子句将订单表根据customer_id进行分组,以便对每个分组应用聚合计算。
-
-
-
连接查询:
-
连接查询(Join)是DML语句SELECT中的一种常用操作,用于将多个表关联起来,根据共享的列值从多个表中获取数据。连接查询可以从多个表中检索相关数据,以便获取更丰富和全面的查询结果。以下是连接查询的详细说明:
-
原型:SELECT 列1, 列2, … FROM 表1 JOIN 表2 ON 表1.列 = 表2.列 WHERE 条件
-
参数:
- 列1, 列2, …:要选择的列名称或表达式,用于返回所需的数据。
- 表1, 表2:要连接的数据库表名称。
- ON 表1.列 = 表2.列:指定连接条件,即指定表1和表2之间的关联列。
- WHERE 条件:可选,用于进一步筛选满足特定条件的数据行。
-
选项:
- 连接查询可以使用不同的连接类型,如内连接(INNER JOIN)、左连接(LEFT JOIN)、右连接(RIGHT JOIN)等,根据需求选择适当的连接类型。
- 连接条件是指定连接的关键,连接条件使用ON子句指定,通常是通过表1和表2之间的列之间的相等关系来建立连接。
示例:
假设我们有两个存储订单信息和客户信息的表:"orders"表包含列order_id、customer_id和order_total,"customers"表包含列customer_id和customer_name。我们要查询订单信息以及每个订单对应的客户名称,查询语句如下所示:SELECT orders.order_id, orders.order_total, customers.customer_name FROM orders JOIN customers ON orders.customer_id = customers.customer_id;这个查询语句使用了内连接(INNER JOIN),将"orders"表和"customers"表根据customer_id列进行关联。通过指定ON子句中的连接条件,共享相同customer_id值的订单和客户记录被关联起来。这样,查询结果将包含订单信息(order_id, order_total)以及对应的客户名称(customer_name)。
-
-
-
DQL 语法编写顺序
在编写DQL(Data Query Language)语句时,通常会按照以下顺序编写语法:
-
SELECT子句:指定要从数据库中检索的列。
-
FROM子句:指定数据查询的源表或视图。
-
WHERE子句:可选,用于筛选特定条件的数据。
-
GROUP BY子句:可选,用于按指定的列进行分组。
-
HAVING子句:可选,用于对分组后的结果进行条件过滤。
-
ORDER BY子句:可选,用于按指定的列对结果进行排序。
-
LIMIT子句:在所有其他子句之后,用于限制查询结果的数量。
编写DQL语句时,可以根据具体需求决定是否编写WHERE子句、GROUP BY子句、HAVING子句和ORDER BY子句。这些子句的顺序可以根据查询的逻辑关系进行调整。最后的查询结果将根据编写的DQL语句进行返回。
DQL 语法执行顺序
DQL(数据查询语言)语句的执行顺序是按照以下顺序进行的:
-
FROM子句:首先,数据库管理系统(DBMS)会检索FROM子句指定的数据表或视图。
-
WHERE子句:接下来,DBMS会对FROM子句返回的数据进行筛选,根据WHERE子句中定义的条件过滤出满足条件的行。
-
GROUP BY子句:如果存在GROUP BY子句,DBMS会将筛选后的数据按照GROUP BY子句中指定的列进行分组。
-
HAVING子句:如果存在HAVING子句,DBMS会在分组后的数据上根据HAVING子句中定义的条件进行进一步筛选。
-
SELECT子句:DBMS会根据SELECT子句中指定的列,从筛选和分组后的数据中提取需要的列数据。
-
ORDER BY子句:如果存在ORDER BY子句,DBMS会按照ORDER BY子句指定的列对结果进行排序。
-
LIMIT子句:最后,如果存在LIMIT子句,DBMS会根据LIMIT子句指定的数量限制结果集的返回数量。
需要注意的是,虽然以上是DQL语句的一般执行顺序,但实际的执行顺序可能会根据DBMS优化执行计划和查询处理方式而有所不同。DBMS会尽可能优化查询,例如使用索引、内部排序等来提高查询性能。因此,在实际执行中可能会调整执行顺序以提高效率。
总结
DQL是用于查询和检索数据库数据的重要工具。它具有丰富的功能和灵活性,可以根据不同的查询需求进行条件过滤、排序、聚合计算等操作。通过合理使用DQL,可以从数据库中提取有用的数据以进行数据分析和决策支持。
相关文章:

MySQL DQL语法
MySQL DQL语法 DQL语法简介 DQL(Data Query Language)语句是一种用于从数据库中检索数据的语言。它主要用于数据查询和数据分析,而不是对数据库中的数据进行更新、插入或删除。DQL语句通常用于获取特定条件下的数据,进行聚合计算…...
带头结点链表的反向输出)
算法之线性表1.1.1(7)带头结点链表的反向输出
设L为带头结点的单链表,编写算法实现从尾到头反向输出每个节点的值。 算法思想: 方法一:将链表压栈再输出,时间复杂度为O(n),空间复杂度为O(n) 方法二:用头插法重新建立单链表在输出,时间复杂度为O(n),空…...
)
设计模式三:抽象工厂模式(Abstract Factory Pattern)
抽象工厂模式(Abstract Factory Pattern)是一种创建型设计模式,它提供了一种方式来创建一系列相关或相互依赖的对象,而无需指定具体实现类。 在软件开发中,有时候需要根据不同的条件或环境来创建一组相关的对象。抽象工…...
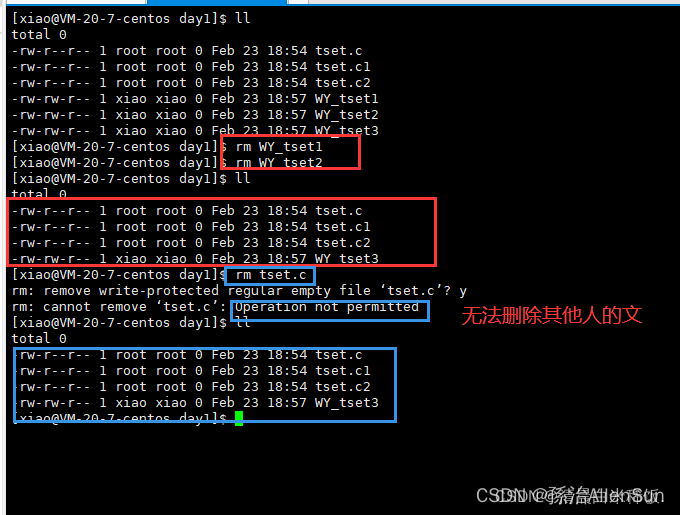
Linux用户权限问题详解
Linux用户权限问题详解 【一】Linux权限的概念(1)用户类型(2)如何切换用户(3)用户相关的一些命令 【二】Linux文件权限管理(1)文件访问者的分类(2)文件类型和…...

flask中的session介绍
flask中的session介绍 在Flask中,session是一个用于存储特定用户会话数据的字典对象。它在不同请求之间保存数据。它通过在客户端设置一个签名的cookie,将所有的会话数据存储在客户端。以下是如何在Flask应用中使用session的基本步骤: 首先…...
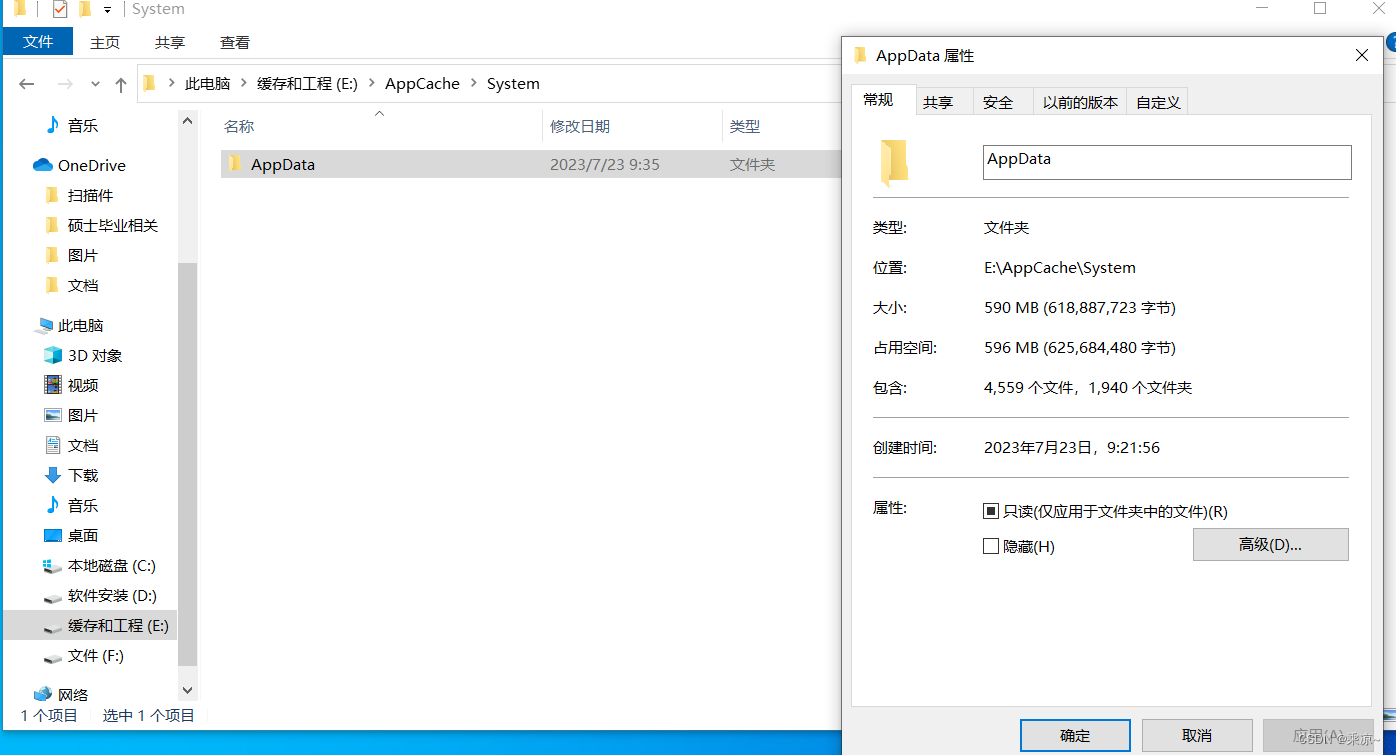
记录联想拯救者R720重装系统
文章目录 bios里找不到U盘启动项2023.7.23重装系统后数据记录C盘内存修改默认AppData的路径(亲测,没用) bios里找不到U盘启动项 制作好启动盘后,开机按F2进入bios后,找不到U盘启动项,如下图所示࿱…...
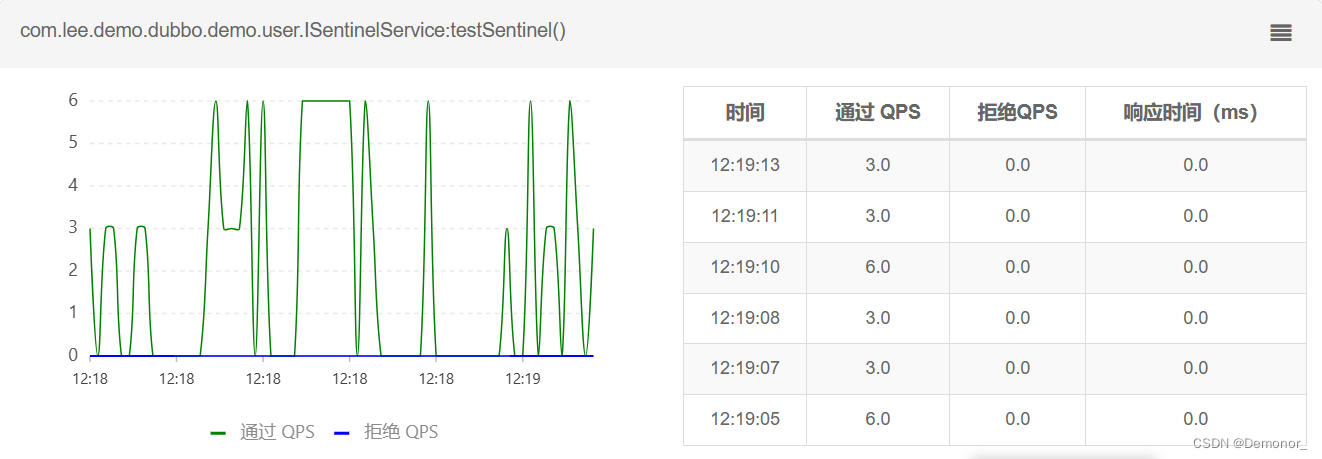
Spring Alibaba Sentinel实现集群限流demo
1.背景 1.什么是单机限流? 小伙伴们或许遇到过下图这样的限流配置 又或者是这样的Nacos动态配置限流规则: 以上这些是什么限流?没错,就是单机限流,那么单机限流有什么弊端呢? 假设我们集群部署3台机器&a…...

102、SOA、分布式、微服务之间有什么关系和区别?
SOA、分布式、微服务之间有什么关系和区别? 分布式架构是指将单体架构中的各个部分拆分,然后部署到不同的机器或进程中去,SOA和微服务基本上都是分布式架构师SOA是一种面向服务的架构,系统的所有服务都注册在总线上,当调用服务时…...

Ubuntu 20.04下的录屏与视频剪辑软件
ubuntu20.04下的录屏与视频剪辑 一、录屏软件SimpleScreenRecorder安装与使用 1、安装 2、设置录制窗口参数 3、开始录制 二、视频剪辑软件kdenlive的安装 1、安装 2、启动 一、录屏软件SimpleScreenRecorder安装与使用 1、安装 (1)直接在终端输入以下命…...

面试题 -- iOS数据存储
文章目录 一、如果后期需要增加数据库中的字段怎么实现,如果不使用CoreData呢?二、SQLite 数据存储是怎么用?三、简单描述下客户端的缓存机制?四、实现过多线程的Core Data 么?NSPersistentStoreCoordinator࿰…...
environment、systemProperties、systemEnvironment三个bean是在哪里被添加到容器的?)
spring复习:(51)environment、systemProperties、systemEnvironment三个bean是在哪里被添加到容器的?
一、主类: package cn.edu.tju.study.service.anno;import cn.edu.tju.study.service.anno.config.MyConfig; import cn.edu.tju.study.service.anno.domain.Person; import com.sun.javafx.runtime.SystemProperties; import org.springframework.context.annotat…...
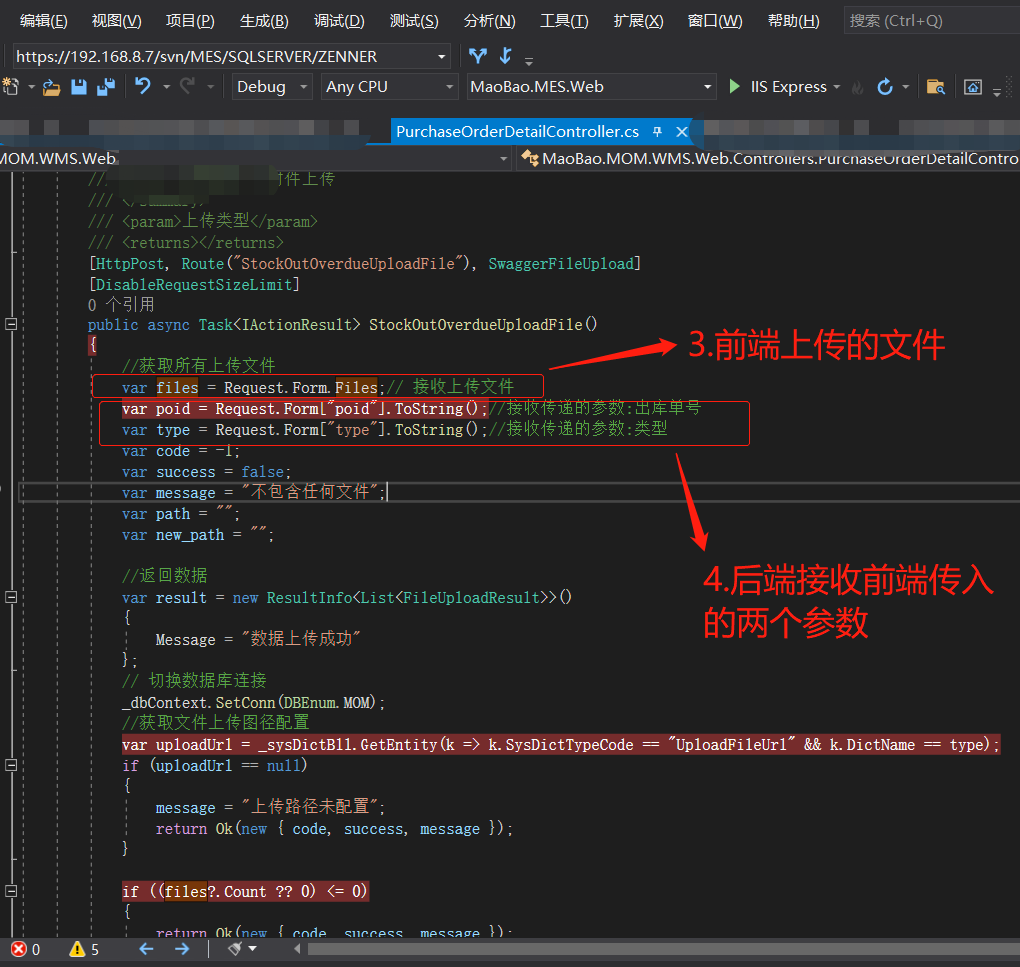
element ui 上传控件携带参数到后端
1.携带固定参数: 2.携带不固定参数: <el-row> <el-col :span"24"> <el-upload :multiple"false" :show-file-list"false" :on-success"f_h…...

scrapy分布式+指纹去重原理
1,指纹去重原理存在于 scrapy.util.requests 里面 需要安装的包 pip install scrapy-redis-cluster # 安装模块 pip install scrapy-redis-cluster0.4 # 安装模块时指定版本 pip install --upgrade scrapy-redis-cluster # 升级模块版本 2,setting配置 …...
FileHub使用教程:Github Token获取步骤,使用快人一步
FileHub介绍 filehub是我开发的一个免费文件存储软件,可存万物。软件仓库:GitHub - Sjj1024/s-hub: 一个使用github作为资源存储的软件 软件下载地址:。有问题可以留言或者提Issue, 使用第一步:获取Github Token 使…...
嵌入式开发:单片机嵌入式Linux学习路径
SOC(System on a Chip)的本质区别在于架构和功能。低端SOC如基于Cortex-M架构的芯片,如STM32和NXP LPC1xxx系列,不具备MMU(Memory Management Unit),适用于轻量级实时操作系统如uCOS和FreeRTOS。…...

Libvirt的virsh工具常用命令
在使用Libvirt的virsh工具时,以下是常见的一些命令: 连接到Hypervisor: virsh -c <URI>:连接到指定的Hypervisor,例如 virsh -c qemu:///system 连接到本地的QEMU/KVM Hypervisor。 虚拟机管理: list…...

高斯消元解异或方程组写法
高斯约旦消元解异或方程组 for(int j1;j<n;j){for(int ij1;i<n;i)if(a[i][j]){swap(a[i],a[j]);break;}if(!a[i][i]){if(a[i][n1])//no...else ...//mul}for(int i1;i<n;i)if(i!j&&a[i][j])for(int kj;k<n1;k)a[i][k]^a[j][k];}正常高斯消元法 int r1;for…...
前端 mock 数据的几种方式
目录 接口demo Better-mock just mock koa webpack Charles 总结 具体需求开发前,后端往往只提供接口文档,对于前端,最简单的方式就是把想要的数据写死在代码里进行开发,但这样的坏处就是和后端联调前还需要再把写死的数据…...

【GO】go语言入门实战 —— 猜数字游戏
文章目录 程序介绍设置随机数读取用户输入实现判断逻辑实现游戏循环完整代码 程序介绍 首先生成一个介于1~100之间的随机数,然后提示玩家输入数字,并告诉玩家是猜对了还是猜错了,如果对了程序就结束,如果错了就提醒玩家是大了还是…...
opencv-25 图像几何变换04- 透视 cv2.warpPerspective()
什么是透视? 透视是一种几何学概念,用于描述在三维空间中观察物体时,由于视角的不同而产生的变形效果。在现实世界中,当我们从不同的角度或位置观察物体时,它们会呈现出不同的形状和大小。这种现象被称为透视效果。 透…...

告别纯手工!用X-AnyLabeling的SAM2模型,5分钟搞定复杂目标分割标注
5分钟解锁X-AnyLabeling的SAM2黑科技:复杂目标分割标注效率提升指南 当面对医学影像中不规则肿瘤轮廓、遥感图像中的破碎地块边界,或是工业质检场景下的缺陷区域时,传统矩形框标注就像用粉笔画框测量云朵形状——既笨拙又低效。X-AnyLabelin…...
第二章——变量的三种定义方式2和3)
Java程序设计(第3版)第二章——变量的三种定义方式2和3
变量的第二种使用方式 在声明的同时并赋值 数据类型 变量名 = 数据; int b = 12; System.out.println(b); 输出为12变量的第三种使用方式 同时定义多个同类型变量 int c,d=1,e=11,f=23,g=32,h=0…...

联邦蒸馏技术解析:从知识共享到隐私保护的实践路径
1. 联邦蒸馏技术:当知识共享遇上隐私保护 第一次听说"联邦蒸馏"这个词时,我正和团队在做一个医疗AI项目。医院的数据就像被锁在保险箱里的珍宝,谁都想要,但谁都拿不到。传统联邦学习虽然解决了数据不出本地的问题&#…...

SEO 究竟是什么_外链对SEO重要吗_如何建设外链
SEO 究竟是什么_外链对SEO重要吗?如何建设外链 在当今互联网时代,网站的流量和排名直接关系到企业的收入和市场竞争力。而搜索引擎优化(SEO)作为网站运营的核心技术之一,无疑是每一个网站经营者都不能忽视的重要环节。本文将深入…...

人到中年,生日收到这三条短信,我读了很久
手机屏幕亮了一下。 我拿起来,以为是工作消息,结果是中国工商银行的短信: 紧接着,第二条进来了——中国联通: 第三条,是母校辽工大发来的: 我看着这三条短信,愣了很久。 没有酒局的邀…...
与权威模板分析)
智能工具助力论文答辩:精选10款AI应用(含爱毕业aibiye)与权威模板分析
工具对比速览表 工具名称 核心功能 适用场景 特色优势 Aibiye 智能成文、文献查找、数据分析 社科/金融/理工类论文 融合多模型架构,精准把握高校规范 Aicheck 初稿生成、大纲定制、图表插入 快速完成初稿需求 全学科覆盖,20-30分钟极速生成 …...
)
【2026年最新600套毕设项目分享】springboot仁和机构的体检预约系统(14336)
有需要的同学,源代码和配套文档领取,加文章最下方的名片哦 一、项目演示 项目演示视频 二、资料介绍 完整源代码(前后端源代码SQL脚本)配套文档(LWPPT开题报告/任务书)远程调试控屏包运行一键启动项目&…...

知网维普都要过,AI率85%用哪款工具最合适
越来越多高校开始同时要求知网和维普检测,这让选工具变得更复杂了——不是只要过一个平台,而是要同时达标。 AI率85%,知网和维普都要过20%以下,这种情况用哪款工具最合适? 知网和维普的算法差异 先说一个背景知识&a…...

C#并行编程进阶:除了Task和Parallel,你还需要学会用PerformanceCounter做资源熔断
C#并行编程中的资源熔断机制:用PerformanceCounter构建自适应系统 当你在深夜部署一个高负载数据处理服务时,最可怕的不是代码报错——而是系统在默默崩溃。我曾经历过这样的时刻:一个看似完美的并行处理管道,在凌晨三点突然吞噬了…...

AI逆向实战:构建MCP工具链赋能Cursor自动化App动态分析
1. 为什么需要AI辅助App逆向分析 逆向工程一直是安全研究和移动应用开发中的重要环节。传统的逆向流程通常需要手动操作adb命令、反编译工具、抓包软件等,不仅效率低下,而且对操作者的技术要求极高。我曾在一次商业App的安全评估中,花了整整三…...