详解Mybatis之自动映射 自定义映射问题
编译软件:IntelliJ IDEA 2019.2.4 x64
操作系统:win10 x64 位 家庭版
Maven版本:apache-maven-3.6.3
Mybatis版本:3.5.6
文章目录
- 一、Mybatis中的自动映射是什么?
- 二、Mybatis中的自定义映射是什么?
- 三、为什么要使用自定义映射[resultMap]?
- 四、自定义映射[resultMap]可以适用哪些场景?
- 4.1 resultMap之级联映射
- 4.1.1 级联映射之association映射[1:1]
- 4.1.2 级联映射之collection映射[1:m]
- 4.2 总结ResultMap中的相关标签及属性
- 4.3 分步查询
- 4.3.1 一对一的关联关系
- 4.3.2 一对多的关联关系
- 4.3.3 扩展
- 五、Mybatis如何使用延迟加载【懒加载】?

一、Mybatis中的自动映射是什么?
Mybatis中的自动映射不是什么高大上的技术名词,而是我们使用Mybatis框架进行持久化层开发时常用select元素中的常见属性resultType,它可以自动将数据库内表中的字段与类中的属性进行关联映射,故而得名。
二、Mybatis中的自定义映射是什么?
👉定义
自定义映射,简而言之,就是resultMap。Mybatis官方将resultMap称为结果映射,在为一些比如连接的复杂语句编写映射代码的时候,一份 resultMap 能够代替实现同等功能的数千行代码。
👉设计思想
对简单的语句做到零配置,对于复杂一点的语句,只需要描述语句之间的关系就行了。
三、为什么要使用自定义映射[resultMap]?
💡原因
它可以解决自动映射[resultType]解决不了的两类问题
❓ 哪两类问题?
-
🍓多表连接查询时,需要返回多张表的结果集
不信?请看如下测试案例
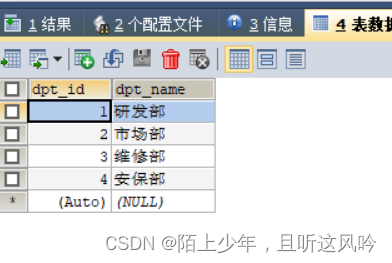
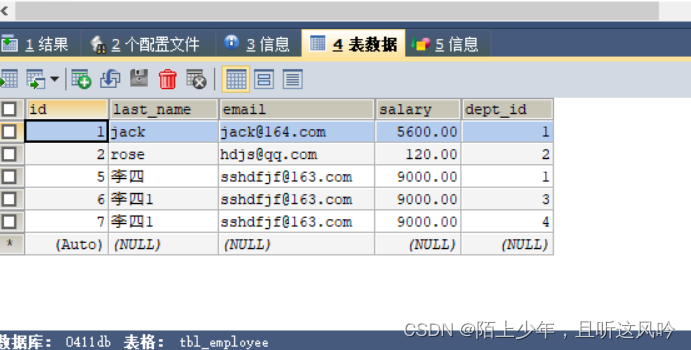
测试案例:通过员工id获取员工信息及员工所属的部门信息
①准备数据
②在Mapper接口书写相应的方法
代码示例如下:
//通过员工id获取员工信息及员工所属的部门信息 public List<Employee> showempByempId(int empId);③在接口对应的映射文件中书写相应的sql
代码示例如下:
<select id="showempByempId" resultType="employee">SELECTe.`id`,e.`last_name`,e.`email`,e.`salary`,d.`dpt_id`,d.`dpt_name`FROM`tbl_employee` e, `tbl_department` dWHEREe.`dept_id`=d.`dpt_id`ANDe.`id`=1; </select>③测试
@Test public void test01(){try {String resource = "mybatis-config.xml";InputStream inputStream = Resources.getResourceAsStream(resource);SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);//通过SqlSessionFactory对象调用openSession();SqlSession sqlSession = sqlSessionFactory.openSession();//获取EmployeeMapper的代理对象EmployeeMapper employeeMapper = sqlSession.getMapper(EmployeeMapper.class);List<Employee> employees = employeeMapper.showempByempId(1);System.out.println(employees);} catch (IOException e) {e.printStackTrace();}}
🙋 为什么员工所属的部门信息查不出来?
🙇 原因
书写的sql涉及到多表查询,映射文件中相应select子标签的属性为resultType。该属性不支持映射多表查询后的结果集,需要用到自定义映射来解决该问题
-
🍓单表查询时,不支持驼峰式自动映射【如果不想为字段定义别名】
自定义映射【resultMap】:自动映射解决不了的问题,可以交给自定义映射
👇 注意
resultType与resultMap只能同时使用一个
四、自定义映射[resultMap]可以适用哪些场景?
4.1 resultMap之级联映射
🙋 何为级联映射?
👇 答曰
级联映射是指在保存主对象时,将关联的对象也一起保存到数据库中。例如,对于一对多或者多对一、多对多等关系对象时,当保存某个一对象时,与这个依赖的对象都应该自动保存或更新。比如:部门和员工表,一对多关系,当保存部门数据时,和部门有关联的员工表也同时保存。
用法案例
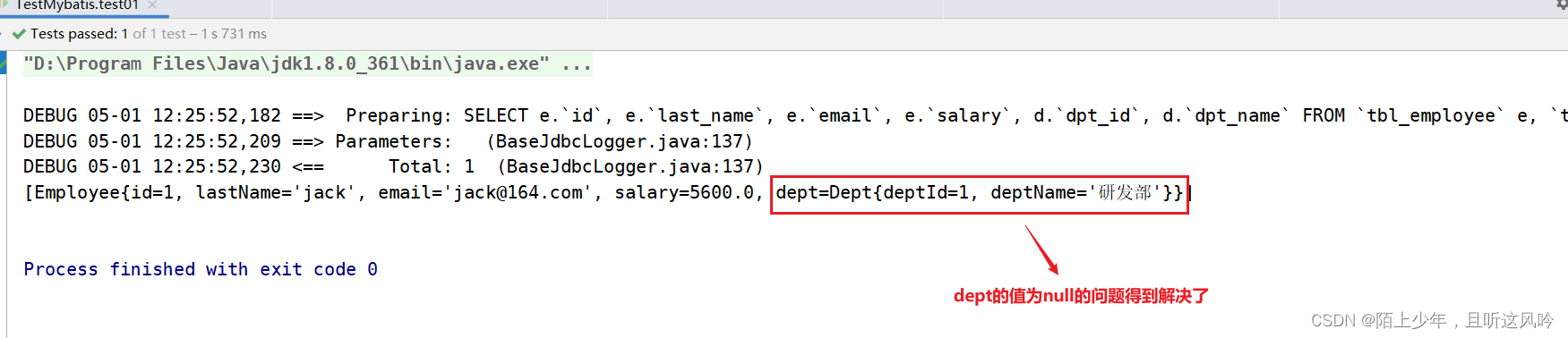
基于第三节中的案例,在映射文件中使用resultMap来解决多表查询后结果集中dept值为null的问题
代码示例如下:
①在在映射文件中使用自定义映射
<resultMap id="empAnddeptResultMap" type="employee"><!-- column:返回的结果集中的字段 property:返回值类型(employee)中的属性,要映射的类 --><!-- id属性是定义主键字段与属性之间的关联关系 --><id column="id" property="id"></id><!-- result属性是定义非主键字段与属性之间的关联关系 --><result column="last_name" property="lastName"></result><result column="email" property="email"></result><result column="salary" property="salary"></result><result column="dpt_id" property="dept.deptId"></result><result column="dpt_name" property="dept.deptName"></result>
</resultMap><select id="showempByempId" resultMap="empAnddeptResultMap">SELECTe.`id`,e.`last_name`,e.`email`,e.`salary`,d.`dpt_id`,d.`dpt_name`FROM`tbl_employee` e, `tbl_department` dWHEREe.`dept_id`=d.`dpt_id`ANDe.`id`=1;
</select>
②测试运行
4.1.1 级联映射之association映射[1:1]
👉特点
解决一对一的关联关系
👉用法案例
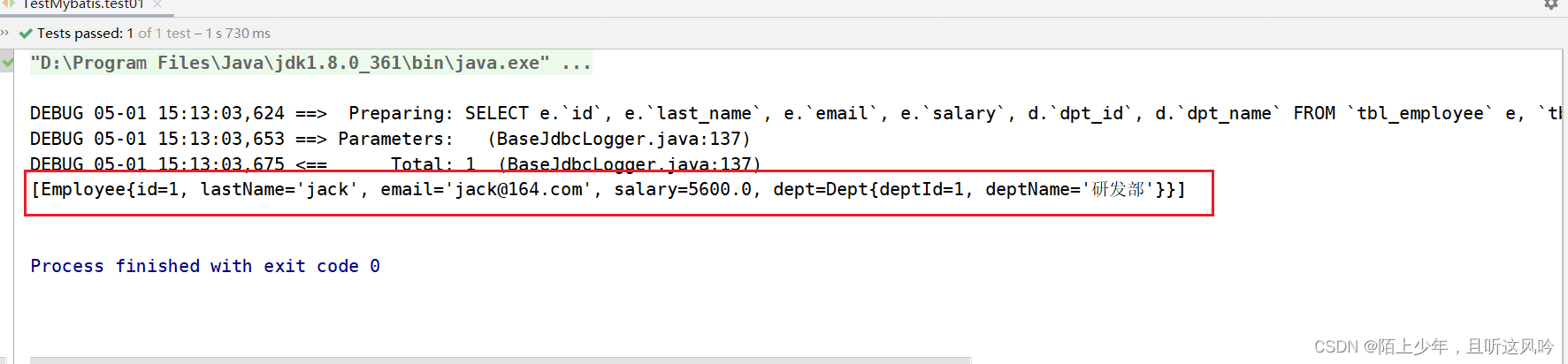
基于4.1小结中的案例,对映射文件中的sql部分进行association映射的改写,观察效果
代码示例如下:
①对映射文件中的sql部分进行association映射的改写
<resultMap id="empAnddeptResultMap" type="employee"><!-- column:返回的结果集中的字段 property:返回值类型(employee)中的属性,要映射的类 --><!-- id属性是定义主键字段与属性之间的关联关系 --><id column="id" property="id"></id><!-- result属性是定义非主键字段与属性之间的关联关系 --><result column="last_name" property="lastName"></result><result column="email" property="email"></result><result column="salary" property="salary"></result><!-- javaType: 用来指定某个属性(dept)或字段在 Java 代码中所对应的具体数据类型 (mybatis.pojo.Dept) --><!-- dept属性指的是employee对象中的属性 --><association property="dept" javaType="mybatis.pojo.Dept"><id column="dpt_id" property="deptId"></id><result column="dpt_name" property="deptName"></result></association></resultMap><select id="showempByempId" resultMap="empAnddeptResultMap">SELECTe.`id`,e.`last_name`,e.`email`,e.`salary`,d.`dpt_id`,d.`dpt_name`FROM`tbl_employee` e, `tbl_department` dWHEREe.`dept_id`=d.`dpt_id`ANDe.`id`=1;
</select>
②测试运行
4.1.2 级联映射之collection映射[1:m]
👉特点
解决一对多的关联关系
👉用法案例
根据部门编号查询对应的部门信息,然后拿着部门编号去员工表里去找所属的员工信息(此时部门与员工是一对多的关系)
代码示例如下:
准备数据
①在DeptMapper接口书写相应的方法
//根据部门编号查询对应的部门信息,然后拿着部门编号去员工表里去找所属的员工信息(一对多)
public Dept showEmployeesByDeptId(int deptId);
②在在DeptMapper接口对应的映射文件中书写相应的sql
<!-- collection property="employees" ofType="mybatis.pojo.Employee" -> 在Dept类中名为employees的集合中存储的元素类型 --><resultMap id="showEmployeesByDeptIdResultMap" type="dept"><id property="deptId" column="dpt_id"></id><result property="deptName" column="dpt_name"></result><collection property="employees" ofType="mybatis.pojo.Employee"><!-- id属性是定义主键字段与属性之间的关联关系 --><id column="id" property="id"></id><!-- result属性是定义非主键字段与属性之间的关联关系 --><result column="last_name" property="lastName"></result><result column="email" property="email"></result><result column="salary" property="salary"></result></collection></resultMap><select id="showEmployeesByDeptId" resultMap="showEmployeesByDeptIdResultMap">SELECTe.`id`,e.`last_name`,e.`email`,e.`salary`,d.`dpt_id`,d.`dpt_name`FROM`tbl_employee` e, `tbl_department` dWHEREe.`dept_id`=d.`dpt_id`ANDd.`dpt_id`=#{dptId};</select>
③测试
@Test
public void test04(){try {String resource = "mybatis-config.xml";InputStream inputStream = Resources.getResourceAsStream(resource);SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);//通过SqlSessionFactory对象调用openSession();SqlSession sqlSession = sqlSessionFactory.openSession();//获取EmployeeMapper的代理对象DeptMapper deptMapper = sqlSession.getMapper(DeptMapper.class);//查询部门编号为1的部门信息,并得到所属员工的所有员工信息Dept dept = deptMapper.showEmployeesByDeptId(1);System.out.println(dept);} catch (IOException e) {e.printStackTrace();}}

4.2 总结ResultMap中的相关标签及属性
-
resultMap标签:自定义映射标签id属性:定义唯一标识type属性:设置映射类型
-
resultMap子标签-
id标签:定义主键字段与属性关联关系 -
result标签:定义非主键字段与属性关联关系column属性:定义表中字段名称property属性:定义类中属性名称
-
associationi标签:定义一对一的关联关系property属性:定义关联关系属性javaType属性:定义关联关系属性的类型select属性:设置分步查询SQL全路径colunm属性:设置分步查询SQL中需要参数fetchType:设置局部延迟加载【懒加载】
-
collection标签:定义一对多的关联关系property属性:定义关联关系属性ofType属性:定义关联关系属性类型select属性:设置分步查询SQL全路径colunm属性:设置分步查询SQL中需要参数fetchType:设置局部延迟加载【懒加载】是否开启
-
4.3 分步查询
🙋 为什么使用分步查询【分步查询优势】?
将多表连接查询,改为【分步单表查询】,从而提高程序运行效率
4.3.1 一对一的关联关系
👉用法案例
使用分步查询实现通过员工id获取员工信息及员工所属的部门信息,比如说1.通过员工id获取员工信息,2.通过员工信息中的部门id获得所属部门得信息(员工与部门是一对一的关系,即一个员工只能归属一个部门)
代码示例如下:
①在EmployeeMapper接口中定义实现通过员工id获取员工信息的方法
//使用分步查询实现通过员工id获取员工信息及员工所属的部门信息
//1.通过员工id获取员工信息
//2.通过员工信息中的部门id获得所属部门得信息
public Employee selectEmpByempId(int empId);
②在DeptMapper接口中定义实现通过从查出来的员工信息中的部门编号去查所属部门信息
//通过部门id查询所属部门得信息
public Dept selectDeptByDeptId(int deptId);
③在EmployeeMapper接口对应的映射文件书写相应的sql
<resultMap id="selectEmpByempIdResultMap" type="mybatis.pojo.Employee"><id property="id" column="id"></id><result property="lastName" column="last_name"></result><result property="email" column="email"></result><result property="salary" column="salary"></result><!-- column="deptId" 设置分步查询SQL中需要得参数dept_Id;将此值传入到mybatis.mapper.DeptMapper中的selectDeptByDeptId()方法中 --><association property="dept"select="mybatis.mapper.DeptMapper.selectDeptByDeptId"column="dept_Id" ></association></resultMap><select id="selectEmpByempId" resultMap="selectEmpByempIdResultMap">SELECT`id`,`last_name`,`email`,`salary`,`dept_id`FROM`tbl_employee`WHERE`id`=#{empId};</select>
④在DeptMapper接口对应的映射文件中书写相应的sql
<resultMap id="selectDeptByDeptIdResultMap" type="dept"><id property="deptId" column="dpt_Id"></id><result property="deptName" column="dpt_name"></result>
</resultMap><select id="selectDeptByDeptId" resultMap="selectDeptByDeptIdResultMap">selectdpt_Id,dpt_namefromtbl_departmentwheredpt_Id=#{dptId}
</select>
⑤测试
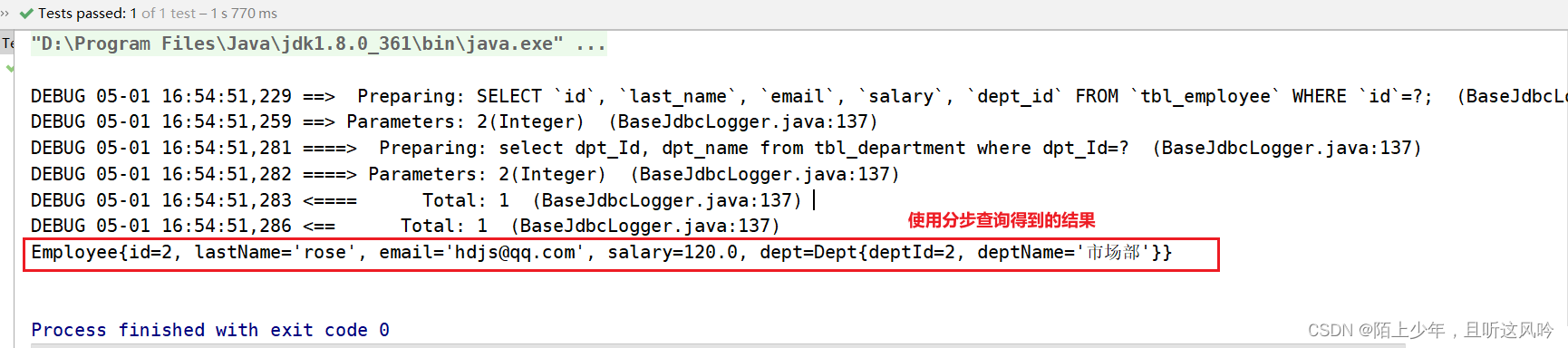
@Test
public void test02(){try {String resource = "mybatis-config.xml";InputStream inputStream = Resources.getResourceAsStream(resource);SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);//通过SqlSessionFactory对象调用openSession();SqlSession sqlSession = sqlSessionFactory.openSession();//获取EmployeeMapper的代理对象EmployeeMapper employeeMapper = sqlSession.getMapper(EmployeeMapper.class);Employee employee = employeeMapper.selectEmpByempId(2);System.out.println(employee);} catch (IOException e) {e.printStackTrace();}}
4.3.2 一对多的关联关系
👉用法案例
通过部门id获取部门信息,及部门所属员工信息【使用分步查询来实现】,其中按1.通过部门id获取部门信息;2.通过部门id获取员工信息等这两个步骤完成分步查询
代码示例如下:
①在DeptMapper接口中书写查询通过部门id获取部门信息的方法
//通过部门id获取部门信息
public Dept showEmployeesByDeptIdBetter(int deptId);
②在DeptMapper接口对应的映射文件中书写相应的sql
<!-- type="dept" 设置映射类型为dept,为什么不是dept类的全称,因为我在配置文件给它起了别名 --><resultMap id="showEmployeesByDeptIdBetterResultMap" type="dept"><id property="deptId" column="dpt_id"></id><result property="deptName" column="dpt_name"></result><collection property="employees"select="mybatis.mapper.EmployeeMapper#selectEmployeeByempId"column="dpt_Id"></collection></resultMap><select id="showEmployeesByDeptIdBetter" resultMap="showEmployeesByDeptIdBetterResultMap">SELECT`dpt_id`,`dpt_name`FROM`tbl_department`WHERE`dpt_id`=#{dptId};</select>
③在EmployeeMapper接口中书写查询通过部门id获取所属员工信息的方法
//通过部门id查询对应的员工信息
public Employee selectEmployeeByempId(int empId);
④在EmployeeMapper接口对应的映射文件中书写相应的sql
<select id="showEmployeesByDeptIdBetter" resultMap="showEmployeesByDeptIdBetterResultMap">SELECT`dpt_id`,`dpt_name`FROM`tbl_department`WHERE`dpt_id`=#{dptId};</select>
⑤测试
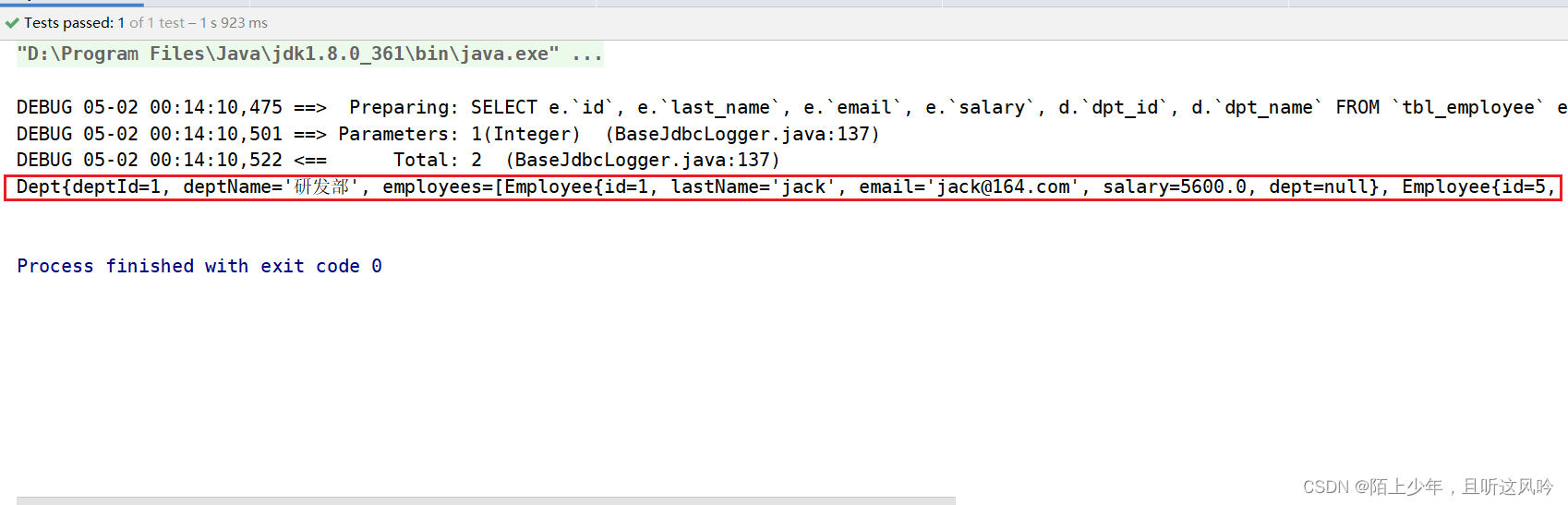
@Test
//测试分步查询版(根据部门编号查询对应的部门信息,然后拿着部门编号去员工表里去找所属的员工信息)
public void test05(){try {String resource = "mybatis-config.xml";InputStream inputStream = Resources.getResourceAsStream(resource);SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);//通过SqlSessionFactory对象调用openSession();SqlSession sqlSession = sqlSessionFactory.openSession();//获取EmployeeMapper的代理对象DeptMapper deptMapper = sqlSession.getMapper(DeptMapper.class);Dept dept = deptMapper.showEmployeesByDeptId(1);System.out.println(dept);} catch (IOException e) {e.printStackTrace();}}
4.3.3 扩展
如果使用分步查询时,需要传递给调用的查询中多个参数,则需要将多个参数封装成 Map来进行传递,语法如下:{k1=v1,k2=v2}
五、Mybatis如何使用延迟加载【懒加载】?
🙋什么是延迟加载?
需要时加载,不需要暂时不加载,如何理解?举个生活中的例子,就好比当你非常饥饿时,才会去吃饭
👉优势
可以提高程序运行效率
👉语法
🚀①全局设置
在核心配置文件中这样写,示例代码如下
<settings><!-- 开启驼峰命名自动映射 --><setting name="mapUnderscoreToCamelCase" value="true"/><!-- 开启全局延迟加载模式 --><setting name="lazyLoadingEnabled" value="true"/><!-- 关闭按需延迟加载模式,在3.4.2版本及以后该步骤可省略 --><setting name="aggressiveLazyLoading" value="false"/>
</settings>
👉用法案例
在核心配置文件开启全局延迟加载模式,借助8.6小结中的案例代码,演示全局延迟加载模式的效果
代码示例如下:
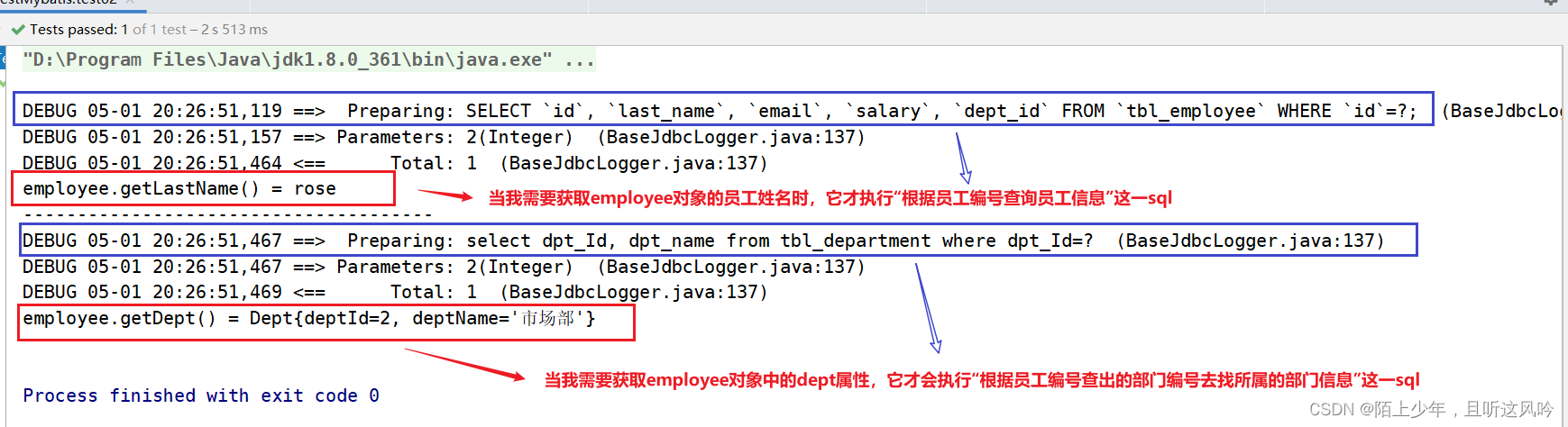
测试运行如下
try {String resource = "mybatis-config.xml";InputStream inputStream = Resources.getResourceAsStream(resource);SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);//通过SqlSessionFactory对象调用openSession();SqlSession sqlSession = sqlSessionFactory.openSession();//获取EmployeeMapper的代理对象EmployeeMapper employeeMapper = sqlSession.getMapper(EmployeeMapper.class);Employee employee = employeeMapper.selectEmpByempId(2);System.out.println("employee.getLastName() = "+employee.getLastName());System.out.println("--------------------------------------");System.out.println("employee.getDept() = "+employee.getDept());} catch (IOException e) {e.printStackTrace();
}
🚀②局部设置
- fetchType
eager:关闭局部延迟加载lazy:开启局部延迟加载
👉用法案例
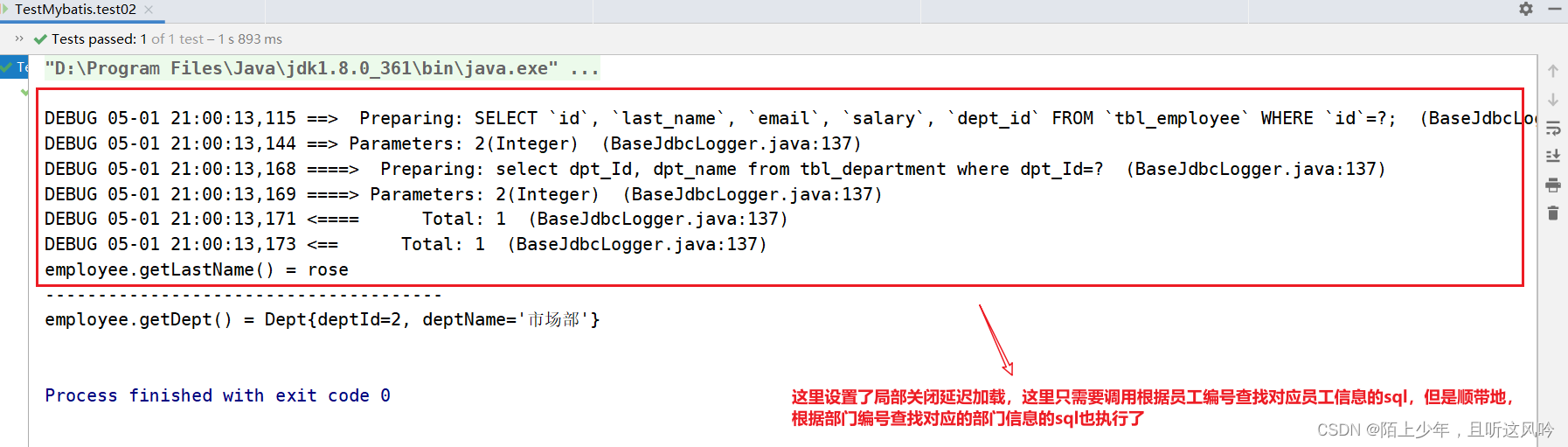
在上述案例中EmployeeMapper接口对应的映射文件里属性id的值为"selectEmpByempId"的sql设置关闭延迟加载(已经设置了全局延迟加载模式,这里再开启局部延迟加载,效果不明显,遂采用关闭局部延迟加载测试效果)
代码示例如下:
<resultMap id="selectEmpByempIdResultMap" type="mybatis.pojo.Employee"><id property="id" column="id"></id><result property="lastName" column="last_name"></result><result property="email" column="email"></result><result property="salary" column="salary"></result><!-- column="deptId" 设置分步查询SQL中需要得参数dept_Id;将此值传入到mybatis.mapper.DeptMapper中的selectDeptByDeptId()方法中 --><!-- fetchType="lazy" 为此方法设置局部延迟加载 --><association property="dept"select="mybatis.mapper.DeptMapper.selectDeptByDeptId"column="dept_Id"fetchType="lazy" ></association></resultMap><select id="selectEmpByempId" resultMap="selectEmpByempIdResultMap">SELECT`id`,`last_name`,`email`,`salary`,`dept_id`FROM`tbl_employee`WHERE`id`=#{empId};</select>
运行测试如下
相关文章:
详解Mybatis之自动映射 自定义映射问题
编译软件:IntelliJ IDEA 2019.2.4 x64 操作系统:win10 x64 位 家庭版 Maven版本:apache-maven-3.6.3 Mybatis版本:3.5.6 文章目录 一、Mybatis中的自动映射是什么?二、Mybatis中的自定义映射是什么?三、为什…...

shiro的优点
shiro是一个强大的java安全框架,它的优点有以下: shiro就是权限管理:包括两部分:身份验证、授权 一、它提供了身份验证、授权、密码和会话管理等功能,可以满足各种应用程序的安全需求。 身份认证就是:验证是…...
使用分布式HTTP代理爬虫实现数据抓取与分析的案例研究
在当今信息爆炸的时代,数据已经成为企业决策和发展的核心资源。然而,要获取大规模的数据并进行有效的分析是一项艰巨的任务。为了解决这一难题,我们进行了一项案例研究,通过使用分布式HTTP代理爬虫,实现数据抓取与分析…...

Linux操作系统运维常用集合
目录 1、服务器磁盘查询、管理常见命令: 2、Centos系统挂载移动硬盘或U盘 3、Linux系统磁盘管理方式 4、Linux系统下挂载磁盘格式详解 1、服务器磁盘查询、管理常见命令: lsblk 查看分区和磁盘df -h …...
)
UE4/5C++多线程插件制作(十四、MTPAbandonable)
目录 MTPAbandonable h实现 cpp实现 MTPMarco.h 首先是异步任务的宏定义部分:...
集装箱装卸作业相关的知识-Part1
1.角件 Corner Fitting of Container or called Corner Casting. there are eigth of it of one container. 国家标准|GB/T 1835-2006https://openstd.samr.gov.cn/bzgk/gb/newGbInfo?hcnoD35857F2200FA115CAA217A114F5EF12 中国的国标:GB/T 1835-2006《系列1集…...
BurpSuite超详细安装教程-功能概述-配置-使用教程---(附下载链接)
一、介绍 BurpSuite是渗透测试、漏洞挖掘以及Web应用程序测试的最佳工具之一,是一款用于攻击web 应用程序的集成攻击测试平台,可以进行抓包、重放、爆破,包含许多工具,能处理对应的HTTP消息、持久性、认证、代理、日志、警报。 二…...
不同局域网下使用Python自带HTTP服务进行文件共享「端口映射」
文章目录 1. 前言2. 视频教程3. 本地文件服务器搭建3.1 python的安装和设置3.2 cpolar的安装和注册 4. 本地文件服务器的发布4.1 Cpolar云端设置4.2 Cpolar本地设置 5. 公网访问测试6. 结语 1. 前言 数据共享作为和连接作为互联网的基础应用,不仅在商业和办公场景有…...

产业大数据应用:洞察企业全维数据,提升企业监、管、服水平
在数字经济时代,数据已经成为重要的生产要素,数字化改革风生水起,在新一代科技革命、产业革命的背景下,产业大数据服务应运而生,为区域产业发展主导部门提供了企业洞察、监测、评估工具。能够助力区域全面了解企业经…...
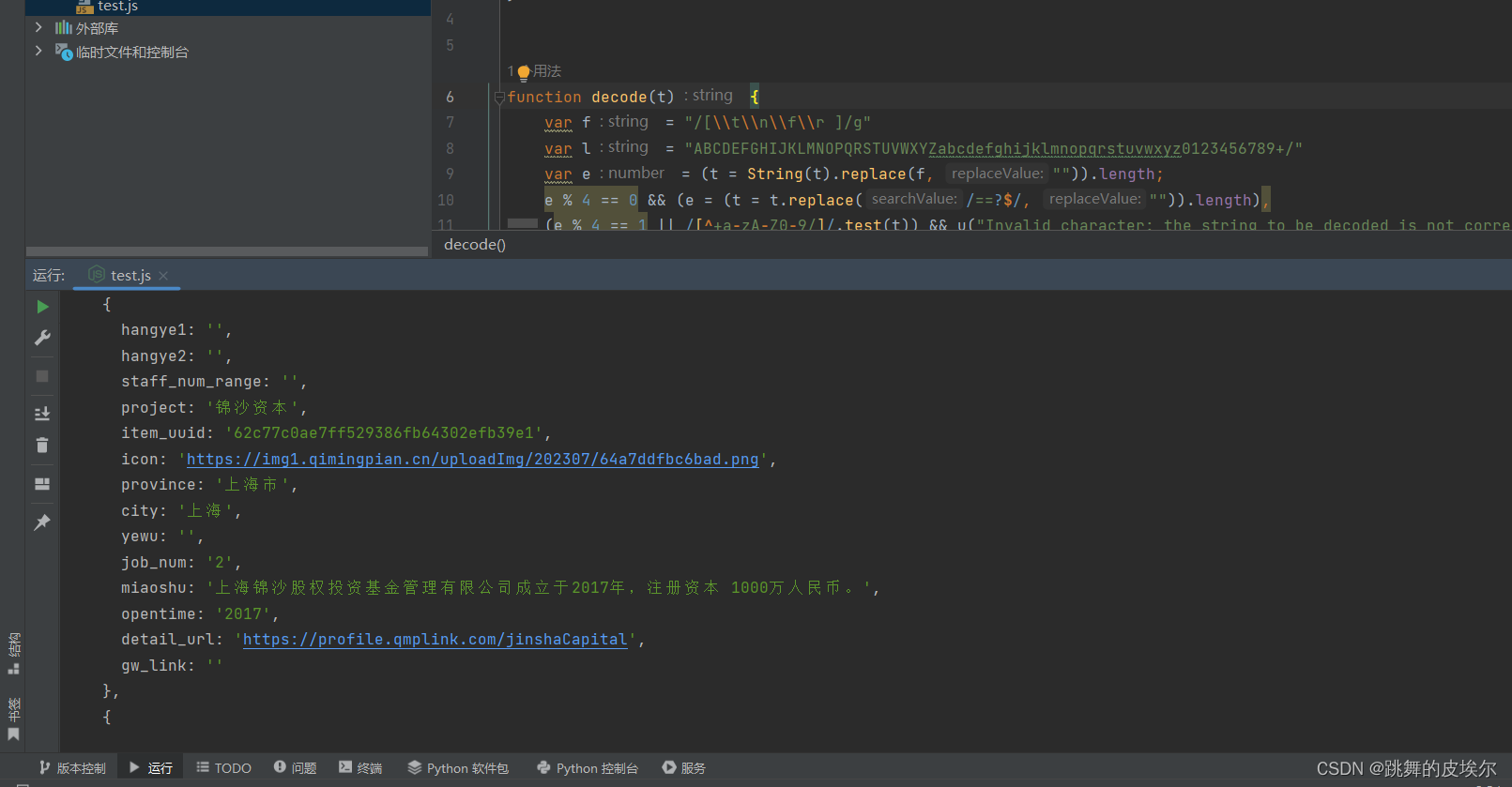
【爬虫逆向案例】某名片网站 js 逆向 —— data解密
声明:本文只作学习研究,禁止用于非法用途,否则后果自负,如有侵权,请告知删除,谢谢! 【爬虫逆向案例】某名片网站js逆向—— data解密 1、前言2、步骤3、号外 1、前言 相信各位小伙伴在写爬虫的…...
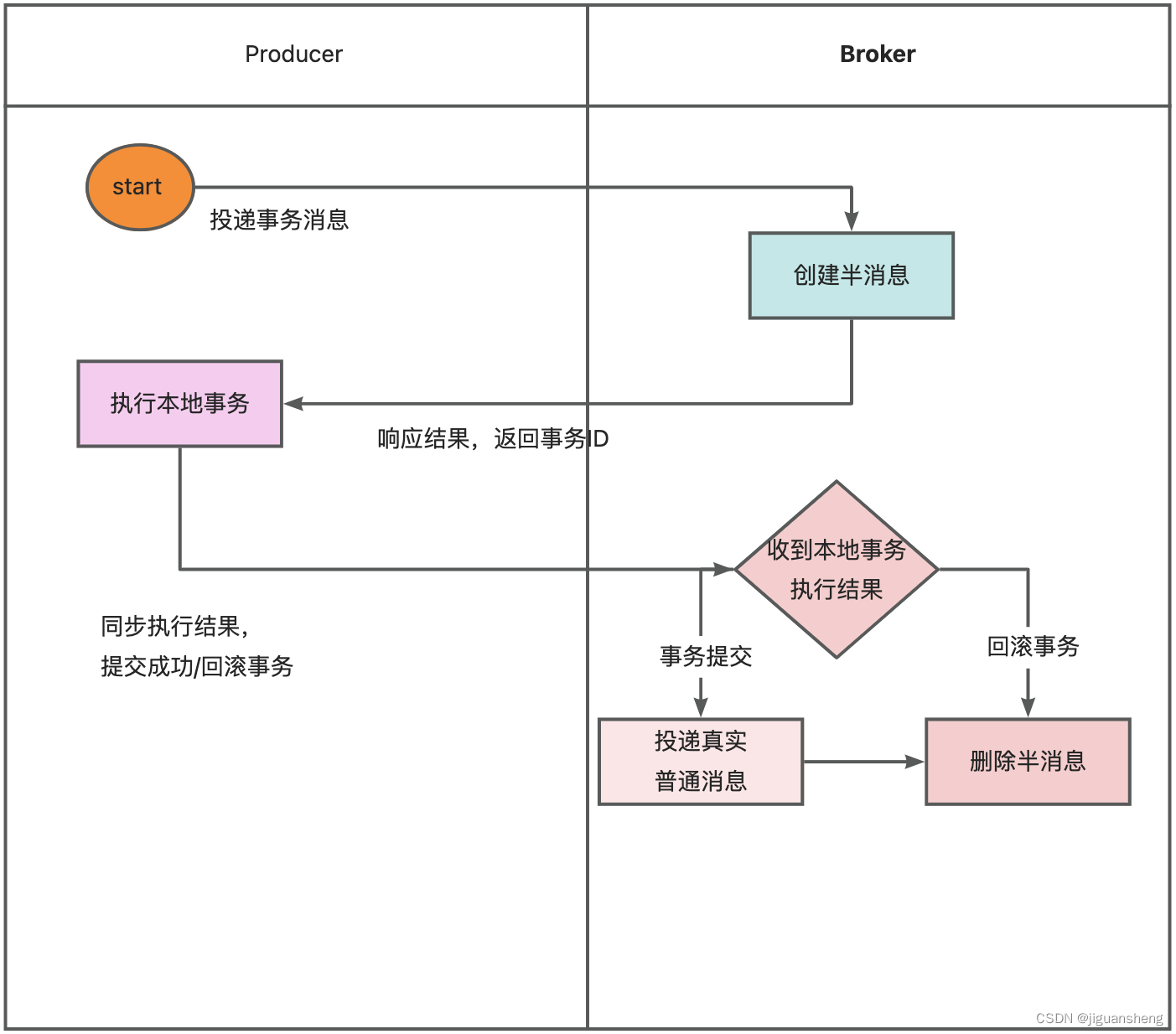
RocketMq 事务消息原理
Rocketmq 事务消息API使用 使用TransactionMQProducer类。 实现TransactionListener 接口覆盖其方法executeLocalTransaction和checkLocalTransaction 即可。 其中executeLocalTransaction 执行本地方法和checkLocalTransaction 事务状态回查。 玩法 简历一张本地事务表&…...
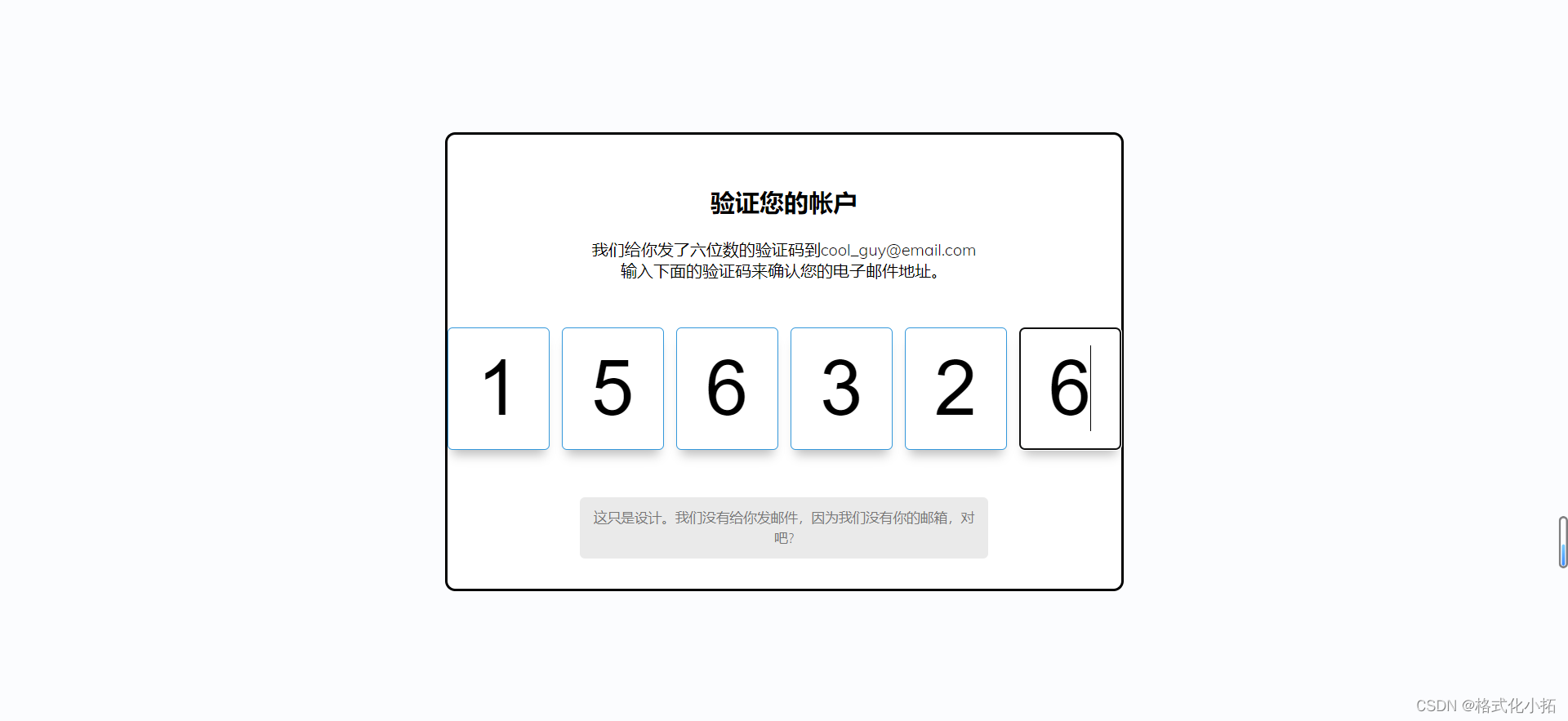
day41-Verify Account Ui(短信验证码小格子输入效果)
50 天学习 50 个项目 - HTMLCSS and JavaScript day41-Verify Account Ui(短信验证码小格子输入效果) 效果 index.html <!DOCTYPE html> <html lang"en"><head><meta charset"UTF-8" /><meta name&qu…...
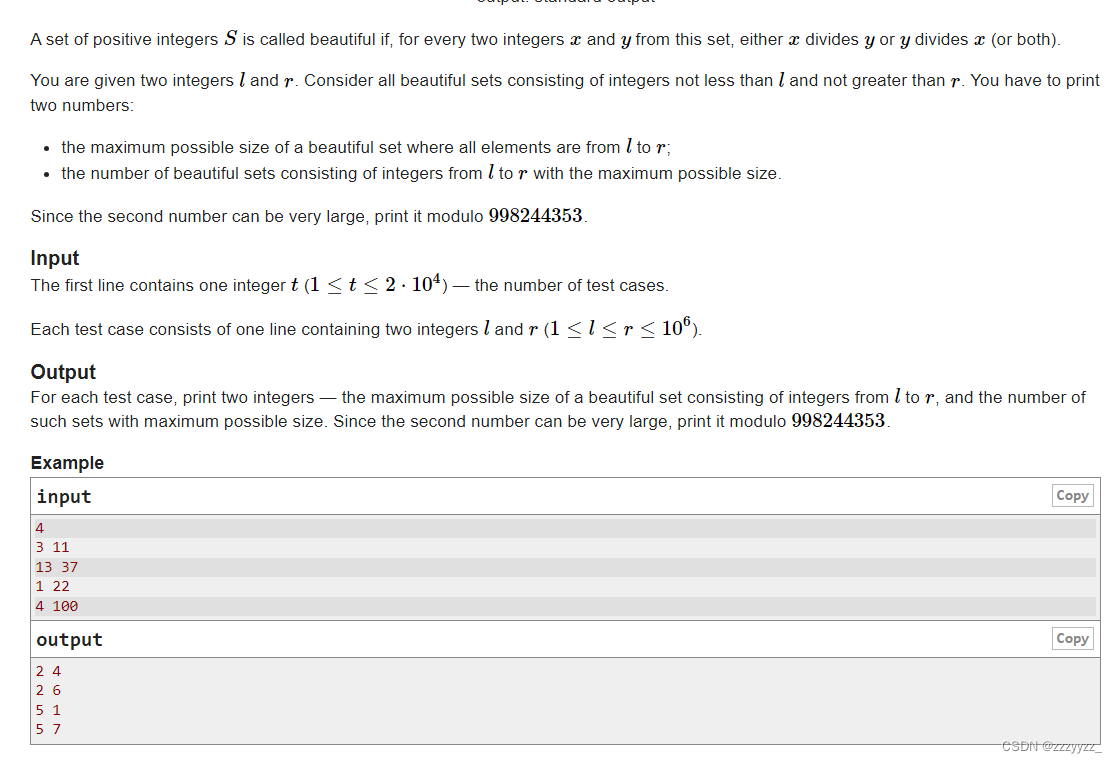
C. Maximum Set
Problem - 1796C - Codeforces 思路:这个题在做的时候基本的思路是对的,但是没有想到O(1)求答案,枚举的然后T了,我们能够知道,假设前面的数小,那么每个数一定是前面的倍数,所以至少乘以2&#x…...
基于springboot+vue学生宿舍报修公寓管理系统
我校日常管理活动中也大部分使用信息化,但学生宿舍的报修管理仍停留在手工办公阶段,使用纸张来记录。不仅对于维修人员和后勤管理人员来说无法提高工作效率,也不方便学生报修。本学生宿舍报修系统主要针对三类人员。第一类是学生用户模块&…...

缓存和数据库一致性问题分析
目录 1、数据不一致的原因 1.1 并发操作 1.2 非原子操作 1.3 数据库主从同步延迟 2、数据不一致的解决方案 2.1 并发操作 2.2 非原子操作 2.3 主从同步延迟 2.4 最终方案 3、不同场景下的特殊考虑 3.1 读多写少的场景 3.2 读少写多的场景 1、数据不一致的原因 导致…...
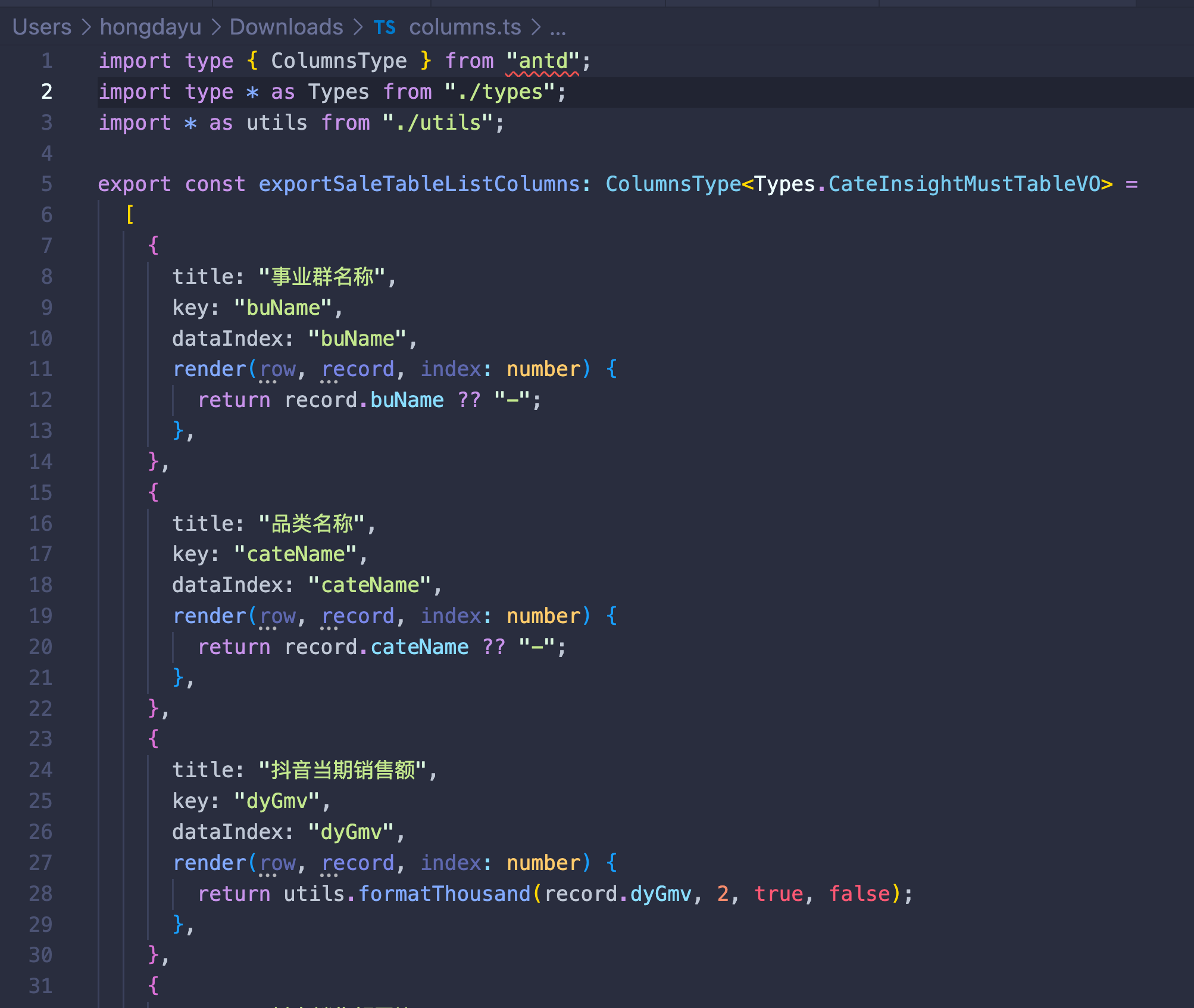
用Rust生成Ant-Design Table Columns | 京东云技术团队
经常开发表格,是不是已经被手写Ant-Design Table的Columns整烦了? 尤其是ToB项目,表格经常动不动就几十列。每次照着后端给的接口文档一个个配置,太头疼了,主要是有时还会粘错就尴尬了。 那有没有办法能自动生成colu…...
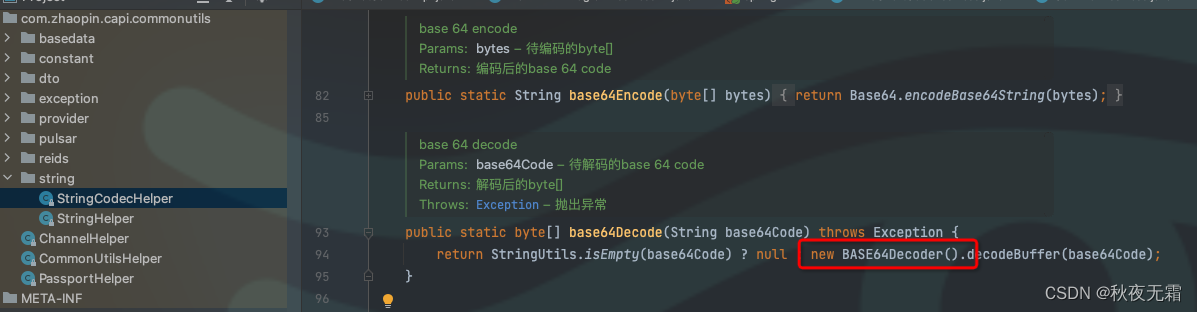
java.lang.ClassNotFoundException: sun.misc.BASE64Decoder
有一个新的应用服务,idea启动应用应用服务时,突然报错java.lang.ClassNotFoundException: sun.misc.BASE64Decoder ,然后在网上搜索,说是建议使用apache包,该类新的JRE已经废弃,并从rt.jar包中移除。但是该…...
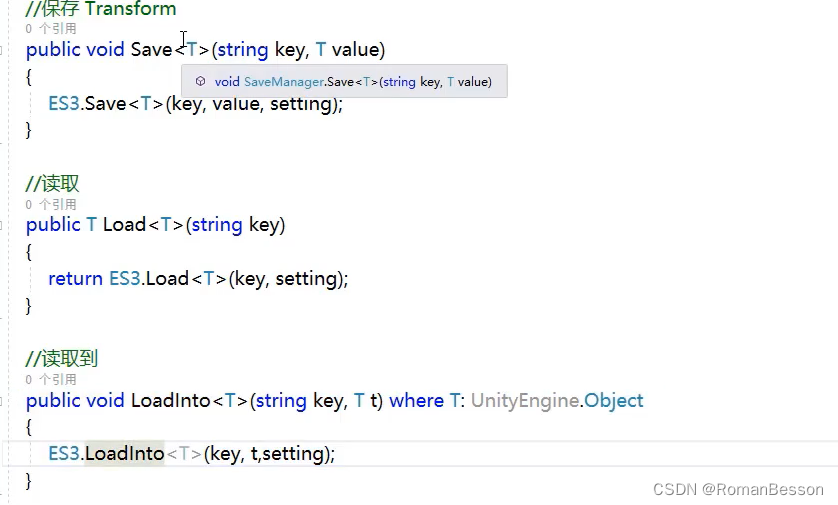
Unity进阶--对象池数据场景管理器笔记
文章目录 泛型单例类泛型单例类(不带组件版)对象池管理器数据管理器场景管理器 泛型单例类 using System.Collections; using System.Collections.Generic;public abstract class ManagersSingle<T> where T : new() {private static T instance;…...

【Seata】微服务集成seata
文章目录 1、Seata介绍2、Seata架构3、部署TC服务4、微服务集成seata 1、Seata介绍 Seata是 2019 年 1 月份蚂蚁金服和阿里巴巴共同开源的分布式事务解决方案。 官网http://seata.io/ 2、Seata架构 Seata事务管理有三个角色: TC (Transaction Coordinator) - 事务…...

解决react,<img>src使用require方法引入图片不显示问题
{settingList.map(i > (<img src{require(./images/${i.deviceTypeName}.png).default} />))} 解决方法: 再导入的图片后加.default即可 <img src{require(../../images/bg.png).default} alt"" /> 推荐阅读:https://www.cnb…...
函数设计一个简单的内存管理Demo)
从“链表长度”到“游戏对象池”:用C++ std::list的size()函数设计一个简单的内存管理Demo
从链表长度到游戏对象池:用C std::list设计高效内存管理方案 在游戏开发中,频繁创建和销毁对象会导致内存碎片化与性能下降。想象一个2D射击游戏场景:玩家发射的子弹、随机生成的敌人都需要动态管理。传统new/delete直接操作内存的方式在这种…...

仲景大语言模型:传承中医智慧的AI创新实践
仲景大语言模型:传承中医智慧的AI创新实践 【免费下载链接】CMLM-ZhongJing 首个中医大语言模型——“仲景”。受古代中医学巨匠张仲景深邃智慧启迪,专为传统中医领域打造的预训练大语言模型。 The first-ever Traditional Chinese Medicine large langu…...

利用快马平台五分钟搭建openmaic网页版图像描述演示原型
最近在调研多模态AI框架时,发现OpenMAIC这个开源项目很有意思。它整合了视觉理解和文本生成能力,特别适合做图像描述这类应用。不过对于想快速验证效果的新手来说,本地部署整套环境还是有点门槛。正好发现InsCode(快马)平台能极速搭建演示原型…...

云安全部署防护成为企业刚需,合规+高效部署指南
企业上云已从可选变为必选项,公有云、私有云、混合云的广泛应用,让企业IT架构更敏捷、成本更可控,但与此同时,云环境的安全风险也呈爆发式增长。Gartner预测,到2025年,99%的云安全事件将由客户配置错误引发…...

如何通过SEO优化让网站排名首页_网站UX设计对SEO有什么影响
如何通过SEO优化让网站排名首页 在当今竞争激烈的互联网环境中,网站排名首页是每个网站主的共同目标。搜索引擎优化(SEO)作为提高网站流量和可见性的关键手段,不可忽视。SEO不仅仅是关于关键词、内容和链接的优化,网站…...

Microsoft团队提出“弯曲雅各布天梯”新思路,了解量子数据如何教会AI做更好的化学
来源:ScienceAI 本文约3500字,建议阅读5分钟量子计算机生成精确数据,AI模型学习并实现百万倍加速预测。有时,一个视觉上引人注目的隐喻,足以让你传达一个复杂的观点。2001 年夏天,杜兰大学物理教授 John P.…...

Lux编译器完整指南:如何将用户意图智能转化为可视化规范
Lux编译器完整指南:如何将用户意图智能转化为可视化规范 【免费下载链接】lux Automatically visualize your pandas dataframe via a single print! 📊 💡 项目地址: https://gitcode.com/gh_mirrors/lux/lux Lux编译器是Lux数据可视…...

突破视频下载壁垒:yt-dlp-gui的全场景应用指南
突破视频下载壁垒:yt-dlp-gui的全场景应用指南 【免费下载链接】yt-dlp-gui Windows GUI for yt-dlp 项目地址: https://gitcode.com/gh_mirrors/yt/yt-dlp-gui 在数字化时代,视频内容已成为信息传递与知识获取的重要载体。然而,多数平…...

Swift Core ML Stable Diffusion架构设计:打造高性能移动端AI绘画引擎
Swift Core ML Stable Diffusion架构设计:打造高性能移动端AI绘画引擎 【免费下载链接】swift-coreml-diffusers Swift app demonstrating Core ML Stable Diffusion 项目地址: https://gitcode.com/gh_mirrors/sw/swift-coreml-diffusers 想要在iPhone和Mac…...

实用指南:使用applera1n安全绕过iOS 15-16激活锁的完整教程
实用指南:使用applera1n安全绕过iOS 15-16激活锁的完整教程 【免费下载链接】applera1n icloud bypass for ios 15-16 项目地址: https://gitcode.com/gh_mirrors/ap/applera1n iOS设备的激活锁是Apple保护用户隐私的重要安全功能,但当您忘记Appl…...