sql中with as用法/with-as 性能调优/with用法
文章目录
- 一、概述
- 二、基本语法
- 三、使用场景
- 3.1、定义CTE,并为每列重命名
- 3.2、多次引用/多次定义
- 3.3、with与union all联合使用
- 3.4、with返回多种结果的值
- 3.5、with与insert使用
- 四、递归查询
- 4.1、语法
- 4.2、使用场景
- 4.2.1、用with递归构造1-10的数据
- 4.2.2、with与insert递归造数据
- 4.2.3、with与update更新数据
- 4.2.4、with与delete删除id为奇数的行
- 4.2.5、with 生成日期序列
一、概述
with as 语句是SQL中的一种常用语法,它可以为一个查询结果或子查询结果创建一个临时表,并且可以在后续的查询中使用这个临时表,在查询结束后该临时表就被清除了。这种语法的使用可以使得复杂的查询变得简单,同时也可以提高查询效率。
WITH AS短语,也叫做子查询部分(subquery factoring),是用来定义一个SQL片断,该SQL片断会被整个SQL语句所用到。这个语句算是公用表表达式(CTE,Common Table Expression)。
with-as 意义:
1、对于多次反复出现的子查询,可以降低扫描表的次数和减少代码重写,优化性能和使编码更加简洁,也可以在UNION ALL的不同部分,作为提供数据的部分。
2、对于UNION ALL,使用WITH AS定义了一个UNION ALL语句,当该片断被调用2次以上,优化器会自动将该WITH AS短语所获取的数据放入一个Temp表中。而提示meterialize则是强制将WITH AS短语的数据放入一个全局临时表中。很多查询通过该方式都可以提高速度。
with as语句支持myql、oracle、db2、hive、sql server、MariaDB、PostgreSQL等数据库,以下列举几种数据库支持的版本
mysql版本:8以及8以上的- sql server:sql server 2005以后的版本
- oracle:Oracle 9i的第二版本数据库
二、基本语法
with查询语句不是以select开始的,而是以“WITH”关键字开头,可以理解为在进行查询之前预先构造了一个临时表,之后便可多次使用它做进一步的分析和处理。
CTE是使用WITH子句定义的,包括三个部分:CTE名称cte_name、定义CTE的查询语句inner_query_definition和引用CTE的外部查询语句outer_query_definition。
CTE可以在select , insert , update , delete , merge语句的执行范围定义。
它的格式如下:
WITH cte_name1[(column_name_list)] AS (inner_query_definition_1)[,cte_name2[(column_name_list)] AS (inner_query_definition_2)]
[,...]
outer_query_definition
其中column_name_list指定inner_query_definition中的列列表名,如果不写该选项,则需要保证在inner_query_definition中的列都有名称且唯一,即对列名有两种命名方式:内部命名和外部命名。
注意,outer_quer_definition必须和CTE定义语句同时执行,因为CTE是临时虚拟表,只有立即引用它,它的定义才是有意义的。
示例:
-- 单个子查询
with tmp as(select username,userage from user)
select username from tmp-- 多个子查询 多个CTE 之间加,分割
with tmp1 as (select * from father),tmp2 as (select * from child)
select * from temp1,temp2 on tmp1.id = tmp2.parentId
注意:
1.必须要整体作为一条sql查询,即with as语句后不能加分号,不然会报错。
2.with子句必须在引用的select语句之前定义,同级with关键字只能使用一次,多个只能用逗号分割;最后一个with 子句与下面的查询之间不能有逗号,只通过右括号分割,with 子句的查询必须用括号括起来.
3. 如果定义了with子句,但其后没有跟使用CTE的SQL语句(如select、insert、update等),则会报错。
4.前面的with子句定义的查询在后面的with子句中可以使用。但是一个with子句内部不能嵌套with子句
5.如果定义了with子句,而在查询中不使用,那么会报ora-32035 错误:未引用在with子句中定义的查询名。(至少一个with查询的name未被引用,解决方法是移除未被引用的with查询),注意:只要后面有引用的就可以,不一定非要在主查询中引用,比如后面的with查询也引用了,也是可以的。
6.当一个查询块名字和一个表名或其他的对象相同时,解析器从内向外搜索,优先使用子查询块名字。
7.with查询的结果列有别名,引用的时候必须使用别名或*。
三、使用场景
3.1、定义CTE,并为每列重命名
mysql 8.0.34版本中测试以下sql
CREATE TABLE user(id INT NOT NULL PRIMARY KEY,sex CHAR(3),NAME CHAR(20)
);INSERT INTO user VALUES
(1,'nan','陈一'),
(2,'nv','珠二'),
(3,'nv','张三'),
(4,'nan','李四'),
(5,'nv','王五'),
(6,'nan','赵六');# 定义CTE,顺便为每列重新命名,且使用ORDER BY子句
WITH nv_user(myid,mysex,myname) AS (SELECT * FROM user WHERE sex='nv' ORDER BY id DESC
)
# 使用CTE
SELECT * FROM nv_user;
+------+-------+-------------+
| myid | mysex | myname |
+------+-------+-------------+
| 5 | nv | 王五 |
| 3 | nv | 张三 |
| 2 | nv | 珠二 |
+------+-------+-------------+
3.2、多次引用/多次定义
1.多次引用:避免重复书写。
2.多次定义:避免派生表的嵌套问题。
3.可以使用递归CTE,实现递归查询。
# 多次引用,避免重复书写
WITH nv_t(myid,mysex,myname) AS (SELECT * FROM user WHERE sex='nv'
)
SELECT t1.*,t2.*
FROM nv_t t1 JOIN nv_t t2
WHERE t1.myid = t2.myid+1;# 多次定义,避免派生表嵌套
WITH
nv_t1 AS ( /* 第一个CTE */SELECT * FROM user WHERE sex='nv'
),
nv_t2 AS ( /* 第二个CTE */SELECT * FROM nv_t1 WHERE id>3
)
SELECT * FROM nv_t2;
如果上面的语句不使用CTE而使用派生表的方式,则它等价于:
SELECT * FROM
(SELECT * FROM
(SELECT * FROM user WHERE sex='nv') AS nv_t1) AS nv_t2;
可以看到这种写法不便于查看。
3.3、with与union all联合使用
前面的with子句定义的查询在后面的with子句中可以使用
with
sql1 as (select s_name from test_tempa),
sql2 as (select s_name from test_tempb where not exists (select s_name from sql1 where rownum=1)) select * from sql1
union all
select * from sql2
union all
select ‘no records’ from dual
where not exists (select s_name from sql1 where rownum=1)
and not exists (select s_name from sql2 where rownum=1);
3.4、with返回多种结果的值
在实际使用中我们可能会遇到需要返回多种结果的值的场景
-- 分类表
CREATE TABLE category ( cid VARCHAR ( 32 ) PRIMARY KEY, cname VARCHAR ( 50 ) );-- 商品表
CREATE TABLE products (pid VARCHAR ( 32 ) PRIMARY KEY,pname VARCHAR ( 50 ),price INT,category_id VARCHAR ( 32 ),FOREIGN KEY ( category_id ) REFERENCES category ( cid )
);
-- 分类数据
INSERT INTO category(cid,cname) VALUES('c001','家电');
INSERT INTO category(cid,cname) VALUES('c002','鞋服');
INSERT INTO category(cid,cname) VALUES('c003','化妆品');
INSERT INTO category(cid,cname) VALUES('c004','汽车');-- 商品数据
INSERT INTO products(pid, pname,price,category_id) VALUES('p001','小米电视机',5000,'c001');
INSERT INTO products(pid, pname,price,category_id) VALUES('p002','格力空调',3000,'c001');
INSERT INTO products(pid, pname,price,category_id) VALUES('p003','美的冰箱',4500,'c001');
INSERT INTO products (pid, pname,price,category_id) VALUES('p004','篮球鞋',800,'c002');
INSERT INTO products (pid, pname,price,category_id) VALUES('p005','运动裤',200,'c002');
INSERT INTO products (pid, pname,price,category_id) VALUES('p006','T恤',300,'c002');
INSERT INTO products (pid, pname,price,category_id) VALUES('p007','冲锋衣',2000,'c002');
INSERT INTO products (pid, pname,price,category_id) VALUES('p008','神仙水',800,'c003');
INSERT INTO products (pid, pname,price,category_id) VALUES('p009','大宝',200,'c003');
如上图,如果我想查询“家电”中“格力空调”与“美的冰箱”的信息,不用with as写法如下:
select * from category c
left join products p on c.cid = p.category_id
where c.cname = '家电' and p.pname in ('格力空调','美的冰箱');
使用with as写法如下:
with c as (select * from category where cname = '家电'),p as (select * from products where pname in ('格力空调','美的冰箱'))
select * from c,p where c.cid = p.category_id;

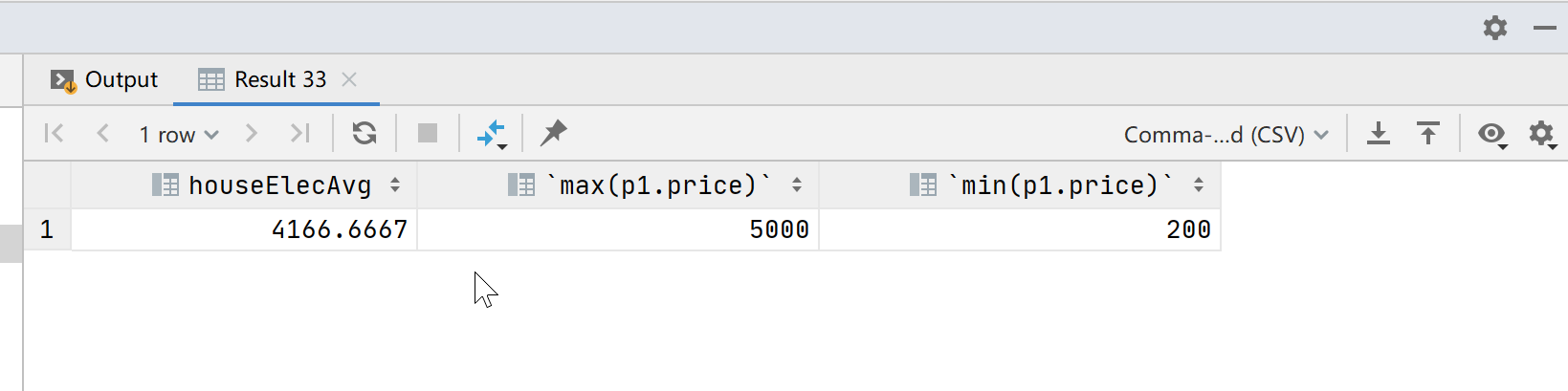
②、查询“家电”的平均价格与所有商品的最小最大值
with tem as (select avg(price) as houseElecAvg from products pleft join category c on c.cid = p.category_idwhere c.cname = '家电'),tem1 as (select max(p1.price),min(p1.price) from products p1)
select * from tem,tem1;
其实 WITH 表达式除了和 SELECT 一起用, 还可以有下面的组合:
insert with 、with update、with delete、with with、with recursive(可以模拟数字、日期等序列)、WITH 可以定义多张表
3.5、with与insert使用
insert into table2
withs1 as (select rownum c1 from dual connect by rownum <= 10),s2 as (select rownum c2 from dual connect by rownum <= 10)
select a.c1, b.c2 from s1 a, s2 b where...;
四、递归查询
在标准的数据库中,如hive,Oracle,DB2,SQL SERVER,PostgreSQL都是支持 WITH AS 语句进行递归查询。mysql8.0及以上支持递归。
公用表表达式(CTE)具有一个重要的优点,那就是能够引用其自身,从而创建递归CTE。递归CTE是一个重复执行初始CTE以返回数据子集直到获取完整结果集的公用表表达式。
当某个查询引用递归CTE时,它即被称为递归查询。递归查询通常用于返回分层数据,例如:显示某个组织图中的雇员或物料清单方案(其中父级产品有一个或多个组件,而那些组件可能还有子组件,或者是其他父级产品的组件)中的数据。
4.1、语法
递归cte中包含一个或多个定位点成员,一个或多个递归成员,最后一个定位点成员必须使用"union [all]"(mariadb中的递归CTE只支持union [all]集合算法)联合第一个递归成员。
更多CTE递归 的其他语法注意事项,请参阅 递归公用表表达式
with recursive cte_name as (select_statement_1 /* 该cte_body称为定位点成员 */union [all]cte_usage_statement /* 此处引用cte自身,称为递归成员 */
)
outer_definition_statement /* 对递归CTE的查询,称为递归查询 */
其中:
- select_statement_1:称为"定位点成员",这是递归cte中最先执行的部分,也是递归成员开始递归时的数据来源。
- cte_usage_statement:称为"递归成员",该语句中必须引用cte自身。它是递归cte中真正开始递归的地方,它首先从定位点成员处获取递归数据来源,然后和其他数据集结合开始递归,每递归一次都将递归结果传递给下一个递归动作,不断重复地查询后,当最终查不出数据时才结束递归。
- outer_definition_statement:是对递归cte的查询,这个查询称为"递归查询"。
4.2、使用场景
4.2.1、用with递归构造1-10的数据
# n迭代次数
with RECURSIVE c(n) as(select 1 union all select n + 1 from c where n < 10)
select n from c;+------+
| n |
+------+
| 1 |
| 2 |
| 3 |
| 4 |
| 5 |
| 6 |
| 7 |
| 8 |
| 9 |
| 10 |
+------+
10 rows in set (0.00 sec)
4.2.2、with与insert递归造数据
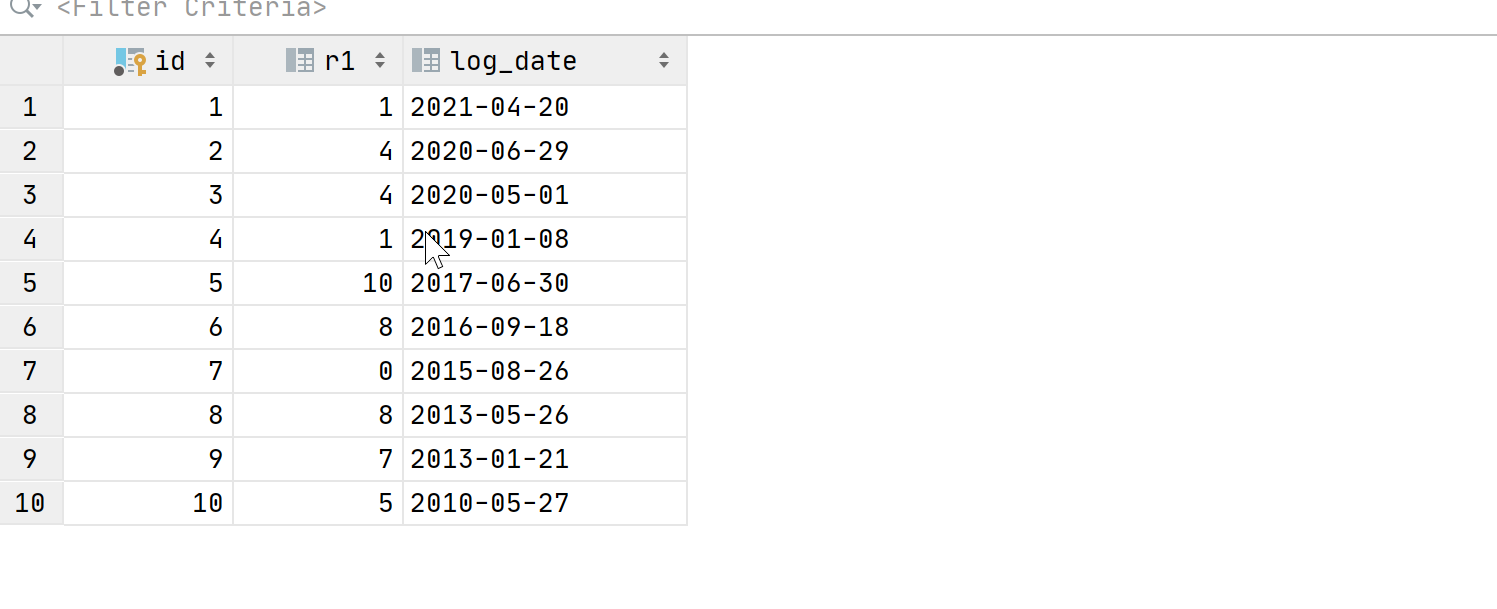
用 WITH 表达式来造数据,非常简单,比如下面例子:给表 y1 添加10条记录,日期字段要随机。
-- 创建测试表
create table y1 (id serial primary key, r1 int,log_date date);-- 插入数据
INSERT y1 (r1,log_date)WITH recursive tmp (a, b) AS(SELECT1,'2021-04-20'UNIONALLSELECTROUND(RAND() * 10),b - INTERVAL ROUND(RAND() * 1000) DAYFROMtmpLIMIT 10)
select * from tmp;
结果:
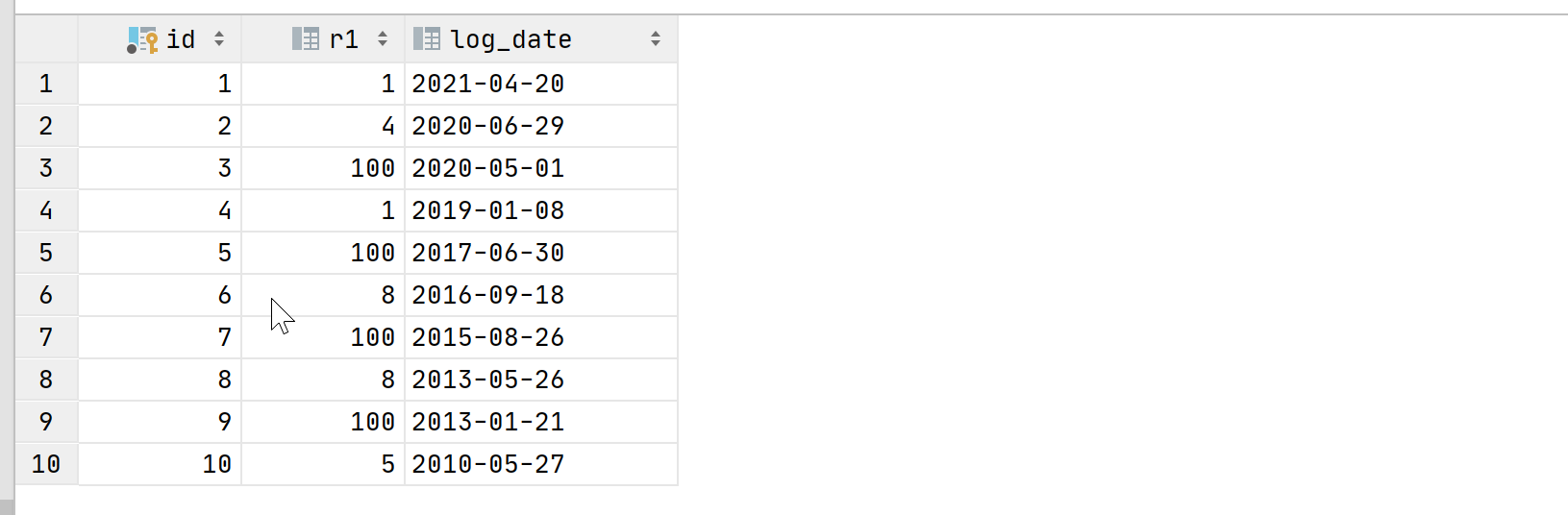
4.2.3、with与update更新数据
WITH recursive tmp (a, b, c) AS(SELECT1,1,'2021-04-20'UNION ALLSELECTa + 2,100,DATE_SUB(CURRENT_DATE(),INTERVAL ROUND(RAND() * 1000, 0) DAY)FROMtmpWHERE a < 10)
UPDATEtmp AS a,y1 AS bSETb.r1 = a.bWHERE a.a = b.id;
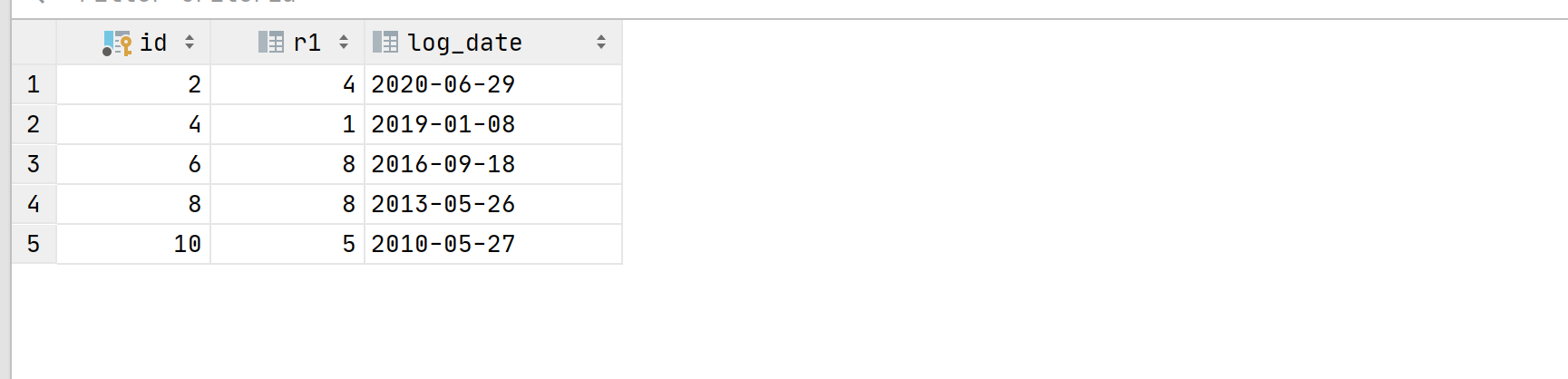
4.2.4、with与delete删除id为奇数的行
比如删除 ID 为奇数的行,可以用 WITH DELETE 形式的删除语句:
WITH recursive tmp (a) AS(SELECT1UNIONALLSELECTa + 2FROMtmpWHERE a < 10)DELETE FROM y1 WHERE id IN (select * from tmp);
与 DELETE 一起使用,要注意一点:WITH 表达式本身数据为只读,所以多表 DELETE 中不能包含 WITH 表达式。比如把上面的语句改成多表删除形式会直接报 WITH 表达式不可更新的错误。
WITH recursive tmp (a) AS(SELECT1UNIONALLSELECTa + 2FROMtmpWHERE a < 100)delete a,b from y1 a join tmp b where a.id = b.a;error: [HY000][1288] The target table b of the DELETE is not updatable
4.2.5、with 生成日期序列
用 WITH 表达式生成日期序列,类似于 POSTGRESQL 的 generate_series 表函数,比如,从 ‘2020-01-01’ 开始,生成一个月的日期序列:
WITH recursive seq_date (log_date) AS(SELECT'2023-07-09'UNIONALLSELECTlog_date + INTERVAL 1 DAYFROMseq_dateWHERE log_date + INTERVAL 1 DAY < '2023-07-20')SELECTlog_dateFROMseq_date;+-----------+
| log_date|
+-----------+
| 2023-07-09|
| 2023-07-10|
| 2023-07-11|
| 2023-07-12|
| 2023-07-13|
| 2023-07-14|
| 2023-07-15|
| 2023-07-16|
| 2023-07-17|
| 2023-07-18|
| 2023-07-19|
+------+参考文档
https://docs.oracle.com/cd/E17952_01/mysql-8.0-en/with.html#common-table-expressions
https://dev.mysql.com/doc/refman/8.0/en/with.html#common-table-expressions-recursive
https://blog.csdn.net/weixin_43194885/article/details/122199299?utm_medium=distribute.pc_relevant.none-task-blog-2defaultbaidujs_baidulandingword~default-1-122199299-blog-74002447.235v38pc_relevant_anti_t3_base&spm=1001.2101.3001.4242.2&utm_relevant_index=4
https://www.jb51.net/article/236061.htm
相关文章:
sql中with as用法/with-as 性能调优/with用法
文章目录 一、概述二、基本语法三、使用场景3.1、定义CTE,并为每列重命名3.2、多次引用/多次定义3.3、with与union all联合使用3.4、with返回多种结果的值3.5、with与insert使用 四、递归查询4.1、语法4.2、使用场景4.2.1、用with递归构造1-10的数据4.2.2、with与insert递归造数…...
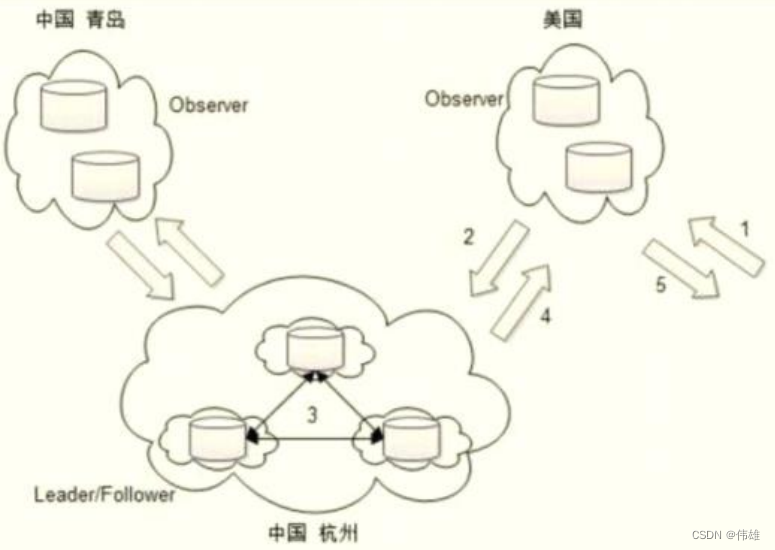
大数据课程C5——ZooKeeper的应用组件
文章作者邮箱:yugongshiyesina.cn 地址:广东惠州 ▲ 本章节目的 ⚪ 掌握Zookeeper的Canal消费组件; ⚪ 掌握Zookeeper的Dubbo分布式服务框架; ⚪ 掌握Zookeeper的Metamorphosis消息中间件; ⚪ 掌握Zo…...
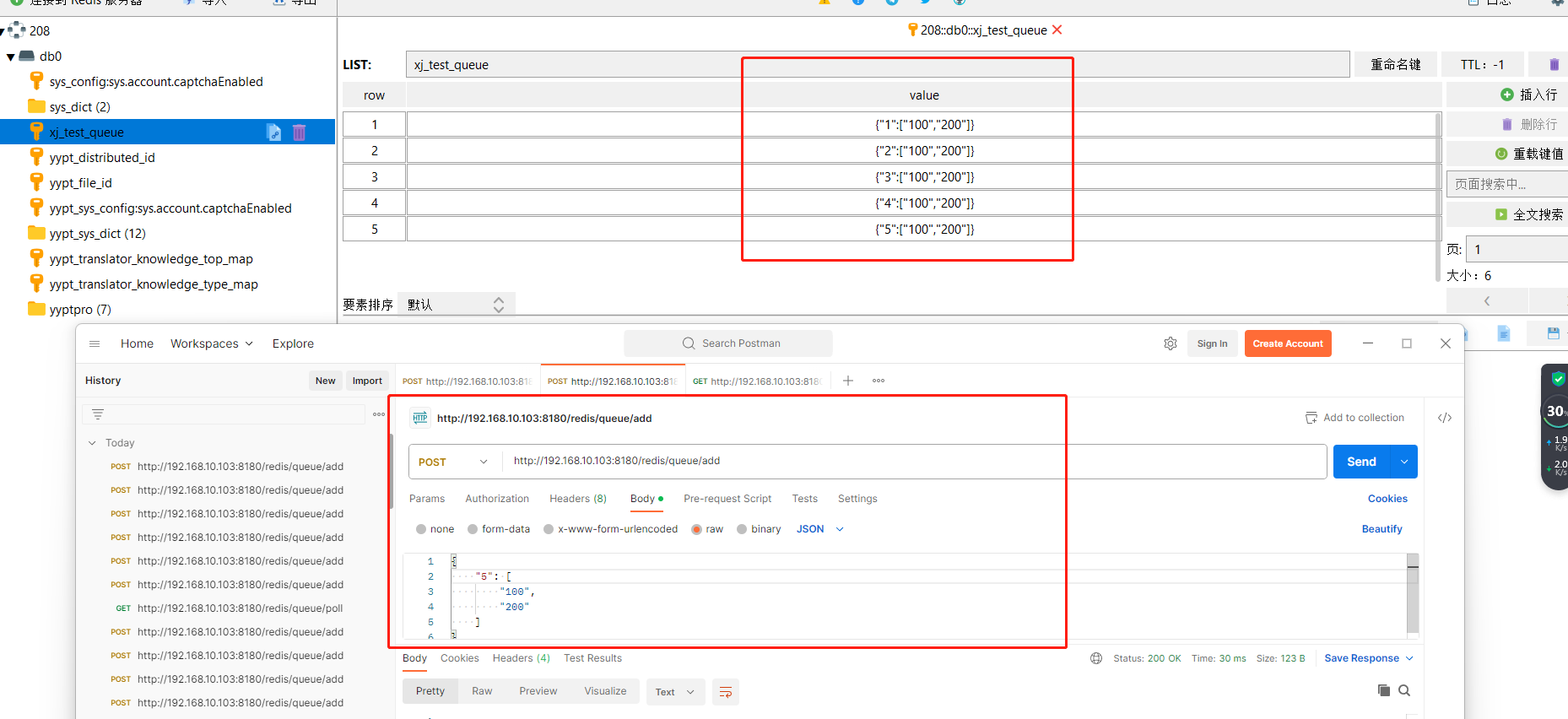
Redisson实现简单消息队列:优雅解决缓存清理冲突
在项目中,缓存是提高应用性能和响应速度的关键手段之一。然而,当多个模块在短时间内发布工单并且需要清理同一个接口的缓存时,容易引发缓存清理冲突,导致缓存失效的问题。为了解决这一难题,我们采用Redisson的消息队列…...

php-golang-rpc 简单的jsonrpc实践
golang代码: package main import ( "net" "net/rpc" "net/rpc/jsonrpc" ) type App struct{} type Res struct { Code int json:"code" Msg string json:"msg" Data any json:"data" } fun…...

Apipost变量高亮展示,变量操作更流畅
之前Apipost配置的各种环境变量只能在右上角环境管理中查看,很多小伙伴希望能有一种更好的解决方案用以快速复制变量值,快速查看变量的当前值和初始值,于是在Apipost 7.1.7中我们推出环境变量高亮展示功能来满足用户的使用需求。 功能描述&a…...
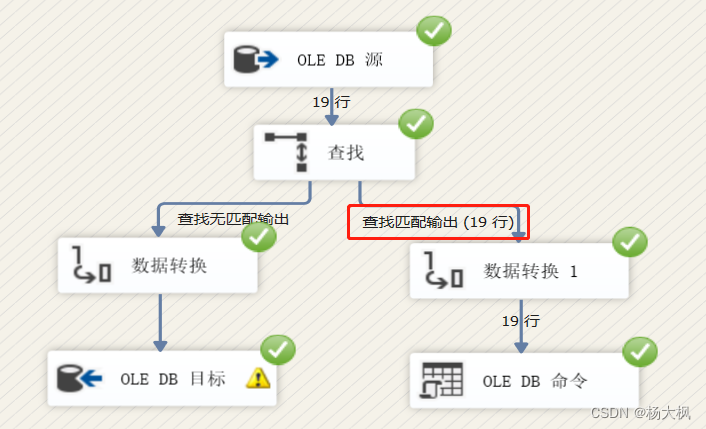
SSIS对SQL Server向Mysql数据转发表数据 (完结)
1、对于根据主键进行更新和插入新的数据,根据前面的文章,对于组件已经很熟悉了,我们直接加入一个 查找 组件 ,如下所示 2、右键点击"查找",然后“编辑” ,选择“连接”,选中我们的目标连接器&…...
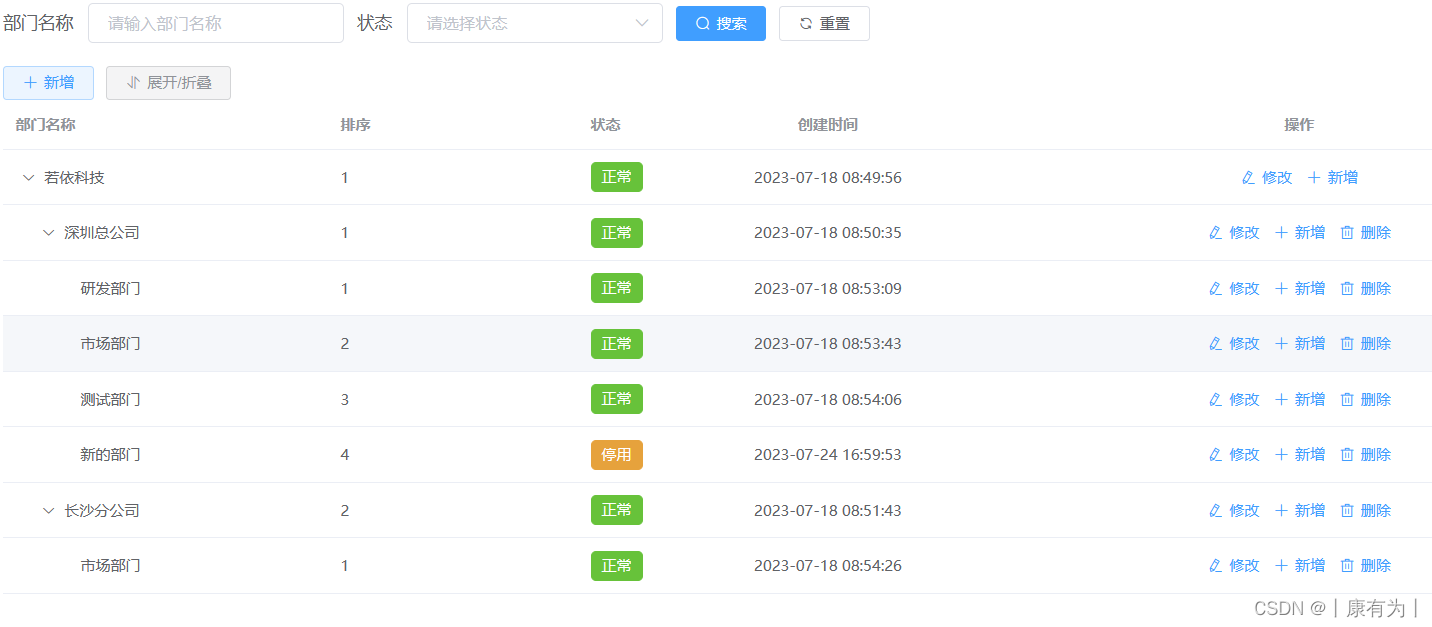
vue+Element-ui实现树形组件、表格树
需求 要做出如下图所示的 树形表格,也就是数据之间有父子类关系的这种,可以点击展开、收缩 像上图这样的表格树 实现 1.使用树形组件 在学习树形表格之前,肯定得先搞懂普通的树形组件是怎么搞的,然后将其套到表格中就好了&…...

【iPadOS 开发】打开 iPad 的开发者模式的方法
文章目录 1. 前提条件2. 具体方法 1. 前提条件 iPad 通过 Type-C 线连接到 Mac Mac上已经安装 Xcode 2. 具体方法 在 Xcode 顶栏中的 Window 中打开 Devices and Simulators ,可以看到自己的设备: 接着在 iPad 上进入 设置 > 隐私与安全性 > 开…...

矩阵对角线元素的和
题目: 给你一个正方形矩阵 mat,请你返回矩阵对角线元素的和。 请你返回在矩阵主对角线上的元素和副对角线上且不在主对角线上元素的和。 示例: 输入:mat [[1,2,3], [4,5,6], [7,8,9]] 输出ÿ…...
看了这篇文章,我也会用grid布局了
grid网格布局 网格布局是由一系列水平及垂直的线构成的一种布局模式,使用网格,我们能够将设计元素进行排列,帮助我们设计一系列具有固定位置以及宽度的元素的页面,使我们的网站页面更加统一。 它将网页划分成一个个网格ÿ…...

{“msg“:“invalid token“,“code“:401}
项目场景: 提示:这里简述项目相关背景: {“msg“:“invalid token“,“code“:401} 前端请求 后端接口时, 请求失败,控制台出现如下所示报错信息 问题描述 问题: 控制台报错信息如下所示: …...

Qt Qml自定义模态对话框
自带的messagedialog不好使,自定义一个,简单的: DialogPop.qml /*** brief 功能:此文件实现了模态框* author lanmanck* date 2023-07-25* CopyRight (C) lanmanck*/ import QtQuick 2.1 import QtQuick.Window 2.0 import QtQu…...
——CSS编写方式)
【前端知识】React 基础巩固(三十)——CSS编写方式
React 基础巩固(三十)——CSS编写方式 1.内联样式 Style 接受一个采用小驼峰命名属性的JS对象,而不是CSS字符串 可以引用state中的状态来设置相关的样式 优点:样式之间不会有冲突;可以动态获取当前state中的状态 缺点:需要使用…...

Langchain 集成 FAISS
Langchain 集成 FAISS 1. FAISS2. Similarity Search with score3. Saving and loading4. Merging5. Similarity Search with filtering 1. FAISS Facebook AI Similarity Search (Faiss)是一个用于高效相似性搜索和密集向量聚类的库。它包含的算法可以搜索任意大小的向量集&a…...

科技与人元宇宙论坛跨界对话
近来,“元宇宙”成为热门话题,越来越频繁地出现在人们的视野里。大家都在谈论它,但似 乎还没有一个被所有人认同的定义。元宇宙究竟是什么?未来它会对我们的工作和生活带来什么样 的改变?当谈论虚拟现实(VR…...

JAVA-生成二维码图片
使用hutool工具包,主动一个简单方便,pom添加依赖 <dependency><groupId>cn.hutool</groupId><artifactId>hutool-all</artifactId><version>5.8.12</version> </dependency> 直接上代码 //设置像素宽高 QrConfig config new…...
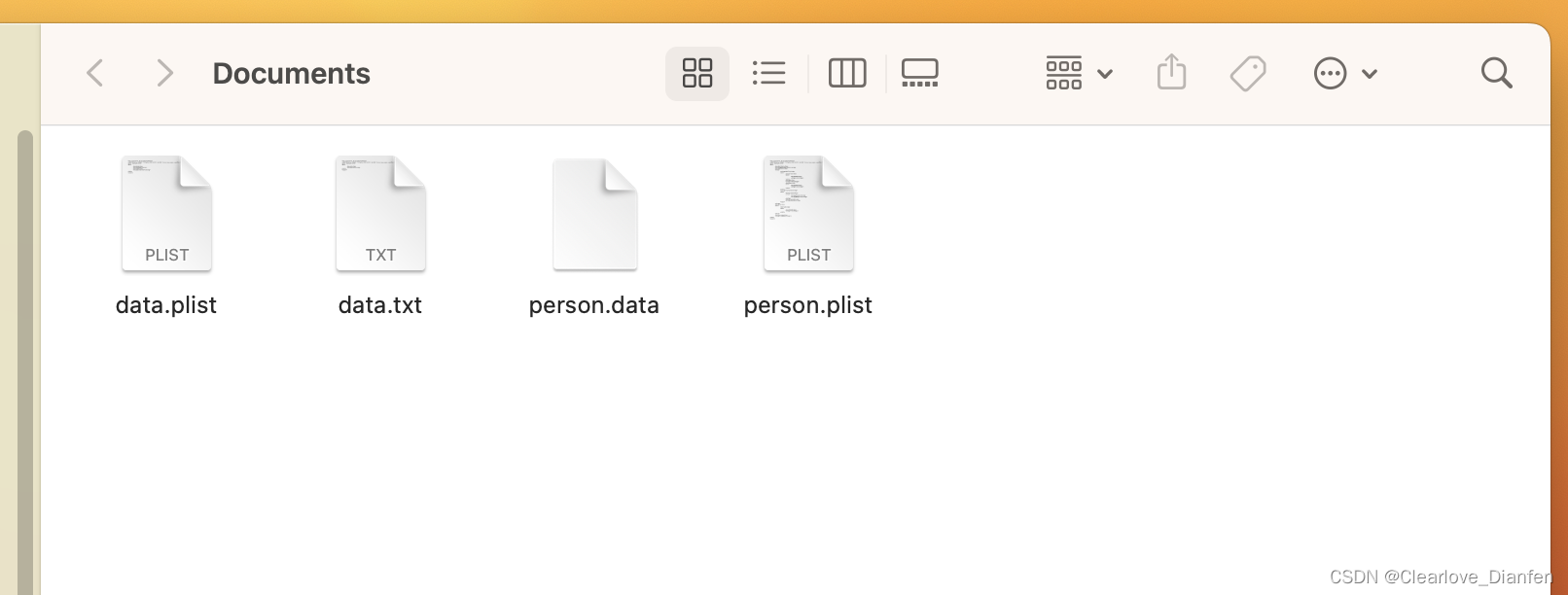
【iOS】iOS持久化
文章目录 一. 数据持久化的目的二. iOS中数据持久化方案三. 数据持有化方式的分类1. 内存缓存2. 磁盘缓存SDWebImage缓存 四. 沙盒机制的介绍五. 沙盒目录结构1. 获取应用程序的沙盒路径2. 访问沙盒目录常用C函数介绍3. 沙盒目录介绍 六. 持久化数据存储方式1. XML属性列表2. P…...
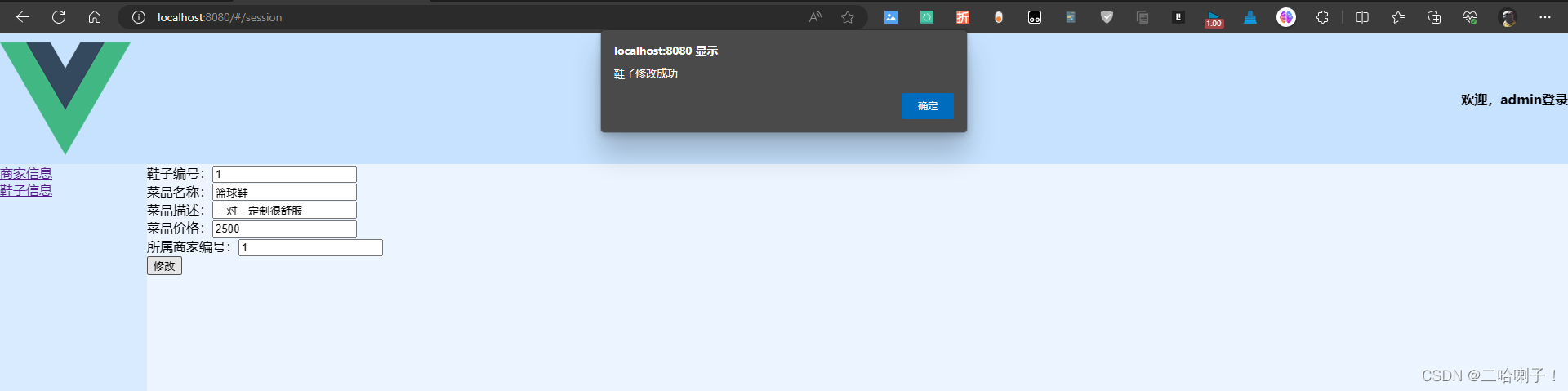
基于Javaweb+Vue3实现淘宝卖鞋前后端分离项目
前端技术栈:HTMLCSSJavaScriptVue3 后端技术栈:JavaSEMySQLJDBCJavaWeb 文章目录 前言1️⃣登录功能登录后端登录前端 2️⃣商家管理查询商家查询商家后端查询商家前端 增加商家增加商家后端增加商家前端 删除商家删除商家后端删除商家前端 修改商家修改…...

bat一键批量、有序启动jar
将脚本文件后缀改为 bat,脚本文件和 jar 包放在同一个目录 echo offstart cmd /c "java -jar register.jar " ping 192.0.2.2 -n 1 -w 10000 > nulstart cmd /c "java -jar admin.jar " ping 192.0.2.2 -n 1 -w 30000 > nulstart cmd /c…...
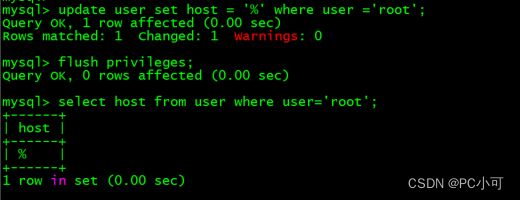
centos7安装mysql数据库详细教程及常见问题解决
mysql数据库详细安装步骤 1.在root身份下输入执行命令: yum -y update 2.检查是否已经安装MySQL,输入以下命令并执行: mysql -v 如出现-bash: mysql: command not found 则说明没有安装mysql 也可以输入rpm -qa | grep -i mysql 查看是否已…...

小说下载器终极指南:一站式解决100+网站小说保存难题
小说下载器终极指南:一站式解决100网站小说保存难题 【免费下载链接】novel-downloader 一个可扩展的通用型小说下载器。 项目地址: https://gitcode.com/gh_mirrors/no/novel-downloader 在数字阅读时代,你是否曾因小说突然下架、网站404或网络中…...

别再手动改路径了!用LabVIEW + MATLAB Script做自动化测试,这份环境配置指南让你效率翻倍
LabVIEW与MATLAB深度整合:构建自动化测试系统的工程实践指南在工业自动化与测试测量领域,LabVIEW和MATLAB的组合堪称黄金搭档。LabVIEW擅长硬件接口和实时控制,而MATLAB在算法开发和数据分析方面具有无可比拟的优势。本文将深入探讨如何将两者…...

Sangfor文件夹可以删除吗?【图文讲解】深信服文件夹残留清理?如何彻底删除深信服?Sangfor文件夹是什么?
(1)问题背景打开C盘,突然冒出个Sangfor 文件夹,占用好几个 GB 空间,想删又不敢删,怕删坏系统、断网崩溃;上网一查,说法五花八门,有人说是病毒,有人说是办公软…...
)
告别硬编码!在UE5.1里用蓝图动态配置MySQL连接参数(控件蓝图实战)
动态配置MySQL连接:UE5.1控件蓝图的工程化实践在游戏开发中,数据库连接往往是项目架构中不可或缺的一环。传统硬编码方式虽然简单直接,却带来了维护困难、安全性差、灵活性低等一系列问题。本文将深入探讨如何在UE5.1中构建一个完全动态化的M…...

终极指南:5步快速掌握免费的3D点云标注工具labelCloud
终极指南:5步快速掌握免费的3D点云标注工具labelCloud 【免费下载链接】labelCloud A lightweight tool for labeling 3D bounding boxes in point clouds. 项目地址: https://gitcode.com/gh_mirrors/la/labelCloud 想要为自动驾驶、机器人视觉或3D目标检测…...
)
紧急预警:DeepSeek代码生成中未公开的3类逻辑漂移现象(附自动化检测脚本+修复模板)
更多请点击: https://intelliparadigm.com 第一章:紧急预警:DeepSeek代码生成中未公开的3类逻辑漂移现象(附自动化检测脚本修复模板) 近期在多轮生产级代码审计中发现,DeepSeek-R1(v2.5&#x…...

基于LSTM自编码器的家用电器功耗异常检测系统构建指南
1. 项目概述:从能耗洞察到智能干预我们每天都在和各种家用电器打交道,从清晨唤醒你的咖啡机,到深夜还在默默工作的路由器。你有没有想过,这些看似微不足道的设备,其背后隐藏的能耗模式,其实大有文章&#x…...

Playwright文件上传避坑指南:遇到动态生成的文件选择框怎么办?
Playwright文件上传避坑指南:动态生成文件选择框的实战解决方案最近在为一个电商平台做自动化测试时,遇到了一个棘手的问题——商品图片上传功能总是失败。页面上的"上传图片"按钮明明可以点击,但传统的set_input_files()方法却毫无…...

ClojureDocs性能优化技巧:5个关键策略提升文档网站响应速度 [特殊字符]
ClojureDocs性能优化技巧:5个关键策略提升文档网站响应速度 🚀 【免费下载链接】clojuredocs clojuredocs.org web app 项目地址: https://gitcode.com/gh_mirrors/cl/clojuredocs ClojureDocs作为社区驱动的Clojure文档网站,其性能优…...

ThriftPy性能测试与基准对比:Cython加速效果分析
ThriftPy性能测试与基准对比:Cython加速效果分析 【免费下载链接】thriftpy Thriftpy has been deprecated, please migrate to https://github.com/Thriftpy/thriftpy2 项目地址: https://gitcode.com/gh_mirrors/th/thriftpy ThriftPy是一款高效的Python T…...