在CSDN学Golang分布式中间件(ElasticSearch)
一,倒排索引,lucene
倒排索引是一种用于快速查找文本中特定单词或短语的数据结构。它将文本中的每个单词或短语与包含该单词或短语的文档列表相关联。这使得可以轻松地查找包含给定单词或短语的所有文档。
在 Go 中,可以使用 map 和 slice 来实现倒排索引。具体来说,可以使用一个 map 将每个单词映射到包含该单词的文档列表。例如:
index := make(map[string][]string)然后,在处理每个文档时,将其拆分成单词,并将每个单词添加到相应的列表中:
words := strings.Split(text, " ")
for _, word := range words {index[word] = append(index[word], docID)
}这样就可以通过检索特定单词来获取包含该单词的所有文档。
另一方面,Lucene 是一个全文搜索引擎库,可用于建立更高效和更复杂的倒排索引。它提供了许多功能,例如支持布尔查询、模糊查询、范围查询等,并且能够处理大规模数据集。
Lucene 倒排索引使用 B 树和倒排列表(Inverted List)来存储信息。B 树是一种平衡树结构,可用于快速查找索引中的文档。而倒排列表则是一个映射,将单词映射到它们出现在哪些文档中。
Go 中的倒排索引适用于较小的数据集和简单的搜索需求,而 Lucene 则适用于需要处理大规模数据集和更高级别查询需求的场景。
二,es-head和kibana
ES-Head 是一个 Elasticsearch 可视化管理工具,它提供了一个 Web 界面,可以帮助用户更直观地理解和管理 Elasticsearch 集群。ES-Head 提供了各种功能,例如索引管理、集群健康监控、搜索等。
Kibana 是一个用于可视化和分析 Elasticsearch 数据的开源工具。它提供了一个基于 Web 的界面,使用户可以轻松地创建交互式仪表板、图表和可视化效果,并进行深入的数据分析。Kibana 也是 ELK(Elasticsearch + Logstash + Kibana)技术栈中的一部分。
在 Go 中使用 ES-Head 和 Kibana 是非常简单的,因为它们都是 Web 应用程序。只需下载这些应用程序并在本地运行即可开始使用。
要使用 ES-Head,请按照以下步骤操作:
- 下载 ES-Head:https://github.com/mobz/elasticsearch-head
- 解压缩文件并进入目录
- 启动 ES-Head:
npm install
grunt server- 打开浏览器访问 http://localhost:9100/ 即可开始使用
要使用 Kibana,请按照以下步骤操作:
- 下载 Kibana:https://www.elastic.co/downloads/kibana
- 解压缩文件并进入目录
- 修改 kibana.yml 文件以指定 Elasticsearch 主机和端口:
elasticsearch.hosts: ["http://localhost:9200"]- 启动 Kibana:
bin/kibana- 打开浏览器访问 http://localhost:5601/ 即可开始使用
ES-Head 和 Kibana 是非常有用的 Elasticsearch 可视化工具。它们可以帮助用户更好地管理和分析 Elasticsearch 数据,并提供了各种功能来满足不同的需求。
三,es 集群健康值检查
在 Go 中,可以使用 Elasticsearch 官方提供的 Go 客户端库(github.com/elastic/go-elasticsearch)来检查 ES 集群的健康值。该客户端库提供了许多方法和结构体,以便于与 Elasticsearch 交互。
以下是一个示例代码,用于获取 ES 集群的健康值:
package mainimport ("context""fmt""log""github.com/elastic/go-elasticsearch/v7"
)func main() {// 创建一个 Elasticsearch 客户端es, err := elasticsearch.NewDefaultClient()if err != nil {log.Fatalf("Error creating the client: %s", err)}// 发送集群健康请求res, err := es.Cluster.Health(es.Cluster.Health.WithContext(context.Background()),es.Cluster.Health.WithIndex("my_index"),es.Cluster.Health.WithWaitForStatus("yellow"), // 等待集群状态为黄色或更好es.Cluster.Health.WithTimeout(30), // 设置超时时间为 30 秒)if err != nil {log.Fatalf("Error getting cluster health: %s", err)}// 获取响应中的健康状态health, _ := res.Status()fmt.Printf("Cluster health is %q\n", health)
}在上面的代码中,我们首先创建了一个默认配置的 Elasticsearch 客户端(elasticsearch.NewDefaultClient())。然后,我们使用 es.Cluster.Health 方法发送一个集群健康请求,并通过各种选项来设置请求参数,例如:索引名称、期望的健康状态等。最后,我们通过 res.Status() 方法获取响应中的健康状态。
需要注意的是,在发送集群健康请求时,可以使用不同的选项来定制请求参数,以满足不同的需求。例如:
- WithIndex():指定一个或多个索引名称。
- WithWaitForStatus():指定期望的健康状态(green/yellow/red)。
- WithTimeout():设置超时时间(单位为秒)。
- WithPretty():指定是否将响应格式化为易于阅读的 JSON 格式。
在 Go 中检查 ES 集群健康值非常简单,只需使用 Elasticsearch 官方提供的 Go 客户端库即可。
四,es 索引操作以及文档操作
在 Go 中,可以使用 Elasticsearch 官方提供的 Go 客户端库(github.com/elastic/go-elasticsearch)来进行索引操作和文档操作。该客户端库提供了许多方法和结构体,以便于与 Elasticsearch 交互。
以下是一个示例代码,用于对 ES 索引进行创建、删除、更新以及文档的增删改查:
package mainimport ("context""encoding/json""fmt""log""github.com/elastic/go-elasticsearch/v7"
)func main() {// 创建一个 Elasticsearch 客户端es, err := elasticsearch.NewDefaultClient()if err != nil {log.Fatalf("Error creating the client: %s", err)}// 创建索引createIndex(es)// 添加文档addDocument(es)// 获取文档getDocument(es)// 更新文档updateDocument(es)// 删除文档deleteDocument(es)// 删除索引deleteIndex(es)
}func createIndex(es *elasticsearch.Client) {// 准备请求参数reqBody := `{"settings": {"number_of_shards": 1,"number_of_replicas": 0},"mappings": {"properties": {"title": { "type": "text" },"content": { "type": "text" }}}}`// 发送请求创建索引res, err := es.Indices.Create("my_index",es.Indices.Create.WithContext(context.Background()),es.Indices.Create.WithBody(strings.NewReader(reqBody)),)if err != nil {log.Fatalf("Error creating the index: %s", err)}// 获取响应中的状态码statusCode := res.StatusCodefmt.Printf("Index created, status code: %d\n", statusCode)
}func addDocument(es *elasticsearch.Client) {// 准备文档数据docData := map[string]interface{}{"title": "First document","content": "This is the first document.",}// 发送请求添加文档res, err := es.Index("my_index",es.Index.WithDocumentID("1"), // 指定文档 IDes.Index.WithBodyJSON(docData), // 指定文档内容es.Index.WithRefresh("true"), // 立即刷新索引以使文档可用于搜索(仅用于测试)es.Index.WithContext(context.Background()),)if err != nil {log.Fatalf("Error adding document: %s", err)}// 获取响应中的状态码和 IDstatusCode := res.StatusCodeid := res.Idfmt.Printf("Document added, status code: %d, id: %s\n", statusCode, id)
}func getDocument(es *elasticsearch.Client) {// 发送请求获取指定 ID 的文档res, err := es.Get("my_index","1",es.Get.WithContext(context.Background()),)if err != nil {log.Fatalf("Error getting document: %s", err)}defer res.Body.Close()// 解析响应中的文档内容var docData map[string]interface{}if err := json.NewDecoder(res.Body).Decode(&docData); err != nil {log.Fatalf("Error parsing the response body: %s", err)}fmt.Printf("Document found, title: %s, content: %s\n", docData["title"], docData["content"])
}func updateDocument(es *elasticsearch.Client) {// 准备更新数据updateData := map[string]interface{}{"doc": map[string]interface{}{"content": "This is an updated document.",},}// 发送请求更新文档res, err := es.Update("my_index","1",es.Update.WithBodyJSON(updateData),es.Update.WithRefresh("true"),es.Update.WithContext(context.Background()),)if err != nil {log.Fatalf("Error updating document: %s", err)}// 获取响应中的状态码和 IDstatusCode := res.StatusCodeid := res.Idfmt.Printf("Document updated, status code: %d, id: %s\n", statusCode, id)
}func deleteDocument(es *elasticsearch.Client) {// 发送请求删除指定 ID 的文档res, err := es.Delete("my_index","1",es.Delete.WithRefresh("true"),es.Delete.WithContext(context.Background()),)if err != nil {log.Fatalf("Error deleting document: %s", err)}// 获取响应中的状态码和 IDstatusCode := res.StatusCodeid := res.Idfmt.Printf("Document deleted, status code: %d, id: %s\n", statusCode, id)
}func deleteIndex(es *elasticsearch.Client) {// 发送请求删除索引res, err := es.Indices.Delete([]string{"my_index"},es.Indices.Delete.WithIgnoreUnavailable(true), // 如果索引不存在,则忽略错误es.Indices.Delete.WithContext(context.Background()),)if err != nil {log.Fatalf("Error deleting index: %s", err)}// 获取响应中的状态码和索引名称statusCode := res.StatusCodeindexName := res.Indexfmt.Printf("Index deleted, status code: %d, index name: %s\n", statusCode, indexName)
}在上面的代码中,我们首先创建了一个默认配置的 Elasticsearch 客户端(elasticsearch.NewDefaultClient())。然后,我们分别实现了创建索引、添加文档、获取文档、更新文档以及删除文档和删除索引等操作。
需要注意的是,在执行这些操作时,可以使用不同的选项来定制请求参数,以满足不同的需求。例如:
- WithDocumentID():指定文档 ID。
- WithBodyJSON():指定请求体中包含的 JSON 数据。
- WithRefresh():控制何时使文档可用于搜索(仅用于测试)。
- WithIgnoreUnavailable():如果索引不存在,则忽略错误。
在 Go 中进行 ES 索引操作和文档操作非常简单,只需使用 Elasticsearch 官方提供的 Go 客户端库即可。
五,es 读写机制
在 Elasticsearch 中,数据存储在分片(Shard)中,并且每个分片都可以有多个副本。这意味着写入和读取操作涉及到许多网络通信和数据复制等操作,因此需要一些特殊的机制来管理读写请求。
以下是 Elasticsearch 中的一些常见的读写机制:
写入机制
- 数据先被写入主分片(Primary Shard)。主分片负责处理所有文档的添加、更新和删除操作。
- 如果有副本分片,则主分片会将数据复制到其它副本上。这样可以保证数据的可靠性和冗余性。
- 当客户端发送写请求时,Elasticsearch 会使用 write consistency level 选项来控制写入操作的行为。write consistency level 有以下几种级别:
- one:只需将数据写入一个节点即可返回成功响应。
- quorum:至少需要将数据写入大多数节点才能返回成功响应。
- all:需要将数据写入所有节点才能返回成功响应。
- 在向客户端返回成功响应之前,Elasticsearch 会执行 refresh 操作以确保新添加或修改过的文档可以立即被搜索。
读取机制
- 客户端发送 read 请求时,Elasticsearch 会根据 request consistency level 选项来确定从哪些节点获取数据。request consistency level 有以下几种级别:
- one:只需从一个节点获取数据即可返回成功响应。
- quorum:需要从大多数节点获取数据才能返回成功响应。
- all:需要从所有节点获取数据才能返回成功响应。
- 如果请求的分片或副本尚未完成写入,则读取操作可能会失败。为了避免这种情况,可以使用 refresh 操作来强制刷新索引以确保文档可用于搜索。
以上是 Elasticsearch 中常见的读写机制,可以通过一些选项来调整和控制它们的行为。在 Go 中使用 Elasticsearch 官方提供的 Go 客户端库时,可以通过在请求中设置相关选项来管理读写请求。
六,es 匹配查询,范围查询,多条件查询
在 Elasticsearch 中,可以使用各种查询来搜索和过滤文档。以下是一些常见的查询类型:
匹配查询
匹配查询是最简单和最基本的查询类型之一,用于查找一个或多个字段中包含指定字符串的文档。在 Go 中,可以使用 MatchQuery 来执行匹配查询。
import ("context""fmt""github.com/elastic/go-elasticsearch/v7""github.com/elastic/go-elasticsearch/v7/esapi"
)func main() {es, _ := elasticsearch.NewDefaultClient()var buf bytes.Bufferquery := map[string]interface{}{"query": map[string]interface{}{"match": map[string]interface{}{"name": "John",},},}if err := json.NewEncoder(&buf).Encode(query); err != nil {log.Fatalf("Error encoding query: %s", err)}res, err := es.Search(es.Search.WithContext(context.Background()),es.Search.WithIndex("my-index"),es.Search.WithBody(&buf),es.Search.WithTrackTotalHits(true),es.Search.WithPretty(),)if err != nil {log.Fatalf("Error getting response: %s", err)}
}范围查询
范围查询用于查找指定字段中符合指定范围条件的文档。在 Go 中,可以使用 RangeQuery 来执行范围查询。
import ("context""fmt""github.com/elastic/go-elasticsearch/v7""github.com/elastic/go-elasticsearch/v7/esapi"
)func main() {es, _ := elasticsearch.NewDefaultClient()var buf bytes.Bufferquery := map[string]interface{}{"query": map[string]interface{}{"range": map[string]interface{}{"age": map[string]interface{}{"gte": 30,"lte": 40,},},},}if err := json.NewEncoder(&buf).Encode(query); err != nil {log.Fatalf("Error encoding query: %s", err)}res, err := es.Search(es.Search.WithContext(context.Background()),es.Search.WithIndex("my-index"),es.Search.WithBody(&buf),es.Search.WithTrackTotalHits(true),es.Search.WithPretty(),)if err != nil {log.Fatalf("Error getting response: %s", err)}
}多条件查询
多条件查询允许同时使用多个查询条件来过滤文档。在 Go 中,可以使用 BoolQuery 来执行多条件查询。
import ("context""fmt""github.com/elastic/go-elasticsearch/v7""github.com/elastic/go-elasticsearch/v7/esapi"
)func main() {es, _ := elasticsearch.NewDefaultClient()var buf bytes.Bufferquery := map[string]interface{}{"query": map[string]interface{}{"bool": map[string]interface{}{"must": []map[string]interface{}{ // 所有子条件必须匹配{"match": {"name": "John"}},{"range": {"age": {"gte": 30}}},},"should": []map[string]interface{}{ // 至少有一个子条件匹配{"match_phrase_prefix":{"description":"quick brown fox"}},{"term":{"is_published":true}},},"must_not": []map[string]interface{}{ // 所有子条件都不匹配{"match": {"gender": "female"}},},},},}if err := json.NewEncoder(&buf).Encode(query); err != nil {log.Fatalf("Error encoding query: %s", err)}res, err := es.Search(es.Search.WithContext(context.Background()),es.Search.WithIndex("my-index"),es.Search.WithBody(&buf),es.Search.WithTrackTotalHits(true),es.Search.WithPretty(),)if err != nil {log.Fatalf("Error getting response: %s", err)}
}以上是 Elasticsearch 中常见的查询类型和 Go 客户端库中对应的使用方法。可以根据具体需求来选择合适的查询类型和选项来搜索和过滤文档。
七,es 中文分词,聚合查询
在 Elasticsearch 中,中文分词和聚合查询是非常常见的功能。以下是如何在 Go 中使用官方客户端库实现这些功能:
中文分词
Elasticsearch 默认支持中文分词器,可以使用 ik_max_word 或 ik_smart 分词器来处理中文字段。在 Go 中,可以通过 mapping 来指定字段的类型和分词器。
import ("context""fmt""github.com/elastic/go-elasticsearch/v7""github.com/elastic/go-elasticsearch/v7/esapi"
)func main() {es, _ := elasticsearch.NewDefaultClient()var mapping = `{"mappings": {"properties": {"content": {"type": "text","analyzer": "ik_max_word" // 使用 ik_max_word 分词器}}}}`res, err := es.Indices.Create([]string{"my-index"},es.Indices.Create.WithBody(strings.NewReader(mapping)),es.Indices.Create.WithPretty(),)if err != nil {log.Fatalf("Error creating index: %s", err)}
}然后,在执行查询时,可以使用 MatchQuery 或其他查询类型来搜索包含指定关键字的文档。
var buf bytes.Buffer
query := map[string]interface{}{"query": map[string]interface{}{"match": map[string]interface{}{"content": "中国",},},
}
if err := json.NewEncoder(&buf).Encode(query); err != nil {log.Fatalf("Error encoding query: %s", err)
}res, err := es.Search(es.Search.WithContext(context.Background()),es.Search.WithIndex("my-index"),es.Search.WithBody(&buf),es.Search.WithTrackTotalHits(true),es.Search.WithPretty(),
)
if err != nil {log.Fatalf("Error getting response: %s", err)
}聚合查询
聚合查询是对搜索结果进行分组、统计和分析的一种功能。在 Go 中,可以使用 Aggregations 和 Bucket 来执行聚合查询。
var buf bytes.Buffer
query := map[string]interface{}{"size": 0,"aggs": map[string]interface{}{"group_by_category": map[string]interface{}{"terms": map[string]interface{}{"field": "category",},},"stats_on_price": map[string]interface{}{"stats": map[string]interface{}{"field": "price",},},},
}
if err := json.NewEncoder(&buf).Encode(query); err != nil {log.Fatalf("Error encoding query: %s", err)
}res, err := es.Search(es.Search.WithContext(context.Background()),es.Search.WithIndex("my-index"),es.Search.WithBody(&buf),es.Search.WithTrackTotalHits(true),
)
if err != nil {log.Fatalf("Error getting response: %s", err)
}defer res.Body.Close()
var r map[string]interface{}
if err := json.NewDecoder(res.Body).Decode(&r); err != nil {log.Printf("Error parsing the response body: %s", err)
} else {// 处理聚合结果groupByCategoryBuckets := r["aggregations"].(map[string]interface{})["group_by_category"].(map[string]interface{})["buckets"].([]interface{})for _, bucket := range groupByCategoryBuckets {key := bucket.(map[string]interface{})["key"]docCount := bucket.(map[string]interface{})["doc_count"]fmt.Printf("%s: %d\n", key, docCount)}statsOnPrice := r["aggregations"].(map[string]interface{})["stats_on_price"].(map[string]interface{})count := statsOnPrice["count"]min := statsOnPrice["min"]max := statsOnPrice["max"]avg := statsOnPrice["avg"]sum := statsOnPrice["sum"]fmt.Printf("count: %v, min: %v, max: %v, avg: %v, sum: %v\n", count, min, max, avg, sum)
}以上是在 Go 中使用官方 Elasticsearch 客户端库执行中文分词和聚合查询的示例。可以根据具体需求来选择合适的分词器和聚合查询选项。
八,es go驱动包操作,索引以及文档操作
在 Go 中,可以使用官方 Elasticsearch 客户端库来进行索引和文档操作。
创建索引
创建一个新的索引,需要指定名称和映射。以下是一个示例:
import ("context""fmt""github.com/elastic/go-elasticsearch/v7"
)func main() {es, _ := elasticsearch.NewDefaultClient()mapping := `{"mappings": {"properties": {"name": { "type": "text" },"age": { "type": "integer" }}}}`res, err := es.Indices.Create([]string{"my-index"},es.Indices.Create.WithBody(strings.NewReader(mapping)),es.Indices.Create.WithContext(context.Background()),)if err != nil {log.Fatalf("Error creating index: %s", err)}defer res.Body.Close()fmt.Println("Index created")
}删除索引
删除一个已存在的索引,只需要指定名称即可。以下是一个示例:
res, err := es.Indices.Delete([]string{"my-index"},es.Indices.Delete.WithContext(context.Background()),
)if err != nil {log.Fatalf("Error deleting index: %s", err)
}defer res.Body.Close()fmt.Println("Index deleted")添加文档
向指定的索引中添加文档,需要指定文档 ID 和文档内容。以下是一个示例:
doc := `{"name": "John","age": 30
}`res, err := es.Index("my-index",strings.NewReader(doc),es.Index.WithDocumentID("1"),es.Index.WithContext(context.Background()),
)if err != nil {log.Fatalf("Error indexing document: %s", err)
}defer res.Body.Close()fmt.Println("Document added")获取文档
从指定的索引中获取文档,需要指定文档 ID。以下是一个示例:
res, err := es.Get("my-index","1",es.Get.WithContext(context.Background()),
)if err != nil {log.Fatalf("Error getting document: %s", err)
}defer res.Body.Close()var r map[string]interface{}if err := json.NewDecoder(res.Body).Decode(&r); err != nil {log.Fatalf("Error parsing the response body: %s", err)
}doc := r["_source"].(map[string]interface{})fmt.Printf("Name: %s, Age: %d\n", doc["name"], int(doc["age"].(float64)))更新文档
更新一个已存在的文档,需要指定文档 ID 和更新内容。以下是一个示例:
updateDoc := `{"doc": {"age": 35}
}`res, err := es.Update("my-index","1",strings.NewReader(updateDoc),es.Update.WithContext(context.Background()),
)if err != nil {log.Fatalf("Error updating document: %s", err)
}defer res.Body.Close()fmt.Println("Document updated")以上是在 Go 中使用官方 Elasticsearch 客户端库进行索引和文档操作的一些示例。可以根据具体需求来选择合适的选项和参数。
九,es 高级查询:term,match,aggregation
在 Go 中,可以使用官方 Elasticsearch 客户端库来进行高级查询,包括 term、match 和聚合操作。
Term 查询
Term 查询是一个完全匹配的查询。它查找指定字段中包含指定值的文档。以下是一个示例:
import ("context""fmt""github.com/elastic/go-elasticsearch/v7"
)func main() {es, _ := elasticsearch.NewDefaultClient()var buf bytes.Bufferquery := map[string]interface{}{"query": map[string]interface{}{"term": map[string]string{"name.keyword": "John",},},}if err := json.NewEncoder(&buf).Encode(query); err != nil {log.Fatalf("Error encoding query: %s", err)}res, err := es.Search(es.Search.WithContext(context.Background()),es.Search.WithIndex("my-index"),es.Search.WithBody(&buf),es.Search.WithTrackTotalHits(true),es.Search.WithPretty(),)if err != nil {log.Fatalf("Error searching for documents: %s", err)}defer res.Body.Close()var r map[string]interface{}if err := json.NewDecoder(res.Body).Decode(&r); err != nil {log.Fatalf("Error parsing the response body: %s", err)}totalHits := int(r["hits"].(map[string]interface{})["total"].(map[string]interface{})["value"].(float64))fmt.Printf("Found %d documents\n", totalHits)
}Match 查询
Match 查询会根据查询条件对指定字段进行分词并搜索匹配的文档。以下是一个示例:
var buf bytes.Buffer
query := map[string]interface{}{"query": map[string]interface{}{"match": map[string]string{"name": "John",},},
}if err := json.NewEncoder(&buf).Encode(query); err != nil {log.Fatalf("Error encoding query: %s", err)
}res, err := es.Search(es.Search.WithContext(context.Background()),es.Search.WithIndex("my-index"),es.Search.WithBody(&buf),es.Search.WithTrackTotalHits(true),es.Search.WithPretty(),
)if err != nil {log.Fatalf("Error searching for documents: %s", err)
}defer res.Body.Close()var r map[string]interface{}if err := json.NewDecoder(res.Body).Decode(&r); err != nil {log.Fatalf("Error parsing the response body: %s", err)
}totalHits := int(r["hits"].(map[string]interface{})["total"].(map[string]interface{})["value"].(float64))fmt.Printf("Found %d documents\n", totalHits)Aggregation
聚合操作可以对搜索结果进行统计和分析,例如计算平均值、最大值等。以下是一个示例:
var buf bytes.Buffer
aggQuery := map[string]interface{}{"aggs": map[string]interface{}{"avg_age": map[string]interface{}{"avg": map[string]interface{}{"field": "age",},},},
}
query := map[string]interface{}{"size": 0,
}
query["aggs"] = aggQueryif err := json.NewEncoder(&buf).Encode(query); err != nil {log.Fatalf("Error encoding query: %s", err)
}res, err := es.Search(es.Search.WithContext(context.Background()),es.Search.WithIndex("my-index"),es.Search.WithBody(&buf),es.Search.WithTrackTotalHits(true),es.Search.WithPretty(),
)if err != nil {log.Fatalf("Error searching for documents: %s", err)
}defer res.Body.Close()var r map[string]interface{}if err := json.NewDecoder(res.Body).Decode(&r); err != nil {log.Fatalf("Error parsing the response body: %s", err)
}aggResult := r["aggregations"].(map[string]interface{})["avg_age"].(map[string]interface{})
avgAge := aggResult["value"].(float64)fmt.Printf("Average age is %f\n", avgAge)以上是在 Go 中使用官方 Elasticsearch 客户端库进行 term、match 和聚合操作的一些示例。可以根据具体需求来选择合适的选项和参数。
相关文章:
)
在CSDN学Golang分布式中间件(ElasticSearch)
一,倒排索引,lucene 倒排索引是一种用于快速查找文本中特定单词或短语的数据结构。它将文本中的每个单词或短语与包含该单词或短语的文档列表相关联。这使得可以轻松地查找包含给定单词或短语的所有文档。 在 Go 中,可以使用 map 和 slice 来…...
web-文件包含
产生原因: 开发人员都希望代码更加灵活,所以通常会将被包含的文件设置为变量,用来进行动态调用。正是这种灵活性,从而导致客户端可以调用一个恶意文件,造成文件包含漏洞。 实际上被包含文件可以是任意格式的࿰…...

20230724----重返学习-vue3知乎日报项目实战
day-119-one-hundred-and-nineteen-20230724-vue3知乎日报项目实战 vue3项目实战-知乎日报 主要问题 pinia 和 vuex4 的区别 vue/cli和vite的区别 vue/cli脚手架的底层核心是webpack。vite脚手架: 开发环境:基于ESModule模块规范处理的生产环境&#…...

1.react useState使用与常见问题
文章目录 0. 取消批处理合并更新, render 2次1. 合并更新,setCount(异步更新) 3次相当于1次, count值为12. 如何取消批处理合并,让值累加?,改为回调函数写法,内部会依次执行函数, 执行3次 count值为33. 异步更新,获取异步更新的值?useEffect4.利用扩展运算符的形式来解决对象…...

LLaMA2可商用|GPT-4变笨|【2023-0723】【第七期】
一、大咖观点: 傅盛:ChatGPT时代如何创业 - BOTAI - 博客园Google 已经被OpenAI 超越了吗?| AlphaGo 之父深度访谈《人民日报》:大模型的竞争,是国家科技战略的竞争WAIC 2023 | 张俊林:大语言模型带来的交…...
[SQL系列] 从头开始学PostgreSQL 自增 权限和时间
[SQL系列] 从头开始学PostgreSQL 事务 锁 子查询_Edward.W的博客-CSDN博客https://blog.csdn.net/u013379032/article/details/131841058上一篇介绍了事务,锁,子查询 事务有点像是原子操作,需要有完整性,要么全都完成了ÿ…...

【云原生】Kubernetes之Secret
使用 kubectl 管理 Secret 准备开始 你必须拥有一个 Kubernetes 的集群,同时你必须配置 kubectl 命令行工具与你的集群通信 创建 Secret Secret 对象用来存储敏感数据,如 Pod 用于访问服务的凭据。例如,为访问数据库,你可能需…...
细说小程序底部标签---【浅入深出系列006】
微信目录集链接在此: 详细解析黑马微信小程序视频–【思维导图知识范围】难度★✰✰✰✰ 不会导入/打开小程序的看这里:参考 让别人的小程序长成自己的样子-更换window上下颜色–【浅入深出系列001】 文章目录 本系列校训学习资源的选择 学习语法的前…...

【VUE】使用elementUI上传组件-提示不存在
使用elementUI上传组件上传图片后,表单验证还是提示不存在 主要是因为组件包的层级比较深,验证取不到值导致 可以通过绑定其他元素获取到值进行验证 比如增加el-checkbox-group元素,将值绑定到它上面 <el-form :model"Form" …...

Flutter Windows通过嵌入Native窗口实现渲染视频
Flutter视频渲染系列 第一章 Android使用Texture渲染视频 第二章 Windows使用Texture渲染视频 第三章 Linux使用Texture渲染视频 第四章 全平台FFICustomPainter渲染视频 第五章 Windows使用Native窗口渲染视频(本章) 文章目录 Flutter视频渲染系列前言…...

MySQL学习笔记 ------ 库和表的管理
#DDL /* 数据定义语言 库和表的管理 一、库的管理 创建、修改、删除 二、表的管理 创建、修改、删除 创建: create 修改: alter 删除: drop */ #一、库的管理 #1、库的创建 /* 语法: create database [if not exists]库名;…...

python中去除字符串中指定的字符
去除字符串中特定字符(但是只能删除头、尾指定字符): a 你好\n我是xx。\n\n\n print(a.strip(\n))# 你好 # 我是xx。 去除中间字符,可使用replace()函数: a 你好\n我是xx。\n\n\n print(a.replace(\n, ))# 你好我…...

Java实现商品ID获取京东商品详情Desc商品描述数据方法
要通过京东的API获取商品详情商品描述,您可以使用京东开放平台提供的接口来实现。以下是一种使用Java编程语言实现的示例,展示如何通过京东开放平台API获取商品详情: 首先,确保您已注册成为京东开放平台的开发者,并创…...

1-高性能计算研究
高性能计算研究 E级计算机系统研制高性能计算应用软件研发并行编程框架应用协同开发优化平台和工具软件示例 高性能计算环境研发 E级计算机系统研制 高性能互联计算、编程、运行模型 应用驱动的新型可扩展基础算法(适用于E级计算的可计算物理建模与新型计算方法&a…...
swagger快速升级方案
背景 在使用SpringBoot 2.6以前去创建API文档工具一般会采用SpringFox提供的Swagger库,但是由于SpringBoot版本的不断升级和SpringFox摆烂不更新,导致了SpringBoot2.6之后的项目无法使用SpringFox去生成API文档,或者可以使用但是有很多的bug…...
sql中with as用法/with-as 性能调优/with用法
文章目录 一、概述二、基本语法三、使用场景3.1、定义CTE,并为每列重命名3.2、多次引用/多次定义3.3、with与union all联合使用3.4、with返回多种结果的值3.5、with与insert使用 四、递归查询4.1、语法4.2、使用场景4.2.1、用with递归构造1-10的数据4.2.2、with与insert递归造数…...
大数据课程C5——ZooKeeper的应用组件
文章作者邮箱:yugongshiyesina.cn 地址:广东惠州 ▲ 本章节目的 ⚪ 掌握Zookeeper的Canal消费组件; ⚪ 掌握Zookeeper的Dubbo分布式服务框架; ⚪ 掌握Zookeeper的Metamorphosis消息中间件; ⚪ 掌握Zo…...
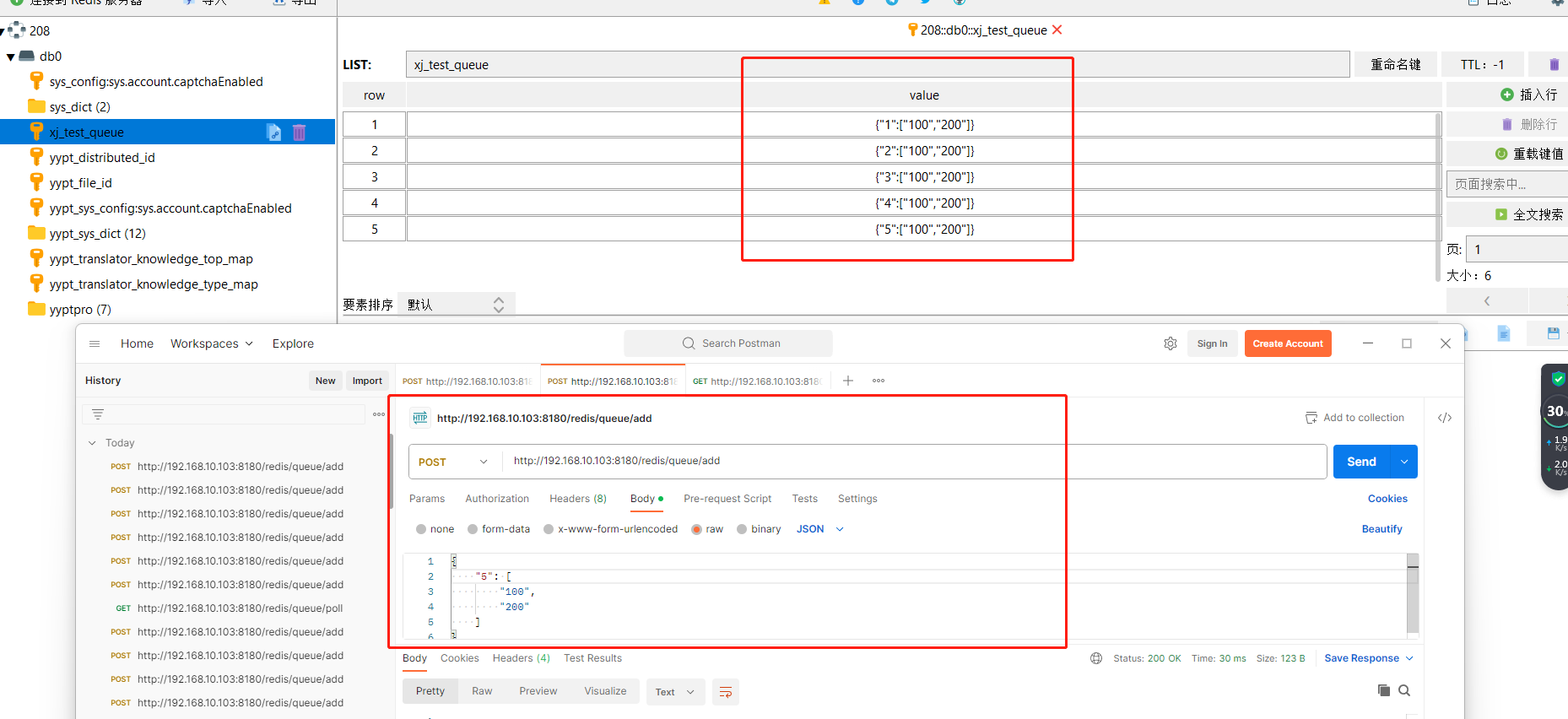
Redisson实现简单消息队列:优雅解决缓存清理冲突
在项目中,缓存是提高应用性能和响应速度的关键手段之一。然而,当多个模块在短时间内发布工单并且需要清理同一个接口的缓存时,容易引发缓存清理冲突,导致缓存失效的问题。为了解决这一难题,我们采用Redisson的消息队列…...

php-golang-rpc 简单的jsonrpc实践
golang代码: package main import ( "net" "net/rpc" "net/rpc/jsonrpc" ) type App struct{} type Res struct { Code int json:"code" Msg string json:"msg" Data any json:"data" } fun…...

Apipost变量高亮展示,变量操作更流畅
之前Apipost配置的各种环境变量只能在右上角环境管理中查看,很多小伙伴希望能有一种更好的解决方案用以快速复制变量值,快速查看变量的当前值和初始值,于是在Apipost 7.1.7中我们推出环境变量高亮展示功能来满足用户的使用需求。 功能描述&a…...

DeepSeek代码质量评估实战手册:7步完成从混沌到可度量的质变跃迁
更多请点击: https://kaifayun.com 第一章:DeepSeek代码质量评估的底层逻辑与核心价值 DeepSeek代码质量评估并非简单地统计行数或检测语法错误,而是基于多维语义理解构建的推理系统。其底层逻辑融合了静态分析、符号执行与大语言模型生成式…...

Office RibbonX Editor:让Office界面定制变得像搭积木一样简单
Office RibbonX Editor:让Office界面定制变得像搭积木一样简单 【免费下载链接】office-ribbonx-editor An overhauled fork of the original Custom UI Editor for Microsoft Office, built with WPF 项目地址: https://gitcode.com/gh_mirrors/of/office-ribbon…...

基于双T振荡器的正弦波LED调光电路设计与实践
1. 项目概述:用双T振荡器实现正弦波LED调光最近在捣鼓一些氛围灯项目,总感觉用单片机PWM做的呼吸灯效果有点“硬”,那种线性的明暗变化看久了难免审美疲劳。于是翻出以前模拟电路的老本行,琢磨着能不能用纯硬件的方式,…...

保姆级教程:在Ubuntu上配置Frida环境,搞定Android App的IO重定向与签名绕过
在Ubuntu上构建Android逆向工程环境:Frida实战与IO重定向技术解析 对于习惯Linux环境的安全研究人员而言,Windows-centric的逆向工具链往往带来诸多不便。本文将系统性地介绍如何在Ubuntu上搭建完整的Android逆向环境,并深入探讨如何利用Frid…...

对比按量计费与Token Plan套餐的实际成本差异
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比按量计费与Token Plan套餐的实际成本差异 在构建和运营基于大模型的应用时,成本控制是一个核心的工程考量。Taotok…...

基于KS距离度量交通流分布偏移:提升DRL交通信号控制鲁棒性的工程实践
1. 项目概述与核心挑战在智能交通系统(ITS)领域,基于深度强化学习(DRL)的交通信号控制(Traffic Signal Control)正从研究走向实际部署。作为一名长期关注AI落地应用的从业者,我见过太…...

从零到远程:手把手教你用Electerm搞定Ubuntu Server的SSH连接与防火墙配置
从零到远程:手把手教你用Electerm搞定Ubuntu Server的SSH连接与防火墙配置当你第一次面对Ubuntu Server时,最迫切的需求可能就是如何安全地远程管理它。作为运维新手或开发者,掌握SSH连接和防火墙配置是进入Linux世界的第一道门槛。本文将带你…...

在ubuntu上为node.js后端服务接入taotoken统一大模型api
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在 Ubuntu 上为 Node.js 后端服务接入 Taotoken 统一大模型 API 为后端服务集成大模型能力已成为提升应用智能水平的关键步骤。对于…...

5大核心功能掌握HandheldCompanion:Windows掌机终极控制伴侣
5大核心功能掌握HandheldCompanion:Windows掌机终极控制伴侣 【免费下载链接】HandheldCompanion ControllerService 项目地址: https://gitcode.com/gh_mirrors/ha/HandheldCompanion 你是否正在寻找一款能够彻底改变Windows掌机游戏体验的控制软件…...
)
【独家首发】DeepSeek边缘计算白皮书未公开章节:3类典型场景QoS SLA保障公式(含实测RTT抖动衰减模型)
更多请点击: https://intelliparadigm.com 第一章:DeepSeek边缘计算架构全景概览 DeepSeek边缘计算架构以“轻量、协同、自治”为核心设计理念,面向AI推理密集型场景构建端—边—云三级协同的分布式智能执行体。该架构并非传统云中心化模型的…...