【LangChain】检索器之MultiQueryRetriever
MultiQueryRetriever
- 概要
- 内容
- 总结
概要
基于距离的向量数据库检索在高维空间中嵌入查询,并根据“距离”查找相似的嵌入文档。
但是,如果查询措辞发生细微变化,或者嵌入不能很好地捕获数据的语义,检索可能会产生不同的结果。有时需要进行及时的工程/调整来手动解决这些问题,但这可能很乏味。
MultiQueryRetriever 通过使用 LLM 从不同角度为给定的用户输入查询生成多个查询,从而自动执行提示调整过程。对于每个查询,它都会检索一组相关文档,并采用所有查询之间的唯一并集来获取更大的一组潜在相关文档。通过对同一问题生成多个视角,MultiQueryRetriever 或许能够克服基于距离的检索的一些限制,并获得更丰富的结果集。
小节下:同一个问题,生成多个角度的问题。
内容
# 构建示例向量数据库
from langchain.vectorstores import Chroma
from langchain.document_loaders import WebBaseLoader
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter# 加载博客文章
loader = WebBaseLoader("https://lilianweng.github.io/posts/2023-06-23-agent/")
data = loader.load()# 拆分
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=0)
splits = text_splitter.split_documents(data)# 向量数据库
embedding = OpenAIEmbeddings()
vectordb = Chroma.from_documents(documents=splits, embedding=embedding)
简单使用:
指定用于查询生成的 LLM,检索器将完成其余的工作。
from langchain.chat_models import ChatOpenAI
from langchain.retrievers.multi_query import MultiQueryRetriever
# 问题
question = "What are the approaches to Task Decomposition?"
# 创建大模型:用于生成内容
llm = ChatOpenAI(temperature=0)
retriever_from_llm = MultiQueryRetriever.from_llm(retriever=vectordb.as_retriever(), llm=llm
)
# 设置查询的日志记录
import logginglogging.basicConfig()
logging.getLogger("langchain.retrievers.multi_query").setLevel(logging.INFO)
# 开始检索
unique_docs = retriever_from_llm.get_relevant_documents(query=question)
# 获取生成内容的文档长度
len(unique_docs)
结果:
INFO:langchain.retrievers.multi_query:Generated queries: ['1. How can Task Decomposition be approached?', '2. What are the different methods for Task Decomposition?', '3. What are the various approaches to decomposing tasks?']
您还可以提供提示和输出解析器,以将结果拆分为查询列表。
from typing import List
from langchain import LLMChain
from pydantic import BaseModel, Field
from langchain.prompts import PromptTemplate
from langchain.output_parsers import PydanticOutputParser# 输出解析器会将 LLM 结果拆分为查询列表
class LineList(BaseModel):# “lines”是解析输出的键(属性名称)lines: List[str] = Field(description="Lines of text")class LineListOutputParser(PydanticOutputParser):def __init__(self) -> None:super().__init__(pydantic_object=LineList)def parse(self, text: str) -> LineList:lines = text.strip().split("\n")return LineList(lines=lines)output_parser = LineListOutputParser()QUERY_PROMPT = PromptTemplate(input_variables=["question"],template="""你是一名AI语言模型助手。你的任务是生成五个
给定用户问题的不同版本,用于从向量中检索相关文档
数据库。通过对用户问题产生多种观点,您的目标是帮助
用户克服了基于距离的相似性搜索的一些限制。
提供这些替代问题,并用换行符分隔。Original question: {question}""",
)
llm = ChatOpenAI(temperature=0)# Chain
llm_chain = LLMChain(llm=llm, prompt=QUERY_PROMPT, output_parser=output_parser)# Other inputs
question = "任务分解的方法有哪些?"
# 执行
retriever = MultiQueryRetriever(retriever=vectordb.as_retriever(), llm_chain=llm_chain, parser_key="lines"
) # “lines”是解析输出的键(属性名称)# 结果
unique_docs = retriever.get_relevant_documents(query="课程中关于回归的内容是怎样的?"
)
# 文档数量
len(unique_docs)
结果:
INFO:langchain.retrievers.multi_query:Generated queries: ["1. 该课程对回归的看法是什么?", '2. 您能否提供课程中讨论的有关回归的信息?', '3. 课程如何涵盖回归主题?', "4. 该课程关于回归的教学内容是什么?", '5. 关于课程,提到了回归?']11
总结
现在的搜索,其实是基于向量库的检索,本质上是距离的检索。而我们搜索的措辞的微妙变化,会产生不同的结果,这需要我们手动调整,这个工作枯燥乏味。
MultiQueryRetriever,可以基于你给出的问题,生成多个相关问题。通过生成多角度问题,来自动调整这种微妙的措施变化。
MultiQueryRetriever的使用步骤:
- 加载文档:
loader = WebBaseLoader("https://lilianweng.github.io/posts/2023-06-23-agent/") data = loader.load() - 初始化拆分器:
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=0) splits = text_splitter.split_documents(data) - 构建嵌入:
embedding = OpenAIEmbeddings() - 构建向量存储库:
vectordb = Chroma.from_documents(documents=splits, embedding=embedding) - 指定
llm:llm = ChatOpenAI(temperature=0) - 得到MultiQueryRetriever:
retriever_from_llm = MultiQueryRetriever.from_llm( retriever=vectordb.as_retriever(), llm=llm ) - 得到多角度问题:
unique_docs = retriever_from_llm.get_relevant_documents(query=question) len(unique_docs)
参考地址:
https://python.langchain.com/docs/modules/data_connection/retrievers/how_to/MultiQueryRetriever
相关文章:

【LangChain】检索器之MultiQueryRetriever
MultiQueryRetriever 概要内容总结 概要 基于距离的向量数据库检索在高维空间中嵌入查询,并根据“距离”查找相似的嵌入文档。 但是,如果查询措辞发生细微变化,或者嵌入不能很好地捕获数据的语义,检索可能会产生不同的结果。有时…...

教师ChatGPT的23种用法
火爆全网的ChatGPT,作为教师应该如何正确使用?本文梳理了教师ChatGPT的23种用法,一起来看看吧! 1、回答问题 ChatGPT可用于实时回答问题,使其成为需要快速获取信息的学生的有用工具。 从这个意义上说,Cha…...

【libevent】http客户端1:转存http下载的数据
read_http_input // // HTTP endpoint: GET /rpc/1 (list methods) or POST /rpc/1 (execute RPC) // // JSON-RPC API endpoint. Handles all JSON-RPC method calls. // static void rpc_jsonrpc(evhttp_request *req, void *opaque) {RpcApiInfo *ap =...
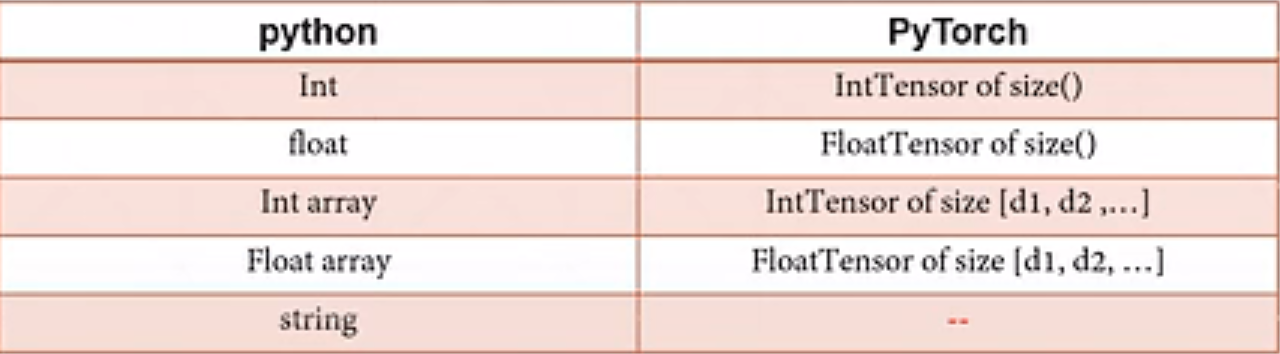
Pytorch学习笔记 | 数据类型 | mnist数据集
数据类型 python中数据类型和pytorch中的对应关系 注意:pytorch是没有没有string类型的 例1:创建一个3行4列的随机数数组,符合均值为0,方差为1的正态分布 import torch a=torch.Tensor(3,4) a Out[17]: tensor([[0....
Linux虚拟机(lvm)报Unmount and run xfs_repair
问题 linux系统没有正常关机,今天启动虚拟机无法进入系统,提示metadata corruption deleted at xxxx; Unmount and run xfs_repair 分析 主机异常掉电后里面的虚拟机无法启动,主要是损坏的分区 解决 看出来应该是dm-0分区损坏…...
【ESP32】Espressif-IDE及ESP-IDF安装
一、下载Espressif-IDE 2.10.0 with ESP-IDF v5.0.2 1.打开ESP-IDF 编程指南 2.点击快速入门–>安装–>手动安装–>Windows Installer–>Windows Installer Download 3.点击下载Espressif-IDE 2.10.0 with ESP-IDF v5.0.2 二、安装Espressif-IDE 2.10.0 wit…...

基于vue3实现画布操作的撤销与重做
基于vue3实现画布操作的撤销与重做 前言 vue3项目中实现在canvas画布上实现画节点和连线功能,要求可以撤销重做 思路 canvasBox 画板数据是存放在对象里面; snapshots存放操作记录; curIndex表示当前操作索引的下标; maxLimit表…...

php 抽象工厂模式
1,抽象工厂(Abstract Factory)模式,是创建设计模式的一种,它创建一系列相关的对象,而不必指定具体的类。该模式为一个产品族提供了统一的创建接口。当需要这个产品族的某一系列的时候,可以为此系…...

WPF实战学习笔记13-创建注册登录接口
创建注册登录接口 添加文件 创建文件 MyToDo.Api ./Controllers/LoginController.cs ./Service/ILoginService.cs ./Service/LoginService.cs MyToDo.Share ./Dtos/UserDto.cs LoginController.cs using Microsoft.AspNetCore.Mvc; using MyToDo.Api.Context;…...

银行API安全解决方案
数字经济背景下,外部市场环境的快速变化给商业银行带来很多不确定性,随着银行行业数字化转型进入深水区,银行经营面临新的机遇和挑战。 数字经济是传统银行向开放银行转型发展的重要支撑,开放银行旨在运用数字技术通过开放数据和…...

3d软件动物生活习性仿真互动教学有哪些优势
软体动物是一类广泛存在于海洋和淡水环境中的生物,其独特的形态和生活习性给学生带来了新奇和有趣的学习主题,为了方便相关专业学科日常授课教学,web3d开发公司深圳华锐视点基于真实的软体动物,制作软体动物3D虚拟展示系统&#x…...

<C语言> 字符串内存函数
C语言中对字符和字符串的处理很是频繁,但是C语言本身是没有字符串类型的,字符串通常放在常量字符串或者字符数组中。 字符串常量 适用于那些对它不做修改的字符串函数. 注意:字符串函数都需要包含头文件<string.h> 1.长度不受限制的…...
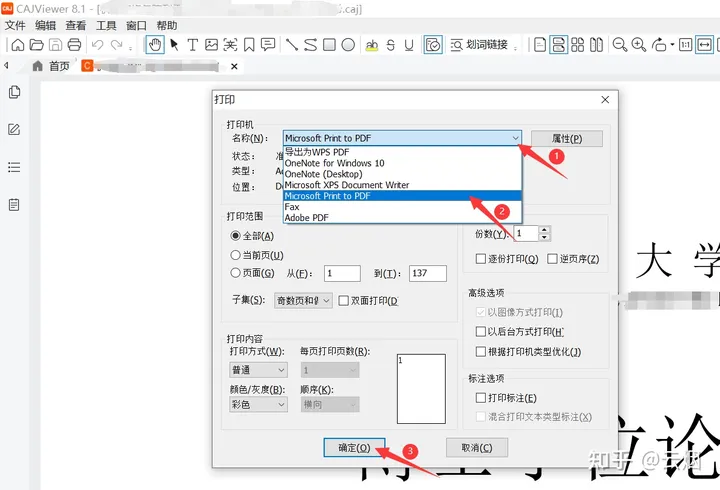
知网的caj格式怎么转化成pdf格式?两个方法简单快捷!
在使用知网等学术资源时,我们常常会遇到CAJ格式的文件,然而CAJ格式并不是常见的文件格式,给我们的查阅和分享带来一些不便。为了更方便地处理这些文件,我们可以将其转换为常见的PDF格式。在本文中,我将为您介绍两种简单…...

【每日一题】2500. 删除每行中的最大值
【每日一题】2500. 删除每行中的最大值 2500. 删除每行中的最大值题目描述解题思路 2500. 删除每行中的最大值 题目描述 给你一个 m x n 大小的矩阵 grid ,由若干正整数组成。 执行下述操作,直到 grid 变为空矩阵: 从每一行删除值最大的元…...
)
通俗解释什么是(ip、网段、端口)
通俗解释什么是(ip、网段、端口) 1:什么是IP? IP地址被用来给Internet上的电脑一个编号。IP地址是一个32位的二进制数,通常被分割为4个“8位二进制数”(也就是4个字节),IP地址通常…...

PyTorch quantization observer
文章目录 PyTorch quantization observerbasic classstandard observersubstandard observer PyTorch quantization observer basic class nameinheritdescribeObserverBaseABC, nn.ModuleBase observer ModuleUniformQuantizationObserverBaseObserverBase standard observ…...
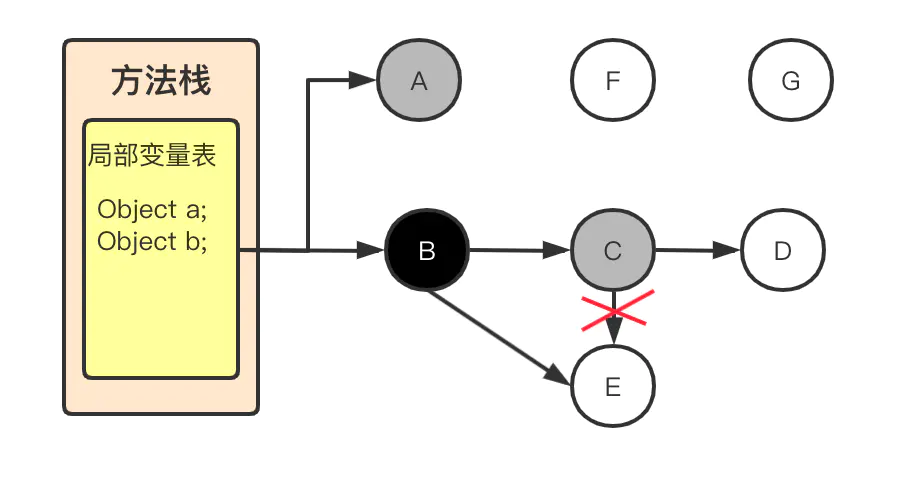
垃圾回收之三色标记法(Tri-color Marking)
关于垃圾回收算法,基本就是那么几种:标记-清除、标记-复制、标记-整理。在此基础上可以增加分代(新生代/老年代),每代采取不同的回收算法,以提高整体的分配和回收效率。 无论使用哪种算法,标记…...
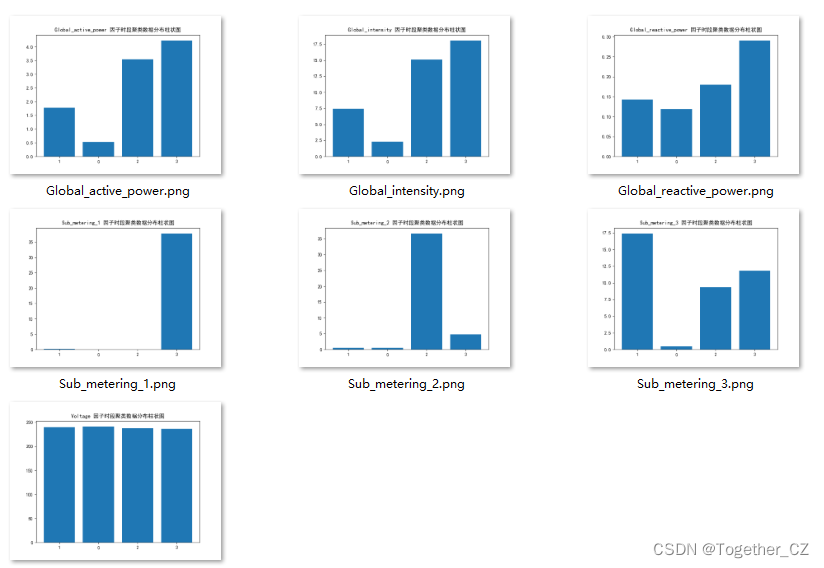
Individual household electric power consumption个人家庭用电量数据挖掘与时序预测建模
今天接到一个任务就是需要基于给定的数据集来进行数据挖掘分析相关的计算,并完成对未来时段内数据的预测建模,话不多少直接看内容。 官方数据详情介绍在这里,如下所示: 数据集中一共包含9个不同的字段,详情如下&#…...
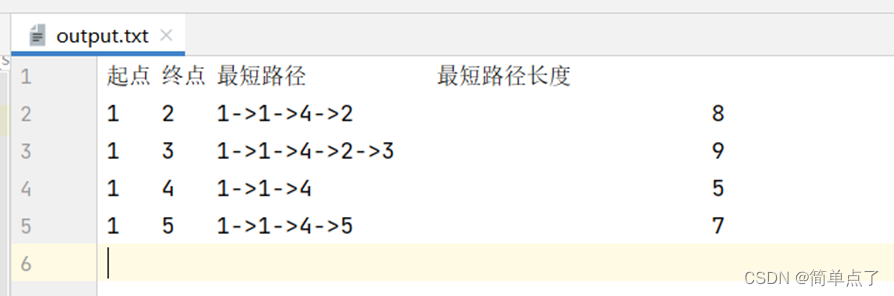
实验三 贪心算法
实验三 贪心算法 迪杰斯特拉的贪心算法实现 优先队列等 1.实验目的 1、掌握贪心算法的基本要素 :最优子结构性质和贪心选择性质 2、应用优先队列求单源顶点的最短路径Dijkstra算法,掌握贪心算法。 2.实验环境 Java 3.问题描述 给定带权有向图G (V…...
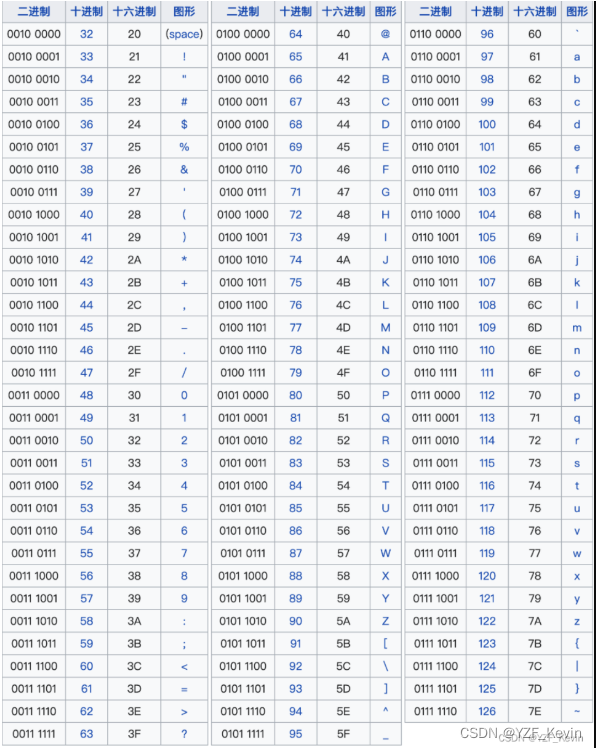
详解go的hex.Encode原理
简言 今天看nsq的messageID生成的时候,发现它使用了hex.Encode函数来产生编码,那就顺道研究一下这个编码方式。 原理 hex是16进制的意思,encode是进行编码的意思,内部实现也很简单,就是 每4位计算出十六进制的值&a…...

机器学习结合基因无关通路映射:从临床数据挖掘新药靶点
1. 项目概述:当机器学习遇见代谢通路,如何从数据中“挖”出新药靶点?在生物医学研究的前沿,我们正面临一个核心矛盾:一方面,我们拥有海量的临床数据,比如血糖、血压、BMI等指标;另一…...

告别C盘战士!ArcGIS 10.6安装路径选择与磁盘空间优化全攻略
告别C盘战士!ArcGIS 10.6安装路径选择与磁盘空间优化全攻略当GIS初学者第一次安装ArcGIS 10.6时,往往会被其庞大的安装体积所震惊。许多用户习惯性地点击"下一步",结果发现C盘空间被迅速吞噬,系统运行变得迟缓。本文将深…...

告别FTP龟速:用NTFS-3G在CentOS7上直连移动硬盘拷贝200G大文件
告别FTP龟速:用NTFS-3G在CentOS7上直连移动硬盘拷贝200G大文件当面对数百GB的设计素材、日志文件或数据库备份需要迁移时,传统的FTP传输往往会成为效率瓶颈。我曾在一个视频处理项目中,需要将230GB的4K原始素材从移动硬盘导入服务器ÿ…...

BurpSuite 2025插件开发JDK版本兼容性实战指南
1. 为什么BurpSuite插件开发环境总在JDK版本上翻车?你是不是也经历过:下载好BurpSuite最新版2025.4,兴冲冲打开插件开发文档,照着官方示例写完第一个HelloWorld插件,一编译——java.lang.UnsupportedClassVersionError…...

美团外卖mtgsig与waimai_sign双层签名逆向解析
1. 这不是“爬虫教程”,而是一份反向工程现场笔记你搜到这篇内容,大概率正卡在某个调试窗口前:抓包看到mtgsig和waimai_sign两个参数像两堵墙,无论怎么改请求头、换UA、清缓存,返回永远是{"code":403,"…...

基于MaixCam的延时摄影系统:从硬件选型到Python编程全解析
1. 项目概述:用MaixCam打造你的专属延时摄影工坊延时摄影,这个听起来有点专业、甚至带点“魔法”色彩的词,其实离我们并不遥远。想想看,把一朵花从含苞到绽放的几天时间,压缩成十几秒的惊艳绽放;或者把一座…...

【MySQL数据库 | 第一篇】 概述
数据库相关概念: 数据库(Database):数据库是指一组有组织的数据的集合,通过计算机程序进行管理和访问。数据库管理系统:操纵和管理数据库的大型软件SQL:操作关系型数据库的编程语言,定义了一套操作关系型数…...

AI圈神秘领袖Ilya一幅画引爆全网,OpenAI三件大事暗示AGI时代将至?
AI圈神秘精神领袖Ilya在Instagram上传一幅画引发疯狂解读,与此同时,OpenAI连续公布数学成果、升级Codex、筹备IPO,释放AGI到来的强烈信号。Ilya画作引猜测Ilya上传的画中,罗丹的「思考者」踩在芯片Die Shot上,右下角签…...

机器学习驱动储氢材料发现:从特征工程到DFT/MD验证的完整指南
1. 项目概述与核心思路氢能被视为未来清洁能源体系的关键一环,但如何安全、高效、经济地储存氢气,一直是制约其大规模应用的瓶颈。在众多储氢技术路线中,固态储氢,特别是基于金属氢化物的储氢材料,因其高体积储氢密度和…...

终极Node.js Mock工具:Mockery入门到精通实战教程
终极Node.js Mock工具:Mockery入门到精通实战教程 【免费下载链接】mockery Simplifying the use of mocks with Node.js 项目地址: https://gitcode.com/gh_mirrors/mock/mockery Mockery是Node.js生态中简化Mock使用的终极工具,它为开发者提供了…...