<C语言> 字符串内存函数
C语言中对字符和字符串的处理很是频繁,但是C语言本身是没有字符串类型的,字符串通常放在常量字符串或者字符数组中。
字符串常量 适用于那些对它不做修改的字符串函数.
注意:字符串函数都需要包含头文件<string.h>
1.长度不受限制的字符串函数
1.1 strlen
strlen()函数用于计算字符串的长度,即字符串中字符的数量,不包括字符串结尾的空字符('\0')。字符串在C语言中是以字符数组的形式表示的,而字符串的结尾总是以空字符('\0')来标识字符串的结束。
strlen()函数的函数原型如下:
size_t strlen(const char *str);
其中,const char *str是一个指向字符数组的指针,表示要计算长度的字符串。size_t是C标准库中定义的无符号整数类型,用于表示数组的大小。
strlen()函数的工作方式是从传入的字符串的开头开始遍历,直到遇到字符串结尾的空字符('\0')为止,并返回遍历过程中经过的字符数量作为字符串的长度。
下面是一个使用strlen()函数的例子:
#include <stdio.h>
#include <string.h>
int main() {//a b c d e f \0char arr1[] = "abcdef";char arr2[] = { 'a','b','c','d' }; //err 随机的数字printf("%d\n", strlen(arr1));//6printf("%d\n", strlen(arr2));//随机的数字return 0;
}
arr2没有以'\0'结尾,strlen()函数会一直遍历直到遇到内存中的第一个空字符为止
注意:
#include <stdio.h>
#include <string.h>
int main() {if (strlen("abc") - strlen("abcdef") > 0)//strlen返回的是无符号整型,不会出现负数printf(">");elseprintf("<");return 0;
}
strlen()函数返回的是size_t类型,它是无符号整数类型。因此,不会出现负数。所以输出结果为>
模拟实现strlen
#include <assert.h>
#include <stdio.h>
#include <string.h>
size_t my_strlen(const char *str) {assert(str);//str!=NULLconst char *start = str;const char *end = str;while (*end != '\0') {end++;}return end - start;
}int main() {char arr[] = "abcdef";size_t len = my_strlen(arr);printf("%zu\n", len);return 0;
}
1.2 strcpy
strcpy()函数用于将一个字符串复制到另一个字符串数组中,包括字符串结尾的空字符('\0')。
strcpy()函数的函数原型如下:
char *strcpy(char *dest, const char *src);
其中,char *dest是目标字符串数组的指针,用于存储复制后的字符串;const char *src是源字符串的指针,表示要复制的字符串。
strcpy()函数的工作方式是从源字符串的开头开始,逐个复制字符到目标字符串,直到遇到源字符串的结尾空字符('\0')为止,同时在目标字符串末尾添加一个空字符('\0')来标识复制结束。
需要注意的是,目标字符串数组必须具有足够的空间来存储源字符串,否则可能导致缓冲区溢出,造成程序崩溃或安全漏洞。因此,在使用strcpy()函数时,应该确保目标字符串的长度足够大。
#include <stdio.h>
#include <string.h>
int main() {char arr[10] = "xxxxxxxxxx";//char arr[3]={ 0 }; //数组空间太小//char* p = "hello world"; //err 常量字符串地址const char *p = "hello world";strcpy(arr, p); printf("%s\n", arr); //hello worldreturn 0;
}
模拟实现strcpy
#include <assert.h>
#include <stdio.h>
#include <string.h>
char *my_strcpy(char *dest, const char *src) {assert(dest);//dest!=NULLassert(src);char *ret = dest;//dest会在下面循环时候改变 所以地址存放在ret中while (*dest++ = *src++) {//直到\0 赋值过去 表达式为假;}return ret;
}int main() {char arr1[20] = "abcdefefadw";char arr2[] = "hello world";printf("%s\n", my_strcpy(arr1, arr2));return 0;
}
1.3 strcat
strcat()函数用于将源字符串追加到目标字符串的末尾,包括字符串结尾的空字符('\0')。
strcat()函数的函数原型如下:
char *strcat(char *dest, const char *src);
其中,char *dest是目标字符串数组的指针,表示要将源字符串追加到的目标字符串;const char *src是源字符串的指针,表示要追加的字符串。
strcat()函数的工作方式是从目标字符串的结尾开始,逐个将源字符串中的字符复制到目标字符串末尾,直到遇到源字符串的结尾空字符('\0')。然后,在目标字符串的末尾添加一个空字符('\0')来标识新的字符串结尾。
需要注意的是,目标字符串数组必须具有足够的空间来存储源字符串追加后的结果,否则可能导致缓冲区溢出,造成程序崩溃或安全漏洞。因此,在使用strcat()函数时,应该确保目标字符串的长度足够大。
下面是一个使用strcat()函数的简单例子:
#include <stdio.h>
#include <string.h>int main() {char dest[20] = "Hello, ";const char *src = "World!";strcat(dest, src);printf("Concatenated string: %s\n", dest); //Concatenated string: Hello, World!return 0;
}
模拟实现strcat
#include <assert.h>
#include <stdio.h>
#include <string.h>
char *my_strcat(char *dest, const char *src) {//1.找目标空间的\0char *cur = dest;while (*dest != '\0') {dest++;}//2.拷贝源头数据到\0之后的空间while (*dest++ = *src++) {;}return cur;
}int main() {char arr1[20] = "hello \0xxxxx";char arr2[] = "world";printf("%s\n", my_strcat(arr1, arr2));return 0;
}
1.4 strcmp
strcmp()函数用于比较两个字符串,并根据字符串的大小关系返回一个整数值。
strcmp()函数的函数原型如下:
int strcmp(const char *str1, const char *str2);
其中,const char *str1和const char *str2是两个要比较的字符串的指针。
strcmp()函数的返回值有以下三种情况:
- 如果
str1和str2相等,返回值为0。 - 如果
str1小于str2,返回值为一个负整数(通常为-1)。 - 如果
str1大于str2,返回值为一个正整数(通常为1)。
strcmp()函数会按照字典顺序逐个比较字符串中的字符,直到遇到不同的字符或遇到两个字符串的结尾空字符('\0')为止。比较是按照字符的ASCII码值进行的,因此,字符串中字符的大小关系是按照它们在ASCII码表中的顺序来决定的。
下面是一个使用strcmp()函数的简单例子:
#include <stdio.h>
#include <string.h>int main() {const char *str1 = "apple";const char *str2 = "banana";int result = strcmp(str1, str2);if (result < 0) {printf("%s is less than %s\n", str1, str2);} else if (result > 0) {printf("%s is greater than %s\n", str1, str2);} else {printf("%s is equal to %s\n", str1, str2);}return 0;
}
//输出结果:apple is less than banana
strcmp()函数将字符串"apple"与字符串"banana"进行比较,因为'a'的ASCII码值比'b'小,所以"apple"被认为是小于"banana"。函数返回一个负整数(-1),表示str1小于str2。
模拟实现strcmp
#include <stdio.h>
int my_strcmp(const char* str1, const char* str2)
{assert(str1 && str2);while (*str1 == *str2){if (*str1 == '\0'){return 0;}str1++;str2++;}return *str1 - *str2; //比较的是ascall码值
}int main()
{char arr1[] = "abcdef";char arr2[] = "zabcdef";int ret = my_strcmp(arr1, arr2);if (ret < 0)printf("arr1<arr2\n");else if (ret > 0)printf("arr1>arr2\n");elseprintf("arr1==arr2\n");return 0;
}//输出结果:arr1<arr2
2.长度受限制的字符串函数
2.1 strncpy
strncpy()函数用于将源字符串的一部分复制到目标字符串中
strncpy()函数的函数原型如下:
char *strncpy(char *dest, const char *src, size_t n);
其中,char *dest是目标字符串数组的指针,表示要复制到的目标字符串;const char *src是源字符串的指针,表示要复制的字符串;size_t n表示要复制的最大字符数。
strncpy()函数的工作方式是从源字符串的开头开始,逐个将字符复制到目标字符串中,直到复制了n个字符或者遇到源字符串的结尾空字符('\0')为止。如果源字符串的长度小于n,那么目标字符串将在最后添加额外的空字符('\0')来填满n个字符。
需要注意的是,strncpy()函数不保证目标字符串以空字符结尾,如果复制的字符数达到了n,而源字符串还未结束,目标字符串将不会以空字符结尾。因此,在使用strncpy()函数时,应该注意目标字符串是否以空字符结尾。
下面是一个使用strncpy()函数的简单例子:
#include <stdio.h>
#include <string.h>
int main() {char arr1[20] = "abcdef";char arr2[] = "xxxx";strncpy(arr1, arr2, 2);//xxcdef 只拷贝2个字符//strncpy(arr1, arr2, 8); //xxxxprintf("%s\n", arr1);return 0;
}
2.2 strncat
strncat()函数用于将源字符串的前若干个字符追加到目标字符串的末尾
strncat()函数的函数原型如下:
char *strncat(char *dest, const char *src, size_t n);
其中,char *dest是目标字符串数组的指针,表示要将源字符串追加到的目标字符串;const char *src是源字符串的指针,表示要追加的字符串;size_t n表示要追加的最大字符数。
下面是两个使用strncat()函数的简单例子:
#include <stdio.h>
#include <string.h>
int main() {char arr1[20] = "abcdef";char arr2[] = "xyz";strncat(arr1, arr2, 2);//2表示追加2个字符printf("%s\n", arr1); //abcdefxyreturn 0;
}
#include <stdio.h>
#include <string.h>
int main() {char arr1[20] = "abc";char arr2[] = "xyz";strncat(arr1, arr1, 3);//2表示追加2个字符printf("%s\n", arr1); //abcabcreturn 0;
}2.3 strncmp
strncmp()函数用于比较两个字符串的前若干个字符,根据字符串的大小关系返回一个整数值。
strncmp()函数的函数原型如下:
int strncmp(const char *str1, const char *str2, size_t n);
其中,const char *str1和const char *str2是两个要比较的字符串的指针,size_t n表示要比较的字符数。
下面是一个使用strncmp()函数的简单例子:
#include <stdio.h>
#include <string.h>
int main() {int ret = strncmp("abcdef", "abc", 3);//3表示比较前三个printf("%d\n", ret); //0ret = strncmp("abcdef", "abc", 4);printf("%d\n", ret);//1return 0;
}
3.字符串查找函数
3.1 strstr
strstr 是 C 语言中用于在字符串中查找子字符串的函数。
它的函数原型为:
char *strstr(const char *str1, const char *str2);
str1:要搜索的主字符串。str2:要查找的子字符串。
函数返回一个指向第一次在 str1 中找到 str2 的指针,如果未找到,则返回 NULL。
下面对 strstr 函数的使用进行详细解释:
示例 1:
#include <stdio.h>
#include <string.h>int main() {char str1[] = "Hello, world!";char str2[] = "world";char *result = strstr(str1, str2);if (result != NULL) {printf("'%s' is found in '%s'\n", str2, str1);printf("Found at position: %ld\n", result - str1);} else {printf("'%s' is not found in '%s'\n", str2, str1);}return 0;
}
输出:
'world' is found in 'Hello, world!'
Found at position: 7
示例 2:
#include <stdio.h>
#include <string.h>int main() {char str1[] = "I love programming!";char str2[] = "Python";char *result = strstr(str1, str2);if (result != NULL) {printf("'%s' is found in '%s'\n", str2, str1);printf("Found at position: %ld\n", result - str1);} else {printf("'%s' is not found in '%s'\n", str2, str1);}return 0;
}
输出:
'Python' is not found in 'I love programming!'
模拟实现strstr
#include <stdio.h>
char *my_strstr(const char *str1, const char *str2) {if (*str2 == '\0') {return (char *)str1; // 如果 str2 是空字符串,直接返回 str1 的地址}while (*str1) {const char *temp_str1 = str1;const char *temp_str2 = str2;// 在 str1 中查找与 str2 相同的子字符串while (*temp_str1 && *temp_str2 && (*temp_str1 == *temp_str2)) {temp_str1++;temp_str2++;}// 如果找到了完全匹配的子字符串,则返回 str1 的地址if (*temp_str2 == '\0') {return (char *)str1;}// 否则,继续在 str1 中寻找下一个可能的匹配位置str1++;}return NULL; // 没有找到匹配的子字符串,返回 NULL
}int main() {char str1[] = "Hello, world!";char str2[] = "world";char *result = my_strstr(str1, str2);if (result != NULL) {printf("'%s' is found in '%s'\n", str2, str1);printf("Found at position: %ld\n", result - str1);} else {printf("'%s' is not found in '%s'\n", str2, str1);}return 0;
}
//'world' is found in 'Hello, world!'
4.字符串拆分函数
4.1 strtok
strtok 是 C 语言中用于将字符串拆分成子字符串的函数。
其函数原型如下:
char *strtok(char *str, const char *delimiters);
str:要拆分的字符串,第一次调用时传入要拆分的字符串,在后续调用中设置为 NULL。delimiters:作为分隔符的字符串,用于确定拆分子字符串的位置。
函数返回一个指向拆分后的子字符串的指针。在第一次调用时,函数返回第一个拆分的子字符串,后续调用返回后续的子字符串,直到没有更多的子字符串可供拆分,此时返回 NULL。
示例:
#include <stdio.h>
#include <string.h>int main() {char str[] = "apple,banana,orange,grape";// 拆分字符串char *token = strtok(str, ",");while (token != NULL) {printf("%s\n", token);token = strtok(NULL, ",");}return 0;
}
模拟实现strtok
#include <stdio.h>
#include <string.h>char *my_strtok(char *str, const char *delimiters) {static char *nextToken = NULL; // 用于保存下一个 token 的位置if (str != NULL) {nextToken = str; // str!=NULL,表示第一次调用,设置初始位置}if (nextToken == NULL || *nextToken == '\0') {return NULL; // 没有更多的 token 可供拆分}// 跳过开始的分隔符字符while (*nextToken && strchr(delimiters, *nextToken)) {nextToken++;}if (*nextToken == '\0') {return NULL; // 已到达字符串末尾}// 找到 token 的起始位置char *currentToken = nextToken;// 继续查找下一个分隔符位置,将其替换为 NULL 字符while (*nextToken && !strchr(delimiters, *nextToken)) {nextToken++;}if (*nextToken) {*nextToken = '\0'; // 替换为 NULL 字符nextToken++; // 下一个 token 的起始位置}return currentToken; // 返回当前拆分的 token
}int main() {char str[] = "apple,banana,orange,grape";char delimiters[] = ",";char *token = my_strtok(str, delimiters);while (token != NULL) {printf("%s\n", token);token = my_strtok(NULL, delimiters);}return 0;
}
5.错误信息报告函数
5.1 strerror
strerror 用于将错误码(整数)转换为对应的错误消息字符串。该函数通常用于处理与系统调用和库函数相关的错误,将错误码转换为人类可读的错误消息,方便程序员或用户理解和处理错误。
函数原型如下:
char *strerror(int errnum);
errnum:要转换的错误码。
函数返回一个指向错误消息字符串的指针。该字符串通常是静态分配的,不应该被修改。因此,最好将返回的字符串复制到另一个缓冲区中,以免被覆盖。
示例:
#include <errno.h>
#include <stdio.h>
#include <string.h>
int main() {//strerror的错误码//c语言中库函数报错的时候的错误码printf("%s\n", strerror(0));//No errorprintf("%s\n", strerror(1));//Operation not permittedprintf("%s\n", strerror(2));//No such file or directoryprintf("%s\n", strerror(3));//No such processprintf("%s\n", strerror(4));//Interrupted function callreturn 0;
}
#include <errno.h>
#include <stdio.h>
#include <string.h>
int main() {//错误码记录到错误码的变量中//errno - #include<errno.h> C语言提供的全局的错误变量FILE *pf = fopen("test.txt", "r");if (pf == NULL) {perror("fopen"); //perror = printf+strerror 打印fopen: No such file or directory//打印的依然是error变量中错误码对应的错误信息printf("%s\n", strerror(errno));//返回了2错误码return 1;}//读文件fclose(pf);pf = NULL;return 0;
}
6.字符操作函数
6.1 字符输入输出函数
getchar和putchar
在 C 语言中,有几个常用的字符输入输出函数,用于读取和输出单个字符。
以下是其中几个常用的字符输入输出函数:
1.getchar 和 putchar 函数:
int getchar(void);
int putchar(int c);
getchar函数用于从标准输入(通常是键盘)读取单个字符,并返回读取的字符的 ASCII 值(作为整数)。putchar函数用于向标准输出(通常是屏幕)输出单个字符。它的参数是一个整数(字符的 ASCII 值)。
这两个函数可以用来逐个读取和输出字符。例如,可以使用 getchar 来读取用户的输入字符,然后使用putchar 将字符输出到屏幕上。
2.getc 和 putc 函数:
int getc(FILE *stream);
int putc(int c, FILE *stream);
getc函数从指定的文件流stream中读取一个字符,并返回读取的字符的 ASCII 值(作为整数)。putc函数将指定的字符c写入到文件流stream中。它的参数是一个整数(字符的 ASCII 值)。
这两个函数与 getchar 和 putchar 函数类似,但可以用于从指定文件流中读取或输出字符。
需要注意的是,字符输入输出函数通常在遇到换行符或文件结尾时终止输入。在使用这些函数时,要确保输入输出的字符数量和顺序符合预期,避免因缓冲区问题导致意外行为。
示例:
#include <stdio.h>int main() {int ch;printf("Enter a character: ");ch = getchar();printf("You entered: ");putchar(ch);printf("\n");return 0;
}
6.2 字符分类函数
在 C 语言中,有一组字符分类函数,用于确定字符的属性。这些函数是 ctype.h 头文件中的标准库函数,提供了一系列用于字符分类的工具。
| 函数 | 条件 |
|---|---|
| iscntrl | 任何控制字符 |
| isspace | 空白字符:空格‘ ’,换页‘\f’,换行’\n’,回车‘\r’,制表符’\t’或者垂直制表符’\v’ |
| isdigital | 十进制数字 0~9 |
| isxdigital | 十六进制数字,包括所有十进制数字,小写字母af,大写字母AF |
| islower | 小写字母a~z |
| isupper | 大写字母A~Z |
| isalpha | 字母az或AZ |
| isalnum | 字母或者数字,az,AZ,0~9 |
| ispunct | 标点符号,任何不属于数字或者字母的图形字符(可打印) |
| isgraph | 任何图形字符 |
| isprint | 任何可打印字符,包括图形字符和空白字符 |
6.3 字符大小写转换函数
1.tolower 函数:
int tolower(int c);
- 用于将大写字母转换为相应的小写字母。如果
c是大写字母,则返回其对应的小写字母;否则,返回原字符c。
2.toupper 函数:
int toupper(int c);
- 用于将小写字母转换为相应的大写字母。如果
c是小写字母,则返回其对应的大写字母;否则,返回原字符c。
实例1:
int main(){char ch = 'w';printf("%c\n", toupper(ch)); // toupeer 转换成大写字母 - Wchar ch2 = 'A';printf("%c\n", tolower(ch2)); // tolower 转换成小写字母 - areturn 0;
}
实例2:
#include <ctype.h>
#include <stdio.h>
#include <string.h>
int main() {char arr[] = "Are you ok?";char *p = arr;while (*p) {if (islower(*p))//islower 判断是否是小写字母{*p = toupper(*p);}p++;}printf("%s\n", arr);// ARE YOU OK?return 0;
}
7.内存函数
7.1 memcpy
memcpy 是用于将内存块的内容从一个位置复制到另一个位置。
其函数原型如下:
void *memcpy(void *dest, const void *src, size_t n);
dest:目标内存块的起始地址,表示复制后的数据将存储在这个地址开始的内存块中。src:源内存块的起始地址,表示要复制的数据来源于这个地址开始的内存块。n:要复制的字节数,即要复制的内存块的大小。
函数返回值为 void * 类型,实际上是指向目标内存块的指针,即 dest 的值。
memcpy 函数通过将源内存块中的数据逐字节复制到目标内存块中来实现内存复制。它是一个高效的内存复制函数,通常用于处理字节流或结构体等的复制操作。
实例:
#include <stdio.h>
#include <string.h>
int main() {int arr1[] = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10};int arr2[10] = {0};memcpy(arr2, arr1, 20);// 20表示字节 拷贝5个整型数据for (int i = 0; i < sizeof(arr2) / sizeof(int); i++) {printf("%d ", arr2[i]);//1 2 3 4 5 0 0 0 0 0}printf("\n");float arr3[] = {1.0f, 2.0f, 3.0f, 4.0f};float arr4[] = {0.0};memcpy(arr4, arr3, 8);// 8表示拷贝2个浮点型数据for (int i = 0; i < sizeof(arr4) / sizeof(float); i++) {printf("%f ", arr4[i]); //1.000000 }return 0;
}
模拟实现memcpy
#include <assert.h>
#include <stdio.h>
void *my_memcpy(void *dest, void *src, size_t num)//需要传void* 的地址 num的单位是字节
{assert(dest && src);void *ret = dest;while (num--)//交换num次字节的内容 一次交换一次字节{*(char *) dest = *(char *) src;dest = (char *) dest + 1;src = (char *) src + 1;}return ret;
}int main() {int arr1[] = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10};int arr2[10] = {0};my_memcpy(arr2, arr1, 20);int i = 0;for (i = 0; i < 10; i++) {printf("%d ", arr2[i]); //1 2 3 4 5 0 0 0 0 0}printf("\n");float arr3[] = {1.0f, 2.0f, 3.0f, 4.0f};float arr4[10] = {0.0};my_memcpy(arr4, arr3, 8);for (i = 0; i < 10; i++) {printf("%f ", arr4[i]); //1.000000 2.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 }return 0;
}
7.2 memmove
memmove函数与memcpy函数类似,都用于内存拷贝,但它可以处理源内存区域和目标内存区域的重叠情况。memmove函数的函数原型如下:
void* memmove(void* dest, const void* src, size_t n);
它接受三个参数:
dest:指向目标内存区域的指针,也就是要将数据拷贝到的位置。src:指向源内存区域的指针,也就是要从中复制数据的位置。n:要复制的字节数。
memmove函数会确保即使源内存区域和目标内存区域有重叠,数据也会正确地被复制。这意味着它比memcpy更安全,因为memcpy在处理重叠内存区域时可能会导致未定义行为。
实例:
#include <stdio.h>
#include <string.h>int main() {float arr3[] = {1.0f, 2.0f, 3.0f, 4.0f};float arr4[] = {0.0f, 0.0f, 0.0f, 0.0f};memmove(arr4, arr3, sizeof(float) * 4);for (int i = 0; i < 4; i++) {printf("%f ", arr4[i]); // 输出: 1.000000 2.000000 3.000000 4.000000}return 0;
}
注意:
memcpy只需要实现不重叠的拷贝就可以了 VS中的memcpy和mommove实现方式差不多 可以替代
memmove是需要实现重叠内存的拷贝
模拟实现memmove
#include <assert.h>
#include <stdio.h>
#include <string.h>
void *my_memmove(void *dest, void *src, size_t num)//需要传void* 的地址 num的单位是字节
{assert(dest && src);void *ret = dest;if (dest < src) {while (num--)//交换num次字节的内容 一次交换一次字节{*(char *) dest = *(char *) src;dest = (char *) dest + 1;src = (char *) src + 1;}} else {while (num--) {*((char *) dest + num) = *((char *) src + num);//后面的数据 换到前面的数}}return ret;
}int main() {float arr3[] = {1.0f, 2.0f, 3.0f, 4.0f};float arr4[] = {0.0f, 0.0f, 0.0f, 0.0f};my_memmove(arr4, arr3, sizeof(float) * 4);for (int i = 0; i < 4; i++) {printf("%f ", arr4[i]);// 输出: 1.000000 2.000000 3.000000 4.000000}return 0;
}
7.3 memcmp
memcmp用于比较两个内存区域的内容是否相等。
int memcmp(const void* ptr1, const void* ptr2, size_t num);
memcmp函数接受三个参数:
ptr1:指向要比较的第一个内存区域的指针。ptr2:指向要比较的第二个内存区域的指针。num:要比较的字节数。
memcmp函数将会按字节逐个比较两个内存区域中的数据,直到比较完指定的字节数num或者遇到不相等的字节为止。如果两个内存区域的数据完全相等,则memcmp函数返回0。如果两个内存区域的数据不相等,则返回一个小于0的值或者大于0的值,其数值大小取决于第一个不相等的字节的差值。
下面是一个简单的例子:
#include <stdio.h>
#include <string.h>
int main(){int arr1[] = { 1,2,3,4,5 }; //01 00 00 00 02 00 00 00 03 00 00 00 04 00 00 00int arr2[] = { 1,2,3,0,0 }; //01 00 00 00 02 00 00 00 03 00 00 00 00 00 00 00int ret = memcmp(arr1, arr2, 12); //前12字节的内存printf("%d\n", ret); //0 ret = memcmp(arr1, arr2, 13); //前13字节的内存printf("%d\n", ret); //1return 0;
}
模拟实现memcmp
int my_memcmp(const void* ptr1, const void* ptr2, size_t num) {const unsigned char* byte_ptr1 = (const unsigned char*)ptr1;const unsigned char* byte_ptr2 = (const unsigned char*)ptr2;for (size_t i = 0; i < num; i++) {if (byte_ptr1[i] < byte_ptr2[i]) {return -1;} else if (byte_ptr1[i] > byte_ptr2[i]) {return 1;}}return 0;
}
7.4 memset
memset函数用于将指定的内存区域设置为特定的值。
其函数原型如下:
void *memset(void *ptr, int value, size_t num);
memset函数接受三个参数:
ptr:指向要设置的内存区域的指针。value:要设置的值,通常以整数形式传递,但实际上会被转换为unsigned char类型。num:要设置的字节数。
memset函数会将指定内存区域的每个字节都设置为value指定的值,重复num次。它通常用于对数组或结构体进行初始化,也可用于将内存区域置零。
实例:
#include <stdio.h>
#include <string.h>
int main() {int arr[] = {1, 2, 3, 4, 5};memset(arr, 0, 8);//8个字节int i = 0;for (i = 0; i < 5; i++) {printf("%d ", arr[i]);// 0 0 3 4 5}return 0;
}
模拟实现memset
void* my_memset(void* ptr, int value, size_t num) {unsigned char* byte_ptr = (unsigned char*)ptr;unsigned char byte_value = (unsigned char)value;for (size_t i = 0; i < num; i++) {byte_ptr[i] = byte_value;}return ptr;
}
相关文章:

<C语言> 字符串内存函数
C语言中对字符和字符串的处理很是频繁,但是C语言本身是没有字符串类型的,字符串通常放在常量字符串或者字符数组中。 字符串常量 适用于那些对它不做修改的字符串函数. 注意:字符串函数都需要包含头文件<string.h> 1.长度不受限制的…...
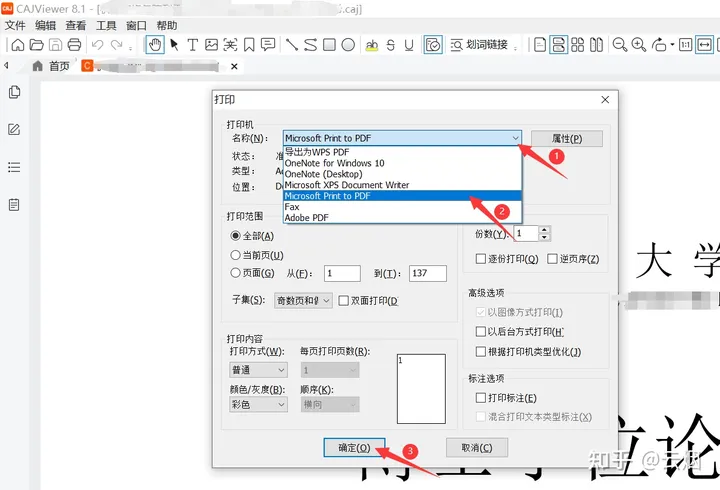
知网的caj格式怎么转化成pdf格式?两个方法简单快捷!
在使用知网等学术资源时,我们常常会遇到CAJ格式的文件,然而CAJ格式并不是常见的文件格式,给我们的查阅和分享带来一些不便。为了更方便地处理这些文件,我们可以将其转换为常见的PDF格式。在本文中,我将为您介绍两种简单…...

【每日一题】2500. 删除每行中的最大值
【每日一题】2500. 删除每行中的最大值 2500. 删除每行中的最大值题目描述解题思路 2500. 删除每行中的最大值 题目描述 给你一个 m x n 大小的矩阵 grid ,由若干正整数组成。 执行下述操作,直到 grid 变为空矩阵: 从每一行删除值最大的元…...
)
通俗解释什么是(ip、网段、端口)
通俗解释什么是(ip、网段、端口) 1:什么是IP? IP地址被用来给Internet上的电脑一个编号。IP地址是一个32位的二进制数,通常被分割为4个“8位二进制数”(也就是4个字节),IP地址通常…...

PyTorch quantization observer
文章目录 PyTorch quantization observerbasic classstandard observersubstandard observer PyTorch quantization observer basic class nameinheritdescribeObserverBaseABC, nn.ModuleBase observer ModuleUniformQuantizationObserverBaseObserverBase standard observ…...
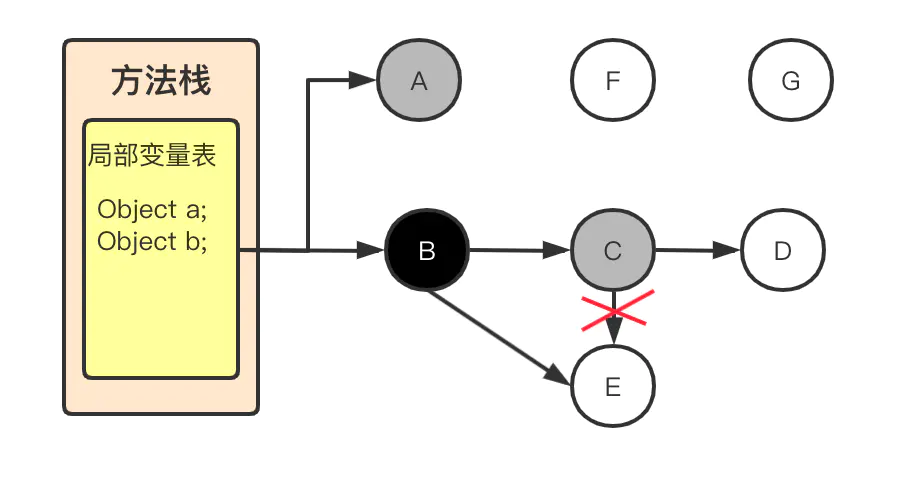
垃圾回收之三色标记法(Tri-color Marking)
关于垃圾回收算法,基本就是那么几种:标记-清除、标记-复制、标记-整理。在此基础上可以增加分代(新生代/老年代),每代采取不同的回收算法,以提高整体的分配和回收效率。 无论使用哪种算法,标记…...
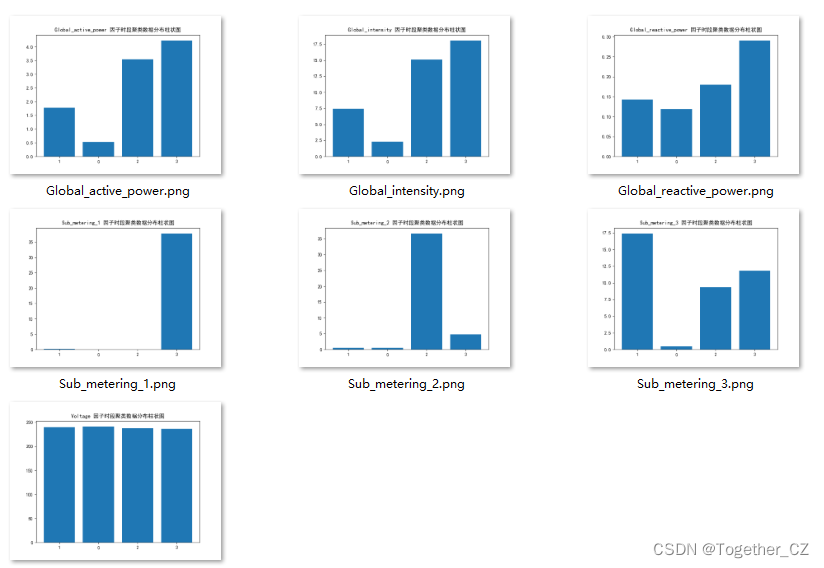
Individual household electric power consumption个人家庭用电量数据挖掘与时序预测建模
今天接到一个任务就是需要基于给定的数据集来进行数据挖掘分析相关的计算,并完成对未来时段内数据的预测建模,话不多少直接看内容。 官方数据详情介绍在这里,如下所示: 数据集中一共包含9个不同的字段,详情如下&#…...
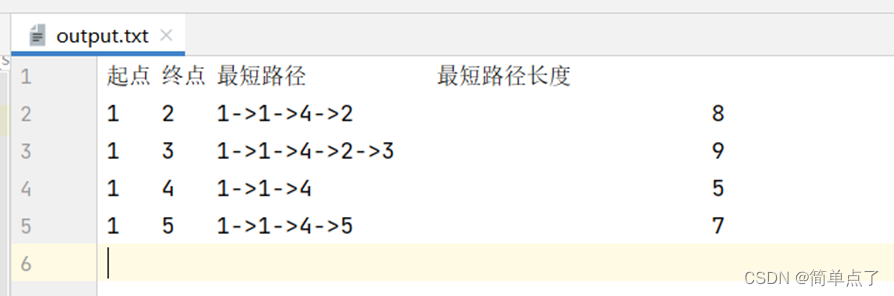
实验三 贪心算法
实验三 贪心算法 迪杰斯特拉的贪心算法实现 优先队列等 1.实验目的 1、掌握贪心算法的基本要素 :最优子结构性质和贪心选择性质 2、应用优先队列求单源顶点的最短路径Dijkstra算法,掌握贪心算法。 2.实验环境 Java 3.问题描述 给定带权有向图G (V…...
详解go的hex.Encode原理
简言 今天看nsq的messageID生成的时候,发现它使用了hex.Encode函数来产生编码,那就顺道研究一下这个编码方式。 原理 hex是16进制的意思,encode是进行编码的意思,内部实现也很简单,就是 每4位计算出十六进制的值&a…...
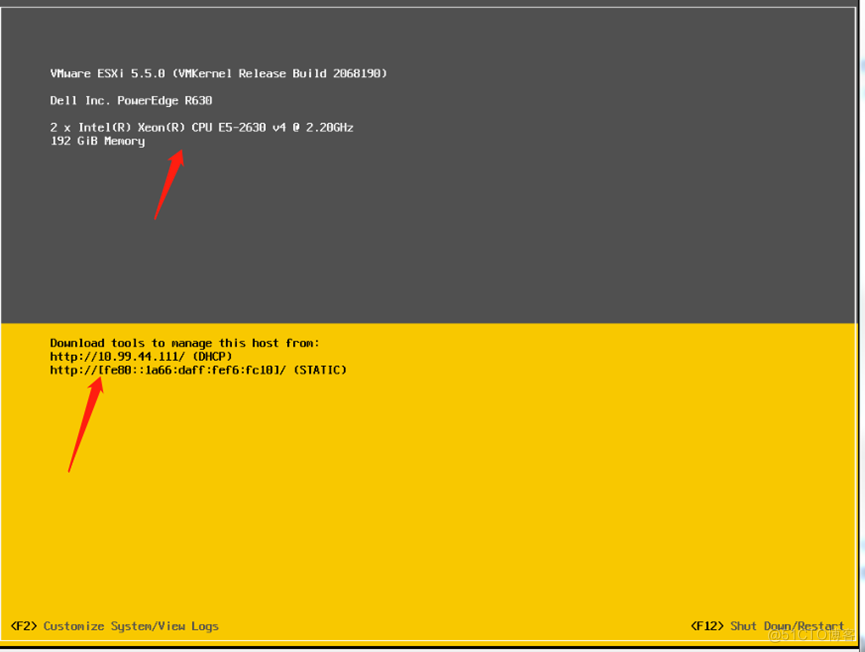
R730服务器用光盘安装系统(Esxi系统)
准备阶段:dell R730服务器,本教程一般适用于dell所有服务器,移动光盘,光碟做好镜像系统。在这里我安装的系统是Esxi系统,其他操作系统类似,只是安装的步骤不一样而已。 1、将系统盘插入光驱(移动光盘)&…...
SpringCloud nacos 集成 gateway ,实现动态路由
🎈 作者:Linux猿 🎈 简介:CSDN博客专家🏆,华为云享专家🏆,Linux、C/C、云计算、物联网、面试、刷题、算法尽管咨询我,关注我,有问题私聊! &…...
flutter:角标
角标应该非常常见了,以小说app为例,通常会在小说封面的右上角上显示当前未读的章数。 badges 简介 Flutter的badges库是一个用于创建徽章组件的开源库。它提供了简单易用的API,使开发者可以轻松地在Flutter应用程序中添加徽章效果。 官方文…...

基于JAVA SpringBoot和Vue高考志愿填报辅助系统
随着信息技术在管理中的应用日益深入和广泛,管理信息系统的实施技术也越来越成熟,管理信息系统是一门不断发展的新学科,任何一个机构要想生存和发展,要想有机、高效地组织内部活动,就必须根据自身的特点进行管理信息时…...
[php-cos]ThinkPHP项目集成腾讯云储存对象COS
Cos技术文档 1、安装phpSdk 通过composer的方式安装。 1.1 在composer.json中添加 qcloud/cos-sdk-v5: >2.0 "require": {"php": ">7.2.5","topthink/framework": "^6.1.0","topthink/think-orm": "…...

DuckDB全面挑战SQLite
概要 当我们想要在具有嵌入式数据库的本地环境中工作时,我们倾向于默认使用 SQLite。虽然大多数情况下这都很好,但这就像骑自行车去 100 公里之外:可能不是最好的选择。 这篇文章中将讨论以下要点: • DuckDB 简介:它…...

Elasticsearch查询裁剪
如果source有成千上百个字段,查询的数据没法看 某些敏感字段不能随意展示 响应数据较大影响网络带宽 查看文档信息 查看ffbf索引id为123的文档信息 GET /ffbf/_doc/123返回结果 {"_index" : "ffbf","_type" : "_doc","_id&qu…...

Hadoop——Hive运行环境搭建
Windows:10 JDK:1.8 Apache Hadoop:2.7.0 Apache Hive:2.1.1 Apache Hive src:1.2.2 MySQL:5.7 1、下载 Hadoop搭建 Apache Hive 2.1.1:https://archive.a…...
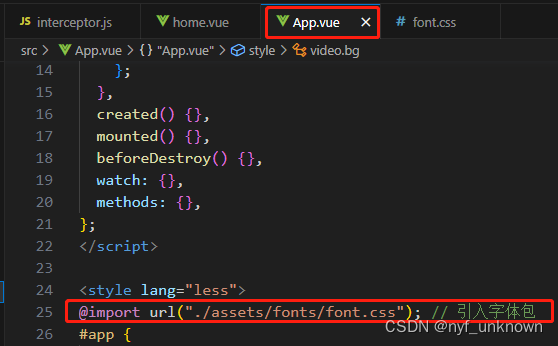
(vue)vue项目中引入外部字体
(vue)vue项目中引入外部字体 效果: 第一步 放置字体包,在assets下创建一个fonts文件夹,放入下载的字体文件 第二步 创建一个font.css文件用于定义这个字体包的名字 第三步 在App.vue的css中将这个css文件引入 第四步 页面使用 font-famil…...

ChatGPT在语义理解和信息提取中的应用如何?
ChatGPT在语义理解和信息提取领域有着广泛的应用潜力。语义理解是指对文本进行深层次的理解,包括词义、句义和篇章义等层面的理解。信息提取是指从文本中自动抽取结构化的信息,如实体、关系、事件等。ChatGPT作为一种预训练语言模型,具有丰富…...

Mysql-主从复制与读写分离
Mysql 主从复制、读写分离 一、前言:二、主从复制原理1.MySQL的复制类型2. MySQL主从复制的工作过程;3.MySQL主从复制延迟4. MySQL 有几种同步方式:5.Mysql应用场景 三、主从复制实验1.主从服务器时间同步1.1 master服务器配置1.2 两台SLAVE服务器配置 2…...

告别C盘战士!ArcGIS 10.6安装路径选择与磁盘空间优化全攻略
告别C盘战士!ArcGIS 10.6安装路径选择与磁盘空间优化全攻略当GIS初学者第一次安装ArcGIS 10.6时,往往会被其庞大的安装体积所震惊。许多用户习惯性地点击"下一步",结果发现C盘空间被迅速吞噬,系统运行变得迟缓。本文将深…...

Python PIL 画矩形框
基础代码 from PIL import Image, ImageDraw# 打开图片 img Image.open(your_image.jpg)# 创建绘图对象 draw ImageDraw.Draw(img)# 矩形坐标 (x1, y1, x2, y2) coords (23, 21, 69, 76)# 画矩形框(红色,线宽2) draw.rectangle(coords, ou…...

METSO A413248自动化系统
METSO A413248 自动化系统模块产品特点: 品牌归属:芬兰METSO(美卓)工业自动化系统原装备件。 产品类型:工业级自动化控制模块/接口模块。 核心功能:用于控制信号处理、数据采集及系统集成。 系统兼容&am…...

从“DOC/PDF”到“WPS”:细看GJB438C-2021文档格式要求背后的国产化信号与落地指南
从“DOC/PDF”到“WPS”:GJB438C-2021文档格式变革的深度解读与实施策略 当一份国家军用标准在文档格式描述中刻意删除"DOC/PDF"字样,转而明确标注"(WPS)文档处理器"时,这绝非简单的技术参数调整。…...

基于ESP8266与MQTT的家庭水压自动控制系统设计与实现
1. 项目概述与核心需求解析家里水压不稳、供水时断时续,这大概是很多朋友都遇到过的烦心事。我所在的城市供水情况就很不理想,为了解决这个问题,我不得不自己动手,搭建了一套基于ESP8266微控制器的家庭水压增压与储水自动控制系统…...

开源ELM327 OBD-II适配器:从硬件设计到多协议固件实现全解析
1. 项目概述:开源ELM327 OBD适配器如果你对汽车诊断、数据监控或者嵌入式开发感兴趣,那么自己动手做一个OBD-II适配器绝对是个能让你学到很多东西的硬核项目。今天要聊的,就是一个完全开源的、基于NXP LPC1517微控制器的ELM327兼容OBD适配器。…...

如何快速解锁艾尔登法环帧率限制:终极性能优化指南
如何快速解锁艾尔登法环帧率限制:终极性能优化指南 【免费下载链接】EldenRingFpsUnlockAndMore A small utility to remove frame rate limit, change FOV, add widescreen support and more for Elden Ring 项目地址: https://gitcode.com/gh_mirrors/el/EldenR…...

基于Max78000与规则引导的音频数据集构建:边缘AI声音识别实战
1. 项目概述:当边缘AI遇见棕榈树里的“窃听者”在边缘计算和物联网设备大行其道的今天,我们常常面临一个核心矛盾:一方面,我们希望设备足够“聪明”,能实时识别并响应特定的声音模式,比如工厂里高压阀门的异…...

3步快速部署:智能茅台抢购平台的终极自动化解决方案
3步快速部署:智能茅台抢购平台的终极自动化解决方案 【免费下载链接】campus-imaotai i茅台app自动预约,每日自动预约,支持docker一键部署(本项目不提供成品,使用的是已淘汰的算法) 项目地址: https://gi…...

遭遇薪酬倒挂后的反向谈判与资产重估策略「蒸汽求职分享」
在 2026 年全球科技大厂与跨国泛金融巨头追求极致人效、频繁进行组织架构重组(Reorg)的买方市场中,一个让无数海外名校留学生在入职两年后心态瞬间崩塌的现象,正在高频发生——“薪酬倒挂(Salary Inversion)…...