DuckDB全面挑战SQLite

概要
当我们想要在具有嵌入式数据库的本地环境中工作时,我们倾向于默认使用 SQLite。虽然大多数情况下这都很好,但这就像骑自行车去 100 公里之外:可能不是最好的选择。
这篇文章中将讨论以下要点:
-
• DuckDB 简介:它是什么、为什么要使用它以及何时使用它
-
• DuckDB 集成到 Python 中
什么是 DuckDB?
如果查看 DuckDB 的网站,在其主页上看到的第一件事就是:DuckDB 是一个进程内 SQL OLAP 数据库管理系统。
让我们尝试解读这句话,因为它包含相关信息。
-
• 进程内 SQL 意味着 DuckDB 的功能在应用程序中运行,而不是在应用程序连接的外部进程中运行。换句话说:没有客户端发送指令,也没有服务器读取和处理它们。与 SQLite 的工作方式相同,而 PostgreSQL、MySQL……则不然。
-
• OLAP 代表在线分析处理,微软将其定义为组织大型业务数据库并支持复杂分析的技术。它可用于执行复杂的分析查询,而不会对事务系统产生负面影响。OLAP 数据库管理系统的另一个示例是 Teradata。
所以基本上,如果寻找无服务器数据分析数据库管理系统,DuckDB 是一个不错的选择。强烈建议查看 Mark Raasveldt 博士和 Hannes Mühleisen 博士 (两位最重要的 DuckDB 开发人员)发表的精彩同行评审论文,以了解 DuckDB 试图填补的空白。
此外它还是一个支持 SQL 的关系数据库管理系统 (DBMS)。这就是为什么我们将它与具有相同特征的其他 DBMS(例如 SQLite 或 PostgreSQL)进行比较。
为什么选择 DuckDB?
知道了 DuckDB 在数据库行业中的作用。但是为什么要选择它而不是针对给定项目可能有的许多其他选项呢?
对于数据库管理系统而言,不存在一刀切的情况,DuckDB 也不例外。我们将介绍它的一些功能,以帮助决定何时使用它。
它是一个高性能工具。正如 GitHub 页面所示:“它的设计目标是快速、可靠且易于使用。”
-
• 它的创建是为了支持分析查询工作负载 (OLAP)。他们的方式是通过向量化查询执行(面向列),而前面提到的其他 DBMS(SQLite、PostgreSQL…)按顺序处理每一行。这就是其性能提高的原因。
-
• DuckDB 采用了 SQLite 的最佳特性:简单性。DuckDB 开发人员在看到 SQLite 的成功后,选择安装简单性和嵌入式进程内操作作为 DBMS。
-
• 此外 DuckDB 没有外部依赖项,也没有需要安装、更新或维护的服务器软件。如前所述,它是完全嵌入式的,这具有与数据库之间进行高速数据传输的额外优势。
-
• 熟练的开创者。他们是一个研究小组,创建它是为了创建一个稳定且成熟的数据库系统。这是通过密集和彻底的测试来完成的,测试套件目前包含数百万个查询,改编自 SQLite、PostgreSQL 和 MonetDB 的测试套件。
-
• 功能完备。支持 SQL 中的复杂查询,提供事务保证( ACID 属性),支持二级索引以加速查询……更重要的是深度集成到 Python 和 R 中,以实现高效的交互式数据分析。
-
• 还提供 C、C++、Java 的 API
-
• 免费和开源
这些都是官方的优势。
还有另外需要再强调一点:DuckDB 不一定是 Pandas 的替代品。它们可以携手合作,如果是 Pandas 粉丝,也可以使用 DuckDB 在 Pandas 上执行高效的 SQL。
什么时候使用DuckDB?
这确实取决于喜好,但让我们回到其联合创始人发布的论文。
他们解释说,显然需要嵌入式分析数据管理。SQLite 是嵌入式的,但如果我们想用它进行详尽的数据分析,它太慢了。他们坚持认为“这种需求来自两个主要来源:交互式数据分析和“边缘”计算。”
以下是 DuckDB 的前 2 个用例:
-
• 交互式数据分析。现在大多数数据专业人员在本地环境中使用 R 或 Python 库(例如 dplyr 或 Pandas)来处理从数据库检索的数据。DuckDB 为我们的本地开发提供了使用 SQL 效率的可能性,而不会影响性能。无需放弃最喜欢的编码语言即可获得这些好处(稍后会详细介绍)。
-
• 边缘计算。使用维基百科的定义“边缘计算是一种分布式计算范式,使计算和数据存储更接近数据源。” 使用嵌入式 DBMS,没有比这更接近的了
DuckDB 可以在不同的环境中安装和使用:Python、R、Java、node.js、Julia、C++…这里,我们将重点关注 Python,很快就会看到它是多么容易使用。
将 DuckDB 与 Python 结合使用(简介)
打开终端并导航到所需的目录,因为我们即将开始。创建一个新的虚拟环境(或不创建)并安装 DuckDB:
pip install duckdb==0.7.1
如果需要另一个版本,请删除或更新该版本。
为了让事情变得更有趣,我将使用我在 Kaggle 上找到的有关 Spotify 有史以来流媒体最多的歌曲的真实数据[6]。我将使用典型的 Jupyter Notebook。由于我们获得的数据是两个 CSV 文件(Features.csv 和 Streams.csv),因此我们需要创建一个新数据库并将它们加载到:
import duckdb# Create DB (embedded DBMS)
conn = duckdb.connect('spotiStats.duckdb')
c = conn.cursor()# Create tables by importing the content from the CSVs
c.execute("CREATE TABLE features AS SELECT * FROM read_csv_auto('Features.csv');"
)
c.execute("CREATE TABLE streams AS SELECT * FROM read_csv_auto('Streams.csv');"
)就像这样,我们创建了一个全新的数据库,添加了两个新表,并用所有数据填充了它们。所有这些都只有 4 行简单的代码(如果我们考虑导入,则为 5 行)。
让我们显示 Streams 表中的内容:
c.sql("SELECT * FROM streams")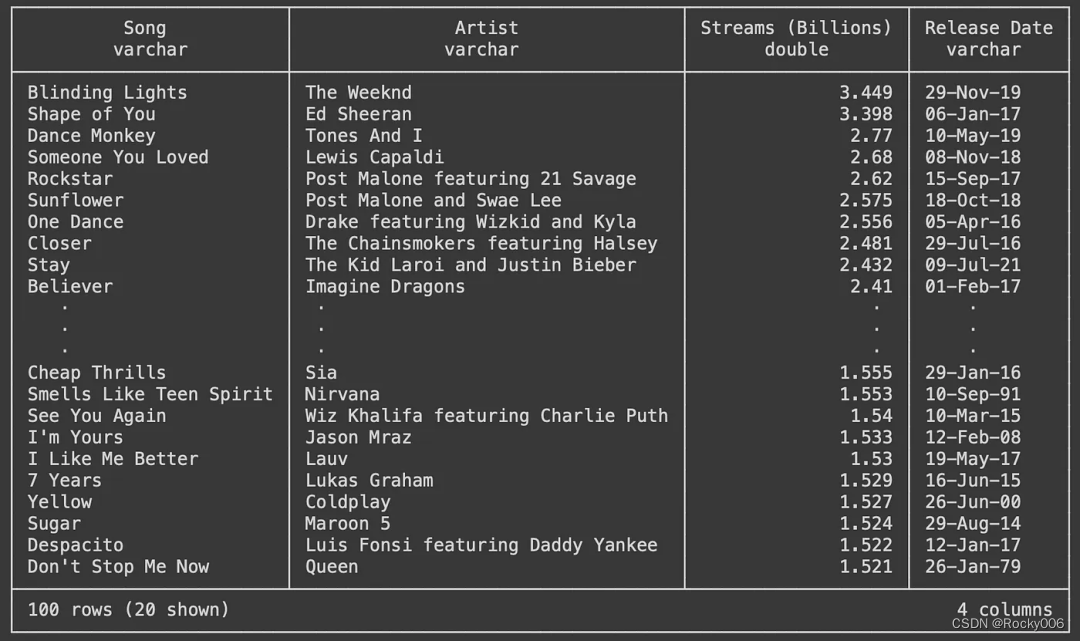
让我们开始做一些分析任务。例如想知道前 100 首中有多少首 2000 年之前的歌曲。这是一种方法:
c.sql('''
SELECT *
FROM streams
WHERE regexp_extract("Release Date", '\d{2}$') > '23'
''')
之前提到过同时使用 DuckDB 和 Pandas 很容易。这是一种使用 Pandas 执行相同操作的方法:
我所做的就是将初始查询转换为 DataFrame,然后以 Pandas 的方式应用过滤器。结果是一样的,但是他们的表现呢?
>>> %timeit df[df['Release Date'].apply(lambda x: x[-2:] > '23')]
434 µs ± 25.6 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)>>> %timeit c.sql('SELECT * FROM streams WHERE regexp_extract("Release Date", \'\d{2}$\') > \'23\'')
112 µs ± 25.3 µs per loop (mean ± std. dev. of 7 runs, 10000 loops each)操作相当简单:我们对 100 行表应用一个简单的过滤器。但如果我们将其与 DuckDB 实现进行比较,使用 Pandas 的执行时间几乎是其 4 倍。
如果我们尝试更详尽的分析操作,改进可能是巨大的。
我认为提供更多示例并没有多大意义,因为对 DuckDB 的介绍将转换为 SQL 介绍。这不是我想要的。
我们将最后的结果(2000 首之前的歌曲)导出为 parquet 文件 - 因为它们始终是传统 CSV 的更好替代品。同样这将非常简单:
c.execute('''
COPY (SELECT * FROM streams WHERE regexp_extract("Release Date", '\d{2}$') > '23'
)
TO 'old_songs.parquet' (FORMAT PARQUET);
''')我所做的就是将之前的查询放在括号内,DuckDB 只是将查询的结果复制到 old_songs.parquet 文件中。
结论
DuckDB 改变了进程内分析领域,这种影响还将继续。
今天的分享就到这里,欢迎点赞收藏转发,感谢🙏
相关文章:
DuckDB全面挑战SQLite
概要 当我们想要在具有嵌入式数据库的本地环境中工作时,我们倾向于默认使用 SQLite。虽然大多数情况下这都很好,但这就像骑自行车去 100 公里之外:可能不是最好的选择。 这篇文章中将讨论以下要点: • DuckDB 简介:它…...

Elasticsearch查询裁剪
如果source有成千上百个字段,查询的数据没法看 某些敏感字段不能随意展示 响应数据较大影响网络带宽 查看文档信息 查看ffbf索引id为123的文档信息 GET /ffbf/_doc/123返回结果 {"_index" : "ffbf","_type" : "_doc","_id&qu…...

Hadoop——Hive运行环境搭建
Windows:10 JDK:1.8 Apache Hadoop:2.7.0 Apache Hive:2.1.1 Apache Hive src:1.2.2 MySQL:5.7 1、下载 Hadoop搭建 Apache Hive 2.1.1:https://archive.a…...
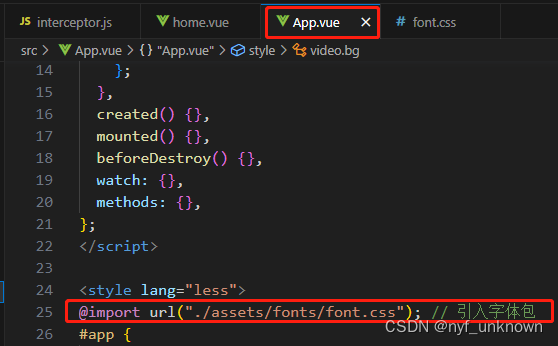
(vue)vue项目中引入外部字体
(vue)vue项目中引入外部字体 效果: 第一步 放置字体包,在assets下创建一个fonts文件夹,放入下载的字体文件 第二步 创建一个font.css文件用于定义这个字体包的名字 第三步 在App.vue的css中将这个css文件引入 第四步 页面使用 font-famil…...

ChatGPT在语义理解和信息提取中的应用如何?
ChatGPT在语义理解和信息提取领域有着广泛的应用潜力。语义理解是指对文本进行深层次的理解,包括词义、句义和篇章义等层面的理解。信息提取是指从文本中自动抽取结构化的信息,如实体、关系、事件等。ChatGPT作为一种预训练语言模型,具有丰富…...

Mysql-主从复制与读写分离
Mysql 主从复制、读写分离 一、前言:二、主从复制原理1.MySQL的复制类型2. MySQL主从复制的工作过程;3.MySQL主从复制延迟4. MySQL 有几种同步方式:5.Mysql应用场景 三、主从复制实验1.主从服务器时间同步1.1 master服务器配置1.2 两台SLAVE服务器配置 2…...
:牛客在线编程04 堆/栈/队列)
算法练习(3):牛客在线编程04 堆/栈/队列
package jz.bm;import java.util.*;public class bm4 {/*** BM42 用两个栈实现队列*/Stack<Integer> stack1 new Stack<>();Stack<Integer> stack2 new Stack<>();public void push(int node) {stack1.push(node);}public int pop() {while (!stack1…...

mac下安装vue cli脚手架并搭建一个简易项目
目录 1、确定本电脑下node和npm版本是否为项目所需版本。 2、下载vue脚手架 3、创建项目 1、下载node。 如果有node,打开终端,输入node -v和npm -v , 确保node和npm的版本,(这里可以根据自己的需求去选择,如果对最新版本的内容有…...

尝试-InsCode Stable Diffusion 美图活动一期
一、 Stable Diffusion 模型在线使用地址: https://inscode.csdn.net/inscode/Stable-Diffusion 二、模型相关版本和参数配置: 活动地址 三、图片生成提示词与反向提示词: 提示词:realistic portrait painting of a japanese…...

【OpenGL学习】之着色器GLSL基础
基本类型: 类型说明void空类型,即不返回任何值bool布尔类型 true,falseint带符号的整数 signed integerfloat带符号的浮点数 floating scalarvec2, vec3, vec4n维浮点数向量 n-component floating point vectorbvec2, bvec3, bvec4n维布尔向量 Boolean vectorivec2, ivec3, iv…...

Python爬虫基础知识点有哪些
目录 Python爬虫基础知识点 Requests库 Beautiful Soup库 正则表达式 数据存储 防止被反爬虫策略 爬虫调度和任务管理 认识robots.txt文件 反爬虫法律与道德 示例代码 Requests库 Beautiful Soup库 正则表达式 数据存储 防止被反爬虫策略 结语 网络世界中信息的…...

【CSS】 vh、rem 和 px 的区别
vh、rem 和 px 都是 CSS 中常见的长度单位,它们有以下区别: px(像素)是一个绝对单位,表示屏幕上的实际像素点。它的大小不会根据设备或浏览器的设置进行调整,是一个固定值。 rem(根元素字体大小…...

如何设置板子从emmc启动-针对imx6ull
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、pandas是什么?二、使用步骤1.引入库2.读入数据总结前言 提示:这里可以添加本文要记录的大概内容: 例如:随着人工智能的不断发展,机器学习这门技术也越来越重要,很多人都开启了学习…...
)
使用Newtonsoft直接读取Json格式文本(Linq to Json)
使用Newtonsoft直接读取Json格式文本(Linq to Json) 使用 Newtonsoft.Json(通常简称为 Newtonsoft)可以轻松地处理 JSON 格式的文本。Newtonsoft.Json 是 .NET 中一个流行的 JSON 处理库,它提供了丰富的功能和灵活性。…...

服务器用友数据库中了locked勒索病毒后怎么解锁数据恢复
随着信息技术的迅速发展,服务器成为现代企业中不可或缺的重要设备。然而,由于网络安全风险的存在,服务器在日常运作中可能遭受各种威胁,包括恶意软件和勒索病毒攻击。近日,我们收到很多企业的求助,企业的用…...

Linux-MariaDB数据库的备份与初始化
Linux-MariaDB数据库的备份与初始化 缘起数据库备份数据库用户查询数据库新建用户数据库权限回收数据库更新密码数据库root密码重置 缘起 Linux系统下我们比较常用的数据库软件是开源又免费的MySQL。MariaDB是MySQL的一个分支,采用GPL授权许可,完全兼容…...

springboot-redis使用fastjson2
1、pom 注:springboot2.*使用fastjson2-extension-spring5,3.*使用fastjson2-extension-spring6 <fastjson.version>2.0.37</fastjson.version> <!-- json --> <dependency><groupId>com.alibaba.fastjson2</groupId…...

SOC FPGA之HPS模型设计(二)
根据SOC FPGA之HPS模型设计(一), Quartus工程经过全编译后会产生Handoff文件夹、SOPCINFO文件、SVD文件 二、生成Preloader镜像文件 通过信息交换文件Handoff文件生成Preloader,需要用到SOC EDS Preloader也被称为spl(Second Program Loader)或u-boot…...

Go基础—反射,性能和灵活性的双刃剑
Go基础—反射,性能和灵活性的双刃剑 1 简介2 结构体成员赋值对比3 结构体成员搜索并赋值对比4 调用函数对比5 基准测试结果对比 1 简介 现在的一些流行设计思想需要建立在反射基础上,如控制反转(Inversion Of Control,IOC&#x…...

MATLAB与ROS联合仿真(慕羽☆)全套开源资料索引
自2021年9月份开始进行MATLAB与ROS联合仿真相关的研究,至2021年12月份研究基本上结束,至今,已经近两年时间,期间曾收到过很多小伙伴的私信,想让我出点教程,期间我也曾多次想要抽点时间出教程,但…...

AI时代程序员职业发展与个人创业可行性研究报告
一、行业宏观变革(2026核心趋势数据佐证) 1.1 开发范式已彻底重构(行业不可逆拐点) 2026年正式进入AI Agent智能体开发时代,传统CRUD编码价值持续崩塌。 核心权威数据: Gartner预测:2026年75%企…...
)
Mysql:事务管理(中)
在前面的章节中,我们提到了 MVCC(多版本并发控制),它巧妙地通过“版本快照”解决了“读-写”冲突,实现了非阻塞读。但如果两个事务同时执行 UPDATE 操作修改同一行数据,即 写-写(Write-Write&am…...

AI圈神秘领袖Ilya一幅画引爆全网,OpenAI三件大事暗示AGI时代将至?
AI圈神秘精神领袖Ilya在Instagram上传一幅画引发疯狂解读,与此同时,OpenAI连续公布数学成果、升级Codex、筹备IPO,释放AGI到来的强烈信号。Ilya画作引猜测Ilya上传的画中,罗丹的「思考者」踩在芯片Die Shot上,右下角签…...

Airtest Poco实战:5分钟搞定微信小程序自动化测试环境搭建与元素抓取
Airtest Poco实战:5分钟搞定微信小程序自动化测试环境搭建与元素抓取微信小程序作为轻量级应用的代表,已经渗透到电商、社交、工具等各个领域。随着小程序功能的日益复杂,自动化测试成为保障产品质量的重要手段。本文将带你快速搭建微信小程序…...
)
YOLOv8晶圆体缺识别检测系统(项目源码+YOLO数据集+模型权重+UI界面+python+深度学习+环境配置)
摘要 晶圆制造过程中的缺陷检测是保证芯片良率的关键环节。本文基于YOLOv8目标检测算法,构建了一套针对晶圆表面9类典型缺陷的自动检测系统。所识别的缺陷类型包括:Center、Donut、Edge-Loc、Edge-Ring、Loc、Near-full、None、Random、Scratch。模型在…...

真可用!美团数字人模型开源,MV、电商等统统拿下
美团开源的数字人视频生成框架 LongCat-Video-Avatar 刚刚更新到 1.5 版本。是真能用。这版更新把音频编码器换了,推理步数砍到8步,在770人、13240条主观评分的大规模评测里,雷达图面积全面领先。音频编码器换血,8步出图LongCat-V…...

告别坐标点击!用Poco精准定位UI控件,让你的Airtest安卓自动化脚本更稳定
告别坐标点击!用Poco精准定位UI控件,让你的Airtest安卓自动化脚本更稳定每次UI微调就导致脚本大面积失效?分辨率变化让精心编写的自动化测试瞬间崩溃?作为从坐标点击转型到控件识别的实践者,我深刻理解这种挫败感。三年…...

对比不同模型在创意生成任务中的效果与token消耗差异
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比不同模型在创意生成任务中的效果与token消耗差异 在为一场创意大赛准备素材时,我们面临一个常见的选择:…...

机器学习的最佳实践:这7个原则让你的模型更稳定
对于软件测试从业者而言,机器学习技术正在快速融入测试流程:从自动化测试用例生成、缺陷预测到测试环境异常检测,机器学习模型的稳定性直接决定了测试结果的可靠性——如果模型在测试环境波动、输入数据变化时性能骤降,不仅无法提…...

遭遇薪酬倒挂后的反向谈判与资产重估策略「蒸汽求职分享」
在 2026 年全球科技大厂与跨国泛金融巨头追求极致人效、频繁进行组织架构重组(Reorg)的买方市场中,一个让无数海外名校留学生在入职两年后心态瞬间崩塌的现象,正在高频发生——“薪酬倒挂(Salary Inversion)…...