吴恩达ChatGPT《LangChain Chat with Your Data》笔记
文章目录
- 1. Introduction
- 2. Document Loading
- 2.1 Retrieval Augmented Generation(RAG)
- 2.2 Load PDFs
- 2.3 Load YouTube
- 2.4 Load URLs
- 2.5 Load Notion
- 3. Document Splitting
- 3.1 Splitter Flow
- 3.2 Character Splitter
- 3.3 Token Splitter
- 3.4 Markdown Splitter
- 4. Vector Stores and Embeddings
- 4.1 Embedding
- 4.2 Vector Store Workflow
- 4.3 Usage Examples
- 4.4 Edge Cases
- 5. Retrieval
- 5.1 Maximum marginal relevance(MMR)
- 5.2 SelfQuery
- 5.3 Compression
- 5.4 Usage Examples
- 5.5 Other Retrievals
- 6. Question Answering
- 6.1 RetrievalQA Chain
- 6.2 Usage Examples
- 7. Chat
- 7.1 ConversationalRetrievalChain
- 7.2 Usage Examples
- 7.3 Create a chatbot that works on your documents
- 8. Conclusion
课程地址:https://learn.deeplearning.ai/langchain-chat-with-your-data/lesson/1/introduction
1. Introduction
像ChatGPT这样的LLM可以回答很多类型的问题,但是如果仅仅依靠LLM,它只知道训练过的内容,而不知道其他内容,比如个人数据,互联网实时信息等。如果个人用户可以利用LLM与自己的文档进行对话,并能够回答用户的问题,是非常有用的。LangChain框架可以实现上述功能。
LangChain是一个用于构建LLM应用的开源开发框架。LangChain由许多模块化组件和端到端Prompt模板组成。此外,还有许多丰富的组合这些组件的用例,方便使用。

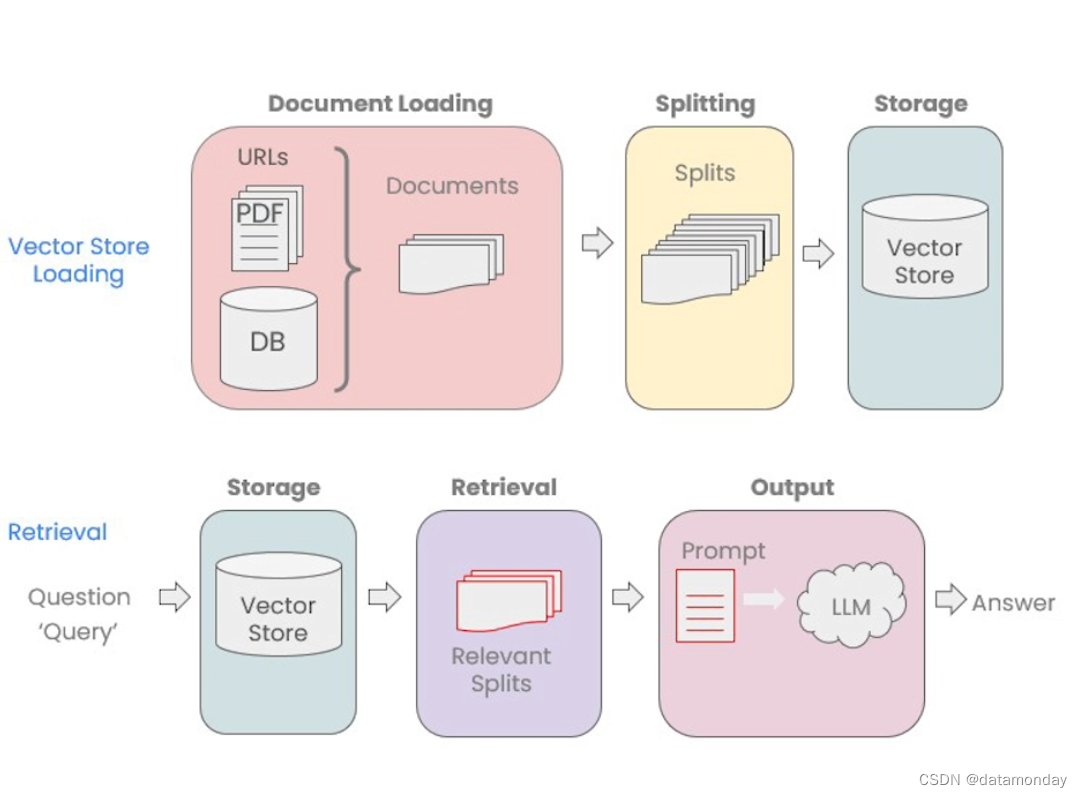
下面是使用LangChain的文档加载器从各种数据源加载数据的流程图:

本课程主要包含了下述内容:
- 其中一个预处理步骤——将这些文档分割成语义上有意义的块:这个看似简单的步骤,实际上有许多细节需要考虑。
- 语义搜索:用于获取用户问题的相关信息
- 失败情况的处理
- 使用检索到的文档回答用户问题
- 与数据对话的聊天机器人的关键——记忆能力
2. Document Loading
要与数据对话的聊天机器人的第一步是将文档数据加载成可以使用的格式。
LangChain提供的文档将在其可以把不同来源的数据格式转换成标准化格式。比如,可以将不同网站,不同数据库等来源的诸如PDF,HTML,JSON等数据格式转换成LLM可用的标准文档对象格式。其包含了内容和关联的元数据。

LangChain中包含了 80+ 种不同的文档加载器,如下图所示:

2.1 Retrieval Augmented Generation(RAG)
在检索增强生成(RAG)中,LLM作为执行的一部分从外部数据集检索上下文文档。如果我们想询问有关特定文档的问题(例如,PDF,视频等),这将很有用。检索增强生成的流程如下图所示:

2.2 Load PDFs
#! pip install langchain
#! pip install pypdf
import os
import openai
import sys
sys.path.append('../..')from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv()) # read local .env fileopenai.api_key = os.environ['OPENAI_API_KEY']
下面是使用LangChain加载PDF文档的示例:
from langchain.document_loaders import PyPDFLoader
loader = PyPDFLoader("docs/cs229_lectures/MachineLearning-Lecture01.pdf")
pages = loader.load()
加载之后的数据结构中,每一个 page 都是 Document 对象。Document 包含了文本(page_content)和元数据。
page = pages[0]
print(page.page_content[0:500])
MachineLearning-Lecture01
Instructor (Andrew Ng): Okay. Good morning. Welcome to CS229, the machine
learning class. So what I wanna do today is ju st spend a little time going over the logistics
of the class, and then we'll start to talk a bit about machine learning.
By way of introduction, my name's Andrew Ng and I'll be instru ctor for this class. And so
I personally work in machine learning, and I' ve worked on it for about 15 years now, and
I actually think that machine learning i
元数据由source和page两部分组成,分别表示来源和页码信息:
page.metadata
{'source': 'docs/cs229_lectures/MachineLearning-Lecture01.pdf', 'page': 0}
2.3 Load YouTube
下面是通过LangChain加载Youtube视频信息的示例:
其中使用了OpenAI的Whisper模型,将语音转换成文本。
from langchain.document_loaders.generic import GenericLoader
from langchain.document_loaders.parsers import OpenAIWhisperParser
from langchain.document_loaders.blob_loaders.youtube_audio import YoutubeAudioLoader
# ! pip install yt_dlp
# ! pip install pydub
参数也很简单,url指定视频链接,save_dir指定转换后的保存目录。
url="https://www.youtube.com/watch?v=jGwO_UgTS7I"
save_dir="docs/youtube/"
loader = GenericLoader(YoutubeAudioLoader([url],save_dir),OpenAIWhisperParser()
)
docs = loader.load()
因为要下载视频,所以这个过程会有些耗时。
[youtube] Extracting URL: https://www.youtube.com/watch?v=jGwO_UgTS7I
[youtube] jGwO_UgTS7I: Downloading webpage
[youtube] jGwO_UgTS7I: Downloading android player API JSON
[info] jGwO_UgTS7I: Downloading 1 format(s): 140
[download] docs/youtube//Stanford CS229: Machine Learning Course, Lecture 1 - Andrew Ng (Autumn 2018).m4a has already been downloaded
[download] 100% of 69.71MiB
[ExtractAudio] Not converting audio docs/youtube//Stanford CS229: Machine Learning Course, Lecture 1 - Andrew Ng (Autumn 2018).m4a; file is already in target format m4a
Transcribing part 1!
docs[0].page_content[0:500]
举一反三,通过LangChain的这个功能,可以充分地将互联网上的海量优质教育资源提炼总结,转换成方便阅读和存储的文字,转换成个性化的知识库,以供学习。
2.4 Load URLs
下面是一个网页内容加载器的使用示例:
from langchain.document_loaders import WebBaseLoaderloader = WebBaseLoader("https://github.com/basecamp/handbook/blob/master/37signals-is-you.md")
docs = loader.load()
print(docs[0].page_content[:500])
2.5 Load Notion
下面是一个Notion笔记加载器的使用示例。需要按照示例进行操作:
1)将页面复制到自己的Notion空间中,并将其导出为Markdown/CSV。
2)解压缩并将其保存为包含Notion page的 markdown 文件的文件夹中。

from langchain.document_loaders import NotionDirectoryLoader
loader = NotionDirectoryLoader("docs/Notion_DB")
docs = loader.load()
print(docs[0].page_content[0:200])
# Blendle's Employee HandbookThis is a living document with everything we've learned working with people while running a startup. And, of course, we continue to learn. Therefore it's a document that
docs[0].metadata
{'source': "docs/Notion_DB/Blendle's Employee Handbook e367aa77e225482c849111687e114a56.md"}
3. Document Splitting
有了标准格式的数据对象,接下来就可以对这些文档数据进行分块,因为文档问答的上下文只需要相关的几部分即可。

该步骤是非常重要并且非常复杂的,其在存储到向量数据库之前。其包含了许多细节需要处理,如果处理不当,则后续步骤会产生异常。
常用的分割方法是根据字符串的长度分割,缺点是会使得完整的句子处于不同的块,丢失语义,无法回答用户问题,因为每个块中都没有包含正确的信息。
3.1 Splitter Flow
在LangChain中,所有文本分割器的原理都是根据块大小和两个块之间的重叠大小进行分割的。下面是一个示意图:

其中,
chunk_size指的是块大小。可以用几种不同的方式来衡量,通过传入一个长度函数来测量块大小。通常是根据字符长度或者Token长度测量。chunk_overlap指的是两个块之间重叠的部分。
这么做的原因是,在块的开头保留上一块的结尾的一部分内容,有助于保持上下文的连贯性。
3.2 Character Splitter
LangChain中目前包含的不同类型的分割器:

这些文本分割器之间的主要差别是如何分隔块以及块由那些字符组成。如何测量块的长度上也有差别,比如按照字符计数,按照token计数等。此外,还有一些方法使用额外的小模型来确定句子的结束位置。
下面介绍两种文本分割器:字符文本分割器和递归字符文本分割器。
这个递归文本分割器的 seperator 参数传递了一个列表,这表示该方法会先按照双换行符进行分割(将文档分割成段落),然后再按照单换行符进行分割(将段落分割成句子),之后在按照空格进行分割(将句子分割成单词),最后会按照字符长度(将单词分割成字符)进行分割。
from langchain.text_splitter import RecursiveCharacterTextSplitter, CharacterTextSplitter
chunk_size =26
chunk_overlap = 4
r_splitter = RecursiveCharacterTextSplitter(chunk_size=chunk_size,chunk_overlap=chunk_overlap
)
c_splitter = CharacterTextSplitter(chunk_size=chunk_size,chunk_overlap=chunk_overlap
)
text1 = 'abcdefghijklmnopqrstuvwxyz'
r_splitter.split_text(text1)
['abcdefghijklmnopqrstuvwxyz']
text2 = 'abcdefghijklmnopqrstuvwxyzabcdefg'
r_splitter.split_text(text2)
['abcdefghijklmnopqrstuvwxyz', 'wxyzabcdefg']
text3 = "a b c d e f g h i j k l m n o p q r s t u v w x y z"
r_splitter.split_text(text3)
['a b c d e f g h i j k l m', 'l m n o p q r s t u v w x', 'w x y z']
c_splitter.split_text(text3)
['a b c d e f g h i j k l m n o p q r s t u v w x y z']
c_splitter = CharacterTextSplitter(chunk_size=chunk_size,chunk_overlap=chunk_overlap,separator = ' '
)
c_splitter.split_text(text3)
['a b c d e f g h i j k l m', 'l m n o p q r s t u v w x', 'w x y z']
RecursiveCharacterTextSplitter 更适用于通用的文本分割。
some_text = """When writing documents, writers will use document structure to group content. \
This can convey to the reader, which idea's are related. For example, closely related ideas \
are in sentances. Similar ideas are in paragraphs. Paragraphs form a document. \n\n \
Paragraphs are often delimited with a carriage return or two carriage returns. \
Carriage returns are the "backslash n" you see embedded in this string. \
Sentences have a period at the end, but also, have a space.\
and words are separated by space."""
len(some_text)
496
c_splitter = CharacterTextSplitter(chunk_size=450,chunk_overlap=0,separator = ' '
)
r_splitter = RecursiveCharacterTextSplitter(chunk_size=450,chunk_overlap=0, separators=["\n\n", "\n", " ", ""]
)
c_splitter.split_text(some_text)
['When writing documents, writers will use document structure to group content. This can convey to the reader, which idea\'s are related. For example, closely related ideas are in sentances. Similar ideas are in paragraphs. Paragraphs form a document. \n\n Paragraphs are often delimited with a carriage return or two carriage returns. Carriage returns are the "backslash n" you see embedded in this string. Sentences have a period at the end, but also,','have a space.and words are separated by space.']
r_splitter.split_text(some_text)
["When writing documents, writers will use document structure to group content. This can convey to the reader, which idea's are related. For example, closely related ideas are in sentances. Similar ideas are in paragraphs. Paragraphs form a document.",'Paragraphs are often delimited with a carriage return or two carriage returns. Carriage returns are the "backslash n" you see embedded in this string. Sentences have a period at the end, but also, have a space.and words are separated by space.']
r_splitter = RecursiveCharacterTextSplitter(chunk_size=150,chunk_overlap=0,separators=["\n\n", "\n", "\. ", " ", ""]
)
r_splitter.split_text(some_text)
["When writing documents, writers will use document structure to group content. This can convey to the reader, which idea's are related",'. For example, closely related ideas are in sentances. Similar ideas are in paragraphs. Paragraphs form a document.','Paragraphs are often delimited with a carriage return or two carriage returns','. Carriage returns are the "backslash n" you see embedded in this string','. Sentences have a period at the end, but also, have a space.and words are separated by space.']
r_splitter = RecursiveCharacterTextSplitter(chunk_size=150,chunk_overlap=0,separators=["\n\n", "\n", "(?<=\. )", " ", ""]
)
r_splitter.split_text(some_text)
["When writing documents, writers will use document structure to group content. This can convey to the reader, which idea's are related.",'For example, closely related ideas are in sentances. Similar ideas are in paragraphs. Paragraphs form a document.','Paragraphs are often delimited with a carriage return or two carriage returns.','Carriage returns are the "backslash n" you see embedded in this string.','Sentences have a period at the end, but also, have a space.and words are separated by space.']
from langchain.document_loaders import PyPDFLoader
loader = PyPDFLoader("docs/cs229_lectures/MachineLearning-Lecture01.pdf")
pages = loader.load()
from langchain.text_splitter import CharacterTextSplitter
text_splitter = CharacterTextSplitter(separator="\n",chunk_size=1000,chunk_overlap=150,length_function=len
)
docs = text_splitter.split_documents(pages)
len(docs)
77
len(pages)
22
from langchain.document_loaders import NotionDirectoryLoader
loader = NotionDirectoryLoader("docs/Notion_DB")
notion_db = loader.load()
docs = text_splitter.split_documents(notion_db)
len(notion_db)
52
len(docs)
353
3.3 Token Splitter
之所以会有基于Token的分割器,是因为LLM的上下文窗口的长度限制都是按照token来计数的。所以,理解token的位置和它们的含义是至关重要的。这样我们就可以从LLM视角对文本按照token进行分割,从而得到更好的结果。
from langchain.text_splitter import TokenTextSplitter
text_splitter = TokenTextSplitter(chunk_size=1, chunk_overlap=0)
text1 = "foo bar bazzyfoo"
text_splitter.split_text(text1)
['foo', ' bar', ' b', 'az', 'zy', 'foo']
text_splitter = TokenTextSplitter(chunk_size=10, chunk_overlap=0)
docs = text_splitter.split_documents(pages)
docs[0]
Document(page_content='MachineLearning-Lecture01 \n', metadata={'source': 'docs/cs229_lectures/MachineLearning-Lecture01.pdf', 'page': 0})
pages[0].metadata
{'source': 'docs/cs229_lectures/MachineLearning-Lecture01.pdf', 'page': 0}
3.4 Markdown Splitter
在实际应用的过程中,我们可能想在块中添加更多的元数据信息,比如块的位置信息——在文档中的位置或者相对于其他内容的位置。通常,这些信息可以在对文档问答时,能够提供更多关于这个块的上下文信息。
MarkdownHeaderTokenSplitter可以实现这个目标。它根据标题或者子标题来分割Markdown文件,然后会将这些标题作为内容添加到元数据中。
此外,它还支持自定义想要分隔后的标题名称,数据结构是元组构成的列表,其中第一个参数表示标题分隔符,第二份参数是分割后的标题名称。
from langchain.document_loaders import NotionDirectoryLoader
from langchain.text_splitter import MarkdownHeaderTextSplitter
markdown_document = """# Title\n\n \
## Chapter 1\n\n \
Hi this is Jim\n\n Hi this is Joe\n\n \
### Section \n\n \
Hi this is Lance \n\n
## Chapter 2\n\n \
Hi this is Molly"""
headers_to_split_on = [("#", "Header 1"),("##", "Header 2"),("###", "Header 3"),
]
markdown_splitter = MarkdownHeaderTextSplitter(headers_to_split_on=headers_to_split_on
)
md_header_splits = markdown_splitter.split_text(markdown_document)
md_header_splits[0]
Document(page_content='Hi this is Jim \nHi this is Joe', metadata={'Header 1': 'Title', 'Header 2': 'Chapter 1'})
md_header_splits[1]
Document(page_content='Hi this is Lance', metadata={'Header 1': 'Title', 'Header 2': 'Chapter 1', 'Header 3': 'Section'})
loader = NotionDirectoryLoader("docs/Notion_DB")
docs = loader.load()
txt = ' '.join([d.page_content for d in docs])
headers_to_split_on = [("#", "Header 1"),("##", "Header 2"),
]
markdown_splitter = MarkdownHeaderTextSplitter(headers_to_split_on=headers_to_split_on
)
md_header_splits = markdown_splitter.split_text(txt)
md_header_splits[0]
Document(page_content="This is a living document with everything we've learned working with people while running a startup. And, of course, we continue to learn. Therefore it's a document that will continue to change. \n**Everything related to working at Blendle and the people of Blendle, made public.** \nThese are the lessons from three years of working with the people of Blendle. It contains everything from [how our leaders lead](https://www.notion.so/ecfb7e647136468a9a0a32f1771a8f52?pvs=21) to [how we increase salaries](https://www.notion.so/Salary-Review-e11b6161c6d34f5c9568bb3e83ed96b6?pvs=21), from [how we hire](https://www.notion.so/Hiring-451bbcfe8d9b49438c0633326bb7af0a?pvs=21) and [fire](https://www.notion.so/Firing-5567687a2000496b8412e53cd58eed9d?pvs=21) to [how we think people should give each other feedback](https://www.notion.so/Our-Feedback-Process-eb64f1de796b4350aeab3bc068e3801f?pvs=21) — and much more. \nWe've made this document public because we want to learn from you. We're very much interested in your feedback (including weeding out typo's and Dunglish ;)). Email us at hr@blendle.com. If you're starting your own company or if you're curious as to how we do things at Blendle, we hope that our employee handbook inspires you. \nIf you want to work at Blendle you can check our [job ads here](https://blendle.homerun.co/). If you want to be kept in the loop about Blendle, you can sign up for [our behind the scenes newsletter](https://blendle.homerun.co/yes-keep-me-posted/tr/apply?token=8092d4128c306003d97dd3821bad06f2).", metadata={'Header 1': "Blendle's Employee Handbook"})
4. Vector Stores and Embeddings
在将文档分割成小的并且在语义上有意义的块之后,就可以对它们建立索引。这样,在回答问题时,就可以轻易地从索引中检索相关的几个快作为上下文,让LLM生成答案。

4.1 Embedding
embedding实际上是由一组-1到1范围内的实数组成的向量。语义上越相似的文本,在向量空间里越接近。

4.2 Vector Store Workflow

4.3 Usage Examples
LangChain集成了30+种不同的向量存储方式。本小节示例中使用的向量数据库是 Chroma。它轻量而且支持内存存储,非常容易上手。
from langchain.document_loaders import PyPDFLoader# Load PDF
loaders = [# Duplicate documents on purpose - messy dataPyPDFLoader("docs/cs229_lectures/MachineLearning-Lecture01.pdf"),PyPDFLoader("docs/cs229_lectures/MachineLearning-Lecture01.pdf"),PyPDFLoader("docs/cs229_lectures/MachineLearning-Lecture02.pdf"),PyPDFLoader("docs/cs229_lectures/MachineLearning-Lecture03.pdf")
]
docs = []
for loader in loaders:docs.extend(loader.load())
# Split
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(chunk_size = 1500,chunk_overlap = 150
)
splits = text_splitter.split_documents(docs)
len(splits)
209
from langchain.embeddings.openai import OpenAIEmbeddings
embedding = OpenAIEmbeddings()
sentence1 = "i like dogs"
sentence2 = "i like canines"
sentence3 = "the weather is ugly outside"
embedding1 = embedding.embed_query(sentence1)
embedding2 = embedding.embed_query(sentence2)
embedding3 = embedding.embed_query(sentence3)
# 1536
len(embedding1)# 0.22333593666553497
np.max(embedding1)# -0.6714226007461548
np.min(embedding1)
import numpy as np
np.dot(embedding1, embedding2)
0.9631923847517209
np.dot(embedding1, embedding3)
0.7711111095422276
np.dot(embedding2, embedding3)
0.7596334120325523
向量存储
# ! pip install chromadb
!rm -rf ./docs/chroma # remove old database files if any
from langchain.vectorstores import Chromapersist_directory = 'docs/chroma/'vectordb = Chroma.from_documents(documents=splits,embedding=embedding,persist_directory=persist_directory
)print(vectordb._collection.count())
209
相似性搜索
question = "is there an email i can ask for help"docs = vectordb.similarity_search(question,k=3)
# 持久化
vectordb.persist()
4.4 Edge Cases
这里展示的一种边缘的情况是将相同的文档内容传递给语言模型,第二个重复的是没有价值的,如果换成另外一个不同的会更好,因为LLM可以从中获得更多的上下文信息。
另一种边缘的情况是,比如提问的问题是:他们在第三节课中涉及了哪些与回归相关的内容?
从直觉上讲,模型应该能够返回第三节中与回归相关的内容,而不会有这个范围之外的内容。但实际上,搜索结果中包含了所有与“回归”一词相关的内容,而没有限制这些内容来自“第三节”。
如果完全是基于Embedding做语义查找,当我们对整个问题创建Embedding,那么它会更突出其中的“回归”一词,而没有捕捉到“第三节”这种结构化信息。
5. Retrieval

5.1 Maximum marginal relevance(MMR)
最大边际相关性(MMR)搜索其背后的直觉是:如果总是选择embedding空间中与查询问题最相似的文档,那么很可能会错过多种不同的信息。
下面举了一个搜索“蘑菇”的例子,如果只使用相似性搜索,那么会搜到与“蘑菇”相关的信息,图中的蓝色框和绿色框的内容。但不会搜到“有些蘑菇是有毒的”这种信息,图中橙色框的内容。而借助MMR则可以解决上述问题,因为它会选择多样化的文档集。

MMR的原理是:当一个查询请求发起时,通过设置的 fetch_k 参数确定返回的响应,这一步是完全基于相似性搜索。之后,通过MR进一步根据语义相似性和文档多样性筛选文档,然后选择 k 篇文档返回给用户。

5.2 SelfQuery
使用语言模型,将问题拆分为两部分——过滤器(Filter)和搜索内容。大多数向量数据库都支持元数据过滤,可以很轻易地根据元数据过滤结果,比如例子中的“年份=1980”。

5.3 Compression
压缩技术对于从候选段落中选取最相关的部分非常有用。比如通过查询的问题,找到了一篇文档中的多个段落,借助压缩LLM可以将这些段落分别总结为更简短的摘要。然后,将其输入到LLM作为上下文,生成答案。这样做的代价是需要多次调用LLM,从成本上和性能上看会有损耗,但是可以让最终的答案集中在最重要的内容上。

5.4 Usage Examples
#!pip install lark
from langchain.vectorstores import Chroma
from langchain.embeddings.openai import OpenAIEmbeddings
persist_directory = 'docs/chroma/'embedding = OpenAIEmbeddings()
vectordb = Chroma(persist_directory=persist_directory,embedding_function=embedding
)# 209
print(vectordb._collection.count())
texts = ["""The Amanita phalloides has a large and imposing epigeous (aboveground) fruiting body (basidiocarp).""","""A mushroom with a large fruiting body is the Amanita phalloides. Some varieties are all-white.""","""A. phalloides, a.k.a Death Cap, is one of the most poisonous of all known mushrooms.""",
]smalldb = Chroma.from_texts(texts, embedding=embedding)question = "Tell me about all-white mushrooms with large fruiting bodies"smalldb.similarity_search(question, k=2)
[Document(page_content='A mushroom with a large fruiting body is the Amanita phalloides. Some varieties are all-white.', metadata={}),Document(page_content='The Amanita phalloides has a large and imposing epigeous (aboveground) fruiting body (basidiocarp).', metadata={})]
相似性搜索:
question = "what did they say about matlab?"
docs_ss = vectordb.similarity_search(question,k=3)
docs_ss[0].page_content[:100]
'those homeworks will be done in either MATLA B or in Octave, which is sort of — I \nknow some people '
docs_ss[1].page_content[:100]
'those homeworks will be done in either MATLA B or in Octave, which is sort of — I \nknow some people '
可以看到,存在重复的数据(脏数据)时,相似性搜索并没有去重能力,而是直接返回了。
通过MMR增加检索的多样性:
docs_mmr = vectordb.max_marginal_relevance_search(question,k=3)
docs_mmr[0].page_content[:100]
'those homeworks will be done in either MATLA B or in Octave, which is sort of — I \nknow some people '
docs_mmr[1].page_content[:100]
'algorithm then? So what’s different? How come I was making all that noise earlier about \nleast squa'
而MMR则可以保证多样性,即使存在重复的数据,也可以去重。
通过向量数据库的元数据过滤功能解决特异性(Specificity):
question = "what did they say about regression in the third lecture?"docs = vectordb.similarity_search(question,k=3,filter={"source":"docs/cs229_lectures/MachineLearning-Lecture03.pdf"}
)for d in docs:print(d.metadata)
{'source': 'docs/cs229_lectures/MachineLearning-Lecture03.pdf', 'page': 0}
{'source': 'docs/cs229_lectures/MachineLearning-Lecture03.pdf', 'page': 14}
{'source': 'docs/cs229_lectures/MachineLearning-Lecture03.pdf', 'page': 4}
从查询本身推断元数据过滤条件:
from langchain.llms import OpenAI
from langchain.retrievers.self_query.base import SelfQueryRetriever
from langchain.chains.query_constructor.base import AttributeInfometadata_field_info = [AttributeInfo(name="source",description="The lecture the chunk is from, should be one of `docs/cs229_lectures/MachineLearning-Lecture01.pdf`, `docs/cs229_lectures/MachineLearning-Lecture02.pdf`, or `docs/cs229_lectures/MachineLearning-Lecture03.pdf`",type="string",),AttributeInfo(name="page",description="The page from the lecture",type="integer",),
]document_content_description = "Lecture notes"
llm = OpenAI(temperature=0)
retriever = SelfQueryRetriever.from_llm(llm,vectordb,document_content_description,metadata_field_info,verbose=True
)question = "what did they say about regression in the third lecture?"
docs = retriever.get_relevant_documents(question)
query='regression' filter=Comparison(comparator=<Comparator.EQ: 'eq'>, attribute='source', value='docs/cs229_lectures/MachineLearning-Lecture03.pdf') limit=None
for d in docs:print(d.metadata)
{'source': 'docs/cs229_lectures/MachineLearning-Lecture03.pdf', 'page': 14}
{'source': 'docs/cs229_lectures/MachineLearning-Lecture03.pdf', 'page': 0}
{'source': 'docs/cs229_lectures/MachineLearning-Lecture03.pdf', 'page': 10}
{'source': 'docs/cs229_lectures/MachineLearning-Lecture03.pdf', 'page': 10}
通过上述的两种方法(一种是手动塞入元数据过滤条件,一种是靠模型自动推断过滤条件)解决了第四节中相似性搜索中无法关注结构化信息的问题。
压缩技巧的使用示例:
from langchain.retrievers import ContextualCompressionRetriever
from langchain.retrievers.document_compressors import LLMChainExtractordef pretty_print_docs(docs):print(f"\n{'-' * 100}\n".join([f"Document {i+1}:\n\n" + d.page_content for i, d in enumerate(docs)]))# Wrap our vectorstore
llm = OpenAI(temperature=0)
compressor = LLMChainExtractor.from_llm(llm)compression_retriever = ContextualCompressionRetriever(base_compressor=compressor,base_retriever=vectordb.as_retriever()
)question = "what did they say about matlab?"
compressed_docs = compression_retriever.get_relevant_documents(question)
pretty_print_docs(compressed_docs)
Document 1:"MATLAB is I guess part of the programming language that makes it very easy to write codes using matrices, to write code for numerical routines, to move data around, to plot data. And it's sort of an extremely easy to learn tool to use for implementing a lot of learning algorithms."
----------------------------------------------------------------------------------------------------
Document 2:"MATLAB is I guess part of the programming language that makes it very easy to write codes using matrices, to write code for numerical routines, to move data around, to plot data. And it's sort of an extremely easy to learn tool to use for implementing a lot of learning algorithms."
----------------------------------------------------------------------------------------------------
Document 3:"And the student said, "Oh, it was the MATLAB." So for those of you that don't know MATLAB yet, I hope you do learn it. It's not hard, and we'll actually have a short MATLAB tutorial in one of the discussion sections for those of you that don't know it."
----------------------------------------------------------------------------------------------------
Document 4:"And the student said, "Oh, it was the MATLAB." So for those of you that don't know MATLAB yet, I hope you do learn it. It's not hard, and we'll actually have a short MATLAB tutorial in one of the discussion sections for those of you that don't know it."
将压缩和检索技巧融合:
compression_retriever = ContextualCompressionRetriever(base_compressor=compressor,base_retriever=vectordb.as_retriever(search_type = "mmr")
)question = "what did they say about matlab?"
compressed_docs = compression_retriever.get_relevant_documents(question)
pretty_print_docs(compressed_docs)
Document 1:"MATLAB is I guess part of the programming language that makes it very easy to write codes using matrices, to write code for numerical routines, to move data around, to plot data. And it's sort of an extremely easy to learn tool to use for implementing a lot of learning algorithms."
----------------------------------------------------------------------------------------------------
Document 2:"And the student said, "Oh, it was the MATLAB." So for those of you that don't know MATLAB yet, I hope you do learn it. It's not hard, and we'll actually have a short MATLAB tutorial in one of the discussion sections for those of you that don't know it."
5.5 Other Retrievals
介绍了两种其他检索器。
from langchain.retrievers import SVMRetriever
from langchain.retrievers import TFIDFRetriever
from langchain.document_loaders import PyPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter# Load PDF
loader = PyPDFLoader("docs/cs229_lectures/MachineLearning-Lecture01.pdf")
pages = loader.load()
all_page_text=[p.page_content for p in pages]
joined_page_text=" ".join(all_page_text)# Split
text_splitter = RecursiveCharacterTextSplitter(chunk_size = 1500,chunk_overlap = 150)
splits = text_splitter.split_text(joined_page_text)# Retrieve
svm_retriever = SVMRetriever.from_texts(splits,embedding)
tfidf_retriever = TFIDFRetriever.from_texts(splits)
question = "What are major topics for this class?"
docs_svm=svm_retriever.get_relevant_documents(question)
docs_svm[0]
question = "What are major topics for this class?"
docs_svm=svm_retriever.get_relevant_documents(question)
docs_svm[0]
question = "What are major topics for this class?"
docs_svm=svm_retriever.get_relevant_documents(question)
docs_svm[0]
Document(page_content="let me just check what questions you have righ t now. So if there are no questions, I'll just \nclose with two reminders, which are after class today or as you start to talk with other \npeople in this class, I just encourage you again to start to form project partners, to try to \nfind project partners to do your project with. And also, this is a good time to start forming \nstudy groups, so either talk to your friends or post in the newsgroup, but we just \nencourage you to try to star t to do both of those today, okay? Form study groups, and try \nto find two other project partners. \nSo thank you. I'm looking forward to teaching this class, and I'll see you in a couple of \ndays. [End of Audio] \nDuration: 69 minutes", metadata={})
question = "what did they say about matlab?"
docs_tfidf=tfidf_retriever.get_relevant_documents(question)
docs_tfidf[0]
Document(page_content="Saxena and Min Sun here did, wh ich is given an image like this, right? This is actually a \npicture taken of the Stanford campus. You can apply that sort of cl ustering algorithm and \ngroup the picture into regions. Let me actually blow that up so that you can see it more \nclearly. Okay. So in the middle, you see the lines sort of groupi ng the image together, \ngrouping the image into [inaudible] regions. \nAnd what Ashutosh and Min did was they then applied the learning algorithm to say can \nwe take this clustering and us e it to build a 3D model of the world? And so using the \nclustering, they then had a lear ning algorithm try to learn what the 3D structure of the \nworld looks like so that they could come up with a 3D model that you can sort of fly \nthrough, okay? Although many people used to th ink it's not possible to take a single \nimage and build a 3D model, but using a lear ning algorithm and that sort of clustering \nalgorithm is the first step. They were able to. \nI'll just show you one more example. I like this because it's a picture of Stanford with our \nbeautiful Stanford campus. So again, taking th e same sort of clustering algorithms, taking \nthe same sort of unsupervised learning algor ithm, you can group the pixels into different \nregions. And using that as a pre-processing step, they eventually built this sort of 3D model of Stanford campus in a single picture. You can sort of walk into the ceiling, look", metadata={})
6. Question Answering

对文档检索完成后,可以将检索结果输入到最终的LLM,让其回答问题。本小节介绍了几种完成这一任务的方法。
6.1 RetrievalQA Chain

当检索结果非常大时,可能会超出LLM的上下文Token限制,这时就需要对这些检索结果进行提炼,一般有下面三种方法:

这些方法在之前的LangChain课程中介绍过了,其原理分别是:
- Map_reduce:将每一个命中的文档分块输入到LLM中进行总结,然后将多个Chunk的经过总结后的更短的文本一起当做上下文,输入到最终的LLM中回答问题。其优点是可以对任意数量的文档进行回答,缺点是有些上下文分布在不同的分块中,可能没办法给出好的回答。
- Refine:类似于递归操作,将第一个文档分块输入到LLM中进行总结,然后将其与第二个文档分块再输入到LLM中进行总结,如此往复,直到得到最终的总结结果,再输入到LLM中回答问题。
- Map_rerank:前面的过程类似,不过会给每一个总结后的文本一个分数,然后对这些总结进行排序,选择分数最高的输入到LLM中回答问题。
6.2 Usage Examples

from langchain.vectorstores import Chroma
from langchain.embeddings.openai import OpenAIEmbeddings
persist_directory = 'docs/chroma/'
embedding = OpenAIEmbeddings()
vectordb = Chroma(persist_directory=persist_directory, embedding_function=embedding)question = "What are major topics for this class?"
docs = vectordb.similarity_search(question,k=3)
len(docs)
from langchain.chat_models import ChatOpenAI
llm = ChatOpenAI(model_name=llm_name, temperature=0)
from langchain.chains import RetrievalQAqa_chain = RetrievalQA.from_chain_type(llm,retriever=vectordb.as_retriever()
)
result = qa_chain({"query": question})
result["result"]
'The major topic for this class is machine learning. Additionally, the class may cover statistics and algebra as refreshers in the discussion sections. Later in the quarter, the discussion sections will also cover extensions for the material taught in the main lectures.'
from langchain.prompts import PromptTemplate# Build prompt
template = """Use the following pieces of context to answer the question at the end. If you don't know the answer, just say that you don't know, don't try to make up an answer. Use three sentences maximum. Keep the answer as concise as possible. Always say "thanks for asking!" at the end of the answer.
{context}
Question: {question}
Helpful Answer:"""
QA_CHAIN_PROMPT = PromptTemplate.from_template(template)# Run chain
qa_chain = RetrievalQA.from_chain_type(llm,retriever=vectordb.as_retriever(),return_source_documents=True,chain_type_kwargs={"prompt": QA_CHAIN_PROMPT}
)question = "Is probability a class topic?"
result = qa_chain({"query": question})
result["result"]
'Yes, probability is assumed to be a prerequisite for this class. The instructor assumes familiarity with basic probability and statistics, and will go over some of the prerequisites in the discussion sections as a refresher course. Thanks for asking!'
qa_chain_mr = RetrievalQA.from_chain_type(llm,retriever=vectordb.as_retriever(),chain_type="map_reduce"
)result = qa_chain_mr({"query": question})
result["result"]
'There is no clear answer to this question based on the given portion of the document. The document mentions familiarity with basic probability and statistics as a prerequisite for the class, and there is a brief mention of probability in the text, but it is not clear if it is a main topic of the class. The instructor mentions using a probabilistic interpretation to derive a learning algorithm, but does not go into further detail about probability as a topic.'
qa_chain_mr = RetrievalQA.from_chain_type(llm,retriever=vectordb.as_retriever(),chain_type="map_reduce"
)result = qa_chain_mr({"query": question})
result["result"]
'There is no clear answer to this question based on the given portion of the document. The document mentions familiarity with basic probability and statistics as a prerequisite for the class, and there is a brief mention of probability in the text, but it is not clear if it is a main topic of the class. The instructor mentions using a probabilistic interpretation to derive a learning algorithm, but does not go into further detail about probability as a topic.'
qa_chain_mr = RetrievalQA.from_chain_type(llm,retriever=vectordb.as_retriever(),chain_type="refine"
)result = qa_chain_mr({"query": question})
result["result"]
"The main topic of the class is machine learning, but the course assumes that students are familiar with basic probability and statistics, including random variables, expectation, variance, and basic linear algebra. The instructor will provide a refresher course on these topics in some of the discussion sections. Later in the quarter, the discussion sections will also cover extensions for the material taught in the main lectures. Machine learning is a vast field, and there are a few extensions that the instructor wants to teach but didn't have time to cover in the main lectures. The class will not be very programming-intensive, but some programming will be done in MATLAB or Octave."
使用这三种方法的LLM返回的答案不相同,并且效果相差很大,有些能概率性地引用原文内容或者回答一部分相关的内容,但是仍然相差甚远。原因是,目前的方案中还都是无状态的,没有记住过去的相关问题或者答案。下一节将介绍如何能让模型能够具有记忆。


7. Chat
7.1 ConversationalRetrievalChain

7.2 Usage Examples

文本
from langchain.vectorstores import Chroma
from langchain.embeddings.openai import OpenAIEmbeddings
persist_directory = 'docs/chroma/'
embedding = OpenAIEmbeddings()
vectordb = Chroma(persist_directory=persist_directory, embedding_function=embedding)
question = "What are major topics for this class?"
docs = vectordb.similarity_search(question,k=3)
len(docs)
3
from langchain.chat_models import ChatOpenAI
llm = ChatOpenAI(model_name=llm_name, temperature=0)
llm.predict("Hello world!")
'Hello there! How can I assist you today?'
# Build prompt
from langchain.prompts import PromptTemplate
template = """Use the following pieces of context to answer the question at the end. If you don't know the answer, just say that you don't know, don't try to make up an answer. Use three sentences maximum. Keep the answer as concise as possible. Always say "thanks for asking!" at the end of the answer.
{context}
Question: {question}
Helpful Answer:"""
QA_CHAIN_PROMPT = PromptTemplate(input_variables=["context", "question"],template=template,)# Run chain
from langchain.chains import RetrievalQA
question = "Is probability a class topic?"
qa_chain = RetrievalQA.from_chain_type(llm,retriever=vectordb.as_retriever(),return_source_documents=True,chain_type_kwargs={"prompt": QA_CHAIN_PROMPT})result = qa_chain({"query": question})
result["result"]
'Yes, probability is assumed to be a prerequisite for this class. The instructor assumes familiarity with basic probability and statistics, and will go over some of the prerequisites in the discussion sections as a refresher course. Thanks for asking!'
Memory
from langchain.memory import ConversationBufferMemory
memory = ConversationBufferMemory(memory_key="chat_history",return_messages=True
)
ConversationalRetrievalChain
from langchain.chains import ConversationalRetrievalChain
retriever=vectordb.as_retriever()
qa = ConversationalRetrievalChain.from_llm(llm,retriever=retriever,memory=memory
)
question = "Is probability a class topic?"
result = qa({"question": question})
result['answer']
'Yes, probability is a topic that will be assumed to be familiar to students in this class. The instructor assumes that students have familiarity with basic probability and statistics, and that most undergraduate statistics classes will be more than enough.'
question = "why are those prerequesites needed?"
result = qa({"question": question})
result['answer']
'The reason for requiring familiarity with basic probability and statistics as prerequisites for this class is that the class assumes that students already know what random variables are, what expectation is, what a variance or a random variable is. The class will not be very programming intensive, but will involve some programming in either MATLAB or Octave.'
7.3 Create a chatbot that works on your documents
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import CharacterTextSplitter, RecursiveCharacterTextSplitter
from langchain.vectorstores import DocArrayInMemorySearch
from langchain.document_loaders import TextLoader
from langchain.chains import RetrievalQA, ConversationalRetrievalChain
from langchain.memory import ConversationBufferMemory
from langchain.chat_models import ChatOpenAI
from langchain.document_loaders import TextLoader
from langchain.document_loaders import PyPDFLoader
The chatbot code has been updated a bit since filming. The GUI appearance also varies depending on the platform it is running on.
def load_db(file, chain_type, k):# load documentsloader = PyPDFLoader(file)documents = loader.load()# split documentstext_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=150)docs = text_splitter.split_documents(documents)# define embeddingembeddings = OpenAIEmbeddings()# create vector database from datadb = DocArrayInMemorySearch.from_documents(docs, embeddings)# define retrieverretriever = db.as_retriever(search_type="similarity", search_kwargs={"k": k})# create a chatbot chain. Memory is managed externally.qa = ConversationalRetrievalChain.from_llm(llm=ChatOpenAI(model_name=llm_name, temperature=0), chain_type=chain_type, retriever=retriever, return_source_documents=True,return_generated_question=True,)return qa import panel as pn
import paramclass cbfs(param.Parameterized):chat_history = param.List([])answer = param.String("")db_query = param.String("")db_response = param.List([])def __init__(self, **params):super(cbfs, self).__init__( **params)self.panels = []self.loaded_file = "docs/cs229_lectures/MachineLearning-Lecture01.pdf"self.qa = load_db(self.loaded_file,"stuff", 4)def call_load_db(self, count):if count == 0 or file_input.value is None: # init or no file specified :return pn.pane.Markdown(f"Loaded File: {self.loaded_file}")else:file_input.save("temp.pdf") # local copyself.loaded_file = file_input.filenamebutton_load.button_style="outline"self.qa = load_db("temp.pdf", "stuff", 4)button_load.button_style="solid"self.clr_history()return pn.pane.Markdown(f"Loaded File: {self.loaded_file}")def convchain(self, query):if not query:return pn.WidgetBox(pn.Row('User:', pn.pane.Markdown("", width=600)), scroll=True)result = self.qa({"question": query, "chat_history": self.chat_history})self.chat_history.extend([(query, result["answer"])])self.db_query = result["generated_question"]self.db_response = result["source_documents"]self.answer = result['answer'] self.panels.extend([pn.Row('User:', pn.pane.Markdown(query, width=600)),pn.Row('ChatBot:', pn.pane.Markdown(self.answer, width=600, style={'background-color': '#F6F6F6'}))])inp.value = '' #clears loading indicator when clearedreturn pn.WidgetBox(*self.panels,scroll=True)@param.depends('db_query ', )def get_lquest(self):if not self.db_query :return pn.Column(pn.Row(pn.pane.Markdown(f"Last question to DB:", styles={'background-color': '#F6F6F6'})),pn.Row(pn.pane.Str("no DB accesses so far")))return pn.Column(pn.Row(pn.pane.Markdown(f"DB query:", styles={'background-color': '#F6F6F6'})),pn.pane.Str(self.db_query ))@param.depends('db_response', )def get_sources(self):if not self.db_response:return rlist=[pn.Row(pn.pane.Markdown(f"Result of DB lookup:", styles={'background-color': '#F6F6F6'}))]for doc in self.db_response:rlist.append(pn.Row(pn.pane.Str(doc)))return pn.WidgetBox(*rlist, width=600, scroll=True)@param.depends('convchain', 'clr_history') def get_chats(self):if not self.chat_history:return pn.WidgetBox(pn.Row(pn.pane.Str("No History Yet")), width=600, scroll=True)rlist=[pn.Row(pn.pane.Markdown(f"Current Chat History variable", styles={'background-color': '#F6F6F6'}))]for exchange in self.chat_history:rlist.append(pn.Row(pn.pane.Str(exchange)))return pn.WidgetBox(*rlist, width=600, scroll=True)def clr_history(self,count=0):self.chat_history = []return Create a chatbot
cb = cbfs()file_input = pn.widgets.FileInput(accept='.pdf')
button_load = pn.widgets.Button(name="Load DB", button_type='primary')
button_clearhistory = pn.widgets.Button(name="Clear History", button_type='warning')
button_clearhistory.on_click(cb.clr_history)
inp = pn.widgets.TextInput( placeholder='Enter text here…')bound_button_load = pn.bind(cb.call_load_db, button_load.param.clicks)
conversation = pn.bind(cb.convchain, inp) jpg_pane = pn.pane.Image( './img/convchain.jpg')tab1 = pn.Column(pn.Row(inp),pn.layout.Divider(),pn.panel(conversation, loading_indicator=True, height=300),pn.layout.Divider(),
)
tab2= pn.Column(pn.panel(cb.get_lquest),pn.layout.Divider(),pn.panel(cb.get_sources ),
)
tab3= pn.Column(pn.panel(cb.get_chats),pn.layout.Divider(),
)
tab4=pn.Column(pn.Row( file_input, button_load, bound_button_load),pn.Row( button_clearhistory, pn.pane.Markdown("Clears chat history. Can use to start a new topic" )),pn.layout.Divider(),pn.Row(jpg_pane.clone(width=400))
)
dashboard = pn.Column(pn.Row(pn.pane.Markdown('# ChatWithYourData_Bot')),pn.Tabs(('Conversation', tab1), ('Database', tab2), ('Chat History', tab3),('Configure', tab4))
)
dashboard



8. Conclusion
相关文章:
吴恩达ChatGPT《LangChain Chat with Your Data》笔记
文章目录 1. Introduction2. Document Loading2.1 Retrieval Augmented Generation(RAG)2.2 Load PDFs2.3 Load YouTube2.4 Load URLs2.5 Load Notion 3. Document Splitting3.1 Splitter Flow3.2 Character Splitter3.3 Token Splitter3.4 Markdown Spl…...

https和http有什么区别
https和http有什么区别 简要 区别如下: https的端口是443.而http的端口是80,且二者连接方式不同;http传输时明文,而https是用ssl进行加密的,https的安全性更高;https是需要申请证书的,而h…...
振弦采集仪及在线监测系统完整链条的岩土工程隧道安全监测
振弦采集仪及在线监测系统完整链条的岩土工程隧道安全监测 近年来,随着城市化的不断推进和基础设施建设的不断发展,隧道建设也日益成为城市交通发展的必需品。然而,隧道建设中存在着一定的安全隐患,如地质灾害、地下水涌流等&…...
linux基础学习
1.day1 2.day2 1、VIM配置; 2、安装SSH,调用putty接入终端; 3、shell命令; *:匹配任意长度的字符 ?:匹配一个长度的字符 [...]:匹配其中指定的一个字符 [-]:匹配指定…...
)
android 前端常用布局文件升级总结(二)
问题一: android:name“android.support.v4.content.FileProvider” 报红 问题解决方案: 把xml布局文件里面: android.support.v4.content.FileProvider 更换成 androidx.core.content.FileProvider 问题二: android.support.design.wid…...

Linux复习——基础知识
作者简介:一名云计算网络运维人员、每天分享网络与运维的技术与干货。 座右铭:低头赶路,敬事如仪 个人主页:网络豆的主页 1. 有关早期linux系统中 sysvin的init的7个级别描述正确的是( )[选择1项] A. init 1 关机状态 B. init 2 字符界面多用户模式 …...
【数据结构】实验三:链表
实验三链表 一、实验目的与要求 1)熟悉链表的类型定义; 2)熟悉链表的基本操作; 3)灵活应用链表解决具体应用问题。 二、实验内容 1)请设计一个单链表的存储结构,并实现单链表中基本运算算…...

第4集丨webpack 江湖 —— loader的安装和使用
目录 一、loader简介1.1 使用 loader1.1.1 配置文件方式1.1.2 内联方式 1.2 loader 特性1.3 解析 loader1.4 命名规范 二、css loader的安装和使用2.1 安装2.2 配置2.3 测试 三、 less-loader 的安装和使用3.1 安装3.2 配置3.3 测试3.4 附件3.4.1 webpack.config.js3.4.2 index…...

【Lua学习笔记】Lua进阶——协程
文章目录 协程协程的定义和调度StatusRunning 协程 协程是一种并发操作,相比于线程,线程在执行时往往是并行的,并且线程在创建销毁执行时极其消耗资源,并且过长的执行时间会造成主进程阻塞。而协程可以以并发时轮值时间片来执行&…...

亚马逊云科技纽约峰会,充分释放数据价值和生成式AI的潜力
生成式AI将深刻改变每个公司的运营方式,标志着人工智能技术发展的新转折点。亚马逊云科技昨日在纽约峰会上宣布,推出七项生成式AI新功能,进一步降低了生成式AI的使用门槛,让无论是业务用户还是开发者都能从中受益。借助这些新功能…...

什么是 web3?
在百度搜索引擎输入 “Web3”、“大厂”。跳出来基本都是这样的标题. 以及如今的互联网行业 “哀鸿遍野”,不仅内卷,还裁员。然后掀起一阵风,猛吹 Web3 的好,数据回归用户……最后再 “威逼利诱” 一下,Web3 就是 20 年…...
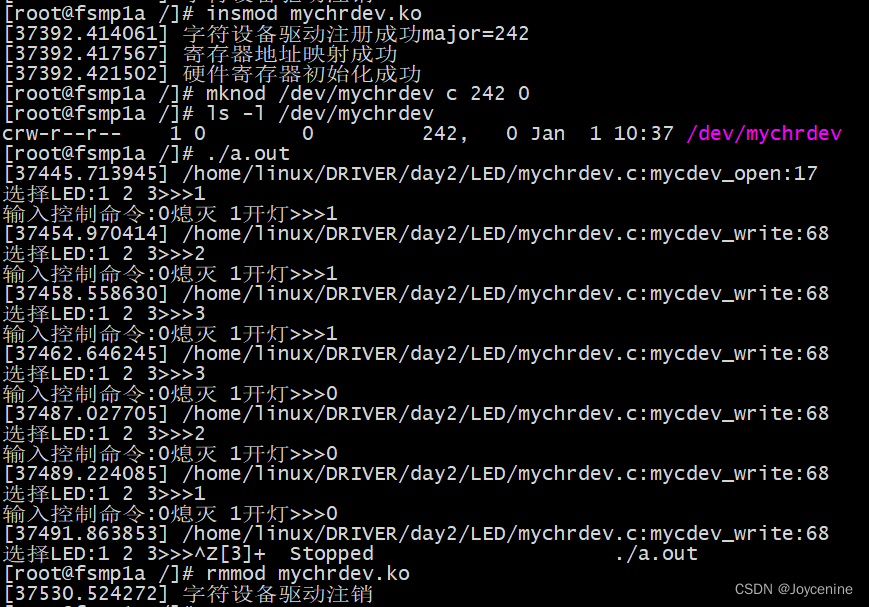
[驱动开发]字符设备驱动应用——点灯
点亮开发板stm32mp157的三盏灯 //头文件 #ifndef __LED_H__ #define __LED_H__//封装GPIO寄存器 typedef struct { volatile unsigned int MODER; // 0x00volatile unsigned int OTYPER; // 0x04volatile unsign…...

前端学习——Vue (Day5)
自定义指令 <template><div><h1>自定义指令</h1><input v-focus ref"inp" type"text" /></div> </template><script> export default {// mounted(){// this.$ref.inp.focus()// }// 2. 局部注册指令di…...
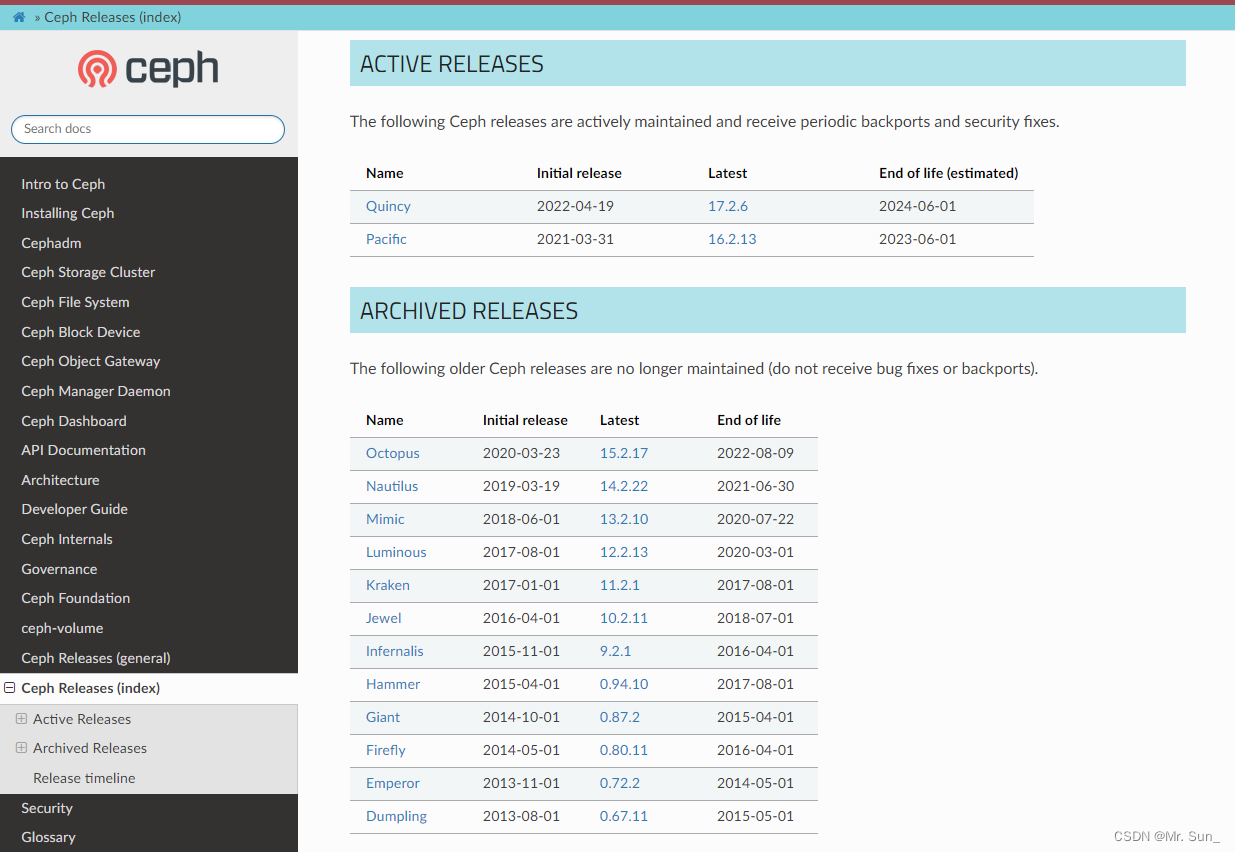
Ceph版本
每个Ceph的版本都有一个英文的名称和一个数字形式的版本编号 第一个 Ceph 版本编号是 0.1,发布于2008 年 1月。之后是0.2,0.3....多年来,版本号方案一直没变。 2015年 4月0.94.1 (Hammer 的第一个修正版) 发布后,为了避免 0.99 (以及 0.100…...
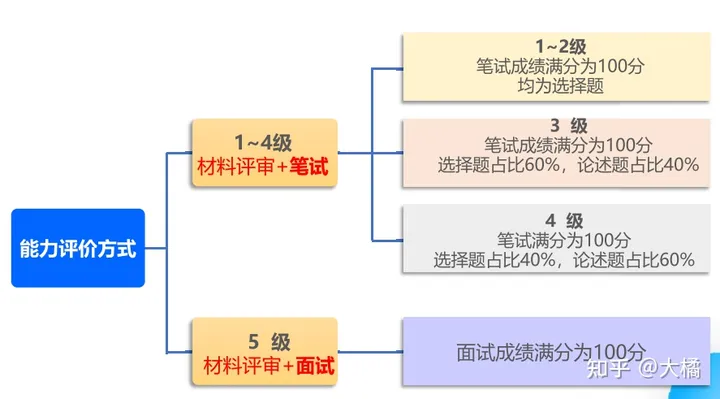
cspm是什么?考了有用吗?
CSPM是项目管理专业人员能力评价等级证书,相当于 PMP 的本土化,CSPM 相关问题大家都很关心,今天就给大家全面解答一下 CSPM到底是何方神圣? 文章主要是解答下面几个常见问题,其他问题可以留言或者私信咨询我哦~ 一、什…...

Java阶段五Day14
Java阶段五Day14 文章目录 Java阶段五Day14分布式事务整合demo案例中架构,代码关系发送半消息本地事务完成检查补偿购物车消费 鲁班周边环境调整前端启动介绍启动前端 直接启动的项目gateway(网关)login(登录注册)atta…...
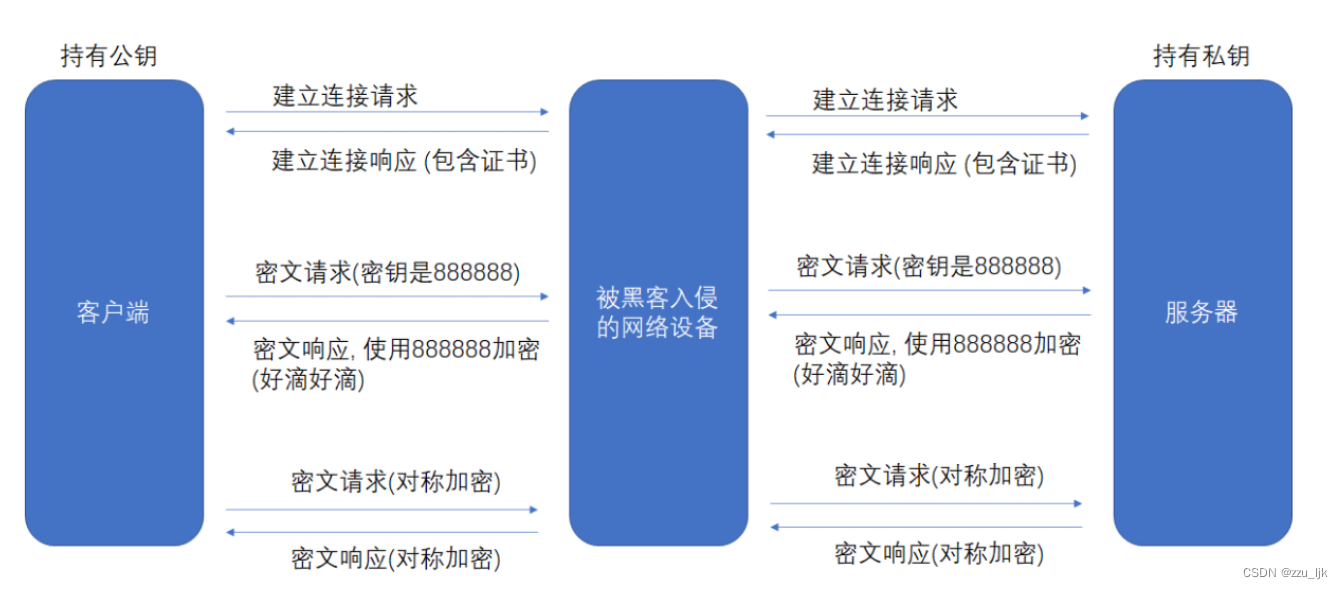
【计算机网络】应用层协议 -- 安全的HTTPS协议
文章目录 1. 认识HTTPS2. 使用HTTPS加密的必要性3. 常见的加密方式3.1 对称加密3.2 非对称加密3.3 非对称加密对称加密 4. 引入CA证书4.1 CA认证4.2 数据签名4.3 非对称机密对称加密证书认证4.4 常见问题 5. 总结 1. 认识HTTPS HTTPS全称为 Hyper Text Tranfer Protocol over …...
小程序通过ip+port+路径获取服务器中的图片
配置IIS 首先需要配置IIS。 打开控制面板,接下来的流程按下图所示。 安装好后,按“win”键,搜索IIS 选择一个ip地址,或手动填写,端口号按需更改...
(A-F))
Codeforces Round 888 (Div. 3)(A-F)
文章目录 ABCDEF A 题意: 就是有一个m步的楼梯。每一层都有k厘米高,现在A的身高是H,给了你n个人的身高问有多少个人与A站在不同层的楼梯高度相同。 思路: 我们只需要去枚举对于A来说每一层和他一样高(人的身高和楼…...
、多卷积核、全连接、池化)
【人工智能】深度神经网络、卷积神经网络(CNN)、多卷积核、全连接、池化
深度神经网络、卷积神经网络(CNN)、多卷积核、全连接、池化) 文章目录 深度神经网络、卷积神经网络(CNN)、多卷积核、全连接、池化)深度神经网络训练训练深度神经网络参数共享卷积神经网络(CNN)卷积多卷积核卷积全连接最大池化卷积+池化拉平向量激活函数优化小结深度神经…...

AI Agent在智能风控中的实战:多智能体欺诈检测与预警
AI Agent在智能风控中的实战:多智能体欺诈检测与预警 你有没有过明明是正常交易却被银行冻结账户的糟糕体验?或是听说过某电商平台上线新活动首日就被黑产团伙薅走数千万补贴的新闻?随着黑产欺诈向团伙化、专业化、动态化演进,传统依赖规则引擎、单模型机器学习的风控体系已…...

艾尔登法环帧率解锁终极指南:告别卡顿,畅享丝滑游戏体验
艾尔登法环帧率解锁终极指南:告别卡顿,畅享丝滑游戏体验 【免费下载链接】EldenRingFpsUnlockAndMore A small utility to remove frame rate limit, change FOV, add widescreen support and more for Elden Ring 项目地址: https://gitcode.com/gh_m…...

智能手机相机光谱特性测量与多光谱成像技术
1. 智能手机相机光谱特性测量基础智能手机相机的光谱灵敏度函数(Spectral Sensitivity Function, SSF)和透射率函数是计算摄影领域的核心参数,它们决定了设备对光信号的响应特性。准确获取这些参数对色彩还原、光谱重建和白平衡校准等任务至关重要。1.1 光谱灵敏度函…...

小米MIMO最新邀请码
欢迎使用,各得10元体验金...

告别手写UI!用NXP GUI Guider拖拽设计LVGL界面,5分钟搞定音乐播放器Demo
嵌入式UI开发革命:5分钟用GUI Guider构建LVGL音乐播放器在嵌入式系统开发中,用户界面(UI)设计曾长期是工程师的痛点——既要考虑资源受限的硬件环境,又要实现流畅美观的交互体验。传统手动编写UI代码的方式不仅效率低下,调试过程更…...

2026年一键生成论文工具对比实测:5款神器从选题到格式全流程护航
写论文的焦虑,是每个科研人和学生都心照不宣的“隐形压力”。选题无从下手,文献检索耗时费力,逻辑框架反复推翻,格式排版让人抓狂,查重降重更是像在和系统玩“猫鼠游戏”。2026年的AI工具早已不是过去那种“打字机”&a…...

终极指南:5步快速掌握免费的3D点云标注工具labelCloud
终极指南:5步快速掌握免费的3D点云标注工具labelCloud 【免费下载链接】labelCloud A lightweight tool for labeling 3D bounding boxes in point clouds. 项目地址: https://gitcode.com/gh_mirrors/la/labelCloud 想要为自动驾驶、机器人视觉或3D目标检测…...

氘可来昔替尼常见副作用为鼻咽炎头痛及腹泻,如何应对
任何口服药物的临床价值,都必须在疗效与安全性的天平上找到精准的平衡点。氘可来昔替尼以PASI 75应答率的全面胜出证明了自己在银屑病治疗中的卓越地位,而其不良反应谱同样经过了严苛的临床验证。鼻咽炎、头痛和腹泻构成了这款药物最需关注的三大安全信号…...

5步彻底解决Windows DLL加载冲突:UE4SS系统故障排查指南
5步彻底解决Windows DLL加载冲突:UE4SS系统故障排查指南 【免费下载链接】RE-UE4SS Injectable LUA scripting system, SDK generator, live property editor and other dumping utilities for UE4/5 games 项目地址: https://gitcode.com/gh_mirrors/re/RE-UE4SS…...

XXPermissions:Android权限管理框架的架构设计与最佳实践
XXPermissions:Android权限管理框架的架构设计与最佳实践 【免费下载链接】XXPermissions Android Permissions Framework, Adapt to Android 16 项目地址: https://gitcode.com/GitHub_Trending/xx/XXPermissions 在Android应用开发中,权限管理一…...