神经网络随记-参数矩阵、剪枝、模型压缩、大小匹配、、
神经网络的参数矩阵
在神经网络中,参数矩阵是模型学习的关键部分,它包含了神经网络的权重和偏置项。下面是神经网络中常见的参数矩阵:
-
权重矩阵(Weight Matrix):权重矩阵用于线性变换操作,将输入数据与神经元的连接权重相乘。对于全连接层或线性层,每个神经元都有一个权重矩阵。权重矩阵的维度取决于输入和输出的大小,通常表示为
(input_size, output_size),其中input_size是输入特征的维度,output_size是输出特征的维度。 -
偏置向量(Bias Vector):偏置向量用于线性变换操作中的偏移项,对输入数据进行平移。每个神经元都有一个偏置向量,与权重矩阵相加后,进一步通过激活函数进行非线性变换。偏置向量的维度与输出特征的维度相同。
这些权重矩阵和偏置向量的参数是在神经网络的训练过程中学习得到的,通过最小化损失函数来优化模型的预测结果。优化算法(如梯度下降)会根据损失函数的梯度对这些参数进行更新,以使模型能够更好地拟合训练数据。
需要注意的是,这些参数矩阵的数量和维度取决于神经网络的结构和层的数量。在深层神经网络中,可能会有多个层和多个权重矩阵与偏置向量。此外,一些特殊的神经网络结构(如卷积神经网络、循环神经网络)可能具有特定类型的参数矩阵(如卷积核、循环权重等)。
通过学习适当的参数矩阵,神经网络可以自动学习输入数据的特征表示,并用于进行预测、分类、生成等任务。
线性函数作为激活函数的缺陷
线性函数作为激活函数的主要缺陷是其有限的表达能力和缺乏非线性特征的学习能力。下面是线性函数作为激活函数的一些缺点:
-
限制表达能力:线性函数无法表示复杂的非线性关系。由于线性函数的输出与输入之间存在线性关系,它无法捕捉到数据中的非线性特征和复杂模式,限制了神经网络的表达能力。
-
局限性:线性函数无法解决线性不可分的问题。许多实际问题的数据具有复杂的非线性关系,使用线性函数作为激活函数的神经网络无法有效地拟合这些数据,导致性能下降。
-
梯度消失问题:线性函数的导数恒为常数,这会导致反向传播过程中的梯度消失问题。梯度消失会影响网络的训练速度和收敛性,使得网络难以学习到深层次的特征。
-
对称性:线性函数具有对称性,即对称地分布在原点两侧。这种对称性限制了神经网络的表示能力和学习能力,使其难以模拟复杂的非线性映射。
为了克服线性函数的缺陷,通常会使用非线性的激活函数,如Sigmoid、ReLU、Tanh等。这些非线性激活函数可以引入非线性特征,提高神经网络的表达能力,更好地适应复杂的数据模式和非线性关系。
剪枝
在神经网络中,剪枝是一种用于减少模型复杂性和提高模型效率的技术。它通过移除神经网络中的冗余连接或神经元,从而减少模型的参数量和计算量,同时保持模型的性能。
神经网络中的剪枝可以应用于不同层面,包括剪枝神经元、剪枝连接和剪枝结构等。
-
剪枝神经元(Neuron Pruning):剪枝神经元是指从神经网络中移除部分不重要的神经元。这些神经元可以是输出低于阈值的神经元、对整体模型贡献较小的神经元或者不活跃的神经元。剪枝神经元可以减少模型的计算量和存储需求。
-
剪枝连接(Connection Pruning):剪枝连接是指从神经网络中移除一些不重要的连接或权重。剪枝连接可以通过对连接权重进行排序并选择阈值来实现。权重低于阈值的连接可以被移除,从而减少模型的参数量和计算量。
-
剪枝结构(Structural Pruning):剪枝结构是指通过减少网络的结构复杂性来降低模型的计算量。这包括剪枝整个神经网络的某些层或剪枝某些层的特定区域。剪枝结构可以通过设置剪枝比例或选择剪枝策略来实现。
剪枝技术的应用可以帮助神经网络实现模型压缩、加速推理和减少存储需求。剪枝可以在训练后应用于已经训练好的模型,也可以与训练过程结合使用,通过迭代地剪枝和微调来优化模型。
需要注意的是,在剪枝过程中,剪枝的方式和策略需要经过合理设计和选择,以保证剪枝后的模型仍然能够保持良好的性能和泛化能力。剪枝过度可能导致性能下降,因此需要进行合适的剪枝程度和剪枝策略的选择。
模型压缩
模型压缩是一种通过减少神经网络模型的大小和计算量,以达到减少存储需求、提高推理速度和降低功耗的技术。模型压缩在深度学习领域中非常重要,特别是在移动设备和嵌入式系统等资源受限的场景下。
下面介绍几种常见的模型压缩技术:
-
参数剪枝(Parameter Pruning):通过剪枝神经网络中的不重要连接或神经元,减少模型的参数量。剪枝可以基于权重大小、梯度信息或其他准则进行。剪枝后的模型可以保持较小的存储需求和计算量,同时尽量保持性能。
-
权重量化(Weight Quantization):将浮点型权重转换为较低位数的定点或整数表示,从而减少存储空间和计算量。例如,将权重从32位浮点型量化为8位整数,可以将模型的大小减小为原来的四分之一。
-
网络结构剪枝(Network Structure Pruning):通过剪枝神经网络中的不重要连接、层或结构,减少模型的复杂性和计算量。可以通过剪枝策略、剪枝比例和剪枝算法来实现。结构剪枝可以结合剪枝和微调过程,通过迭代地剪枝和微调来优化模型。
-
低秩近似(Low-Rank Approximation):通过对模型权重矩阵进行低秩分解,将其表示为较小秩的近似矩阵,从而减少模型的参数量和计算量。低秩近似可以通过奇异值分解(SVD)等技术实现。
-
知识蒸馏(Knowledge Distillation):通过将一个大型、复杂模型的知识转移给一个小型、简化模型,从而压缩模型大小并保持性能。知识蒸馏通过训练小型模型去拟合大型模型的预测结果或中间表示,以实现模型压缩。
-
迁移学习(Transfer Learning):利用已经训练好的大型模型的参数和特征表示,对目标任务的小型模型进行初始化或微调。迁移学习可以减少小型模型的训练时间和数据需求,并且可以借助大型模型的表示能力提升性能。
这些模型压缩技术可以单独或组合使用,根据具体任务和需求选择适合的方法。同时,模型压缩需要在保持性能的同时权衡压缩程度、推理速度和存储需求。在实践中,通常需要对压缩后的模型进行评估和微调,以获得最佳的性能和压缩效果。
数据集大小和模型大小怎么匹配
数据集大小和模型大小的匹配是深度学习模型训练中非常重要的问题,合理匹配可以提高模型的性能和泛化能力。下面是一些指导原则,可以帮助数据集大小和模型大小的匹配:
-
数据集大小要足够大:较大的数据集有助于模型学习更多的特征和模式,提高泛化能力。通常情况下,数据集大小应该能够覆盖模型参数的数量几倍以上。
-
数据集要具有代表性:确保数据集涵盖了模型可能会遇到的不同情况和样本,以便让模型学习到更全面的特征。
-
模型大小要适中:模型的大小和复杂度应该适合数据集的规模和复杂程度。如果数据集较小,使用过于复杂的模型可能导致过拟合。
-
选择合适的模型结构:在模型设计阶段,应该根据数据集的特点选择合适的模型结构,避免使用过于复杂的模型,使其能够更好地拟合数据。
-
使用预训练模型:对于较小的数据集,可以考虑使用预训练模型,利用预训练的参数来初始化模型,并进行微调。
-
交叉验证:使用交叉验证来评估模型在不同数据集划分上的性能,以了解模型在不同数据集规模上的表现。
-
数据增强:对于小数据集,可以使用数据增强技术来扩充数据,增加样本的多样性,提高模型的泛化能力。
总的来说,数据集大小和模型大小之间的匹配是一个动态调整的过程,需要综合考虑数据集的规模、复杂程度和模型的设计。选择合适的数据集和模型可以提高模型的性能,使其更好地适应实际应用。
如何通过float转int的方法进行模型的优化
通过将模型参数从浮点数转换为整数(float转int)可以实现模型的优化,主要优点包括减少模型的存储需求和加快计算速度,从而提高模型在嵌入式设备或资源受限环境中的执行效率。以下是一些常见的方法用于模型优化:
-
量化(Quantization):将模型参数由浮点数转换为定点数。在量化中,可以将浮点数参数映射到一个有限的整数范围内。常用的量化方式有对称量化和非对称量化。对称量化将参数映射到整数范围中心附近,而非对称量化将参数映射到整数范围的两端。
-
低精度训练(Low-Precision Training):在模型训练过程中,可以使用低精度的浮点数进行计算,例如16位浮点数(half-precision)或8位浮点数(bfloat16)。低精度训练可以减少计算开销,并在一定程度上减轻过拟合问题。
-
网络剪枝(Network Pruning):通过剪枝模型中冗余的参数和连接,减小模型大小。剪枝可以去除对模型性能影响较小的参数,使得模型更加轻量化。
-
知识蒸馏(Knowledge Distillation):将一个复杂的模型(教师模型)的知识转移到一个较简单的模型(学生模型)中。学生模型可以使用更低精度的参数表示,从而减少模型大小。
-
模型量化工具:一些深度学习框架提供了模型量化的工具,可以自动将浮点模型转换为定点模型,并提供了一些量化方法和优化选项。
需要注意的是,浮点转整数的方法虽然可以优化模型,但也可能会引入一定的精度损失。因此,在使用这些优化方法时,需要进行充分的测试和评估,以确保模型在精度和性能之间取得合适的平衡。
线性层和激活函数层如何交换
在深度学习中,线性层和激活函数层的顺序通常是紧密相关的,因为它们一起构成了神经网络的基本构建块。线性层用于对输入进行线性变换,而激活函数层用于引入非线性性,从而增加网络的表达能力。
在标准的神经网络中,通常的顺序是先应用线性层,然后再应用激活函数层。这被称为线性层(全连接层或卷积层)和非线性激活函数之间的交替。
示例:
- 先线性层后激活函数:
# 假设有一个线性层 fc1 和一个激活函数层 relu
import torch.nn as nn# 定义线性层
fc1 = nn.Linear(in_features=10, out_features=20) # 输入特征为10,输出特征为20# 定义激活函数层
activation = nn.ReLU()# 假设输入 x 是一个10维的张量
x = torch.randn(10)# 先应用线性层,然后再应用激活函数
output = activation(fc1(x))
- 先激活函数后线性层:
# 假设有一个线性层 fc1 和一个激活函数层 relu
import torch.nn as nn# 定义线性层
fc1 = nn.Linear(in_features=10, out_features=20) # 输入特征为10,输出特征为20# 定义激活函数层
activation = nn.ReLU()# 假设输入 x 是一个10维的张量
x = torch.randn(10)# 先应用激活函数,然后再应用线性层
output = fc1(activation(x))
两种顺序都是合理的,但在实际使用中,先应用线性层再应用激活函数的顺序更为常见。这是因为激活函数的作用是引入非线性性,使得神经网络可以拟合更为复杂的函数。如果先应用激活函数再应用线性层,输出的特征将不再是线性组合,可能导致模型表达能力的下降。因此,在大多数情况下,先应用线性层再应用激活函数是较为常见和有效的顺序。
深度学习和机器学习的区别
深度学习和机器学习是两个密切相关的领域,它们都属于人工智能(AI)的范畴,但在方法和应用上有一些区别。
-
定义和目标:
- 机器学习(Machine Learning):机器学习是一种使用算法和统计模型来让计算机从数据中学习并改进性能的方法。其目标是通过学习和发现数据的规律,从而使计算机能够做出准确的预测、分类或决策。
- 深度学习(Deep Learning):深度学习是机器学习的一种特定分支,它基于神经网络的结构和算法,通过多层次的神经元来模拟人脑的工作方式。其目标是通过学习多层次的特征表示,实现对数据的高层次抽象和复杂模式识别。
-
特征工程:
- 机器学习:在传统的机器学习方法中,通常需要手动设计和选择合适的特征表示,这称为特征工程。特征工程的质量直接影响到机器学习算法的性能。
- 深度学习:深度学习通过多层次的神经网络自动从原始数据中学习特征表示,不需要手动进行特征工程。这使得深度学习在大规模数据和复杂任务上表现出色。
-
数据量和计算力要求:
- 机器学习:传统的机器学习算法通常在小规模数据上表现良好,但在大规模数据上容易遇到性能瓶颈。
- 深度学习:深度学习的优势在于大规模数据的处理,它通常需要更多的数据来训练复杂的神经网络,并且需要大量的计算力进行模型训练。
-
应用领域:
- 机器学习:传统的机器学习方法在图像识别、自然语言处理、推荐系统等领域取得了很多成果。
- 深度学习:深度学习在图像识别、语音识别、自然语言处理、自动驾驶、游戏等领域取得了突破性的进展,并在许多领域取得了超越传统机器学习方法的效果。
虽然深度学习是机器学习的一个分支,但由于其强大的表示学习能力和优秀的性能,在许多领域已经成为主流方法。然而,机器学习仍然是一个非常广泛和重要的领域,包括许多不依赖于神经网络的方法和技术。因此,深度学习和机器学习在整个人工智能领域都有着不可或缺的作用。
深度学习和现在大模型的区别
深度学习是一种机器学习方法的特定分支,其核心是通过多层次的神经网络模拟人脑的工作方式,实现对数据的高层次抽象和复杂模式识别。而现在大模型指的是一类特别庞大、参数众多的神经网络模型,例如BERT、GPT-3等。
主要区别如下:
-
规模和参数量:
- 深度学习:深度学习是一类方法,涵盖了各种规模的神经网络,包括小型神经网络、中等规模的深度学习模型等。
- 大模型:现在大模型指的是参数非常庞大的神经网络,通常拥有数亿甚至数十亿个参数。这些模型的规模远远超过传统的深度学习模型,具有更强大的学习和表示能力。
-
训练数据量:
- 深度学习:传统的深度学习模型通常需要大量的训练数据来取得好的效果,但规模相对较小的深度学习模型在数据量有限的情况下也能表现良好。
- 大模型:现在的大模型通常需要海量的训练数据来训练,因为它们具有更高的参数量和更强的表达能力,需要更多的样本来学习复杂的模式和特征。
-
训练时间和计算资源:
- 深度学习:传统的深度学习模型通常可以在相对较短的时间内训练完毕,使用较少的计算资源。
- 大模型:现在的大模型由于参数量巨大,训练时间通常需要数天甚至数周,同时需要大量的计算资源,如GPU集群或者专门的TPU硬件。
-
应用场景:
- 深度学习:传统的深度学习模型已经广泛应用于图像识别、自然语言处理、推荐系统等领域,取得了很多成果。
- 大模型:现在的大模型在自然语言处理领域表现突出,例如GPT-3在自然语言生成任务中取得了令人瞩目的成果,但由于计算资源和训练时间的限制,大模型在其他领域的应用相对较少。
总的来说,现在的大模型是深度学习的一种进化,它们具有更强大的学习和表示能力,但同时也需要更多的数据和计算资源来训练。大模型在某些特定领域表现出色,但对于一般的任务,传统的深度学习模型仍然是一种有效和实用的方法。
相关文章:

神经网络随记-参数矩阵、剪枝、模型压缩、大小匹配、、
神经网络的参数矩阵 在神经网络中,参数矩阵是模型学习的关键部分,它包含了神经网络的权重和偏置项。下面是神经网络中常见的参数矩阵: 权重矩阵(Weight Matrix):权重矩阵用于线性变换操作,将输…...

4、Kubernetes 集群 YAML 文件详解
目录 一、YAML 概述 二、YAML 基本语法 三、YAML 数据结构 四、k8s资源清单描述方法 五、YAML 快速编写 1、使用 kubectl create 命令 2、使用 kubectl get 命令导出 yaml 文件 一、YAML 概述 k8s 集群中对资源管理和资源对象编排部署都可以通过声明YAML文件来解决&…...
)
leetcode93. 复原 IP 地址(java)
复原 IP 地址 leetcode93. 复原 IP 地址回溯算法代码演示 回溯算法 leetcode93. 复原 IP 地址 有效 IP 地址 正好由四个整数(每个整数位于 0 到 255 之间组成,且不能含有前导 0),整数之间用 ‘.’ 分隔。 例如:“0.1.2…...

极光Java 版本服务器端实现别名消息推送
文章目录 引言I 概述1.1 依赖包1.2 极光证书环境参数1.3 构建推送对象II 推送内容2.1 配置推送内容2.2 获取通知消息内容2.3 配置IOS通知内容2.4 配置Android通知内容2.5 发起推送2.6 分批推送2.7 初始化密钥2.8 配置密钥引言 REST API 文档:https://docs.jiguang.cn/jpush/se…...

【Lua学习笔记】Lua进阶——Table(4)继承,封装,多态
文章目录 封装继承多态 封装 // 定义基类 Object {}//由于表的特性,该句就相当于定义基类变量 Object.id 1//该句相当于定义方法,Object可以视为定义的对象,Test可以视为方法名 //我们知道Object是一个表,但是抽象地看ÿ…...

Linux中常用的指令
ls ls [选项] [目录或文件] 功能:对于目录,列出该目录下所有的子目录和文件;对于文件,列出该文件的文件名和其他属性 常用选项: -a:列出目录下的所有文件,包括以.开头的隐藏文件 -l:列出文件的详细信息。…...
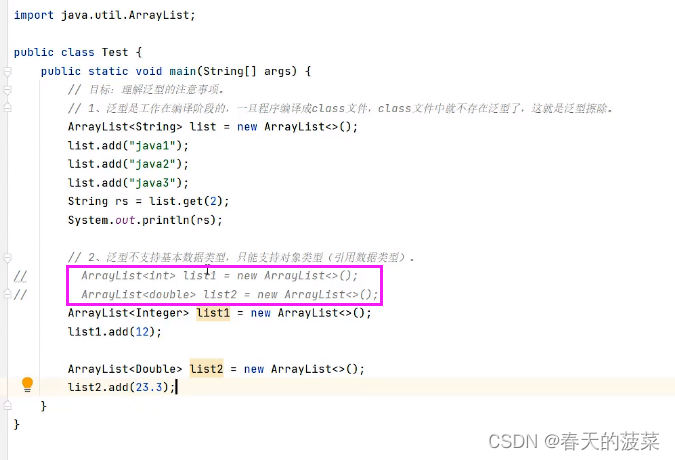
【java】【面对对象高级4】内部类、枚举、泛型
目录 1、内部类 1.1 成员内部类【了解】 1.1.1 定义 1.1.2 扩展变量 1.2 静态内部类【了解】 1.2.1 定义 1.2.2 扩展变量 1.3 局部内部类【了解】 1.4 匿名内部类【重点】 1.4.1 定义 1.4.1.1 常规写法 1.4.1.2 匿名内部类改造 1.4.2 匿名内部类的常见使用场景 1.4.2…...
)
Python的用处到底是什么?(三)
11. 数据库操作:Python的库,如sqlite3和SQLAlchemy,可以连接和操作各种类型的数据库。 Python提供了一些库和工具,如sqlite3和SQLAlchemy,用于连接和操作各种类型的数据库。以下是关于这两个库的详细解释:…...
【Nodejs】Express基本使用
Express 中文网 基于 Node.js 平台,快速、开放、极简的 web 开发框架。 1.Express的安装方式 Express的安装可直接使用npm包管理器上的项目,在安装npm之前可先安装淘宝镜像: npm install -g cnpm --registryhttps://registry.npmmirror.com/…...

k8s集群安装v1.20.9
参考网上资料并将异常问题解决,经测试可正常安装集群。 1.我的环境准备 本人使用vmware pro 17新建三个centos7虚拟机,每个2cpu,20GB磁盘存储,内存2GB,其中主节点的内存3GB,可使用外网. 2.所有节点安装D…...

Staples Drop Ship EDI 需求分析
Staples 是一家美国零售公司,总部位于马萨诸塞州弗拉明汉,主要提供支持工作和学习的产品和服务。该公司于 1986 年在马萨诸塞州布莱顿开设了第一家门店。到 1996 年,该公司已跻身《财富》世界 500 强,后来又收购了办公用品公司 Qu…...

模型调参及优化
调参 调权重参数,偏置参数 训练数据集用来训练参数w,b 调超参数 验证数据集用来选择超参数学习率lr,隐藏层大小等 如何调参 当泛化误差和训练误差都没有降下去说明欠拟合;当训练误差降下去,但泛化误差出现上升形式&…...

多数据源数据转换和同步的ETL工具推荐
有许多支持多数据源数据转换和同步的ETL工具可供选择。以下是一些常见的ETL工具和它们支持多数据源数据转换和同步的特点: Apache NiFi:Apache NiFi是一个开源的ETL工具,支持多种数据源的连接,包括文件系统、数据库、消息队列、网…...

配置 gitlab https 访问
文章目录 1. 备份2. 生成SSL证书3. 配置文件4. 重启5. 访问 1. 备份 docker exec -ti gitlab-ce gitlab-rake gitlab:backup:create2. 生成SSL证书 yum install openssl openssl-devel -y mkdir /data/gitlab/config/ssl ; cd /data/gitlab/config/ssl### 生成证书 openssl…...
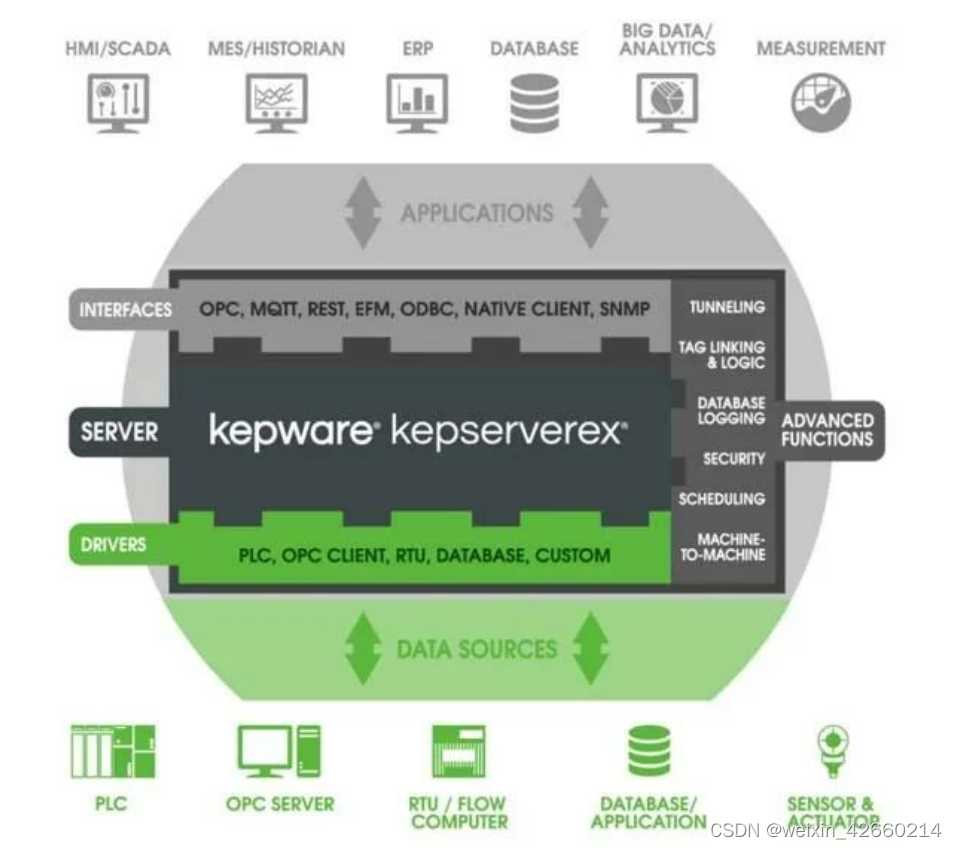
Kepware Modbus驱动简介
1. Modbus驱动能够解决什么问题? 它是Modbus设备驱动的集合,为用户提供一种方便快捷的Modbus设备数采解决方案。 只需要通过简单的配置就可以将常见的例如Modbus TCP/IP Ethernet、RTU Serial 和 ASCII Serial等协议设备无缝连接到 HMI/SCADA、MES/His…...
从零开始学习CTF——CTF是什么
引言: 从2019年10月开始接触CTF,学习了sql注入、文件包含等web知识点,但都是只知道知识点却实用不上,后来在刷CTF题才发现知识点的使用方法,知道在哪里使用,哪里容易出漏洞,可是在挖src漏洞中还…...

为Android构建现代应用——主体结构
创建Screents和ViewModels 在前面的章节中,我们已经分析了OrderNow项目的理论概念和我们将赋予的组织。 在本章中,我们将开始实现初始结构和模板,这将联接每一个应用程序的部分。 首先将添加以下带有各自视图模型的主屏幕: •…...
)
【shell脚本】shell脚本之日志切割(进阶实战三)
恭喜你,找到宝藏博主了,这里会分享shell的学习整过程。 shell 对于运维来说是必备技能之一,它可以提高很多运维重复工作,提高效率。 shell的专栏,我会详细地讲解shell的基础和使用,以及一些比较常用的she…...

VMLogin和虚拟机里的浏览器有什么区别?
虚拟机(Virtual Machine)指通过软件模拟的具有完整硬件系统功能的、运行在一个完全隔离环境中的完整计算机系统。 指纹浏览器,也称防关联浏览器。 简单来说,就是允许在同一台电设备上操作和管理多个平台、多个账号,账…...

Phi-3-mini-128k-instruct Chainlit集成:支持Markdown渲染、LaTeX公式与代码高亮
Phi-3-mini-128k-instruct Chainlit集成:支持Markdown渲染、LaTeX公式与代码高亮 1. 模型简介 Phi-3-Mini-128K-Instruct是一个38亿参数的轻量级开放模型,属于Phi-3系列中的高性能版本。这个模型经过精心训练,特别适合需要长文本理解和复杂…...

用 AI 助手清理 Windows C盘缓存:AppData/IDE/AI模型深度分析与安全清理实战
关键词:C盘清理、Windows磁盘优化、AppData缓存、AI工具缓存、VS Code扩展、Hugging Face缓存、Ollama模型清理、WorkBuddy 适用系统:Windows 10 / Windows 11 难度:⭐⭐(适合有基础的开发者) 目录 背景:开发机C盘为何特别容易爆满 环境准备 Step 1:调用AI进行深度磁盘扫…...

从L298到自举H桥:深入聊聊直流电机驱动方案的演进与选型心得
从L298到自举H桥:直流电机驱动方案的技术演进与工程实践 在机器人底盘、自动化产线和智能硬件开发中,直流电机驱动电路的设计往往决定着整个系统的性能天花板。十年前我们可能还在用L298这类经典驱动芯片,如今工程师们的工具箱里已经出现了IR…...

实测:用GPT-4和KernelBench自动生成CUDA内核,效果到底如何?
实测:GPT-4与KernelBench自动生成CUDA内核的实战效果分析 当我在深夜调试一个矩阵乘法的CUDA内核时,第17次尝试依然无法突破PyTorch原生实现的性能。这种场景对GPU开发者来说再熟悉不过——我们总在手工优化与开发效率之间寻找平衡。而当我第一次听说可以…...

2025年阿里云幻兽帕鲁联机服务器极速搭建指南
1. 为什么选择阿里云搭建幻兽帕鲁服务器? 最近很多朋友问我,为什么非要选择阿里云来搭建幻兽帕鲁的联机服务器?作为一个从游戏测试阶段就开始折腾服务器搭建的老玩家,我总结了几个关键原因。首先,阿里云的游戏服务器专…...

从零开始:在VMware虚拟机中部署Janus-Pro-7B进行开发测试
从零开始:在VMware虚拟机中部署Janus-Pro-7B进行开发测试 想试试最新的AI大模型,但手头没有昂贵的独立GPU服务器?别担心,今天我们就来聊聊一个非常接地气的方案:用你手边的普通电脑,通过VMware虚拟机&…...

文件上传进阶:PHP Graph SDK多媒体处理与分块上传教程
文件上传进阶:PHP Graph SDK多媒体处理与分块上传教程 【免费下载链接】php-graph-sdk The Facebook SDK for PHP provides a native interface to the Graph API and Facebook Login. https://developers.facebook.com/docs/php 项目地址: https://gitcode.com/g…...

Janus-Pro-7B实操手册:批量图片理解任务脚本编写与结果结构化导出
Janus-Pro-7B实操手册:批量图片理解任务脚本编写与结果结构化导出 1. 项目背景与需求场景 在日常工作中,我们经常需要处理大量的图片理解任务。比如电商平台需要分析商品图片中的信息,内容审核团队需要识别图片中的违规内容,或者…...

开源电子书工具:如何用鸿蒙系统打造专属个性化阅读空间
开源电子书工具:如何用鸿蒙系统打造专属个性化阅读空间 【免费下载链接】legado-Harmony 开源阅读鸿蒙版仓库 项目地址: https://gitcode.com/gh_mirrors/le/legado-Harmony 你是否曾因阅读应用充斥广告而烦躁?是否渴望完全掌控自己的阅读体验&am…...

QLVideo:macOS视频管理效率提升的完整解决方案
QLVideo:macOS视频管理效率提升的完整解决方案 【免费下载链接】QuickLookVideo This package allows macOS Finder to display thumbnails, static QuickLook previews, cover art and metadata for most types of video files. 项目地址: https://gitcode.com/g…...