【博学谷学习记录】超强总结,用心分享|Spark的RDD算子分类
概念
RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据抽象,代表一个不可变、可分区、里面的元素可并行计算的集合,它是一种抽象的数据模型,本身并不存储数据,仅仅是一个数据传输的管道,作为使用者,只需要告知RDD,数据从哪里读,中间需要进行什么样的转换逻辑,以及最后需要将结果输出到什么位置即可,RDD启动后,会根据用户设置的规则,完成整个处理操作
分类
所有的RDD算子,共分为2大类
- Transformation(转换算子)
- 所有的转换算子执行后,都会返回一个新的RDD
- 所有转换算子是惰性的,不会立即执行,可以认为只是此时只是定义了RDD的计算规则
- 转换算子必须遇到动作算子都会触发执行
- 常见转换算子
- map, filter, flatMap, mapPartitions, mapPartitionsWithIndex
- Action(动作算子)
- 动作算子执行后,不会返回一个RDD,要么没有返回值,要么返回其它的
- 动作算子都是立即执行,一个动作算子会产生一个Jo任务,运行动作算子所依赖的所有RDD
- 常见动作算子
- collect, count, first, take, reduce
转换算子
值类型的算子
map算子
- 格式:
rdd.map(fn) - 说明:根据传入的函数,对数据进行一对一的转换操作,传入一行,返回一行
rdd = sc.parallelize([1,2,3,4,5,6,7,8,9,10])# 需求: 请对每一个元素进行 +1 返回
rdd_collect = rdd.map(lambda num: num + 1).collect()
print(rdd_collect)结果:
[2, 3, 4, 5, 6, 7, 8, 9, 10, 11]
groupBy算子
- 格式:
rdd.groupBy(fn) - 说明:根据传入的函数对数据进行分组操作
rdd = sc.parallelize([1,2,3,4,5,6,7,8,9,10])# 需求: 请将数据分为奇数和偶数二部分
rdd_collect = rdd.groupBy(lambda num: 'o' if num % 2 == 0 else 'j').mapValues(list).collect()
print(rdd_collect)结果:[('j', [1, 3, 5, 7, 9]), ('o', [2, 4, 6, 8, 10])]
filter算子
- 格式:
rdd.filter(fn) - 说明:过滤算子, 可以根据函数中指定的过滤条件, 对数据进行过滤操作, 条件返回True表示保留, 返回False表示过滤掉
rdd = sc.parallelize([1,2,3,4,5,6,7,8,9,10])# 需求: 请将 <=3的数据过滤掉
rdd_collect = rdd.filter(lambda num: num > 3).collect()
print(rdd_collect)结果:[4, 5, 6, 7, 8, 9, 10]
flatMap算子
- 格式:
rdd.flatMap(fn) - 说明:在map算子的基础上, 在加入一个压扁的操作, 主要适用于一行中包含多个内容的操作, 实现一转多的操作
rdd = sc.parallelize(['张三 李四 王五 赵六','田七 周八 李九'])# 需求: 将其转换为一个个的姓名
rdd_collect = rdd.flatMap(lambda line: line.split()).collect()
print(rdd_collect)结果:['张三', '李四', '王五', '赵六', '田七', '周八', '李九']
双值类型的算子
union算子
- 格式:
rdd1.union(rdd2) - 说明:取两组数据的并集
rdd1 = sc.parallelize([3,1,5,7,9])
rdd2 = sc.parallelize([5,8,2,4,0])# 需求: 取两组数据的并集
rdd1.union(rdd2).collect()结果:[3, 1, 5, 7, 9, 5, 8, 2, 4, 0]# 去重操作:
rdd1.union(rdd2).distinct().collect()结果:[8, 4, 0, 1, 5, 9, 2, 3, 7]
intersection算子
- 格式:
rdd1.intersection(rdd2) - 说明:取两组数据的交集
rdd1.intersection(rdd2).collect()结果:[5]
KV类型的算子
groupByKey算子:
- 格式: groupByKey()
- 说明: 根据key进行分组操作
rdd = sc.parallelize([('c01','张三'),('c02','李四'),('c02','王五'),('c03','赵六'),('c02','田七'),('c02','周八'),('c03','李九')])# 需求: 根据班级分组统计
rdd_collect = rdd.groupByKey().mapValues(list).collect()
print(rdd_collect)结果:[('c01', ['张三']), ('c02', ['李四', '王五', '田七', '周八']), ('c03', ['赵六', '李九'])]
reduceByKey()
- 格式: reduceByKey(fn)
- 说明: 根据key进行分组, 将一个组内的value数据放置到一个列表中, 对这个列表基于 传入函数进行聚合计算操作
rdd = sc.parallelize([('c01','张三'),('c02','李四'),('c02','王五'),('c03','赵六'),('c02','田七'),('c02','周八'),('c03','李九')])# 需求: 统计每个班级有多少个人
rdd_collect = rdd.map(lambda kv: (kv[0],1)).reduceByKey(lambda agg, curr: agg + curr).collect()
print(rdd_collect)结果:[('c01', 1), ('c02', 4), ('c03', 2)]# 如果不转为1:
rdd.reduceByKey(lambda agg,curr: agg + curr).collect()
结果: [('c01', '张三'), ('c02', '李四王五田七周八'), ('c03', '赵六李九')]
sortByKey()算子
- 格式: sortByKey(ascending = True|False)
- 说明: 根据key进行排序操作, 默认按照key进行升序排序, 如果需要倒序, 设置 ascending 为False
rdd = sc.parallelize([('c03','张三'),('c05','李四'),('c011','王五'),('c09','赵六'),('c02','田七'),('c07','周八'),('c06','李九')])# 根据班级序号排序
rdd.sortByKey().collect()结果: 字典序 如果key是字符串[('c011', '王五'), ('c02', '田七'), ('c03', '张三'), ('c05', '李四'), ('c06', '李九'), ('c07', '周八'), ('c09', '赵六')]
动作算子
collect() 算子
- 格式: collect()
- 作用: 收集各个分区的数据, 将数据汇总到一个大的列表返回
reduce() 算子
- 格式: reduce(fn)
- 作用: 根据传入的函数对数据进行聚合操作
rdd = sc.parallelize([1,2,3,4,5,6,7,8,9,10])# 求第1数累加到最后一个数的和
rdd.reduce(lambda agg,curr: agg + curr)结果:55
first()算子
- 格式: first()
- 说明: 获取第一个元素
rdd = sc.parallelize([1,2,3,4,5,6,7,8,9,10])# 获取数据集中的第一个元素
rdd.first()结果:1
take() 算子
- 格式: take(N)
- 说明: 获取前N个元素, 类似于limit操作
rdd = sc.parallelize([1,2,3,4,5,6,7,8,9,10])# 获取数据集中的前5个元素
rdd.take(5)结果
[1, 2, 3, 4, 5]
top() 算子
- 格式: top(N, [fn])
- 说明: 对数据集进行倒序排序操作, 如果是kv类型, 默认是针对key进行排序, 获取前N个元素
- fn: 可以自定义排序, 根据谁来排序
rdd = sc.parallelize([1,2,3,4,5,6,7,8,9,10])rdd.top(3)
结果:
[10, 9, 8]rdd = sc.parallelize([('c03','张三'),('c05','李四'),('c011','王五'),('c09','赵六'),('c02','田七'),('c07','周八'),('c06','李九')])rdd.top(3)
结果:
[('c09', '赵六'), ('c07', '周八'), ('c06', '李九')]rdd = sc.parallelize([('c03',5),('c05',9),('c011',2),('c09',6),('c02',80),('c07',12),('c06',10)])rdd.top(3,lambda kv: kv[1])
结果:
[('c02', 80), ('c07', 12), ('c06', 10)]
count()算子
- 格式: count()
- 说明: 统计多少个
rdd = sc.parallelize([('c03',5),('c05',9),('c011',2),('c09',6),('c02',80),('c07',12),('c06',10)])rdd.count()
结果:7
foreach()算子
- 格式: foreach(fn)
- 说明: 对数据集进行遍历操作, 遍历后做什么, 取决于传入的函数
rdd = sc.parallelize([('c03',5),('c05',9),('c011',2),('c09',6),('c02',80),('c07',12),('c06',10)])rdd.foreach(lambda kv: print(kv))
结果:('c03', 5)('c05', 9)('c011', 2)('c09', 6)('c02', 80)('c07', 12)('c06', 10)
takeSample()算子
- 格式: takeSample(True|False, N,seed(种子值))
- 参数1: 是否允许重复采样
- 参数2: 采样多少个, 如果允许重复采样, 采样个数不限制, 否则最多等于本身数量个数
- 参数3: 设置种子值, 值可以随便写, 一旦写死了, 表示每次采样的内容也是固定的(可选的) 如果没有特殊需要, 一般不设置
- 作用: 数据抽样
rdd = sc.parallelize([1,2,3,4,5,6,7,8,9,10])rdd.takeSample(True,5)
[9, 9, 4, 8, 9]
rdd.takeSample(True,5)
[3, 8, 1, 3, 9]
rdd.takeSample(False,5)
[6, 1, 8, 7, 3]
rdd.takeSample(False,5)
[5, 7, 6, 3, 8]
rdd.takeSample(False,20)
[2, 10, 7, 5, 8, 9, 3, 4, 6, 1]
rdd.takeSample(False,5)
[8, 3, 10, 7, 9]rdd.takeSample(False,5,2)
[6, 10, 4, 5, 7]
rdd.takeSample(False,5,2)
[6, 10, 4, 5, 7]
rdd.takeSample(False,5,2)
[6, 10, 4, 5, 7]
rdd.takeSample(False,3,2)
[6, 10, 4]
相关文章:

【博学谷学习记录】超强总结,用心分享|Spark的RDD算子分类
概念 RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据抽象,代表一个不可变、可分区、里面的元素可并行计算的集合,它是一种抽象的数据模型,本身并不存储数据,仅…...
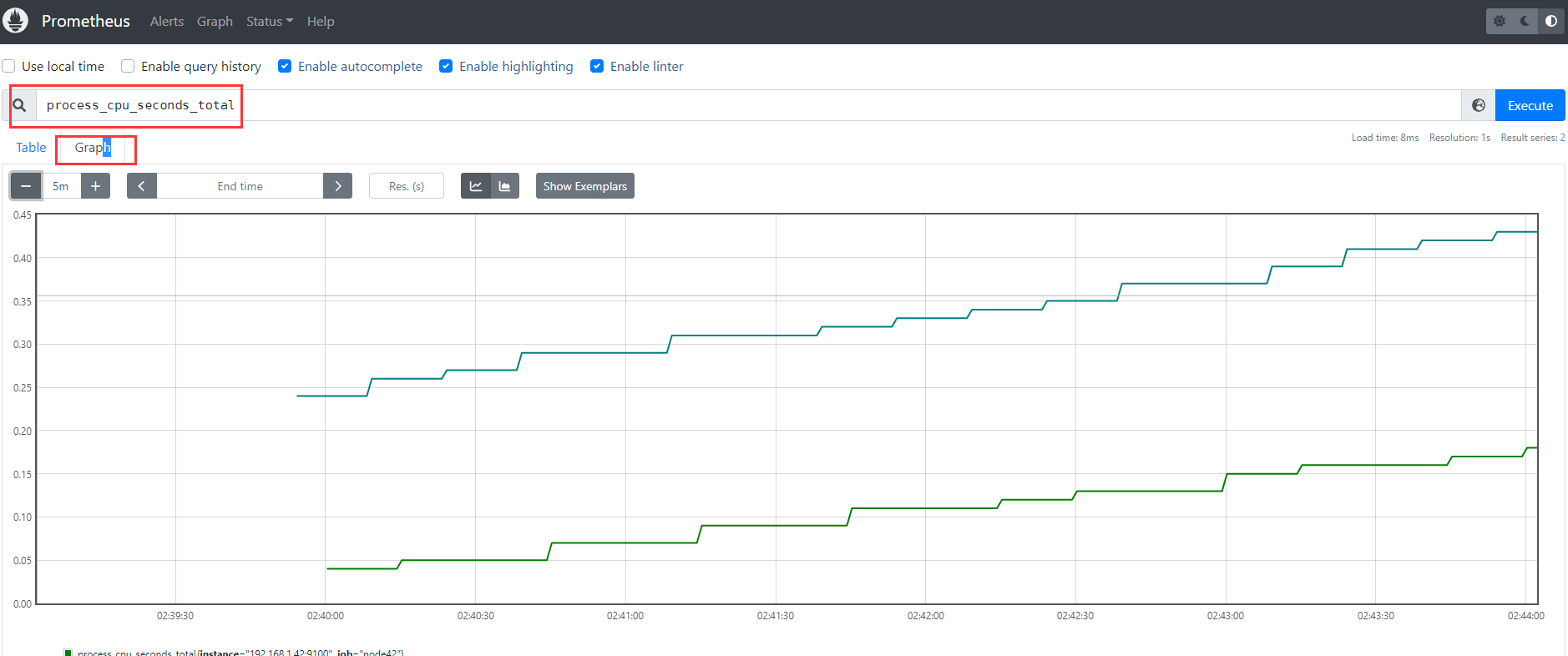
云原生系列之使用 prometheus监控远程主机实战
文章目录前言一. 实验环境二. 安装node_exporter2.1 node_exporter的介绍2.2 node_exporter的安装三. 在prometheus服务端配置监控远程主机3.1 在server端配置拉取node的信息3.2 重启prometheus3.3 通过浏览器查看prometheus总结前言 大家好,又见面了,我…...
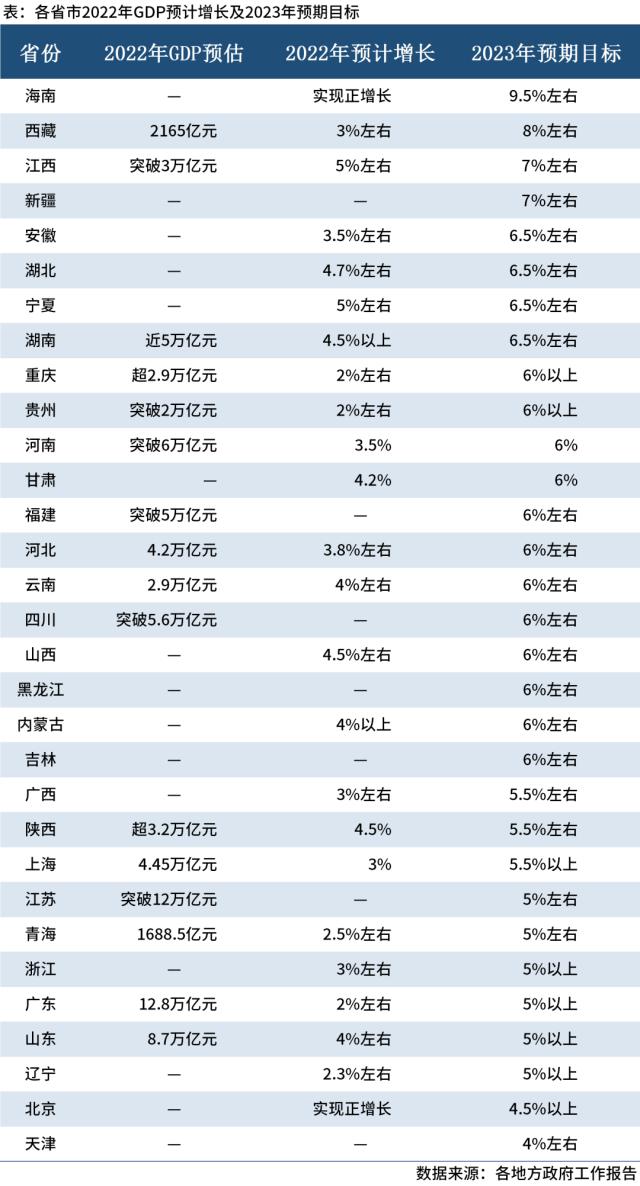
2023年地方两会政府工作报告汇总(各省市23年重点工作)
新年伊始,全国各地两会密集召开,各省、市、自治区2023年政府工作报告相继出炉,各地经济增长预期目标均已明确。相较于2022年,多地经济增长目标放缓,经济不断向“高质量”发展优化转型。今年是二十大后的开局之年&#…...
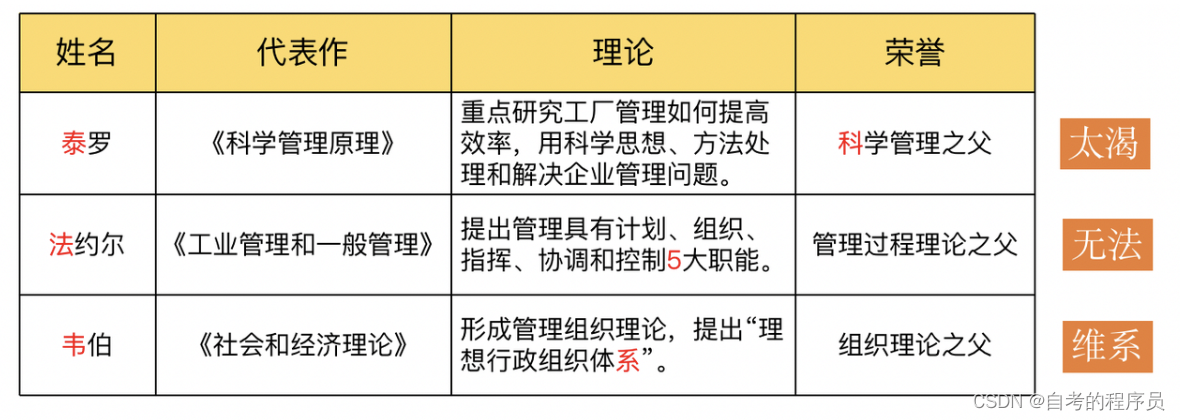
第一章 企业管理概论
目录 一、企业及其形式 二、企业管理概述 三、企业管理理论与实践的产生与发展 四、网络时代的企业环境 五、网络时代企业管理的变革 一、企业及其形式 1、企业的概念 企业以市场为导向,以价值增值作为经济活动的目的; 企业是从事商品生产和流通的…...

独立图片服务器有什么突出之处
服务器是网络中非常重要的设施,承载着不同流量的访问,这就要求服务器具有快速的吞吐量、高稳定性和高可靠性。独立图片服务器作为独立服务器的衍生品,在数据利用方面的应用可以为企业在数据处理和分析方面带来一场革命。本文就将介绍独立图片…...

Linux驱动开发基础__mmap
目录 1 引入 2 内存映射现象与数据结构 3 ARM 架构内存映射简介 3.1 一级页表映射过程 3.2 二级页表映射过程 4 怎么给 APP 新建一块内存映射 4.1 mmap 调用过程 编辑4.2 cache 和 buffer 4.3 驱动程序要做的事 5 编程 5.1 app编程 5.2 hello_drv_test…...

若依框架---为什么把添加和更新分成两个接口
👏作者简介:大家好,我是小童,Java开发工程师,CSDN博客博主,Java领域新星创作者 📕系列专栏:前端、Java、Java中间件大全、微信小程序、微信支付、若依框架、Spring全家桶 Ǵ…...

图论算法:Floyd算法
文章目录Floyd算法例题:灾后重建Floyd算法 Floyd算法用于求图中任意两点之间的最短路径,该算法主要运用了动态规划的思想。 思考: 给你几个点与边,可以组成一张图,那么如何求得任意两点之间的最短路径呢?…...

回顾 | .NET MAUI 跨平台应用开发 - 用 .NET MAUI 开发一个无人机应用(下)
点击蓝字关注我们编辑:Alan Wang排版:Rani Sun微软 Reactor 为帮助广开发者,技术爱好者,更好的学习 .NET Core, C#, Python,数据科学,机器学习,AI,区块链, IoT 等技术,将…...
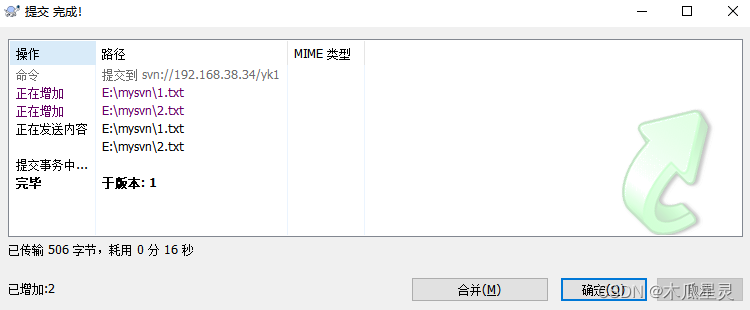
部署有多个仓库的svn服务
centos7自带svn服务,现需要创建多个仓库,并实现用户读写功能 创建svn版本库 mkdir /home/svn mkdir /home/svn/confmkdir /home/svn/yk1 mkdir /home/svn/yk2 svnadmin create /home/svn/yk1 svnadmin create /home/svn/yk2 进入版本库yk1的配置文件路…...
Mapper文件注入问题
Mapper文件注入问题UserMapper that could not be found.原因分析解决方案程序正常运行,但是注入类爆红问题原因分析解决方法UserMapper’ that could not be found. 原因分析 撰写了mapper文件,但是没有注入spring容器 解决方案 添加mybatis.mapper-…...
基于微信小程序的国产动漫论坛小程序
文末联系获取源码 开发语言:Java 框架:ssm JDK版本:JDK1.8 服务器:tomcat7 数据库:mysql 5.7/8.0 数据库工具:Navicat11 开发软件:eclipse/myeclipse/idea Maven包:Maven3.3.9 浏览器…...
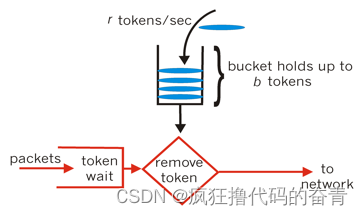
常用限流算法
简单时间窗口 算法逻辑:设置周期时间内的最大并发量问题:在周期尾端进去阈值并发后,进入下一周期时,又进入阈值并发量,则会出现瞬时并发量是阈值的2倍。 滑动时间窗口(优化) 算法逻辑…...

前端面经详解
目录 css 盒子充满屏幕 A.给div设置定位 B.设置html,body的宽高 C.相对当前屏幕高度(强烈推荐) 三列布局:左右固定,中间自适应 flex布局(强烈推荐) grid布局 magin负值法 自身浮动 绝对定位 圣…...
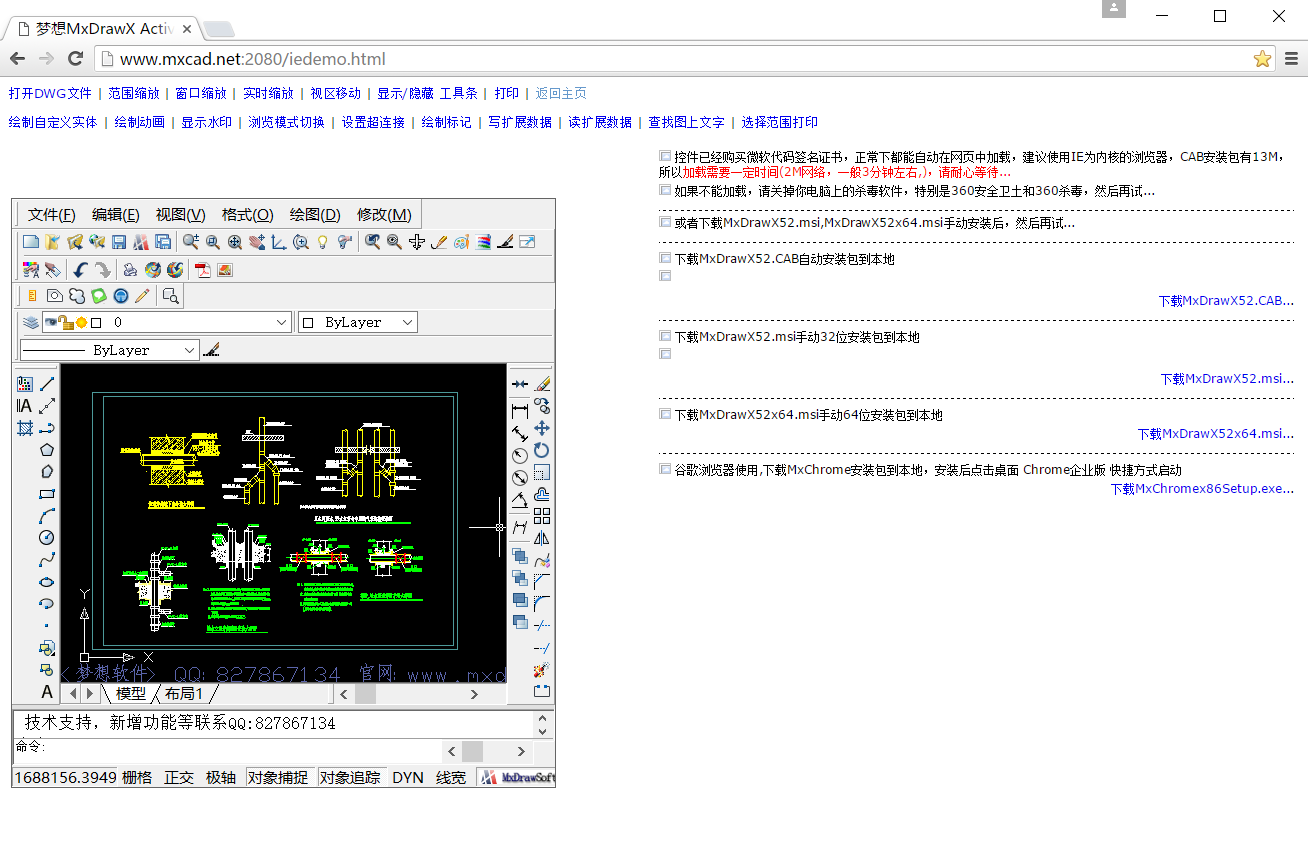
网页CAD开发快速入门
演示说明 提示:目前提供两种在网页中浏览编辑CAD图纸方案,详细说明见:MxDraw帮助 网页中打开CAD最简步骤: 第一步: 安装插件运行环境,下载安装(可能需要退杀毒软件):https://demo.mxdraw3d.com:3562/MxDrawx86Setup…...

C#开发的OpenRA的mod.yaml文件
C#开发的OpenRA的mod.yaml文件 在OpenRA游戏里,会看到这样一段代码: Manifest LoadMod(string id, string path){IReadOnlyPackage package = null;try{if (!Directory.Exists(path)){Log.Write("debug", path + " is not a valid mod package");return …...
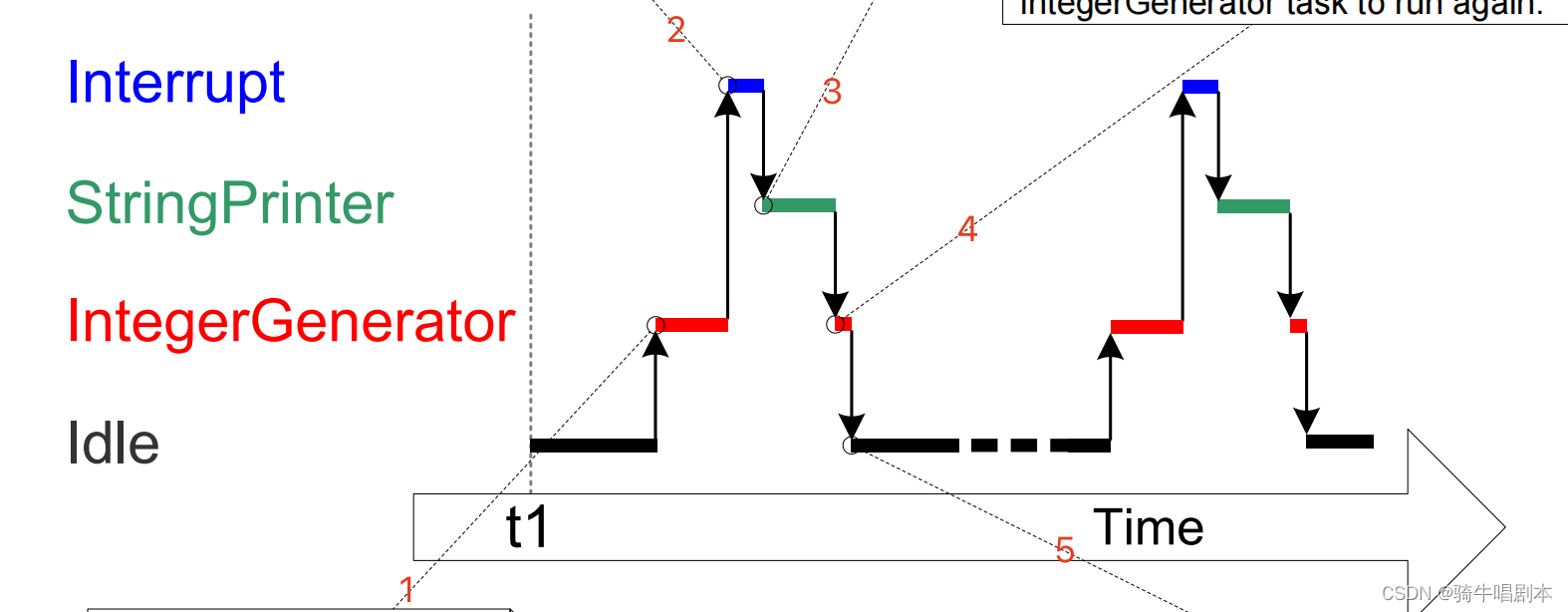
【ESP32+freeRTOS学习笔记-(七)中断管理】
目录1、概述2、在ISR中使用FreeRTOS中专用的API2.1 独立的用于ISR中的API2.2 关于xHigherPriorityTaskWoken 参数的初步理解3、延迟中断处理的方法-将中断中的处理推迟到任务中去4 方法一:用二进制信号量来同步ISR与”延时处理的任务“4.1 二进制信号量4.2 函数用法…...

【总结】1591- 从入门到精通:使用 TypeScript 开发超强的 CLI 工具
作为一名开发者,掌握 CLI 工具的开发能力是非常重要的。本文将指导你如何使用 TypeScript 和 CAC 库开发出功能强大的 CLI 工具。快速入门首先,需要先安装 Node.js 和 npm(Node Package Manager),然后在项目目录中创建…...

【Java】int和Integer的区别?为什么有包装类?
int和Integer的区别?为什么有包装类? java是一种强类型的语言,所以所有的属性都必须要有一个数据类型。 PS:java10有了局部变量类型推导,可以使用var来代替某个具体的数据类型,但是在字节码阶段࿰…...
)
【LeetCode】石子游戏 IV [H](动态规划)
1510. 石子游戏 IV - 力扣(LeetCode) 一、题目 Alice 和 Bob 两个人轮流玩一个游戏,Alice 先手。 一开始,有 n 个石子堆在一起。每个人轮流操作,正在操作的玩家可以从石子堆里拿走 任意 非零 平方数 个石子。 如果石…...

某民办高校关键人才梯队建设项目成功案例纪实
——破解“断层”隐忧,构建人才梯队蓄水池【客户行业】学校、民办学校、民办高等教育【问题类型】人才梯队建设;人才培养体系;激励体系;核心人才保留【客户背景】长三角地区一所知名的民办应用型本科院校,建校25年&…...

OpenClaw自动化测试:Qwen3-32B批量执行LeetCode题目
OpenClaw自动化测试:Qwen3-32B批量执行LeetCode题目 1. 为什么需要自动化编程能力测试 作为一名长期关注AI编程辅助工具的技术博主,我一直在寻找能够客观评估大模型编程能力的方法。传统的单次对话测试往往带有偶然性,无法系统性地反映模型…...

做了十几年财务,我用RPA把最累的工作交给了“机器人”
在财务这行摸爬滚打了十几年,算是一路看着这个行业慢慢“进化”过来的:从最早拿计算器对数据,到后来用电脑做账,从手工账本过渡到ERP系统,再到这两年铺天盖地的“数智化转型”。中间也确实尝试过不少所谓的“黑科技”。…...

【adb端口5555】烽火hg680系列安卓9线刷全攻略:告别强制升级与花屏困扰
1. 烽火HG680系列机顶盒的痛点与解决方案 最近在折腾烽火HG680-GY和HG680-GC这两款机顶盒的朋友应该都深有体会,官方系统用着用着就会弹出强制升级提示,有时候还会莫名其妙出现花屏问题。作为一个折腾过不下20台烽火盒子的老玩家,我太理解这种…...

2026 年终醒悟,AI 让我误以为自己很强,我思考了未来程序员的转型之路
2025 可以说只要是开发者都绕不过 AI ,时至今日你说你不用 AI 写代码我是不信的,但是直到最近我才发现,我似乎已经把 AI 的能力当做自己的能力,这种错觉体现在,昨天我用 AI 五分钟做出这下方这个动画效果: …...

技术日报|字节DeerFlow今日强势登顶日增3787星总量破4.6万,3D建筑编辑器黑马杀入前二
🌟 TrendForge 每日精选 - 发现最具潜力的开源项目 📊 今日共收录 12 个热门项目🌐 智能中文翻译版 - 项目描述已自动翻译,便于理解🏆 今日最热项目 Top 10 🥇 bytedance/deer-flow 项目简介: DeerFlow是一…...

基于STM32CubeMX的AD9850驱动开发与频率合成实战
1. 从零开始认识AD9850与STM32CubeMX 第一次接触AD9850这个芯片时,我完全被它的性能震撼到了——这个比指甲盖还小的芯片,居然能产生0.0291Hz分辨率的信号!当时我正在做一个射频测试项目,需要生成精确的正弦波信号。市面上常见的…...
)
手把手教你用两块STM32F103C8T6实现CAN总线点对点通信(附完整代码)
从零开始实现STM32F103C8T6双板CAN总线通信实战指南 在嵌入式开发领域,CAN总线因其高可靠性和实时性成为工业控制、汽车电子等场景的首选通信协议。对于初学者而言,使用两块STM32F103C8T6开发板搭建CAN通信系统是掌握该技术的经典入门项目。本文将彻底拆…...

java 短信验证码接口开发面向接口编程实现
在Java企业级后端开发中,短信验证码是用户登录、注册、密码重置的核心身份验证方案,java短信验证码接口的规范化开发直接决定系统的扩展性与维护性。传统硬编码开发模式存在耦合度高、服务商切换困难等问题,本文基于面向接口编程思想…...

密码学实战:从古典密码到AES,手把手教你用Python实现加密算法
密码学实战:从古典密码到AES的Python实现之旅 密码学作为信息安全的核心支柱,其发展历程就像一部浓缩的科技史。从凯撒大帝用过的简单字母替换,到如今保护我们银行卡交易的AES算法,加密技术始终在与破解者进行着无声的较量。本文…...