MYSQL 主从复制
在读多写少的网络环境下,MySQL 如何优化数据查询方案
假如说一个电商平台 到双十一了 大量的读写操作 如果不做点什么的话 平台就被冲烂了 那我们要怎么办呢?
你或许会想 林北直接一个redis缓存 帮数据库度过难关
这个操作实际上是不行的 因为应用缓存的原则之一是保证缓存命中率足够高,不然很多请求会穿透缓存,最终打到数据库上。然而在“订单中心”这样的场景中,每个用户的订单都不同,除非全量缓存数据库订单信息(又会带来架构的复杂度),不然缓存的命中率依旧很低。
所以在这种场景下,缓存只能作为数据库的前置保护机制,但是还会有很多流量打到数据库上,并且随着用户订单不断增多,请求到 MySQL 上的读写流量会越来越多,当单台 MySQL 支撑不了大量的并发请求时,该怎么办?
哎 这里就引入了 主从复制
一般来讲 互联网大部分系统的访问流量是读多写少 对吧 相对于我浏览信息的时候 我写入信息的时候真的很少 读写请求量的差距可能达到几个数量级 具体例子 我逛淘宝 逛半天买不了屁崩俩东西
所以我们把主库复制很多份 作为从库 啊 每次读取都从这个从库上面读取 写就直接写到主库上面 啊 写到主库上面的数据 还要再同步到从库上面 这就是大体流程
主从复制原理
总得来说这个复制流程 MySQL 的主从复制依赖于 binlog ,也就是记录 MySQL 上的所有变化并以二进制形式保存在磁盘上。复制的过程就是将 binlog 中的数据从主库传输到从库上。这个过程一般是异步的,也就是主库上执行事务操作的线程不会等待复制 binlog 的线程同步完成。
具体来讲
1.把更新写进binlog日志
MySQL 主库在收到客户端提交事务的请求之后,会先写入 binlog,再提交事务,更新存储引擎中的数据,事务提交完成后,返回给客户端“操作成功”的响应。
2.把binlog传给从库
从库会创建一个专门的 I/O 线程,连接主库的 log dump 线程,来接收主库的 binlog 日志,再把 binlog 信息写入 relay log 的中继日志里,再返回给主库“复制成功”的响应。
3.从库用binlog更新
从库会创建一个用于回放 binlog 的线程,去读 relay log 中继日志,然后回放 binlog 更新存储引擎中的数据,最终实现主从的数据一致性。(SQL/Worker 线程负责并行执行中继日志)
细说binlog
MySQL InnoDB 引擎的主从复制,是通过二进制日志 binlog 来实现。除了数据查询语句 select 以外,binlog 日志记录了其他各类数据写入操作,包括 DDL 和 DML 语句。
binlog 有三种格式:Statement、Row 及 Mixed。
- Statement 格式,基于 SQL 语句的复制
在 Statement 格式中,binlog 会记录每一条修改数据的 SQL 操作,从库拿到后在本地进行回放就可以了。
- Row 格式,基于行信息复制
Row 格式以行为维度,记录每一行数据修改的细节,不记录执行 SQL 语句的上下文相关的信息,仅记录行数据的修改。假设有一个批量更新操作,会以行记录的形式来保存二进制文件,这样可能会产生大量的日志内容。
- Mixed 格式,混合模式复制
Mixed 格式,就是 Statement 与 Row 的结合,在这种方式下,不同的 SQL 操作会区别对待。比如一般的数据操作使用 row 格式保存,有些表结构的变更语句,使用 statement 来记录。
主从复制模型
哎 那你说 我从库无限多是不是无敌了 每个从库上面分散的读操作无限少 贼快 并不行 因为从库数量增加,从库连接上来的 I/O 线程也比较多,主库也要创建同样多的 log dump 线程来处理复制的请求,对主库资源消耗比较高,同时还受限于主库的网络带宽。所以在实际使用中,一个主库一般跟 2~3 个从库(1 套数据库,1 主 2 从 1 备主),这就是一主多从的 MySQL 集群结构。
- 同步复制:事务线程要等待所有从库的复制成功响应。同步复制指的是在多从库的情况下,当主库执行完一个事务,需要等待所有的从库都同步完成以后,才完成本次写操作。全同步复制需要等待所有从库执行完对应的事务,所以整体性能是最差的。
- 异步复制:事务线程完全不等待从库的复制成功响应。异步复制模式下,主库在接受并处理客户端的写入请求时,直接返回执行结果,不关心从库同步是否成功,这样就会存在上面说的问题,主库崩溃以后,可能有部分操作没有同步到从库,出现数据丢失问题。
- 半同步复制:MySQL 5.7 版本之后增加的一种复制方式,介于两者之间,事务线程不用等待所有的从库复制成功响应,只要一部分复制成功响应回来就行,比如一主二从的集群,只要数据成功复制到任意一个从库上,主库的事务线程就可以返回给客户端。在半同步复制模式下,主库需要等待至少一个从库完成同步之后,才完成写操作。主库在执行完客户端提交的事务后,从库将日志写入自己本地的 relay log 之后,会返回一个响应结果给主库,主库确认从库已经同步完成,才会结束本次写操作。相对于异步复制,半同步复制提高了数据的安全性,避免了主库崩溃出现的数据丢失,但是同时也增加了主库写操作的耗时。
这种半同步复制的方式,兼顾了异步复制和同步复制的优点,即使出现主库宕机,至少还有一个从库有最新的数据,不存在数据丢失的风险。话又说回来也算是同步和异步的优点都不明显?
对于半同步复制来说 MYSQL5.7之前叫做有损半同步复制 这种半同步复制在主库 发生宕机时,从库会丢失最后一批提交的数据,若这时 从库 提升(Failover)为主库,可能会发生已经提交的事情不见了,发生了回滚的情况。
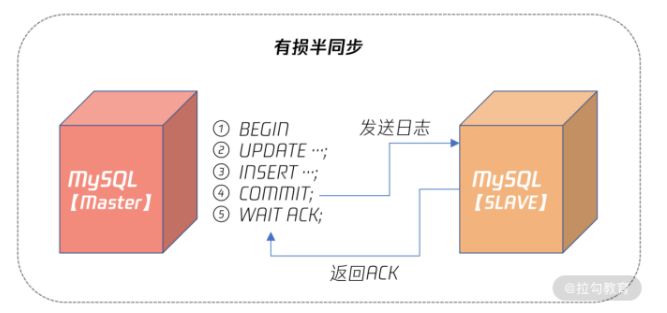
可以看到,有损半同步是在 Master 事务提交后,即步骤 4 后,等待 Slave 返回 ACK,表示至少有 Slave 接收到了二进制日志,如果这时二进制日志还未发送到 Slave,Master 就发生宕机,则此时 Slave 就会丢失 Master 已经提交的数据。
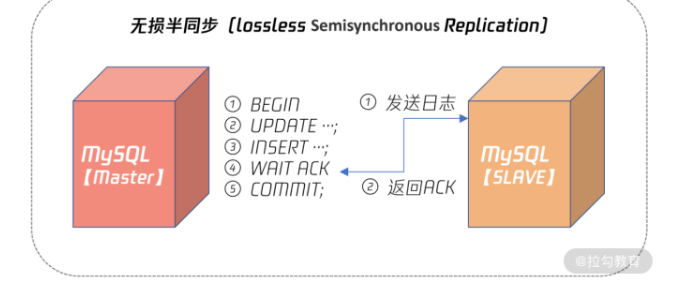
从上图可以看到,无损半同步复制 WAIT ACK 发生在事务提交之前,这样即便 Slave 没有收到二进制日志,但是 Master 宕机了,由于最后一个事务还没有提交,所以本身这个数据对外也不可见,不存在丢失的问题。
所以,对于任何有数据一致性要求的业务,如电商的核心订单业务、银行、保险、证券等与资金密切相关的业务,务必使用无损半同步复制。这样数据才是安全的、有保障的、即使发生宕机,从机也有一份完整的数据。
多源复制
无论是异步复制还是半同步复制,都是 1 个 Master 对应 N 个 Slave。其实 MySQL 也支持 N 个 Master 对应 1 个 Slave,这种架构就称之为多源复制。
多源复制允许在不同 MySQL 实例上的数据同步到 1 台 MySQL 实例上,方便在 1 台 Slave 服务器上进行一些统计查询,如常见的 OLAP 业务查询。
多源复制的架构如下所示:
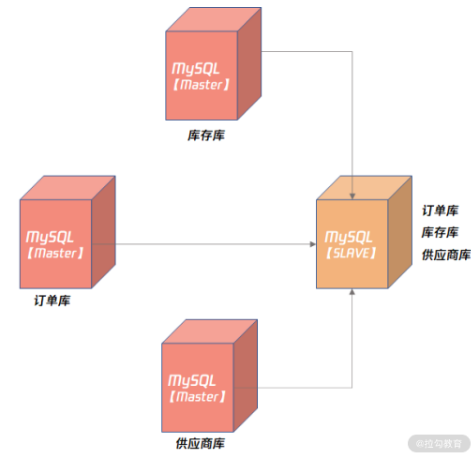

上图显示了订单库、库存库、供应商库,通过多源复制同步到了一台 MySQL 实例上,接着就可以通过 MySQL 8.0 提供的复杂 SQL 能力,对业务进行深度的数据分析和挖掘。
延迟复制
前面介绍的复制架构,Slave 在接收二进制日志后会尽可能快地回放日志,这样是为了避免主从之间出现延迟。而延迟复制却允许Slave 延迟回放接收到的二进制日志,为了避免主服务器上的误操作,马上又同步到了从服务器,导致数据完全丢失。
我们可以通过以下命令设置延迟复制:
CHANGE MASTER TO master_delay = 3600
这样就人为设置了 Slave 落后 Master 服务器1个小时。
延迟复制在数据库的备份架构设计中非常常见,比如可以设置一个延迟一天的延迟备机,这样本质上说,用户可以有 1 份 24 小时前的快照。
那么当线上发生误操作,如 DROP TABLE、DROP DATABASE 这样灾难性的命令时,用户有一个 24 小时前的快照,数据可以快速恢复。
对金融行业来说,延迟复制是你备份设计中,必须考虑的一个架构部分。
解决主从复制延迟
就是主从复制延迟是个啥情况呢 我先更新主库 然后由于这个更新量太大了 然后我们查询的时候这个新数据还没更新好呢 那就查不到这个结果了
啊 具体例子
在电商平台,每次用户发布商品评论时,都会先调用评论审核,目的是对用户发布的商品评论进行如言论监控、图片鉴黄等操作。
评论在更新完主库后,商品发布模块会异步调用审核模块,并把评论 ID 传递给审核模块,然后再由评论审核模块用评论 ID 查询从库中获取到完整的评论信息。此时如果主从数据库存在延迟,在从库中就会获取不到评论信息,整个流程就会出现异常。
解决方案:
- 使用数据冗余
可以在异步调用审核模块时,不仅仅发送商品 ID,而是发送审核模块需要的所有评论信息,借此避免在从库中重新查询数据(这个方案简单易实现,推荐你选择)。但你要注意每次调用的参数大小,过大的消息会占用网络带宽和通信时间。
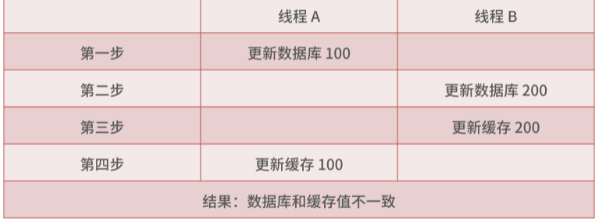
- 使用缓存解决
可以在写入数据主库的同时,把评论数据写到 Redis 缓存里,这样其他线程再获取评论信息时会优先查询缓存,也可以保证数据的一致性。
会出现更新丢失的可能性
- 直接查询主库
?那我还主从复制干啥
或者我们可以根据业务类型来选择怎么解决主从延迟
- 敏感业务强制读主库
在开发中有部分业务需要写库后实时读数据,这一类操作通常可以通过强制读主库来解决。
- 关键业务不进行读写分离
对一致性不敏感的业务,比如电商中的订单评论、个人信息等可以进行读写分离,对一致性要求比较高的业务,比如金融支付,不进行读写分离,避免延迟导致的问题。
主从复制的优化
大事务拆成小事务
逻辑日志在事务提交时才写入,若存在大事务,则提交速度很慢
所以在 MySQL 中,你一定要对大事务特别对待, 总结起来就是:
- 设计时,把 DELETE 删除操作转化为 DROP TABLE/PARTITION 操作;
- 业务设计时,把大事务拆成小事务。
对于第一点(把 DELETE 删除操作转化为 DROP TABLE/PARTITION 操作),主要是在设计时把流水或日志类的表按时间分表或者分区,这样在删除时,二进制日志内容就是一条 DROP TABLE/PARITION 的 SQL,写入速度就非常快了
而第二点(把大事务拆分成小事务)也能控制二进制日志的大小。比如对于前面的 DELETE 操作,如果设计时没有分表或分区,那么你可以进行如下面的小事务拆分:
DELETE FROM ...WHEREE time between ... and ...LIMIT 1000;
上面的 SQL 就是把一个大的 DELETE 操作拆分成了每次删除 1000 条记录的小操作。而小事务的另一个优势是:可以进行多线程的并发操作,进一步提升删除效率。
调整参数
要彻底避免 MySQL 主从复制延迟,数据库版本至少要升级到 5.7,因为之前的MySQL 版本从机回放二进制都是单线程的(5.6 是基于库级别的单线程)。
从 MySQL 5.7 版本开始,MySQL 支持了从机多线程回放二进制日志的方式,通常把它叫作“并行复制”,官方文档中称为“Multi-Threaded Slave(MTS)”。
MySQL 的从机并行复制有两种模式。
- COMMIT ORDER: 主机怎么并行,从机就怎么并行。
- WRITESET: 基于每个事务,只要事务更新的记录不冲突,就可以并行。
COMMIT ORDER 模式的从机并行复制,从机完全根据主服务的并行度进行回放。理论上来说,主从延迟极小。但如果主服务器上并行度非常小,事务并不小,比如单线程每次插入 1000 条记录,则从机单线程回放,也会存在一些复制延迟的情况。
而 WRITESET 模式是基于每个事务并行,如果事务间更新的记录不冲突,就可以并行。还是以“单线程每次插入 1000 条记录”为例,如果插入的记录没有冲突,比如唯一索引冲突,那么虽然主机是单线程,但从机可以是多线程并行回放!!!
所以在 WRITESET 模式下,主从复制几乎没有延迟
这点我没实操 不懂
但是总之就是
主从复制延迟监控不能依赖 Seconds_Behind_Master 的值,最好的方法是额外配置一张心跳表;
主从复制的兜底
如果真的由于一些不可预知的情况发生,比如一个初级 DBA 在主机上做了一个大事务操作,导致主从延迟发生,那么怎么做好读写分离设计的兜底呢?
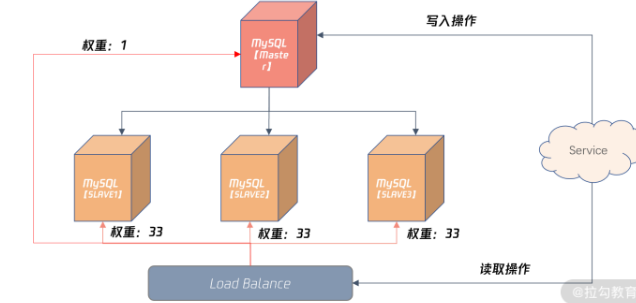
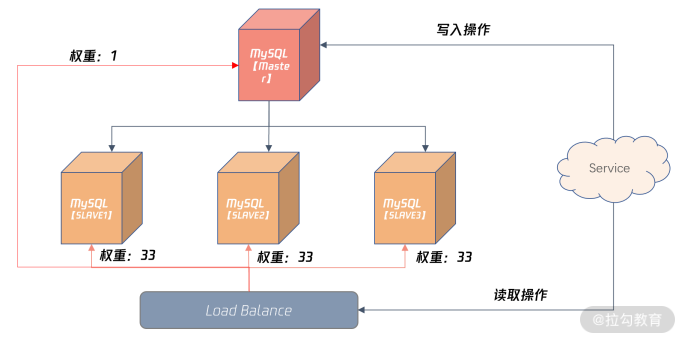
在 Load Balance 服务器,可以配置较小比例的读取请求访问主机,如上图所示的 1%,其余三台从服务器各自承担 33% 的读取请求。
如果发生严重的主从复制情况,可以设置下面从机权重为 0,将主机权重设置为 100%,这样就不会因为数据延迟,导致对于业务的影响了。
相关文章:
MYSQL 主从复制
在读多写少的网络环境下,MySQL 如何优化数据查询方案 假如说一个电商平台 到双十一了 大量的读写操作 如果不做点什么的话 平台就被冲烂了 那我们要怎么办呢? 你或许会想 林北直接一个redis缓存 帮数据库度过难关 这个操作实际上是不行的 因为应用缓存的原则之一…...

网络安全领域关键信息泄露事件引发关注
近日,一家知名网络安全公司发布了一份报告揭露了一起重大信息泄露事件。据称,该事件涉及大量敏感用户数据的泄露引发了全球网络安全领域的广泛关注。 根据报道,该事件发生在全球范围内涉及多个国家和组织。专家指出,此次泄露事件…...
AI 绘画Stable Diffusion 研究(一)sd整合包v4.2 版本安装说明
部署包作者:秋葉aaaki 免责声明: 本安装包及启动器免费提供 无任何盈利目的 大家好,我是风雨无阻。众所周知,StableDiffusion 是非常强大的AI绘图工具,需要详细了解StableDiffusion的朋友,可查看我之前的这篇文章: 最…...

夯实数字化转型安全地基,华东某农商行开源安全治理经验
华东某农村商业银行是一家全国首批组建的股份制农村金融机构。近年来,该农商行坚持“科技强行”战略,进一步夯实数字化核心基础,积极推动金融科技与产品、服务的深度融合,努力拓展数字金融的包容性,让数字金融更有温度…...
第G3周:CGAN|生成手势图像
目录 一、准备工作1. 导入数据2. 数据可视化 二、构建模型1. 构建生成器2. 构建鉴别器 三、训练模型1. 定义损失函数2. 定义优化器3. 训练模型 四、理论基础1.DCGAN原理2.DCGAN网络3.个人感悟 🍨 本文为🔗365天深度学习训练营 中的学习记录博客…...
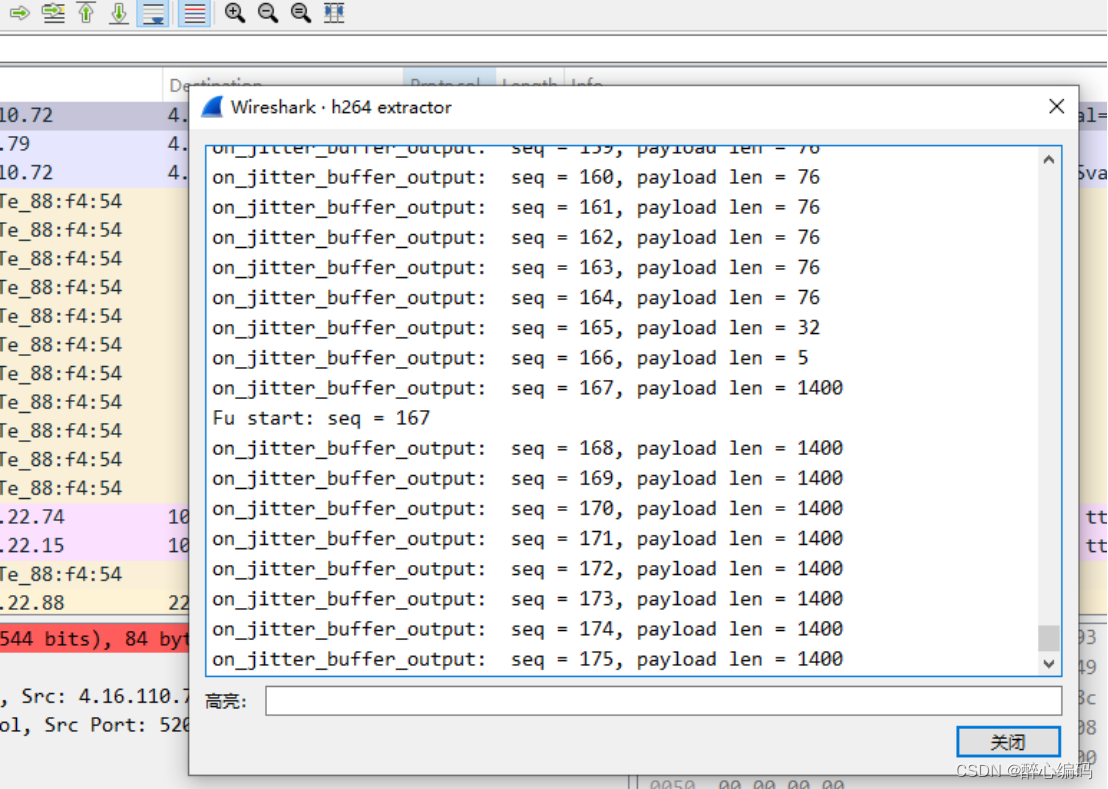
wireshark导出H264裸流
导出H264裸流 安装wireshark下载rtp_h264_extractor.lua脚本配置lua脚本重启wireshark筛选 安装wireshark 下载抓包工具:首先,您需要下载并安装一个网络抓包工具,例如Wireshark(https://www.wireshark.org)或tcpdump&…...

Sentinel针对IP限流
改造限流策略的针对来源选项 import com.alibaba.csp.sentinel.adapter.spring.webmvc.callback.RequestOriginParser; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration;Configuration public class Senti…...
S475支持 ModbusRTU 转 MQTT协议采集网关
6路模拟量输入和2路RS485串口是一种功能强大的通信接口,可以接入多种设备和系统,支持4-20mA输出的传感器以及开关量输入输出。本文将详细介绍6路模拟量输入和2路RS485串口的应用场景和功能,重点介绍其在SCADA、HMI、远程数据监控以及采集控制…...
js的变量
目录 变量 var和let 1.for循环中的声明 2.暂时性死区 3.全局声明 4.条件声明 const声明 变量 java是一种强数据类型语言,对数据类型要求高,要声明清楚变量的类型 数据类型 变量名 值 -----> int a 10 而javaScrit是一种弱类型语言,在声明变…...

MicroPython for ESP32
MicroPython for ESP32 开发板引脚图 环境搭建 参考资料 https://zhuanlan.zhihu.com/p/587027345 官方资料 https://docs.micropython.org/en/latest/ http://vcc-gnd.com/rtd/html/esp32/quickref.html#i2c 创建一个虚拟环境, conda create -n esp32 pytho…...
选择适合产品需求管理的项目管理系统,打造完美项目流程!
一般来说,互联网产品经理收到的需求一般分为业务需求、用户需求和产品功能需求。业务需求主要包括战略和规则需求;用户需求一般是真实反馈、真实需求、吐槽、建议等。;功能需求主要围绕产品的旧功能问题进行升级,bug处理、技术问题…...

@monaco-editor/react组件CDN加载失败解决办法
monaco-editor/react引入这个cdn资源会load失败 网上很多例子都是这样写的,我这样写monaco会报错 import * as monaco from monaco-editor; import { loader } from monaco-editor/react;loader.config({ monaco });改成这样 import * as monaco from monaco-edi…...

java对象的强引用,弱引用,软引用,虚引用
前言:java对象在java虚拟机中的生存状态,面试可能会有人问道,了解一下 这里大量引用 《疯狂Java讲义第4版》 书中的内容...
ubuntu ssh
前置 需要知道自己的ip 如果没有ifconfig sudo apt-get install net-tools然后 ifconfig中文用户 winr,输入 intl.cpl在git里,选zh_cn和UTF-8 安装 sudo apt-get install -y openssh-client openssh-server设置开机启动 sudo systemctl enable sshsudo nano…...

js:斐波那契额数列生成器Generator
请你编写一个生成器函数,并返回一个可以生成 斐波那契数列 的生成器对象。 斐波那契数列 的递推公式为 Xn Xn-1 Xn-2 。 这个数列的前几个数字是 0, 1, 1, 2, 3, 5, 8, 13 。 /*** return {Generator<number>}*/ var fibGenerator function*() {let pre…...
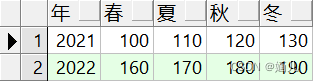
行列转换.
表abc: (建表语句在文章末尾) 想要得到: 方法一 with a as(select 年,产 from abc where 季1), b as(select 年,产 from abc where 季2), c as(select 年,产 from abc where 季3), d as(select 年,产 from abc where 季4) selec…...

CentOs 7利用iscaiadm工具发现并连接外接存储
CentOs 7利用iscaiadm工具发现并连接外接存储 1.1 使用iscsiadm发现存储 iscsiadm -m discovery -t st -p ${外接存储IP} # 执行结果may like ${外接存储IP}:3260,1 iqn.${存储唯一标识} 1.2 登入发现的存储 iscsiadm -m node -T iqn.${存储唯一标识} -p ${外接存储IP} -…...
Java期末复习基础题编程题
文章目录 基础题记录实践题记录&&与C比较题目1:题目2:题目3: 基础题记录 编译型语言: 定义:在程序运行之前,通过编译器将源程序编译成机器码(可运行的二进制代码),以后执行这个程序时&…...
资深测试总结,自动化测试-ddt数据驱动yaml文件实战(详细)
目录:导读 前言一、Python编程入门到精通二、接口自动化项目实战三、Web自动化项目实战四、App自动化项目实战五、一线大厂简历六、测试开发DevOps体系七、常用自动化测试工具八、JMeter性能测试九、总结(尾部小惊喜) 前言 ddt 驱动 yaml/ym…...
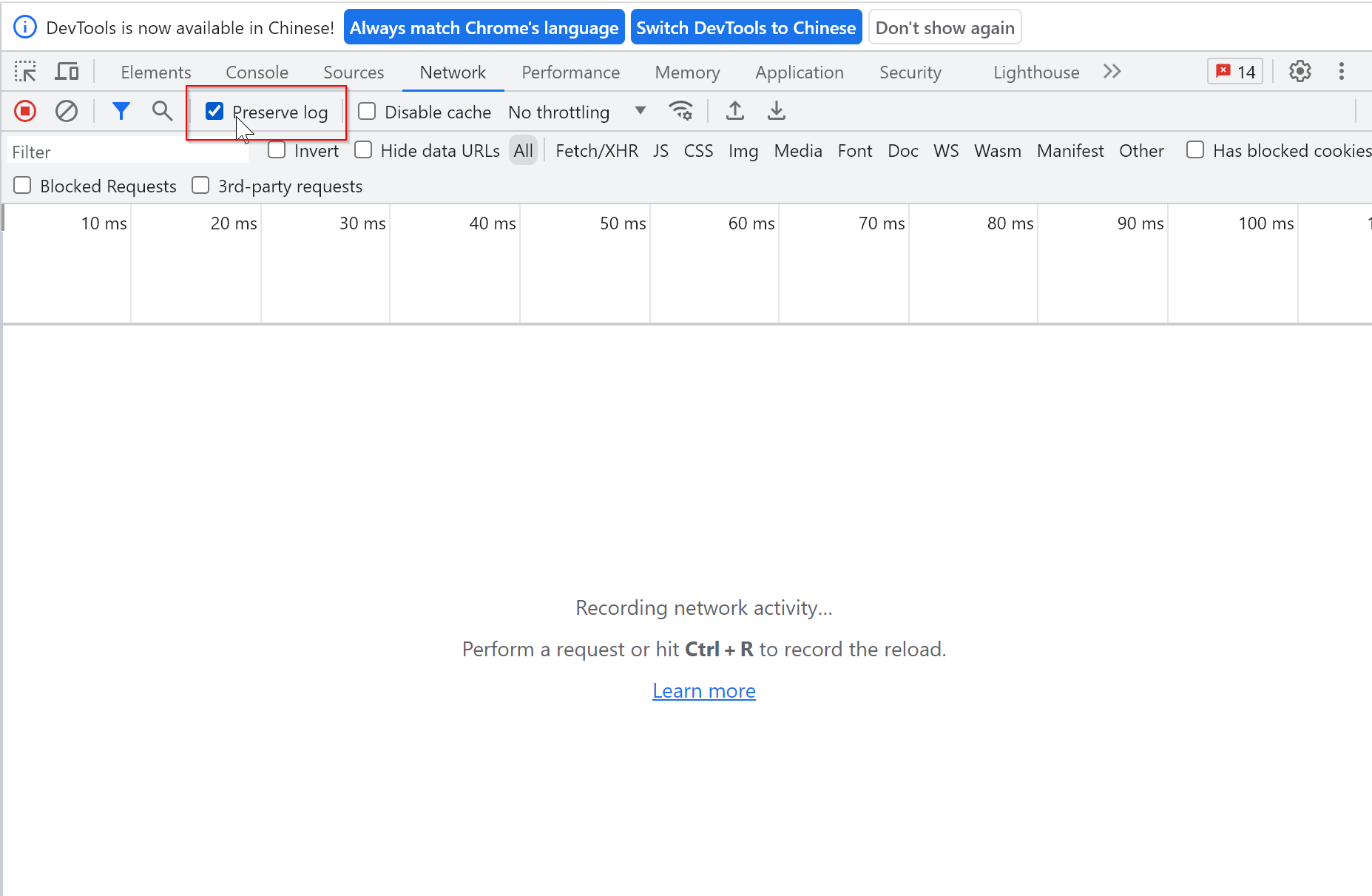
F12 浏览器调试模式页面刷新 network 日志刷新消失的解决办法
每次请求刷新后都把之前的请求记录刷新掉了,把preserve log勾选上后,所有的请求都会保留,再也不怕抓不到记录了。...

7个高级配置技巧:打造极致Markdown预览体验
7个高级配置技巧:打造极致Markdown预览体验 【免费下载链接】vscode-markdown-preview-enhanced One of the "BEST" markdown preview extensions for Visual Studio Code 项目地址: https://gitcode.com/gh_mirrors/vs/vscode-markdown-preview-enhanc…...

智能家居控制中心:OpenClaw+Qwen3.5-9B语音指令中转
智能家居控制中心:OpenClawQwen3.5-9B语音指令中转 1. 为什么需要语音控制的智能家居中枢? 去年装修新房时,我装了十几款不同品牌的智能设备——从米家的灯泡到涂鸦的窗帘电机,再到HomeKit的温控器。每次想调整家居状态…...

3个核心价值重塑漫画阅读体验:Venera跨平台漫画阅读器全面解析
3个核心价值重塑漫画阅读体验:Venera跨平台漫画阅读器全面解析 【免费下载链接】venera A comic app 项目地址: https://gitcode.com/gh_mirrors/ve/venera 当你在手机上读到精彩漫画章节却不得不中断通勤,回家后打开电脑却要重新寻找上次阅读位置…...

C++/Qt 使用 Tushare 获取股票信息
探索数据之源:使用tushare为Qt/C学习项目获取股票数据在进行金融量化分析或学习金融市场行为时,获取高质量、结构化的股票数据是至关重要的第一步。作为一个计划将Qt/C用于金融数据可视化或策略模拟的学习者,我近期深入体验了使用Python库tus…...

【linux】Xorg与X Window System的交互机制解析
1. X Window System与Xorg的关系 当你打开Linux电脑看到图形界面时,背后默默工作的就是X Window System。这个诞生于1984年的图形系统至今仍是Linux桌面环境的基石,而Xorg则是它的现代实现版本。简单来说,X Window System定义了图形显示的标准…...

合肥高中英语一对一辅导2026指南,突破听说读写全面提升路径
合肥高中英语一对一辅导2026指南,突破听说读写全面提升路径据《2026年中国基础教育课外辅导行业白皮书》数据显示,2026年高中阶段英语学科辅导需求同比增长23%,其中超过65%的学生家长明确表示,传统大班教学已无法满足孩子个性化提…...

HunyuanVideo-Foley入门指南:infer.py命令行参数全量说明与组合技巧
HunyuanVideo-Foley入门指南:infer.py命令行参数全量说明与组合技巧 1. 环境准备与快速部署 HunyuanVideo-Foley是一款强大的视频与音效生成工具,基于RTX 4090D 24GB显存和CUDA 12.4深度优化。在开始使用前,请确保您的硬件配置满足以下要求…...
)
实战指南:如何用FAISS和GPT-4o-mini构建高效RAG系统(附开源代码)
实战指南:如何用FAISS和GPT-4o-mini构建高效RAG系统(附开源代码) 在人工智能领域,检索增强生成(RAG)技术正迅速成为连接大型语言模型与专业知识的桥梁。不同于传统LLM仅依赖预训练知识,RAG系统通…...

Maven阿里云镜像配置详解:提升依赖下载速度的终极方案
Maven阿里云镜像配置实战:突破国内依赖下载瓶颈的完整指南 每次打开IDE准备大干一场时,最扫兴的莫过于看着Maven依赖下载进度条像蜗牛一样缓慢爬行。作为Java开发者,我们都经历过中央仓库下载速度只有几十KB/s的煎熬时刻——特别是当团队新成…...

LFM2.5-1.2B-Thinking-GGUF保姆级教程:Web界面汉化+响应式布局适配移动端指南
LFM2.5-1.2B-Thinking-GGUF保姆级教程:Web界面汉化响应式布局适配移动端指南 1. 模型与平台介绍 LFM2.5-1.2B-Thinking-GGUF是Liquid AI推出的一款轻量级文本生成模型,特别适合在资源有限的环境中快速部署使用。这个镜像内置了GGUF模型文件和llama.cpp…...