第G3周:CGAN|生成手势图像
目录
- 一、准备工作
- 1. 导入数据
- 2. 数据可视化
- 二、构建模型
- 1. 构建生成器
- 2. 构建鉴别器
- 三、训练模型
- 1. 定义损失函数
- 2. 定义优化器
- 3. 训练模型
- 四、理论基础
- 1.DCGAN原理
- 2.DCGAN网络
- 3.个人感悟
- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊|接辅导、项目定制
一、准备工作
import torch
import numpy as np
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.autograd import Variable
from torchvision.utils import save_image
from torchvision.utils import make_grid
from torch.utils.tensorboard import SummaryWriter
from torchsummary import summary
import matplotlib.pyplot as plt
import datetime
torch.manual_seed(1)
<torch._C.Generator at 0x1737fda1c10>
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
batch_size = 128
1. 导入数据
train_transform = transforms.Compose([transforms.Resize(128),transforms.ToTensor(),transforms.Normalize([0.5,0.5,0.5], [0.5,0.5,0.5])])train_dataset = datasets.ImageFolder(root='./data/rps/', transform=train_transform)
train_loader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=batch_size, shuffle=True,num_workers=6)
2. 数据可视化
def show_images(images):fig, ax = plt.subplots(figsize=(20, 20))ax.set_xticks([]); ax.set_yticks([])ax.imshow(make_grid(images.detach(), nrow=22).permute(1, 2, 0))def show_batch(dl):for images, _ in dl:show_images(images)break
~~~python
show_batch(train_loader)
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).

image_shape = (3, 128, 128)
image_dim = int(np.prod(image_shape))
latent_dim = 100n_classes = 3
embedding_dim = 100
二、构建模型
# 自定义权重初始化函数,用于初始化生成器和判别器的权重
def weights_init(m):# 获取当前层的类名classname = m.__class__.__name__# 如果当前层是卷积层(类名中包含 'Conv' )if classname.find('Conv') != -1:# 使用正态分布随机初始化权重,均值为0,标准差为0.02torch.nn.init.normal_(m.weight, 0.0, 0.02)# 如果当前层是批归一化层(类名中包含 'BatchNorm' )elif classname.find('BatchNorm') != -1:# 使用正态分布随机初始化权重,均值为1,标准差为0.02torch.nn.init.normal_(m.weight, 1.0, 0.02)# 将偏置项初始化为全零torch.nn.init.zeros_(m.bias)
1. 构建生成器
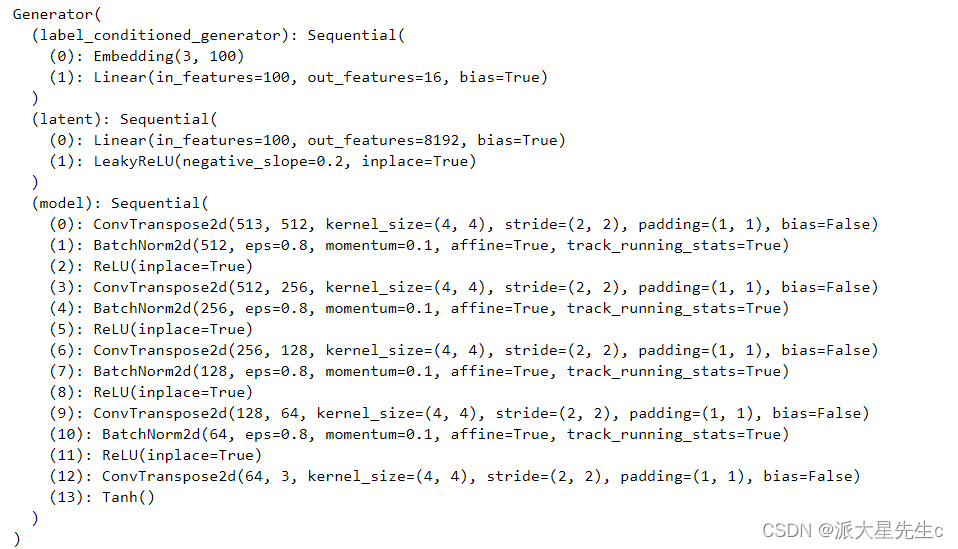
class Generator(nn.Module):def __init__(self):super(Generator, self).__init__()# 定义条件标签的生成器部分,用于将标签映射到嵌入空间中# n_classes:条件标签的总数# embedding_dim:嵌入空间的维度self.label_conditioned_generator = nn.Sequential(nn.Embedding(n_classes, embedding_dim), # 使用Embedding层将条件标签映射为稠密向量nn.Linear(embedding_dim, 16) # 使用线性层将稠密向量转换为更高维度)# 定义潜在向量的生成器部分,用于将噪声向量映射到图像空间中# latent_dim:潜在向量的维度self.latent = nn.Sequential(nn.Linear(latent_dim, 4*4*512), # 使用线性层将潜在向量转换为更高维度nn.LeakyReLU(0.2, inplace=True) # 使用LeakyReLU激活函数进行非线性映射)# 定义生成器的主要结构,将条件标签和潜在向量合并成生成的图像self.model = nn.Sequential(# 反卷积层1:将合并后的向量映射为64x8x8的特征图nn.ConvTranspose2d(513, 64*8, 4, 2, 1, bias=False),nn.BatchNorm2d(64*8, momentum=0.1, eps=0.8), # 批标准化nn.ReLU(True), # ReLU激活函数# 反卷积层2:将64x8x8的特征图映射为64x4x4的特征图nn.ConvTranspose2d(64*8, 64*4, 4, 2, 1, bias=False),nn.BatchNorm2d(64*4, momentum=0.1, eps=0.8),nn.ReLU(True),# 反卷积层3:将64x4x4的特征图映射为64x2x2的特征图nn.ConvTranspose2d(64*4, 64*2, 4, 2, 1, bias=False),nn.BatchNorm2d(64*2, momentum=0.1, eps=0.8),nn.ReLU(True),# 反卷积层4:将64x2x2的特征图映射为64x1x1的特征图nn.ConvTranspose2d(64*2, 64*1, 4, 2, 1, bias=False),nn.BatchNorm2d(64*1, momentum=0.1, eps=0.8),nn.ReLU(True),# 反卷积层5:将64x1x1的特征图映射为3x64x64的RGB图像nn.ConvTranspose2d(64*1, 3, 4, 2, 1, bias=False),nn.Tanh() # 使用Tanh激活函数将生成的图像像素值映射到[-1, 1]范围内)def forward(self, inputs):noise_vector, label = inputs# 通过条件标签生成器将标签映射为嵌入向量label_output = self.label_conditioned_generator(label)# 将嵌入向量的形状变为(batch_size, 1, 4, 4),以便与潜在向量进行合并label_output = label_output.view(-1, 1, 4, 4)# 通过潜在向量生成器将噪声向量映射为潜在向量latent_output = self.latent(noise_vector)# 将潜在向量的形状变为(batch_size, 512, 4, 4),以便与条件标签进行合并latent_output = latent_output.view(-1, 512, 4, 4)# 将条件标签和潜在向量在通道维度上进行合并,得到合并后的特征图concat = torch.cat((latent_output, label_output), dim=1)# 通过生成器的主要结构将合并后的特征图生成为RGB图像image = self.model(concat)return image~~~python
generator = Generator().to(device)
generator.apply(weights_init)
print(generator)
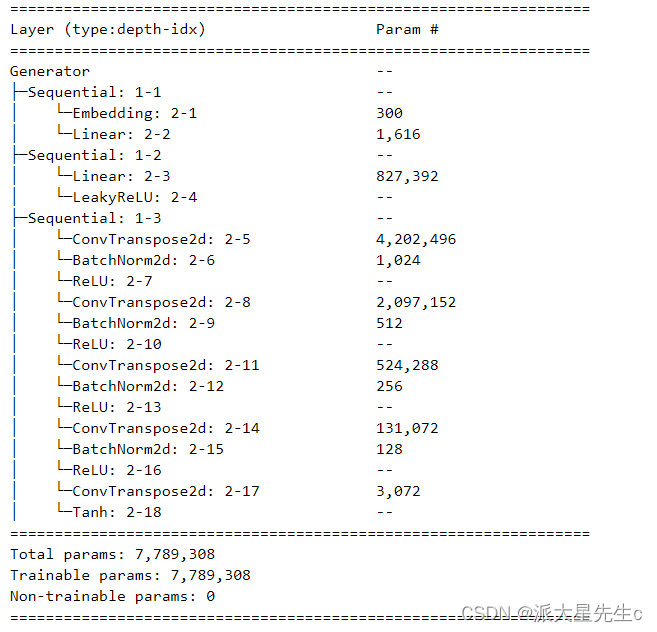
from torchinfo import summarysummary(generator)
a = torch.ones(100)
b = torch.ones(1)
b = b.long()
a = a.to(device)
b = b.to(device)
# generator((a,b))2. 构建鉴别器
import torch
import torch.nn as nnclass Discriminator(nn.Module):def __init__(self):super(Discriminator, self).__init__()# 定义一个条件标签的嵌入层,用于将类别标签转换为特征向量self.label_condition_disc = nn.Sequential(nn.Embedding(n_classes, embedding_dim), # 嵌入层将类别标签编码为固定长度的向量nn.Linear(embedding_dim, 3*128*128) # 线性层将嵌入的向量转换为与图像尺寸相匹配的特征张量)# 定义主要的鉴别器模型self.model = nn.Sequential(nn.Conv2d(6, 64, 4, 2, 1, bias=False), # 输入通道为6(包含图像和标签的通道数),输出通道为64,4x4的卷积核,步长为2,padding为1nn.LeakyReLU(0.2, inplace=True), # LeakyReLU激活函数,带有负斜率,增加模型对输入中的负值的感知能力nn.Conv2d(64, 64*2, 4, 3, 2, bias=False), # 输入通道为64,输出通道为64*2,4x4的卷积核,步长为3,padding为2nn.BatchNorm2d(64*2, momentum=0.1, eps=0.8), # 批量归一化层,有利于训练稳定性和收敛速度nn.LeakyReLU(0.2, inplace=True),nn.Conv2d(64*2, 64*4, 4, 3, 2, bias=False), # 输入通道为64*2,输出通道为64*4,4x4的卷积核,步长为3,padding为2nn.BatchNorm2d(64*4, momentum=0.1, eps=0.8),nn.LeakyReLU(0.2, inplace=True),nn.Conv2d(64*4, 64*8, 4, 3, 2, bias=False), # 输入通道为64*4,输出通道为64*8,4x4的卷积核,步长为3,padding为2nn.BatchNorm2d(64*8, momentum=0.1, eps=0.8),nn.LeakyReLU(0.2, inplace=True),nn.Flatten(), # 将特征图展平为一维向量,用于后续全连接层处理nn.Dropout(0.4), # 随机失活层,用于减少过拟合风险nn.Linear(4608, 1), # 全连接层,将特征向量映射到输出维度为1的向量nn.Sigmoid() # Sigmoid激活函数,用于输出范围限制在0到1之间的概率值)def forward(self, inputs):img, label = inputs# 将类别标签转换为特征向量label_output = self.label_condition_disc(label)# 重塑特征向量为与图像尺寸相匹配的特征张量label_output = label_output.view(-1, 3, 128, 128)# 将图像特征和标签特征拼接在一起作为鉴别器的输入concat = torch.cat((img, label_output), dim=1)# 将拼接后的输入通过鉴别器模型进行前向传播,得到输出结果output = self.model(concat)return output
discriminator = Discriminator().to(device)
discriminator.apply(weights_init)
print(discriminator)

summary(discriminator)

a = torch.ones(2,3,128,128)
b = torch.ones(2,1)
b = b.long()
a = a.to(device)
b = b.to(device)c = discriminator((a,b))
c.size()torch.Size([2, 1])
三、训练模型
1. 定义损失函数
adversarial_loss = nn.BCELoss() def generator_loss(fake_output, label):gen_loss = adversarial_loss(fake_output, label)return gen_lossdef discriminator_loss(output, label):disc_loss = adversarial_loss(output, label)return disc_loss
2. 定义优化器
learning_rate = 0.0002G_optimizer = optim.Adam(generator.parameters(), lr = learning_rate, betas=(0.5, 0.999))
D_optimizer = optim.Adam(discriminator.parameters(), lr = learning_rate, betas=(0.5, 0.999))
3. 训练模型
# 设置训练的总轮数
num_epochs = 100
# 初始化用于存储每轮训练中判别器和生成器损失的列表
D_loss_plot, G_loss_plot = [], []# 循环进行训练
for epoch in range(1, num_epochs + 1):# 初始化每轮训练中判别器和生成器损失的临时列表D_loss_list, G_loss_list = [], []# 遍历训练数据加载器中的数据for index, (real_images, labels) in enumerate(train_loader):# 清空判别器的梯度缓存D_optimizer.zero_grad()# 将真实图像数据和标签转移到GPU(如果可用)real_images = real_images.to(device)labels = labels.to(device)# 将标签的形状从一维向量转换为二维张量(用于后续计算)labels = labels.unsqueeze(1).long()# 创建真实目标和虚假目标的张量(用于判别器损失函数)real_target = Variable(torch.ones(real_images.size(0), 1).to(device))fake_target = Variable(torch.zeros(real_images.size(0), 1).to(device))# 计算判别器对真实图像的损失D_real_loss = discriminator_loss(discriminator((real_images, labels)), real_target)# 从噪声向量中生成假图像(生成器的输入)noise_vector = torch.randn(real_images.size(0), latent_dim, device=device)noise_vector = noise_vector.to(device)generated_image = generator((noise_vector, labels))# 计算判别器对假图像的损失(注意detach()函数用于分离生成器梯度计算图)output = discriminator((generated_image.detach(), labels))D_fake_loss = discriminator_loss(output, fake_target)# 计算判别器总体损失(真实图像损失和假图像损失的平均值)D_total_loss = (D_real_loss + D_fake_loss) / 2D_loss_list.append(D_total_loss)# 反向传播更新判别器的参数D_total_loss.backward()D_optimizer.step()# 清空生成器的梯度缓存G_optimizer.zero_grad()# 计算生成器的损失G_loss = generator_loss(discriminator((generated_image, labels)), real_target)G_loss_list.append(G_loss)# 反向传播更新生成器的参数G_loss.backward()G_optimizer.step()# 打印当前轮次的判别器和生成器的平均损失print('Epoch: [%d/%d]: D_loss: %.3f, G_loss: %.3f' % ((epoch), num_epochs, torch.mean(torch.FloatTensor(D_loss_list)), torch.mean(torch.FloatTensor(G_loss_list))))# 将当前轮次的判别器和生成器的平均损失保存到列表中D_loss_plot.append(torch.mean(torch.FloatTensor(D_loss_list)))G_loss_plot.append(torch.mean(torch.FloatTensor(G_loss_list)))if epoch%10 == 0:# 将生成的假图像保存为图片文件save_image(generated_image.data[:50], './images/sample_%d' % epoch + '.png', nrow=5, normalize=True)# 将当前轮次的生成器和判别器的权重保存到文件torch.save(generator.state_dict(), './training_weights/generator_epoch_%d.pth' % (epoch))torch.save(discriminator.state_dict(), './training_weights/discriminator_epoch_%d.pth' % (epoch))
# 四、模型分析
## 1. 加载模型
~~~python
generator.load_state_dict(torch.load('./training_weights/generator_epoch_100.pth'), strict=False)
generator.eval()

# 导入所需的库
from numpy import asarray
from numpy.random import randn
from numpy.random import randint
from numpy import linspace
from matplotlib import pyplot
from matplotlib import gridspec# 生成潜在空间的点,作为生成器的输入
def generate_latent_points(latent_dim, n_samples, n_classes=3):# 从标准正态分布中生成潜在空间的点x_input = randn(latent_dim * n_samples)# 将生成的点整形成用于神经网络的输入的批量z_input = x_input.reshape(n_samples, latent_dim)return z_input# 在两个潜在空间点之间进行均匀插值
def interpolate_points(p1, p2, n_steps=10):# 在两个点之间进行插值,生成插值比率ratios = linspace(0, 1, num=n_steps)# 线性插值向量vectors = list()for ratio in ratios:v = (1.0 - ratio) * p1 + ratio * p2vectors.append(v)return asarray(vectors)# 生成两个潜在空间的点
pts = generate_latent_points(100, 2)
# 在两个潜在空间点之间进行插值
interpolated = interpolate_points(pts[0], pts[1])# 将数据转换为torch张量并将其移至GPU(假设device已正确声明为GPU)
interpolated = torch.tensor(interpolated).to(device).type(torch.float32)output = None
# 对于三个类别的循环,分别进行插值和生成图片
for label in range(3):# 创建包含相同类别标签的张量labels = torch.ones(10) * labellabels = labels.to(device)labels = labels.unsqueeze(1).long()print(labels.size())# 使用生成器生成插值结果predictions = generator((interpolated, labels))predictions = predictions.permute(0,2,3,1)pred = predictions.detach().cpu()if output is None:output = predelse:output = np.concatenate((output,pred))
torch.Size([10, 1])
torch.Size([10, 1])
torch.Size([10, 1])output.shape(30, 128, 128, 3)nrow = 3
ncol = 10fig = plt.figure(figsize=(15,4))
gs = gridspec.GridSpec(nrow, ncol) k = 0
for i in range(nrow):for j in range(ncol):pred = (output[k, :, :, :] + 1 ) * 127.5pred = np.array(pred) ax= plt.subplot(gs[i,j])ax.imshow(pred.astype(np.uint8))ax.set_xticklabels([])ax.set_yticklabels([])ax.axis('off')k += 1 plt.show()

四、理论基础
1.DCGAN原理
条件生成对抗网络(CGAN)是在生成对抗网络(GAN)的基础上进行了一些改进。对于原始GAN的生成器而言,其生成的图像数据是随机不可预测的,因此我们无法控制网络的输出,在实际操作中的可控性不强。
针对上述原始GAN无法生成具有特定属性的图像数据的问题,Mehdi Mirza等人在2014年提出了条件生成对抗网络(CGAN),全称为Conditional Generative Adversarial Network。与标准的 GAN 不同,CGAN 通过给定额外的条件信息来控制生成的样本的特征。这个条件信息可以是任何类型的,例如图像标签、文本标签等。
在 CGAN 中,生成器(Generator)和判别器(Discriminator)都接收条件信息。生成器的目标是生成与条件信息相关的合成样本,而判别器的目标是将生成的样本与真实样本区分开来。当生成器和判别器通过反馈循环不断地进行训练时,生成器会逐渐学会如何生成符合条件信息的样本,而判别器则会逐渐变得更加准确。
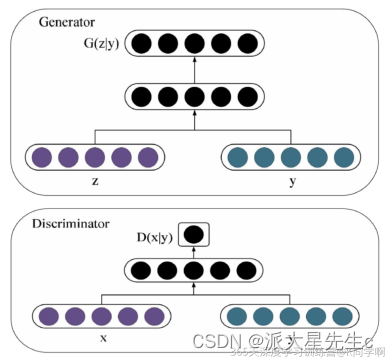
由上图的网络结构可知,条件信息y作为额外的输入被引入对抗网络中,与生成器中的噪声z合并作为隐含层表达;而在判别器D中,条件信息y则与原始数据x合并作为判别函数的输入。
2.DCGAN网络
DCGAN(Deep Convolutional Generative Adversarial Network)是一种基于卷积神经网络的生成对抗网络。它在原始GAN的基础上引入了深度卷积网络来增强模型的表达能力和生成图像的质量。
DCGAN的核心思想是将生成器(Generator)和判别器(Discriminator)组合在一起,并通过互相对抗的训练方式来不断优化两个网络。生成器的目标是生成逼真的图像样本,而判别器的目标是将生成的样本与真实样本区分开来。
具体而言,DCGAN采用了以下关键技术:
-
使用卷积层代替全连接层:在生成器和判别器中,使用卷积层来处理图像数据,这使得网络可以有效地捕捉到图像的局部纹理特征和全局结构信息。同时,卷积层还减少了参数数量,降低了计算复杂度。
-
采用批量归一化(Batch Normalization):为了加速训练过程并稳定模型的学习过程,DCGAN在生成器和判别器的每一层后面都添加了批量归一化层。批量归一化可以使得网络对输入数据的变动更加鲁棒,并且有助于减少梯度消失和梯度爆炸问题。
-
使用LeakyReLU激活函数:为了避免生成器和判别器中的神经元出现“死亡”现象(即永远不会激活),DCGAN采用了LeakyReLU激活函数。它可以在负输入时引入一个小的斜率,使得信息可以更好地传播。
-
去除全连接层:与原始的GAN不同,DCGAN去除了生成器和判别器中的全连接层,这样可以避免过拟合的问题,降低了模型的复杂度。
通过以上技术的应用,DCGAN可以生成逼真的图像样本,并具备一定的生成控制能力。
3.个人感悟
DCGAN作为一种生成对抗网络的改进模型,为我们提供了一种有条件控制生成图像的方式。通过给定额外的条件信息,我们可以精确地生成符合要求的图像样本,这对于许多实际应用非常有意义。
同时,DCGAN也展示了深度卷积网络在图像生成任务中的强大能力。通过使用深度卷积网络,模型可以有效地捕捉到图像中的局部特征和全局结构,生成的图像更加真实自然。
然而,在使用DCGAN进行图像生成时,还需要考虑模型的训练稳定性和收敛性的问题。由于生成对抗网络的优化过程相对复杂,需要平衡生成器和判别器的能力,以及调整超参数等方面的工作。
总之,DCGAN作为一种生成对抗网络的改进模型,不仅提高了图像生成的可控性和质量,同时也展示了深度卷积网络在图像生成任务中的重要作用。我对于这种模型的发展和应用潜力感到非常期待。
相关文章:
第G3周:CGAN|生成手势图像
目录 一、准备工作1. 导入数据2. 数据可视化 二、构建模型1. 构建生成器2. 构建鉴别器 三、训练模型1. 定义损失函数2. 定义优化器3. 训练模型 四、理论基础1.DCGAN原理2.DCGAN网络3.个人感悟 🍨 本文为🔗365天深度学习训练营 中的学习记录博客…...
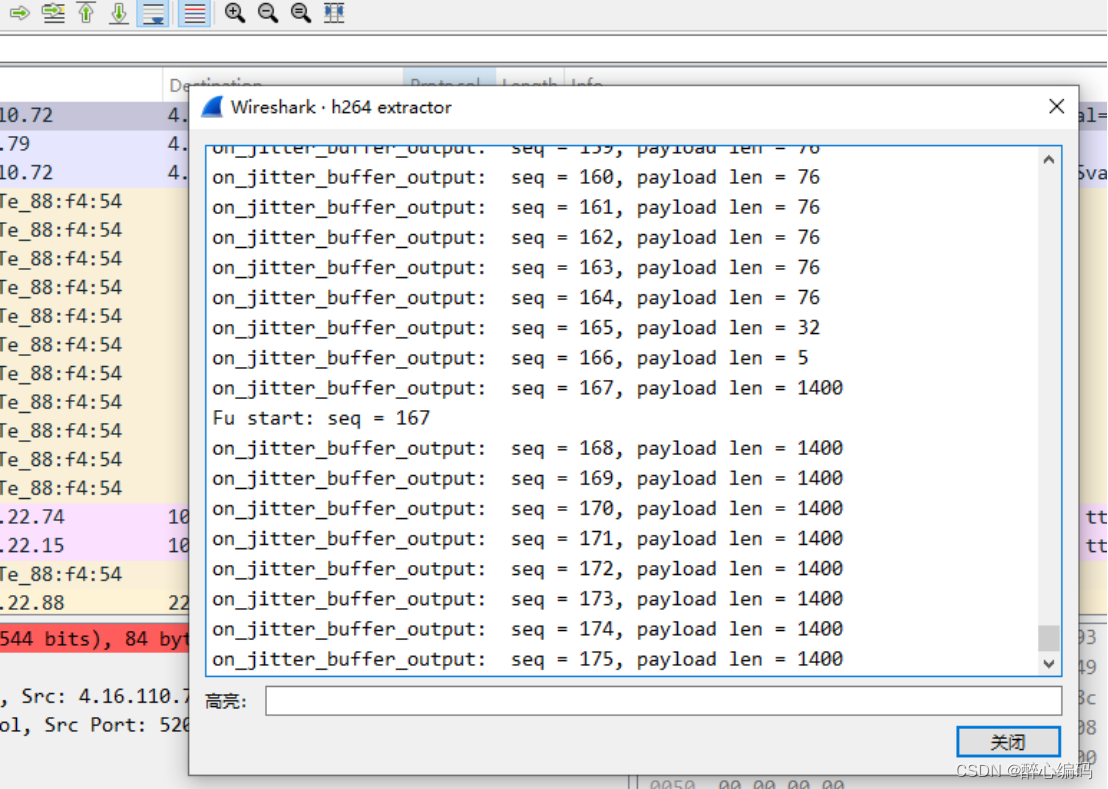
wireshark导出H264裸流
导出H264裸流 安装wireshark下载rtp_h264_extractor.lua脚本配置lua脚本重启wireshark筛选 安装wireshark 下载抓包工具:首先,您需要下载并安装一个网络抓包工具,例如Wireshark(https://www.wireshark.org)或tcpdump&…...

Sentinel针对IP限流
改造限流策略的针对来源选项 import com.alibaba.csp.sentinel.adapter.spring.webmvc.callback.RequestOriginParser; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration;Configuration public class Senti…...
S475支持 ModbusRTU 转 MQTT协议采集网关
6路模拟量输入和2路RS485串口是一种功能强大的通信接口,可以接入多种设备和系统,支持4-20mA输出的传感器以及开关量输入输出。本文将详细介绍6路模拟量输入和2路RS485串口的应用场景和功能,重点介绍其在SCADA、HMI、远程数据监控以及采集控制…...
js的变量
目录 变量 var和let 1.for循环中的声明 2.暂时性死区 3.全局声明 4.条件声明 const声明 变量 java是一种强数据类型语言,对数据类型要求高,要声明清楚变量的类型 数据类型 变量名 值 -----> int a 10 而javaScrit是一种弱类型语言,在声明变…...

MicroPython for ESP32
MicroPython for ESP32 开发板引脚图 环境搭建 参考资料 https://zhuanlan.zhihu.com/p/587027345 官方资料 https://docs.micropython.org/en/latest/ http://vcc-gnd.com/rtd/html/esp32/quickref.html#i2c 创建一个虚拟环境, conda create -n esp32 pytho…...
选择适合产品需求管理的项目管理系统,打造完美项目流程!
一般来说,互联网产品经理收到的需求一般分为业务需求、用户需求和产品功能需求。业务需求主要包括战略和规则需求;用户需求一般是真实反馈、真实需求、吐槽、建议等。;功能需求主要围绕产品的旧功能问题进行升级,bug处理、技术问题…...

@monaco-editor/react组件CDN加载失败解决办法
monaco-editor/react引入这个cdn资源会load失败 网上很多例子都是这样写的,我这样写monaco会报错 import * as monaco from monaco-editor; import { loader } from monaco-editor/react;loader.config({ monaco });改成这样 import * as monaco from monaco-edi…...

java对象的强引用,弱引用,软引用,虚引用
前言:java对象在java虚拟机中的生存状态,面试可能会有人问道,了解一下 这里大量引用 《疯狂Java讲义第4版》 书中的内容...
ubuntu ssh
前置 需要知道自己的ip 如果没有ifconfig sudo apt-get install net-tools然后 ifconfig中文用户 winr,输入 intl.cpl在git里,选zh_cn和UTF-8 安装 sudo apt-get install -y openssh-client openssh-server设置开机启动 sudo systemctl enable sshsudo nano…...

js:斐波那契额数列生成器Generator
请你编写一个生成器函数,并返回一个可以生成 斐波那契数列 的生成器对象。 斐波那契数列 的递推公式为 Xn Xn-1 Xn-2 。 这个数列的前几个数字是 0, 1, 1, 2, 3, 5, 8, 13 。 /*** return {Generator<number>}*/ var fibGenerator function*() {let pre…...
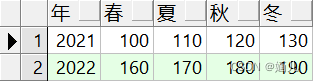
行列转换.
表abc: (建表语句在文章末尾) 想要得到: 方法一 with a as(select 年,产 from abc where 季1), b as(select 年,产 from abc where 季2), c as(select 年,产 from abc where 季3), d as(select 年,产 from abc where 季4) selec…...

CentOs 7利用iscaiadm工具发现并连接外接存储
CentOs 7利用iscaiadm工具发现并连接外接存储 1.1 使用iscsiadm发现存储 iscsiadm -m discovery -t st -p ${外接存储IP} # 执行结果may like ${外接存储IP}:3260,1 iqn.${存储唯一标识} 1.2 登入发现的存储 iscsiadm -m node -T iqn.${存储唯一标识} -p ${外接存储IP} -…...
Java期末复习基础题编程题
文章目录 基础题记录实践题记录&&与C比较题目1:题目2:题目3: 基础题记录 编译型语言: 定义:在程序运行之前,通过编译器将源程序编译成机器码(可运行的二进制代码),以后执行这个程序时&…...
资深测试总结,自动化测试-ddt数据驱动yaml文件实战(详细)
目录:导读 前言一、Python编程入门到精通二、接口自动化项目实战三、Web自动化项目实战四、App自动化项目实战五、一线大厂简历六、测试开发DevOps体系七、常用自动化测试工具八、JMeter性能测试九、总结(尾部小惊喜) 前言 ddt 驱动 yaml/ym…...
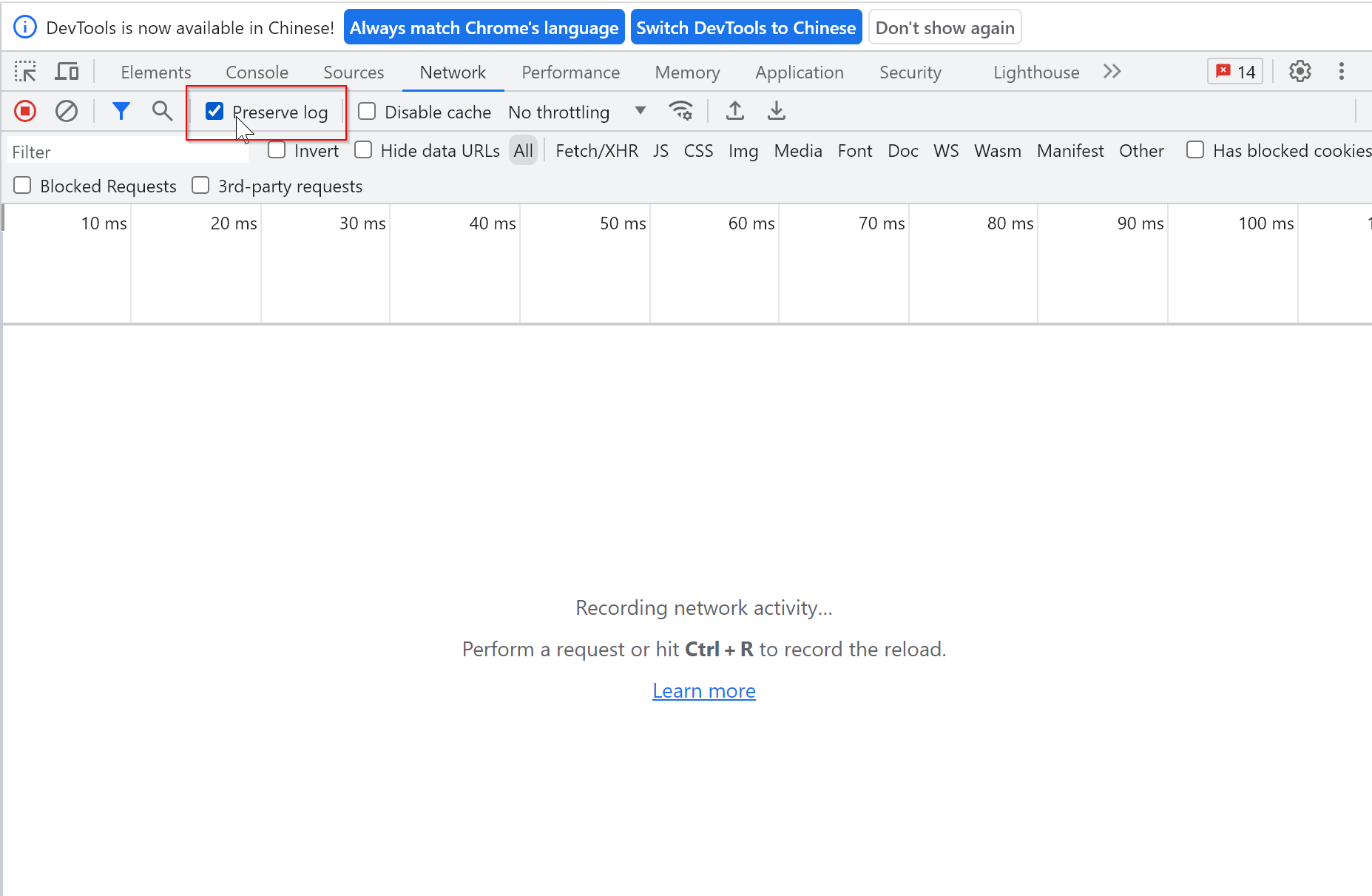
F12 浏览器调试模式页面刷新 network 日志刷新消失的解决办法
每次请求刷新后都把之前的请求记录刷新掉了,把preserve log勾选上后,所有的请求都会保留,再也不怕抓不到记录了。...
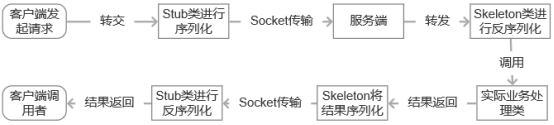
代理模式-对象的间接访问
现在朋友圈有好多做香港代购的微商,大部分网民无法自己去香港购买想要的商品,于是委托这些微商,告诉他们想要的商品,让他们帮我们购买。我们只需要付钱给他们,他们就会去香港购买,然后把商品寄给我们。这就…...

汽车产业链面临重大变革 大运乘用车加强产业布局 助力低碳出行
当前,国家“双碳”战略的全面实施,全球绿色产业发展理念的不断加深以及汽车产品形态、交通出行模式、能源消费结构变革所呈现的发展机遇等诸多因素,持续推动新能源汽车产业全面转型提速。据悉,2022年,中国新能源汽车销…...
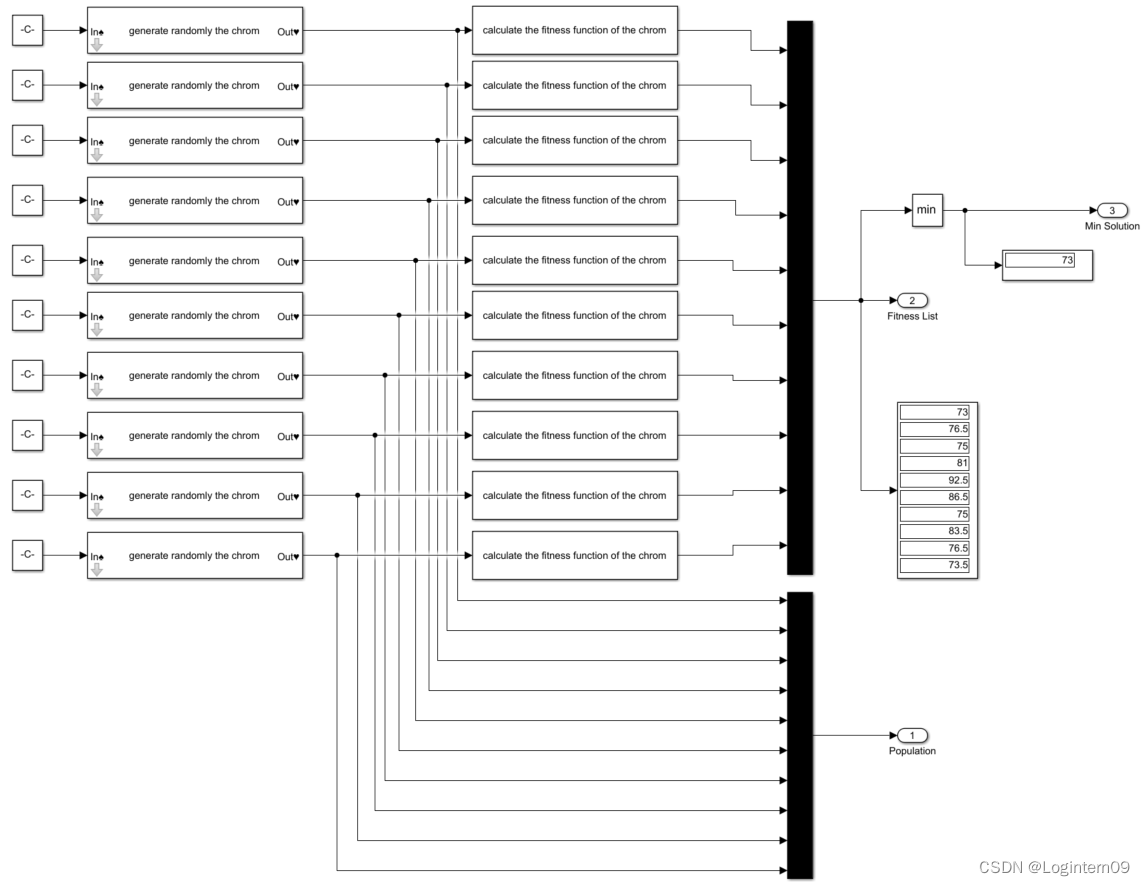
simulink与遗传算法结合求解TSP问题
前言:刚开始入门学习simulink,了解了基本的模块功能后想尝试从自己熟悉的领域入手,自己出题使用simulink搭建模型。选择的是TSP问题的遗传算法,考虑如何用simulink建模思想来实现一个简单TSP问题的遗传算法。 TSP问题描述 一个配…...

环境搭建-Ubuntu18.04.6系统TensorFlow BenchMark的GPU测试
1. 下载Ubuntu18.04.6镜像 登录阿里云官方镜像站:阿里巴巴开源镜像站-OPSX镜像站-阿里云开发者社区 2. 测试环境 Server OS:Ubuntu 20.04.6 LTS Kernel: Linux 5.4.0-155-generic x86-64 Docker Version:24.0.5, build ced0996 docker-com…...

效率提升秘籍:用快马AI自动生成技能评估系统的管理后台与评分引擎
今天想和大家分享一个提升开发效率的实用技巧——如何快速搭建技能评估系统的核心模块。最近在做一个叫skill-vetter的项目,发现其中很多功能其实可以通过智能工具自动生成,省去了大量重复编码的时间。 题库管理模块的实现思路 这个模块的核心需求是让…...

OpenClaw日志分析:QwQ-32B任务执行效率监控
OpenClaw日志分析:QwQ-32B任务执行效率监控 1. 为什么需要监控OpenClaw任务执行效率 去年冬天,我部署了一个自动整理会议纪要的OpenClaw工作流。起初运行得很顺利,直到某天早上发现它漏掉了三场重要会议的记录。检查日志才发现,…...

比亚迪多款新车激光雷达性能超越华为:千线级感知开启智驾新纪元
2026年,中国智能驾驶行业正式进入“千线级激光雷达”时代。继华为发布896线双光路激光雷达后,比亚迪携速腾聚创EM4数字化激光雷达强势反击,以1080线物理扫描、600米最远探测的硬核参数,在核心感知硬件上实现对华为的全面超越。这一突破不仅标志着比亚迪补齐了智能化短板,更…...

基于主从博弈的主动配电网阻塞管理探索
基于主从博弈的主动配电网阻塞管理 首先,在日前市场中,LA(负荷聚合商)根据历史数据预测次日向上级电网购电的电价信息和预测分布式电源(燃气轮机)出力、风电场出力信息,同时考虑事前与用户签订协议的可中断负荷&#x…...

Apache Sedona 使用教程
Apache Sedona 使用教程 项目介绍 Apache Sedona 是一个用于大规模空间数据处理的分布式计算系统。它基于 Apache Spark,提供了高效的空间数据处理能力,支持多种空间数据类型和操作。Sedona 旨在为大数据环境下的地理空间分析提供强大的支持,…...

Gorgonia性能优化终极指南:10个技巧让你的深度学习模型运行速度翻倍
Gorgonia性能优化终极指南:10个技巧让你的深度学习模型运行速度翻倍 【免费下载链接】gorgonia 项目地址: https://gitcode.com/gh_mirrors/gor/gorgonia Gorgonia是一个功能强大的深度学习框架,能够帮助开发者构建和训练复杂的神经网络模型。然…...

Vue中实现动态标签页的切换优化与状态管理
1. 动态标签页的核心需求与实现思路 在后台管理系统这类多页面应用中,动态标签页几乎是标配功能。想象一下你正在使用某电商后台,同时开着商品管理、订单处理和用户分析三个页面,这时候标签页的流畅切换和状态保持就显得尤为重要。 我经历过一…...

OpenClaw任务编排技巧:Qwen3.5-4B-Claude-4.6-Opus-Reasoning-Distilled-GGUF复杂流程分解策略
OpenClaw任务编排技巧:Qwen3.5-4B-Claude-4.6-Opus-Reasoning-Distilled-GGUF复杂流程分解策略 1. 为什么需要任务编排 上周我尝试用OpenClaw自动完成一篇技术博客的写作和发布,结果遭遇了连环翻车:模型先花20分钟生成了偏离主题的初稿&…...

KKManager全流程管理指南:从安装到效率提升
KKManager全流程管理指南:从安装到效率提升 【免费下载链接】KKManager Mod, plugin and card manager for games by Illusion that use BepInEx 项目地址: https://gitcode.com/gh_mirrors/kk/KKManager 学习目标 理解KKManager的核心价值与应用场景掌握从…...

永磁同步电机双矢量模型预测电流MPCC控制仿真:传统与现代控制策略的对比分析
永磁同步电机双矢量模型预测电流MPCC控制仿真【参考文献】 (1)参考文献:《永磁同步电机鲁棒双矢量模型预测电流控制_郭鑫》 (2)描述:传统单矢量预测电流控制在单个控制周期内只能输出单个电压矢量ÿ…...