MQ - 闲聊MQ一二事儿 (Kafka、RocketMQ 、Pulsar )
文章目录
- MQ的发展史
- 阶段一:追求解耦
- 阶段二:追求吞吐量与一致性
- 阶段三:追求平台化
- MQ的通用架构
- 主题topic、生产者producer、消费者consumer
- 分区partition
- MQ 存储
- Kafka
- Good Design ---> 磁盘顺序写盘
- Poor Impact---> topic 数量不能过大
- RocketMQ
- zookeeper vs namesrv
- 局部顺序写(kafka) 与 完全顺序写(rocketmq)
- Rocketmq 存储结构
- Pulsar
- 架构图(分层+分片)
- 服务层设计
- 存储层设计
- 扩容
- 容灾
- 小结

MQ的发展史

如上图我们可以把消息队列的发展切分成了三个大的阶段
阶段一:追求解耦
- 2003-2010年,计算机软件行业兴起。
- 系统间强耦合是程序设计的难题。
- ActiveMQ和RabbitMQ等消息队列出现。
- 消息队列致力于解决系统间耦合和异步化操作问题。
- 系统间解耦和异步化是消息队列最主要的功能和使用场景。
阶段二:追求吞吐量与一致性
- 10 -12 年期间,大数据时代实时计算需求增长,数据规模扩大,Kafka应运而生满足消息队列高吞吐量和并发需求。
- 随着阿里电商业务发展,Kafka在可靠性、一致性、顺序消息等方面无法满足需求。
- RocketMQ诞生,吸收Kafka设计理念之余,解决其痛点。
- RocketMQ不依赖Zookeeper,增强可靠性、一致性、顺序消息能力。
- 阿里将RocketMQ开源,最终成为Apache项目,满足大数据 messaging 需求。
阶段三:追求平台化
- 平台化的产品会取代非平台化的产品,这是行业发展趋势。
- 2012年后,云计算、容器化兴起,公司开始把基础技术能力平台化。
- 阿里云、腾讯云等云服务的出现证明了这一趋势。
- Pulsar诞生于此背景下,目的是解决雅虎内部重复建设、消息队列隔离不好、数据迁移难等问题。
- Pulsar通过提供平台化的消息队列服务来解决这些问题。
- 平台化是Pulsar产生的核心原因,也是解决上述问题的关键所在。
MQ的通用架构
主题topic、生产者producer、消费者consumer
用吃饭的场景生动地诠释了消息队列的几个关键概念:
- 饭堂的不同档口(米饭、面、麻辣香锅)对应消息队列的主题(topic)概念。
- 用户选择某个档口排队取餐,这个过程相当于生产者生产了一条消息到该主题的消息队列中。
- 档口将餐食提供给用户,则相当于消费者从消息队列中消费了一条消息。
- 用户排队等待相当于消息在队列中的存储等待被消费的过程。
- 取餐按排队顺序进行,消费也是按顺序进行的。
通过日常生活的吃饭场景,形象地解释了消息队列的工作原理,包括消息主题、生产者、消费者、消息存储和消费等核心概念。这些概念抽象起来可能较难理解,但结合具象的例子就很容易理解了
分区partition
- 分区是消息队列的一种架构方式,类似于食堂的多个档口。
- 当消息数量增长时,可以通过增加分区数进行扩容,如食堂增加档口数。
- 增加分区可以扩大消息队列的并行处理能力,提高吞吐量,就像增加档口可以减少等待时间。
- 生产者可以根据分区规则,将消息发到不同分区,就像食客可以选择人少的档口。
- 消费者可以从多个分区并行消费消息,提高效率。
- Kafka之所以能达到高吞吐量,是因为它是通过分区实现消息队列并行化和横向扩展的。
总结为:分区实现了消息队列的并行化,是提升吞吐量和实现横向扩展的关键手段。
MQ 存储
特性和性能是存储结构的外在表现,其实质是存储设计。我们需要了解每种消息传递协议的特性,以便更好地理解它们的架构设计。
我们将首先介绍 Kafka、RocketMQ 和 Pulsar 的架构特点,然后比较它们在架构上的不同之处,以及这些不同之处如何影响它们的功能特性。
Kafka
- Kafka 架构中,服务节点没有主从之分,主从概念是针对某个 topic 下的分区。
- 存储单位为分区,通过不同方式分散在各个节点,形成各种架构图。
- 生产者数量为 1,消费者数量为 1,分区数为 2,副本数为 3,服务节点数为 3。
- 图中有两块绿色图案,分别为 topic1-partition1 分区和 topic1-partition2 分区,浅绿色方块为它们的副本。
- 对于服务节点 1,topic1-partition1 是主节点;对于服务节点 2,topic1-partition2 是主节点。
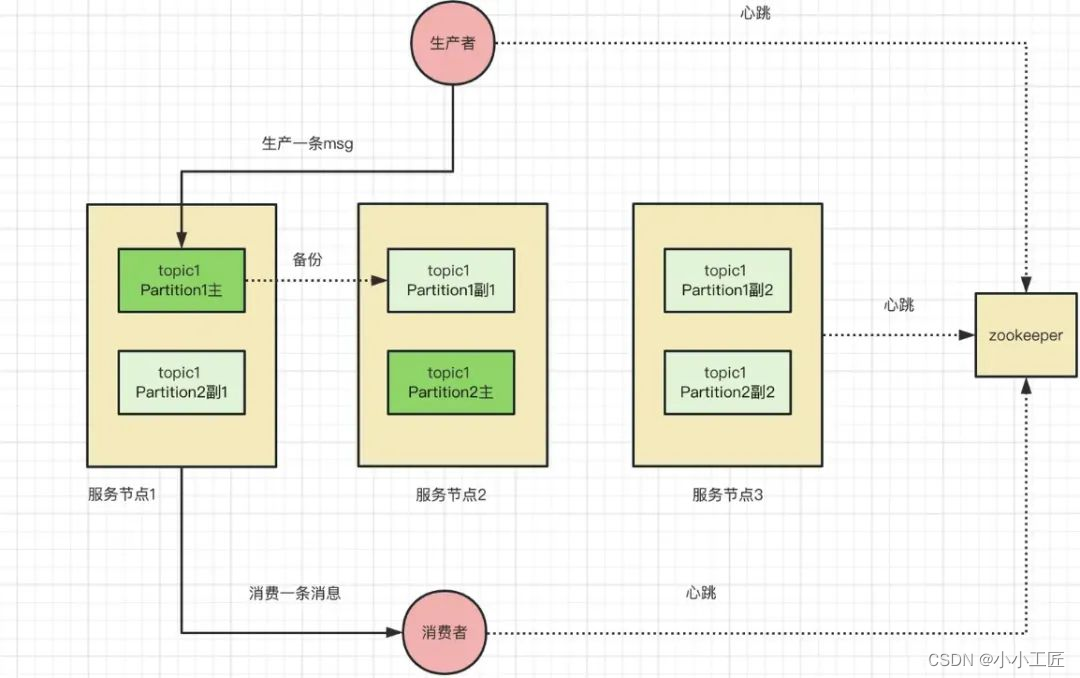
消息队列的大致工作流程如下:
- 生产者、消费者与元数据中心建立连接,并保持心跳,获取服务的实况和路由信息。
- 生产者将消息发送到 topic 下的任一分区中,通过算法保证每个 topic 下的分区尽可能均匀。
- 信息需要落盘才可以给上游返回 ack,以保证宕机后的信息的完整性。
- 在信息写成功主分区后,系统会根据策略选择同步复制还是异步复制,以保证单节点故障时的信息完整性。
- 消费者开始工作,拉取响应的信息,并返回 ack。
- 消费者在获取消息时,会根据偏移量 (offset) 进行拉取,每次拉取后偏移量加 1。
Good Design —> 磁盘顺序写盘
Kafka 在底层设计上强依赖于文件系统(一个分区对应一个文件系统),本质上是基于磁盘存储的消息队列,在我们固有印象中磁盘的读写速度是非常慢的,慢的原因是因为在读写的过程中所有的进程都在抢占“磁头”这把锁,磁头在读写之前需要将其移动到合适的位置,这个“移动”极其耗费时间,这也就是磁盘慢的原因,但是如何不用移动磁头呢,顺序写盘就诞生了。
Kafka 消息存储在分区中,每个分区对应一组连续的物理空间。新消息追加到磁盘文件末尾。消费者按顺序拉取分区数据消费。Kafka 的读写是顺序的,可以高效地利用 PageCache,解决磁盘读写的性能问题。
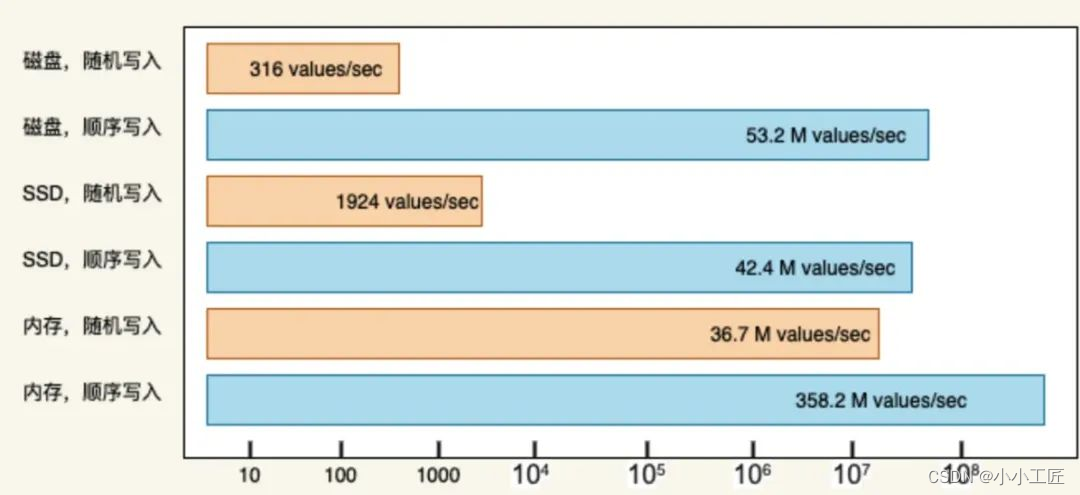
这一特性非常重要,很多组件的底层存储设计都会用到这点,理解好这点对理解消息队列尤为重要。
The Pathologies of Big Data
Poor Impact—> topic 数量不能过大
kafka 的整体性能收到了 topic 数量的限制,这和底层的存储有密不可分的关系,我们上面讲过,当消息来的时候,底层数据使用追加写入的方式,顺序写盘,使得整体的写性能大大提高,但这并不能代表所有情况,当我们 topic 数量从几个变成上千个的时候,情况就有所不同了
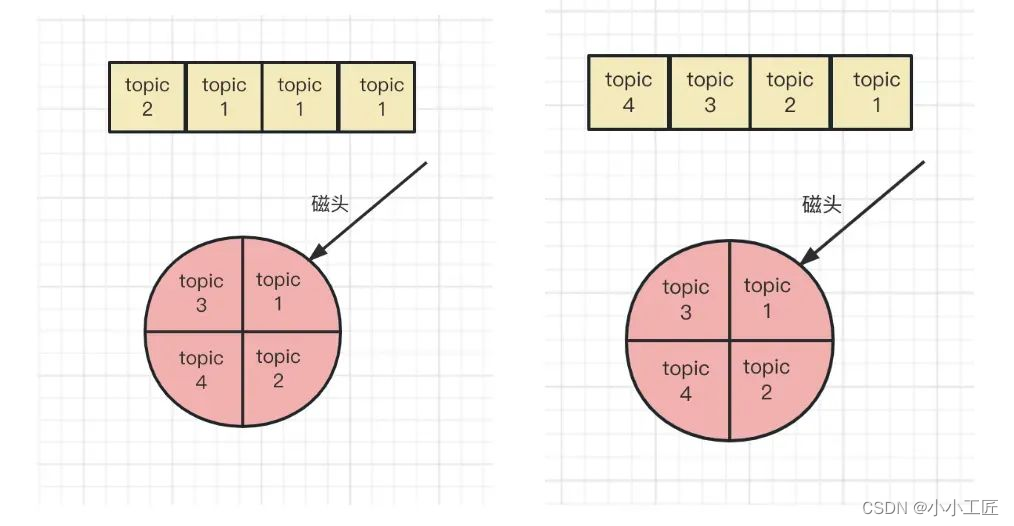
- 左图代表了,队列中从头到尾的信息为:topic1、topic1、topic1、topic2,在这种情况下,很好地运用了顺序写盘的特性,磁头不用去移动
- 右边图的情况,队列中从头到尾的信息为:topic1、topic2、topic3、topic4,当队列中的信息变的很分散的时候,这个时候我们会发现,似乎没有办法利用磁盘的顺序写盘的特性,因为每次写完一种信息,磁头都需要进行移动
就很好理解,为什么当 topic 数量很大时,kafka 的性能会急剧下降了。
当然没有其他办法了吗,当然有。我们可以把存储换成速度更快 ssd 或者针对每一个分区都搞一块磁盘,当然这都是钱! 这也是架构设计中的一种 trade off

RocketMQ
对比 kafka,rocketmq 有两点很大的不同:
- 元数据管理系统,从 zookeeper 变成了轻量级的独立服务集群。
- 服务节点变为 多主多从架构
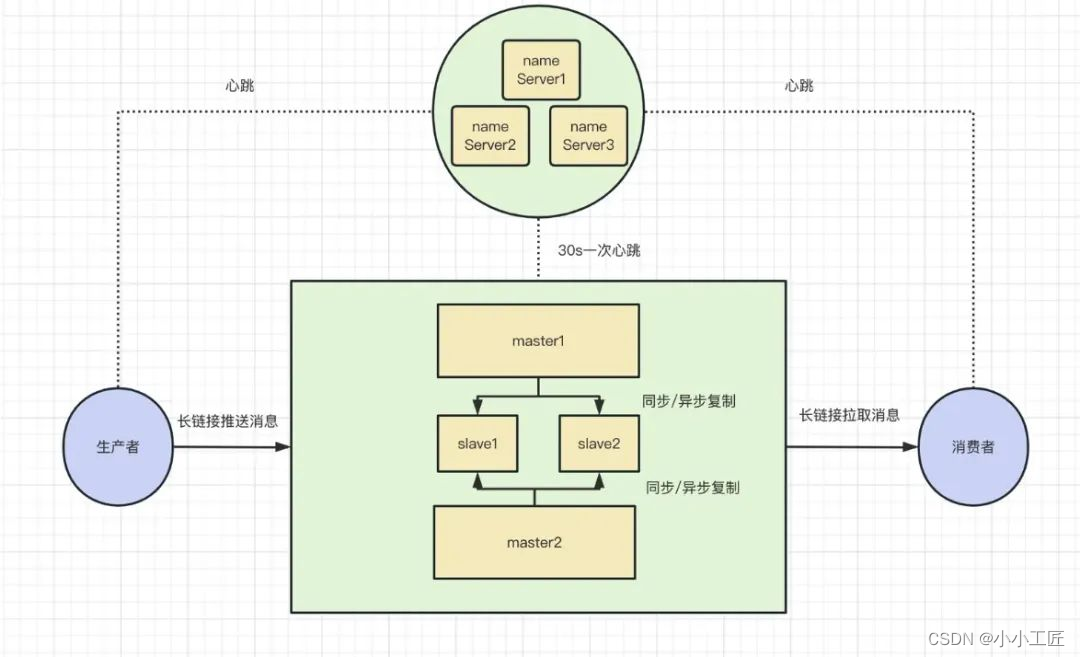
zookeeper vs namesrv
ookeeper 是 cp 强一致架构的一种,其内部使用 zab 算法,进行信息同步和容灾,在信息量较小的情况下,性能较好,当信息交互变多,因为同步带来的性能损耗加大,性能和吞吐量降低。如果 zookeeper 宕机,会导致整个集群的不可用,对于一些交易场景,这是不可接受的
- 相比 Zookeeper,RocketMQ 选择了轻量级的独立服务器 NameSRV。
- NameSRV 使用简单的 K/V 结构保存信息。
- NameSRV 支持集群模式,每个 NameSRV 相互独立,不进行任何通信。
- Data 都保存在内存当中,Broker 的注册过程通过循环遍历所有 NameSRV 进行注册。

局部顺序写(kafka) 与 完全顺序写(rocketmq)
- Kafka 将不同分区写入对应的文件系统中,保证了优秀的水平扩容能力。
- RocketMQ 追求极致的消息写,将所有 topic 消息存储在同一个文件中,确保消息发送时按顺序写文件,提高可用性和吞吐量。
- RocketMQ 的设计使得其不支持删除指定 topic 功能,因为 topic 信息在磁盘上是一段非连续的区域,不像 Kafka 一个 topic 是一段连续的区域。
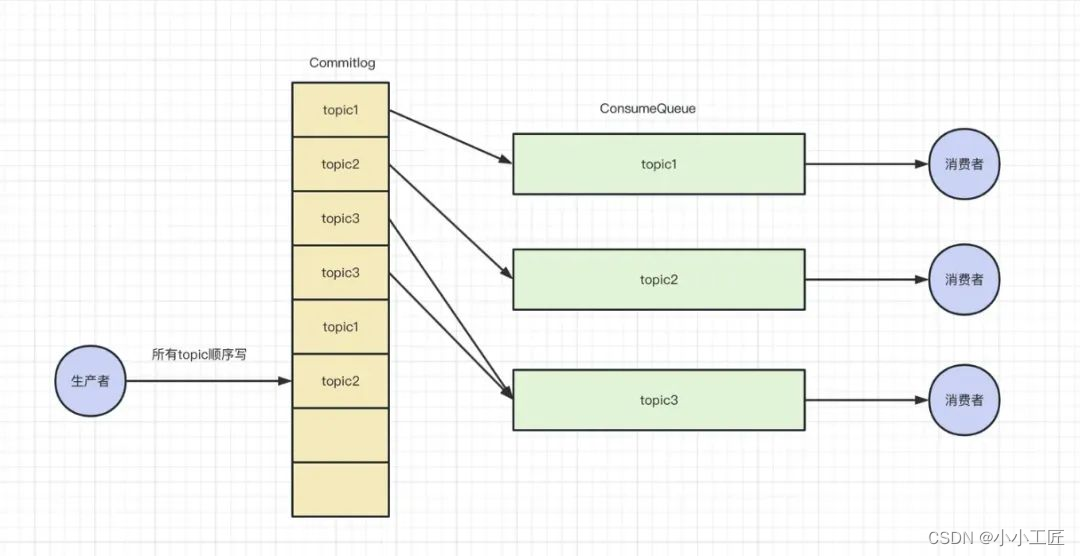
Rocketmq 存储结构
RocketMQ 的存储结构设计是为了追求极致的消息写性能,它采用了混合存储的方式,将多个 Topic 的消息实体内容都存储于一个 CommitLog 中。在 RocketMQ 的存储架构中,有三个重要的存储文件,分别是 CommitLog、ConsumeQueue 和 IndexFile。
-
CommitLog
CommitLog 是存储消息的主体。Producer 发送的消息都会顺序写入 commitLog 文件,所以随着写入的消息增多,文件也会随之变大。单个文件大小默认 1G,文件名长度为 20 位,左边补零,剩余为起始偏移量。例如,00000000000000000000 代表了第一个文件,起始偏移量为 0,文件大小为 1G。当第一个文件写满了,第二个文件为 00000000001073741824,起始偏移量为 1073741824,以此类推。存储路径为HOME/store/commitLog。 -
ConsumeQueue
ConsumeQueue(逻辑消费队列) 可以看成基于 topic 的 commitLog 的索引文件。因为 CommitLog 是按照顺序写入的,不同的 topic 消息都会混淆在一起,而 Consumer 又是按照 topic 来消费消息的,这样的话势必会去遍历 commitLog 文件来过滤 topic,这样性能肯定会非常差,所以 rocketMq 采用 ConsumeQueue 来提高消费性能。即每个 Topic 下的每个 queueId 对应一个 Consumequeue,其中存储了单条消息对应在 commitLog 文件中的物理偏移量 offset,消息大小 size,消息 Tag 的 hash 值。存储路径为HOME/store/consumequeue/topic/queueId/fileName。 -
IndexFile
IndexFile 提供了一种可以通过 key(topicmsgId) 或时间区间来查询消息的方法。他的存在主要是针对在客户端 (生产者和消费者) 和控制台接口提供了根据 key 查询消息的实现。为了方便用户查询具体某条消息。IndexFile 的存储结构可以认为是一个 hashmap。存储路径为HOME/store/index/.HOME/store/index/fileName文件名 fileName 是以创建时的时间戳命名的。
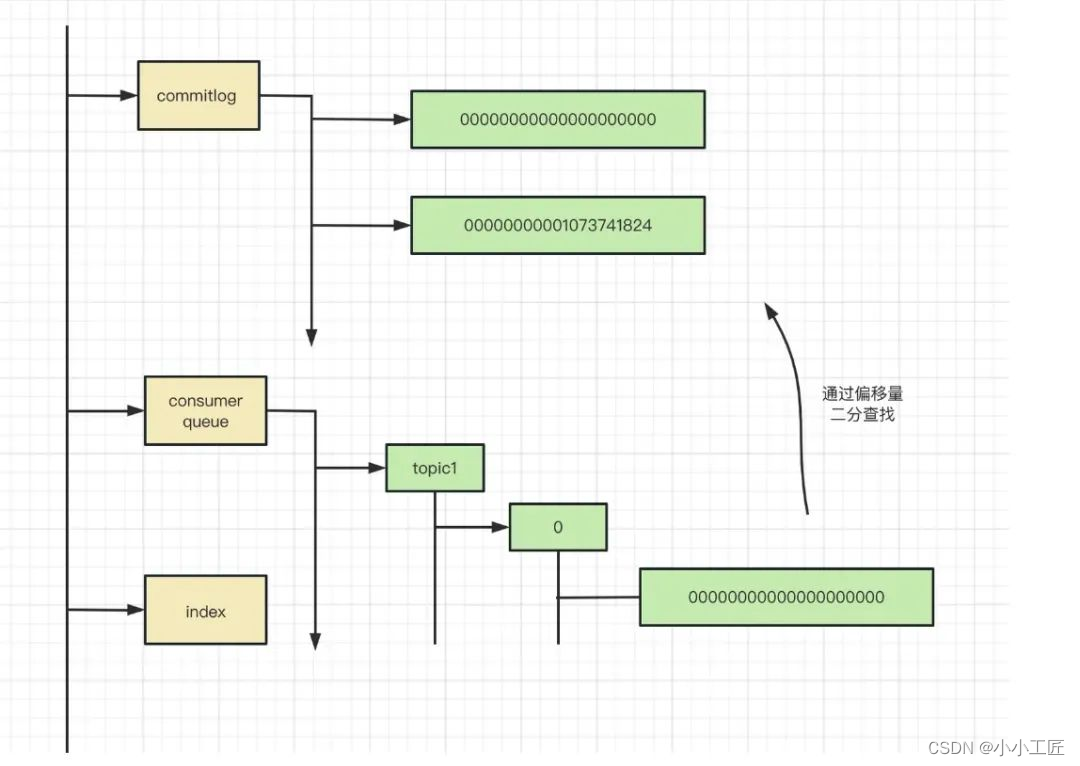
我们在想想 kafka 是怎么做的,对的,kafka 并没有类似的烦恼,因为所有信息都是连续的
总结起来,RocketMQ 的存储结构设计非常复杂,但它通过合理的设计实现了高效的消息写入和读取性能。同时,RocketMQ 也支持多种存储方式,如本地存储、分布式存储和云存储等,可以满足不同场景下的需求。

Pulsar
架构图(分层+分片)
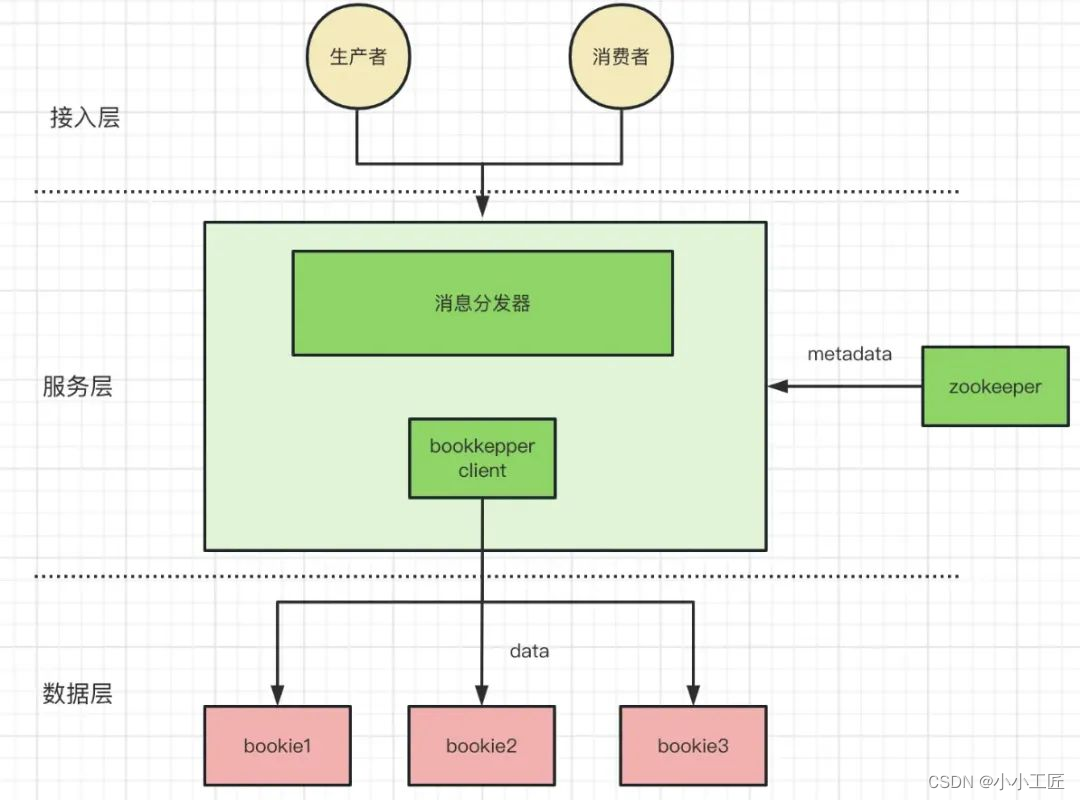
pulsar 相比与 kafka 与 rocketmq 最大的特点则是使用了分层和分片的架构,回想一下 kafka 与 rocketmq,一个服务节点即是计算节点也是服务节点,节点有状态使得平台化、容器化困难、数据迁移、数据扩缩容等运维工作都变的复杂且困难。
-
分层:Pulsar 分离出了 Broker(服务层)和 Bookie(存储层)架构,Broker 为无状态服务,用于发布和消费消息,而 BookKeeper 专注于存储。
-
分片 : 这种将存储从消息服务中抽离出来,使用更细粒度的分片(Segment)替代粗粒度的分区(Partition),为 Pulsar 提供了更高的可用性,更灵活的扩展能力
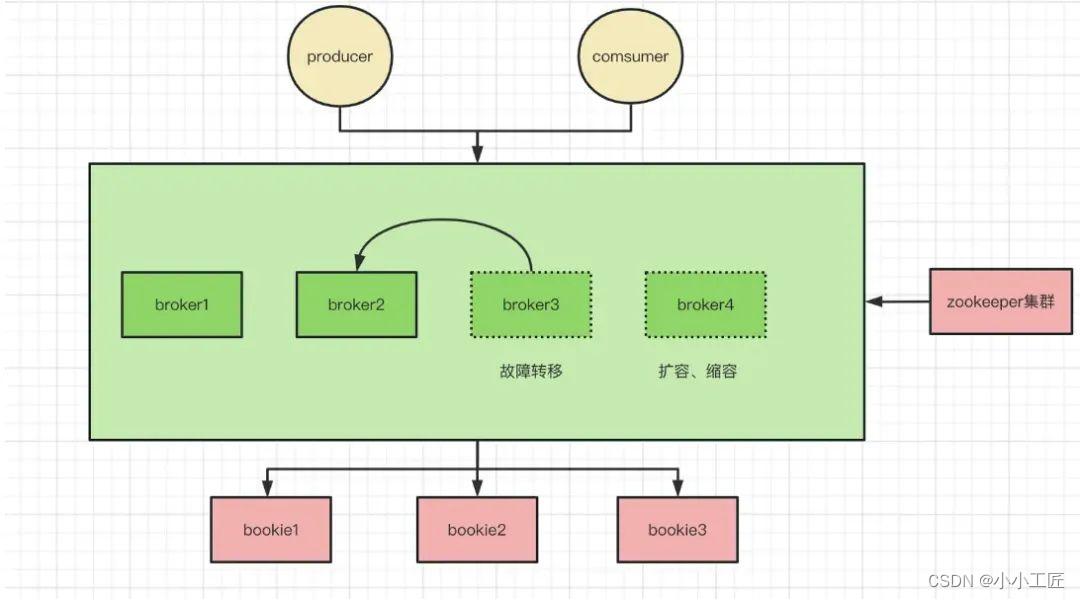
服务层设计
Broker 集群在 Pulsar 中形成无状态服务层。服务层是“无状态的”,所有的数据信息都存储在了 BookKeeper 上,所有的元信息都存储在了 zookeeper 上,这样使得一个 broker 节点没有任何的负担,这里的负担有几层含义:
- 容器化没负担,broker 节点不用考虑任何数据状态带来的麻烦。
- 扩容、缩容没负担,当请求量级突增或者降低的同时,可以随时的添加节点或者减少节点以动态的调整资源,使得整体在一种“合适”的状态。
- 故障转移没负担,当一个节点宕机、服务不可用时,可以通快速地转移所负责的 topic 信息到别的基节点上,可以很好做到故障对外无感知。
存储层设计
pulsar 使用了类似于 raft 的存储方案,数据会并发的写入多个存储节点上,下图为四存储节点、三副本架构。
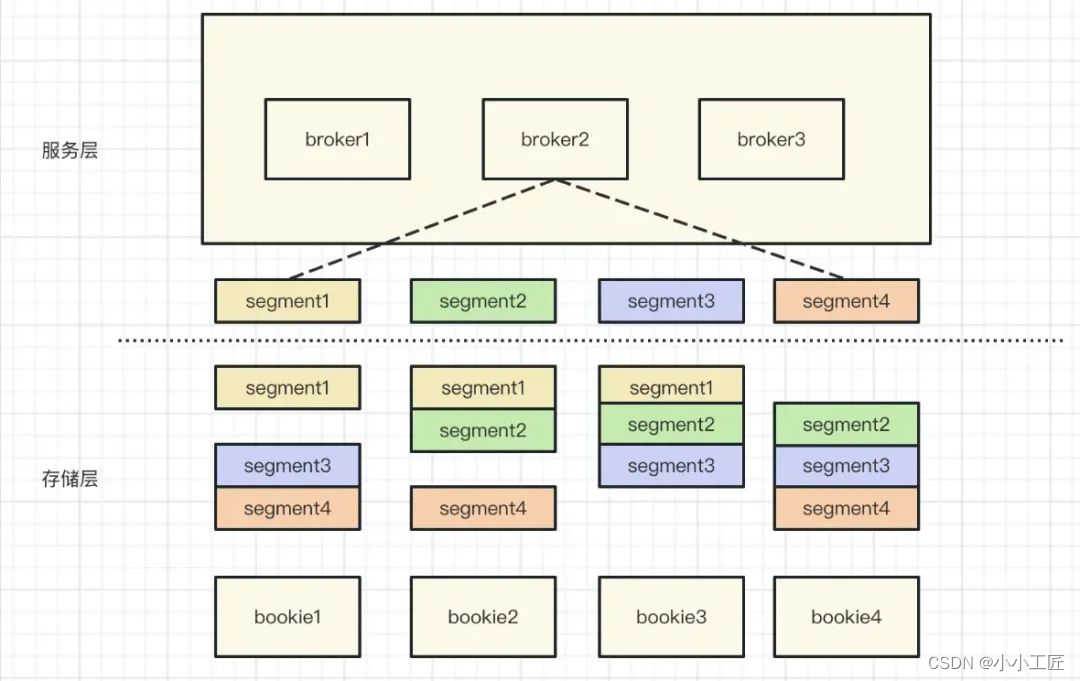
broker2 节点当前需要写入 segment1 到 segment4 数据,流程为: segment1 并发写入 b1、b2、b3 数据节点、segment2 并发写入 b2、b3、b4 数据节点、segment3 并发写入 b3、b4、b1 数据节点、segment4 并发写入 b1、b2、b4 数据节点。这种写入方式称为条带化的写入方式。
这种方式潜在的决定了数据的分布方式、通过路由算法,可以很快的找到对应数据的位置信息,在数据迁移与恢复中起到重要的作用。
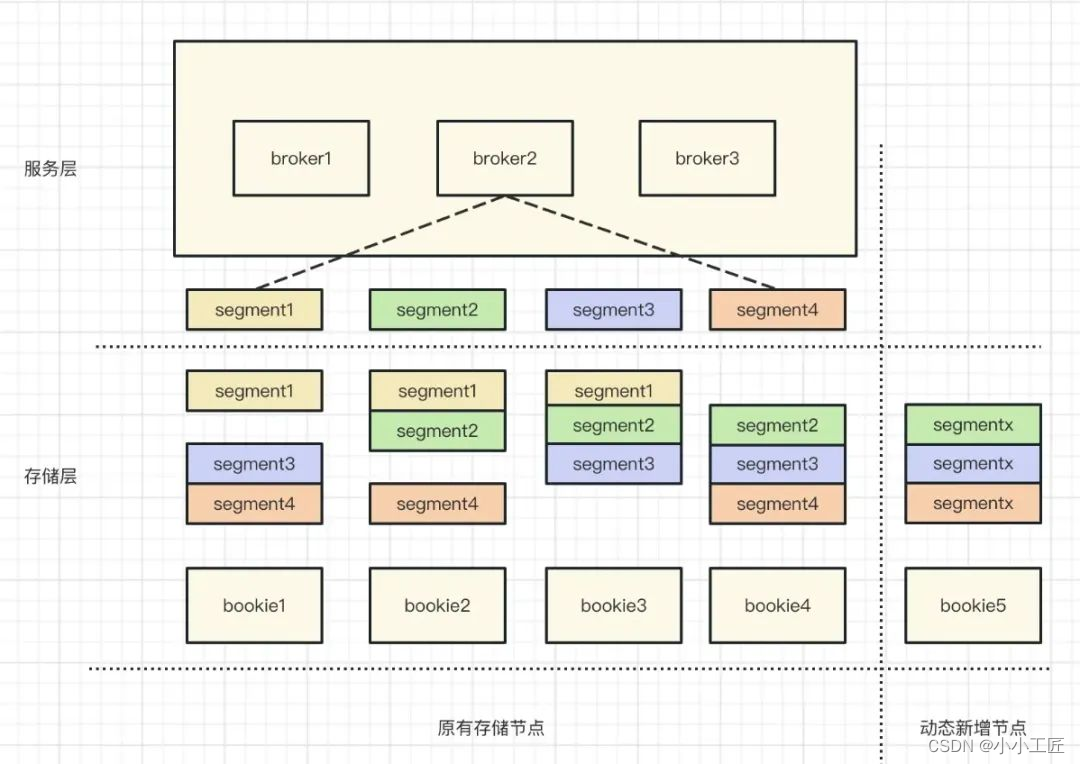
扩容
当存储节点资源不足的时候,常规的运维操作就是动态扩容,相比 kafka 与 rocketmq、pulsar 不用考虑原数据的"人为"搬移工作,而是动态新增一个或者多个节点,broker 在写入数据时通过路有算法优先写入资源充足的节点,使得整体的资源利用力达到一个平衡的状态,如图所示。
以下是一张 kafka 分区和 pulsar 分片的一张对比图,左图是 kafka 的数据存储特点,因为数据和分区的强绑定,导致了第三艘小船没有任何的数据,而相比 pulsar,数据不和任何存储节点绑定,而是实时的动态写入,从数据分布和资源利用来说,要做的更好。

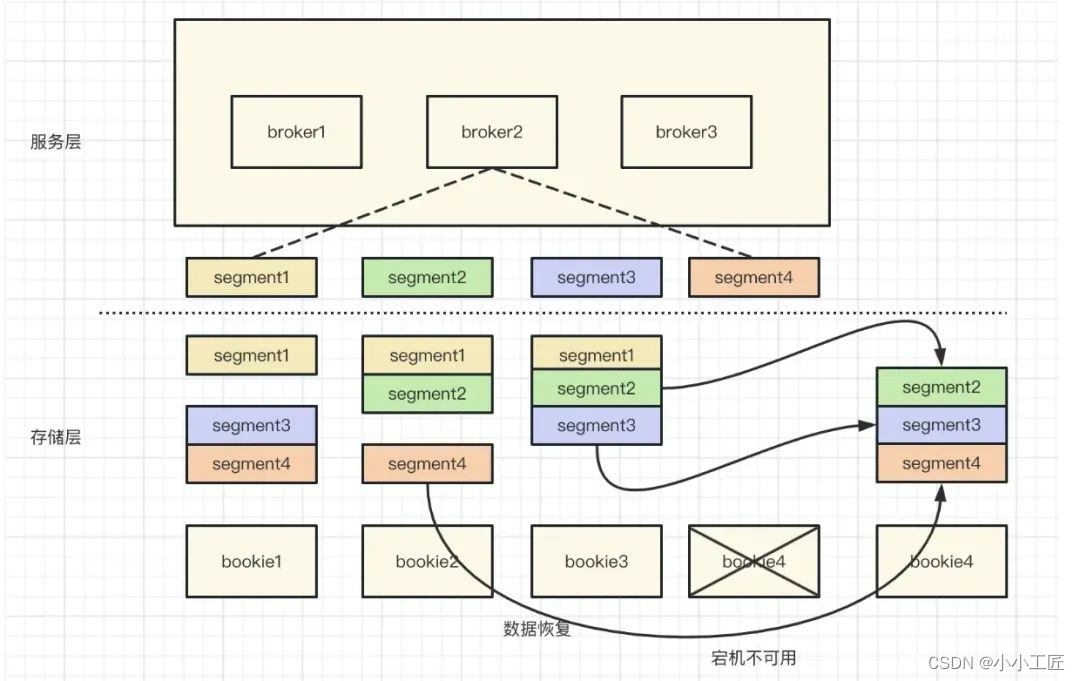
容灾
当 bookie4 存储节点宕机不可用时,如何恢复节点数据?这里只需要增加新的存储节点,并且拷贝 bookie2 与 bookie3 上的数据即可,这个过程对外是无感知的,实现了平滑切换,如图所示
小结
每种设计都有其特定的优势和局限,适应不同场景和需求。因此,在选用产品时,需要根据实际业务场景和需求,权衡各种设计的优缺点,作出最合适的选择。这种选择过程正是体现了设计与需求之间的平衡。所以,针对不同场景选择合适的产品是非常关键的。

相关文章:
MQ - 闲聊MQ一二事儿 (Kafka、RocketMQ 、Pulsar )
文章目录 MQ的发展史阶段一:追求解耦阶段二:追求吞吐量与一致性阶段三:追求平台化 MQ的通用架构主题topic、生产者producer、消费者consumer分区partition MQ 存储KafkaGood Design ---> 磁盘顺序写盘Poor Impact---> topic 数量不能过…...
)
Qt中的 QIODevice类(包含:随机访问、顺序访问设备)
QIODevice类 一、简介 QIODevice用于对输入输出设备进行管理,是Qt中所有I/O设备的基接口类。为支持读写数据块的设备(如QFile、QBuffer和QTcpSocket)提供了通用实现和抽象接口。 输入设备有2种类型: 一种是随机访问设备,QFile(文件)和QBuff…...
【JavaScript 07】函数声明 地位平等 函数提升 属性方法 作用域 参数 arguments对象 闭包 IIFE立即调用函数表达式 eval命令
函数 1 概述1.1 声明1.2 重复声明 1.3 圆括号/return/recursion1.4 一等公民1.5 函数提升 2 函数属性与方法2.1 name属性2.2 length属性2.3 toString() 3 函数作用域3.1 概念3.2 函数内部变量提升3.3 函数本身作用域 4 参数4.1 概念4.2 省略4.3 传递4.4 同名4.5 arguments 对象…...
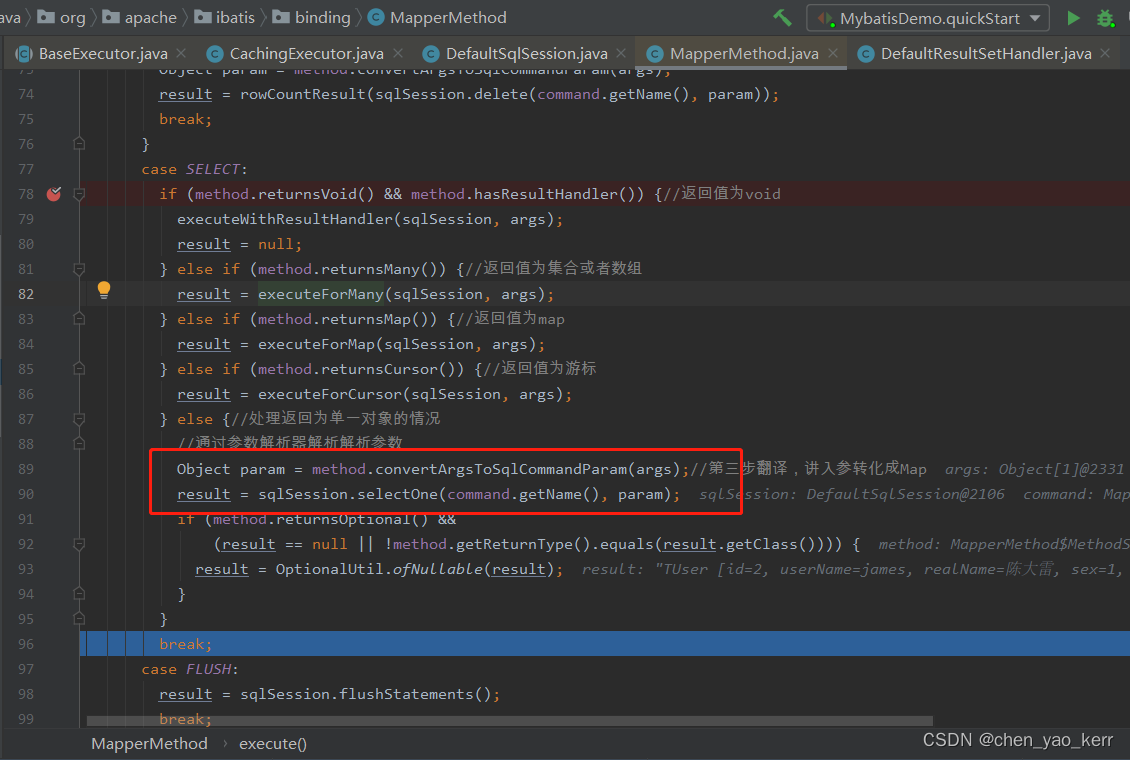
MyBatis源码分析_ResultSetHandler(7)
目录 1. 传统JDBC 2. Mybatis访问数据库 2.1 Statement访问数据库 2.2 火枪手 ResultSetHandler 出现 3. ResultSetHandler处理结果集 3.1 首先就是进入 handleResultSets 方法 3.2 handleResultSet 方法根据映射规则(resultMap)对结果集进行转化…...
Unittest加载执行用例的方法总结
前言 说到测试框架,unittest是我最先接触的自动化测试框架之一了, 而且也是用的时间最长的, unittest框架有很多方法加载用例,让我们针对不同的项目,不同项目的大小及用例的多少自己选择加载方式。今天我们就简单的说说…...

使用预训练的2D扩散模型改进3D成像
扩散模型已经成为一种新的生成高质量样本的生成模型,也被作为有效的逆问题求解器。然而,由于生成过程仍然处于相同的高维(即与数据维相同)空间中,极高的内存和计算成本导致模型尚未扩展到3D逆问题。在本文中࿰…...
微服务测试是什么?
微服务测试是一种特殊的测试类型,因为它涉及到多个独立的服务。以下是进行微服务测试的一般性步骤: 【B站最通俗易懂】Python接口自动化测试从入门到精通,超详细的进阶教程,看完这套视频就够了 1. 确定系统架构 了解微服务架构对…...
)
《现代C++教程》笔记(5-7)
文章目录 5 智能指针与内存管理5.1 RAII与引用计数5.2 std::shared_ptr5.3 std::unique_ptr5.4 std::weak_ptr 6 正则表达式7 并行与并发7.1 并行基础7.2 互斥量与临界区7.3 期物7.4 条件变量7.5 原子操作与内存模型 5 智能指针与内存管理 5.1 RAII与引用计数 在传统 C 中&am…...
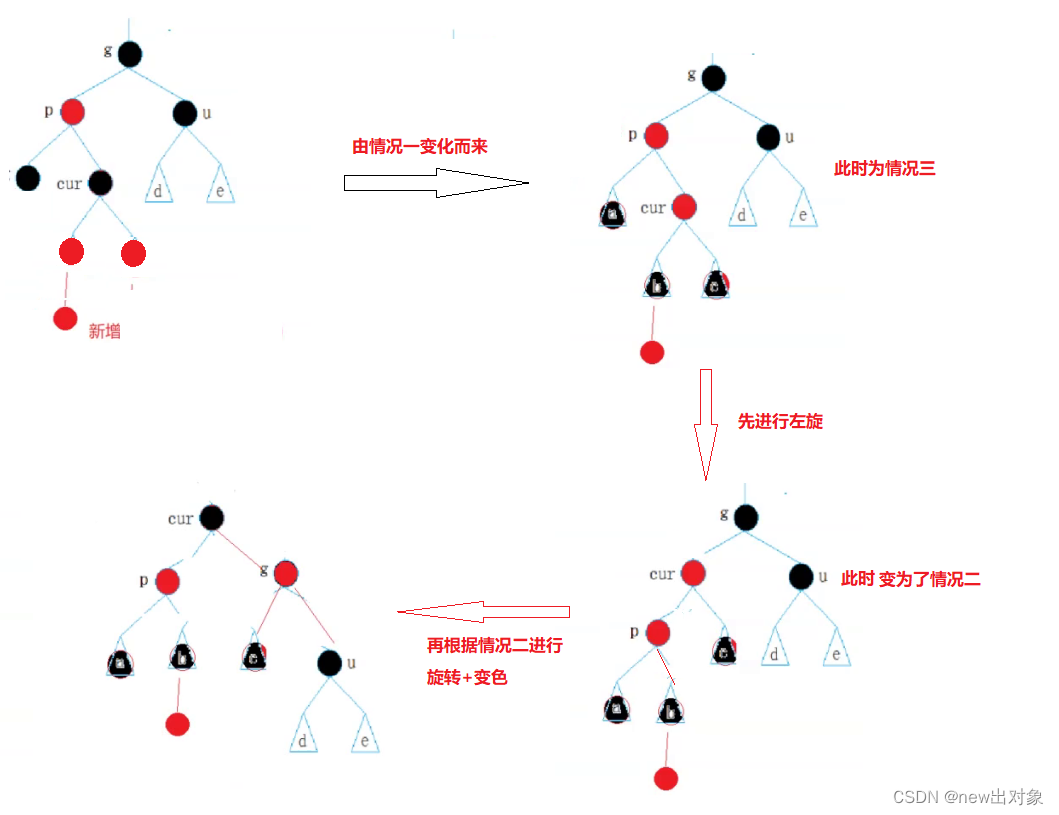
红黑树深入剖析【C++】
目录 一、红黑树概念 二、红黑树节点结构设计 三、插入操作 处理情况1 处理情况2 处理情况3 插入总结: 四、插入操作源码 五、红黑树验证 一、红黑树概念 红黑树,是一种二叉搜索树,但在每个结点上增加一个存储位表示结点的颜色࿰…...
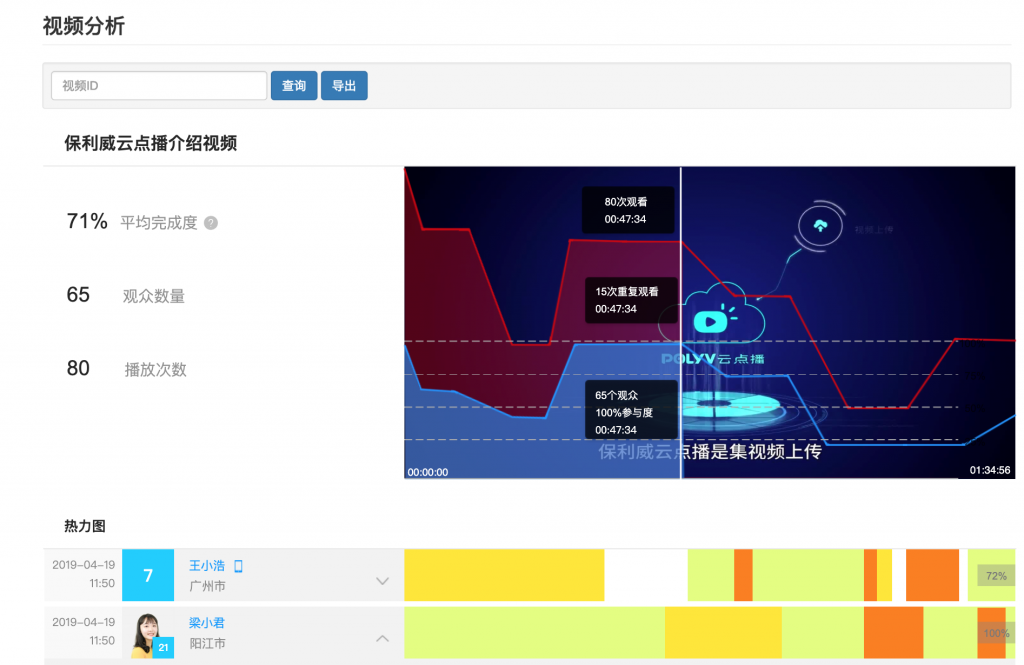
教育机构视频播放时观看行为分析有哪些应用?
教育机构视频播放时观看行为分析有哪些应用? 观看行为分析 观看行为分析是指我们平台基于视频大数据分析,能够以秒为粒度展示观众如何观看您的视频。 视频观看热力图是单次观看行为的图形化表示,我们平台云点播视频的每一次播放࿰…...

Jmeter+验证json结果是否正确小技巧
前言: 通过sql语句或者返回的参数,可以在查看结果树返回的结果中,用方法先跑一下验证是否取到自己想要的值 步骤: 1、添加查看结果树 2、跑出结果 3、在查看结果树中 text改成选Json Path Tester 返回的值如果是列表里面的字符…...
: singleton类型的bean和prototype类型的bean协同工作的方法(一))
Spring 6.0官方文档示例(22): singleton类型的bean和prototype类型的bean协同工作的方法(一)
一、配置文件: <beans xmlns"http://www.springframework.org/schema/beans"xmlns:xsi"http://www.w3.org/2001/XMLSchema-instance"xmlns:context"http://www.springframework.org/schema/context"xsi:schemaLocation"http…...

Android平台GB28181设备接入侧如何同时对外输出RTSP流?
技术背景 GB28181的应用场景非常广泛,如公共安全、交通管理、企业安全、教育、医疗等众多领域,细分场景可用于如执法记录仪、智能安全帽、智能监控、智慧零售、智慧教育、远程办公、明厨亮灶、智慧交通、智慧工地、雪亮工程、平安乡村、生产运输、车载终…...
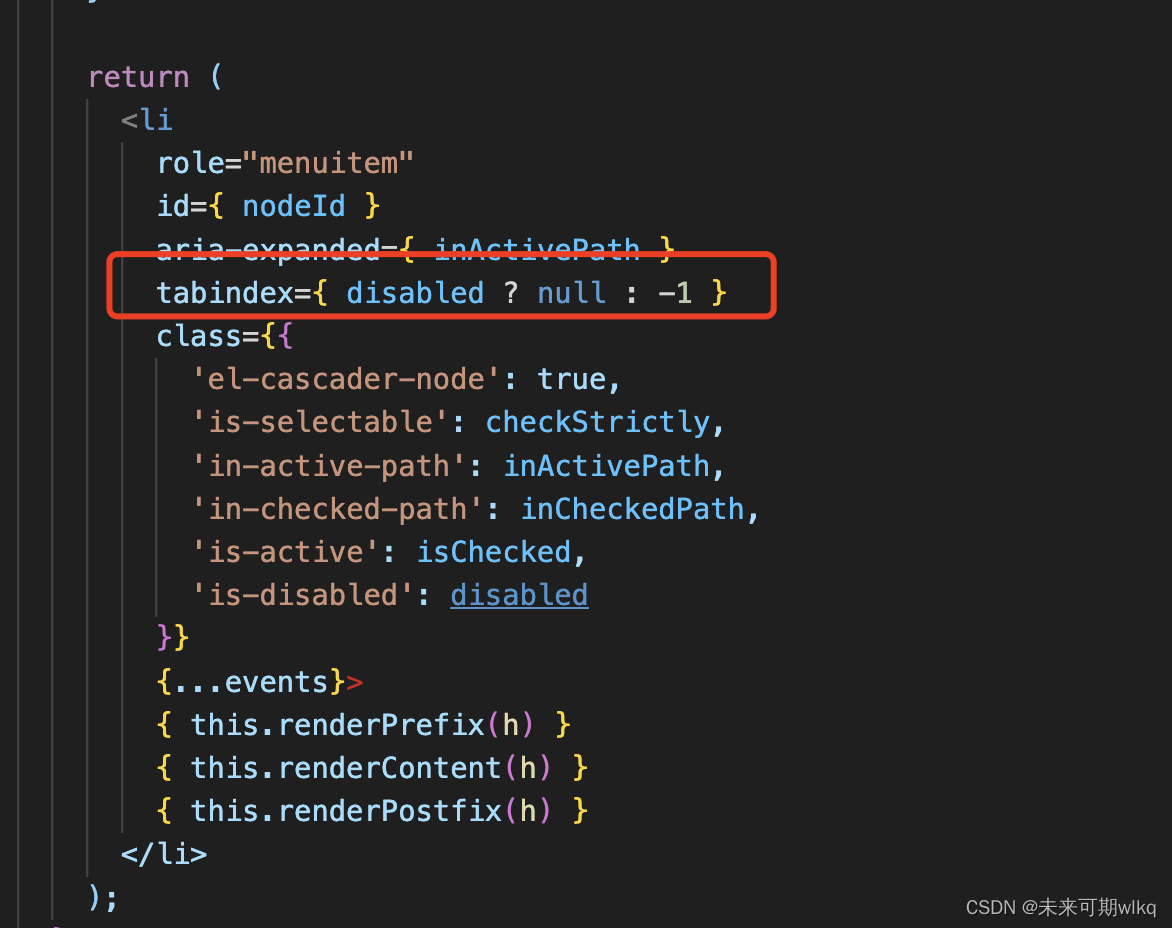
el-Cascader 中div上绑定keyDown事件
keydown,keyup,keypress 事件默认是给页面上可以聚焦的元素绑定键盘事件,例如input输入框,点击输入框即代表聚焦在该元素上。那么想要给div或者其他不能聚焦的元素上使用键盘事件怎么处理呢?这里用到tabindex属性。 …...

elementUI 表格滚动分页加载请求数据
需求:elementui Table表格滚动分页(不使用分页组件),请求数据。 1、自定义加载更多数据的指令,在utils文件夹中创建 loadMore.js /*** 加载更多数据的指令*/ export default {install(Vue) {Vue.mixin({directives: …...

JAVA面试总结-Redis篇章(五)——持久化
Java面试总结-Redis篇章(五)——持久化 1.RDBRDB全称Redis Database Backup file (Redis数据备份文件),也被叫做Redis数据快照。简单来说就是把内存中的所有数据都记录到磁盘中。当Redis实例故障重启后,从磁盘读取快照文件&#x…...
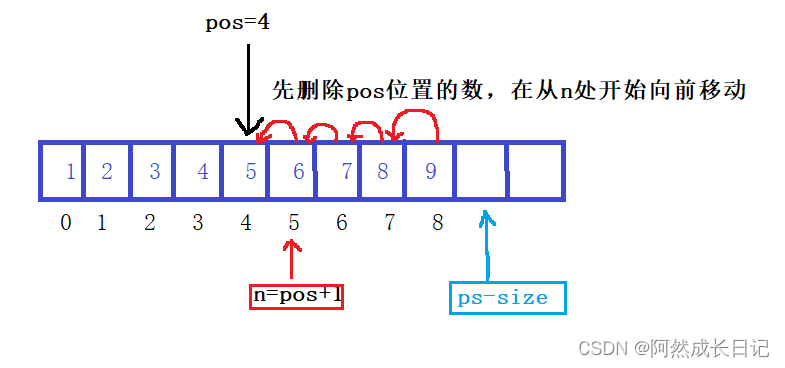
【数据结构】·顺序表函数实现·赶紧学起来呀
💐 🌸 🌷 🍀 🌹 🌻 🌺 🍁 🍃 🍂 🌿 🍄🍝 🍛 🍤 📃个人主页 :阿然成长日记 …...
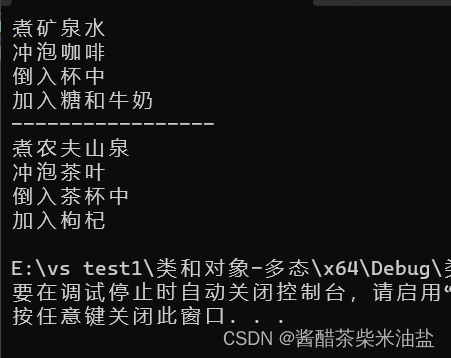
C++,类和对象-多态,制作饮品
#include<iostream> using namespace std;//多态案例,制作饮品class AbstractDrinking { public://煮水virtual void Boil() 0;//冲泡virtual void Brew() 0;//倒入茶杯virtual void PourInCup() 0;//加入辅料virtual void PutSomething() 0;//制作饮品vo…...

网站分析:学习如何分析目标网站的页面结构和URL规律,确定爬取目标和策略。
要学习如何分析目标网站的页面结构和URL规律,确定爬取目标和策略,可以遵循以下步骤: 目标网站的页面结构分析: 寻找目标网站的主页,并观察主页上的链接、导航菜单和内容分类等元素,以了解网站的整体结构。 …...

《向量数据库指南》:向量数据库Pinecone如何集成数据湖
目录 为什么选择Databricks? 为什么选择Pinecone? 设置Spark集群 环境设置 将数据集加载到分区中 创建将文本转换为嵌入的函数 将UDF应用于数据 更新嵌入 摘要 使用Databricks和Pinecone在规模上创建和索引向量嵌入 建立在Apache Spark之上的Databricks是一个强大的…...

安卓应用按钮样式问题及解决方案
在开发安卓应用的过程中,我们常常会遇到一些看似简单但实际上隐藏着复杂问题的样式问题。今天我们来探讨一个在更换设备后按钮样式发生变化的问题。 问题描述 一位开发者在Android Studio中开发了一个食谱应用。当他从一台手机切换到另一台手机运行应用时,发现所有的按钮都…...

实战指南:为spring boot项目快速配置最优jdk环境,助力应用高效部署
最近在准备一个Spring Boot项目时,发现JDK环境配置这个看似简单的环节其实藏着不少学问。特别是当项目需要兼顾开发效率和生产环境稳定性时,合理的JDK配置方案就显得尤为重要。今天就来分享下我的实战经验,以及如何利用工具快速搞定这些配置。…...

忍者像素绘卷惊艳效果:宇智波佐助千鸟刃×16-Bit闪电特效像素动效展示
忍者像素绘卷惊艳效果:宇智波佐助千鸟刃16-Bit闪电特效像素动效展示 1. 作品概览 忍者像素绘卷是基于Z-Image-Turbo深度优化的图像生成工作站,它将传统忍者文化与16-Bit复古游戏美学完美融合。这款工具特别适合创作具有强烈视觉冲击力的像素风格动漫角…...

迈瑞医疗营收超330亿,国际业务持续发力未来何在?
最近的财报季,各家上市公司的财报都牵动着每个人的心,就在最近迈瑞医疗的成绩单公布,营收超330亿,国际业务持续向好,这样的成绩单我们到底该怎么看待呢?一、迈瑞医疗业绩稳健向好据每日经济新闻的报道&…...

小白友好!Stable Diffusion v1.5单卡运行多个服务,详细步骤+避坑指南
小白友好!Stable Diffusion v1.5单卡运行多个服务,详细步骤避坑指南 1. 为什么需要单卡多服务? 很多刚接触Stable Diffusion的朋友都会遇到这样的困扰:团队里几个人共用一台服务器,但GPU卡只有一张。一个人用的时候还…...

VoxCPM-1.5-WEBUI问题解决:部署常见错误与一键启动脚本详解
VoxCPM-1.5-WEBUI问题解决:部署常见错误与一键启动脚本详解 1. 快速入门指南 1.1 镜像部署准备 在开始使用VoxCPM-1.5-WEBUI之前,您需要确保具备以下条件: 支持CUDA的NVIDIA显卡(建议RTX 3060及以上)至少16GB系统内…...

跨平台终端与进程控制:从原理到实践
跨平台终端与进程控制:从原理到实践 【免费下载链接】node-pty Fork pseudoterminals in Node.JS 项目地址: https://gitcode.com/gh_mirrors/no/node-pty 在现代软件开发中,终端交互和进程管理是不可或缺的核心能力。无论是构建IDE、开发自动化工…...
)
别再手动埋点了!用OpenTelemetry Operator在K8s里给Java应用自动注入链路追踪(附完整YAML)
零代码改造:OpenTelemetry Operator在K8s中实现Java应用全自动观测 当微服务架构遇上云原生环境,可观测性成为工程团队的生命线。但传统埋点方案需要侵入业务代码、增加维护成本,这与快速迭代的DevOps理念背道而驰。本文将揭示如何通过OpenTe…...

CVE-2024-36401复现
一.漏洞概述 CVE-2024-36401 是 GeoServer 中的一个严重级远程代码执行漏洞(CVSS 9.8),允许未经身份验证的远程攻击者在服务器上执行任意代码。该漏洞源于 GeoServer 调用的 GeoTools 库 API 在评估 XPath 表达式时存在不安全处理࿰…...

React - React Redux 数据共享、Redux DevTools、React Redux 最终优化
一、React Redux 数据共享 1、基本介绍 combineReducers 函数用于汇总所有的 Reducer 变为一个总的 Reducer 2、演示 (1)redux constant // 定义 action 中 type 的常量值export const INCREMENT "increment"; export const DECREMENT "…...