机器学习01 -Hello World(对鸢尾花(Iris Flower)进行训练及测试)
什么是机器学习?
机器学习是一种人工智能(AI)的子领域,它探索和开发计算机系统,使其能够从数据中学习和改进,并在没有明确编程指令的情况下做出决策或完成任务。
传统的程序需要程序员明确编写指令来告诉计算机如何执行特定任务。但是,机器学习采用不同的方法。它允许计算机通过分析大量的数据来发现模式、关系和规律,并根据这些发现做出预测和决策。
机器学习系统的主要特点是可以通过反复迭代来改进自己的性能。这是通过使用数据集进行训练实现的。训练数据集包含一组示例,每个示例都有相应的输入和输出。机器学习算法使用这些示例来学习如何将输入与输出相关联,从而使其能够对新的、未见过的数据做出合理的预测或决策。
机器学习可以应用于各种领域,如图像识别、自然语言处理、推荐系统、医疗诊断、金融预测等。它在现代科技和业务中扮演着越来越重要的角色,并在很多领域取得了显著的进展。
机器学习的主要类型
监督学习(Supervised Learning):在监督学习中,算法从带有标签的训练数据集中学习。每个训练样本都包含输入和对应的输出(标签)。算法的目标是学习一个映射函数,可以将输入映射到正确的输出。例如,给定一组包含图片和相应标签的数据,监督学习算法可以学习识别图片中的对象。
无监督学习(Unsupervised Learning):无监督学习中,算法处理没有标签的数据。它的目标是发现数据中的结构、模式或关联。这类算法通常用于聚类、降维、异常检测等任务。例如,通过无监督学习,可以将相似的用户聚集在一起,以便更好地推荐产品或服务。
强化学习(Reinforcement Learning):强化学习涉及到一个智能体(agent)在一个动态环境中采取行动,并根据其行动获得奖励或惩罚。智能体的目标是通过与环境不断交互,最大化累积奖励。强化学习在许多自动化系统中发挥着重要作用,如自动驾驶、游戏智能体等。
半监督学习(Semi-Supervised Learning):这是介于监督学习和无监督学习之间的一种方法。它利用少量有标签的数据和大量无标签的数据进行训练,以提高算法的性能。
深度学习(Deep Learning):深度学习是机器学习的一个分支,专注于使用人工神经网络进行学习。这些神经网络由许多层(深层)组成,可以自动从数据中学习特征表达,从而使其在图像识别、自然语言处理等任务中表现出色。
什么是数据集?
数据集是机器学习和统计学中的一个重要概念,它是一组有序的数据样本的集合。每个数据样本由一组特征(也称为特征变量)组成,以及一个相应的目标变量(也称为标签或输出),用来描述数据的某种属性或特征。
在机器学习任务中,数据集通常被用于训练和评估模型。数据集可以分为以下几种类型:
训练数据集(Training Dataset):训练数据集用于训练机器学习模型。它包含多个数据样本,每个样本都有一组特征和对应的目标变量(如果是监督学习任务)。模型使用训练数据集来学习特征与目标变量之间的关系,以便进行预测或分类。
验证数据集(Validation Dataset):验证数据集用于模型选择和调优。在训练过程中,模型通过与训练数据集的学习来调整参数,但为了避免过拟合(overfitting)的问题,需要使用验证数据集来验证模型的性能。验证数据集不参与模型训练,它仅用于评估模型在未见过数据上的表现。
测试数据集(Test Dataset):测试数据集用于评估最终模型的性能。当模型经过训练和调优后,使用测试数据集来进行最终的性能评估。测试数据集是模型在整个训练过程中从未见过的数据,因此可以提供对模型在真实场景中的泛化能力的估计。
数据集的质量和规模对于机器学习的结果至关重要。大规模、高质量的数据集通常能够帮助机器学习模型更好地学习数据中的规律和特征,从而获得更好的预测能力。
在现实世界中,数据集可以是从各种来源收集而来的,包括传感器数据、数据库记录、图像、文本等。数据集的构建和准备是机器学习项目中的关键步骤之一,它直接影响着模型的性能和实用性。
讲点白话:假如模型就是你家的小孩,现在你要让他学会辨别动物,然后你拿了一个动物图册,那这个动物图册就是数据集
鸢尾花数据集概述
机器学习包sklearn 中集成了各种各样的数据集,其中就包括鸢尾花数据集(Iris)是最简单的分类任务数据集。
鸢尾花数据集共有3个分类类别,分别是山鸢尾(Iris-setosa)、变色鸢尾(Iris-versicolor)和维吉尼亚鸢尾(Iris-virginica)
该数据集共有150个样本,5个变量(4个特征变量,1个类别变量)。iris是鸢尾植物,4个特征分别对应萼片和花瓣的长和宽。如下表:

理解数据集
通俗地说,iris数据集是用来给花做分类的数据集,每个样本包含了花萼长度、花萼宽度、花瓣长度、花瓣宽度四个特征(前4列),我们需要建立一个分类器,分类器可以通过样本的四个特征来判断样本属于山鸢尾(setosa)、变色鸢尾(versicolor)、维吉尼亚鸢尾(virginica)这三个名词都是花的品种。iris的每个样本都包含了品种信息,即目标属性(第5列,也叫target或label)
iris在机器学习中的应用:
属于监督式学习应用:可以通过这4个特征预测鸢尾花卉属于(iris-setosa, iris-versicolour, iris-virginica)中的哪一品种。
这是机器学习中经典案例,简单而具有代表性。
from sklearn import datasets # 导入sklearn中集成的数据集
# iris数据集加载
iris = datasets.load_iris()
target = iris['target_names'] # 标签的名称
print("鸢尾花标签名称:\n", target)
print("鸢尾花特征:\n", iris.data[:5]) # print前5个特征
print("鸢尾花特征的维度:\n", iris.data.shape)
print("鸢尾花标签:\n", iris.target)
print("鸢尾花标签的维度:\n", iris.target.shape)
运行结果如下:
鸢尾花标签名称:['setosa' 'versicolor' 'virginica']
鸢尾花标签:0 代表setosa,1代表versicolor,2 代表virginica[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 00 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 11 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 22 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 22 2]
鸢尾花特征:[[5.1 3.5 1.4 0.2][4.9 3. 1.4 0.2][4.7 3.2 1.3 0.2][4.6 3.1 1.5 0.2][5. 3.6 1.4 0.2]]
鸢尾花特征的维度:(150, 4)
鸢尾花标签:
也就是种类标识[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 00 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 11 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 22 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 22 2]
鸢尾花标签的维度:(150,)从输出结果可以看到,类别标签共分为三类,前面50个类标位0,中间50个类标位1,后面50个类别为2。
分别代表为山鸢尾、杂色鸢尾、维吉尼亚鸢尾。
可以从官网地址下载这个数据集
http://archive.ics.uci.edu/dataset/53/iris
利用knn模型进行预测结果
什么是knn模型?
KNN(K-Nearest Neighbors,K近邻算法)是一种简单而常用的机器学习算法,用于分类和回归任务。它属于一类称为“基于实例的学习”或“懒惰学习”的算法,因为它不像其他算法(例如神经网络或决策树)那样训练模型来学习数据的规律,而是在测试时通过寻找最近的邻居来做出预测。
工作原理:
训练阶段:KNN算法的训练阶段仅仅是将训练样本数据保存起来,没有显式的训练过程。算法将训练样本和其对应的标签存储在内存中。
预测阶段:在预测时,当需要对一个新的数据样本进行分类或回归时,KNN算法会做以下步骤: a.
计算新样本与所有训练样本之间的距离(通常使用欧氏距离或曼哈顿距离等)。 b. 选择与新样本距离最近的K个训练样本(这就是“K近邻”中的K)。
c. 对于分类任务,通过投票机制来决定新样本的类别。即,K个最近邻中出现次数最多的类别即为新样本的预测类别。 d.
对于回归任务,对K个最近邻的目标值进行平均,得到新样本的预测值。参数K的选择很重要,过小的K值可能会使模型过于复杂和容易受到噪声的影响,而过大的K值可能会导致模型过于简单,忽略了数据的细节。
优点:
简单、直观,易于理解和实现。 适用于多类别的分类问题。 对数据分布没有过多假设,可以适用于各种数据类型。
缺点:预测时的计算成本较高,特别是对于大规模数据集。 对于高维数据或特征空间较大的数据集,效果可能不如其他算法好。
对于不平衡数据集,可能会受到少数类别的影响较大。KNN是一个基本的机器学习算法,通常用于起步学习或作为基准模型。在实际应用中,可以根据数据集的规模和特点选择合适的算法
莺尾花预测
1.获取数据集
2.数据基本处理
3.特征工程
4.机器学习(模型训练)
5.模型评估
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier# 1.获取数据集
iris = load_iris()# 2.数据基本处理
# x_train,x_test,y_train,y_test为训练集特征值、测试集特征值、训练集目标值、测试集目标值
x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.2, random_state=22)# 3、特征工程:标准化
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)# 4、机器学习(模型训练)
estimator = KNeighborsClassifier(n_neighbors=9)
estimator.fit(x_train, y_train)# 5、模型评估
# 方法1:比对真实值和预测值
y_predict = estimator.predict(x_test)
print("预测结果为:\n", y_predict)
print("比对真实值和预测值:\n", y_predict == y_test)
# 方法2:直接计算准确率
score = estimator.score(x_test, y_test)
print("准确率为:\n", score)
运行结果:
预测结果为:[0 2 1 2 1 1 1 1 1 0 2 1 2 2 0 2 1 1 1 1 0 2 0 1 2 0 2 2 2 2]
比对真实值和预测值:[ True True True True True True True False True True True TrueTrue True True True True True False True True True True TrueTrue True True True True True]
准确率为:0.9333333333333333
我们也可以根据上面的训练随便推理一组数据看看
#预测某种花的品种
ourData = estimator.predict([[1,2,3,4]])
print("预测某种花的品种:\n", ourData)
1,2,3,4分别代表 花萼长度、花萼宽度、花瓣长度、花瓣宽度四个特征(前4列)
运行结果:
[2]
从结果中预测的是 维吉尼亚鸢尾
相关文章:
机器学习01 -Hello World(对鸢尾花(Iris Flower)进行训练及测试)
什么是机器学习? 机器学习是一种人工智能(AI)的子领域,它探索和开发计算机系统,使其能够从数据中学习和改进,并在没有明确编程指令的情况下做出决策或完成任务。 传统的程序需要程序员明确编写指令来告诉…...
android studio JNI开发
一、JNI的作用: 1.使Java与本地其他类型语言(C、C)交互; 2.在Java代码调用C、C等语言的代码 或者 C、C调用Java代码。 由于JAVA具有跨平台的特点,所以JAVA与本地代码的交互能力弱,采用JNI特性可以增强JA…...
CSS 高频按钮样式
矩形与圆角按钮 正常而言,我们遇到的按钮就这两种 -- 矩形和圆角: 它们非常的简单,宽高和圆角和背景色。 <div classbtn rect>rect</div><div classbtn circle>circle</div>.btn {margin: 8px auto;flex-shrink: 0;…...
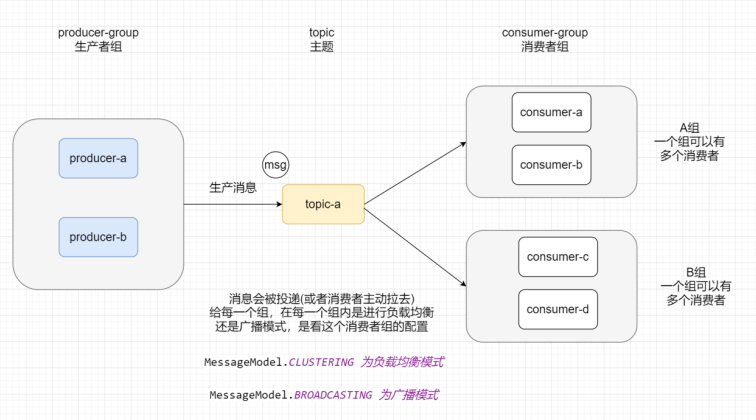
系列二、RocketMQ简介
一、概述 RocketMQ是一款阿里巴巴开源的消息中间件。2016年11月28日,阿里巴巴向Apache软件基金会捐赠RabbitMQ,成为Apache孵化项目。2017年9月25日,Apache宣布RocketMQ孵化成为Apache顶级项目(TLP),成为国内…...

论文笔记--Skip-Thought Vectors
论文笔记--Skip-Thought Vectors 1. 文章简介2. 文章概括3 文章重点技术3.1 Skip Thought Vectors3.2 词表拓展 4. 文章亮点5. 原文传送门6. References 1. 文章简介 标题:Skip-Thought Vectors作者:Ryan Kiros, Yukun Zhu, Ruslan Salakhutdinov, Rich…...

1400*B. Karen and Coffee
Examples input 3 2 4 91 94 92 97 97 99 92 94 93 97 95 96 90 100 output 3 3 0 4 input 2 1 1 1 1 200000 200000 90 100 output 0 解析: 题意为,给你多个区间(会有重叠),每个区间的每个值都会为这个值累加…...

【业务功能篇54】Springboot项目常用工具类:HTTP状态码/客户端request
状态码常量类 /*** 返回状态码**/ public class HttpStatus {/*** 操作成功*/public static final int SUCCESS 200;/*** 对象创建成功*/public static final int CREATED 201;/*** 请求已经被接受*/public static final int ACCEPTED 202;/*** 操作已经执行成功࿰…...

Fine Logic
登录—专业IT笔试面试备考平台_牛客网 题目大意:有n个数分别为1~n,有m个数值对(u,v)表示u要排在v左边,问至少要多少个排列才能满足所有数值对至少一次 2<n<1e6;1<m<1e6 思路:如果数值对中要求u在v左边,…...

Neo4j图数据基本操作
Neo4j 文章目录 Neo4jCQL结点和关系增删改查匹配语句 根据标签匹配节点根据标签和属性匹配节点删除导入数据目前的问题菜谱解决的问题 命令行窗口 neo4j.bat console 导入rdf格式的文件 :GET /rdf/ping CALL n10s.graphconfig.init(); //初始化 call n10s.rdf.import.fetch(&q…...
)
前端JavaScript面试100问(中)
31、http 的理解 ? HTTP 协议是超文本传输协议,是客户端浏览器或其他程序“请求”与 Web 服务器响应之间的应用层通信协议。HTTPS主要是由HTTPSSL构建的可进行加密传输、身份认证的一种安全通信通道。32、http 和 https 的区别 ? 1、https协议需要到ca申请证书&…...

Docker 安全及日志管理与https部署
容器的安全性问题的根源在于容器和宿主机共享内核。如果容器里的应用导致Linux内核崩溃,那么整个系统可能都会崩溃。与虚拟机是不同的,虚拟机并没有与主机共享内核,虚拟机崩溃一般不会导致宿主机崩溃。 Docker 容器与虚拟机的区别 虚拟机通…...

2.3 HLSL常用函数
一、函数介绍 函数图像参考网站:Graphtoy 1.基本数学运算 函数 含义 示例图 min(a,b) 返回a、b中较小的数值 mul(a,b) 两数相乘用于矩阵计算 max(a,b) 返回a、b中较大的数值 abs(a) 返回a的绝对值 round(x) 返回与x最近的整数 sqrt(x) 返回x的…...

互联网的发展
概述 互联网是现代社会中举足轻重的一个领域,它的发展对于人类的生活和工作方式产生了深远的影响。互联网的发展经历了几个阶段,从初创阶段到如今的高度普及和深入应用,本文将详细介绍互联网的发展状况。 第一阶段:互联网的起源…...
STM32 CAN通讯实验程序
目录 STM32 CAN通讯实验 CAN硬件原理图 CAN外设原理图 TJA1050T硬件描述 实验线路图 回环实验 CAN头文件配置 CAN_GPIO_Config初始化 CAN初始化结构体 CAN筛选器结构体 接收中断优先级配置 接收中断函数 main文件 实验现象 补充 STM32 CAN通讯实验 CAN硬件原理图…...

Python代码片段之Django静态文件URL的配置
首先要说明这段python代码并不完整,而且我也没有做过测试,只是我在工作时参考了其中的一些个方法。这是我在找python相关源码资料里看到的一段代码,是Django静态文件URL配置代码片段2,代码中有些方法还是挺技巧的,做其…...

基于飞桨paddle的极简方案构建手写数字识别模型测试代码
基于飞桨paddle的极简方案构建手写数字识别模型测试代码 原始测试图片为255X252的图片 因为是极简方案采用的是线性回归模型,所以预测结果数字不一致 本次预测的数字是 [[3]] 测试结果: PS E:\project\python> & D:/Python39/python.exe e:/pro…...

soft ip与hard ip
ip分soft和hard两种,soft就是纯代码,买过来要自己综合自己pr。hard ip如mem和analog与工艺有关。 mem的lib和lef是memory compiler产生的,基于bitcell,是foundry给的。 我正在「拾陆楼」和朋友们讨论有趣的话题,你⼀起…...
MyBatisPlus从入门到精通-2
接着上一讲的Mp的分页功能 下面我们讲解条件查询功能和其他功能 解决一下日志输出和banner问题 每次卞就会输出这些日志 很不美观,现在我们关闭一下 这样建个xml,文件名为logback.xml 文件内容改成这样 配置了logback但是里面什么都没写就不会说有日…...
)
AI面试官:Asp.Net 中使用Log4Net (一)
AI面试官:Asp.Net 中使用Log4Net (一) 当面试涉及到使用log4net日志记录框架的相关问题时,通常会聚焦在如何在.NET或.NET Core应用程序中集成和使用log4net。以下是一些关于log4net的面试题目,以及相应的解答、案例和代码: 文章目…...

Selenium自动化元素定位方式与浏览器测试脚本
Selenium八大元素定位方法 Selenium可以驱动浏览器完成各种操作,比如模拟点击等。要想操作一个元素,首先应该识别这个元素。人有各种的特征(属性),我们可以通过其特征找到人,如通过身份证号、姓名、家庭住…...

告别C盘爆满!手把手教你配置Miniforge,让所有虚拟环境乖乖待在D盘
彻底解放C盘空间:Miniforge虚拟环境全迁移至D盘实战指南 每次打开资源管理器看到C盘飘红的存储条,心跳都会漏半拍——这大概是Windows开发者最熟悉的焦虑场景。特别是当你发现conda创建的虚拟环境正悄无声息吞噬着宝贵的系统盘空间时,那种无…...

Bootstrap 下拉菜单:全面解析与应用指南
Bootstrap 下拉菜单:全面解析与应用指南 引言 Bootstrap 是一个流行的前端框架,它提供了丰富的组件和工具来帮助开发者快速构建响应式、美观的网页。其中,下拉菜单是 Bootstrap 中一个常用且重要的组件,它能够帮助用户在有限的空间…...

为MusicBee集成网易云音乐同步歌词的技术实现方案
为MusicBee集成网易云音乐同步歌词的技术实现方案 【免费下载链接】MusicBee-NeteaseLyrics A plugin to retrieve lyrics from Netease Cloud Music for MusicBee. 项目地址: https://gitcode.com/gh_mirrors/mu/MusicBee-NeteaseLyrics MusicBee作为一款功能强大的本地…...

手把手教你用AI超分镜像:低清图片3倍放大,细节修复超简单
手把手教你用AI超分镜像:低清图片3倍放大,细节修复超简单 1. 为什么你需要这个AI超分工具? 你是不是也遇到过这些头疼的情况? 翻出十几年前的老照片,想打印出来,却发现画面模糊得像蒙了一层雾。从网上下…...

专业安防怎么选?奥尔特云与普通摄像头核心性能对比
不少人认为安防摄像头只是“能录像、能看见”就够,选型无需太过考究,实则这是安防系统搭建的关键误区。安防系统的核心是精准感知、有效采集,而摄像头作为前端核心采集设备,是所有安防数据的源头。若源头的画面质量、感知能力不达…...

广东省高级会计师评审辅导知名品牌
在职业发展的道路上,专业资格认证是许多财务从业者提升自我、拓宽职业路径的重要一环。广东省高级会计师评审,作为一项专业性强、要求严格的职业能力认定,其准备过程需要系统性的指导与支持。中山力朗教育咨询有限公司,作为一家立…...

告别格式枷锁:ncmdumpGUI让音乐自由播放变得触手可及
告别格式枷锁:ncmdumpGUI让音乐自由播放变得触手可及 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI 开篇痛点直击:那些被NCM格式困住的…...

HarmonyOS 音乐播放器进阶实战——AVPlayer状态管理与播放列表
1. AVPlayer状态机深度解析 在HarmonyOS音乐播放器开发中,AVPlayer的状态管理就像驾驶手动挡汽车——你需要清楚知道当前处于哪个档位,才能平稳切换。我曾在项目中因为状态处理不当导致音乐卡顿,后来才发现是状态机流转出了问题。 AVPlayer…...

优化算法中的‘0.618’魔法:黄金分割法为何是工程优化的首选入门工具?
黄金分割法:从古希腊美学到现代工程优化的优雅解决方案 在工程优化领域,算法选择往往让初学者感到困惑。面对梯度下降、牛顿法等复杂方法,有一种源自公元前300年的数学比例——黄金分割比(0.618),却成为了…...

思源宋体免费商用字体:设计师的终极开源字体解决方案
思源宋体免费商用字体:设计师的终极开源字体解决方案 【免费下载链接】source-han-serif-ttf Source Han Serif TTF 项目地址: https://gitcode.com/gh_mirrors/so/source-han-serif-ttf 还在为商业项目寻找高质量中文字体而烦恼吗?Source Han Se…...