MySQL大数据量分页查询方法及其优化
---方法1: 直接使用数据库提供的SQL语句
---语句样式: MySQL中,可用如下方法: SELECT * FROM 表名称 LIMIT M,N
---适应场景: 适用于数据量较少的情况(元组百/千级)
---原因/缺点: 全表扫描,速度会很慢 且 有的数据库结果集返回不稳定(如某次返回1,2,3,另外的一次返回2,1,3). Limit限制的是从结果集的M位置处取出N条输出,其余抛弃.
---方法2: 建立主键或唯一索引, 利用索引(假设每页10条)
---语句样式: MySQL中,可用如下方法: SELECT * FROM 表名称 WHERE id_pk > (pageNum*10) LIMIT M
---适应场景: 适用于数据量多的情况(元组数上万)
---原因: 索引扫描,速度会很快. 有朋友提出: 因为数据查询出来并不是按照pk_id排序的,所以会有漏掉数据的情况,只能方法3
---方法3: 基于索引再排序
---语句样式: MySQL中,可用如下方法: SELECT * FROM 表名称 WHERE id_pk > (pageNum*10) ORDER BY id_pk ASC LIMIT M
---适应场景: 适用于数据量多的情况(元组数上万). 最好ORDER BY后的列对象是主键或唯一所以,使得ORDERBY操作能利用索引被消除但结果集是稳定的(稳定的含义,参见方法1)
---原因: 索引扫描,速度会很快. 但MySQL的排序操作,只有ASC没有DESC(DESC是假的,未来会做真正的DESC,期待...).
---方法4: 基于索引使用prepare(第一个问号表示pageNum,第二个?表示每页元组数)
---语句样式: MySQL中,可用如下方法: PREPARE stmt_name FROM SELECT * FROM 表名称 WHERE id_pk > (?* ?) ORDER BY id_pk ASC LIMIT M
---适应场景: 大数据量
---原因: 索引扫描,速度会很快. prepare语句又比一般的查询语句快一点。
---方法5: 利用MySQL支持ORDER操作可以利用索引快速定位部分元组,避免全表扫描
比如: 读第1000到1019行元组(pk是主键/唯一键).
SELECT * FROM your_table WHERE pk>=1000 ORDER BY pk ASC LIMIT 0,20
---方法6: 利用"子查询/连接+索引"快速定位元组的位置,然后再读取元组. 道理同方法5
如(id是主键/唯一键,蓝色字体时变量):
利用子查询示例:
SELECT * FROM your_table WHERE id <=
(SELECT id FROM your_table ORDER BY id desc LIMIT ($page-1)*$pagesize ORDER BY id desc LIMIT $pagesize
利用连接示例:
SELECT * FROM your_table AS t1
JOIN (SELECT id FROM your_table ORDER BY id desc LIMIT ($page-1)*$pagesize AS t2
WHERE t1.id <= t2.id ORDER BY t1.id desc LIMIT $pagesize;
mysql大数据量使用limit分页,随着页码的增大,查询效率越低下。
测试实验
1. 直接用limit start, count分页语句, 也是我程序中用的方法:
select * from product limit start, count
当起始页较小时,查询没有性能问题,我们分别看下从10, 100, 1000, 10000开始分页的执行时间(每页取20条), 如下:
select * from product limit 10, 20 0.016秒
select * from product limit 100, 20 0.016秒
select * from product limit 1000, 20 0.047秒
select * from product limit 10000, 20 0.094秒
我们已经看出随着起始记录的增加,时间也随着增大, 这说明分页语句limit跟起始页码是有很大关系的,那么我们把起始记录改为40w看下(也就是记录的一般左右)
select * from product limit 400000, 20 3.229秒
再看我们取最后一页记录的时间
select * from product limit 866613, 20 37.44秒
像这种分页最大的页码页显然这种时间是无法忍受的。
从中我们也能总结出两件事情:
1)limit语句的查询时间与起始记录的位置成正比
2)mysql的limit语句是很方便,但是对记录很多的表并不适合直接使用。
2. 对limit分页问题的性能优化方法
利用表的覆盖索引来加速分页查询
我们都知道,利用了索引查询的语句中如果只包含了那个索引列(覆盖索引),那么这种情况会查询很快。
因为利用索引查找有优化算法,且数据就在查询索引上面,不用再去找相关的数据地址了,这样节省了很多时间。另外Mysql中也有相关的索引缓存,在并发高的时候利用缓存就效果更好了。
在我们的例子中,我们知道id字段是主键,自然就包含了默认的主键索引。现在让我们看看利用覆盖索引的查询效果如何:
这次我们之间查询最后一页的数据(利用覆盖索引,只包含id列),如下:
select id from product limit 866613, 20 0.2秒
相对于查询了所有列的37.44秒,提升了大概100多倍的速度
那么如果我们也要查询所有列,有两种方法,一种是id>=的形式,另一种就是利用join,看下实际情况:
SELECT * FROM product WHERE ID > =(select id from product limit 866613, 1) limit 20
查询时间为0.2秒!
另一种写法
SELECT * FROM product a JOIN (select id from product limit 866613, 20) b ON a.ID = b.id
查询时间也很短!
3. 复合索引优化方法
MySql 性能到底能有多高?MySql 这个数据库绝对是适合dba级的高手去玩的,一般做一点1万篇新闻的小型系统怎么写都可以,用xx框架可以实现快速开发。可是数据量到了10万,百万至千万,他的性能还能那么高吗?一点小小的失误,可能造成整个系统的改写,甚至更本系统无法正常运行!好了,不那么多废话了。用事实说话,看例子:
数据表 collect ( id, title ,info ,vtype) 就这4个字段,其中 title 用定长,info 用text, id 是逐渐,vtype是tinyint,vtype是索引。这是一个基本的新闻系统的简单模型。现在往里面填充数据,填充10万篇新闻。最后collect 为 10万条记录,数据库表占用硬1.6G。OK ,看下面这条sql语句:
select id,title from collect limit 1000,10; 很快;基本上0.01秒就OK,再看下面的
select id,title from collect limit 90000,10; 从9万条开始分页,结果?
8-9秒完成,my god 哪出问题了?其实要优化这条数据,网上找得到答案。看下面一条语句:
select id from collect order by id limit 90000,10;
很快,0.04秒就OK。 为什么?因为用了id主键做索引当然快。网上的改法是:
select id,title from collect where id>=(select id from collect order by id limit 90000,1) limit 10;
这就是用了id做索引的结果。可是问题复杂那么一点点,就完了。看下面的语句
select id from collect where vtype=1 order by id limit 90000,10; 很慢,用了8-9秒!
到了这里我相信很多人会和我一样,有崩溃感觉!vtype 做了索引了啊?怎么会慢呢?vtype做了索引是不错,你直接
select id from collect where vtype=1 limit 1000,10;
是很快的,基本上0.05秒,可是提高90倍,从9万开始,那就是0.05*90=4.5秒的速度了。和测试结果8-9秒到了一个数量级。从这里开始有人提出了分表的思路,这个和dis #cuz 论坛是一样的思路。思路如下:
建一个索引表: t (id,title,vtype) 并设置成定长,然后做分页,分页出结果再到 collect 里面去找info 。 是否可行呢?实验下就知道了。
10万条记录到 t(id,title,vtype) 里,数据表大小20M左右。用
select id from t where vtype=1 order by id limit 90000,10;
很快了。基本上0.1-0.2秒可以跑完。为什么会这样呢?我猜想是因为collect 数据太多,所以分页要跑很长的路。limit 完全和数据表的大小有关的。其实这样做还是全表扫描,只是因为数据量小,只有10万才快。OK, 来个疯狂的实验,加到100万条,测试性能。加了10倍的数据,马上t表就到了200多M,而且是定长。还是刚才的查询语句,时间是0.1-0.2秒完成!分表性能没问题?错!因为我们的limit还是9万,所以快。给个大的,90万开始
select id from t where vtype=1 order by id limit 900000,10;
看看结果,时间是1-2秒!why ?
分表了时间还是这么长,非常之郁闷!有人说定长会提高limit的性能,开始我也以为,因为一条记录的长度是固定的,mysql 应该可以算出90万的位置才对啊?可是我们高估了mysql 的智能,他不是商务数据库,事实证明定长和非定长对limit影响不大?怪不得有人说discuz到了100万条记录就会很慢,我相信这是真的,这个和数据库设计有关!
难道MySQL 无法突破100万的限制吗???到了100万的分页就真的到了极限?
答案是: NO 为什么突破不了100万是因为不会设计mysql造成的。下面介绍非分表法,来个疯狂的测试!一张表搞定100万记录,并且10G 数据库,如何快速分页!
好了,我们的测试又回到 collect表,开始测试结论是:
30万数据,用分表法可行,超过30万他的速度会慢道你无法忍受!当然如果用分表+我这种方法,那是绝对完美的。但是用了我这种方法后,不用分表也可以完美解决!
答 案就是:复合索引! 有一次设计mysql索引的时候,无意中发现索引名字可以任取,可以选择几个字段进来,这有什么用呢?开始的
select id from collect order by id limit 90000,10;
这么快就是因为走了索引,可是如果加了where 就不走索引了。抱着试试看的想法加了 search(vtype,id) 这样的索引。然后测试
select id from collect where vtype=1 limit 90000,10; 非常快!0.04秒完成!
再测试: select id ,title from collect where vtype=1 limit 90000,10; 非常遗憾,8-9秒,没走search索引!
再测试:search(id,vtype),还是select id 这个语句,也非常遗憾,0.5秒。
综上:如果对于有where 条件,又想走索引用limit的,必须设计一个索引,将where 放第一位,limit用到的主键放第2位,而且只能select 主键!
完美解决了分页问题了。可以快速返回id就有希望优化limit , 按这样的逻辑,百万级的limit 应该在0.0x秒就可以分完。看来mysql 语句的优化和索引时非常重要的!
相关文章:

MySQL大数据量分页查询方法及其优化
---方法1: 直接使用数据库提供的SQL语句 ---语句样式: MySQL中,可用如下方法: SELECT * FROM 表名称 LIMIT M,N ---适应场景: 适用于数据量较少的情况(元组百/千级) ---原因/缺点: 全表扫描,速度会很慢 且 有的数据库结果集返回不稳定(如某次返回1,2,3,另外的一次返回2,1,3). L…...

dataTable转成对象、json、list
datatable转换成list集合 public static T TableToEntity<T>(DataTable dt, int rowindex 0, bool isStoreDB true){Type type typeof(T);T entity Activator.CreateInstance<T>();if (dt null){return entity;}DataRow row dt.Rows[rowindex];PropertyInfo…...

ubuntu环境安装centos7虚拟机网络主机不可达,ping不通
【NAT模式下解决】1.首先vi /etc/sysconfig/network-scripts/ifcfg-ens33检查ONBOOTyes,保存 2.输入systemctl restart network命令重启网关...

STN:Spatial Transformer Networks
1.Abstract 卷积神经网络缺乏对输入数据保持空间不变的能力,导致模型性能下降。作者提出了一种新的可学习模块,STN。这个可微模块可以插入现有的卷积结构中,使神经网络能够根据特征图像本身,主动地对特征图像进行空间变换&#x…...

C语言学习笔记 VScode设置C环境-06
目录 一、下载vscode软件 二、安装minGW软件 三、VS Code安装C/C插件 3.1 搜索并安装C/C插件 3.2 配置C/C环境 总结 一、下载vscode软件 在官网上下载最新的版本 Download Visual Studio Code - Mac, Linux, Windowshttps://code.visualstudio.com/download 二、安装minGW…...

alias取别名后,另一个shell中和shell脚本中不生效的问题以及crontab执行docker失败问题
目录 问题一:用alias取别名后,另一个shell中不生效描述原因解决 问题二:用alias取别名后,别名在脚本中不生效描述原因解决 问题三:crontab计划任务不能运行docker命令描述原因解决 问题一:用alias取别名后&…...
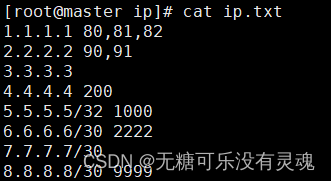
Shell ❀ 一键配置Iptables规则脚本 (HW推荐)
文章目录 注意事项1. 地址列表填写规范2. 代码块3. 执行结果4. 地址与端口获取方法4.1 tcpdump抓包分析(推荐使用)4.2 TCP连接分析(仅能识别TCP连接) 注意事项 请务必按照格式填写具体参数,否则会影响到匹配规则的创建…...

linux服务器查找大文件及删除文件后磁盘空间没有得到释放
1、查询服务器中大于1G的文件 find / -type f -size 1G这条命令是查询自”/”根目录下所有大小超过1G的文件,查询的大小可以根据需要改变,如下: 相关查询:查询服务器中大于100M的文件 find / -type f -size 100M2、查询服务器中…...
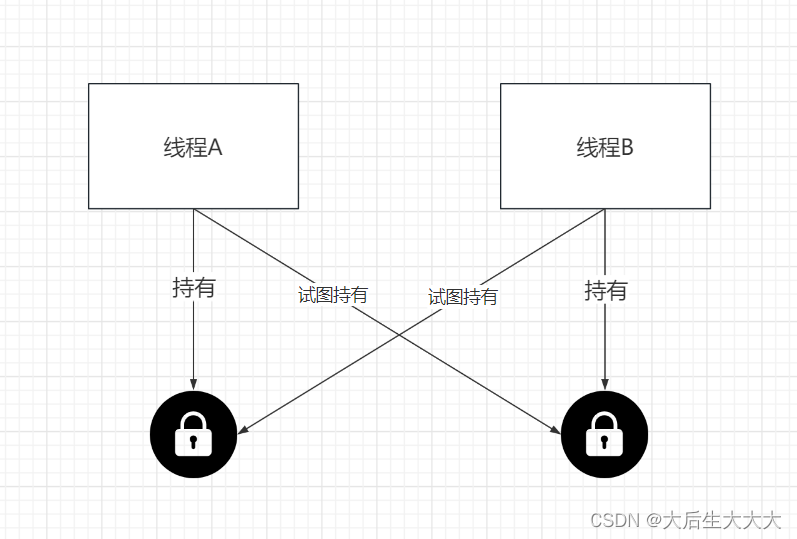
Java那些“锁”事 - 死锁及排查
死锁是两个或者两个以上的线程在执行过程中,因争夺资源而造成的一种互斥等待现象,若没有外界干涉那么它们将无法推进下去。如果系统资源不足,进程的资源请求都得到满足,死锁出现的可能性就很低,否则就会因为争夺有限的…...

LLM系列 | 18 : 如何用LangChain进行网页问答
简介 一夕轻雷落万丝,霁光浮瓦碧参差。 紧接之前LangChain专题文章: 15:如何用LangChain做长文档问答?16:如何基于LangChain打造联网版ChatGPT?17:ChatGPT应用框架LangChain速成大法 今天这篇小作文是LangChain实践专题的第4…...
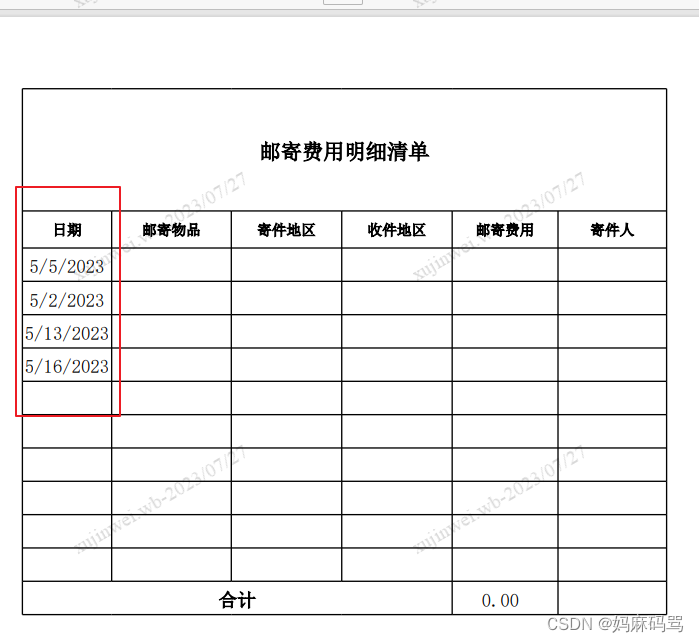
Aspose.cell excel转pdf日期格式不正确yyyy/MM/dd变成MM/dd/yyyy
最近使用Aspose.cell将excel转pdf过程中excel中时间格式列的显示和excel表里的值显示不一样。 excel里日期格式 yyyy/MM/dd pdf里日期格式MM/dd/yyyy 主要原因:linux和windows里内置的时间格式不一致,当代码部署到linux服务器的时候转换格式就会发生不一…...

搭建golang开发环境
这里参考一篇文章: golang环境变量链接,还不错...
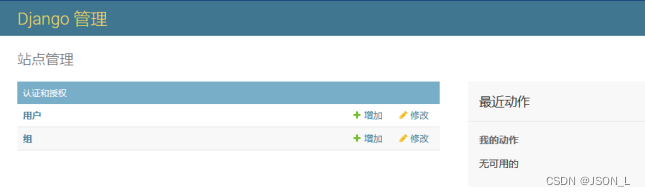
Django实现音乐网站 ⑴
使用Python Django框架制作一个音乐网站。 目录 网站功能模块 安装django 创建项目 创建应用 注册应用 配置数据库 设置数据库配置 设置pymysql库引用 创建数据库 创建数据表 生成表迁移文件 执行表迁移 后台管理 创建管理员账户 启动服务器 登录网站 配置时区…...

基于粒子群优化算法的分布式电源选址与定容【多目标优化】【IEEE33节点】(Matlab代码实现)
目录 💥1 概述 1.1 目标函数 2.2 约束条件 📚2 运行结果 🎉3 参考文献 🌈4 Matlab代码实现 💥1 概述 分布式电源接入配电网,实现就地消纳,可以提高新能源的利用率、提高电能质量和降低系统网损…...

打卡一个力扣题目
目录 一、问题 二、解题办法一 三、解题方法二 四、对比分析 关于 ARTS 的释义 —— 每周完成一个 ARTS: ● Algorithm: 每周至少做一个 LeetCode 的算法题 ● Review: 阅读并点评至少一篇英文技术文章 ● Tips: 学习至少一个技术技巧 ● Share: 分享一篇有观点…...
【SSM—SpringMVC】 问题集锦(持续更新)
目录 1.Tomcat启动,部署工件失败 1.Tomcat启动,部署工件失败 解决:使用SpringMVC,添加Web支持,要将项目结构进行添加WEB-INF下添加lib目录,将依赖添进去...
“软件测试”赛项接口测试任务书)
2022年全国职业院校技能大赛(高职组)“软件测试”赛项接口测试任务书
任务七 接口测试 执行接口测试 本部分按照要求,执行接口测试;使用接口测试工具PostMan,编写脚本、配置参数、执行接口测试并且截图,截图需粘贴在接口测试总结报告中。 接口测试具体要求如下: 题目1:资产…...
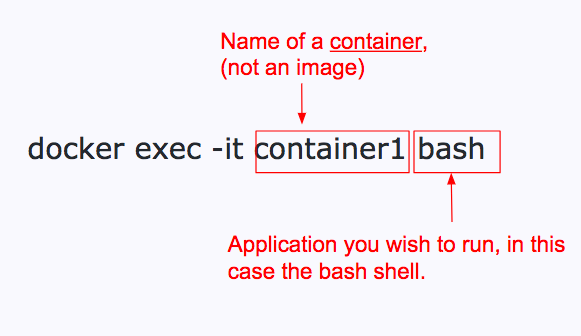
Docker 如何助您成为数据科学家
一、说明 在过去的 5 年里,我听到了很多关于 docker 容器的嗡嗡声。似乎我所有的软件工程朋友都在使用它们来开发应用程序。我想弄清楚这项技术如何使我更有效率,但我发现网上的教程要么太详细:阐明我作为数据科学家永远不会使用的功能&#…...

机器学习01 -Hello World(对鸢尾花(Iris Flower)进行训练及测试)
什么是机器学习? 机器学习是一种人工智能(AI)的子领域,它探索和开发计算机系统,使其能够从数据中学习和改进,并在没有明确编程指令的情况下做出决策或完成任务。 传统的程序需要程序员明确编写指令来告诉…...
android studio JNI开发
一、JNI的作用: 1.使Java与本地其他类型语言(C、C)交互; 2.在Java代码调用C、C等语言的代码 或者 C、C调用Java代码。 由于JAVA具有跨平台的特点,所以JAVA与本地代码的交互能力弱,采用JNI特性可以增强JA…...

思源宋体免费商用字体:设计师的终极开源字体解决方案
思源宋体免费商用字体:设计师的终极开源字体解决方案 【免费下载链接】source-han-serif-ttf Source Han Serif TTF 项目地址: https://gitcode.com/gh_mirrors/so/source-han-serif-ttf 还在为商业项目寻找高质量中文字体而烦恼吗?Source Han Se…...

颠覆原神体验:Snap Hutao智能助手如何重构你的游戏效率
颠覆原神体验:Snap Hutao智能助手如何重构你的游戏效率 【免费下载链接】Snap.Hutao 实用的开源多功能原神工具箱 🧰 / Multifunctional Open-Source Genshin Impact Toolkit 🧰 项目地址: https://gitcode.com/GitHub_Trending/sn/Snap.Hu…...

ReplaceItems.jsx:基于智能匹配引擎的Illustrator对象替换解决方案
ReplaceItems.jsx:基于智能匹配引擎的Illustrator对象替换解决方案 【免费下载链接】illustrator-scripts Adobe Illustrator scripts 项目地址: https://gitcode.com/gh_mirrors/il/illustrator-scripts 副标题:面向专业设计师的批量元素管理工具…...

如何用网盘直链下载助手突破限制提升效率:5个实用技巧
如何用网盘直链下载助手突破限制提升效率:5个实用技巧 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘 / 天翼…...

高效突破:Cursor Pro功能优化与多场景应用指南
高效突破:Cursor Pro功能优化与多场景应用指南 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached your trial requ…...

OpenClaw数据安全:Qwen3.5-4B-Claude本地处理敏感合同
OpenClaw数据安全:Qwen3.5-4B-Claude本地处理敏感合同 1. 为什么法律行业需要本地化AI处理 去年我参与了一个法律科技项目,团队最初尝试用公有云API处理合同文本时,遭遇了客户对数据出海的强烈抵触。某次演示中,当法务总监看到合…...

如何通过手机号快速查询QQ号:3分钟解决账号遗忘难题
如何通过手机号快速查询QQ号:3分钟解决账号遗忘难题 【免费下载链接】phone2qq 项目地址: https://gitcode.com/gh_mirrors/ph/phone2qq 在数字时代,QQ账号作为重要的社交和工作工具,其安全性与可访问性至关重要。然而,更…...

为什么小数据集上神经网络会突然‘开窍‘?揭秘Grokking现象背后的LU机制
为什么小数据集上神经网络会突然"开窍"?揭秘Grokking现象背后的LU机制 在机器学习实践中,我们常常观察到一种反直觉的现象:当神经网络在小规模算法数据集上训练时,测试准确率会在长时间停滞于随机猜测水平后突然跃升至接…...
)
别再让Jetson NX的CPU跑视频了!手把手教你用FFmpeg+NVENC实现硬件编解码(附4.2版本完整编译流程)
Jetson NX视频处理性能优化实战:FFmpegNVENC硬件加速全解析 如果你正在使用Jetson Xavier NX开发视频处理应用,却苦于CPU软编解码的低效表现,这篇文章将为你揭示如何彻底释放这块嵌入式AI计算板的硬件潜能。我们将从性能瓶颈分析开始…...

在GCP上运行autoresearch
Andrej Karpathy最近开源了autoresearch,这是一个将真实LLM训练环境交给AI代理并让它自主实验的项目。代理修改模型代码,训练恰好5分钟,检查验证损失是否改善,保留或丢弃更改,然后重复。你去睡觉;醒来时会看…...