[语义分割] DeepLab v3(Cascaded model、ASPP model、两种ASPP对比、Multi-grid、训练细节)
- 论文地址:Rethinking Atrous Convolution for Semantic Image Segmentation
- Pytorch 实现代码:pytorch_segmentation/deeplab_v3
这是一篇 2017 年发表在CVPR上的文章。相比 DeepLab V2 有三点变化:①引入了 Multi-grid;②改进了 ASPP 结构;③移除 CRFs 后处理。
① 引入了 Multi-grid,目的:Multi-grid 的引入旨在进一步改进空洞卷积的使用方式,提高语义分割模型在不同尺度上的性能。在之前的版本(如 DeepLab V2)中,空洞卷积的膨胀系数是固定的,这限制了模型在不同尺度上捕捉上下文信息的能力。通过引入 Multi-grid,DeepLab v3 可以使用不同的膨胀系数来处理特征图,从而在多个尺度上捕获更丰富的上下文信息,这有助于更好地分割不同大小的目标。
② 改进了 ASPP 结构(Atrous Spatial Pyramid Pooling),目的:ASPP 结构用于在特征图的不同尺度上捕获多尺度上下文信息。在 DeepLab V3 中,ASPP 结构得到了改进,除了原来的多个膨胀系数的膨胀卷积外,还引入了图像级特征(全局平均池化),这样在 ASPP 模块中既能获取局部细节信息,也能融合全局上下文信息。这种改进有助于提高模型的感知范围和语义信息,从而改善分割性能。
③ 移除 CRFs 后处理(Conditional Random Fields),目的:在 DeepLab V2 中,使用CRF进行后处理是为了进一步优化语义分割结果,特别是在边界细节上进行平滑处理。然而,CRF 的计算代价较高,并且会增加模型的复杂性。DeepLab V3 移除了 CRF 后处理步骤,而是通过引入 Multi-grid 和改进 ASPP 结构来在模型中直接获得更全面和精确的特征表示,从而减少了 CRF 的需求。这样一来,DeepLab V3 在保持高性能的同时,简化了模型结构和训练过程。
DeepLab v3 概况
DeepLab v3是一个语义分割模型,其核心思想是使用深度卷积神经网络来实现高精度的语义分割任务。它是DeepLab系列模型的第三个版本,针对之前版本的一些缺点进行了改进。
DeepLab v3的核心思想包括以下几个关键点:
-
空洞卷积(Dilated Convolution):为了增加感受野(Receptive Field)的大小,DeepLab v3引入了空洞卷积。传统的卷积操作在特征提取时只考虑局部邻域信息,而空洞卷积通过在卷积核中引入空洞(或称为膨胀率),使得卷积核可以在更大范围内获取特征信息,从而捕捉更广阔的上下文信息。
-
多尺度信息融合:DeepLab v3采用了多尺度信息融合的方法,通过在不同尺度下对特征图进行空间金字塔池化操作,得到不同分辨率的特征图。然后,通过上采样和融合这些特征图,使得模型能够在不同尺度下获得更为丰富的信息,有利于对目标进行更准确的分割。
-
全局平均池化(Global Average Pooling):DeepLab v3在最后的特征图上使用全局平均池化来获得整体图像的全局信息。这有助于进一步提升模型的上下文感知能力,对于包含大范围目标的图像尤为重要。
-
条件随机场(Conditional Random Field,CRF):在得到初步的语义分割结果后,DeepLab v3采用了条件随机场来进行后处理。CRF能够利用像素之间的空间相关性和颜色相似性,对分割结果进行平滑,减少一些细节上的错误。
综合以上几点,DeepLab v3能够有效地捕获图像中的上下文信息和多尺度特征,并对这些特征进行充分融合和处理,从而在语义分割任务中达到较高的准确率。
Abstract
在这项工作中,我们重新考虑了空洞卷积(atrous convolution),这是一种强大的工具,可以明确地调整卷积核的感受野,并控制 CNNs 计算的特征响应的分辨率,用于语义图像分割的应用。为了解决在多个尺度上分割对象的问题,我们设计了使用空洞卷积的模块,这些模块串联或并行地采用多个膨胀率 r r r 来捕获多尺度上下文。此外,我们提出了对之前提出的空洞空间金字塔池化(Atrous Spatial Pyramid Pooling,ASPP)模块进行增强,该模块可以在多个尺度上探测卷积特征,并融合包含全局上下文的图像级特征,从而进一步提升性能。我们还详细阐述了实现细节,并分享了训练系统的经验。所提出的“DeepLabv3”系统在没有 DenseCRF 后处理的情况下明显优于我们之前的 DeepLab 版本,并在 PASCAL VOC 2012 语义图像分割基准测试中达到了与其他最先进模型相当的性能。
1. 用于捕获多尺度上下文信息的可选架构

- (a) 图像金字塔:这是我们最容易想到的一种方式,即将图片缩放到不同的尺度后再分别送入网络进行推理;最终再进行融合
- (b) 编解码器:首先按照 Backbone 对输入图片进行一系列的下采样,最后再将最终的特征图进行一系列上采样;在上采样的过程中会和 Backbone 中得到的特征图进行融合;依次类推直至还原回原图大小
- (c) DeepLab v1 中的方法:将 Backbone 中最后几个卷积层的
stride设置为 1;然后再引入膨胀卷积以增大网络的感受野 - (d) DeepLab v2 中的方法:引入 ASPP(空洞空间金字塔池化)以增加模型获取多尺度信息的能力
2. DeepLab v3 的两种模型结构
- Cascaded Model:级联的模型
- ASPP Model
在 Cascaded model 中是没有使用 ASPP 模块的,在 ASPP model 中是没有使用 cascaded blocks 模块的。
注意,虽然文中提出了两种结构,但作者说 ASPP model 比 cascaded model 略好点。包括在 Github 上开源的一些代码,大部分也是用的 ASPP model。
2.1 Cascaded Model

论文中提出的 cascaded model 指的是图 (b)。其中 Block1、Block2、Block3、Block4 是原始 ResNet 网络中的层结构,但在 Block4 中将第一个残差结构里的 3 × 3 3\times 3 3×3 卷积层以及捷径分支上的 1 × 1 1\times 1 1×1 卷积层步距 stride 由 2 改成了 1(即不进行下采样),并且所有残差结构里 3 × 3 3\times 3 3×3 的普通卷积层都换成了膨胀卷积层。Block5、Block6 和 Block7 是额外新增的层结构,它们的结构和 Block4 是一模一样的,即由三个残差结构(使用了膨胀卷积)构成。
注意❗️原论文说在训练 cascaded model 时
output_stride=16(即特征层相对输入图片的下采样率),但验证时使用的output_stride=8。因为output_stride=16时最终得到的特征层H和W会更小,这意味着可以设置更大的batch_size并且能够加快训练速度。但特征层H和W变小会导致特征层丢失细节信息(文中说变的更“粗糙”),所以在验证时采用的output_stride=8。其实只要你GPU显存足够大,算力足够强也可以直接把output_stride设置成 8。—— 简单来说,训练的时候作者使用了 16 倍下采样率,而验证的时候使用了 8 倍下采样率。
另外需要注意❗️的是,图中标注的 rate 并不是膨胀卷积真正采用的膨胀系数。 真正采用的膨胀系数应该是图中的 rate 乘上 Multi-Grid参数,比如 Block4 中 rate=2,Multi-Grid=(1, 2, 4),那么真正采用的膨胀系数是 2 × ( 1 , 2 , 4 ) = ( 2 , 4 , 8 ) 2 \times (1, 2, 4) = (2, 4, 8) 2×(1,2,4)=(2,4,8)。关于Multi-Grid参数后面会提到。
r a c t u a l l y = r a t e × M u l t i G r i d r_\mathrm{actually} = \mathrm{rate} \times \mathrm{MultiGrid} ractually=rate×MultiGrid
2.2 ASPP Model
2.2.1 整体模型结构
虽然论文大篇幅的内容都在讲 Cascaded Model 及其对应的实验,但实际使用的最多的还是 ASPP Model,其模型结构如下图所示。

注意❗️和 Cascaded Model 一样,原论文中说在训练时
output_stride=16(即特征层相对输入图片的下采样率),但验证时使用的output_stride=8。但在 PyTorch 官方实现的 DeepLabV3 源码中就直接把output_stride设置成 8 进行训练的。
2.2.2 两种版本 ASPP 的对比
2.2.2.1 ASPP in v2
首先回顾 DeepLab V2 中的 ASPP 结构,DeepLab V2 中的 ASPP 结构其实就是 通过四个并行的膨胀卷积层,每个分支上的膨胀卷积层所采用的膨胀系数不同(注意,这里的膨胀卷积层后没有跟 BatchNorm 并且使用了偏执 Bias)。接着通过 add ⊕ \oplus ⊕ 相加的方式融合四个分支上的输出。

2.2.2.2 ASPP in v3
我们再来看下 DeepLab V3 中的 ASPP 结构,如下图所示。

这里的 ASPP 结构有 5 个并行分支,分别是:
① 一个 1 × 1 1\times 1 1×1 的卷积层
② ~ ④ 三个 3 × 3 3\times 3 3×3 的膨胀卷积层
⑤ 以及一个全局平均池化层(后面还跟有一个 1 × 1 1\times 1 1×1 的卷积层,然后通过双线性插值的方法还原回输入的 W 和 H)。
关于最后一个全局池化分支作者说是为了增加一个全局上下文信息(Global Contextual Information)。
之后通过 Concat 的方式将这 5 个分支的输出进行拼接(沿着 channels 方向),最后再通过一个 1 × 1 1\times 1 1×1 的卷积层进一步融合信息。
3. Multi-grid(多级网格方法)
在之前的 DeepLab 模型中虽然一直在使用膨胀卷积,但设置的膨胀系数都比较随意。在 DeepLab V3 中作者有去做一些相关实验看如何设置更合理。下表是以 Cascaded Model(ResNet-101 作为 Backbone 为例)为实验对象,研究采用不同数量的 cascaded blocks 模型以及 cascaded blocks 采用不同的 Multi-Grid 参数的效果。

注意❗️
- block5 ~ block7 都是和 block4 结构一样,只不过膨胀系数变了
- 刚刚在讲 cascaded model 时有提到,blocks 中真正采用的膨胀系数应该是图中的 rate 乘上这里的 Multi-Grid 参数
通过实验发现:
- 当采用三个额外的 Block 时(即额外添加 Block5、Block6 和 Block7)将 Multi-Grid 设置成
(1, 2, 1)效果最好 —— Cascaded Model 最佳模型 - 另外如果不添加任何额外 Block(即没有Block5、Block6 和 Block7)将 Multi-Grid 设置成
(1, 2, 4)效果最好 —— ASPP Model 最佳模型
因为在 ASPP model 中是没有额外添加 Block 层的,后面讲 ASPP model 的消融实验时采用的就是 Multi-Grid 等于(1, 2, 4)的情况。
4. 消融实验
4.1 Cascaded model(联级模型)消融实验
下表是有关 cascaded model 的消融实验。

其中:
- MG 代表 Multi-Grid,刚刚在上面也有说在 cascaded model 中采用
MG(1, 2, 1)是最好的。 - OS 代表 output_stride(下采样倍数),刚刚在上面也有提到过验证时将
output_stride设置成 8 效果会更好 - MS 代表多尺度,和 DeepLab V2 中类似。不过在 DeepLab V3 中采用的尺度更多
scales = {0.5, 0.75, 1.0, 1.25, 1.5, 1.75} - Flip 代表增加一个水平翻转后的图像输入
4.2 ASPP model 消融实验
下表是有关ASPP model的消融实验。

其中:
- MG 代表 Multi-Grid,刚刚在上面也有说在 ASPP model 中采用
MG(1, 2, 4)是最好的 - ASPP 前面讲过
- Image Pooling 代表在 ASPP 中加入全局平均池化层分支
- OS 代表 output_stride,刚刚在上面也有提到过验证时将
output_stride设置成 8 效果会更好 - MS 代表多尺度,和 DeepLab V2 中类似。不过在 DeepLab V3 中采用的尺度更多
scales = {0.5, 0.75, 1.0, 1.25, 1.5, 1.75} - Flip 代表增加一个水平翻转后的图像输入
- COCO 代表在 COCO 数据集上进行预训练
5. 训练细节
下表是原论文中给出的关于 DeepLab V3 在 Pascal VOC2012 测试数据集上的 mean IOU。

通过对比发现,其实 DeepLab V3 和 V2 比起来提升了大约 6 个点。但这里的 DeepLab V3 貌似并没有明确指出具体是 cascaded model 还是 ASPP model,个人觉得大概率是指的 ASPP model。然后仔细想想这 6 个点到底是怎么提升的,如果仅通过引入 Multi-Grid,改进 ASPP 模块以及在 MSC 中使用更多的尺度应该不会提升这么多个点。所以我能想到的就是在训练过程中的某些改动导致 mean IOU 提升了。
论文中 A. Effect of hyper-parameters 部分,其中作者有说:
在训练过程中增大了训练输入图片的尺寸(论文中有个观点大家需要注意下,即采用大的膨胀系数时,输入的图像尺寸不能太小,否则 3 × 3 3\times 3 3×3 的膨胀卷积可能退化成 1 × 1 1\times 1 1×1 的普通卷积。
计算损失时,是将预测的结果通过上采样还原回原尺度后(即网络最后的双线性插值上采样 8 倍)在和真实标签图像计算损失。而之前在 V1 和 V2 中是将真实标签图像下采用 8 倍然后和没有进行上采样的预测结果计算损失(当时这么做的目的是为了加快训练)。根据 Table 8 中的实验可以提升 1 个多点。
训练完毕后,冻结 BN 层的参数,然后再去 fine-turn 下网络的其它层,根据 Table 8 中的实验可以提升 1 个多点。
6. PyTorch 官方实现 DeepLab V3 模型结构
下图是霹雳吧啦WZ根据 PyTorch 官方实现的 DeepLab V3 源码绘制的网络结构(与原论文有些许差异):
- 在 PyTorch 官方实现的 DeepLab V3 中,并没有使用 Multi-Grid
- 在 PyTorch 官方实现的 DeepLab V3 中多了一个 FCNHead 辅助训练分支,可以选择不使用
- 在 PyTorch 官方实现的 DeepLab V3 中无论是训练还是验证
output_stride都使用的 8 - ASPP 中三个膨胀卷积分支的膨胀系数是
{12, 24, 36},因为论文中说当output_stride=8时膨胀系数要翻倍

知识来源
- https://blog.csdn.net/qq_37541097/article/details/121797301
- https://www.bilibili.com/video/BV1Jb4y1q7j7
相关文章:
[语义分割] DeepLab v3(Cascaded model、ASPP model、两种ASPP对比、Multi-grid、训练细节)
Rethinking Atrous Convolution for Semantic Image Segmentation 论文地址:Rethinking Atrous Convolution for Semantic Image SegmentationPytorch 实现代码:pytorch_segmentation/deeplab_v3 这是一篇 2017 年发表在CVPR上的文章。相比 DeepLab V2 有…...

css - Media Query
使用bootstrap的grid system可以在一个较为粗糙的范围得到较好的响应性,但是通过viewport可以看到网站在具体哪个像素点处变得丑陋,再通过css media query来精细调整网页布局。 可以通过media query来提高网页移动响应能力。...
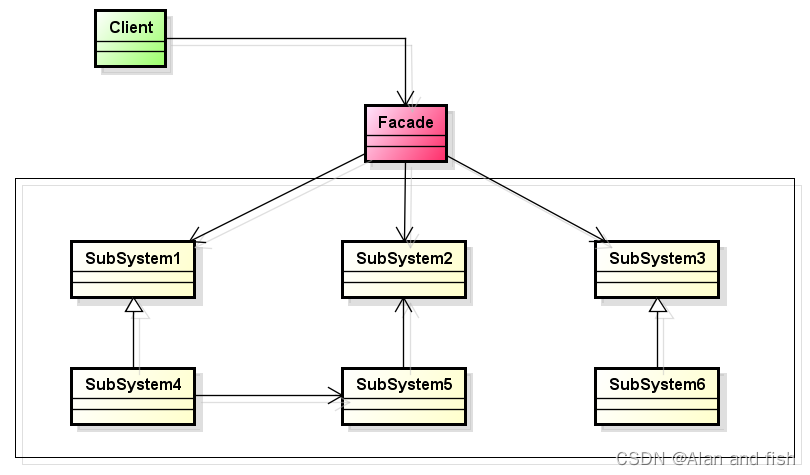
9.python设计模式【外观模式】
内容:为子系统中的一组接口提供一个一致的界面,外观模式定义了一个高层接口,这个接口使得这一个子系统更加容易使用。 角色: 外观(facade)子类系统(subsystem classes) UML图 举…...

Webpack5 CopyPlugin的作用
在Webpack 5中,CopyPlugin是一个插件,用于将文件或目录从源位置复制到构建目录中。它的作用是帮助开发人员在构建过程中将静态文件(如图片、字体等)直接复制到输出目录,而无需经过任何处理。 CopyPlugin并不是必须的&…...

kafka服务端允许生产者发送最大消息体大小
1、kafka config服务端配置文件server.properties server.properties中加上的message.max.bytes配置,我目前设置为5242880,即5MB,可以根据实际情况增大。 message.max.bytes5242880 在生产者端配置max.request.size,这是单个消息…...

台阶型Nim游戏博弈论
台阶型Nim游戏 题目 https://www.acwing.com/problem/content/894/ 现在,有一个 n n n 级台阶的楼梯,每级台阶上都有若干个石子,其中第 i i i 级台阶上有 a i a_i ai 个石子( i ≥ 1 i \ge 1 i≥1)。 两位玩家轮流操作,每…...

NestJS 的 中间件 学习
基本概念 中间件是在路由处理程序之前调用的函数。中间件函数可以访问请求和响应对象。在程序中我们可以让多个中间件串起来一起使用,当多个中间件一起使用时我们可以使用next()调用下一个中间件。 中间件主要是可以实现如下功能: 执行任何代码更改请…...

搭建自己第一个golang程序
概念: golang 和 java有些类似,配置好环境就可以直接编写运行了;这里分两种: 一.shell模式 创建一个go类型的文件 往里面编写代码 二.开发工具模式 这里的开发工具 我选用goland package mainimport "fmt"func mai…...
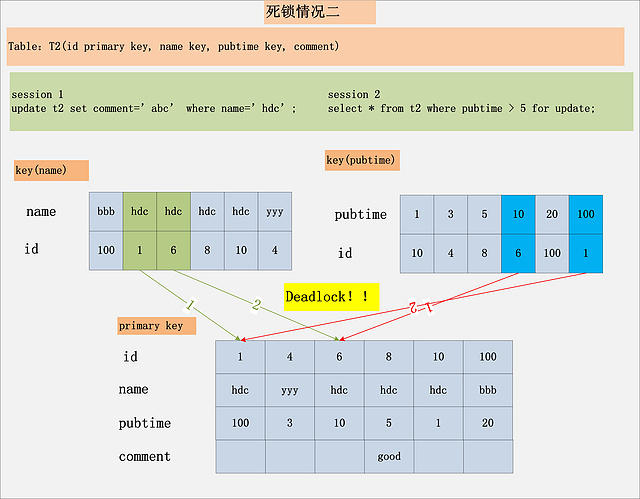
Mysql加锁过程
1、背景 MySQL/InnoDB的加锁分析,一直是一个比较困难的话题。我在工作过程中,经常会有同事咨询这方面的问题。同时,微博上也经常会收到MySQL锁相关的私信,让我帮助解决一些死锁的问题。本文,准备就MySQL/InnoDB的加锁问…...

财经界杂志财经界杂志社财经界编辑部2023年第19期目录
《财经界》投稿邮箱:cnqikantg126.com(注明投稿“《财经界》”) ●崔编辑Q Q :695548262 微信号:f99832970 名刊名著_国内外名刊名著 财经名刊名著 李少鹏 ;王海蕴; 6-7 发改委专线 六方面发力 看中国经济形势,既要看准当…...

Linux常用命令——dpkg-split命令
在线Linux命令查询工具 dpkg-split Debian Linux中将大软件包分割成小包 补充说明 dpkg-split命令用来将Debian Linux中的大软件包分割成小软件包,它还能够将已分割的文件进行合并。 语法 dpkg-split(选项)(参数)选项 -S:设置分割后的每个小文件最…...
常见的二十种软件测试方法详解
一.单元测试(模块测试) 单元测试是对软件组成单元进行测试。其目的是检验软件组成单位的正确性。测试对象是:模块。 对模块进行测试,单独的一个模块测试,属于静态测试的一类 测试阶段:编码后或者编码前&…...

Python(一)
要做到坚韧不拔,最要紧的是坚持到底。——陀思妥耶夫斯基 2023 6 14~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ --根据你自己的操作系统下载对应的。 -- pyhton 文档 --交互方式 使用的工具 --如何启动工具 -- 交互式方式一般在数据分析中…...

git pull无效,显示 * branch master -> FETCH_HEADAlready up to date. pull无效解决方法
报错情况 本地文件夹中删除文件后,git pull无效。显示如下: **** MINGW64 ~/****/haha (master) $ git pull origin master From https://gitee.com/****/haha* branch master -> FETCH_HEAD Already up to date.解决 方法一 命令…...

SK5代理与socks5代理
第一部分:SK5代理与socks5代理的原理与功能 SK5代理 SK5代理是一种加密代理技术,其工作原理主要包括以下几个关键步骤: 代理服务器接收客户端请求;客户端与代理服务器之间建立加密连接;代理服务器将客户端的请求转发…...

【【51单片机红外遥控小风车】】
51单片机红外遥控小风车 今天结束了51单片机的学习,明天开始学习stm32 我是学习江科大的视频一步一步完成的 ,他讲的非常好,非常好 特别通俗易懂 学习复刻他的作品我也自己创作了一些 但是现在暂时脱离这块板子了 以后可能会更新一个应用51单…...

如何连接远程服务器?快解析内内网穿透可以吗?
如今我们迎来了数字化转型的时代,众多企业来为了更好地推动业务的发展,常常需要在公司内部搭建一个远程服务器。然而,对于企业员工来说,在工作过程中经常需要与这个服务器进行互动,而服务器位于公司的局域网中…...

【云边有个小卖部】上新《探秘Linux》第三章 Linux 软件包管理器 yum
🕺作者: 主页 我的专栏C语言从0到1C初阶C进阶数据结构从0到1探秘Linux菜鸟刷题集 😘欢迎关注:👍点赞🙌收藏✍️留言 🏇码字不易,你的👍点赞🙌收藏❤️关注对我…...

【深度学习】【Image Inpainting】Free-Form Image Inpainting with Gated Convolution
模型:DeepFillv2 (CVPR’2019) 论文:https://arxiv.org/abs/1806.03589 代码:https://github.com/JiahuiYu/generative_inpainting 文章目录 效果AbstractIntroductionRelated WorkAutomatic Image InpaintingGuided Image Inpainting and Sy…...
游戏引擎UE如何革新影视行业?创意云全面支持UE云渲染
虚幻引擎UE(Unreal Engine)作为一款“殿堂级”的游戏引擎,占据了全球80%的商用游戏引擎市场,但如果仅仅将其当做游戏开发的工具,显然是低估了它的能力。比如迪士尼出品的电视剧《曼达洛人》、电影《狮子王》等等都使用…...

Spring Cloud AWS 实战教程:构建高可用 SQS 消息队列应用 [特殊字符]
Spring Cloud AWS 实战教程:构建高可用 SQS 消息队列应用 🚀 【免费下载链接】spring-cloud-aws The New Home for Spring Cloud AWS 项目地址: https://gitcode.com/gh_mirrors/sp/spring-cloud-aws Spring Cloud AWS 是一个强大的开源框架&…...

PA100K数据集实战:从下载到结构化解析全流程
1. PA100K数据集初探:为什么选择它?如果你正在研究行人属性识别,PA100K绝对是个绕不开的宝藏数据集。这个数据集包含了10万张真实监控场景下的行人图像,每张图都标注了26种常见属性——从衣着风格(比如是否穿T恤、裙子…...

信息系统项目管理师核心知识点精讲
一、项目整合管理(重点:项目章程与项目管理计划) 知识点详解: 项目整体管理是项目管理知识体系的核心,它确保项目各要素协调统一。在考试中,特别要掌握项目章程和项目管理计划的区别与联系。 项目章程是项目的“出生证明”,由项目发起人发布。它正式授权项目,赋予项…...
:数组排序、去重、查找)
数组专项(一):数组排序、去重、查找
大家好,欢迎来到《算法面试60讲(2026最新版全真题带解析)》第19篇!上一篇我们彻底吃透了字符串专项的核心难点——BF暴力匹配与KMP高效匹配算法,搞定了字符串模块面试最难的算法考点。从本节课开始,我们正式进入算法面试第一高频模块:数组专项。 在算法面试中,数组是出…...

终极艾尔登法环帧率解锁指南:轻松突破60FPS限制
终极艾尔登法环帧率解锁指南:轻松突破60FPS限制 【免费下载链接】EldenRingFpsUnlockAndMore A small utility to remove frame rate limit, change FOV, add widescreen support and more for Elden Ring 项目地址: https://gitcode.com/gh_mirrors/el/EldenRing…...
)
ROS Noetic实战:从bag包里‘抠’出雷达点云和IMU数据的保姆级教程(Ubuntu 20.04)
ROS Noetic实战:从bag包里提取雷达点云和IMU数据的完整指南(Ubuntu 20.04)在机器人开发中,ROS bag文件就像是一个装满珍贵数据的宝箱,而雷达点云和IMU数据则是其中最闪亮的宝石。作为一名长期与ROS打交道的开发者&…...

智能体所有权与版权:AI Agent Harness Engineering 创造的作品归谁所有?
1. 标题选项 《AI Agent创作版权迷局破解:从Harness工程原理到所有权划分的完整指南》 《智能体作品归谁?AI Agent Harness Engineering场景下的版权规则深度拆解》 《告别权属纠纷:一文搞懂AI Agent生成内容的所有权、版权与收益分配规则》 《Harness工程视角下的AI创作权:…...

终极Node.js Mock工具:Mockery入门到精通实战教程
终极Node.js Mock工具:Mockery入门到精通实战教程 【免费下载链接】mockery Simplifying the use of mocks with Node.js 项目地址: https://gitcode.com/gh_mirrors/mock/mockery Mockery是Node.js生态中简化Mock使用的终极工具,它为开发者提供了…...

1688运营培训/询盘成本从500元降到63.9!1688运营培训还原1688真实玩法
1688运营培训/询盘成本从500元降到63.9!1688运营培训还原1688真实玩法500块钱一个询盘,你敢信?做1688运营培训这么多年,这个数字我都觉得离谱。前阵子遇到一个老板,一上来就开始吐槽1688,说1688就是个垃圾平…...

【python】ImportError: DLL load failed while importing QtWidgets: 找不到指定的程序。重新安装后搞定
文章目录前言一、PyQt6引用后报错二、使用步骤总结前言 想做个好看的界面,引用了PyQt6,却产生了新问题。 pip install pyqt6-tools,优先做这个动作进行修复。 一、PyQt6引用后报错 python里引用: from PyQt6.QtWidgets import…...