【深度学习】【Image Inpainting】Free-Form Image Inpainting with Gated Convolution
模型:DeepFillv2 (CVPR’2019)
论文:https://arxiv.org/abs/1806.03589
代码:https://github.com/JiahuiYu/generative_inpainting
文章目录
- 效果
- Abstract
- Introduction
- Related Work
- Automatic Image Inpainting
- Guided Image Inpainting and Synthesis
- Feature-wise Gating
- Approach
- Gated Convolution
- Spectral-Normalized Markovian Discriminator (SN-PatchGAN)
- Inpainting Network Architecture
- Free-Form Mask Generation
- Extension to User-Guided Image Inpainting
- Results
- 模型速度
- Quantitative Results
- Qualitative Comparisons
- Object Removal and Creative Editing
- object removal
- creative editing
- User Study
- Ablation Study
- Conclusions
论文摘录
效果

Abstract
提出了一种生成式图像绘制系统,利用free-form mask and guidance完成图像。该系统基于从数百万张图像中学习的gated convolutions,而无需额外的标记工作。所提出的门控卷积解决了vanilla convolution (原始普通的神经网络)将所有输入像素视为有效像素的问题,通过为所有层的每个空间位置的每个通道提供可学习的动态特征选择机制来推广部分卷积。此外,由于free-form masks 可能出现在任何形状的图像中的任何位置,因此为单个矩形蒙版设计的全局和局部gan不适用。因此,我们还提出了一种 patch-based GAN loss,称为SNPatchGAN,通过在密集图像补丁上应用频谱归一化鉴别器(spectral-normalized discriminator)。SN-PatchGAN公式简单,训练快速稳定。在自动图像绘制和用户引导扩展方面的实验结果表明,该系统比以前的方法生成的结果质量更高,更灵活。我们的系统可以帮助用户快速删除分散注意力的对象,修改图像布局,清除水印和编辑面孔。
Introduction
Image inpainting (又称 image completion or image hole-filling)是将缺失区域的替代内容综合起来,使修改在视觉上真实、语义上正确的任务。它允许删除分散注意力的物体或修饰照片中不需要的区域。它也可以扩展到任务,包括图像/视频的裁剪,旋转,拼接,重新定位,重新合成,压缩,超分辨率,协调和许多其他。
在计算机视觉中,存在两种广泛的图像绘制方法:使用低级图像特征的补丁匹配和使用深度卷积网络的前馈生成模型。前一种方法[3,8,9]可以合成合理的静止纹理,但在复杂场景、人脸和物体等非静止情况下通常会出现严重失败。后一种方法[15,49,45,46,38,37,48,26,52,33,35,19]可以利用从大规模数据集中学习的语义,以端到端方式合成非平稳图像中的内容。
然而,基于vanilla conv的深度生成模型自然不适合于图像填充,因为空间共享卷积滤波器将所有输入像素或特征视为相同的有效像素或特征。对于填充孔,每层的输入由孔外的有效像素/特征和掩膜区域的无效像素/特征组成。vanilla conv对所有有效的、无效的和混合的(例如,孔边界上的)像素/特征应用相同的过滤器,导致在自由格式掩模上测试时,孔周围的颜色差异、模糊和明显的边缘响应等视觉伪影[15,49]。


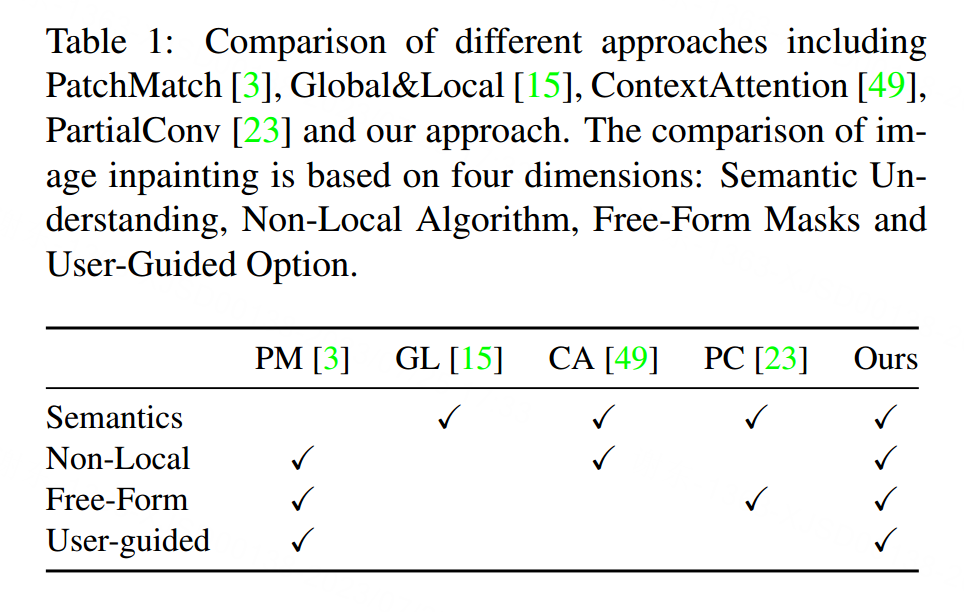
为了解决这一限制,最近提出了partial convolution[23],其中卷积被masked and normalized 为仅以有效像素为条件。然后是一个基于规则的mask-update step来更新下一层的有效位置。Partial convolution将所有输入位置分类为无效或有效,并对所有层的输入乘以0或1掩码。掩码也可以看作是单个不可学习的特征门控通道1。然而,这种假设有一些局限性。
首先,考虑网络的不同层上的输入空间位置,它们可以包括(1)输入图像中的有效像素,(2)输入图像的掩蔽像素,(3)感受野不覆盖输入图像的有效像素的神经元,(4)感受野覆盖输入图像的不同数量的有效像素的神经元(这些有效图像像素也可能具有不同的相对位置),以及(5)深层中的合成像素。启发式地将所有位置分类为无效或有效会忽略这些重要信息。其次,如果我们扩展到用户引导的图像修复,用户在掩模内提供稀疏草图,这些像素位置应该被视为有效还是无效?如何正确更新下一层的遮罩?第三,对于部分卷积,“无效”像素将逐层逐渐消失,基于规则的掩码将是深层中的所有掩码。然而,为了合成空穴中的像素,这些深层可能还需要当前位置是在空穴内部还是外部的信息。具有全一掩码的部分卷积不能提供这样的信息。我们将表明,如果我们允许网络自动学习掩码,则掩码可能具有不同的值,这取决于输入图像中的当前位置是否被掩码,即使在深层中也是如此。

我们提出了用于free-form image inpainting的门控卷积。它学习每个通道和每个空间位置(例如,内部或外部遮罩、RGB通道或用户指导通道)的动态特征门控机制。

在不影响性能的情况下,我们还将训练目标简化为两个术语:逐像素重建损失和对抗性损失(a pixelwise reconstruction loss and an adversarial loss)。

对于实用的图像修复工具来说,启用用户交互至关重要,因为可能存在许多看似合理的解决方案来填补图像中的漏洞。为此,我们提供了一个扩展,允许用户将草图作为引导输入。表1总结了与其他方法的比较。我们的主要贡献如下:(1)我们引入门控卷积,为所有层中每个空间位置的每个通道学习动态特征选择机制,显著提高了自由形式掩模和输入的颜色一致性和修复质量。(2) 我们提出了一种更实用的基于补丁的GAN鉴别器SN-PatchGAN,用于自由形式的图像修复。它简单、快速,并产生高质量的修复结果。(3) 我们将我们的修复模型扩展到交互式模型,使用户能够以草图为指导来获得更多用户想要的修复结果。(4) 我们提出的修复系统在包括Places2自然场景和CelebA HQ人脸在内的基准数据集上实现了比先前技术状态更高质量的自由形式修复。我们展示了所提出的系统可以帮助用户快速去除分散注意力的物体,修改图像布局,清除水印和编辑图像中的人脸。
Related Work
Automatic Image Inpainting
已经提出了多种用于图像修复的方法。传统上,基于补丁的[8,9]算法基于低级特征(例如,RGB空间上的均方差分特征)逐渐扩展接近孔洞边界的像素,以搜索和粘贴最相似的图像补丁。这些算法在静止纹理区域上运行良好,但在非平稳图像上经常失败。此外,Simakov等人提出了双向相似性综合方法[36],以更好地捕捉和总结非平稳视觉数据。为了降低搜索过程中的高内存和计算成本,提出了基于树的内存加速结构[25]和随机算法[3]。此外,通过匹配局部特征,如图像梯度[2,5]和相似补丁的偏移统计[11],可以改善修复结果。最近,提出了基于深度学习的图像修复系统来直接预测掩模内的像素值。这是一个显著的优势。Yu等人[49]通过采用堆叠生成网络,提出了一种端到端的图像修复模型,以进一步确保生成区域与周围环境的颜色和纹理一致性。此外,为了捕捉长程空间依赖性,提出了上下文注意力模块[49],并将其集成到网络中,以明确地从遥远的空间位置借用信息。然而,这种方法主要在大型矩形掩模上训练,而在自由形式掩模上不能很好地推广。为了更好地处理不规则掩码,提出了部分卷积[23],其中卷积被掩码并重新归一化以仅利用有效像素。是基于规则的掩模更新步骤,以逐层重新计算新的掩模。
Guided Image Inpainting and Synthesis
为了改进图像修复,探索了user guidance,包括点或线[1,3,7,40]、结构[13]、变换或失真信息[14,30]和图像示例[4,10,20,43,51]。值得注意的是,Hays和Efros[10]首先利用数百万张照片作为数据库来搜索与输入最相似的示例图像,然后通过从匹配的图像中剪切和粘贴相应的区域来完成图像。
条件生成网络的最新进展使用户能够从大规模数据集中学习图像处理、合成和操作。在这里,我们选择性地回顾了几项相关工作。张等人[50]提出了可以将用户指导作为额外输入的彩色化网络。王等人[42]提出使用条件生成对抗性网络从语义标签图合成高分辨率照片真实感图像。Scribbler[34]探索了一个基于草图边界和稀疏颜色笔划的深层生成网络,以合成汽车、卧室或人脸。
Feature-wise Gating
Feature-wise Gating在视觉[12,28,39,41]、语言[6]、语音[27]和许多其他任务中得到了广泛的探索。例如,Highway Networks[39]利用特征门控来简化非常深度网络的基于梯度的训练。挤压和激励网络通过将每个通道与学习的S形门控值显式相乘来重新校准特征响应。WaveNets[27]通过采用特殊特征门控y=tanh(w1x)·sigmoid(w2x)对音频信号进行建模,获得了更好的结果。
Approach
在本节中,我们将自下而上地介绍我们的方法。我们首先介绍了门控卷积SN PatchGAN的细节,然后在图3中介绍了修复网络的概述以及我们的扩展,以允许可选的用户指导。
Gated Convolution
vanilla convolutions 在free-form image inpainting 中不适用,所以才提出了partial convolution。
![我们首先解释了为什么[15,49]中使用的香草卷积不适合自由形式的图像修复任务。我们考虑一个卷积层,其中一组滤波器被应用于输入特征图作为输出。假设输入是C−通道,位于C 0-通道输出图中(y,x)处的每个像素计算为](https://img-blog.csdnimg.cn/6bbc1eabc5284ca7a85ecd60cef584a3.png)


Partial convolution[23]提高了不规则掩模的补图质量,但仍存在以下问题:(1)启发式地对所有空间位置进行有效或无效的分类。下一层的遮罩将被设置为1,无论前一层的过滤范围覆盖了多少像素(例如,1个有效像素和9个有效像素被视为相同以更新当前遮罩)。(2)与附加用户输入不兼容。我们的目标是一个用户引导的图像绘制系统,在这个系统中,用户可以选择在遮罩内提供稀疏的草图作为条件通道。在这种情况下,这些像素位置是有效的还是无效的?如何正确更新下一层的蒙版?(3)对于部分卷积,无效像素将在深层逐渐消失,逐渐将所有掩码值转换为1。然而,我们的研究表明,如果我们允许网络自动学习最优掩码,即使在深层中,网络也会为每个空间位置分配软掩码值。(4)每一层的所有通道共用同一个掩码,限制了灵活性。从本质上讲,部分卷积可以看作是不可学习的单通道特征硬门控。
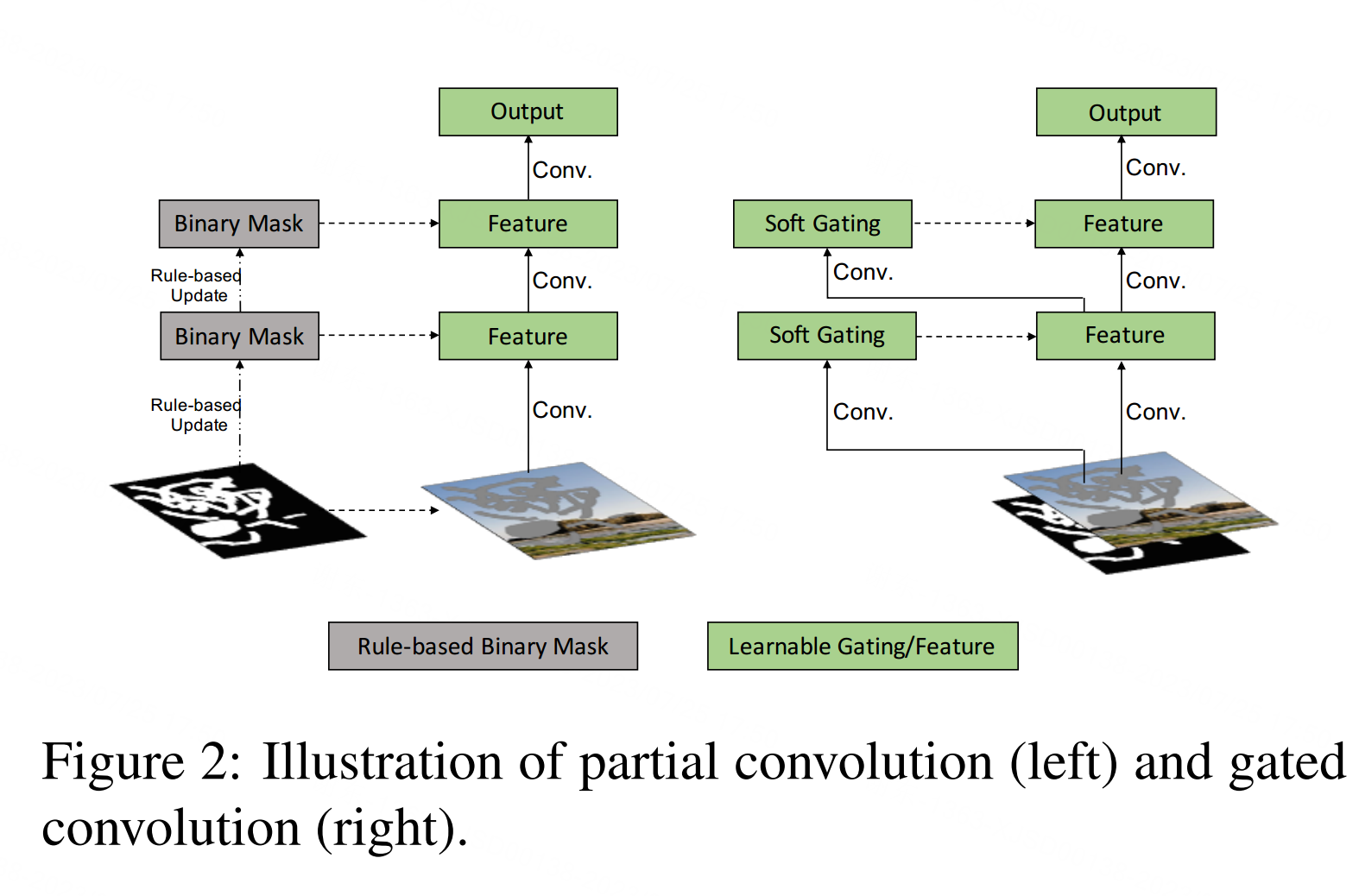
我们提出了一种门控卷积图像补绘网络,如图2所示。不是硬mask,门控卷积从数据中自动学习软掩码。其公式为:

所提出的门控卷积学习每个通道和每个空间位置的动态特征选择机制。有趣的是,中间门值的可视化表明,它不仅可以根据背景,掩码,草图学习选择特征,而且还可以考虑某些通道的语义分割。即使在较深的图层中,门控卷积也学习在单独的通道中突出显示遮罩区域和草图信息,以更好地生成绘图结果。
Spectral-Normalized Markovian Discriminator (SN-PatchGAN)
对于之前尝试填充单个矩形孔的补图网络,在被遮挡的矩形区域上使用额外的局部GAN来改善结果[15,49]。
然而,我们考虑的任务是自由形式的图像绘制,其中在任何位置可能有多个任意形状的孔。受全局和局部GAN[15]、MarkovianGANs[16,21]、感知损失[17]和最近对频谱归一化GAN[24]的研究的启发,我们提出了一种简单有效的GAN损失算法,即n - patchgan,用于训练自由形式的图像。鉴别器采用卷积网络,输入由图像、掩模和引导通道组成,输出为形状为R h×w×c的三维特征(h、w、c分别表示通道的高度、宽度和数量)。如图3所示,内核大小为5、步幅为2的6个跨步卷积被堆叠为捕获马尔可夫补丁的特征统计[21]。然后,我们直接对该特征图中的每个特征元素应用gan,针对输入图像的不同位置和不同语义(在不同通道中表示),形成h × w × c个数的gan。值得注意的是,在我们的训练设置中,输出映射中每个神经元的接受野可以覆盖整个输入图像,因此不需要全局鉴别器。

使用SN-PatchGAN,我们的inpainting网络训练速度比基线模型更快,更稳定[49]。不使用感知损失,因为在SN-PatchGAN中已经编码了类似的补丁级信息。与PartialConv[23]相比,其中6种不同的损失项和平衡项使用超参数时,我们的最终目标函数仅由逐像素的L1重建损失和SN-PatchGAN损失组成,默认损失平衡超参数为1:1。
Inpainting Network Architecture
我们使用所提出的门控卷积和SN-PatchGAN损失定制了一个生成式图像网络[49]。具体来说,我们采用了[49]中的完整模型架构,包括粗网络和精化网络。完整的框架如图3所示。
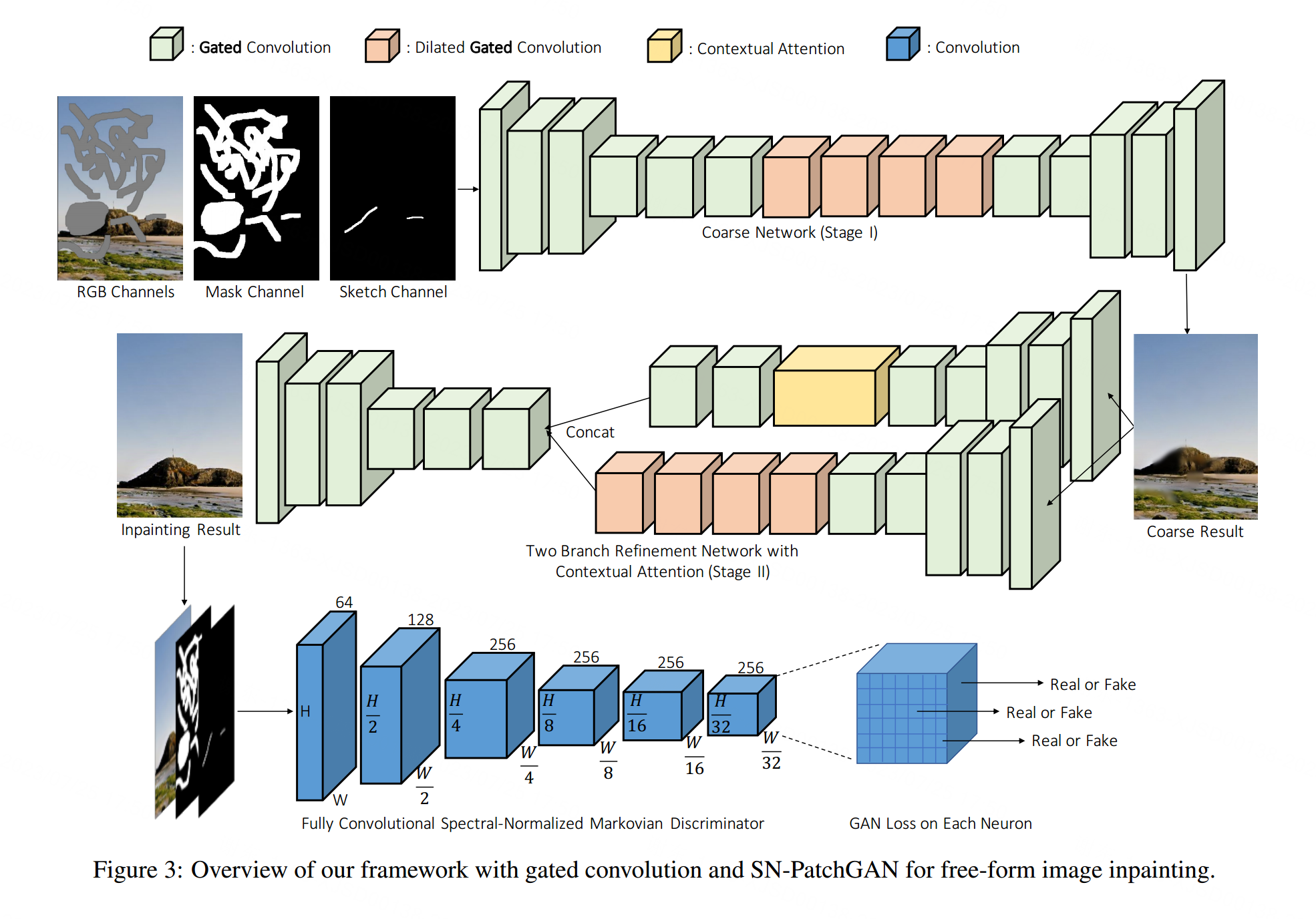
对于粗网络和精化网络,我们使用一个简单的编码器-解码器网络[49],而不是PartialConv[23]中使用的U-Net。我们发现UNet中的跳过连接[31]对非窄掩码没有显著影响。
这主要是因为对于掩蔽区域的中心,这些跳过连接的输入几乎为零,因此无法将详细的颜色或纹理信息传播到该区域的解码器。对于孔边界,我们的编解码器架构配备了门控卷积,足以产生无缝的结果。
我们用门控卷积代替所有的普通卷积[49]。一个潜在的问题是门控卷积引入其他参数。为了保持与基线模型相同的效率[49],我们将模型宽度缩小了25%,并且在数量和质量上都没有发现明显的性能下降。inpainting 网络是端到端训练的,可以在任意位置的自由孔上进行测试。我们的网络是完全卷积的,在推理中支持不同的输入分辨率。
Free-Form Mask Generation
自动生成自由格式掩码的算法非常重要。采样的掩码本质上应该(1)与实际用例中绘制的掩码相似,(2)多样化以避免过度拟合,(3)计算和存储效率高,(4)可控和灵活。先前的方法[23]从两个连续视频帧之间的遮挡估计方法中收集一组固定的不规则遮罩。虽然增加了随机扩张、轮作和种植来增加其多样性,但该方法不满足上述其他要求。
我们介绍了一种简单的算法,在训练过程中自动生成随机的自由格式蒙版。对于填充孔的任务,用户的行为就像使用橡皮擦来回刷,以掩盖不需要的区域。这种行为可以通过重复绘制线条和旋转角度的随机算法简单地模拟。为了保证两条线的平整度,我们还在两条线的连接处画了一个圆。由于篇幅限制,更多的细节在补充材料中。
Extension to User-Guided Image Inpainting
我们以草图为例,将我们的图像绘制网络扩展为一个用户引导系统。草图(或边缘)是简单和直观的用户绘制。我们用人脸和自然场景来展示这两种情况。对于人脸,我们提取地标并连接相关地标。对于自然场景图像,我们直接使用HED边缘检测器提取边缘地图[44],并将高于某一阈值(即0.6)的所有值设置为1。由于篇幅限制,在补充材料中给出了示例草图。
为了在绘画系统中训练用户引导的图像,直观地,我们需要额外的约束损失来强制网络生成以用户引导为条件的结果。然而,通过像素级重构损失和GAN损失的相同组合(将条件通道作为判别器的输入),我们能够学习条件生成网络,其中生成的结果忠实地尊重用户指导。我们还尝试在HED[44]输出特征上使用额外的像素级损失,将原始图像或生成的结果作为输入来执行约束,但绘制质量是相似的。使用5通道输入(R、G、B颜色通道、掩模通道和草图通道)单独训练用户引导的inpainting模型。
Results
模型速度
我们在Places2[53]和CelebA-HQ面部[18]上评估了所提出的自由形式图像绘制系统。我们的模型共有4.1万个参数,使用TensorFlow v1.8, CUDNN v7.0, CUDA v9.0进行训练。在测试中,它在单个NVIDIA® Tesla® V100 GPU上运行每张图像0.21秒,在Intel® Xeon® CPU @ 2.00GHz上运行每张图像平均1.9秒,分辨率为512 × 512,无论孔大小如何。
Quantitative Results
如文献[49]所述,图像补绘缺乏良好的定量评价指标。尽管如此,我们在表2中报告了我们对Places2验证图像的平均误差1和平均误差2的评估结果,其中包括中心矩形掩码和自由格式掩码。如表所示,基于学习的方法在平均“1”和“2”误差方面优于PatchMatch[3]。此外,在同一框架内实现的部分卷积得到较差的性能,这可能是由于不可学习的基于规则的门控。

Qualitative Comparisons
接下来,我们将我们的模型与之前最先进的方法[15,23,49]进行比较。图4和图5显示了带有几个代表性图像的自动和用户引导的绘图结果。对于自动图像绘制,PartialConv的结果是通过其在线演示得到的2。对于用户引导的图像绘制,我们使用与GatedConv完全相同的设置训练PartialConv*,除了卷积类型(草图区域被视为基于规则的掩码更新的有效像素)。对于所有基于学习的方法,都不执行后处理步骤以确保公平性。

据文献[15]报道,简单均匀区域(图4和图5的最后一行)是基于学习的图像在绘画网络中的难点。以前的普通卷积方法在孔内/周围有明显的视觉伪影和边缘响应。PartialConv产生更好的结果,但仍然表现出可观察到的颜色差异。
我们基于门控卷积的方法获得了更令人赏心悦目的视觉效果,并且没有明显的颜色不一致。
在图5中,给定稀疏的草图,我们的方法产生了具有无缝边界转换的逼真结果。

PS. 哈哈哈哈,很有意思,PConv论文的确说GL需要后处理,而DeepFillv1也没处理好,大佬这做出了DeepFillv2,直接说你PConv没做好,我这次是做好了。
Object Removal and Creative Editing
此外,我们研究了图像绘画的两个重要的实际用例:对象去除和创造性编辑(object removal and creative editing)。
object removal
在第一个示例中,我们试图移除图6中分散注意力的人。我们将我们的方法与商业产品Photoshop(基于PatchMatch[3])和之前最先进的生成绘画网络(在Places2上训练的官方发布模型)[49]进行了比较。结果表明,Photoshop的Content-Aware填充功能错误地从左边复制了一半的脸。这个例子反映了这样一个事实,即没有从大规模数据中学习的传统方法忽略了图像的语义,这导致在非平稳/复杂场景中出现严重故障。对于使用vanilla卷积的基于学习的方法[49],伪影存在于孔边界附近。

creative editing
接下来,我们将研究用户与绘图系统交互以产生更理想结果的情况。人脸和自然场景的示例如图7所示。我们的绘制结果很好地遵循用户草图。

User Study
我们进行了一项用户研究,首先从Places2验证数据集中收集了30张测试图像(有洞但没有草图),而不知道它们在每个模型上的涂漆结果。然后我们计算了以下四种方法的结果进行比较:(1)ground truth,(2)我们的模型,(3)在同一框架内重新实现的PartialConv[23],以及(4)官方的PartialConv[23]。我们做了两种类型的用户研究。(A)我们单独评估每种方法以评估结果的自然度/油漆质量(从1到10,越高越好),(B)我们比较我们的模型和官方的PartialConv模型,以评估哪种方法产生更好的结果。104名用户完成了用户研究,结果如下:
(A) Naturalness: (1) 9.89, (2) 7.72, (3) 7.07, (4) 6.54
(B) Pairwise comparison of (2) our model vs. (4) official PartialConv model: 79.4% vs. 20.6% (the higher the better).
Ablation Study
提出SN-PatchGAN的原因是自由格式蒙版可能出现在任何形状的图像中的任何位置。先前介绍的针对单个矩形掩模设计的全局gan和局部gan[15]不适用。我们在图8中提供了SN-PatchGAN在图像修复背景下的消融实验。SN-PatchGAN的结果明显更好,这验证了(1)单一全局鉴别器的性能较差[15],(2)谱归一化的GAN具有更好的稳定性和性能[24]。虽然引入更多的损失函数可能有助于训练自由形式的图像补图网络[23],但我们证明了SN-PatchGAN损失和像素级L1损失的简单组合,默认损失平衡超参数为1:1,可以产生逼真的补图结果。在补充资料中给出了更多的比较实例。

Conclusions
我们提出了一种基于端到端门控卷积生成网络的新型自由形式图像绘制系统,该系统使用逐像素的L1损失和SN-PatchGAN进行训练。
我们证明了门控卷积显著改善了自由格式蒙版和用户指导输入的图像绘制结果。我们展示了用户草图作为示例指导,以帮助用户快速删除分散注意力的对象,修改图像布局,清除水印,编辑面部和交互式地创建照片中的新对象。定量结果、定性比较和用户研究证明了我们提出的自由形式图像绘制系统的优越性。
相关文章:
【深度学习】【Image Inpainting】Free-Form Image Inpainting with Gated Convolution
模型:DeepFillv2 (CVPR’2019) 论文:https://arxiv.org/abs/1806.03589 代码:https://github.com/JiahuiYu/generative_inpainting 文章目录 效果AbstractIntroductionRelated WorkAutomatic Image InpaintingGuided Image Inpainting and Sy…...
游戏引擎UE如何革新影视行业?创意云全面支持UE云渲染
虚幻引擎UE(Unreal Engine)作为一款“殿堂级”的游戏引擎,占据了全球80%的商用游戏引擎市场,但如果仅仅将其当做游戏开发的工具,显然是低估了它的能力。比如迪士尼出品的电视剧《曼达洛人》、电影《狮子王》等等都使用…...
DB-GPT:强强联合Langchain-Vicuna的应用实战开源项目,彻底改变与数据库的交互方式
今天看到 蚂蚁科技 Magic 开源的DB-GPT项目,觉得创意很好,集成了当前LLM的主流技术,主要如下 Langchain: 构建在LLM之上的应用开发框架HuggingFace: 模型标准,提供大模型管理功能Vicuna: 一个令GPT-4惊艳的开源聊天机…...

STM32CubeMX v6.9.0 BUG:FLASH_LATENCY设置错误导致初始化失败
背景 今天在调试外设功能时,发现设置了使用外部时钟之后程序运行异常,进行追踪调试并与先前可以正常运行的项目进行对比之后发现这个问题可能是由于新版本的STM32CubeMX配置生成代码时的BUG引起的。 测试环境 MCU: STM32H750VBT6 STM32CubeIDE: Versi…...
K8s-资源管理(二)
文章目录 2. 资源管理2.1 资源管理介绍2.2 YAML语言介绍2.3 资源管理方式2.3.1 命令式对象管理2.3.2 命令式对象配置2.3.3 声明式对象配置 2.4. 模拟使用普通用户来操作2.5 kubectl 一些基本命令2.6 使用个人的 docker 仓库的镜像 2. 资源管理 2.1 资源管理介绍 在kubernetes…...
脉冲信号测试应如何选择示波器带宽?
示波器模拟带宽的定义大家都比较熟悉,是针对于正弦波信号定义的。从频域上看,正弦波信号的频谱就是单根谱线,只要示波器的带宽不小于信号的频率,那么就可以有效观测到波形。若要追求更高的幅度测试精度,则可以按照5倍法…...

OpenCV DNN模块推理YOLOv5 ONNX模型方法
文章目录 概述1. 环境部署YOLOv5算法ONNX模型获取opencv-python模块安装 2.关键代码2.1 模型加载2.2 图片数据预处理2.3 模型推理2.4 推理结果后处理2.4.1 NMS2.4.2 score_threshold过滤2.4.3 bbox坐标转换与还原 3. 示例代码(可运行)3.1 未封装3.2 封装成类调用 概述 本文档主…...
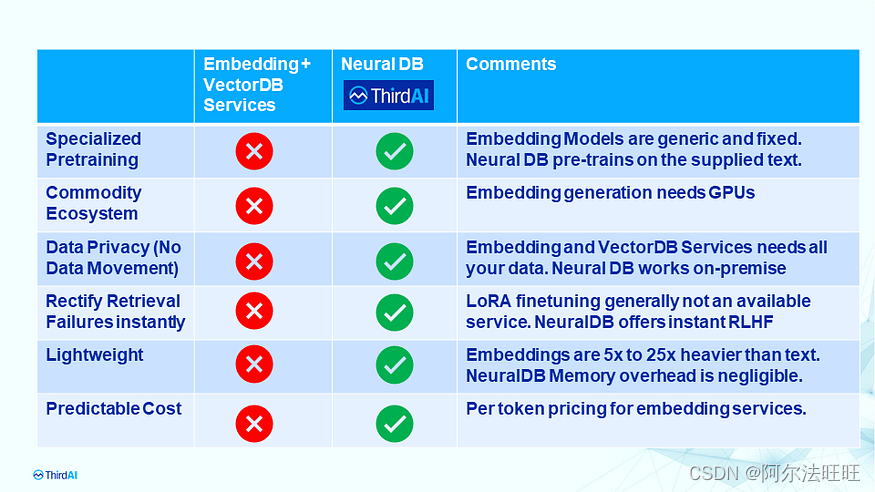
ThirdAI 的私有和可个性化神经数据库:增强检索增强生成(第 3/3 部分)
这是我们关于使用检索增强生成构建 AI 代理的系列的最后一章 (3/3)。在第 1/3 部分中,我们讨论了断开连接的嵌入和基于矢量的检索管道的局限性。在第 2/3 部分中,我们介绍了神经数据库,它消除了存储和操作繁重且昂贵的…...

C# 解决TCP Server 关不掉客户端连接的问题
问题描述 拷贝了一段 TCP Server的应用代码,第一次运行正常,但是关闭软件或者实现disconnectclose后都无法关闭端口连接。 关闭之后,另外一个客户端还在正常与PC连接。 TCP Server 重新运行,无法接收到客户端的连接。 复现环境…...
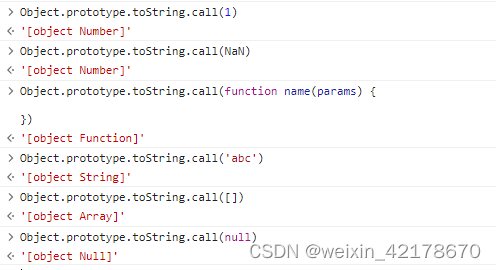
JS判断类型的方法和对应的局限性(typeof、instanceof和Object.prototype.toString.call()的用法)
JS判断类型的方法和对应的局限性(typeof、instanceof和Object.prototype.toString.call()的用法) 一、typeof 返回: 该方法返回小写字符串表示检测数据属于什么类型,例如: 检测函数返回function 可判断的数据类型:…...

mongostat跟踪Mongodb运行的状态
版本控制 从 MongoDB 4.4 开始,mongostat 现在与 MongoDB 服务器分开发布,并使用自己的版本控制,初始版本为100.0.0. 之前, mongostat 与 MongoDB Server 一起发布并使用匹配的版本控制。 兼容性 mongostat 版本100.7.3支持以下…...
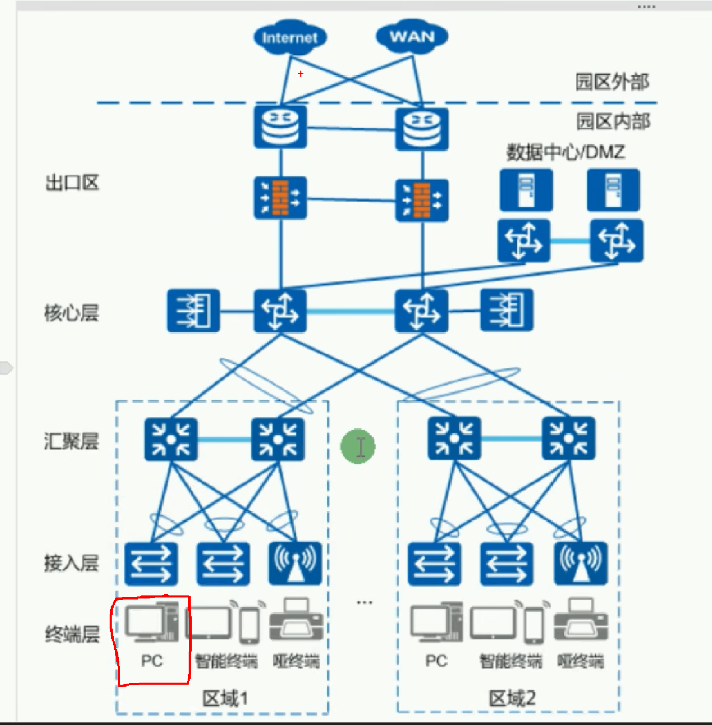
华为数通HCIA-数通网络基础
基础概念 通信:两个实体之间进行信息交流 数据通信:网络设备之间进行的通信 计算机网络:实现网络设备之间进行数据通信的媒介 园区网络(企业网络)/私网/内网:用于实现园区内部互通,并且需要部…...
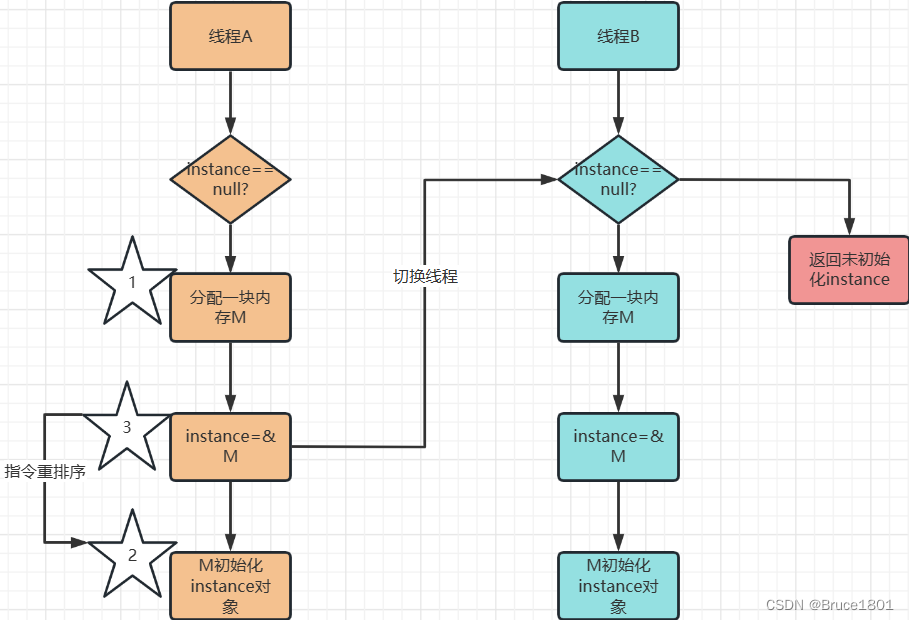
【设计模式】详解单例设计模式(包含并发、JVM)
文章目录 1、背景2、单例模式3、代码实现1、第一种实现(饿汉式)为什么属性都是static的?2、第二种实现(懒汉式,线程不安全)3、第三种实现(懒汉式,线程安全)4、第四种实现…...
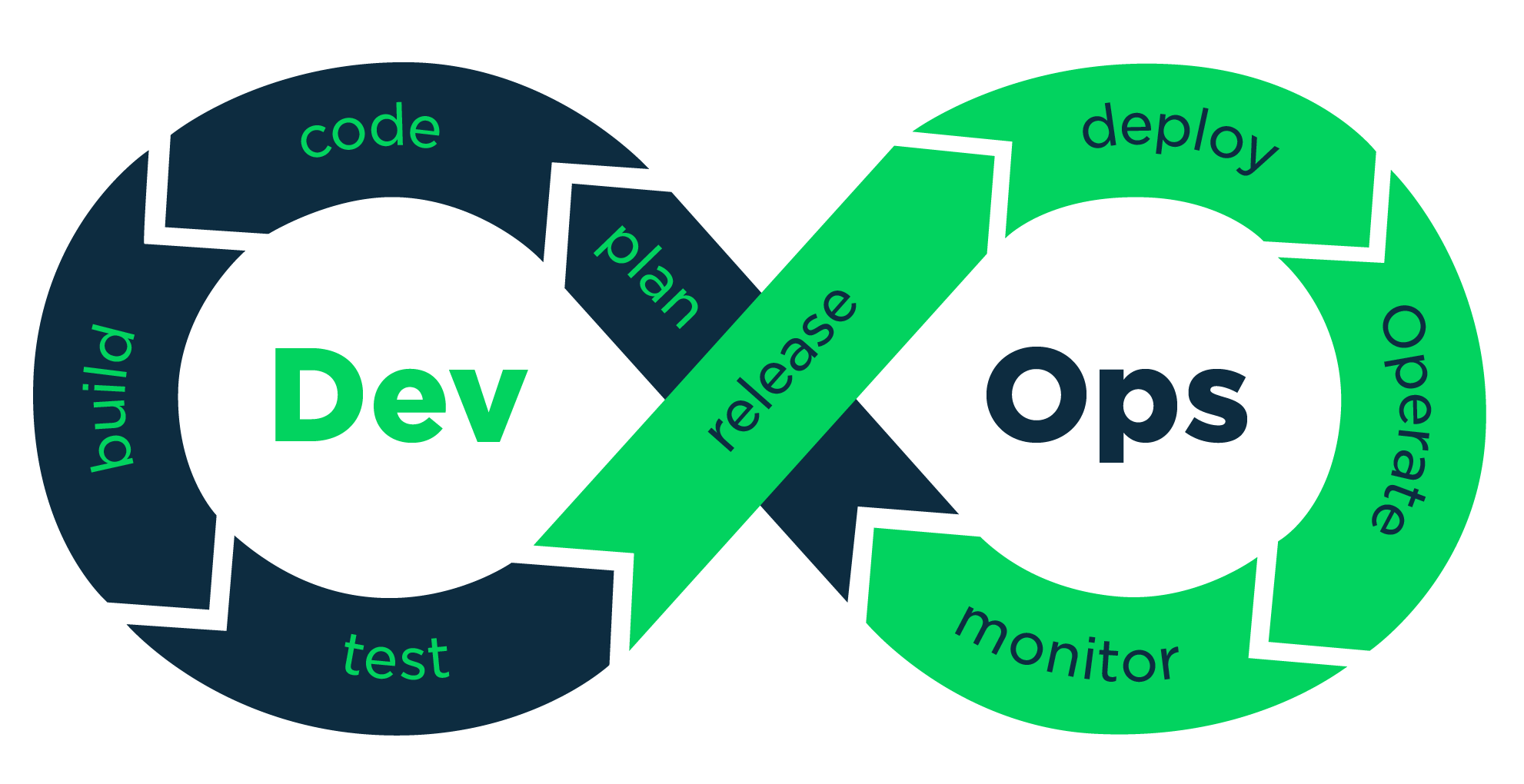
监控和可观察性在 DevOps 中的作用!
在不断发展的DevOps世界中,深入了解系统行为、诊断问题和提高整体性能的能力是首要任务之一。监控和可观察性是促进这一过程的两个关键概念,为系统的健康状况和性能提供有价值的可见性。虽然这些术语经常互换使用,但它们代表了理解和管理复杂…...
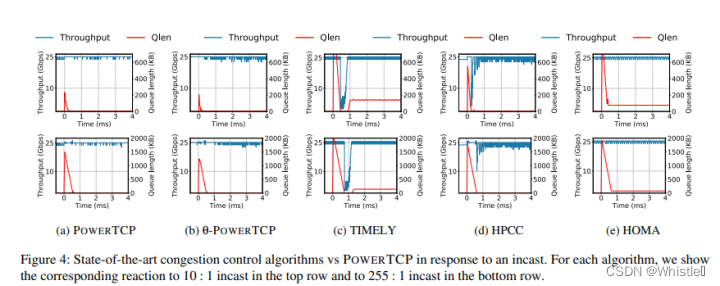
论文分享:PowerTCP: Pushing the Performance Limits of Datacenter Networks
1 原论文的题目(中英文)、题目中包含了哪些关键词?这些关键词的相关知识分别是什么? 题目:PowerTCP: Pushing the Performance Limits of Datacenter Networks PowerTCP:逼近数据中心的网络性能极限 2 论…...
浏览器的同源策略 - 跨域问题
1.什么是跨域 跨域问题的实质是浏览器的同源策略造成的。浏览器同源策略是浏览器为 JavaScript 施加的限制。简单点说就是非同源会出现如下等限制: 无法访问其他源下的网页的 Cookies,Storage等;无法访问其他源下的DOM对象和 JS 对象;无法使…...
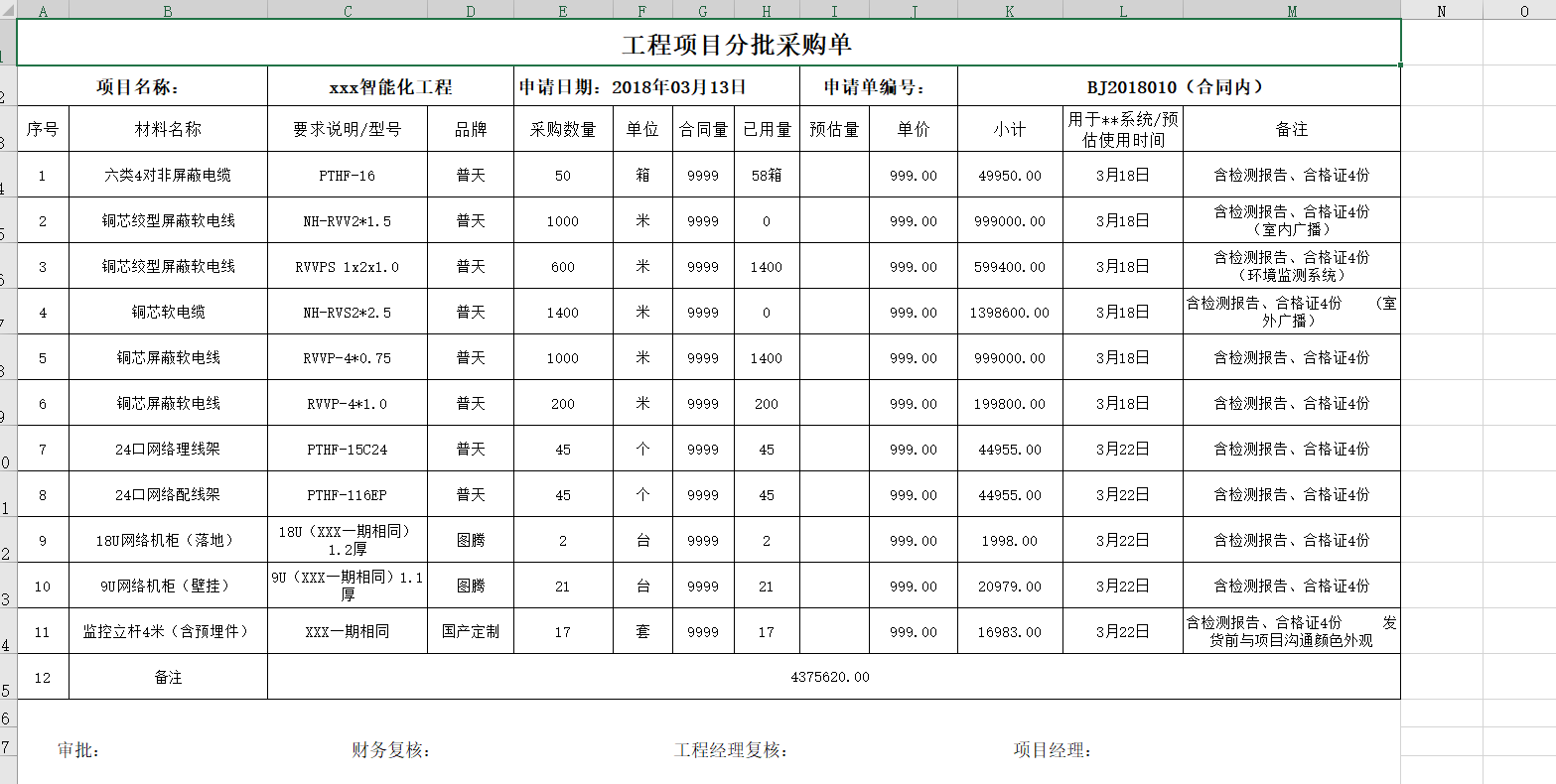
go 查询采购单设备事项[小示例]V2-两种模式{严格,包含模式}
第一版: https://mp.csdn.net/mp_blog/creation/editor/131979385 第二版: 优化内容: 检索数据的两种方式: 1.严格模式--找寻名称是一模一样的内容,在上一个版本实现了 2.包含模式,也就是我输入检索关…...

c++11 标准模板(STL)(std::basic_filebuf)(八)
定义于头文件 <fstream> template< class CharT, class Traits std::char_traits<CharT> > class basic_filebuf : public std::basic_streambuf<CharT, Traits> std::basic_filebuf 是关联字符序列为文件的 std::basic_streambuf 。输入序…...

行为型模式之解释器模式
解释器模式(Interpreter Pattern) 解释器模式(Interpreter Pattern)是一种行为设计模式,它用于对语言的文法进行解释和解析,以实现特定的操作。 在解释器模式中,存在以下几个角色: 抽…...

阿里云域名备案
最好的爱情,不是因为我们彼此需要在一起,而是因为我们彼此想要在一起。 阿里云的域名如何备案,域名备案和ICP备案一样吗?? 截至我所掌握的知识(2021年9月),阿里云的域名备案和ICP备案…...

从分立逻辑到单片机:基于ATmega8的MIDI通道分析仪设计与实现
1. 项目概述:从分立逻辑到单片机的MIDI通道分析仪进化史二十年前,当我在《Elektor》杂志上发表第一版MIDI通道分析仪时,整个数字音乐世界还处于一个相当“硬核”的阶段。那个版本的设计,用今天的话来说,简直就是一场“…...

森优时铁锌维发根养黑用三个月真实效果实测:内服营养养黑的客观测评
"森优时铁锌维发根养黑用三个月真实效果实测显示,针对压力、熬夜引发的早白问题,通过内服补充毛囊所需营养的方式,多数使用者能感受到发根韧性提升、新生发色素沉淀改善,整体改善效果因人而异,合规的营养补充是目…...

【DeepSeek开源协议识别权威指南】:20年合规专家亲授3大协议陷阱与5步精准识别法
更多请点击: https://intelliparadigm.com 第一章:DeepSeek开源协议识别的底层逻辑与合规价值 DeepSeek系列模型(如DeepSeek-V2、DeepSeek-Coder)虽以“开源”名义发布,但其实际许可状态需通过结构化协议解析才能准确…...

3分钟告别英文恐惧:Android Studio中文界面轻松切换指南
3分钟告别英文恐惧:Android Studio中文界面轻松切换指南 【免费下载链接】AndroidStudioChineseLanguagePack AndroidStudio中文插件(官方修改版本) 项目地址: https://gitcode.com/gh_mirrors/an/AndroidStudioChineseLanguagePack 你是否曾经因…...

5分钟掌握AutoClicker:Windows鼠标点击自动化的终极指南
5分钟掌握AutoClicker:Windows鼠标点击自动化的终极指南 【免费下载链接】AutoClicker AutoClicker is a useful simple tool for automating mouse clicks. 项目地址: https://gitcode.com/gh_mirrors/au/AutoClicker AutoClicker是一款专为Windows设计的鼠…...
:openclaw agent 如何触发一次 Agent 运行?)
OpenClaw 源码解析(六):openclaw agent 如何触发一次 Agent 运行?
1. 本期要解决的问题 前几期我们已经从项目整体结构、CLI 命令体系、配置加载、Gateway 运行机制等角度理解了 OpenClaw 的基础框架。到了这一期,可以进一步进入 OpenClaw 最核心的使用动作:用户在终端中执行一条 openclaw agent --message "...&q…...

MFCC与可解释机器学习:构建可解释的L2发音AI诊断系统
1. 项目概述:当语音技术遇见二语教学 作为一名在语音技术和教育技术交叉领域摸爬滚打了十多年的从业者,我常常思考一个问题:我们能用算法“听”出一个人说外语时,他的母语口音吗?更进一步,我们能否不仅“听…...

在ubuntu上为node.js后端服务接入taotoken统一大模型api
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在 Ubuntu 上为 Node.js 后端服务接入 Taotoken 统一大模型 API 为后端服务集成大模型能力已成为提升应用智能水平的关键步骤。对于…...

为内部知识库问答系统集成多模型后备路由以提升服务韧性
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为内部知识库问答系统集成多模型后备路由以提升服务韧性 对于依赖大模型提供智能问答服务的企业内部知识库而言,服务的…...

Win11Debloat:如何用自动化配置工具实现Windows系统的智能优化
Win11Debloat:如何用自动化配置工具实现Windows系统的智能优化 【免费下载链接】Win11Debloat A simple, lightweight PowerShell script that allows you to remove pre-installed apps, disable telemetry, as well as perform various other changes to declutte…...