Mysql原理篇--第二章 索引
文章目录
- 前言
- 一、mysql的索引是什么?
- 1.1 索引的结构:
- 1.2 b+树特性:
- 1.3 b+树每个节点的结构:
- 1.4 b+树 键值的大小排序:
- 1.4 b+树 存储(InnoDB):
- 二、索引类型
- 2.1 主要的索引类型:
- 2.2 聚集索引和非聚集索引:
- 2.3 复合索引:
- 2.3.1 复合索引说明:
- 2.3.2 复合索引最左匹配:
- 2.4 前缀索引:
- 2.4.1 前缀索引说明和设置:
- 2.4.2 否会得到与查询条件不相同的数据:
- 2.4.3 前缀索引长度的设置:
- 2.5 索引的回表:
- 2.5.1 为什么会产生回表:
- 2.5.2 非聚集索引叶子节点为什么不存整条数据内容:
- 2.6 索引下推(Index Condition Pushdown):
- 2.7 多个索引怎么协同工作:
- 2.8 适合做索引的列:
- 三、索引失效的场景
- 总结
- 参考
前言
在使用Mysql时 当表中数据量增加,需要对表中的列建立索引以增加检索速度,那么Mysql 中的索引究竟是什么,它为什么能增加检索速度,索引都有哪些类型,我们应该为哪些列创建索引,索引的失效场景有哪些,本文进行探究。
一、mysql的索引是什么?
1.1 索引的结构:
mysql 的索引本质上是一棵b+ 树,其实一个索引就对应一棵b+ 树;当进行查询的时候,可以通过查询的字段,遍历这颗b+树找到需要需要的数据,从而避免扫描对比表中的所有该列数据,要检索的数据少了,那么io就不需要那么多次,对cpu和内存的消耗就少,检索效率就会提高;
1.2 b+树特性:
- 所有叶子节点中包含了全部键值的信息,且叶子节点本身依键值大小从小到大顺序链接。
- 所有非叶子节点可以看成是索引部分,节点中的键值是为了引导搜索方向。
1.3 b+树每个节点的结构:
在B+树索引中,一个节点主要包含以下几个部分:
- 键值:键值是用于对数据进行排序和查询的关键字,存储在节点中。在非叶子节点,键值用于指导搜索方向;在叶子节点,键值就是实际的索引值。
- 指针:指针用于指向其他节点。在非叶子节点,指针指向键值对应的子节点;在叶子节点,指针指向数据记录或者指向下一个叶子节点。
所以对于B+树索引的一个节点来说,如果我们将其看做一个结构体,那么其基本结构可以简化为:
struct BTreeNode {int keys[m]; // 键值数组struct BTreeNode *children[m+1]; // 孩子节点指针数组struct Record *records[m]; // 只在叶子节点中使用,记录指针数组,指向具体的数据记录struct BTreeNode *next; // 只在叶子节点中使用,指向下一个叶子节点 链表结构
};
这里m代表了B+树的阶数(最多含有的子树个数)或者说是分支因子(每个节点最多含有的键的个数)。这个结构是理论上的B+树节点的主要组成部分。在实际的数据库系统中,B+树的实现会更为复杂,会有更多的控制信息,比如节点类型(根节点、内部节点或叶子节点)、键值数量、父节点指针等。
1.4 b+树 键值的大小排序:
MySQL在比较B+树索引的键值时,会根据字段的数据类型使用相应的比较规则。
-
数值类型对于整数、实数这样的数值类型,MySQL直接比较其数值大小。
-
字符串类型:对于char、varchar、text这样的字符串类型,MySQL通常进行字典排序(dictionary order)。这种比较方式会考虑字符的字节编码值,而且通常是区分大小写的。具体的比较方式也会受到字符集和排序规则(collation)的影响。
-
日期时间类型:对于date、datetime、timestamp这样的日期时间类型,MySQL会转换成对应的内部格式进行比较。日期时间类型的内部格式设计成了可以直接进行数值比较的。
-
枚举和集合类型:对于enum和set这样的类型,MySQL会将其转换为数值或字符串进行比较。
-
二进制类型:对于binary、varbinary、blob这样的二进制类型,MySQL会按照二进制值进行比较。
1.4 b+树 存储(InnoDB):
InnoDB存储引擎以Index page(索引页)为存储单位,每个索引页的大小默认为16KB。
索引的节点(包括根节点、中间节点、叶子结点)都存储在索引页中。每个索引节点会有自己的节点头信息,如记录类型、记录头信息、事务ID、回滚指针和真正的行记录等等。
对于B+树索引,非叶子节点存储的是键值+子节点的指针,叶子节点存储的是键值+行数据。如果是主键索引(聚集索引),那么叶子节点直接存储整行数据。如果是非主键索引(第二索引),叶子节点存储的行数据实际上是主键的值。
每个索引页按照上述结构进行组织,通过一个页目录来快速定位和访问记录。页与页之间通过双向链表连在一起,保证了范围查找示可以按页顺序进行读取,提高效率。
二、索引类型
2.1 主要的索引类型:
-
B+树索引:MySQL默认的索引类型,适用于全值匹配和范围查询。B+树索引有聚集索引(主键索引)和非聚集索引(二级索引)之分。
-
哈希索引:根据哈希函数对键值计算出一个哈希值,通过哈希值进行查询。哈希索引只支持等值查询,不支持范围查询。MySQL的内存型存储引擎MEMORY可以使用哈希索引。
-
空间索引:用于对地理空间数据进行索引,比如经纬度。MySQL的MyISAM存储引擎和InnoDB存储引擎支持空间索引。
-
全文索引:用于对文本内容进行索引,提供了对全文内容进行搜索的功能。MySQL的MyISAM存储引擎在很早就支持全文索引,InnoDB存储引擎在5.6版本后开始支持全文索引。
-
索引组合/复合索引:针对多个字段同时创建一个索引。在查询时,可以用来优化对多个字段的组合查询。
-
唯一索引:索引列的值必须唯一,但允许有空值。
-
主键索引:是一种特殊的唯一索引,不允许有空值。一个表只能有一个主键。
2.2 聚集索引和非聚集索引:
(1) 存储内容上的区别:
- 聚集索引:在聚集索引的叶子节点中直接
包含了数据行的内容。也就是说,一棵聚集索引树可以完整的获取表中的所有内容,因此一个表只能有一个聚集索引。 - 非聚集索引:非聚簇索引的叶子节点并不包含数据行的全部内容,而是
存储了对应行数据在聚集索引中的键值(一般是主键)。当数据库根据非聚集索引查找数据时在非聚集索引中找到对应主键值后,再在聚沼索引中查找对应的数据行,这个过程通常叫做"回表"。
(2) 存储方式的区别:
- 聚集索引:
聚集索引将数据行的存储和索引放在一起,数据行的存储顺序与键值在索引树中的逻辑顺序一致,所以适合查找范围数据和排序。 - 非聚簇索引:
非聚簇索引与数据行存储分离,优点是在进行全表扫描的时候可以跳过那些不需要的数据,提高检索效率。
(3) 性能上的区别:
- 聚集索引:因为索引和数据存储在一起,故而
查找速度通常较快,尤其对于基于主键的查找和范围查找。 - 非聚簇索引:通常
需要额外的一次查询(即回表),因此查询性能通常不如聚集索引。但是,非聚簇索引在某些场景下可能会更高效,比如查询只需要使用非聚簇索引即可获取的列时。
2.3 复合索引:
2.3.1 复合索引说明:
复合索引,也被称为联合索引或者多列索引,是指基于表中两个或两个以上的列创建的索引。复合索引的顺序很重要,因为MySQL只能高效地使用复合索引的最左前缀,也就是说,查询只能使用复合索引从左到右的一个或多个索引列。
2.3.2 复合索引最左匹配:
MySQL 的复合索引是 B+ 树数据结构,它是根据复合索引中的所有字段构建出一棵 B+ 树。
假设我们有一个复合索引 (A,B,C),那么 B+ 树的索引顺序会依次按照 A、B、C 的顺序排列。也就是说,B 和 C 的排序都依赖于 A 的值,类似的,C 的排序依赖于 A 和 B 的值。
因此,当我们进行查询时,必须先通过最左边的索引字段 A 去找到正确的 B 范围,再通过 B 找到 C,这样才能保证找到的数据是的。如果我们直接用 B 或者 C 来查找,由于 B 和 C 的排序依赖于 A 的值,所以不能保证我们找到正确的范围,这样数据就会出错。
这就是为什么我们在使用复合索引时,只能使用索引的最左前缀。如果不遵守这个原则,那复合索引可能就无法发挥它应有的效果。
2.4 前缀索引:
2.4.1 前缀索引说明和设置:
前缀索引一般应用于CHAR, VARCHAR, BLOB, TEXT等类型的字段,特别是在这些字段`长度比较长的情况下。完全索引这些长字段对存储和性能都是一种负担,所以我们可以只索引这些字段值的前缀部分。
创建前缀索引的语法如下:
ALTER TABLE tbl_name ADD INDEX index_name (column_name(length));
前缀索引可以尽可能减少索引的存储空间,但也有一些限制,比如它不能被用于 ORDER BY 和 GROUP BY (除非是ORDER BY和GROUP BY的字段列表和索引的前缀一致)。同时,在使用前缀索引时,也应该注意选择合适的前缀长度,使得前缀索引的选择性(独立值与总行数的比例)尽可能的高,查询效果才能更好。
2.4.2 否会得到与查询条件不相同的数据:
在 MySQL 中,前缀索引是根据指定的前缀长度来对字段值创建索引。因此,在一些特定情况下,是有可能出现你所说的多个不同的列值被映射到同一个索引前缀上的情况。然而,这并不会导致查询结果与查询条件不符。
当进行查询时,MySQL 首先会使用前缀索引来定位到可能的数据位置,这个过程可能会返回多个结果,包括你说的那些被映射到同一个索引前缀上的值。然而,这时 MySQL 并不会直接返回这些结果,它会再次对这些结果应用 WHERE 子句中的过滤条件,也就是你的查询条件。只有满足你的查询条件的结果,才会被最终返回。
因此,即使在使用前缀索引时,多个不同的列值被映射到同一个索引前缀上,你最终得到的查询结果也仍然会是符合你的查询条件的数据。
2.4.3 前缀索引长度的设置:
选择性:索引的唯一值数量/表的总行数;如果一个表有1000行,而某个索引列有500个不同的值,那么这个索引的选择性就是500/1000 = 0.5。在创建前缀索引时,前缀的长度影响这个索引的选择性。过短的前缀可能导致选择性低,因为相同前缀的值可能非常多;过长的前缀则可能降低性能并增加存储需求,因为索引变大了。因此,尽量选择能保持较高选择性(即索引的值比较独立)的前缀长度很重要。
选择性的值介于 0 和 1 之间:
- 如果选择性接近 0,表示索引列中重复值较多,比如性别字段只有 ‘男’,'女’两个值,那么索引的选择性就很低。
- 如果选择性接近 1,则表示索引列的值几乎唯一,比如身份证号、邮箱等,这类索引的效率通常非常高。
可以通过应用 SUBSTR() 函数来模拟前缀索引:
SELECT COUNT(DISTINCT SUBSTR(column_name, 1, prefix_length)) FROM your_table;将 “your_table” 替换为你的表名,将 “column_name” 替换为你打算创建索引的列名,将 “prefix_length” 替换为你想要测试的前缀长度。
这个查询可以统计给定前缀长度下的独立值数量,可以尝试不同的前缀长度,来找出最佳的前缀索引长度。
MySQL 官方并没有给出关于前缀索引的选择性的具体建议值,因为这取决于你的具体使用场景和表的数据分布。官方的一般建议是,创建索引时应尽量保持较高的选择性。
2.5 索引的回表:
2.5.1 为什么会产生回表:
在数据库中,“回表” 是指通过非聚集索引查询数据时,因为非聚集索引并不包含全部需要的数据,一次查询不能够得到结果,需要再通过聚集索引查询一次数据。
通常情况下,非聚集索引的叶子节点存储的是聚集索引(通常是主键)的值,而不是整行数据,当我们的查询需要获取的数据不在非聚集索引中时,MySQL就需要再通过聚集索引查询一次数据,这就是"回表"。
回表通常会导致额外的IO操作,因此在查询性能优化时,尽量通过选择合适的索引来避免回表操作。例如,覆盖索引(Covering Index)就是一种很好的避免回表的方法,覆盖索引的列含了查询所需要的全部列,因此查询可以直接在索引上完成,无需再次查询数据表。
2.5.2 非聚集索引叶子节点为什么不存整条数据内容:
每个非聚集索引叶子节点 如果都存整条数据行内容,会占用大量空间;当进行数据修改时,会产生大量的修改,维护成本增高;所以mysql 在非聚集索引叶子节点值存储数据的主键id;
2.6 索引下推(Index Condition Pushdown):
在使用索引查询时,如果没有索引下推,MySQL Server 通常会先读取索引,然后通过索引找到符合条件的行的地址,再根据地址将这一行数据完整地读取到内存中,然后对这一行数据执行 WHERE 子句中的其他部分进行筛选。
而如果使用了索引下推,MySQL Server 在读取索引的时候,就会去检查行数据是否符合 WHERE 子句中的其他筛选条件,如果不符合,就跳过这一行,不再读取这一行的数据。这样可以减少磁盘 I/O,从而提升查询性能。
简单说,索引下推就是把 WHERE 子句中的过滤条件尽可能地"下推"到存储引擎层的索引查询过程中,这样存储引擎在扫描索引的时候就能直接过滤掉一些不需要的数据,减少数据的访问量,从而提升查询效率,Mysql 默认也开启了这个功能。
2.7 多个索引怎么协同工作:
假如对一张表的 name、phone 和 email 分别创建索引:
MySQL 在查询过程中,一次只能使用一个索引。尽管你为 name、phone 和 email 字段都创建了索引,但是在执行如下查询时:
SELECT * FROM table WHERE name = "John" AND phone = "12345" AND email = "john@example.com"
MySQL 优化器的决策通常会选择一个最优的索引(选择覆盖记录最少的索引)来执行查询,而不是同时使用多个索引。
然而,在某些情况下,MySQL 可以使用索引合并(Index Merge)的策略来优化查询。索引合并是在 MySQL 5.1 以后的版本中引入的优化策略,它可以在同一张表的多个索引上查找行,然后合并结果。有两种主要的索引合并策略:
- AND 合并:先分别从两个索引找出满足条件的记录(RowID),然后取交集。
- OR 合并:先分别从两个索引找出满足条件的记录(RowID),然后取并集。
需要注意的是,尽管索引合并可以在一次查询中使用多个索引,但是它的效率并不一定会比使用单一索引高,因为它需要额外的步骤来合并结果。而且,索引合并不总是可用的,是否使用索引合并,由 MySQL 优化器决定。
2.8 适合做索引的列:
我们知道并不是所有的列都可以去创建索引:
- 可以在
WHERE 子句中经常使用的列加速对这些列的数据查询; ORDER BY 和 GROUP BY 语句中使用的列,可以建立索引以提高排序的速度;连接表的时候,经常用作连接条件的列,建立索引加速数据表的连接;
并非所有列都适合建立索引:
- 数据重复度(Cardinality)高的列,比如性别、是否默认等,这类字段即使加了索引也不会提高查询速度,列重复性越低,离散度越高,越适合做索引,离散度公式: count(distinct(column_name)): count(*);
- 对于大文本字段,建立索引可能会消耗较多存储空间,可以考虑使用全文索引或者其它方式;
- 如果一个表很小,或者对一张表的查询并不频繁,索引可能带来的效益非常有限;
- 不建议使用无序的列建立索引,因为可能会频繁造成索引页的修改和分离;
- 索引并不是无限制的,过多的索引会占用额外的磁盘空间,增、删、改三个操作的性能也会有所下降,因为每次 DML 操作都需要维护索引。所以创建索引需要平衡查询性能和存储及维护成本;
三、索引失效的场景
在MySQL中,以下情况可能会导致索引失效:
-
使用 != 或 <> 操作符时,索引可能不会被使用,这将返回所有与操作数不匹配的行,可能导致全表扫描。
-
对于列进行表达式运算将可能导致其索引失效,比如对列进行函数运算,如 SELECT * FROM table WHERE YEAR(date) = 2021,使用函数会导致MySQL无法有效地使用索引,因为索引是根据列的原始值排序的;
-
使用 NOT IN 和 NOT EXISTS 时索引将失效,可能导致全表扫描。
-
不精确的查询,例如使用 LIKE 操作符做模糊查询时,如果通配符在开头,那么索引将不会被使用,如 SELECT * FROM table WHERE name LIKE ‘%abc’,这构成了一个范围查询,因为MySQL不知道一个字符串的开始应该是什么。
-
如果列类型是字符串,那么查询时必须带引号,否则索引无法生效,例如,应该是 WHERE name = ‘abc’ 而不是 WHERE name = abc,
-
如果对某个列做了NULL的查询,索引也会失效,索引不包含NULL值。
-
如果MySQL估计全表扫描比索引更快时,例如某些小表,或者大部分情况下,某个索引的值是一样的,那么索引也可能失效。
-
在使用前缀索引的情况下,如果查询列中超过前缀长度的部分,索引将失效,索引是按照前缀创建的,如果查询超出了前缀长度,则无法利用索引。
总结
本文讲述了mysql 索引的类型,索引的具体实现,以及索引的失效场景,欢迎各位 码友 进行交流指正。
参考
1 数据结构在线模拟;
相关文章:

Mysql原理篇--第二章 索引
文章目录 前言一、mysql的索引是什么?1.1 索引的结构:1.2 b树特性:1.3 b树每个节点的结构:1.4 b树 键值的大小排序:1.4 b树 存储(InnoDB): 二、索引类型2.1 主要的索引类型ÿ…...
保姆级系列教程-玩转Fiddler抓包教程(1)-HTTP和HTTPS基础知识
1.简介 有的小伙伴或者童鞋们可能会好奇地问,不是讲解和分享抓包工具了怎么这里开始讲解HTTP和HTTPS协议了。这是因为你对HTTP协议越了解,你就能越掌握Fiddler的使用方法,反过来你越使用Fiddler,就越能帮助你了解HTTP协议。 Fid…...

【iOS】单例、通知、代理
1 单例模式 1.1 什么是单例 单例模式在整个工程中,相当于一个全局变量,就是不论在哪里需要用到这个类的实例变量,都可以通过单例方法来取得,而且一旦你创建了一个单例类,不论你在多少个界面中初始化调用了这个单例方…...

从Vue2到Vue3【五】——新的组件(Fragment、Teleport、Suspense)
系列文章目录 内容链接从Vue2到Vue3【零】Vue3简介从Vue2到Vue3【一】Composition API(第一章)从Vue2到Vue3【二】Composition API(第二章)从Vue2到Vue3【三】Composition API(第三章)从Vue2到Vue3【四】C…...
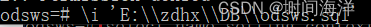
PostgreSQL——sql文件导入
Windows方式: 进入PostgreSQL安装目录的bin,进入cmd 执行命令: psql -d 数据库名 -h localhost -p 5432 -U 用户名 -f 文件目录 SQL Shell: 执行命令: \i 文件目录(Windows下要加引号和双斜线)...

[SQL挖掘机] - 全连接: full join
介绍: 在sql中,join是将多个表中的数据按照一定条件进行关联的操作。全连接(full join)是一种连接类型,它会返回所有满足连接条件的行,同时还包括那些在左表和右表中没有匹配行的数据。 在进行全连接时,会…...

SpringDataJpa 实体类—主键生成策略
主键配置 IdGeneratedValue(strategy GenerationType.IDENTITY)Column(name "cust_id")private Long custId;//主键 Id:表示这个注解表示此属性对应数据表中的主键GeneratedValue(strategy GenerationType.IDENTITY) 此注解表示配置主键的生成策…...

【LeetCode 算法】Parallel Courses III 并行课程 III-拓扑
文章目录 Parallel Courses III 并行课程 III问题描述:分析代码拓扑 Tag Parallel Courses III 并行课程 III 问题描述: 给你一个整数 n ,表示有 n 节课,课程编号从 1 到 n 。同时给你一个二维整数数组 relations ,其…...

进行消息撤回功能的测试时,需要考虑哪些?
进行消息撤回功能的测试时,可以考虑以下测试点: 1. 功能可用性测试:确认消息撤回功能是否能够正常使用,并且在不同的场景下(例如单聊、群聊)是否表现一致。 2. 撤回时限测试:检查消息撤回的时…...
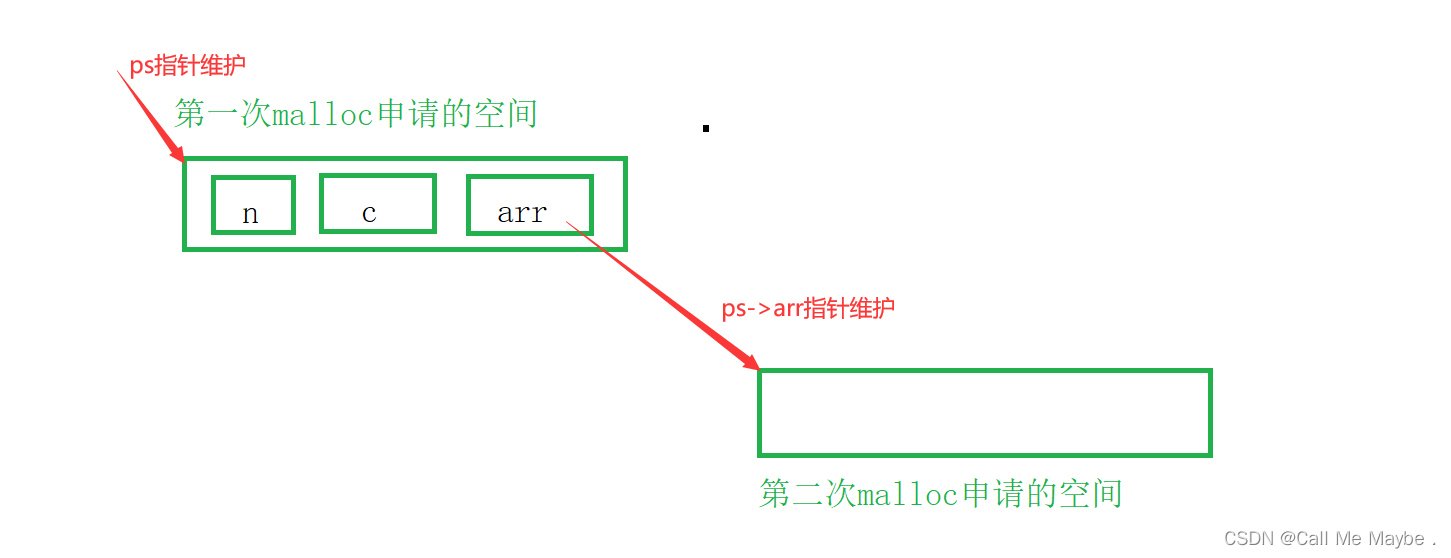
C语言动态内存管理(三)
目录 五、C/C程序的内存开辟1.图解2.关键点 六、柔性数组1.什么是柔性数组2.两种语法形式3.柔性数组的特点4.柔性数组的创建及使用在这个方案中柔性数组的柔性怎么体现出来的? 5.不用柔性数组,实现数组可大可小的思路6.对比 总结 五、C/C程序的内存开辟 1.图解 &a…...
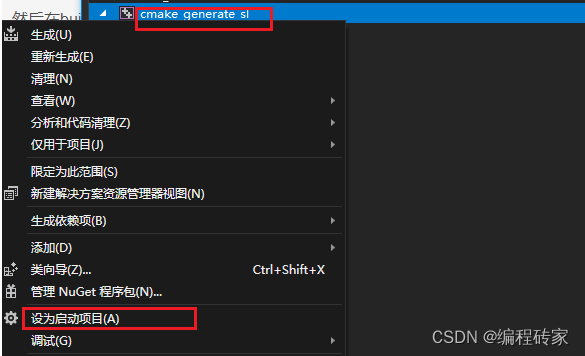
通过cmake工程生成visual studio解决方案
1、前言 visual studio是一个很强大的开发工具,这个工具主要是通过解决方案对我们的源码进行编译等操作。但是我们很多时候拿到的可能并不是一个直接的解决方案,可能是是一个cmake工程,那么这个时候我们就需要通过cmake工程生成解决方案&…...
STM32CubeMX配置STM32G031多通道ADC + DMA采集(HAL库开发)
时钟配置HSI主频配置64M 勾选打开8个通道的ADC 使能连续转换模式 添加DMA DMA模式选择循环模式 使能DMA连续请求 采样时间配置160.5 转换次数为8 配置好8次转换的顺序 配置好串口,选择异步模式配置好需要的开发环境并获取代码 修改main.c 串口重定向 #include &…...
Vue入门项目——WebApi
Vue入门——WebApi vue3项目搭建组合式API响应式APIreactive()ref() 生命周期钩子computed计算属性函数watch监听函数父子通信模板引用组合选项 vue3项目搭建 简单看下Vue3的优势吧 下载安装npm及node.js16.0以上版本(确保安装成功可用如下代码检查版本࿰…...

【电源专题】电量计参数RSOC/RM/FCC定义
在文章【电源芯片】电量计(Gauge)介绍中我们讲到电量计的功能就是监测电池、计量电量。 那么电量计其实也是有很多算法的,比如【电源专题】电量计估计电池荷电状态方法(开路电压法及库仑计法)的差别文章所说的开路电压法和库仑计法。当然还有如阻抗跟踪法、CEDV算法等。 …...

实际开发中,React应用常见问题【持续更新中】
实际开发中,React应用常见问题【持续更新中】 实际开发中,React应用常见问题【持续更新中】 一、路由相关 “react-router-dom”: “^6.14.2”, “react”: “^18.2.0”, 1、监听路由 import { useLocation } from react-router-domexport default func…...

HTML5前端开发工程师的岗位职责说明(合集)
HTML5前端开发工程师的岗位职责说明1 职责 1、根据产品设计文档和视觉文件,利用HTML5相关技术开发移动平台的web前端页面; 2、基于HTML5.0标准进行页面制作,编写可复用的用户界面组件; 3、持续的优化前端体验和页面响应速度,并保证兼容性和…...

Go编写服务监管程序
前言 程序的目的:一个基于Linux系统下的进程监控与管理工具,它能够监控指定的进程或服务的运行情况,并在发现它们不存在或出现异常时自动进行重启操作。这个程序就像一个可靠的看门狗,时刻守护着系统的稳定运行。 程序的本身是周期…...

API商品详情:详尽呈现产品信息的利器
API商品详情:详尽呈现产品信息的利器 随着电子商务的迅速发展,越来越多的企业和开发者开始关注和利用API来实现灵活、高效的商品展示和推广。而在这一领域中,API商品详情成为了无可替代的利器,为用户提供了极为详尽的产品信息。 …...

Cisco 路由器配置管理
大多数网络中断的最常见原因是错误的配置更改。对网络设备配置的每一次更改都伴随着造成网络中断、安全问题甚至性能下降的风险。计划外更改使网络容易受到意外中断的影响。 Network Configuration Manager 网络更改和配置管理 (NCCM)解决方案ÿ…...

java面试真题附参考答案【下册】
tips:下面简述题为java面试真题,阅读本文且感兴趣的,还有将要面试的小伙伴有条件的准备一下笔和纸,将之转述出来成为自己的知识,希望接下来的面试好运连连 上一册:java面试真题【上册】_CsDn.FF的博客-CSD…...
到panic:深入Linux 5.4内核,看异常处理如何层层递进)
从BUG()到panic:深入Linux 5.4内核,看异常处理如何层层递进
从BUG()到panic:Linux内核异常处理的防御体系全解析当你在深夜调试一个内核模块时,突然屏幕刷出一串红色警告——这可能是每个Linux内核开发者都经历过的噩梦时刻。但你是否想过,从第一行警告出现到系统完全崩溃,内核究竟经历了怎…...
)
别再死磕USB HID了!用ESP32的Arduino框架手把手教你实现蓝牙鼠标键盘(附完整代码)
ESP32蓝牙HID实战:零基础打造自定义键盘鼠标 手里那块吃灰的ESP32开发板终于能派上用场了!上周我用它做了个无线演示控制器,在会议室里走着就能翻PPT,同事们都问是怎么实现的。其实秘诀就在于ESP32的蓝牙HID功能——不需要任何USB…...

对比自行维护多个 API 源,使用 Taotoken 聚合服务在运维复杂度上的降低
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比自行维护多个 API 源,使用 Taotoken 聚合服务在运维复杂度上的降低 在构建依赖多个大语言模型的应用时,…...
)
Frida无Root Hook PC微信小程序源码(Electron+Chromium)
1. 这不是“破解”,而是一次对微信小程序运行机制的逆向观察 你有没有试过,在PC版微信里点开一个小程序,想看看它背后是怎么写的?比如某个电商小程序的优惠券逻辑、某个工具类小程序的数据渲染方式,甚至只是单纯好奇—…...

Godot 4.2 + C# 避坑指南:手把手教你打包发布你的第一个2D游戏到Steam
Godot 4.2 C# 避坑指南:从开发到Steam发布的完整实战手册当你终于完成心爱的2D游戏开发,准备向全世界展示你的作品时,打包发布这个看似简单的环节往往会成为独立开发者最大的噩梦。特别是使用Godot 4.2搭配C#的项目,从导出设置到…...

5步完美解决Windows 10 PL2303驱动兼容性问题:完整实施方案指南
5步完美解决Windows 10 PL2303驱动兼容性问题:完整实施方案指南 【免费下载链接】pl2303-win10 Windows 10 driver for end-of-life PL-2303 chipsets. 项目地址: https://gitcode.com/gh_mirrors/pl/pl2303-win10 在Windows 10系统中使用PL2303 USB转串口设…...

【Midjourney霓虹效果终极指南】:20年AI视觉工程师亲授5大参数组合+3类光源建模公式,97%新手一周内复刻赛博朋克海报
更多请点击: https://kaifayun.com 第一章:霓虹美学的视觉原理与Midjourney适配性解析 霓虹美学源于20世纪都市夜景中的荧光灯管、电子广告与赛博朋克文化,其核心视觉特征包括高饱和度冷暖对比、边缘辉光(glow)、深色…...

用Arduino改造TDA7010T FM收音机:数字调谐与自动搜台实战
1. 项目概述:当复古芯片遇上现代微控制器翻出抽屉角落里那个积灰的Kemo B156N套件时,我压根没想到它会变成一个如此有趣的周末项目。这个套件的核心,是一颗来自上世纪八十年代的FM收音机芯片——TDA7010T。当年,它和它的前身TDA70…...

<数据集>yolo高粱叶片病害识别<目标检测>
数据集下载链接https://download.csdn.net/download/qq_53332949/92902223数据集格式:VOCYOLO格式 图片数量:3242张 标注数量(xml文件个数):3242 标注数量(txt文件个数):3242 标注类别数:1 使用标注工具ÿ…...

混合物理-ML辐射方案:攻克气候模型中次网格云效应的新范式
1. 项目概述与核心挑战在气候模拟这个庞大的数字沙盘中,地球系统模型(ESM)是我们理解未来气候演变的核心工具。然而,这个沙盘有一个长期存在的“颗粒度”难题:受限于计算资源,模型的水平分辨率通常在100到2…...