【数据挖掘】使用 LSTM 进行时间和序列预测
一、说明
每天,人类在执行诸如过马路之类的任务时都会做出被动预测,他们估计汽车的速度和与汽车的距离,或者通过猜测球的速度并相应地定位手来接球。这些技能是通过经验和实践获得的。然而,由于涉及众多变量,预测天气或经济等复杂现象可能很困难。在这种情况下使用时间和序列预测,依靠历史数据和数学模型对未来趋势和模式进行预测。在本文中,我们将看到使用航空公司数据集使用数学概念进行预测的示例。
二、第1部分:
2.1 数学概念
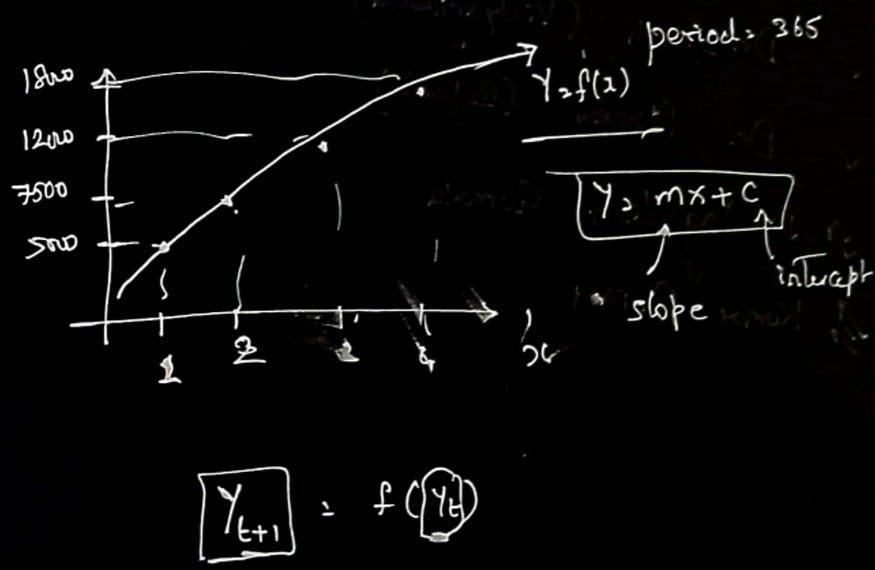
在本文使用的时间序列预测算法的上下文中,该算法不是手动计算线的斜率和截距,而是使用具有 LSTM 层的神经网络来学习时间序列数据中的基础模式和关系。神经网络在一部分数据上进行训练,然后用于对剩余部分进行预测。在该算法中,下一个时间步长的预测基于前面n_inputs的时间步长,类似于线性回归示例中使用 y(t) 预测 y(T+1) 的概念。但是,该算法中的预测不是使用简单的线性方程,而是使用 LSTM 层的激活函数生成的。激活函数允许模型捕获数据中的非线性关系,使其更有效地捕获时间序列数据中的复杂模式。
2.2 激活功能

摄影:@learnwithutsav
LSTM 模型中使用的激活函数是整流线性单元 (ReLU) 激活函数。这种激活函数通常用于深度学习模型,因为它在处理梯度消失问题方面简单有效。在 LSTM 模型中,ReLU 激活函数应用于每个 LSTM 单元的输出,以在模型中引入非线性,并允许它学习数据中的复杂模式。ReLU 函数具有简单的阈值行为,其中任何负输入都映射到零,任何正输入都保持不变地通过,从而使其计算效率高。
三、第 2 部分:
3.1 实施
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
df = pd.read_csv('airline-passengers.csv', index_col='Month', parse_dates=True)
df.index.freq = 'MS'
df.shape
df.columns
plt.figure(figsize=(20, 4))
plt.plot(df.Passengers, linewidth=2)
plt.show()该代码导入了三个重要的库:numpy、pandas 和 matplotlib。熊猫库用于读取“航空公司乘客.csv”文件,并将“月”列设置为索引,从而允许随时间分析数据。然后,该代码使用 matplotlib 库创建一个线图,显示一段时间内的航空公司乘客数量。最后,使用“plt.show”功能显示绘图。此代码对于任何对分析时序数据感兴趣的人都很有用,它演示了如何使用 pandas 和 matplotlib 来可视化数据趋势。

nobs = 12
df_train = df.iloc[:-nobs]
df_test = df.iloc[-nobs:]
df_train.shape
df_test.shape此代码通过将现有时间序列数据帧“df”拆分为训练集和测试集来创建两个新的数据帧“df_train”和“df_test”。“nobs”变量设置为 12,这意味着“df”的最后 12 个观测值将用于测试,而其余数据将用于训练。训练集存储在“df_train”中,由“df”中除最后12行以外的所有行组成,而测试集存储在“df_test”中,仅由“df”的最后12行组成。然后使用“shape”属性打印每个数据框中的行数和列数,从而确认拆分正确完成。此代码通过将时序数据拆分为两组,可用于准备用于建模和测试目的的时序数据。
3.2 模型架构
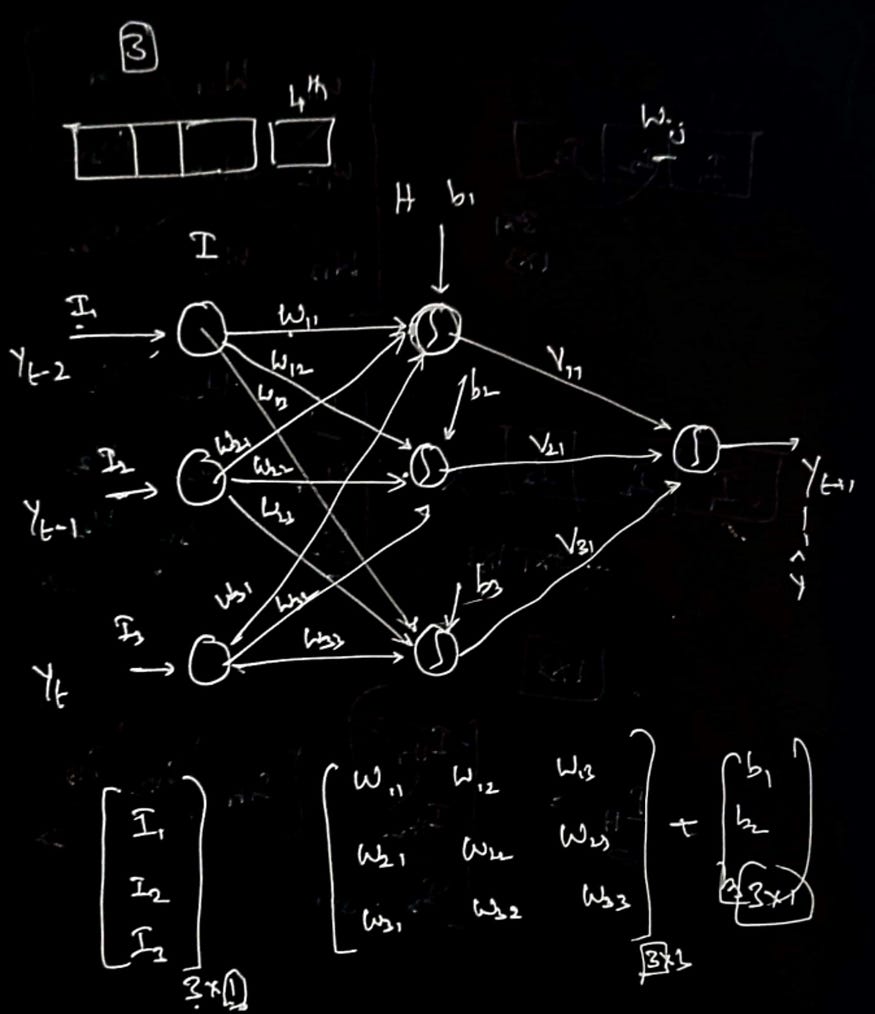
图片来源:@learnwithutsav
from keras.preprocessing.sequence import TimeseriesGenerator
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
scaler.fit(df_train)
scaled_train = scaler.transform(df_train)
scaled_test = scaler.transform(df_test)n_inputs = 12
n_features = 1
generator = TimeseriesGenerator(scaled_train, scaled_train, length = n_inputs, batch_size =1)for i in range(len(generator)):X, y = generator[i]print(f' \n {X.flatten()} and {y}')此代码片段演示了如何使用 Keras 的“TimeseriesGenerator”类和 scikit-learn 的“MinMaxScaler”类为时间序列预测模型生成输入和输出数组。代码首先创建“MinMaxScaler”类的实例,并将其拟合到训练数据集(“df_train”),以便缩放数据。然后将缩放后的数据存储在“scaled_train”和“scaled_test”数据框中。时间步长数 ('n_inputs“) 设置为 12,要素数 ('n_features') 设置为 1。使用“scaled_train”数据创建“TimeseriesGenerator”对象,窗口长度为“n_inputs”,批大小为 1。最后,循环用于迭代“生成器”对象并打印出每个时间步的输入和输出数组。“X”和“y”变量分别表示每个时间步长的输入和输出数组。“flatten()”方法用于将输入数组转换为一维数组,以便于打印。总体而言,此代码对于准备使用滑动窗口方法预测模型的时间序列数据非常有用。

X.shape此代码返回数组或矩阵“X”的形状。“shape”属性是 NumPy 数组的一个属性,并返回一个表示数组维度的元组。该代码没有提供任何其他上下文,因此不清楚“X”的形状是什么。输出将采用以下格式(行、列)。

from keras.models import Sequential
from keras.layers import Dense
from keras.layers import LSTMmodel = Sequential()
model.add(LSTM(200, activation='relu', input_shape = (n_inputs, n_features)))
model.add(Dense(1))
model.compile(optimizer='adam', loss='mse')model.summary()此代码演示如何使用 Keras 创建用于时间序列预测的 LSTM 神经网络模型。首先,导入必要的 Keras 类,包括“顺序”、“密集”和“LSTM”。该模型被创建为“顺序”对象,并添加了一个包含 200 个神经元、“relu”激活函数以及由“n_inputs”和“n_features”定义的输入形状的 LSTM 层。然后将 LSTM 层输出传递到具有单个输出神经元的“密集”层。该模型使用“adam”优化器和均方误差(“mse”)损失函数进行编译。'summary()' 方法用于显示架构的摘要,包括参数的数量以及每层输入和输出张量的形状。此代码可用于创建用于时间序列预测的 LSTM 模型,因为它提供了一个易于遵循的示例,可以适应不同的数据集和预测问题。

3.3 训练阶段

model.fit(generator, epochs = 50)此代码使用 Keras 中的“fit()”方法训练 LSTM 神经网络模型 50 个 epoch。“TimeseriesGenerator”对象生成成批的输入/输出对,供模型学习。'fit()' 方法使用基于模型编译期间定义的损失函数和优化器的反向传播来更新模型参数。通过训练模型,它学习根据训练数据中学习的模式对新的、看不见的数据进行预测。

plt.plot(model.history.history['loss'])
last_train_batch = scaled_train[-12:]last_train_batch = last_train_batch.reshape(1, 12, 1)last_train_batchmodel.predict(last_train_batch)此代码使用经过训练的 LSTM 神经网络模型对新数据点进行预测。从训练数据中选择、缩放并调整为模型的适当格式。在模型上调用“predict()”方法,将重塑的数据作为输入,输出是时间序列中下一个时间步长的预测值。这是使用 LSTM 模型进行时间序列预测的重要步骤。
<span style="background-color:#f9f9f9"><span style="color:#242424">scaled_test[0]</span></span>此代码打印缩放测试数据数组的第一个元素。“scaled_test”变量是使用“MinMaxScaler”对象转换的测试数据的 NumPy 数组。打印此数组的第一个元素将显示测试数据中第一个时间步长的缩放值。
![]()
3.4 预测
y_pred = []first_batch = scaled_train[-n_inputs:]
current_batch = first_batch.reshape(1, n_inputs, n_features)for i in range(len(scaled_test)):batch = current_batchpred = model.predict(batch)[0]y_pred.append(pred)current_batch = np.append(current_batch[:,1:, :], [[pred]], axis = 1)y_predscaled_test此代码使用经过训练的 LSTM 模型生成测试数据的预测。它使用 for 循环循环遍历缩放测试数据中的每个元素。在每次迭代中,当前批处理用于使用模型的“predict()”方法进行预测。然后将预测值添加到“y_pred”列表中,并更新当前批次。最后,将“y_pred”列表与“scaled_test”数据一起打印,以将预测值与实际值进行比较。此步骤对于评估 LSTM 模型在测试数据上的性能至关重要。

df_testy_pred_transformed = scaler.inverse_transform(y_pred)y_pred_transformed = np.round(y_pred_transformed,0)y_pred_final = y_pred_transformed.astype(int)y_pred_final此代码使用 scaler 对象的“inverse_transform()”方法将上一步中生成的预测值转换回原始比例。转换后的值使用 'round()' 函数舍入到最接近的整数,并使用 'astype()' 方法转换为整数。打印生成的预测值数组“y_pred_final”,以显示测试数据的最终预测值。此步骤对于评估 LSTM 模型在数据原始尺度上的预测的准确性非常重要。

df_test.values, y_pred_finaldf_test['Predictions'] = y_pred_finaldf_test上面的代码显示了添加到原始测试数据集的 LSTM 模型生成的预测值。首先,“values”属性用于提取“df_test”数据帧的值,然后将其与预测值“y_pred_final”配对。然后,将一个名为“预测”的新列添加到“df_test”数据帧以存储预测值。最后,使用新添加的“预测”列打印“df_test”数据帧。此步骤对于直观地将测试数据集的实际值与预测值进行比较并评估模型的准确性非常重要。
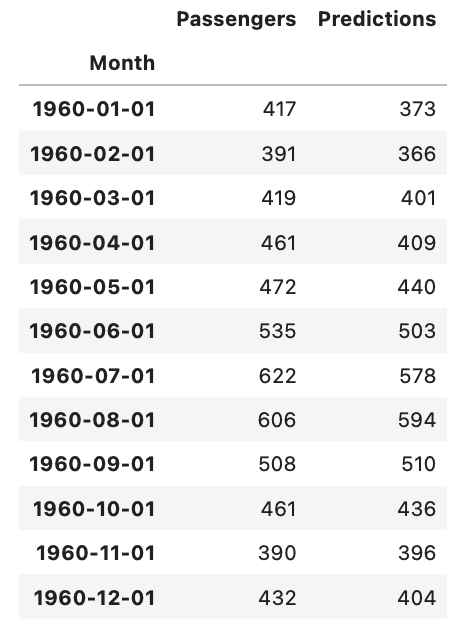
plt.figure(figsize=(15, 6))
plt.plot(df_train.index, df_train.Passengers, linewidth=2, color='black', label='Train Values')
plt.plot(df_test.index, df_test.Passengers, linewidth=2, color='green', label='True Values')
plt.plot(df_test.index, df_test.Predictions, linewidth=2, color='red', label='Predicted Values')
plt.legend()
plt.show()此代码块正在使用库生成绘图。它首先设置图形大小,然后将训练数据绘制为黑线,将真实测试值绘制为绿线,将预测的测试值绘制为红线。它还向绘图添加图例,并使用该方法显示图例。matplotlibshow()

3.5均方误差

均方误差 (MSE) 是回归线与一组点的接近程度的度量。它是通过取预测值和实际值之间的平方差的平均值来计算的。MSE 的平方根称为均方根误差 (RMSE),这是预测准确性的常用度量。在此代码块中,RMSE 是使用模块中的函数和模块 中的函数计算的 。RMSE 用于评估 LSTM 模型预测的准确性与测试集中的真实值相比。mean_squared_errorsklearn.metricssqrtmath
from sklearn.metrics import mean_squared_error
from math import sqrtsqrt(mean_squared_error(df_test.Passengers, df_test.Predictions)) 此代码计算测试集中的实际乘客值 () 与预测乘客值 () 之间的均方根误差 (RMSE)。RMSE 是评估回归模型性能的常用指标。它测量预测值和实际值之间的平均距离,同时考虑它们之间差值的平方。RMSE 是一个有用的指标,因为它对大误差的惩罚比小误差更严重,使其成为模型预测整体准确性的良好指标。df_test.Passengersdf_test.Predictions
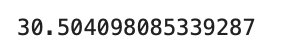
总之,我们在 Keras 中使用 LSTM 算法实现了时间序列预测模型。我们在每月航空公司乘客数据集上训练了模型,并使用它来预测未来 12 个月。该模型表现良好,均方根误差为 30.5。真实值、预测值和训练值的可视化表明,该模型能够捕获数据中的总体趋势和季节性。这证明了 LSTM 在捕获时间序列数据中复杂时间关系方面的强大功能及其进行准确预测的潜力。
四、结论
本文示例是一个典型的时间序列处理办法,可以当作经典来用。读者可以多花一些时间消化该案例;事实表明,用LSTM这种工具不仅可以处理NLP,而且可以针对任何的时间序列,比如股票预测。
相关文章:
【数据挖掘】使用 LSTM 进行时间和序列预测
一、说明 每天,人类在执行诸如过马路之类的任务时都会做出被动预测,他们估计汽车的速度和与汽车的距离,或者通过猜测球的速度并相应地定位手来接球。这些技能是通过经验和实践获得的。然而,由于涉及众多变量,预测天气或…...
)
Typescript第四章 函数(声明和调用,注解参数类型,多态,类型别名,泛型)
第四章 函数 ts中声明和调用函数的不同方式签名重载多态函数多态类型声明 4.1 声明和调用函数 在js中函数是一等对象,我们可以像对象那样使用函数,可以复制给变量,可以作为参数传递,返回值,赋值给对象的原型&#x…...

大数据-Spark批处理实用广播Broadcast构建一个全局缓存Cache
1、broadcast广播 在Spark中,broadcast是一种优化技术,它可以将一个只读变量缓存到每个节点上,以便在执行任务时使用。这样可以避免在每个任务中重复传输数据。 2、构建缓存 import org.apache.spark.sql.SparkSession import org.apache.s…...

Android Service的生命周期,两种启动方法,有什么区别
Android Service的生命周期,两种启动方法,有什么区别 Android Service是一种后台组件,用于在后台执行长时间运行的任务,而无需与用户界面进行交互。Service具有自己的生命周期,其主要包含以下几个状态:创建…...
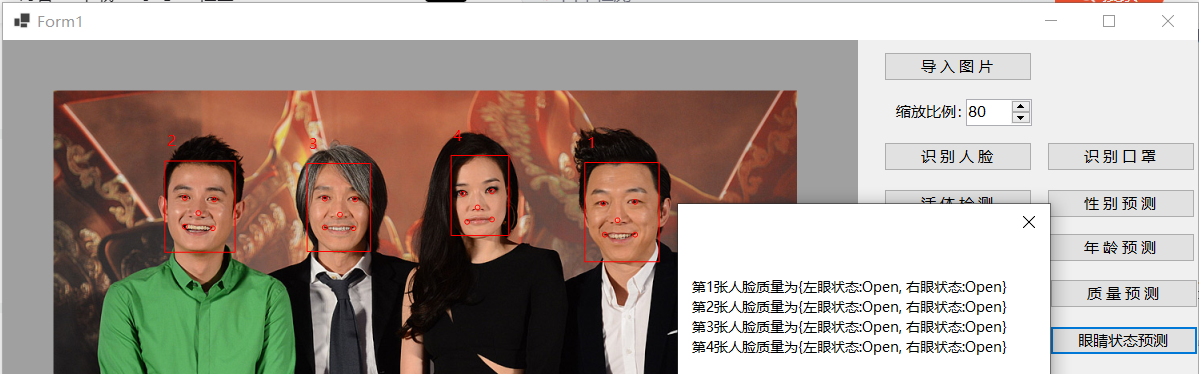
测试开源C#人脸识别模块ViewFaceCore(5:质量检测和眼睛状态检测)
ViewFaceCore模块中的FaceQuality支持预测人脸质量,最初以为是预测人体体重,实际测试过程中才发现是评估人脸图片质量,主要调用Detect函数执行图片质量检测操作,其函数原型如下所示: //// 摘要:// 人脸质量评估///…...

Go语言网络库net/http
Go语言网络库net/http Http 协议(Hyper Text Transfer Protocol,超文本传输协议)是一个简单的请求-响应协议,它通常运行在 TCP 之 上。超文本传输协议是互联网上应用最为广泛的一种网络传输协议,所有的WWW文件都必须遵守这个标准。 Http 协…...

Acwing.91 最短Hamilton路径(动态规划)
题目 给定一张n个点的带权无向图,点从0~n-1标号,求起点0到终点n-1的最短Hamilton路径。Hamilton路径的定义是从0到n-1不重不漏地经过每个点恰好一次。 输入格式 第—行输入整数n。 接下来n行每行n个整数,其中第i行第j个整数表示点i到j的距…...

[hfut] [important] v4l2 vedio使用总结/opevx/ffpeg/v4l2/opencv/cuda
(158条消息) linux驱动camera//test ok_感知算法工程师的博客-CSDN博客 (158条消息) linux V4L2子系统——v4l2架构(1)之整体架构_感知算法工程师的博客-CSDN博客 (158条消息) linux V4L2子系统——v4l2的结构体(2)之video_devi…...

2023年深圳杯数学建模A题影响城市居民身体健康的因素分析
2023年深圳杯数学建模 A题 影响城市居民身体健康的因素分析 原题再现: 以心脑血管疾病、糖尿病、恶性肿瘤以及慢性阻塞性肺病为代表的慢性非传染性疾病(以下简称慢性病)已经成为影响我国居民身体健康的重要问题。随着人们生活方式的改变&am…...

指令调度(Instruction Scheduling)
指令调度(Instruction Scheduling) 指令调度的约束基本机器模型基本块调度全局调度 指令调度是为了提高指令级并行(ILP),对于超长指令字(VLIW, Very Long Instruction Word)和多发射系统&#x…...

【运维】Linux 跨服务器复制文件文件夹
【运维】Linux 跨服务器复制文件文件夹 如果是云服务 建议用内网ip scp是secure copy的简写,用于在Linux下进行远程拷贝文件的命令,和它类似的命令有cp,不过cp只是在本机进行拷贝不能跨服务器,而且scp传输是加密的。可能会稍微影…...

k8s apiserver如何支持http访问?
原本是可以通过设置api-server的--insecure-port来实现,但是这个参数已经被废弃了,更好的方法则是使用proxy来实现: 在集群任意一个节点上起一个proxy服务,并设置允许所有host访问: kubectl proxy --address0.0.0.0 …...

Safetensors,高效安全易用的深度学习新工具
大家好,本文将介绍一种为深度学习应用提供速度、效率、跨平台兼容性、用户友好性和安全性的新工具。 Safetensors简介 Hugging Face开发了一种名为Safetensors的新序列化格式,旨在简化和精简大型复杂张量的存储和加载。张量是深度学习中使用的主要数据…...
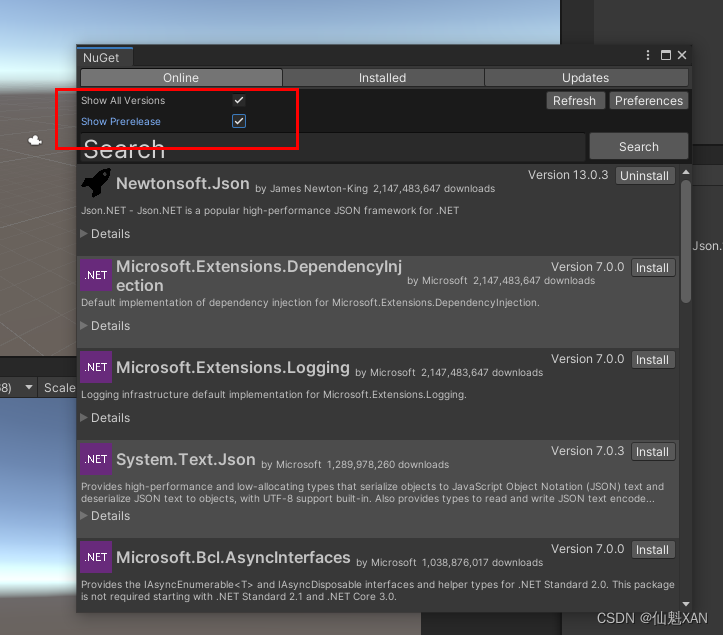
Unity 工具之 NuGetForUnity 包管理器,方便在 Unity 中的进行包管理的简单使用
Unity 工具之 NuGetForUnity 包管理器,方便在 Unity 中的进行包管理的简单使用 目录 Unity 工具之 NuGetForUnity 包管理器,方便在 Unity 中的进行包管理的简单使用 一、简单介绍 二、NuGetForUnity 的下载导入 Unity 三、NuGetForUnity 在 Unity 的…...
运算放大器(二):恒流源
一、实现原理 恒流源的输出电流能够在一定范围内保持稳定,不会随负载的变化而变化。 通过运放,将输入的电压信号转换成满足一定关系的电流信号,转换后的电流相当一个输出可调的简易恒流源。 二、电路结构 常用的恒流源电路如…...
企业选择租用CRM还是一次性买断CRM?分别有哪些优势?
CRM是企业管理客户关系,提升销售业绩,实现业务增长的重要工具。市场上的CRM系统销售方式主要有两种——租用型和买断型。那么,租用CRM好还是一次性买断CRM好?本文将从以下几个方面进行分析: 1、什么是租用型CRM和买断…...

VBA_MF系列技术资料1-133
MF系列VBA技术资料 为了让广大学员在实际VBA编程中有切实可行的思路及有效的提高自己的编程技巧,我参考大量的资料,并结合自己的经验总结了这份MF系列VBA技术综合资料,而且开放源码(MF04除外),其中MF01-04属…...

Android 项目架构
🔥 什么是架构 🔥 在维基百科里是这样定义的: 软件架构是一个系统的轮廓 . 软件架构描述的对象是直接构成系统的抽象组件. 各个组件之间的连接则明确和相对细致地描述组件之间的通讯 . 在实现阶段, 这些抽象组件被细化为实际组件 , 比如具体某个类或者对象 . 面试的过程中…...

【Linux】进程通信 — 管道
文章目录 📖 前言1. 通信背景1.1 进程通信的目的:1.2 管道的引入: 2. 匿名管道2.1 匿名管道的原理:2.2 匿名管道的创建:2.3 父子进程通信:2.3.1 read()阻塞等待 2.4 父进程给子进程派发任务:2.5…...
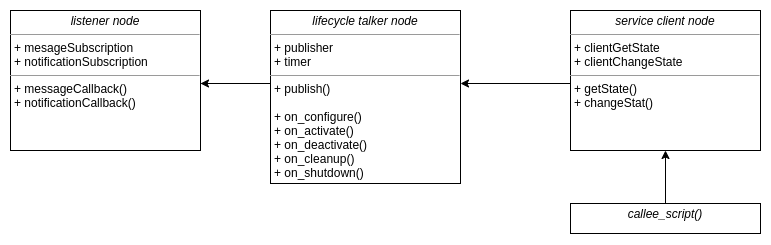
ROS 2 — 托管(生命周期)节点简介
一、说明 这篇文章是关于理解ROS 2中托管(生命周期)节点的概念。我们描述了概念性的想法以及我们为什么需要它。所以让我们开始吧! 二、托管式节点 — 什么和为什么? 为了理解托管式节点,让我们从一个简单的问题陈述开…...

【DeepSeek事件驱动架构实战指南】:20年架构师亲授5大核心陷阱与避坑清单
更多请点击: https://kaifayun.com 第一章:DeepSeek事件驱动架构全景认知 DeepSeek事件驱动架构(Event-Driven Architecture, EDA)并非单一技术组件的堆叠,而是一种以事件为第一公民、强调松耦合与异步协作的系统设计…...

股票买卖最佳时机:LeetCode121题解
题目LeetCode121给定一个数组 prices ,它的第 i 个元素 prices[i] 表示一支给定股票第 i 天的价格。你只能选择 某一天 买入这只股票,并选择在 未来的某一个不同的日子 卖出该股票。设计一个算法来计算你所能获取的最大利润。返回你可以从这笔交易中获取…...

Unity UI交互进阶:手把手教你打造一个支持单击、双击、长按的万能按钮组件
Unity UI交互进阶:手把手教你打造一个支持单击、双击、长按的万能按钮组件在游戏开发中,UI交互的流畅性和多样性直接影响玩家的游戏体验。想象一下,当你在开发一个RPG游戏的背包系统时,需要实现道具的单击查看详情、双击快速使用、…...

武汉国电华美16875kVA串联谐振试验装置,这手活儿细
在超高压变电站和长距离电缆的现场,交流耐压试验是检验设备绝缘的“最后一关”。这位老师傅经手过不少大工程,他说,面对GIS、大型变压器这些“大块头”电容性试品,能不能顺利“过关”,往往就看串联谐振装置顶不顶得住。…...

Codex使用API Key授权无法使用插件?
小伙伴们,大家好,我是小溪,见字如面。对于没有ChatGPT账号的小伙伴来说,虽然可以通过API Key授权的方式使用Codex桌面端,但是会有一些限制。比如无法使用插件功能,无法使用Codex移动端进行远程控制等。为了…...

告别枯燥理论!用Unity脚本生命周期与预制体玩转一个“会变身的敌人”
用Unity打造会变身的敌人:脚本生命周期与预制体的实战应用在游戏开发中,敌人AI的行为设计往往是新手开发者最感兴趣也最容易感到困惑的部分。Unity的脚本生命周期和预制体系统为这类需求提供了强大支持,但教科书式的讲解常常让学习者陷入枯燥…...

机器学习在射电天文数据分类中的应用:以MIGHTEE巡天SFG/AGN分类为例
1. 项目概述:当机器学习遇见深空射电巡天在射电天文学领域,我们正经历一场数据洪流。以MeerKAT望远镜阵列主导的MIGHTEE巡天项目为例,其在COSMOS天区的一次早期科学数据释放,就在不到1平方度的天区内探测到了超过6000个射电源。传…...

如何通过Joy-Con Toolkit实现专业级Switch手柄控制与硬件逆向工程
如何通过Joy-Con Toolkit实现专业级Switch手柄控制与硬件逆向工程 【免费下载链接】jc_toolkit Joy-Con Toolkit 项目地址: https://gitcode.com/gh_mirrors/jc/jc_toolkit 在游戏开发、硬件调试和嵌入式系统研究中,与游戏手柄等专业输入设备进行深度交互一直…...

终极免费音乐解锁工具:5步轻松解密你的加密音乐文件
终极免费音乐解锁工具:5步轻松解密你的加密音乐文件 【免费下载链接】unlock-music 在浏览器中解锁加密的音乐文件。原仓库: 1. https://github.com/unlock-music/unlock-music ;2. https://git.unlock-music.dev/um/web 项目地址: https:/…...
)
微信聊天图片丢了别慌!保姆级教程:找回并解密DAT文件(支持新旧版微信路径)
微信DAT图片恢复实战:从文件定位到批量解密的完整指南 微信聊天记录中的图片突然消失?别急着放弃!那些看似无法打开的DAT文件里,可能藏着您的重要回忆或工作资料。本文将带您深入微信存储机制,手把手完成从文件定位到…...