LLaMA模型论文《LLaMA: Open and Efficient Foundation Language Models》阅读笔记
文章目录
- 1. 简介
- 2.方法
- 2.1 预训练数据
- 2.2 网络架构
- 2.3 优化器
- 2.4 高效的实现
- 3.论文其余部分
- 4. 参考资料
1. 简介
LLaMA是meta在2023年2月开源的大模型,在这之后,很多开源模型都是基于LLaMA的,比如斯坦福大学的羊驼模型。
LLaMA的重点是比通常情况下使用更多的语料,来训练一系列可在各种推理预算下实现可能的最佳性能的语言模型。
摘要翻译:我们在此介绍LLaMA,这是一个参数范围从7B到65B的基础语言模型集合。我们在数万亿个token上训练了我们的模型,并表明在不使用私有和不可公开获得的数据集的情况下,仅仅使用公开可用的数据,是有可能训练最先进的模型的。特别的是,LLaMA-13B在大多数基准测试中都优于175B大小的GPT-3,而LLaMA-65B可以与最好的模型Chinchilla-70B and PaLM-540B匹敌。我们向研究社区开源所有的模型。
2.方法
2.1 预训练数据
训练集数据覆盖了不同的领域的数据,具体如下图。值得注意的是,这些数据集都是可公开获得的,不包括私有数据。

数据集的详情如下:
English CommonCrawl [67%]:用CCNet pipeline的方式预处理了从2017至2020年的5个CommonCrawl dump: 在行级别去重数据,用fastText线性分类器进行语言判断并去掉非英语页面,使用n-gram语言模型过滤掉低质量内容。训练了一个线性模型来分类页面是否是Wikipedia的参考页或随机抽样的页面,并丢掉没有被分类为参考页的页面。
C4 [15%]: 预处理过程也有去重和质量过滤,与CCNet采用了不一样的质量过滤,主要采用启发式规则如一个网页中标点负荷或句子和词的个数。
Github [4.5%]: 使用Google Bigquery上的Github数据集,只保留Apache、BSD、MIT开源协议的项目。根据代码行的长度、字母数字并用的字符的比例采用启发式规则过滤掉低质量文件,并用正则表达式去掉样板文件如头文件。最后用精确匹配的方式在文件级别上删除重复数据。
Wikipedia [4.5%]: 使用从2022年6-8月的Wikipedia dumps文件,覆盖20种Latin或Cyrillic语言: bg, ca, cs, da, de, en, es, fr, hr, hu, it,nl, pl, pt, ro, ru, sl, sr, sv, uk。去掉数据中的超链接、注释及其他格式化样板文件。
Gutenberg and Books3 [4.5%]: 这是两个书本语料数据集,在书本级别进行去重,去掉超过90%重复内容的书本。
ArXiv [2.5%]: 这个数据集是为了添加科学数据,去掉参考数目和第一部分之前的所有内容。并去掉了.tex文件中的注释以及用户编写的内联扩展定义和宏,以提高论文之间的一致性。
Stack Exchange [2%]: 保留前28个数据量的网站的数据,去掉了HTML 标签,并对答案按照评分从高到低排序。
Tokenizer: 使用BPE 算法,采用SentencePiece的实现。并且将所有数字拆分为单独的数字,并回退到byte来分解未知的 UTF-8 字符。
最后生成的整个训练数据集在分词后包括大约1.4T的tokens。除了Wikipedia和书籍数据集被用来训练了2个epoch外,其他的数据在训练阶段都只被使用了一次。
2.2 网络架构
网络也是基于transformer架构,在原始transformer上做了修改,具体如下(括号中的模型名表示曾受此模型启发):
Pre-normalization [GPT-3]: 对transfromer的每一个sub-layer的输入作归一化,使用了RMSNorm 归一化函数。
SwiGLU activation function [PaLM]: 将ReLu激活函数替换成SwiGLU激活函数。使用 2 3 4 d \frac{2}{3}4d 324d的尺度(PaLM的尺度是 4 d 4d 4d)
Rotary Embeddings [GPTNeo]: 在网络的每一层使用rotary positional embeddings (RoPE),而不是原论文中的绝对位置嵌入向量。
各个大小的模型的超参数如下图

2.3 优化器
- 模型使用AdamW 优化器,对应的超参: β 1 = 0.9 , β 2 = 0.95 \beta_1 = 0.9, \ \beta_2 = 0.95 β1=0.9, β2=0.95
- 使用cosine learning rate schedule, 最后的学习率是最大学习的10%
- 使用0.1的weight decay, 大小为1.0的gradient clipping
- 使用2000步的warmup,随模型大小改变学习率和batch size(如上图,不过从图片里batch size看起来貌似是一样的)
2.4 高效的实现
为了提高模型的训练速度,做了以下优化操作:
- 使用causal multi-head attention的有效实现来减少内存使用和运行时间。用的是xformers的代码,通过不存储被掩码的注意力权重和key/query分数来实现的。
- 用checkpointing减少反向传播过程中要重复计算的激活函数的量。也就是存储了计算昂贵的激活函数,比如线性层的输出,通过自己实现反向传播层而不是使用pytorch的实现来达到这个目的。 为了从这个改动中获益,需要使用模型和序列并行来减少模型的内存,此外,还尽可能地重叠激活计算和 GPU 之间的网络通信(由于 all_reduce 操作)。
当训练65B参数的模型时,实现代码可以在2048块的80GB内存的A100 GPU上达到 380 t o k e n s / s e c / G P U 380\ tokens/sec/GPU 380 tokens/sec/GPU的处理速度,也就是用1.4T tokens的数据集训练模型大约21天。
3.论文其余部分
-
与GPT-3一样,考虑模型在Zero-shot和few-shot任务上的效果,在20个benchmarks进行了验证实验,考虑到LLaMA最大的模型为65B,其性能还是不错的。
-
在模型训练过程中,也跟踪了模型在问答和常识基准库上的效果。大部分基准库上模型随着训练时间逐渐提升。


- 作者们对大模型的偏见、毒性、错误信息也进行评估,在RealToxicityPrompts上发现模型越大,毒性越强。
- 对5个月训练期间的碳足迹进行估算,大约花了2,638 MWh电,大概1,015 t的二氧化碳。
4. 参考资料
- Touvron, Hugo, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothee Lacroix, Baptiste Rozière, et al. n.d. “LLaMA: Open and Efficient Foundation Language Models.”
- 开源代码
相关文章:
LLaMA模型论文《LLaMA: Open and Efficient Foundation Language Models》阅读笔记
文章目录 1. 简介2.方法2.1 预训练数据2.2 网络架构2.3 优化器2.4 高效的实现 3.论文其余部分4. 参考资料 1. 简介 LLaMA是meta在2023年2月开源的大模型,在这之后,很多开源模型都是基于LLaMA的,比如斯坦福大学的羊驼模型。 LLaMA的重点是比…...

了解Unity编辑器 之组件篇Effects(十一)
一、Halo:是一个可用于游戏对象的特效组件,它可以在对象周围添加一个光晕效果 Color属性: 用于设置Halo的颜色。你可以通过选择颜色面板中的颜色来指定光晕的外观。选择适当的颜色可以使光晕与游戏场景中的其他元素相匹配或突出显示。 Size属性: 用于设…...

笔记整理-SpringBoot中的扩展点
SpringBoot有哪些扩展点 aware 感知类接口 aware系列的扩展接口,允许spring应用感知/获取特定的上下文环境或对象。bean生命周期控制类接口 bean生命周期类的接口,可以控制spring容器对bean的处理。app生命周期控制类接口 app生命周期控制类接口…...

各系统的目录信息路径
Windows系统: 查看系统版本——C:\boot.ini IIS配置文件——C:\windows\system32\inetsrv\MetaBase.xml 存储Windows系统初次安装的密码——C:\windows\repair\sam Mysql配置——C:\ProgramFiles\mysql\my.ini MySQL root密码——C:\P…...
)
Asp.Net 使用Log4Net (封装帮助类)
Asp.Net 使用Log4Net (封装帮助类) 1. 创建Log4Net帮助类 首先,在你的项目中创建一个Log4Net帮助类,用于封装Log4Net的配置和日志记录逻辑。 using log4net; using log4net.Config;public class LogHelper {private static readonly ILog log LogMan…...

全志F1C200S嵌入式驱动开发(lcd屏幕驱动)
【 声明:版权所有,欢迎转载,请勿用于商业用途。 联系信箱:feixiaoxing @163.com】 lcd RGB屏幕作为比较经济、实用的显示工具,在实际场景中使用较多。它的信号来说,一般也比较简单,除了常规的数据信号,剩下来就是行同步、场同步、数据使能和时钟信号了。数据信…...
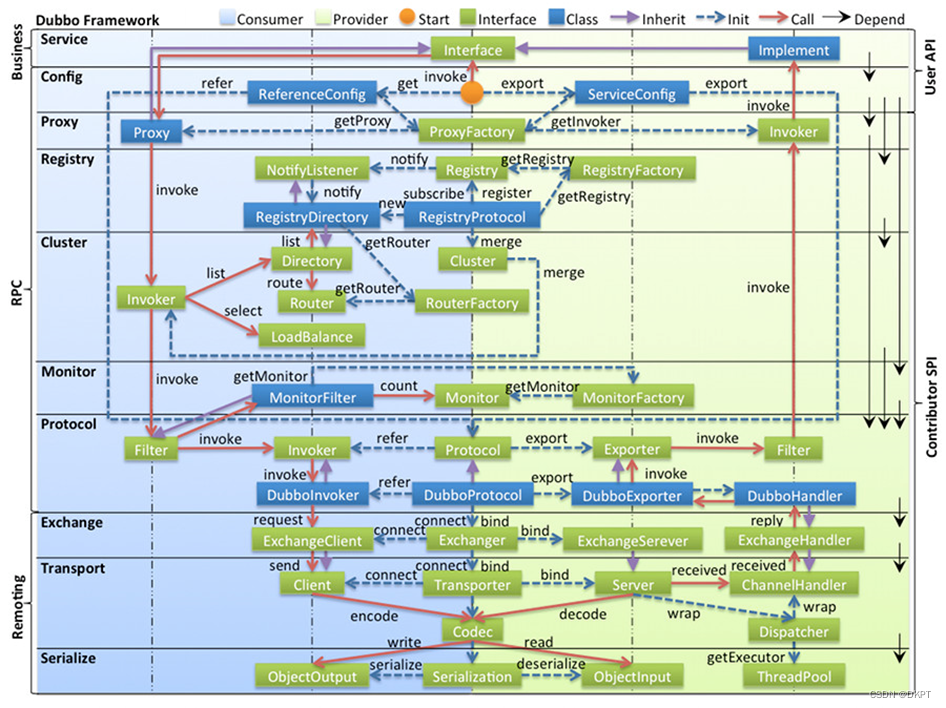
dubbo原理框架设计
dubbo原理框架设计 (1)config 配置层:对外配置接口,以 ServiceConfig, ReferenceConfig 为中心,可以直接初始化配置类,也可以通过 spring 解析配置生成配置类。 (2)proxy 服务代理…...
【数据挖掘】使用 LSTM 进行时间和序列预测
一、说明 每天,人类在执行诸如过马路之类的任务时都会做出被动预测,他们估计汽车的速度和与汽车的距离,或者通过猜测球的速度并相应地定位手来接球。这些技能是通过经验和实践获得的。然而,由于涉及众多变量,预测天气或…...
)
Typescript第四章 函数(声明和调用,注解参数类型,多态,类型别名,泛型)
第四章 函数 ts中声明和调用函数的不同方式签名重载多态函数多态类型声明 4.1 声明和调用函数 在js中函数是一等对象,我们可以像对象那样使用函数,可以复制给变量,可以作为参数传递,返回值,赋值给对象的原型&#x…...

大数据-Spark批处理实用广播Broadcast构建一个全局缓存Cache
1、broadcast广播 在Spark中,broadcast是一种优化技术,它可以将一个只读变量缓存到每个节点上,以便在执行任务时使用。这样可以避免在每个任务中重复传输数据。 2、构建缓存 import org.apache.spark.sql.SparkSession import org.apache.s…...

Android Service的生命周期,两种启动方法,有什么区别
Android Service的生命周期,两种启动方法,有什么区别 Android Service是一种后台组件,用于在后台执行长时间运行的任务,而无需与用户界面进行交互。Service具有自己的生命周期,其主要包含以下几个状态:创建…...
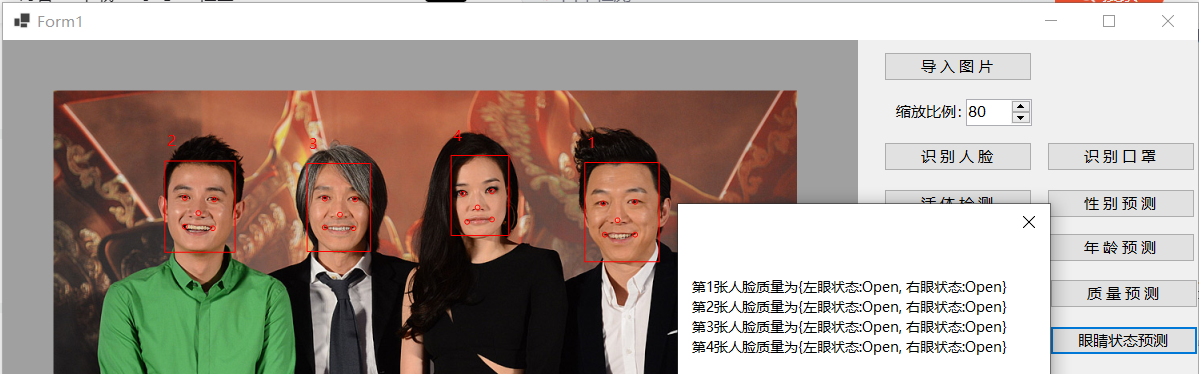
测试开源C#人脸识别模块ViewFaceCore(5:质量检测和眼睛状态检测)
ViewFaceCore模块中的FaceQuality支持预测人脸质量,最初以为是预测人体体重,实际测试过程中才发现是评估人脸图片质量,主要调用Detect函数执行图片质量检测操作,其函数原型如下所示: //// 摘要:// 人脸质量评估///…...

Go语言网络库net/http
Go语言网络库net/http Http 协议(Hyper Text Transfer Protocol,超文本传输协议)是一个简单的请求-响应协议,它通常运行在 TCP 之 上。超文本传输协议是互联网上应用最为广泛的一种网络传输协议,所有的WWW文件都必须遵守这个标准。 Http 协…...

Acwing.91 最短Hamilton路径(动态规划)
题目 给定一张n个点的带权无向图,点从0~n-1标号,求起点0到终点n-1的最短Hamilton路径。Hamilton路径的定义是从0到n-1不重不漏地经过每个点恰好一次。 输入格式 第—行输入整数n。 接下来n行每行n个整数,其中第i行第j个整数表示点i到j的距…...

[hfut] [important] v4l2 vedio使用总结/opevx/ffpeg/v4l2/opencv/cuda
(158条消息) linux驱动camera//test ok_感知算法工程师的博客-CSDN博客 (158条消息) linux V4L2子系统——v4l2架构(1)之整体架构_感知算法工程师的博客-CSDN博客 (158条消息) linux V4L2子系统——v4l2的结构体(2)之video_devi…...

2023年深圳杯数学建模A题影响城市居民身体健康的因素分析
2023年深圳杯数学建模 A题 影响城市居民身体健康的因素分析 原题再现: 以心脑血管疾病、糖尿病、恶性肿瘤以及慢性阻塞性肺病为代表的慢性非传染性疾病(以下简称慢性病)已经成为影响我国居民身体健康的重要问题。随着人们生活方式的改变&am…...

指令调度(Instruction Scheduling)
指令调度(Instruction Scheduling) 指令调度的约束基本机器模型基本块调度全局调度 指令调度是为了提高指令级并行(ILP),对于超长指令字(VLIW, Very Long Instruction Word)和多发射系统&#x…...

【运维】Linux 跨服务器复制文件文件夹
【运维】Linux 跨服务器复制文件文件夹 如果是云服务 建议用内网ip scp是secure copy的简写,用于在Linux下进行远程拷贝文件的命令,和它类似的命令有cp,不过cp只是在本机进行拷贝不能跨服务器,而且scp传输是加密的。可能会稍微影…...

k8s apiserver如何支持http访问?
原本是可以通过设置api-server的--insecure-port来实现,但是这个参数已经被废弃了,更好的方法则是使用proxy来实现: 在集群任意一个节点上起一个proxy服务,并设置允许所有host访问: kubectl proxy --address0.0.0.0 …...

Safetensors,高效安全易用的深度学习新工具
大家好,本文将介绍一种为深度学习应用提供速度、效率、跨平台兼容性、用户友好性和安全性的新工具。 Safetensors简介 Hugging Face开发了一种名为Safetensors的新序列化格式,旨在简化和精简大型复杂张量的存储和加载。张量是深度学习中使用的主要数据…...

UE5 BaseEditorSettings.ini加载原理与配置生效机制
1. 为什么你改了BaseEditorSettings.ini却没生效?——从UE5编辑器启动流程讲起很多人在UE5项目里折腾半天,把BaseEditorSettings.ini文件翻来覆去改了十几遍,重启编辑器后发现:缩放比例还是不对、网格间距没变、甚至“启用实时预览…...

OpenClaw技能安装失败全解析:从依赖冲突到网络问题的系统性解决方案
1. 项目概述:当技能“卡住”时,我们遇到了什么?最近在折腾OpenClaw这类开源AI助手平台时,不少朋友都踩进了同一个坑:从官方市场或者第三方渠道找到了心仪的技能(Skill),点击“安装”…...

AX-MES生产制造管理系统-总览
前言说起 MES 就不得不说 ERP,但是 ERP 大家基本上都知道,MES 就不一定了,常见的 ERP 系统包括 SAP、金蝶、用友等,ERP的流程相对来说也比较统一;MES就不同了,基本上熟悉业务流程的软件公司都可以开发并实施…...

【DeepSeek测试用例生成实战指南】:20年QA专家亲授5大高覆盖率生成模式与3个避坑红线
更多请点击: https://codechina.net 第一章:DeepSeek测试用例生成的核心价值与适用边界 DeepSeek系列大模型在代码理解与生成任务中展现出显著的上下文建模能力,其测试用例生成功能并非通用“黑盒测试器”,而是聚焦于**单元级、函…...

从入门到实践:EEG公开数据集分类与应用场景全解析
1. EEG公开数据集入门指南刚接触脑电信号分析的研究者,常常会被一个问题困扰:"我应该从哪里获取可靠的EEG数据?"作为一个在这个领域摸爬滚打多年的研究者,我完全理解这种困惑。记得我第一次接触EEG研究时,光…...

[智能体-81]:工程化智能体 = 模型做脑力拆解 + 框架做流程落地。前者是决策者,后者是管理者,tools/function call是内部员工;mcp server是外部资源;
一、全角色人设 & 对应技术组件角色定位对应技术模块核心职责决策者(脑力大脑)大模型 LLM理解目标、任务拆解、逻辑判断、分支决策、内容生成,负责 “想方案、定步骤”管理者(流程总管)智能体编排框架(…...

深度解析网络设备权限管理工具:中兴光猫工厂模式与Telnet服务完整指南
深度解析网络设备权限管理工具:中兴光猫工厂模式与Telnet服务完整指南 【免费下载链接】zteOnu A tool that can open ZTE onu device factory mode 项目地址: https://gitcode.com/gh_mirrors/zt/zteOnu 在当今网络设备管理领域,获取设备完整控制…...
)
Unity3D深度纹理实战:手把手教你实现可交互的激光雷达扫描特效(附完整C#/Shader代码)
Unity3D深度纹理实战:手把手教你实现可交互的激光雷达扫描特效(附完整C#/Shader代码)在科幻题材的游戏开发中,激光雷达扫描特效是营造科技感的经典元素。从《赛博朋克2077》的战术目镜到《看门狗》的环境扫描,这种动态…...

Xia Sql插件:可调试的SQL注入决策引擎
1. 这不是又一个“自动扫SQL”的插件,而是把渗透工程师的判断逻辑塞进了Burp里你有没有过这种经历:在Burp Proxy里看着一堆GET参数、POST JSON、Cookie字段,心里清楚“这里大概率能注入”,但手动拼payload试了七八轮,还…...

观察Taotoken在多模型聚合调用下的路由与失败重试效果
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 观察Taotoken在多模型聚合调用下的路由与失败重试效果 在构建依赖大模型能力的应用时,服务的稳定性是开发者关注的核心…...