ChatGPT | 分割Word文字及表格,优化文本分析
知识库读取Word内容时,由于embedding切片操作,可能会出现表格被分割成多个切片的情况。这种切片方式可能导致“列名栏”和“内容栏”之间的Y轴关系链断裂,从而无法准确地确定每一列的数据对应关系,从而使得无法准确知道每一列的数据汇总。
用下面表格为例子:
| 级数 | T1 | T2 | T3 | T4 | T5 | T6 | T7 |
| 子等 | T1.1-1.2 | T2.1-2.2 | T3.1-3.3 | T4.1-4.3 | T5.1-5.2 | T6.1-6.2 | T7 |
| 专业名称 | 实习 工程师 | 助理 工程师 | 工程师 | 高级 工程师 | 资深 工程师 | 专家级 工程师 | 首席 工程师 |
| 学历 | 本科及以上 | 本科及以上 | 本科及以上 | 本科及以上 | 本科及以上 | 硕士及以上 | 硕士及以上 |
| 工作经验 | 1年以内(兼职) | 1-3年 | 3-5年 | 5-8年 | 8-10年 | 10-15年 | 15年以上 |
| 级数 | T1 | T2 | T3 | T4 | T5 | T6 | T7 |
| 子等 | T1.1-1.2 | T2.1-2.2 | T3.1-3.3 | T4.1-4.3 | T5.1-5.2 | T6.1-T6.2 | T7 |
| 专业名称 | 实习 工程师 | 助理 工程师 | 工程师 | 高级 工程师 | 资深 工程师 | 专家级 工程师 | 首席 工程师 |
| 分值 | 60-64分 | 65-69分 | 70-79分 | 80-89分 | 90-94分 | 95-97分 | 98-100分 |
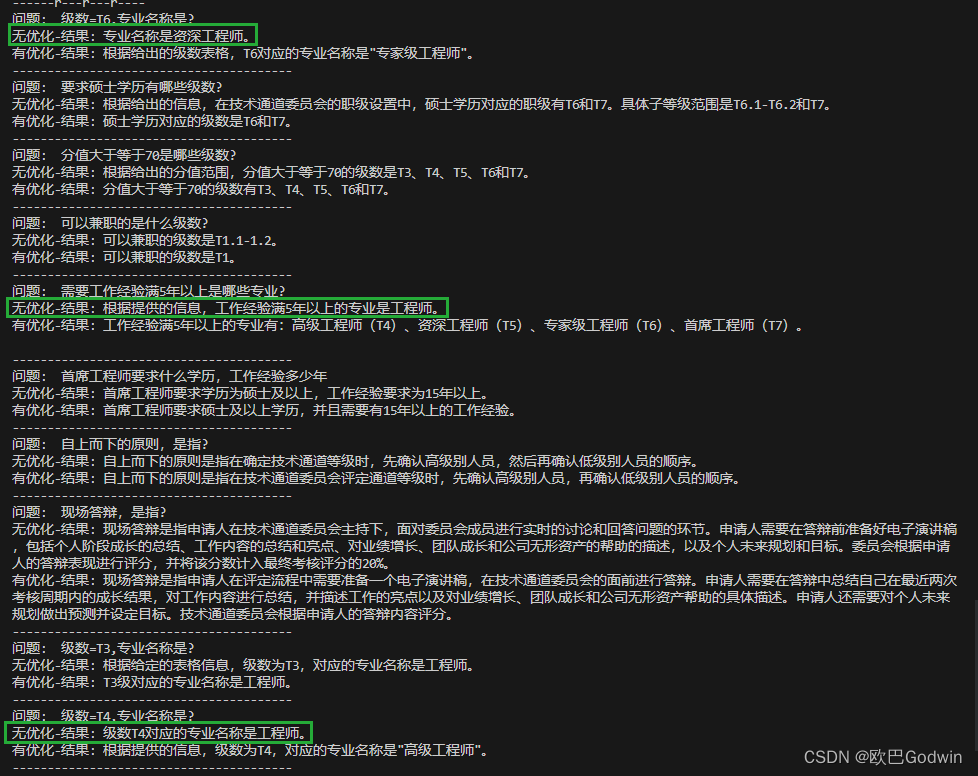
直接演示一下本文代码运行的对比结果,分别展示“无优化”和“有优化”的问答结果,标绿框的是回答错误的:
本文帮助提高文本处理和向量化的效率,以下是对每个步骤的详细说明,详见md_embedding.py源码:
- 分离文字和表格:将原始Word文档中的文字内容和表格分开保存。将文字内容保存为纯文本的Markdown文件,而将表格单独保存为多个只包含Markdown表格的Markdown文件。例如,一个Word文档包含2个表格,即生成1个纯文字Markdown文件,2个纯表格的Markdown文件。
- 切片并向量化处理:对于多个Markdown文件,按照固定的大小切片,确保切片大小是大于Markdown表格的体积,以确保包含完整的表格。然后对这些切片进行向量化处理。
这种方法的优点是能够有效地分离文字和表格,并通过切片和向量化处理提高处理效率。通过将表格转化为向量表示,可以更方便地进行后续的计算和分析。同时,由于切片时保证了表格的完整性,可以避免表格被切断导致信息丢失的问题。
有优化的embedding的源码, md_embedding.py 如下:
import os
from langchain.embeddings import OpenAIEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.vectorstores import Chroma
from langchain.document_loaders import TextLoader
from langchain.text_splitter import CharacterTextSplitter
from langchain.document_loaders import DirectoryLoader
from langchain.document_loaders import UnstructuredFileLoader
from langchain.document_loaders import UnstructuredWordDocumentLoaderfrom docx import Documentdef convert_word_tables_to_markdown(file_path, output_folder):def convert_table_to_markdown(table):markdown = ""for row in table.rows:cells = [cell.text.replace('\n', '').replace('|', '|') for cell in row.cells]markdown += "|".join(cells) + "|\n"return markdowndoc = Document(file_path)# 创建输出文件夹(如果不存在)os.makedirs(output_folder, exist_ok=True)# 将每个表格转换为Markdown并保存为单独的TXT文件for i, table in enumerate(doc.tables):markdown = convert_table_to_markdown(table)filename_without_ext=os.path.splitext(os.path.basename(file_path))[0]# 将Markdown表格写入TXT文件output_file_path = os.path.join(output_folder, filename_without_ext+f"_output_{i+1}.md")with open(output_file_path, "w", encoding='utf-8') as file:file.write(markdown)return output_folderdef remove_tables_save_as_md(file_path, output_file_path):doc = Document(file_path)# 移除所有表格for table in doc.tables:table._element.getparent().remove(table._element)# 获取剩余内容的纯文本,并构建Markdown格式字符串content = [p.text.strip() for p in doc.paragraphs if p.text.strip()]markdown_content = '\n\n'.join(content)# 保存为MD文件with open(output_file_path, 'w', encoding='utf-8') as file:file.write(markdown_content)return output_file_pathabs_docx_path='D:\CloudDisk\OpenAI\博客的源码\Docx表格优化\带表格DOCX.docx'
embedding_folder_path=os.path.dirname(abs_docx_path)+'\\md_txt'
os.makedirs(embedding_folder_path,exist_ok=True)convert_word_tables_to_markdown(abs_docx_path,embedding_folder_path)
remove_tables_save_as_md(abs_docx_path,embedding_folder_path+'\\'+os.path.basename(abs_docx_path)+'.md')# 1 定义embedding
embeddings = OpenAIEmbeddings(openai_api_key='aaaaaaaaaaaaaaaaaa',openai_api_base='bbbbbbbbbbbbbbbbbbbbbbbbbb',openai_api_type='azure',model="text-embedding-ada-002",deployment="lk-text-embedding-ada-002",chunk_size=1)# 2 定义文件
loader = DirectoryLoader(embedding_folder_path, glob="**/*.md")
pages = loader.load_and_split()# 按固定尺寸切分段落
text_splitter_RCTS = RecursiveCharacterTextSplitter(chunk_size = 500,chunk_overlap = 100
)split_docs_RCTS = text_splitter_RCTS.split_documents(pages)
for item in split_docs_RCTS:print(item)print('')#写入向量数据库
print(f'写入RCTS向量数据库')
vectordb = Chroma.from_documents(split_docs_RCTS, embedding=embeddings, persist_directory="./MD_RCTS/")
vectordb.persist()
无优化的embedding的源码,docx_embedding.py 如下:
import os
from langchain.embeddings import OpenAIEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.vectorstores import Chroma
from langchain.document_loaders import UnstructuredWordDocumentLoader# 1 定义embedding
embeddings = OpenAIEmbeddings(openai_api_key='aaaaaaaaaa',openai_api_base='bbbbbbbbbbb',openai_api_type='azure',model="text-embedding-ada-002",deployment="lk-text-embedding-ada-002",chunk_size=1)docx_file_path="D:\CloudDisk\OpenAI\博客的源码\Docx表格优化\带表格DOCX.docx"# 2 定义文件
loader = UnstructuredWordDocumentLoader(docx_file_path)
pages = loader.load_and_split()# 按固定尺寸切分段落
text_splitter_RCTS = RecursiveCharacterTextSplitter(chunk_size = 500,chunk_overlap = 100
)split_docs_RCTS = text_splitter_RCTS.split_documents(pages)
for item in split_docs_RCTS:print(item)print('')#写入向量数据库
print(f'写入RCTS向量数据库')
vectordb = Chroma.from_documents(split_docs_RCTS, embedding=embeddings, persist_directory="./Word_RCTS/")
vectordb.persist()问答测试 chat_qa.py:
import time
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.vectorstores import Chroma
from langchain.chains import RetrievalQA
from langchain.chat_models import AzureChatOpenAIdef getQuestionList():question_list=['级数=T6,专业名称是?','要求硕士学历有哪些级数?','分值大于等于70是哪些级数?','可以兼职的是什么级数?','需要工作经验满5年以上是哪些专业?','首席工程师要求什么学历,工作经验多少年','自上而下的原则,是指?','现场答辩,是指?','级数=T3,专业名称是?','级数=T4,专业名称是?',]return question_listembeddings = OpenAIEmbeddings(openai_api_key='aaaaaaaaaaaaaaaaa',openai_api_base='bbbbbbbbbbbbbbbbbbbbbbb',openai_api_type='azure',model="text-embedding-ada-002",deployment="lk-text-embedding-ada-002",chunk_size=1)openAiLLm = AzureChatOpenAI(openai_api_key='aaaaaaaaaaaaaaaaaaaaaaaaaaaa', #注意这里,不同 API_BASE 使用不同 APK_KEYopenai_api_base="bbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbb",openai_api_version='2023-03-15-preview',deployment_name='lk-gpt-35-turbo-16k',temperature=0.9,model_name="gpt-35-turbo-16k",max_tokens=300)print('------r---r---r----')word_RTCS = Chroma(persist_directory="./Word_RCTS/", embedding_function=embeddings)
word_qa = RetrievalQA.from_chain_type(llm=openAiLLm,chain_type="stuff",retriever=word_RTCS.as_retriever(),return_source_documents = False) md_RTCS = Chroma(persist_directory="./MD_RCTS/", embedding_function=embeddings)
md_qa = RetrievalQA.from_chain_type(llm=openAiLLm,chain_type="stuff",retriever=md_RTCS.as_retriever(),return_source_documents = False)#print(qa_RTCS)#查看自定义Prompt的结构体内容
for i in range(0,len(getQuestionList())):question_text=getQuestionList()[i]# 进行问答wordchat = word_qa({"query": question_text}) wordquery = str(wordchat['query'])wordresult = str(wordchat['result'])print("问题: ",wordquery)print("无优化-结果:",wordresult)time.sleep(1)#每次提问间隔1scsvchat = md_qa({"query": question_text}) csvquery = str(csvchat['query'])csvresult = str(csvchat['result'])#print("MD问题: ",csvquery)print("有优化-结果:",csvresult)print('----------------------------------------')time.sleep(1)#每次提问间隔1s相关文章:
ChatGPT | 分割Word文字及表格,优化文本分析
知识库读取Word内容时,由于embedding切片操作,可能会出现表格被分割成多个切片的情况。这种切片方式可能导致“列名栏”和“内容栏”之间的Y轴关系链断裂,从而无法准确地确定每一列的数据对应关系,从而使得无法准确知道每一列的数…...

基于JavaSE的手机库存管理系统
1、项目背景 基于JavaSE完成如下需求: 功能需求: 1、查询库存量 2、可以修改库存中不同品牌手机的个数 3、退出系统 实现步骤: 1、把List当做库房 2、把手机存放在库房中 3、使用封装的方法区操作仓库中的手机 2、项目知识点 面向对象 集合…...
)
驱动开发 day4 (led灯组分块驱动)
//编译驱动(注意Makefile的编译到移植到开发板的内核) make archarm //清除编译生成文件 make clean //安装驱动 insmod mycdev.ko //卸载驱动 rmmod mycdev //编译fun.c 函数(用到交叉工具编译) arm-linux-gnueabihf-gcc fun.c head.h #ifndef __HEAD_H__ #define __HEAD_H__…...
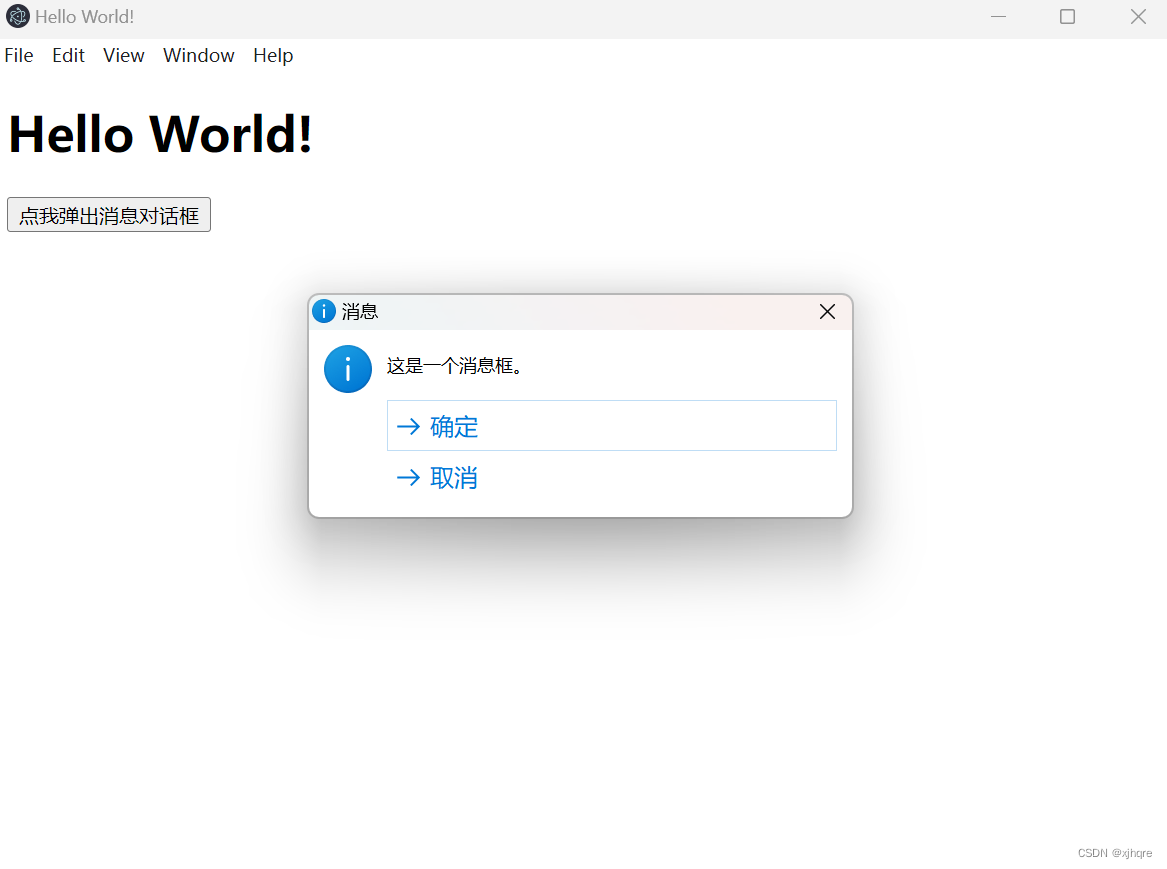
electron dialog.showMessageBox使用案例
electron 版本:25.3.1 index.html <!DOCTYPE html> <html> <head><meta charset"UTF-8"><title>Hello World!</title><meta http-equiv"Content-Security-Policy" content"script-src self unsa…...

代码随想录算法训练营第二十二天 | 读PDF复习环节2
读PDF复习环节2 本博客的内容只是做一个大概的记录,整个PDF看下来,内容上是不如代码随想录网站上的文章全面的,并且PDF中有些地方的描述,是很让我疑惑的,在困扰我很久后,无意间发现,其网站上的讲…...

TimescaleDB时序数据库初识
注:本文翻译自https://legacy-docs.timescale.com/v1.7/introduction TimescaleDB是一个开源时间序列数据库,针对快速摄取和复杂查询进行了优化。它说的是“完整的SQL”,因此像传统的关系数据库一样易于使用,并且以以前为NoSQL数…...

Numpy-聚合函数
NumPy 提供了很多统计函数,用于从数组中查找最小元素,最大元素,百分位标准差和方差等。 函数名说明np.sum()求和np.prod()所有元素相乘np.mean()平均值np.std()标准差np.var()方差np.median()中位数np.power()幂运算np.sqrt()开方np.min()最小…...
企业博客资讯如何高效运营起来?
运营一个高效的企业博客资讯需要综合考虑多个因素,包括内容策划、发布频率、优化推广、互动反馈等。下面将从这些方面介绍如何高效运营企业博客资讯。 如何高效运营企业博客资讯 内容策划 首先,需要制定一个明确的内容策略。确定博客的定位和目标受众…...

跟我学c++中级篇——模板的继承
一、继承 面向对象编程有三个特点:封装、继承和多态。其中继承在其中起着承上启下的作用。一般来说,继承现在和组合的应用比较难区分,出于各种场景和目的,往往各有千秋。但目前主流的观点,一般是如果没有特殊情况&…...
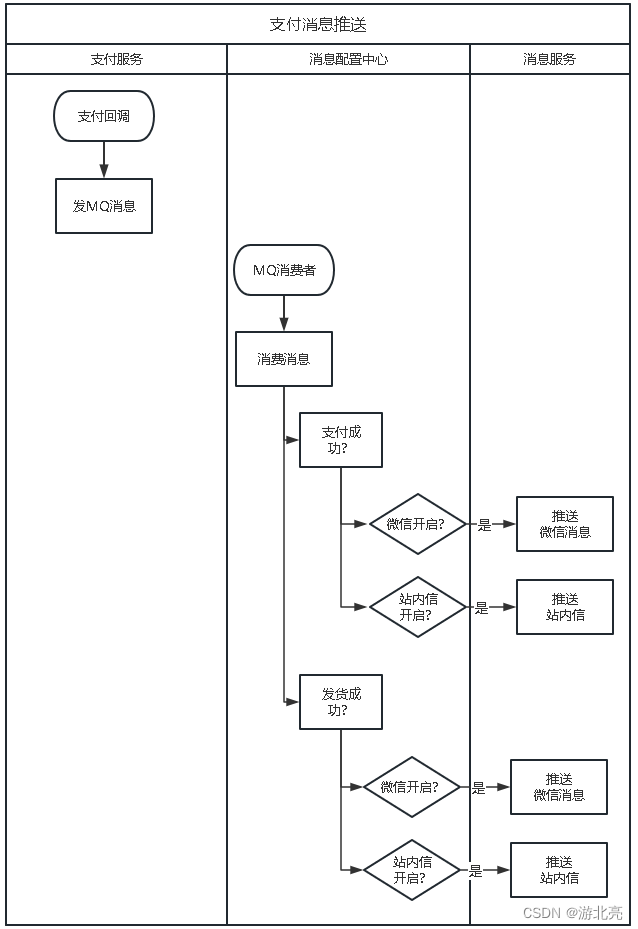
需求分析案例:消息配置中心
本文介绍了一个很常见的消息推送需求,在系统需要短信、微信、邮件之类的消息推送时,边界如何划分和如何设计技术方案。 1、需求 一个系统,一般会区分多个业务模块,并拆分成不同的业务系统,例如一个商城的架构如下&am…...

自动化测试——环境
一、搭建环境 1、安装Slenium pip install selenium 2、安装浏览器驱动-》查询浏览器版本-》下载对应版本驱动-》在path路径中配置(浏览器更新需要重新下载) pip install webdriver -helper(自动化)python3.9以上 pip install 安…...

短视频矩阵营销系统技术开发者开发笔记分享
一、开发短视频seo抖音矩阵系统需要遵循以下步骤: 1. 确定系统需求:根据客户的需求,确定系统的功能和特点,例如用户注册登录、视频上传、视频浏览、评论点赞等。 2. 设计系统架构:根据系统需求,设计系统的…...

vue2和vue3引用ueditor的区别
官方文档入口 UEditor Docs vue2使用方式 UE.vue组件 <template><div><script id"editor" type"text/plain"></script><Upload v-if"isupload" :config"{total:9}" :isupload"isupload" ret…...
【每日运维】RockyLinux8非容器化安装Mysql、Redis、RabitMQ单机环境
系统版本:RockyLinux 8.6 安装方式:非容器化单机部署 安装版本:mysql 8.0.32 redis 6.2.11 rabbitmq 3.11.11 elasticsearch 6.7.1 前置条件:时间同步、关闭selinux、主机名、主机解析host 环境说明:PC电脑VMware Work…...
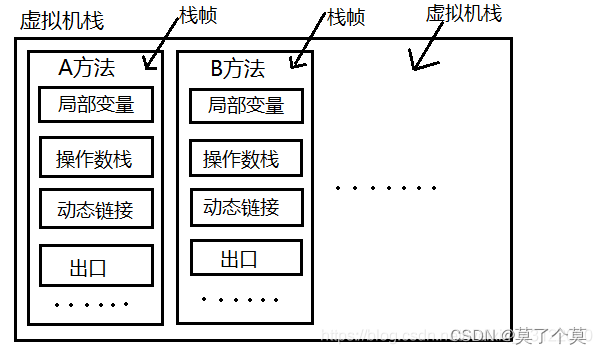
第一次后端复习整理(JVM、Redis、反射)
1. JVM 文章仅为自身笔记 详情查看一篇文章掌握整个JVM,JVM超详细解析!!! 1.1 什么是JVM jvm是Java虚拟机 1.2 Java文件的编译过程 程序员编写代码形成.java文件经过javac编译成.class文件再通过JVM的类加载器进入运行时数据…...
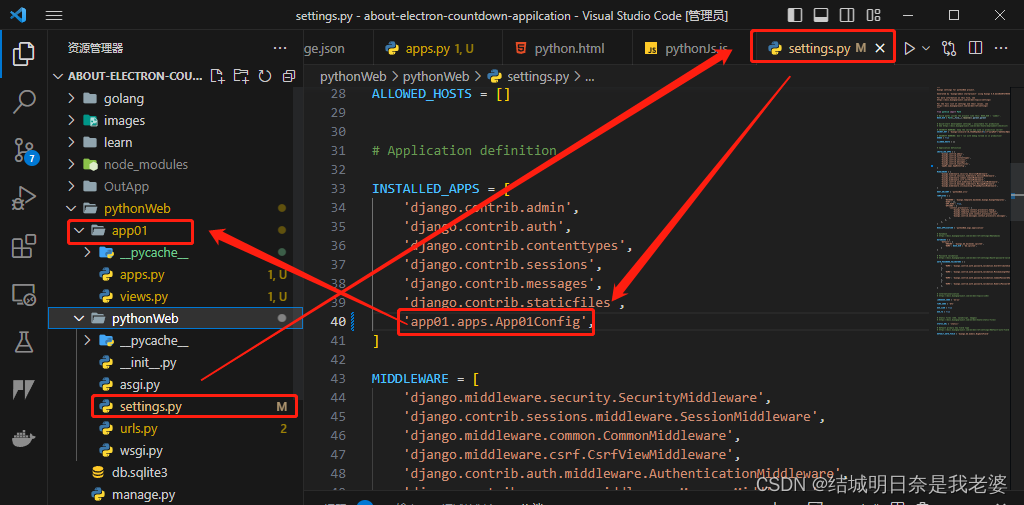
python的web学习(一)-初识django
文章目录 软件创建项目默认项目文件说明App的概念(应用)apps.py编写URL和视图函数对应关系【urls.py】编写视图函数【views.py】启动服务 软件 python下载 django下载 创建项目 django-admin startproject 文件名默认项目文件说明 项目名 manage.py(项目管理,启…...
JavaWeb+jsp+Tomcat的叮当书城项目
点击以下链接获取源码: https://download.csdn.net/download/qq_64505944/88123111?spm1001.2014.3001.5503 技术:ssm jsp JDK1.8 MySQL5.7 Tomcat8.3 源码数据库课程设计 功能:管理员与普通用户和超级管理员三个角色,管理员可…...
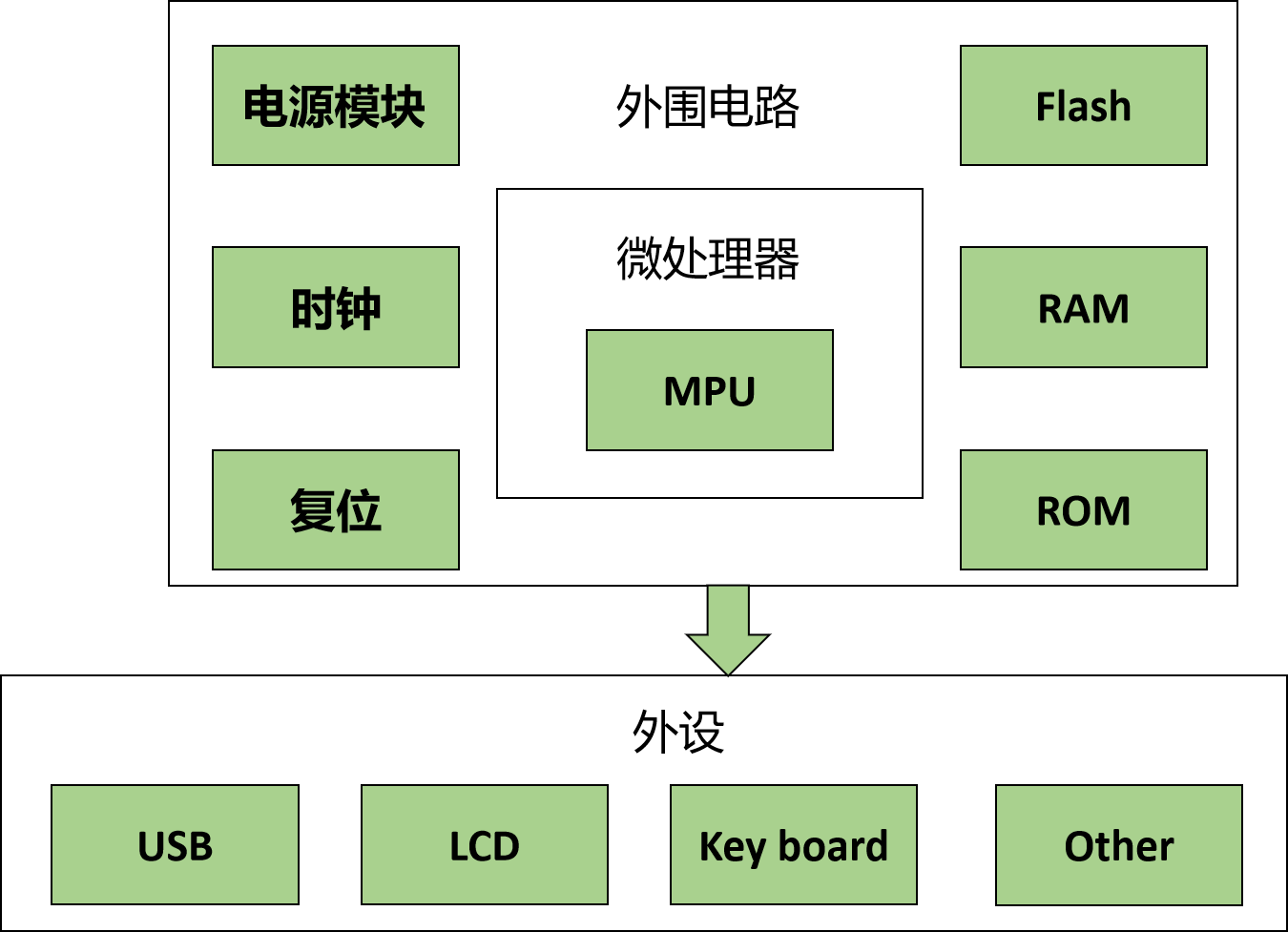
【嵌入式Linux系统开发】——系统移植概述
目录 🍉🍉一、什么是嵌入式系统 🍉🍉二、嵌入式系统操作 🍉🍉三、嵌入式Linux的特点 🍉🍉四、嵌入式系统的组成 1、硬件和软件 2、硬件层 3、中间层 4、软件层 5、 功能层与执…...

升讯威在线客服系统是如何实现对 IE8 完全完美支持的(怎样从 WebSocket 降级到 Http)【干货】
简介 升讯威在线客服与营销系统是基于 .net core / WPF 开发的一款在线客服软件,宗旨是: 开放、开源、共享。努力打造 .net 社区的一款优秀开源产品。 完整私有化包下载地址 💾 https://kf.shengxunwei.com/freesite.zip 当前版本信息 发布…...
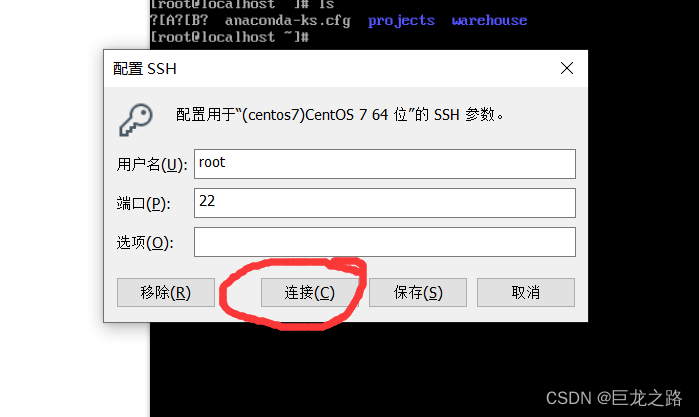
用VMware给运行在VMware上的CentOS7生成一个以SSH方式连接VMware上的CentOS7的运行在Windows上的命令行窗口
2023年7月27日,周四早上 目录 一个发现生成方法如果上面的方法连接失败,就采取这个方法 一个发现 今天早上无意间发现VMware可以生成一个以SSH方式连接着CentOS7的Windows命令行窗口, 这样做可以带来一定的便利性 : 方便复制、…...

GEMM内核与MHA中的寄存器分配优化策略
1. GEMM内核与寄存器分配基础解析通用矩阵乘法(GEMM)作为深度学习计算的核心算子,其性能表现直接决定了神经网络训练和推理的效率。在硬件层面,寄存器分配的优劣往往能带来数倍的性能差异。我们以典型的GEMM运算C αAB βC为例&…...

别再手动改路径了!用LabVIEW + MATLAB Script做自动化测试,这份环境配置指南让你效率翻倍
LabVIEW与MATLAB深度整合:构建自动化测试系统的工程实践指南在工业自动化与测试测量领域,LabVIEW和MATLAB的组合堪称黄金搭档。LabVIEW擅长硬件接口和实时控制,而MATLAB在算法开发和数据分析方面具有无可比拟的优势。本文将深入探讨如何将两者…...
)
Python基础语法:生成器 generator(yield)
一、简介根据指定的规则循环生成数据,当条件不成立时则生成数据结束。数据不是一次性全部生成出来,而是使用一个,再生成一个,好处是可以节约大量的内存。就像设计模式中的懒汉式。适合处理大数据或流数。生成器是一种特殊的迭代器…...

照着用就行:2026 最新降AIGC软件测评与推荐
2026年真正好用的AI论文降重与改写工具,核心看降重效果、去AI味、格式保留、学术适配四大指标。综合实测,千笔AI、ThouPen、豆包、DeepSeek、Grammarly 是当前最值得推荐的梯队,覆盖从免费到付费、从中文到英文、从文科到理工的全场景需求。 …...

Python PIL 画矩形框
基础代码 from PIL import Image, ImageDraw# 打开图片 img Image.open(your_image.jpg)# 创建绘图对象 draw ImageDraw.Draw(img)# 矩形坐标 (x1, y1, x2, y2) coords (23, 21, 69, 76)# 画矩形框(红色,线宽2) draw.rectangle(coords, ou…...

Unity Visual Scripting不是拖拽玩具:中阶开发者的编程范式重构指南
1. 为什么Unity官方Visual Scripting不是“拖拽完就能跑”的玩具,而是一套需要重新理解的编程范式很多人第一次点开Unity的Visual Scripting(VS)面板时,看到那些五颜六色的节点和丝滑的连线,下意识觉得:“这…...
)
告别硬编码!在UE5.1里用蓝图动态配置MySQL连接参数(控件蓝图实战)
动态配置MySQL连接:UE5.1控件蓝图的工程化实践在游戏开发中,数据库连接往往是项目架构中不可或缺的一环。传统硬编码方式虽然简单直接,却带来了维护困难、安全性差、灵活性低等一系列问题。本文将深入探讨如何在UE5.1中构建一个完全动态化的M…...

16个分片+2副本:pg_shard的master_create_worker_shards最佳实践
16个分片2副本:pg_shard的master_create_worker_shards最佳实践 【免费下载链接】pg_shard ATTENTION: pg_shard is superseded by Citus, its more powerful replacement 项目地址: https://gitcode.com/gh_mirrors/pg/pg_shard pg_shard作为PostgreSQL的分…...

航空发动机叶片三维扫描-诺斯顿
航空发动机叶片作为发动机的核心动力部件,其精度与性能直接决定发动机的推力、燃油效率及运行安全性,三维扫描技术作为航空制造领域的核心数字化手段,已广泛应用于叶片全生命周期的多个关键环节。其应用涵盖叶片研发设计阶段的逆向工程&#…...

DIY四路自动音频源切换器:从信号检测到继电器隔离的完整设计
1. 项目概述与核心需求解析作为一个喜欢在工作室里捣鼓各种音频设备的玩家,我经常遇到一个挺烦人的问题:我的功放只有一组输入,但我想接的设备却有好几个——台式电脑、平板、蓝牙接收模块,还有一台树莓派。每次想切换音源&#x…...