使用langchain与你自己的数据对话(二):向量存储与嵌入

之前我以前完成了“使用langchain与你自己的数据对话(一):文档加载与切割”这篇博客,没有阅读的朋友可以先阅读一下,今天我们来继续讲解deepleaning.AI的在线课程“LangChain: Chat with Your Data”的第三门课:向量存储与嵌入。
Langchain在实现与外部数据对话的功能时需要经历下面的5个阶段,它们分别是:Document Loading->Splitting->Storage->Retrieval->Output,如下图所示:
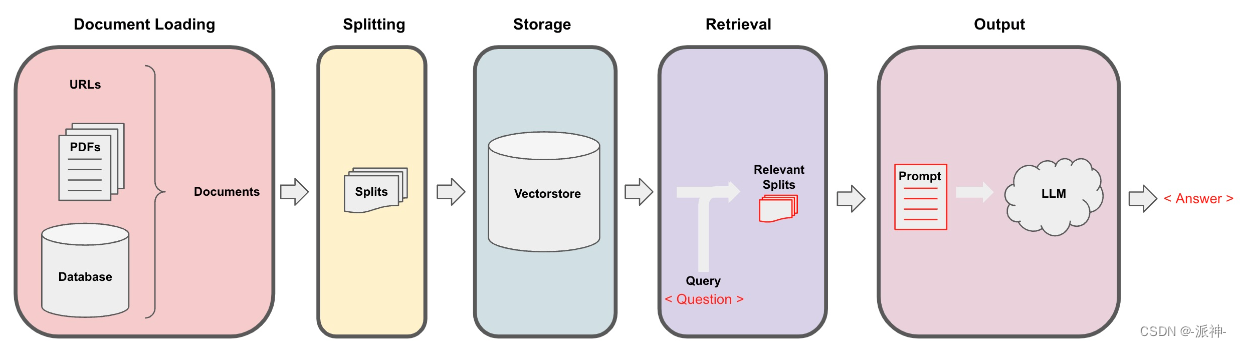
在上一篇博客:文档加载与切割中我已经介绍了如何使用Langchain来加载外部的文档,以及如何切割文档,之所以要对文档做加载与切割的操作,是因为外部数据类型和属性有所不同,比如外部数据可能是pdf, text, 网页,youtube视频等,要读取不同类型的外部数据我们就需要有专门的Loader来加载这些数据,所以我们就需要各种类型的文档加载器,当数据被加载器加载以后,接下来我们需要做文档的切割,这是因为外部数据的体量可能比较大,如pdf文档可能会有几十页,几百页的内容,所以我们需要将文档内容按一点尺寸(chunk_size)均匀的切成小块(chunks), 在上一篇博客中我们介绍了几种Langchain常用的文档切割器如RecursiveCharacterTextSplitter, CharacterTextSplitter,TokenTextSplitter,MarkdownHeaderTextSplitter等,其中Langchain默认使用RecursiveCharacterTextSplitter切割器。当文档被切割以后,加下来就到了嵌入(Embeddings)和向量存储(vectorstores)的环节,如下图所示:
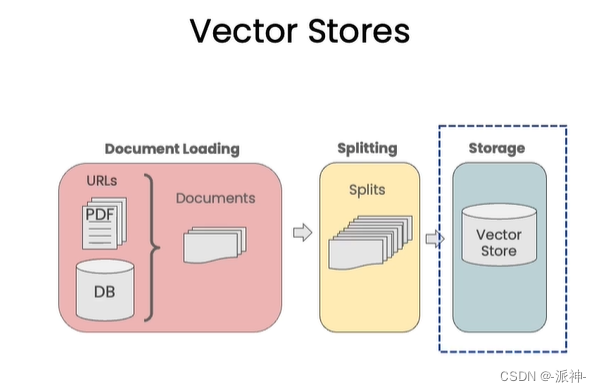
所谓的向量存储是指被切割的文档需要经过向量化操作以后存储到向量数据库的过程,因为大型语言模型(LLM)无法理解文字信息(只能理解数字),所以我们必须对文字信息进行编码,这里说的编码就是只嵌入(Embeddings), 嵌入操作可以将文本转换成数字编码并以向量的形式存储在向量数据库中,如下图所示:
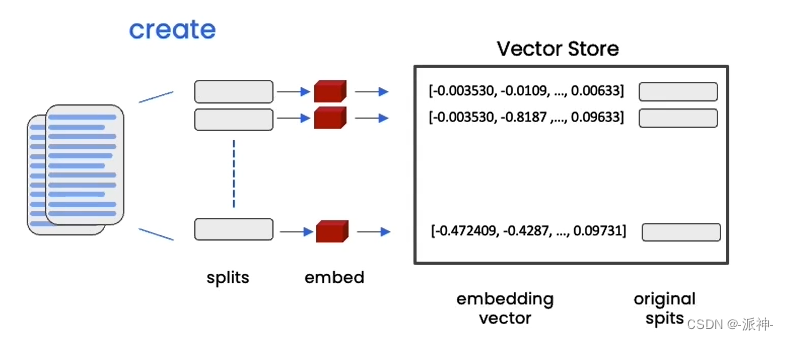
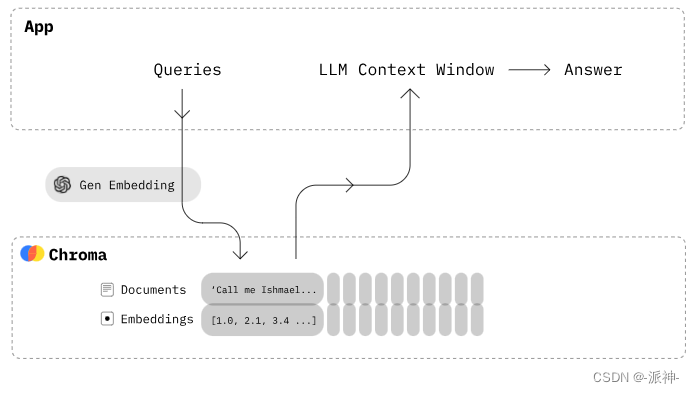
当文档被切割成块(chunks)后,每一个块都会经嵌入操作后转换成向量并存储在向量数据库中,当用户对文档内容提出问题时,用户的问题也会经嵌入操作后被转换成向量并与向量数据库中的所有向量做相似度比较,最后找出与问题最相关的n个向量,如下图所示:
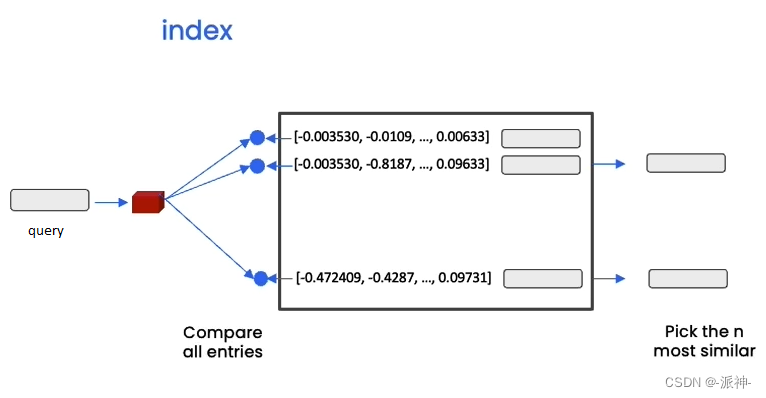
当找到与用户问题最相关的n个向量以后,这些向量会被还原成原始文本,然后将用户的问题和这些文本信息发送给LLM, LLM会针对用户的问题对这些文本内容做提炼和汇总,最后给出正确合理的答案,如下图所示:
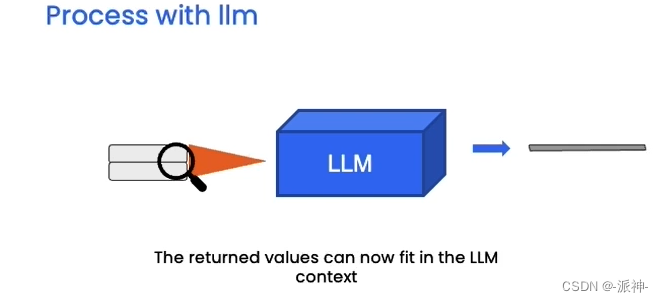
整个与文档对话的过程大致就是这样,下面我们来实操一下上面的嵌入和向量存储的过程,不过首先我们还是需要做一下些基础性工作,比如设置一下openai的api key:
import os
import openai
import sys
sys.path.append('../..')from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv()) # read local .env fileopenai.api_key = os.environ['OPENAI_API_KEY']Document Loading & Splitting
接下来我们首先来实现文档的加载和切割,这里我们会加载一组吴恩达老师著名的机器学习课程cs229的pdf讲义稿:
from langchain.document_loaders import PyPDFLoader# Load PDF
loaders = [# Duplicate documents on purpose - messy dataPyPDFLoader("docs/cs229_lectures/MachineLearning-Lecture01.pdf"),PyPDFLoader("docs/cs229_lectures/MachineLearning-Lecture01.pdf"),PyPDFLoader("docs/cs229_lectures/MachineLearning-Lecture02.pdf"),PyPDFLoader("docs/cs229_lectures/MachineLearning-Lecture03.pdf")
]
docs = []
for loader in loaders:docs.extend(loader.load())需要说明一下的是这里我们加载了2篇相同的pdf文档:Lecture01.pdf,之所以要加载两篇相同的pdf文档,是为了后面我们需要做一些测试看看当文档内容相同的时候LLM的表现。当文档完成加载以后,下面我们就需要对文档进行切割,首先我们需要创建一个文档切割器RecursiveCharacterTextSplitter:
# Split
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(chunk_size = 1500,chunk_overlap = 150
)这里关于参数chunk_size ,和chunk_overlap 的含义在文档加载与切割这篇博客中已经详细说明过了,这里不再赘述。当文档切割器创建完成以后,我们可以开始切割文档的操作:
#切割文档
splits = text_splitter.split_documents(docs)#查看切割后文档的数量
print(len(splits))![]()
这里我们看到切割后的文档长度是209,也就是说所有的pdf文档被切割成了209块(chunks),我们可以查看其中的某一块的文档内容:
splits[0] 
我们看到被切换的文档块中包含了文档的内容(page_content)和元数据(metadata),在元数据中记录了文档的位置和该块内容所在的页数。那么现在在splits中就包含了209个这样的文档块。
Embeddings
所谓的嵌入(Embeddings)是一种文本的编码的方法,它可以一段文字转换成一定长度的一组向量,下面我们来做一下简单的embedding测试:
from langchain.embeddings.openai import OpenAIEmbeddings
embedding = OpenAIEmbeddings()sentence1 = "我喜欢小狗。"
sentence2 = "我喜欢小动物。"
sentence3 = "我今天心情很差。"embedding1 = embedding.embed_query(sentence1)
embedding2 = embedding.embed_query(sentence2)
embedding3 = embedding.embed_query(sentence3)这里我们有三句简单的中文句子,前两句表达人和动物之间的关系,第三句表达人的心情,所以前两句的含义应该比较相似,后第三句和前两句的含义完全不同,下面我们可以通过计算两个向量的点积来得到两个向量的相似度:
np.dot(embedding1, embedding2) 
np.dot(embedding1, embedding3) 
np.dot(embedding2, embedding3) 
我们可以看到embedding1与embedding2之间有较高的相似性达到了0.94,而embedding3与embedding1和embedding2的相似度只都只有0.8以下,这说明第一句和第二句话有较高的相似度。下面我们看一下经过embedding操作以后的结果是怎么样的:
print(embedding1) 
这里我们看到经过embdding操作后生成的向量是一个python的list, 其中包含了很多数字,下面我们再看一下这个embdding的长度:
print(len(embedding1))![]()
这里我们可以看到经过embdding操作以后生成的向量的长度是1536,也就是说由1536个数字来表示了被embdding的这句文本,我们也可以看成是由1536个维度来表示这句文本。
向量数据库
当我们知道了Embedding的原理以后,接下来我们来介绍一种向量数据库Chroma,Chroma 是开源嵌入(Embedding)数据库。Chroma 通过为大型语言模型(LLM)提供可嵌入的知识、事实和技能,让构建大型语言模型(LLM)的应用程序变得更加容易,如下图所示:
接下来我们来实际操作创建向量数据库的过程,并且将生成的向量数据库保存在本地。当我们在创建Chroma数据库时,我们需要传递如下参数:
- documents: 切割好的文档对象
- embedding: embedding对象
- persist_directory: 向量数据库存储路径
from langchain.vectorstores import Chroma#向量数据库保存位置
persist_directory = 'docs/chroma/'#创建向量数据库
vectordb = Chroma.from_documents(documents=splits,embedding=embedding,persist_directory=persist_directory
)#查看向量数据库中的文档数量
print(vectordb._collection.count()) ![]()
这里我们看到向量数据库中存储这209个向量,这和我们之前切割文档后的splits 中的数量是一至的,这说明原来209个文档块已经被转换成了209个向量并且被保存在了Chroma数据库中。
相似度搜索(Similarity Search)
当文档被切割并经embedding操作后转换成向量存储到Chroma数据库中后,我们可以对Chroma数据库中的向量进行相似度的比较,也就是我们可以模拟用户提出问题,然后去Chroma执行相似内容搜索,并返回与问题相似度较高的文本内容:
question = "is there an email i can ask for help"docs = vectordb.similarity_search(question,k=3)#打印文档数量
print(len(docs))![]()
这里我们要求向量数据库对问题进行相似度搜索,找出和问题最相关的3个(k=3)文档。下面我们查看其中的一个文档的内容:
docs[0].page_content
我们看到第一篇文档中包含了"email"这个单词,这和我们的问题显然是相关的。接下来我们来实现向量数据库的持久化:
vectordb.persist()执行了persist()操作以后向量数据库才真正的被保存到了本地,下次在需要使用该向量数据库时我们只需要从本地加载数据库即可,无需再根据原始文档来生成向量数据库了。
失败的应用场景
虽然有了向量数据库,基本上可以让我们轻松完成 80% 的相似性搜索任务。但也存在一些失败的场景,比如下面的例子:
question = "what did they say about matlab?"docs = vectordb.similarity_search(question,k=5)这里我们要求向量数据库搜索5个和问题相关的答案,但是大家还记得之前我们在创建文档加载器时加载了两篇相同的文档(Lecture01.pdf),所以现在向量数据库中应该有重复的向量,因此如果当用户的问题和Lecture01.pdf中的内容相关时,向量数据库会返回重复的内容:
docs[0]
docs[1] 
这两我们看到docs[0]和docs[1]的内容是完全一样的,这是因为我们之前加载了重复的文档(Lecture01.pdf)所导致的。如何避免让向量数据库返回重复的内容,我们将在下一篇博客中讨论这个问题,下面我们再看一种失败的场景,这里我们要求向量数据库在第三篇原始文档()中搜索相关答案:
question = "what did they say about regression in the third lecture?"docs = vectordb.similarity_search(question,k=5)for doc in docs:print(doc.metadata)
从上面的返回结果中我们看到,虽然我们要求向量数据库只能从第三篇文档中搜索相关答案,但是从返回结果的元数据中我们看到第一篇(Lecture01.pdf)和第二篇(Lecture02.pdf)的内容也在其中,这与我们的要求(问题)相违背,因为我们只要求搜索第三篇文档(Lecture03.pdf)即可。这似乎说明向量数据库并没有很好的理解问题的语义。下面我们查看一下返回的最后一个文档的内容(Lecture01.pdf):
print(docs[4].page_content)
这里我们看到docs[4]对应的是Lecture01.pdf中的第8页的内容,其中也包含了“regression”,这和我们的问题相关。
关于如何避免上述失效的应用场景,我们将会在下一篇博客中进行讨论。
总结
今天我们学习了嵌入和向量数据库的基本原理,并且对嵌入(Embeddings)和开源数据库Chroma进行了实际的操作,并观察了它们的返回结果,同时我们还发现了两种Chroma数据库相似搜索失效的场景。关于如何避免产生失效的结果我们将在下一篇博客中进行讨论。
参考资料
🏡 Home | Chroma
Chroma | 🦜️🔗 Langchain
相关文章:
使用langchain与你自己的数据对话(二):向量存储与嵌入
之前我以前完成了“使用langchain与你自己的数据对话(一):文档加载与切割”这篇博客,没有阅读的朋友可以先阅读一下,今天我们来继续讲解deepleaning.AI的在线课程“LangChain: Chat with Your Data”的第三门课:向量存储与嵌入。 …...

No105.精选前端面试题,享受每天的挑战和学习
文章目录 手写new手写Mapget和post区别发起post请求的时候,服务端是怎么解析你的body的(content-type),常见的content-type都有哪些,发文件是怎么解析的(FormData),如果多个文件&…...

【计算机网络】第 3 课 - 计算机网络体系结构
欢迎来到博主 Apeiron 的博客,祝您旅程愉快 ! 时止则止,时行则行。动静不失其时,其道光明。 目录 1、常见的计算机网络体系结构 2、计算机网络体系结构分层的必要性 2.1、物理层 2.2、数据链路层 2.3、网路层 2.4、运输层 2…...

精细呵护:如何维护自己的电脑,提升性能和寿命
导语: 在当今数字化时代,电脑已经成为我们日常生活和工作的必需品。然而,就像任何其他设备一样,电脑需要得到适当的维护和保养,以保持良好的性能和延长使用寿命。在本文中,我们将分享一些简单而有效的方法&…...
DevOps-Jenkins
Jenkins Jenkins是一个可扩展的持续集成引擎,是一个开源软件项目,旨在提供一个开放易用的软件平台,使软件的持续集成变成可能。 官网 应用场景 场景一 研发人员上传开发好的代码到github代码仓库需要将代码下载nginx服务器部署手动下载再…...

Jasper裁员,成也GPT,败也GPT
大家好! 我是老洪。 今天来聊一聊人工智能(artificial intelligence),简称AI。 当前的AI可谓是热火朝天, 自从ChatGPT发布以来,引起了广泛的关注和热情, 许多公司和研究者都试图将其应用于自己的产品或研究中。 按理说…...
安卓开发后台应用周期循环获取位置信息上报服务器
问题背景 最近有需求,在APP启动后,退到后台,还要能实现周期获取位置信息上报服务器,研究了一下实现方案。 问题分析 一、APP退到后台后网络请求实现 APP退到后台后,实现周期循环发送网络请求。目前尝试了两种方案是…...

为什么你的独立站有流量没转化?如何做诊断检查?
新店的创业初期,即使网站有流量,但是销售额为零的情况也常有发生。如果你确定流量是高质量的,寻找阻止潜在客户购买的具体因素可能会感到困难重重。 从“立即购买”按钮的色彩选择这样的细节,到构建品牌故事这样的大计划…...

【深度学习】【三维重建】windows10环境配置PyTorch3d详细教程
【深度学习】【三维重建】windows10环境配置PyTorch3d详细教程 文章目录 【深度学习】【三维重建】windows10环境配置PyTorch3d详细教程前言确定版本对应关系源码编译安装Pytorch3d总结 前言 本人windows10下使用【Code for Neural Reflectance Surfaces (NeRS)】算法时需要搭…...
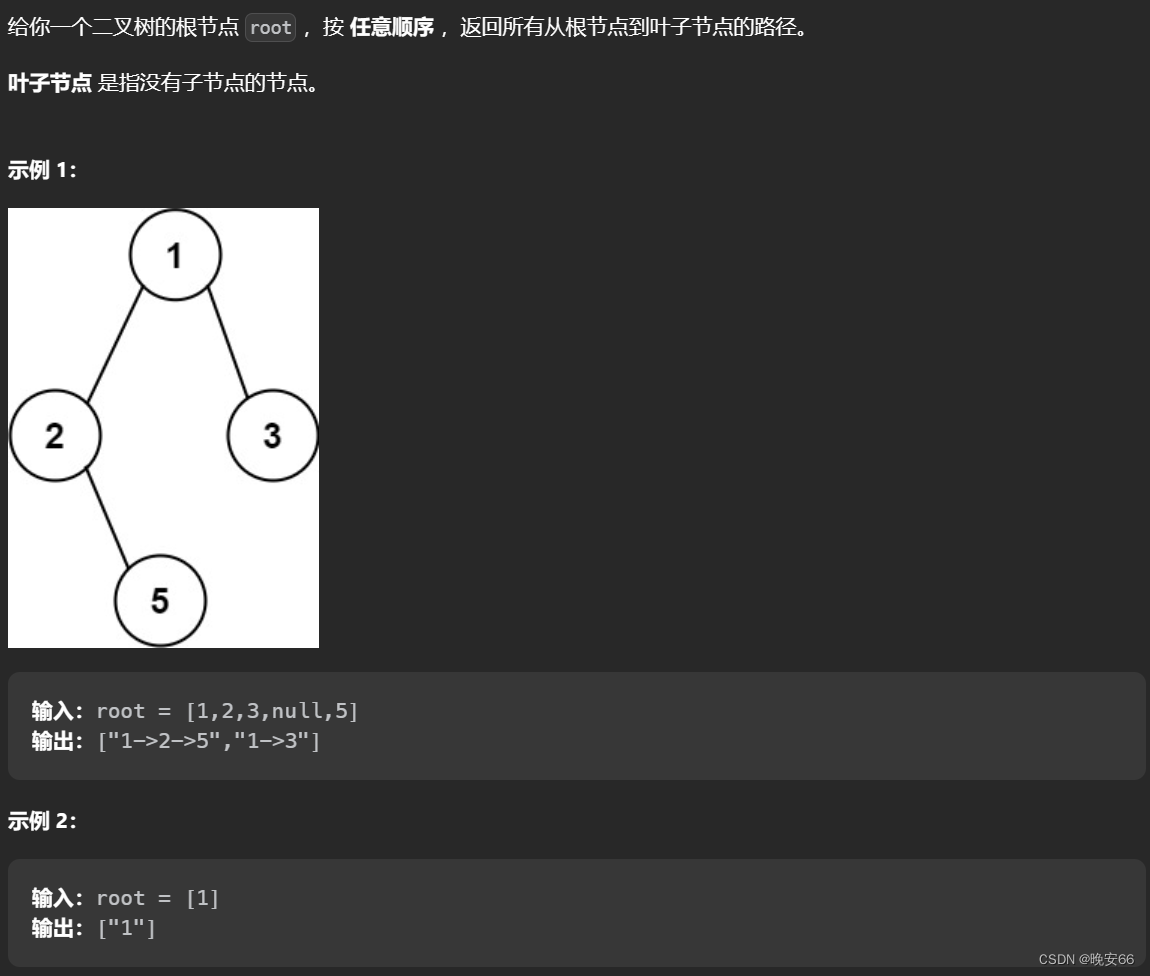
【算法和数据结构】257、LeetCode二叉树的所有路径
文章目录 一、题目二、解法三、完整代码 所有的LeetCode题解索引,可以看这篇文章——【算法和数据结构】LeetCode题解。 一、题目 二、解法 思路分析:首先看这道题的输出结果,是前序遍历。然后需要找到从根节点到叶子节点的所有路径ÿ…...
yolov5的后处理解析
由于最近实习项目使用到了yolov5, 发现对yolov5的后处理部分不太熟悉,为防止忘记,这里简单做个记录。 在yolov5里,利用FPN特征金字塔,可以得到三个加强特征层,每一个特征层上每一个特征点存在3个先验框&am…...
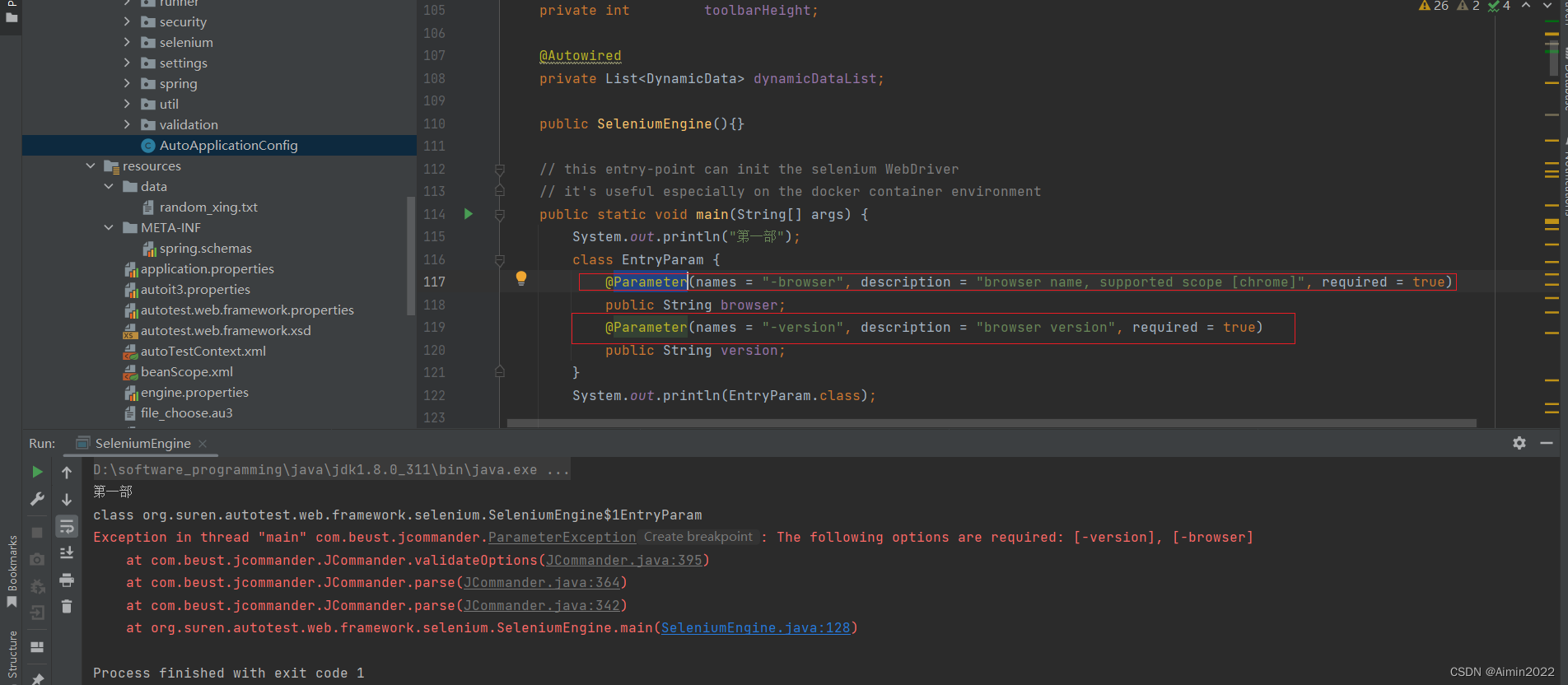
Java中注解应用场景
1.Parameter注解 Parameter(names "-browser", description "browser name, supported scope [chrome]", required true) Param注解的用法解析_parameter_fFee-ops的博客-CSDN博客 Public User selectUser(param(“userName”) String name, param(“…...

verilog
数据类型 reg reg [3:0] counter; counter是一个寄存器,这个寄存器有4bit大小; reg [3:0] byte1 [7:0]; 有8个寄存器,每个4bit大小; wire 有符号整数 interge 无符号 reg clk_temp (小数)verilog中称实数…...
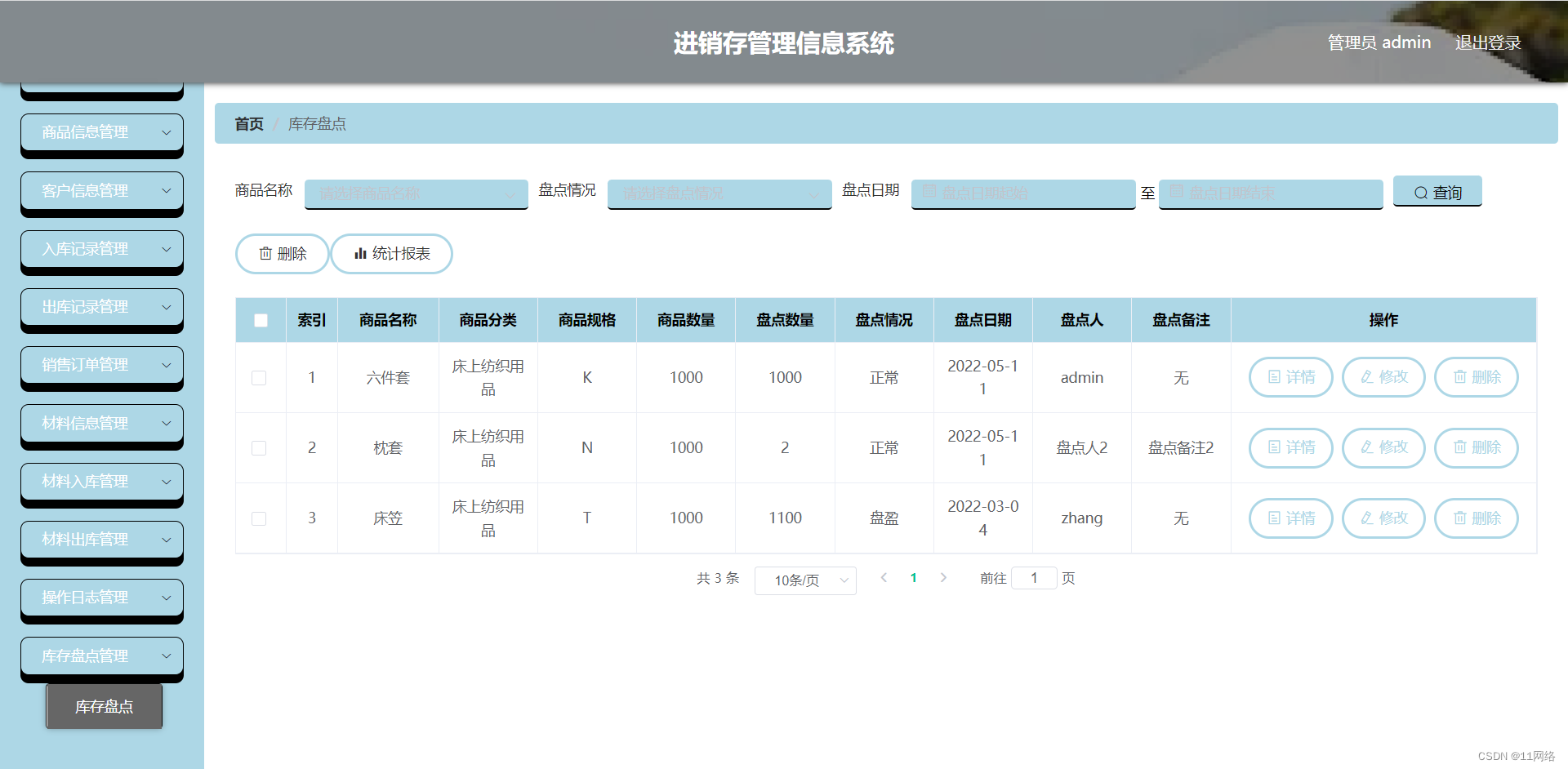
基于springboot+mybatis+vue进销存管理信息系统
基于springbootmybatisvue进销存管理信息系统 一、系统介绍二、功能展示1.个人中心2.企业信息管理3.商品信息管理4.客户信息管理5.入库记录管理6.出库记录管理7.出库记录管理8.操作日志管理9.库存盘点管理 四、获取源码 一、系统介绍 系统主要功能: 普通用户&#…...

Keepalived 在CentOS安装
下载 有两种下载方式,一种为yum源下载,另一种通过源代码下载,本文章使用源代码编译下载。 官网下载地址:https://www.keepalived.org/download.html wget https://www.keepalived.org/software/keepalived-2.0.20.tar.gz --no-…...

Lua语法学习
Lua 文章目录 Lua变量数据类型nilbooleanstringtable 循环if函数运算符Table -- Events local StateEvents ReplicatedStorage:WaitForChild("StateEvents"); local AddMoneyEvent StateEvents:WaitForChild("AddMoneyEvent");AddMoneyEvent:FireServer(…...
【Ajax】笔记-jsonp实现原理
JSONP JSONP是什么 JSONP(JSON With Padding),是一个非官方的跨域解决方案,纯粹凭借程序员的聪明才智开发出来的,只支持get请求。JSONP 怎么工作的? 在网页有一些标签天生具有跨域能力,比如:img link iframe script. …...
LLM - Chinese-Llama-2-7b 初体验
目录 一.引言 二.模型下载 三.快速测试 四.训练数据 五.总结 一.引言 自打 LLama-2 发布后就一直在等大佬们发布 LLama-2 的适配中文版,也是这几天蹲到了一版由 LinkSoul 发布的 Chinese-Llama-2-7b,其共发布了一个常规版本和一个 4-bit 的量化版本…...
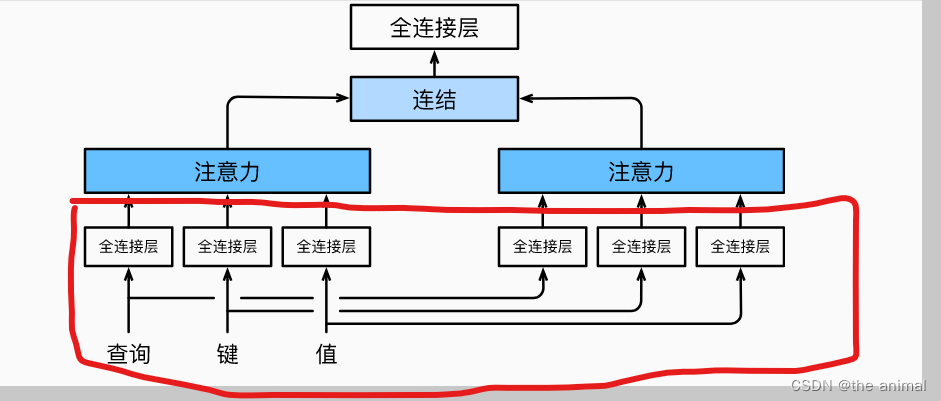
transformer代码注解
其中代码均来自李沐老师的动手学pytorch中。 class PositionWiseFFN(nn.Module):ffn_num_inputs 4ffn_num_hiddens 4ffn_num_outputs 8def __init__(self,ffn_num_inputs,ffn_num_hiddens,ffn_num_outputs):super(PositionWiseFFN,self).__init__()self.dense1 nn.Linear(ffn…...
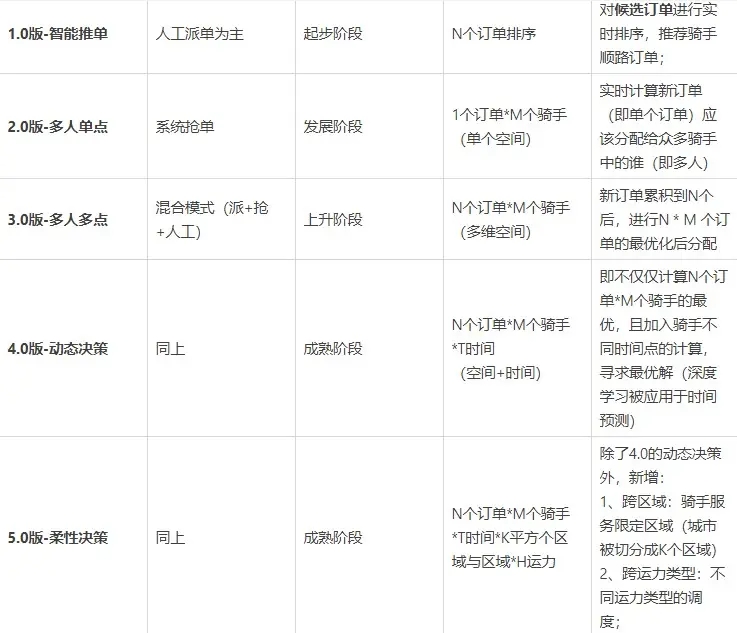
【产品经理】高阶产品如何处理需求?(3方法论+2案例+1清单)
不管你是萌新小白,还是工作了几年的“老油条”,需求一直是产品经理工作的重点。只不过,不同年限的产品经理需要面对的需求大有不同,对能力的要求更高。 不知你是否遇过以下问题? 你接手一个项目后,不知从何…...

基于LM22678的树莓派硬盘专用电源设计:解决供电不稳与电流冲击
1. 项目概述:为什么我们需要一个“专用”电源?如果你正在用树莓派搭配一块机械硬盘搭建一个家庭服务器或者个人云存储,可能已经遇到了一个不大不小的麻烦:供电不稳。树莓派官方推荐的5V/3A电源,单独带树莓派4B跑满负载…...

航空航天为什么离不开高强镁合金?国产替代到哪一步了
飞机每减重一千克,全年大约节省四千两百美元的燃油费用——这是航空工程师熟悉的经验值。在商业航空领域,这个数字还只是财务账;在战斗机、导弹和卫星的世界里,减重的收益被换算成更远的航程、更大的载荷、更高的机动性࿰…...

账务台账数据
银行里说的 “账务台账数据”,本质就是按会计规则把每笔业务逐笔、分户、分科目记下来的完整明细流水 余额 辅助信息,核心是 “可逐笔追溯、可对账、可审计” 的一套明细数据。下面用通俗、具体的方式拆开说:一、银行 “账务台账” 到底是什…...
)
YOLOv8晶圆体缺识别检测系统(项目源码+YOLO数据集+模型权重+UI界面+python+深度学习+环境配置)
摘要 晶圆制造过程中的缺陷检测是保证芯片良率的关键环节。本文基于YOLOv8目标检测算法,构建了一套针对晶圆表面9类典型缺陷的自动检测系统。所识别的缺陷类型包括:Center、Donut、Edge-Loc、Edge-Ring、Loc、Near-full、None、Random、Scratch。模型在…...

独立开发者如何利用Taotoken Token Plan,以更低成本启动AI项目
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 独立开发者如何利用Taotoken Token Plan,以更低成本启动AI项目 对于独立开发者或小型团队而言,启动一个集成…...

超低功耗电池电压监控电路设计:从LM324到LPV324的硬件方案优化
1. 项目概述与核心需求解析在捣鼓各种电池供电的电子设备时,无论是自己做的无线传感器节点、便携式小工具,还是给孩子改装的玩具,有一个问题总是绕不开:你怎么知道电池快没电了?总不能每次都等到设备彻底罢工ÿ…...

机器学习在射电天文数据分类中的应用:以MIGHTEE巡天SFG/AGN分类为例
1. 项目概述:当机器学习遇见深空射电巡天在射电天文学领域,我们正经历一场数据洪流。以MeerKAT望远镜阵列主导的MIGHTEE巡天项目为例,其在COSMOS天区的一次早期科学数据释放,就在不到1平方度的天区内探测到了超过6000个射电源。传…...

如何通过Joy-Con Toolkit实现专业级Switch手柄控制与硬件逆向工程
如何通过Joy-Con Toolkit实现专业级Switch手柄控制与硬件逆向工程 【免费下载链接】jc_toolkit Joy-Con Toolkit 项目地址: https://gitcode.com/gh_mirrors/jc/jc_toolkit 在游戏开发、硬件调试和嵌入式系统研究中,与游戏手柄等专业输入设备进行深度交互一直…...

完整指南:如何在5分钟内快速上手BioAge生物年龄计算工具包
完整指南:如何在5分钟内快速上手BioAge生物年龄计算工具包 【免费下载链接】BioAge Biological Age Calculations Using Several Biomarker Algorithms 项目地址: https://gitcode.com/gh_mirrors/bi/BioAge BioAge生物年龄计算工具包是一款基于R语言开发的强…...

Unity中实现深度遮挡:LingBot-Depth实战接入与优化
1. 这不是“加个插件就完事”的AR效果——为什么LingBot-Depth在Unity里值得专门写一篇实战教程你肯定见过那种AR应用:虚拟椅子摆在真实地板上,但当你绕到椅子后面,它依然完整显示,完全无视身后那堵真实的墙;或者一只3…...