LLM - Chinese-Llama-2-7b 初体验

目录
一.引言
二.模型下载
三.快速测试
四.训练数据
五.总结
一.引言
自打 LLama-2 发布后就一直在等大佬们发布 LLama-2 的适配中文版,也是这几天蹲到了一版由 LinkSoul 发布的 Chinese-Llama-2-7b,其共发布了一个常规版本和一个 4-bit 的量化版本,今天我们主要体验下 Llama-2 的中文逻辑顺便看下其训练样本的样式,后续有机会把训练和微调跑起来。
二.模型下载
HuggingFace: https://huggingface.co/LinkSoul/Chinese-Llama-2-7b
4bit 量化版本: https://huggingface.co/LinkSoul/Chinese-Llama-2-7b-4bit
这里我们先整一版量化版本:
省事且网络好的同学可以直接用 Hugging Face 的 API 下载,网不好就半夜慢慢下载吧。
from huggingface_hub import hf_hub_download, snapshot_downloadsnapshot_download(repo_id="LinkSoul/Chinese-Llama-2-7b-4bit", local_dir='./models')三.快速测试
Tips 测试用到的基本库的版本,运行显卡为 Tesla-V100 32G:
python 3.9.11
numpy==1.23.5
torch==2.0.1
transformers==4.29.1
测试代码:
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, TextStreamer# Original version
# model_path = "LinkSoul/Chinese-Llama-2-7b"
# 4 bit version
model_path = "/models/LLama2_4bit"tokenizer = AutoTokenizer.from_pretrained(model_path, use_fast=False)
if model_path.endswith("4bit"):model = AutoModelForCausalLM.from_pretrained(model_path,torch_dtype=torch.float16,device_map='auto')
else:model = AutoModelForCausalLM.from_pretrained(model_path).half().cuda()
streamer = TextStreamer(tokenizer, skip_prompt=True, skip_special_tokens=True)instruction = """[INST] <<SYS>>\nYou are a helpful, respectful and honest assistant. Always answer as helpfully as possible, while being safe. Your answers should not include any harmful, unethical, racist, sexist, toxic, dangerous, or illegal content. Please ensure that your responses are socially unbiased and positive in nature.If a question does not make any sense, or is not factually coherent, explain why instead of answering something not correct. If you don't know the answer to a question, please don't share false information.\n<</SYS>>\n\n{} [/INST]"""while True:text = input("请输入 prompt\n")if text == "q":breakprompt = instruction.format(text)generate_ids = model.generate(tokenizer(prompt, return_tensors='pt').input_ids.cuda(), max_new_tokens=4096, streamer=streamer)★ 常规测试
知识:

推理:

★ 一些 Bad Case
知识错乱:

重复:

这里由于是 4-bit 的量化版本,模型的效果可能也会受影响,可以看到图中原始 LLama2 的知识能力相对还算不错。
四.训练数据
LinkSoul 在 LLama2 的基础上使用了中英文 SFT 数据集,数据量 1000 万:
LinkSoul/instruction_merge_set · Datasets at Hugging Face
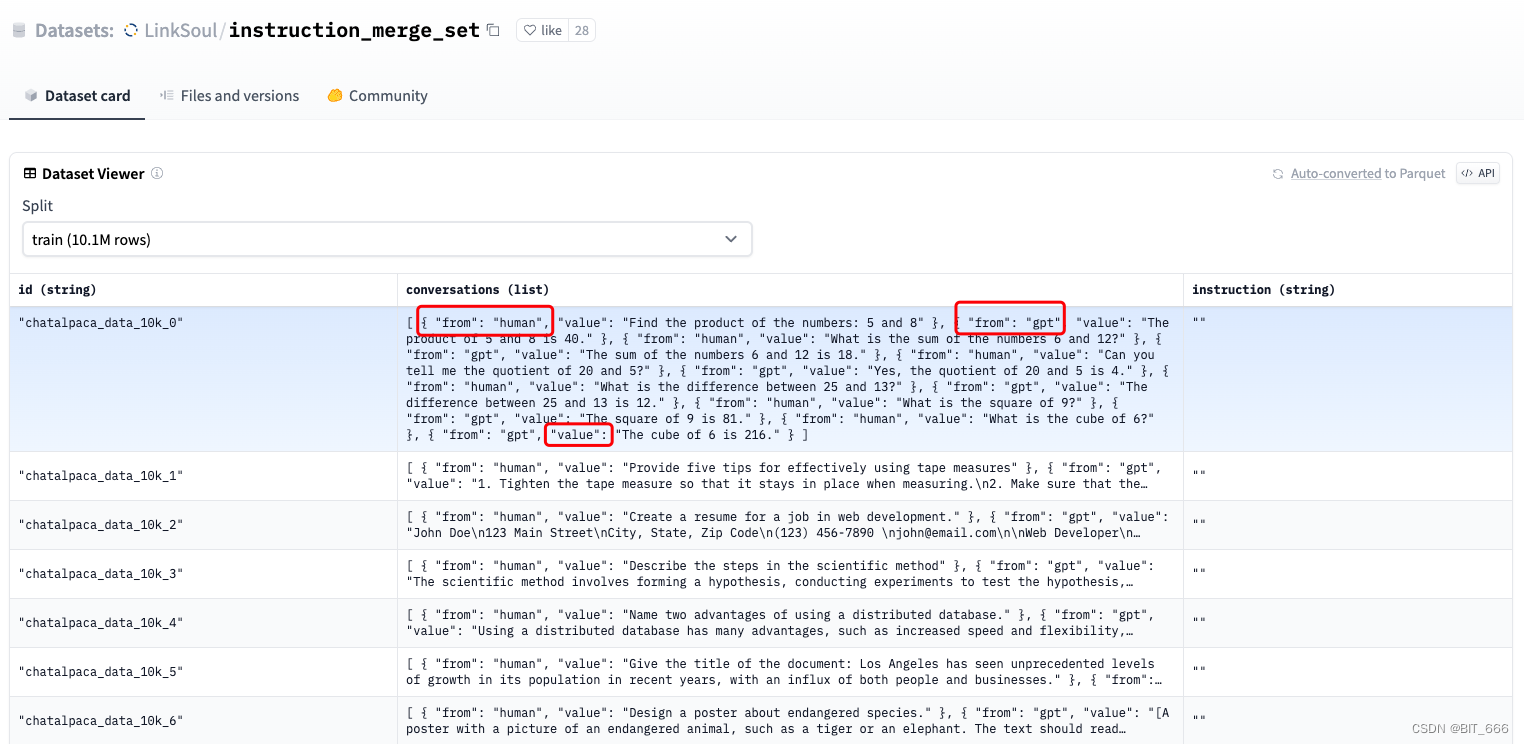
给定的数据是 parquet 格式的:
{"instruction":"","id":"chatalpaca_data_10k_0","conversations":"WrappedArray([human,Find the product of the numbers: 5 and 8], [gpt,The product of 5 and 8 is 40.], [human,What is the sum of the numbers 6 and 12?], [gpt,The sum of the numbers 6 and 12 is 18.], [human,Can you tell me the quotient of 20 and 5?], [gpt,Yes, the quotient of 20 and 5 is 4.], [human,What is the difference between 25 and 13?], [gpt,The difference between 25 and 13 is 12.], [human,What is the square of 9?], [gpt,The square of 9 is 81.], [human,What is the cube of 6?], [gpt,The cube of 6 is 216.])"}
{"instruction":"","id":"chatalpaca_data_10k_1","conversations":"WrappedArray([human,Provide five tips for effectively using tape measures], [gpt,1. Tighten the tape measure so that it stays in place when measuring.\n2. Make sure that the hook of the tape measure hits the starting point precisely.\n3. Allow for a bit of slack when measuring around curves or corners.\n4. Measure from a stable surface, such as a table or workbench.\n5. Mark the beginning and end of each measurement with a pen or marker.], [human,Can you give me an example of when to use tip number three, \"Allow for a bit of slack when measuring around curves or corners\"?], [gpt,Sure! Let's say you're measuring the circumference of a circular object, like a pipe. If you pull the tape measure too tightly, you won't get an accurate measurement because the tape measure will be stretched out of its original shape, making the measurement longer than it should be. Instead, you should wrap the tape measure around the curve or corner of the object without pulling it too tightly. This way, you'll get a more accurate measurement that takes into account the shape of the object.], [human,Can you tell me more about the markers or pens that should be used to mark the measurements? Do you recommend a certain type of pen?], [gpt,As an AI language model, I do not have personal preferences as a human, but there are certain types of markers or pens that are better suited for marking measurements than others. For example, a fine-tipped marker or mechanical pencil is great for making precise marks on a tape measure, because they produce a precise line that is easy to see. You'll want to avoid using a ballpoint pen or a marker with a thick tip, since these types of pens can produce marks that are too thick or blurry, making it difficult to accurately read the measurement. It's also a good idea to choose a marker or pen that is a different color than the color of the tape measure, so that you can easily distinguish your marks from the printed markings on the tape measure.], [human,Are there any other tips you recommend for maintaining tape measures in good condition? \n\nassistant: \nYes! One tip is to keep your tape measure clean and free from debris, so that it moves smoothly and doesn't get jammed or stuck. You can use a soft cloth or a brush to wipe down the tape measure after each use, and make sure to store it in a dry place to prevent rust or corrosion. Another tip is to avoid dropping or mishandling the tape measure, since this can damage the internal components and make it less accurate. It's also a good idea to periodically check your tape measure against a known length or standard to make sure that it is still measuring accurately.], [gpt,Finally, when retracting the tape measure, avoid letting it snap back quickly, as this can cause the tape to twist or become tangled. Instead, hold it firmly and retract it slowly and steadily to avoid damaging the internal components. With proper care and maintenance, your tape measure should last for years and provide accurate measurements every time.], [human,Goodbye.])"}instruction 指令可选,剩下 conversations 里是 human 和 gpt 的多轮对话。
def tokenize(item, tokenizer):roles = {"human": "user", "gpt": "assistant"}input_ids = []labels = []if "instruction" in item and len(item["instruction"]) > 0:system = item["instruction"]else:system = dummy_message["system"]system = B_SYS + system + E_SYS# add system before the first content in conversationsitem["conversations"][0]['value'] = system + item["conversations"][0]['value']for i, turn in enumerate(item["conversations"]):role = turn['from']content = turn['value']content = content.strip()if role == 'human':content = f"{B_INST} {content} {E_INST} "content_ids = tokenizer.encode(content)labels += [IGNORE_TOKEN_ID] * (len(content_ids))else:# assert role == "gpt"content = f"{content} "content_ids = tokenizer.encode(content, add_special_tokens=False) + [tokenizer.eos_token_id] # add_special_tokens=False remove bos token, and add eos at the endlabels += content_idsinput_ids += content_idsinput_ids = input_ids[:tokenizer.model_max_length]labels = labels[:tokenizer.model_max_length]trunc_id = last_index(labels, IGNORE_TOKEN_ID) + 1input_ids = input_ids[:trunc_id]labels = labels[:trunc_id]if len(labels) == 0:return tokenize(dummy_message, tokenizer)input_ids = safe_ids(input_ids, tokenizer.vocab_size, tokenizer.pad_token_id)labels = safe_ids(labels, tokenizer.vocab_size, IGNORE_TOKEN_ID)return input_ids, labels训练代码:https://github.com/LinkSoul-AI/Chinese-Llama-2-7b/blob/main/train.py
中展示了 tokenizer 原始样本的流程:
◆ 根据指令生成 system
◆ 根据 from 和 value 的多轮对话生成 input_ids 和 labels
Tips: 这里会把前面生成的 system 缀到第一个 value 前面,labels 会在 human 部分用 IGNORE_TOKEN_ID 的掩码进行 Mask
◆ 最后 safe_ids 用于限制 id < max_value 超过使用 pad_id 进行填充
def safe_ids(ids, max_value, pad_id):return [i if i < max_value else pad_id for i in ids]这里输入格式严格遵循 llama-2-chat 格式,兼容适配所有针对原版 llama-2-chat 模型的优化。
五.总结
这里简单介绍了 LLama-2 7B Chinese 的推理和数据样式,后续有机会训练和微调该模型。
参考:
Chinese Llama 2 7B: https://github.com/LinkSoul-AI/Chinese-Llama-2-7b
Model: https://huggingface.co/LinkSoul/Chinese-Llama-2-7b
Instruction_merge_set: https://huggingface.co/datasets/LinkSoul/instruction_merge_set/
Download Files: https://huggingface.co/docs/huggingface_hub/v0.16.3/guides/download
相关文章:
LLM - Chinese-Llama-2-7b 初体验
目录 一.引言 二.模型下载 三.快速测试 四.训练数据 五.总结 一.引言 自打 LLama-2 发布后就一直在等大佬们发布 LLama-2 的适配中文版,也是这几天蹲到了一版由 LinkSoul 发布的 Chinese-Llama-2-7b,其共发布了一个常规版本和一个 4-bit 的量化版本…...
transformer代码注解
其中代码均来自李沐老师的动手学pytorch中。 class PositionWiseFFN(nn.Module):ffn_num_inputs 4ffn_num_hiddens 4ffn_num_outputs 8def __init__(self,ffn_num_inputs,ffn_num_hiddens,ffn_num_outputs):super(PositionWiseFFN,self).__init__()self.dense1 nn.Linear(ffn…...
【产品经理】高阶产品如何处理需求?(3方法论+2案例+1清单)
不管你是萌新小白,还是工作了几年的“老油条”,需求一直是产品经理工作的重点。只不过,不同年限的产品经理需要面对的需求大有不同,对能力的要求更高。 不知你是否遇过以下问题? 你接手一个项目后,不知从何…...

Neo4j数据库中导入CSV示例数据
本文简要介绍Neo4j数据库以及如何从CSV文件中导入示例数据,方便我们快速学习测试图数据库。首先介绍简单数据模型以及基本图查询概念,然后通过LOAD CSV命令导入数据,生成节点和关系。 环境准备 读者可以快速安装Neo4j Desktop,启…...
第四章 No.1树状数组的原理与使用
文章目录 应用问题原理树状数组练习题241. 楼兰图腾242. 一个简单的整数问题243. 一个简单的整数问题2244. 谜一样的牛 线段树的反面:树状数组原理复杂,实现简单 应用问题 支持两个操作:快速求前缀和任意地修改某个数,时间复杂度…...

mysql(五)主从配置
目录 前言 一、MySQL Replication概述 二、MySQL复制类型 三、部署MySQL主从异步复制 总结 前言 为了实现MySQL的读写分离,可以使用MySQL官方提供的工具和技术,如MySQL Replication(复制)、MySQL Group Replication(组…...
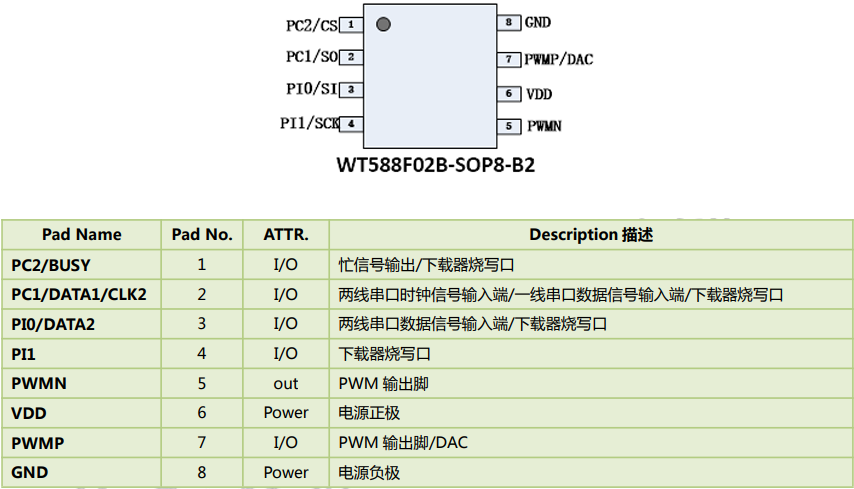
扫地机语音提示芯片,智能家居语音交互首选方案,WT588F02B-8S
智能家居已经成为现代家庭不可或缺的一部分,而语音交互技术正是智能家居的核心。在智能家居设备中,扫地机无疑是最受欢迎的产品之一。然而,要实现一个更智能的扫地机,需要一颗语音提示芯片,以提供高质量的语音交互体验…...
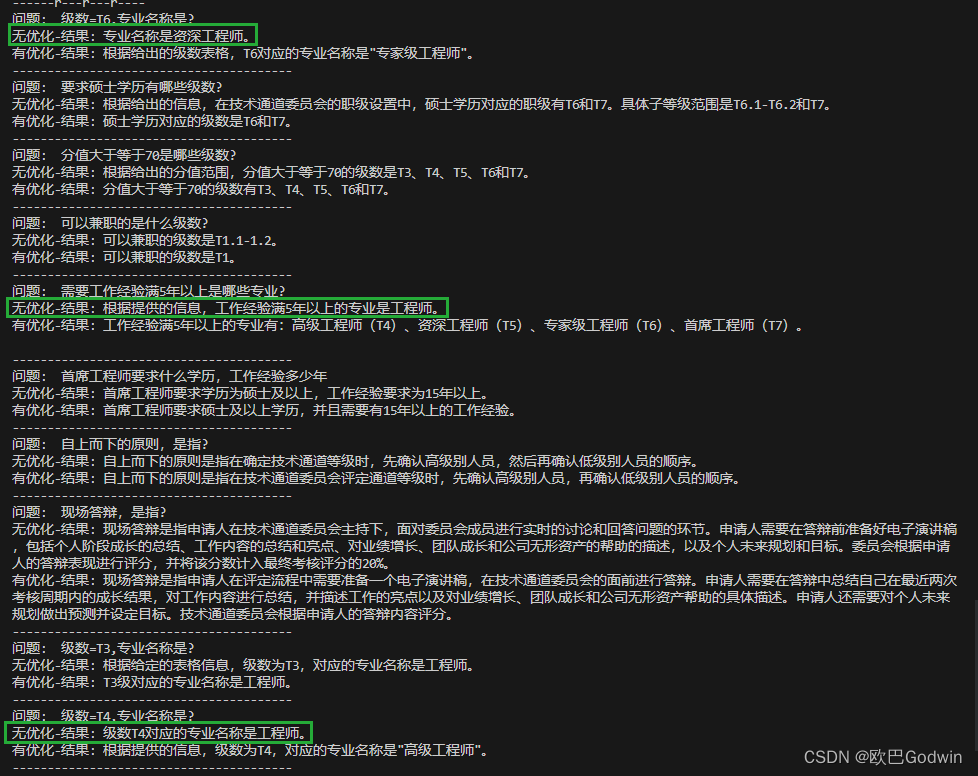
ChatGPT | 分割Word文字及表格,优化文本分析
知识库读取Word内容时,由于embedding切片操作,可能会出现表格被分割成多个切片的情况。这种切片方式可能导致“列名栏”和“内容栏”之间的Y轴关系链断裂,从而无法准确地确定每一列的数据对应关系,从而使得无法准确知道每一列的数…...

基于JavaSE的手机库存管理系统
1、项目背景 基于JavaSE完成如下需求: 功能需求: 1、查询库存量 2、可以修改库存中不同品牌手机的个数 3、退出系统 实现步骤: 1、把List当做库房 2、把手机存放在库房中 3、使用封装的方法区操作仓库中的手机 2、项目知识点 面向对象 集合…...
)
驱动开发 day4 (led灯组分块驱动)
//编译驱动(注意Makefile的编译到移植到开发板的内核) make archarm //清除编译生成文件 make clean //安装驱动 insmod mycdev.ko //卸载驱动 rmmod mycdev //编译fun.c 函数(用到交叉工具编译) arm-linux-gnueabihf-gcc fun.c head.h #ifndef __HEAD_H__ #define __HEAD_H__…...
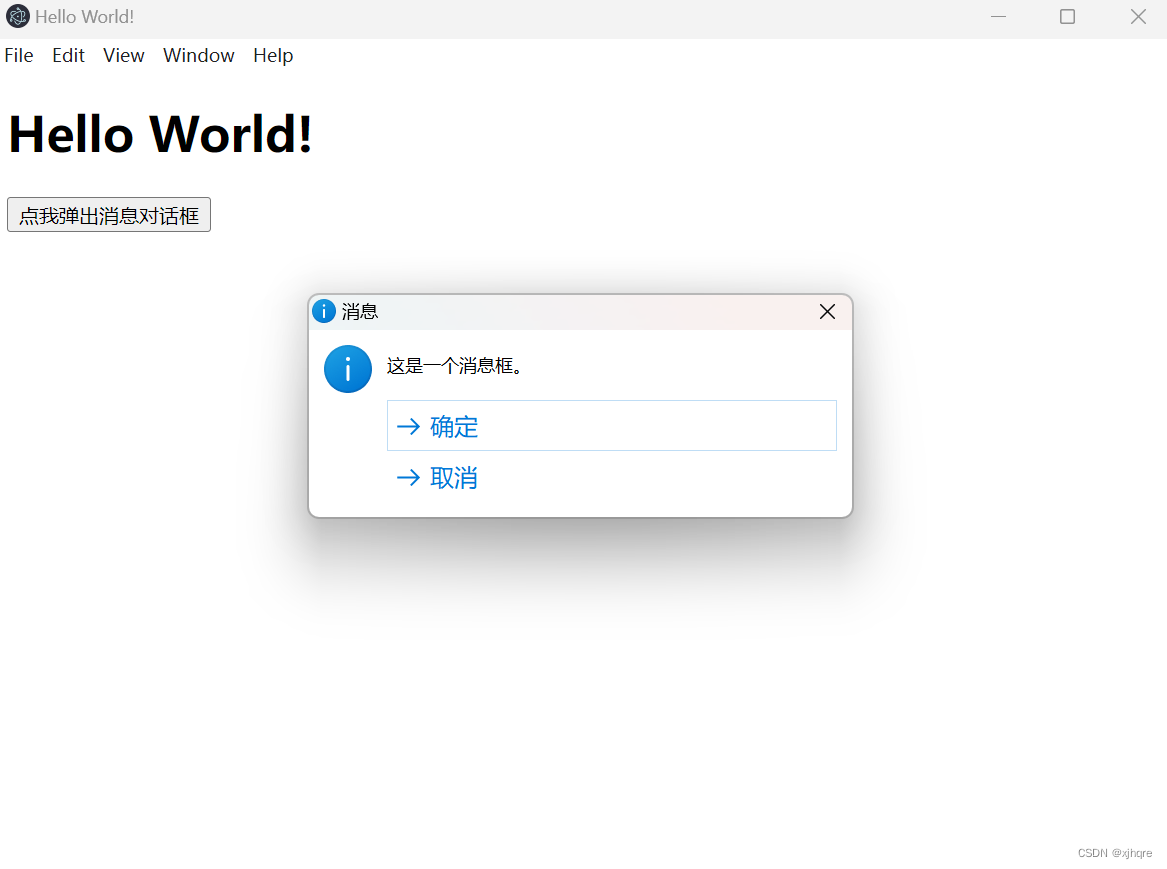
electron dialog.showMessageBox使用案例
electron 版本:25.3.1 index.html <!DOCTYPE html> <html> <head><meta charset"UTF-8"><title>Hello World!</title><meta http-equiv"Content-Security-Policy" content"script-src self unsa…...

代码随想录算法训练营第二十二天 | 读PDF复习环节2
读PDF复习环节2 本博客的内容只是做一个大概的记录,整个PDF看下来,内容上是不如代码随想录网站上的文章全面的,并且PDF中有些地方的描述,是很让我疑惑的,在困扰我很久后,无意间发现,其网站上的讲…...

TimescaleDB时序数据库初识
注:本文翻译自https://legacy-docs.timescale.com/v1.7/introduction TimescaleDB是一个开源时间序列数据库,针对快速摄取和复杂查询进行了优化。它说的是“完整的SQL”,因此像传统的关系数据库一样易于使用,并且以以前为NoSQL数…...

Numpy-聚合函数
NumPy 提供了很多统计函数,用于从数组中查找最小元素,最大元素,百分位标准差和方差等。 函数名说明np.sum()求和np.prod()所有元素相乘np.mean()平均值np.std()标准差np.var()方差np.median()中位数np.power()幂运算np.sqrt()开方np.min()最小…...
企业博客资讯如何高效运营起来?
运营一个高效的企业博客资讯需要综合考虑多个因素,包括内容策划、发布频率、优化推广、互动反馈等。下面将从这些方面介绍如何高效运营企业博客资讯。 如何高效运营企业博客资讯 内容策划 首先,需要制定一个明确的内容策略。确定博客的定位和目标受众…...

跟我学c++中级篇——模板的继承
一、继承 面向对象编程有三个特点:封装、继承和多态。其中继承在其中起着承上启下的作用。一般来说,继承现在和组合的应用比较难区分,出于各种场景和目的,往往各有千秋。但目前主流的观点,一般是如果没有特殊情况&…...
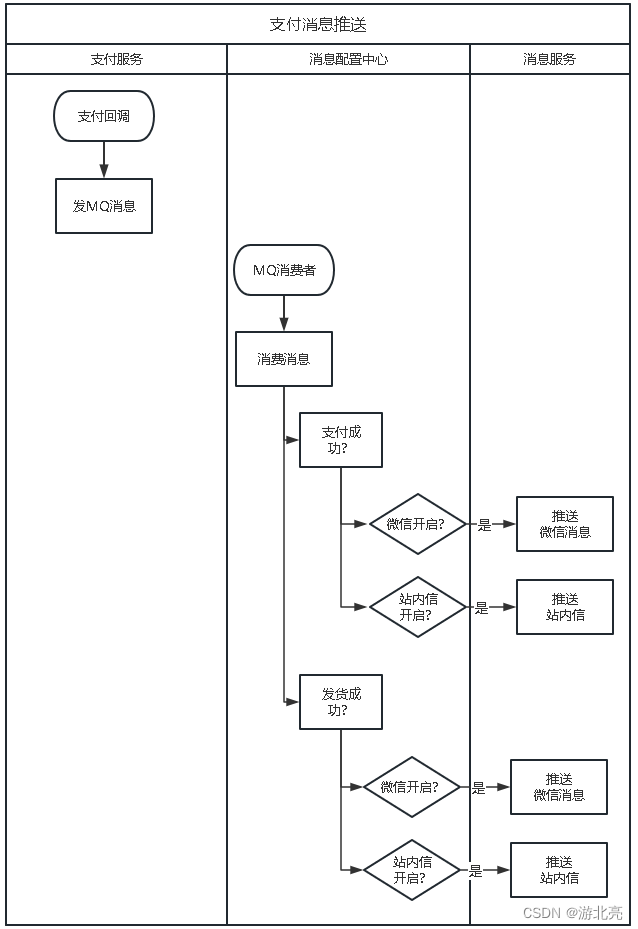
需求分析案例:消息配置中心
本文介绍了一个很常见的消息推送需求,在系统需要短信、微信、邮件之类的消息推送时,边界如何划分和如何设计技术方案。 1、需求 一个系统,一般会区分多个业务模块,并拆分成不同的业务系统,例如一个商城的架构如下&am…...

自动化测试——环境
一、搭建环境 1、安装Slenium pip install selenium 2、安装浏览器驱动-》查询浏览器版本-》下载对应版本驱动-》在path路径中配置(浏览器更新需要重新下载) pip install webdriver -helper(自动化)python3.9以上 pip install 安…...

短视频矩阵营销系统技术开发者开发笔记分享
一、开发短视频seo抖音矩阵系统需要遵循以下步骤: 1. 确定系统需求:根据客户的需求,确定系统的功能和特点,例如用户注册登录、视频上传、视频浏览、评论点赞等。 2. 设计系统架构:根据系统需求,设计系统的…...

vue2和vue3引用ueditor的区别
官方文档入口 UEditor Docs vue2使用方式 UE.vue组件 <template><div><script id"editor" type"text/plain"></script><Upload v-if"isupload" :config"{total:9}" :isupload"isupload" ret…...
)
别再手动点菜单了!用这招让Cadence Virtuoso Schematic效率翻倍(附Net高亮快捷键配置)
电路设计效率革命:Cadence Virtuoso Schematic高阶快捷键配置指南 在集成电路设计的浩瀚宇宙中,Cadence Virtuoso如同设计师手中的光刻机,每一次精准操作都直接影响最终芯片的性能与可靠性。然而,当面对数百个晶体管组成的复杂模…...

[智能体-69]:重新认知MCP:协议不生产智能,只是AI全域交互的标准化基石
MCP只是提供了大模型、编排调度、外部工具能够进行结构化交流的标准,而整个系统的智能主要依赖编排调度,与外部软件系统的交互取决于外部工具,包括外部语音交互、视觉交互、数字化交互。当下MCP(Model Context Protocol࿰…...

物联网与云技术赋能咖啡后处理:CeriTech 的实时监控系统实践
1. 项目概述:用物联网与云技术重塑咖啡后处理在印尼的咖啡农场里,传统的发酵与干燥过程很大程度上依赖“感觉”和“经验”。一位有经验的农人可能会用手触摸、用鼻子闻,或者根据天气和日照时间来估算发酵是否完成、干燥是否均匀。这种方法固然…...

如何高效批量下载音乐歌词:智能歌词管理完整指南
如何高效批量下载音乐歌词:智能歌词管理完整指南 【免费下载链接】ZonyLrcToolsX ZonyLrcToolsX 是一个能够方便地下载歌词的小软件。 项目地址: https://gitcode.com/gh_mirrors/zo/ZonyLrcToolsX ZonyLrcToolsX 是一款专业的跨平台歌词下载工具,…...
)
Windows10下V-REP教育版安装保姆级教程(附百度网盘资源与避坑点)
Windows10系统V-REP教育版完整安装指南:从下载到实战避坑在机器人仿真和自动化控制领域,V-REP(现更名为CoppeliaSim)作为一款功能强大的跨平台机器人仿真软件,已经成为众多工科学生和研究人员的首选工具。特别是其教育…...

LangGraph状态机工程:构建复杂AI工作流的完整指南
传统RAG(检索增强生成)在处理简单的"单跳"问题时表现良好——“文章里提到了什么” “这个概念是什么意思”——但当问题涉及多个实体之间的关系、需要跨多个文档推理时,传统RAG就显得力不从心。GraphRAG(Graph-based R…...
)
告别SVN恐惧症:美术策划也能轻松上手的Unity PlasticSCM极简入门(附团队项目拉取实战)
告别SVN恐惧症:美术策划也能轻松上手的Unity PlasticSCM极简入门(附团队项目拉取实战) 在游戏开发团队中,版本控制系统是协作的基石,但传统工具如SVN往往让非技术成员望而生畏。当美术资源频繁更新、策划案不断迭代时&…...

Lovable电商网站搭建:如何用不到3人技术团队,72小时内上线PCI-DSS合规MVP版本?
更多请点击: https://codechina.net 第一章:Lovable电商网站搭建 Lovable 是一个面向中小商户的轻量级电商解决方案,采用现代 Web 技术栈构建,强调可扩展性、用户体验与快速部署能力。本章将指导你从零开始搭建一个具备商品展示、…...

Claude Code + LM Studio + CC-Switch 本地自动化编程部署指南
Claude Code LM Studio CC-Switch 本地自动化编程部署指南 本指南汇总了在 Windows 本地环境下,使用 Claude Code 配合 LM Studio 本地模型、CC-Switch 代理进行自动化编程开发的完整配置方案。 目录 硬件与模型选型LM Studio 本地模型部署CC-Switch 代理配置Cla…...

如何在5分钟内免费搭建工业级OpenPLC虚拟控制器
如何在5分钟内免费搭建工业级OpenPLC虚拟控制器 【免费下载链接】OpenPLC Software for the OpenPLC - an open source industrial controller 项目地址: https://gitcode.com/gh_mirrors/op/OpenPLC OpenPLC是一款功能强大的开源虚拟PLC(可编程逻辑控制器&a…...